
% netstat -r
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
default outside-gw UGS 37 418 em0
localhost localhost UH 0 181 lo0
test0 0:e0:b5:36:cf:4f UHLW 5 63288 re0 77
10.20.30.255 link#1 UHLW 1 2421
example.com link#1 UC 0 0
host1 0:e0:a8:37:8:1e UHLW 3 4601 lo0
host2 0:e0:a8:37:8:1e UHLW 0 5 lo0 =>
host2.example.com link#1 UC 0 0
224 link#1 UC 0 0Capítulo 34. Redes Avanzadas
This translation may be out of date. To help with the translations please access the FreeBSD translations instance.
Tabla de contenidos
34.1. Sinopsis
Este capítulo cubre cierto número de temas avanzados de redes.
Después de leer este capítulo, sabrás:
Lo básico acerca de gateways y rutas.
Cómo configurar tethering por USB.
Cómo configurar dispositivos IEEE® 802.11 y Bluetooth®.
Cómo hacer que FreeBSD actúe como un puente.
Cómo configurar arranque por red PXE.
Cómo habilitar y utilizar las características del Common Address Redundancy Protocol (CARP) en FreeBSD.
Cómo configurar múltiples VLANs en FreeBSD.
Configurar unos auriculares con micrófono vía bluetooth.
Antes de leer este capítulo, deberías:
Comprender lo básico acerca de los scripts /etc/rc.
Estar familiarizado con la terminología básica de red.
Entendiendo la configuración básica de red en FreeBSD (FreeBSD network).
Saber cómo configurar e instalar un nuevo kernel de FreeBSD (Configurando el Núcleo de FreeBSD).
Cómo instalar software adicional de terceros (Instalando Aplicaciones: Paquetes y Ports).
34.2. Gateways y Rutas
Routing es el mecanismo que permite a un sistema encontrar el camino de red a otro sistema. Una ruta es un par de direcciones definido las cuales representan el "destino" y el "gateway". La ruta indica que cuando se trata de llegar a un destino especificado, se deben enviar los paquetes a través del gateway especificado. Hay tres tipos de destinos: hosts individuales, subredes, y "default". La "ruta por defecto" se utiliza si no se puede aplicar ninguna otra ruta. También hay tres tipos de gateways: hosts individuales, interfaces, también llamados enlaces, y direcciones Ethernet (MAC). Las rutas conocidas se almacenan en una tabla de enrutamiento.
Esta sección proporciona una visión general de aspectos básicos de enrutado. Luego muestra cómo configurar un sistema FreeBSD como un router y proporciona algunas pistas para resolver problemas.
34.2.1. Enrutamiento Básico
Para ver la tabla de enrutamiento de un sistema FreeBSD, usa netstat(1):
Las entradas en este ejemplo son como sigue:
- Defecto
La primera ruta en esta tabla especifica la ruta por defecto (
default). Cuando el sistema local necesita conectarse a un host remoto, comprueba la tabla de enrutamiento para determinar si existe un camino. Si el host remoto tiene una entrada en la tabla, el sistema comprueba si puede conectar utilizando el interfaz especificado en dicha entrada.Si el destino no tiene una entrada, o si todos los caminos conocidos fallan, el sistema utiliza la entrada para el enrutamiento por defecto. Para hosts en la red de área local, el campo
Gatewayen la ruta por defecto se establece al sistema que tiene una conexión directa a Internet. Cuando se lee esta entrada, verifica que la columnaFlagsindica que el gateway se puede usar (UG).La ruta por defecto para una máquina que está funcionando como gateway para el mundo exterior será la máquina gateway del Proveedor de Servicio de Internet (ISP).
- localhost
La segunda ruta es
localhost. El interfaz especificado en la columnaNetifparalocalhostes lo0, también conocido como el dispositivo loopback. Esto indica que todo el tráfico para este destino debería ser interno, en lugar de enviarlo a través de la red.- Dirección MAC
Las direcciones que comienzan con
0:e0son direcciones MAC. FreeBSD identificará automáticamente cualquier host,test0en el ejemplo, en el Ethernet local y añadirá una ruta para ese host sobre el interfaz Ethernet, re0. Este tipo de ruta tiene un timeout, mostrado en la columnaExpire, que es usado si el host no responde en un tiempo determinado. Cuando esto sucede, la ruta a este host será automáticamente borrada. Estos hosts se identifican usando el Routing Information Protocol (RIP), que calcula rutas a los hosts locales basándose en la determinación del camino más corto.- subred
FreeBSD añadirá rutas para la subred local. En este ejemplo,
10.20.30.255es la dirección de broadcast para la subred10.20.30yexample.comes el nombre de dominio asociado con esa subred. La designaciónlink#1hace referencia a la primera tarjeta Ethernet de la máquina.Hosts en la red local y subredes locales tienen sus rutas configuradas automáticamente por un demonio llamado routed(8). Si no se está ejecutando, sólo existirán las rutas que hayan sido configuradas estáticamente por el administrador.
- host
La línea
host1hace referencia al host mediante su dirección Ethernet. Puesto que es el host que envía, FreeBSD sabe que tienen que usar el interfaz loopback (lo0) en lugar del interfaz Ethernet.Las dos líneas
host2representan alias que se crean utilizando ifconfig(8). El símbolo⇒después del interfaz lo0 indica que se ha establecido un alias además de la dirección de loopback. Estas rutas sólo se muestran en el host que suporta el alias y el resto de hosts en la red local tendrán una línealink#1para esas rutas.- 224
La última línea (subred de destino
224) tiene que ver con multicasting.
Se pueden ver varios atributos para cada ruta en la columna Flags. Flags Habituales de la Tabla de Enrutado resume algunos de estos flags y sus significados:
| Flag | Propósito |
|---|---|
U | La ruta está activa (up). |
H | La ruta de destino es un único host. |
G | Envía cualquier cosa a este destino a través de este gateway, que averiguará a dónde enviarlo a continuación. |
S | Esta ruta se ha configurado de forma estática. |
C | Clona una nueva ruta basada en esta ruta para que las máquinas puedan conectarse. Este tipo de ruta se usa normalmente para redes locales. |
W | La ruta ha sido auto configurada basada en una ruta (clonada) de una red de área local. |
L | La ruta incluye referencias a hardware Ethernet (link). |
En un sistema FreeBSD, la ruta por defecto se puede configurar en /etc/rc.conf especificando la dirección IP del gateway por defecto:
defaultrouter="10.20.30.1"
También es posible añadir la ruta de forma manual usando route:
# route add default 10.20.30.1Date cuenta de que las rutas añadidas manualmente no persisten entre reinicios. Para más información sobre la manipulación manual de tablas de enrutamiento de red, consulta route(8).
34.2.2. Configurando un Router con Rutas Estáticas
Un sistema FreeBSD se puede configurar como el gateway por defecto, o router, para una red si es un sistema "dual-homed". Un sistema "dual-homed" es una máquina que está en al menos dos redes diferentes. Típicamente cada red se conecta a un interfaz de red separada, aunque se puede usar IP aliasing para enlazar múltiples direcciones, cada una en una subred diferente, a una única interfaz física.
Para que el sistema pueda reenviar paquetes entre interfaces, FreeBSD debe ser configurado como un router. Los estándares de Internet y las buenas prácticas de ingeniería evitan que el Proyecto FreeBSD active esta característica por defecto, pero se puede configurar en el arranque añadiendo esta línea a /etc/rc.conf:
gateway_enable="YES" # Set to YES if this host will be a gateway
Para habilitar el enrutado, establece la variable sysctl(8) net.inet.ip.forwarding a 1. Para parar el enrutado, restablece esta variable a 0.
La tabla de enrutamiento de un router necesita rutas adicionales para saber cómo llegar a otras redes. Las rutas se puede añadir manualmente utilizando rutas estáticas o se pueden aprender automáticamente usando un protocolo de enrutamiento. Las rutas estáticas son apropiadas para redes pequeñas y esta sección describe cómo añadir una ruta estática para una red pequeña.
Para redes grandes, las rutas estáticas pronto se vuelven impracticables. FreeBSD incluye el demonio de enrutamiento BSD estándar routed(8), que proporciona los protocolos de enrutamiento RIP, versiones 1 y 2, y IRDP. Se puede instalar soporte para los protocolos de enrutado BGP y OSPFS usando el paquete o port net/quagga. |
Considera la siguiente red:
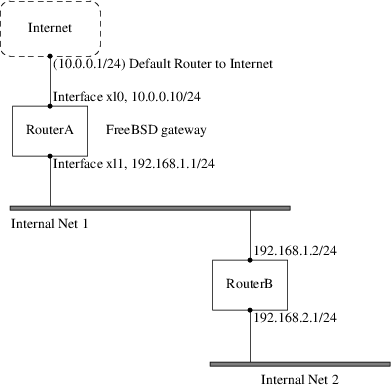
En este escenario, RouterA es una máquina FreeBSD que está actuando como un router para el resto de Internet. Tiene una ruta por defecto establecida a 10.0.0.1 que le permite conectarse con el mundo exterior. RouterB ya está configurado para utilizar 192.168.1.1 como su gateway por defecto.
Antes de añadir ninguna ruta estática, la tabla de enrutamiento de RouterA tiene este aspecto:
% netstat -nr
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
default 10.0.0.1 UGS 0 49378 xl0
127.0.0.1 127.0.0.1 UH 0 6 lo0
10.0.0.0/24 link#1 UC 0 0 xl0
192.168.1.0/24 link#2 UC 0 0 xl1Con la tabla de enrutamiento actual, RouterA no tiene una ruta a la red 192.168.2.0/24. El siguiente comando añade la red Internal Net 2 a la tabla de enrutamiento de RouterA usando 192.168.1.2 para el siguiente salto:
# route add -net 192.168.2.0/24 192.168.1.2Ahora, RouterA puede alcanzar cualquier host en la red 192.168.2.0/24. Sin embargo, la información de enrutamiento no persistirá si el sistema FreeBSD se reinicia. Si una ruta estática necesita ser persistente, añádela a /etc/rc.conf:
# Add Internal Net 2 as a persistent static route static_routes="internalnet2" route_internalnet2="-net 192.168.2.0/24 192.168.1.2"
La variable de configuración static_routes es una lista de cadenas separadas por un espacio, donde cada cadena referencia el nombre de una ruta. La variable route_internalnet2 contiene la ruta estática para el nombre de esa ruta.
Usar más de una cadena en static_routes crea múltiples rutas estáticas. Lo siguiente muestra un ejemplo de cómo añadir rutas estáticas para las redes 192.168.0.0/24 y 192.168.1.0/24:
static_routes="net1 net2" route_net1="-net 192.168.0.0/24 192.168.0.1" route_net2="-net 192.168.1.0/24 192.168.1.1"
34.2.3. Resolución de problemas
Cuando se asigna un espacio de direcciones a una red, el proveedor de servicio configura sus propias tablas de enrutamiento de forma que todo el tráfico para la red se enviará a través del enlace para el sitio. Pero ¿cómo saben los sitios externos que tienen que enviar sus paquetes al ISP de la red?
Hay un sistema que lleva el control de todos los espacios de direcciones asignados y define sus puntos de conexión a la red principal de Internet, o las líneas troncales que llevan el tráfico por todo el país y alrededor del mundo. Cada máquina troncal tiene una copia de un conjunto maestro de tablas, las cuales dirigen el tráfico para una red particular hacia un portador troncal específico, y de ahí bajando por la cadena de proveedores de servicio hasta que alcanza una red particular.
Es tarea del proveedor de servicio avisar a los sitios troncales de que son el punto de conexión, y por tanto el camino de entrada, para un sitio. Esto se conoce como propagación de ruta.
A veces, hay algún problema con la propagación de ruta y algunos sitios son incapaces de conectar. Quizás el comando más útil para intentar averiguar dónde se rompe la ruta es traceroute. Es útil cuando ping falla.
Cuando uses traceroute, incluye la dirección del host remoto al que conectar. La salida mostrará el gateway junto con el camino que sigue el intento, eventualmente alcanzando el destino, o terminando debido a la falta de conexión. Para más información, consulta traceroute(8).
34.2.4. Consideraciones para Multicast
FreeBSD soporta de forma nativa tanto aplicaciones multicast como enrutamiento multicast. Las aplicaciones multicast no necesitan ninguna configuración especial para ejecutarse en FreeBSD. El soporte para enrutamiento multicast requiere que la siguiente opción esté incluida en un kernel personalizado:
options MROUTING
El demonio de enrutamiento multicast, mrouted se puede instalar usando el paquete o port net/mrouted. Este demonio implementa el protocolo de enrutamiento multicast DVMRP y se configura editando el fichero /usr/local/etc/mrouted.conf para configurar los túneles y DVMRP. La instalación de mrouted también instala map-mbone y mrinfo, así como sus páginas de manual. Consúltalas para ver ejemplos de configuración.
DVMRP ha sido ampliamente sustituido por el protocolo PIM en muchas instalaciones multicast. Consulta pim(4) para más información. |
34.3. Hosts Virtuales
Un uso habitual para FreeBSD es el de proporcionar alojamiento virtual de sitios, donde un servidor aparece en la red como muchos servidores. Esto se consigue asignando múltiples direcciones de red a una única interfaz.
Una interfaz dada tiene una dirección "real", y puede tener un determinado número de direcciones "alias". Estos alias se añaden normalmente poniendo entradas alias en /etc/rc.conf, como se ve en este ejemplo:
# sysrc ifconfig_fxp0_alias0="inet xxx.xxx.xxx.xxx netmask xxx.xxx.xxx.xxx"Las entradas de alias deben empezar con alias0 usando un número secuencial como alias0, alias1, y así sucesivamente. El proceso de configuración terminará en el primer número que falte.
El cálculo de las máscaras de red de los alias es importante. Para una interfaz data, debe haber una dirección que represente correctamente la máscara de la red. Cualquier otra dirección que esté en esta red tiene que tener una más cara con todo 1s, expresada como 255.255.255.255 o 0xffffffff.
Por ejemplo, considera el caso donde la interfaz fxp0 está conectada a dos redes: 10.1.1.0 con máscara de red 255.255.255.0 y 202.0.75.16 con máscara de red`255.255.255.240`. El sistema está configurado para aparecer en los rangos 10.1.1.1 hasta 10.1.1.5 y 202.0.75.17 hasta 202.0.75.20. Sólo la primera dirección en un rango de red dado debería tener una máscara de red real. Todas las demás (10.1.1.2 hasta 10.1.1.5 y 202.0.75.18 hasta 202.0.75.20) se deben configurar con máscara de red 255.255.255.255.
Las siguientes entradas de /etc/rc.conf configuran correctamente el adaptador para este escenario:
# sysrc ifconfig_fxp0="inet 10.1.1.1 netmask 255.255.255.0"
# sysrc ifconfig_fxp0_alias0="inet 10.1.1.2 netmask 255.255.255.255"
# sysrc ifconfig_fxp0_alias1="inet 10.1.1.3 netmask 255.255.255.255"
# sysrc ifconfig_fxp0_alias2="inet 10.1.1.4 netmask 255.255.255.255"
# sysrc ifconfig_fxp0_alias3="inet 10.1.1.5 netmask 255.255.255.255"
# sysrc ifconfig_fxp0_alias4="inet 202.0.75.17 netmask 255.255.255.240"
# sysrc ifconfig_fxp0_alias5="inet 202.0.75.18 netmask 255.255.255.255"
# sysrc ifconfig_fxp0_alias6="inet 202.0.75.19 netmask 255.255.255.255"
# sysrc ifconfig_fxp0_alias7="inet 202.0.75.20 netmask 255.255.255.255"Una forma más sencilla de expresar esto es con una lista de rangos de direcciones IP separadas por espacios. A la primera dirección se le asignará la máscara de subred indicada y las demás direcciones tendrán una máscara de subred de 255.255.255.255.
# sysrc ifconfig_fxp0_aliases="inet 10.1.1.1-5/24 inet 202.0.75.17-20/28"34.4. Autenticación Inalámbrica Avanzada
FreeBSD soporta distintas formas de conectarse a una red inalámbrica. Esta sección describe como realizar autenticación avanzada en una Red Inalámbrica.
Para hacer una conexión y autenticación básica a una red inalámbrica la sección Conexión y Autenticación a una Red Inalámbrica en el Capítulo de Red describe como hacerlo.
34.4.1. WPA with EAP-TLS
La segunda forma de utilizar WPA es con un servidor de autenticación 802.1X. En este caso, WPA se llama WPA Enterprise para diferenciarlo del WPA Personal menos seguro. La autenticación en WPA Enterprise se basa en el Extensible Authentication Protocol (EAP).
EAP no viene con un método de encriptación. En su lugar, EAP se introduce dentro de un túnel encriptado. Hay muchos métodos de autenticación EAP, pero EAP-TLS, EAP-TTLS, y EAP-PEAP son los más comunes.
EAP con Transport Layer Security (EAP-TLS) es un protocolo de autenticación inalámbrica bien soportado ya que fue el primer método EAP certificado por la Wi-Fi Alliance. EAP-TLS requiere tres certificados para funcionar: el certificado de Certificate Authority (CA) instalado en todas las máquinas, el certificado de servidor para el servidor de autenticación, y un cliente de certificado para cliente inalámbrico. En este método EAP, tanto el servidor de autenticación como el cliente inalámbrico se autentican entre sí presentando sus respectivos certificados, y luego verificando que estos certificados están firmados por la CA de la organización.
Como antes, la configuración se hace mediante /etc/wpa_supplicant.conf:
network={
ssid="freebsdap" (1)
proto=RSN (2)
key_mgmt=WPA-EAP (3)
eap=TLS (4)
identity="loader" (5)
ca_cert="/etc/certs/cacert.pem" (6)
client_cert="/etc/certs/clientcert.pem" (7)
private_key="/etc/certs/clientkey.pem" (8)
private_key_passwd="freebsdmallclient" (9)
}| 1 | Este campo indica el nombre de la red (SSID). |
| 2 | Este ejemplo utiliza el protocolo RSN IEEE® 802.11i también conocido como WPA2. |
| 3 | La línea key_mgmt hace referencia al protocolo de gestión de claves que se utiliza. En este ejemplo, es WPA con autenticación EAP. |
| 4 | Este campo indica el método EAP para la conexión. |
| 5 | El campo identity contiene la cadena de identidad para EAP. |
| 6 | El campo ca_cert indica la ruta al fichero del certificado de CA. Este fichero es necesario para verificar el certificado de servidor. |
| 7 | La línea cliente_cert da la ruta al fichero de certificado del cliente. Este certificado es único para cada cliente inalámbrico de la red. |
| 8 | El campo private_key es la ruta al fichero de clave privada del certificado del cliente. |
| 9 | El campo private_key_passwd contienen la contraseña para la clave privada. |
Después, añade las siguientes líneas a /etc/rc.conf:
wlans_ath0="wlan0" ifconfig_wlan0="WPA DHCP"
El siguiente paso es levantar la interfaz:
# service netif start
Starting wpa_supplicant.
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 7
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 15
DHCPACK from 192.168.0.20
bound to 192.168.0.254 -- renewal in 300 seconds.
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
ether 00:11:95:d5:43:62
inet 192.168.0.254 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet DS/11Mbps mode 11g
status: associated
ssid freebsdap channel 1 (2412 Mhz 11g) bssid 00:11:95:c3:0d:ac
country US ecm authmode WPA2/802.11i privacy ON deftxkey UNDEF
AES-CCM 3:128-bit txpower 21.5 bmiss 7 scanvalid 450 bgscan
bgscanintvl 300 bgscanidle 250 roam:rssi 7 roam:rate 5 protmode CTS
wme burst roaming MANUALTambién es posible levantar la interfaz manualmente utilizando wpa_supplicant(8) y ifconfig(8).
34.4.2. WPA with EAP-TTLS
Con EAP-TLS, tanto la autenticación de servidor como la de cliente necesitan un certificado. Con EAP-TTLS, el certificado de cliente es opcional. Este método es similar a un servidor web que crea un tunel SSL seguro incluso cuando los visitantes no tienen certificados de cliente. EAP-TTLS utiliza un túnel encriptado con TLS para el transporte seguro de los datos de autenticación.
La configuración necesaria se puede añadir a /etc/wpa_supplicant.conf:
network={
ssid="freebsdap"
proto=RSN
key_mgmt=WPA-EAP
eap=TTLS (1)
identity="test" (2)
password="test" (3)
ca_cert="/etc/certs/cacert.pem" (4)
phase2="auth=MD5" (5)
}| 1 | Este campo especifica el método EAP para la conexión. |
| 2 | El campo identity contiene la cadena de identidad para la autenticación EAP dentro del túnel encriptado con TLS. |
| 3 | El campo password contiene la contraseña para la autenticación EAP. |
| 4 | El campo ca_cert indica la ruta al fichero del certificado de CA. Este fichero es necesario para verificar el certificado de servidor. |
| 5 | Este campo especifica el método de autenticación usado en el túnel TLS encriptado. En este ejemplo, se utiliza EAP con MD5-Challenge. La fase de "autenticación interna" se llama habitualmente "phase2". |
Después, añade las siguientes líneas a /etc/rc.conf:
wlans_ath0="wlan0" ifconfig_wlan0="WPA DHCP"
El siguiente paso es levantar la interfaz:
# service netif start
Starting wpa_supplicant.
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 7
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 15
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 21
DHCPACK from 192.168.0.20
bound to 192.168.0.254 -- renewal in 300 seconds.
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
ether 00:11:95:d5:43:62
inet 192.168.0.254 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet DS/11Mbps mode 11g
status: associated
ssid freebsdap channel 1 (2412 Mhz 11g) bssid 00:11:95:c3:0d:ac
country US ecm authmode WPA2/802.11i privacy ON deftxkey UNDEF
AES-CCM 3:128-bit txpower 21.5 bmiss 7 scanvalid 450 bgscan
bgscanintvl 300 bgscanidle 250 roam:rssi 7 roam:rate 5 protmode CTS
wme burst roaming MANUAL34.4.3. WPA with EAP-PEAP
PEAPv0/EAP-MSCHAPv2 es el método PEAP más común. En este capítulo, el término PEAP se usa para referirnos a ese método. |
Protected EAP (PEAP) se diseñó como una alternativa a EAP-TTLS y es el segundo estándar EAP más usado por detrás de EAP-TLS. En una red con sistemas operativos variados, PEAP debería ser el estándar más soportado por detrás de EAP-TLS.
PEAP es similar a EAP-TTLS ya que utiliza un certificado de servidor para autenticar clientes mediante la creación de un túnel TLS encriptado entre el cliente y el servidor de autenticación, el cual protege el subsiguiente intercambio de información de autenticación. La autenticación PEAP es diferente de EAP-TTLS ya que emite el usuario sin encriptar y sólo la contraseña se envía por el túnel TLS encriptado. EAP-TTLS utilizará el túnel TLS tanto para el nombre de usuario como para la contraseña.
Añade las siguientes líneas a /etc/wpa_supplicant.conf para configurar los parámetros relacionados con EAP-PEAP:
network={
ssid="freebsdap"
proto=RSN
key_mgmt=WPA-EAP
eap=PEAP (1)
identity="test" (2)
password="test" (3)
ca_cert="/etc/certs/cacert.pem" (4)
phase1="peaplabel=0" (5)
phase2="auth=MSCHAPV2" (6)
}| 1 | Este campo especifica el método EAP para la conexión. |
| 2 | El campo identity contiene la cadena de identidad para la autenticación EAP dentro del túnel encriptado con TLS. |
| 3 | El campo password contiene la contraseña para la autenticación EAP. |
| 4 | El campo ca_cert indica la ruta al fichero del certificado de CA. Este fichero es necesario para verificar el certificado de servidor. |
| 5 | Este campo contiene los parámetros para la primera fase de autenticación, el túnel TLS. Según el servidor de autenticación utilizado, especifica una etiqueta concreta para la autenticación. La mayoría de las veces la etiqueta será "cliente EAP encryption" que se establece usando peaplabel=0. Se puede encontrar más información en wpa_supplicant.confg(5). |
| 6 | Este campo especifica el protocolo de autenticación utilizado en el túnel encriptado con TLS. En el caso de PEAP, es auth=MSCHAPV2. |
Añade lo siguiente a /etc/rc.conf:
wlans_ath0="wlan0" ifconfig_wlan0="WPA DHCP"
Después, levanta la interfaz:
# service netif start
Starting wpa_supplicant.
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 7
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 15
DHCPREQUEST on wlan0 to 255.255.255.255 port 67 interval 21
DHCPACK from 192.168.0.20
bound to 192.168.0.254 -- renewal in 300 seconds.
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
ether 00:11:95:d5:43:62
inet 192.168.0.254 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet DS/11Mbps mode 11g
status: associated
ssid freebsdap channel 1 (2412 Mhz 11g) bssid 00:11:95:c3:0d:ac
country US ecm authmode WPA2/802.11i privacy ON deftxkey UNDEF
AES-CCM 3:128-bit txpower 21.5 bmiss 7 scanvalid 450 bgscan
bgscanintvl 300 bgscanidle 250 roam:rssi 7 roam:rate 5 protmode CTS
wme burst roaming MANUAL34.5. Modo Ad-hoc Inalámbrico
El modo IBSS, también llamado modo ad-hoc, está diseñado para comunicaciones punto a punto. Por ejemplo, para establecer una red ad-hoc entre las máquinas A y B, escoge dos direcciones IP y un SSID.
En A:
# ifconfig wlan0 create wlandev ath0 wlanmode adhoc
# ifconfig wlan0 inet 192.168.0.1 netmask 255.255.255.0 ssid freebsdap
# ifconfig wlan0
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 00:11:95:c3:0d:ac
inet 192.168.0.1 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet autoselect mode 11g <adhoc>
status: running
ssid freebsdap channel 2 (2417 Mhz 11g) bssid 02:11:95:c3:0d:ac
country US ecm authmode OPEN privacy OFF txpower 21.5 scanvalid 60
protmode CTS wme burstEl parámetro ad-hoc indica que el interfaz está funcionando en modo IBSS.
Ahora B debería ser capaz de detecta a A:
# ifconfig wlan0 create wlandev ath0 wlanmode adhoc
# ifconfig wlan0 up scan
SSID/MESH ID BSSID CHAN RATE S:N INT CAPS
freebsdap 02:11:95:c3:0d:ac 2 54M -64:-96 100 IS WMELa I en la salida confirma que A está en modo ad-hoc. Ahora, configura B con una dirección IP diferente:
# ifconfig wlan0 inet 192.168.0.2 netmask 255.255.255.0 ssid freebsdap
# ifconfig wlan0
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 00:11:95:d5:43:62
inet 192.168.0.2 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet autoselect mode 11g <adhoc>
status: running
ssid freebsdap channel 2 (2417 Mhz 11g) bssid 02:11:95:c3:0d:ac
country US ecm authmode OPEN privacy OFF txpower 21.5 scanvalid 60
protmode CTS wme burstAhora A y B están listas para intercambiar información.
34.5.1. Puntos de Acceso Host FreeBSD
FreeBSD puede actuar como un Punto de Acceso (AP) lo que elimina la necesidad de comparar un hardware AP o montar una red ad-hoc. Esto puede ser particularmente útil cuando una máquina FreeBSD está actuando como gateway a otra red como Internet.
34.5.1.1. Configuración Básica
Antes de configurar una máquina FreeBSD como un AP, el kernel se tiene que configurar con el soporte de red apropiado para la tarjeta inalámbrica así como con los protocolos de seguridad que se utilizarán. Para más detalles, consulta [network-wireless-basic].
El adaptador de controladores NDIS para controladores de Windows® actualmente no soporta operar en modo AP. Sólo los controladores inalámbricos nativos de FreeBSD soportan modo AP. |
Una vez que se ha cargado el soporte para redes inalámbricas, comprueba si el dispositivo inalámbrico soporta el modo de punto de acceso basado en host, también conocido como modo hostap:
# ifconfig wlan0 create wlandev ath0
# ifconfig wlan0 list caps
drivercaps=6f85edc1<STA,FF,TURBOP,IBSS,HOSTAP,AHDEMO,TXPMGT,SHSLOT,SHPREAMBLE,MONITOR,MBSS,WPA1,WPA2,BURST,WME,WDS,BGSCAN,TXFRAG>
cryptocaps=1f<WEP,TKIP,AES,AES_CCM,TKIPMIC>Esta salida muestra las capacidades de la tarjeta. La palabra HOSTAP confirma que la tarjeta inalámbrica puede actuar como un AP. También se listan varios encriptadores soportados: WEP, TKIP, y AES. Esta información indica qué protocolos de seguridad se pueden utilizar con el AP.
El dispositivo inalámbrico sólo puede ser puesto en modo hostap durante la creación del pseudo-dispositivo de red, de forma que si hay una dispositivo creado anteriormente se tiene que destruir primero:
# ifconfig wlan0 destroydespués regenerado con la opción correcta antes de establecer otros parámetros:
# ifconfig wlan0 create wlandev ath0 wlanmode hostap
# ifconfig wlan0 inet 192.168.0.1 netmask 255.255.255.0 ssid freebsdap mode 11g channel 1Usa ifconfig(8) de nuevo para ver el estado de la interfaz wlan0:
# ifconfig wlan0
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 00:11:95:c3:0d:ac
inet 192.168.0.1 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet autoselect mode 11g <hostap>
status: running
ssid freebsdap channel 1 (2412 Mhz 11g) bssid 00:11:95:c3:0d:ac
country US ecm authmode OPEN privacy OFF txpower 21.5 scanvalid 60
protmode CTS wme burst dtimperiod 1 -dfsEl parámetro hostap indica que el interfaz está funcionando en modo punto de acceso basado en host.
La configuración del interfaz se puede hacer de forma automática al arrancar añadiendo las siguientes líneas a /etc/rc.conf:
wlans_ath0="wlan0" create_args_wlan0="wlanmode hostap" ifconfig_wlan0="inet 192.168.0.1 netmask 255.255.255.0 ssid freebsdap mode 11g channel 1"
34.5.1.2. Punto de Acceso basado en Host Sin Autenticación o Encriptación
Aunque no se recomienda ejecutar un AP sin ninguna autenticación o encriptación, es una forma simple de comprobar que el AP funciona. Esta configuración también es importante para depurar problemas en el cliente.
Una vez que el AP está configurado, inicia un escaneo desde otra máquina inalámbrica para encontrar el AP:
# ifconfig wlan0 create wlandev ath0
# ifconfig wlan0 up scan
SSID/MESH ID BSSID CHAN RATE S:N INT CAPS
freebsdap 00:11:95:c3:0d:ac 1 54M -66:-96 100 ES WMELa máquina cliente ha encontrado el AP y se puede asociar con él:
# ifconfig wlan0 inet 192.168.0.2 netmask 255.255.255.0 ssid freebsdap
# ifconfig wlan0
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 00:11:95:d5:43:62
inet 192.168.0.2 netmask 0xffffff00 broadcast 192.168.0.255
media: IEEE 802.11 Wireless Ethernet OFDM/54Mbps mode 11g
status: associated
ssid freebsdap channel 1 (2412 Mhz 11g) bssid 00:11:95:c3:0d:ac
country US ecm authmode OPEN privacy OFF txpower 21.5 bmiss 7
scanvalid 60 bgscan bgscanintvl 300 bgscanidle 250 roam:rssi 7
roam:rate 5 protmode CTS wme burst34.5.1.3. Punto de Acceso WPA2 basado en Host
Esta sección se centra en configurar un punto de acceso FreeBSD usando el protocolo de seguridad WPA2. Se pueden encontrar más detalles acerca de WPA y de la configuración de clientes inalámbricos basados en WPA en [network-wireless-wpa].
El demonio hostapd(8) se usa para manejar la autenticación del cliente y la gestión de la clave en el AP con WPA2 habilitado.
Una máquina FreeBSD configurada como AP realiza las siguientes operaciones de configuración. Una vez que el AP está funcionando correctamente, se puede iniciar hostapd(8) durante el arranque con esta línea en /etc/rc.conf:
hostapd_enable="YES"
Antes de intentar configurar hostapd(8), primero configura los parámetros básicos presentados en Configuración Básica.
WPA2-PSK
WPA2-PSK está pensado para pequeñas redes donde no se puede o no es deseable utilizar un servidor de autenticación.
La configuración se hace en /etc/hostapd.conf:
interface=wlan0 (1) debug=1 (2) ctrl_interface=/var/run/hostapd (3) ctrl_interface_group=wheel (4) ssid=freebsdap (5) wpa=2 (6) wpa_passphrase=freebsdmall (7) wpa_key_mgmt=WPA-PSK (8) wpa_pairwise=CCMP (9)
| 1 | Interfaz inalámbrica utilizada para el punto de acceso. |
| 2 | Nivel de verbosidad utilizado durante la ejecución de hostapd(8). Un valor de 1 representa el nivel mínimo. |
| 3 | Ruta del directorio utilizado por hostapd(8) para almacenar ficheros de sockets de dominio para comunicación con programas externos como hostapd_cli(8). En este ejemplo se usa el valor por defecto. |
| 4 | El grupo que tiene permitido el acceso a los ficheros de control del interfaz. |
| 5 | El nombre de la red inalámbrica, o SSID, que aparecerá en los escaneos inalámbricos. |
| 6 | Activa WPA y especifica qué protocolo de autenticación WPA se requerirá. Un valor de 2 configura el AP para WPA2 y es el recomendado. Establécelo a 1 sólo si se necesita el obsoleto WPA. |
| 7 | Contraseña ASCII para la autenticación WPA. |
| 8 | El protocolo de gestión de claves a usar. Este ejemplo establece WPA-PSK. |
| 9 | Algoritmos de encriptación aceptados por el punto de acceso. En este ejemplo, sólo se acepta el encriptador CCMP (AES). CCMP es una alternativa a TKIP y se prefiere siempre que se a posible. TKIP sólo debería permitirse cuando las estaciones con incapaces de usar CCMP. |
El siguiente paso es arrancar hostapd(8):
# service hostapd forcestart# ifconfig wlan0
wlan0: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 04:f0:21:16:8e:10
inet6 fe80::6f0:21ff:fe16:8e10%wlan0 prefixlen 64 scopeid 0x9
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
media: IEEE 802.11 Wireless Ethernet autoselect mode 11na <hostap>
status: running
ssid No5ignal channel 36 (5180 MHz 11a ht/40+) bssid 04:f0:21:16:8e:10
country US ecm authmode WPA2/802.11i privacy MIXED deftxkey 2
AES-CCM 2:128-bit AES-CCM 3:128-bit txpower 17 mcastrate 6 mgmtrate 6
scanvalid 60 ampdulimit 64k ampdudensity 8 shortgi wme burst
dtimperiod 1 -dfs
groups: wlanUna vez que el AP está funcionando, los clientes se pueden asociar a él. Consulta [network-wireless-wpa] para más detalles. Es posible ver las estaciones asociadas con el AP usando ifconfig wlan0 list sta.
34.6. Tethering USB
Muchos teléfonos móviles proporcionan la opción de compartir su conexión de datos a través de USB (habitualmente llamado "tethering"). Esta característica usa uno de los protocolos RNDIS, CDC o el protocolo personalizado Apple® iPhone®/iPad®.
Antes de conectar un dispositivo, carga el controlador apropiado en el kernel:
# kldload if_urndis
# kldload if_cdce
# kldload if_iphethUna vez que el dispositivo está conectado ue0 estará disponible para que lo usemos como un dispositivo de red normal. Asegúrate de que el dispositivo tiene la opción "USB tethering" activada.
Para hacer este cambio permanente y cargar el controlador como un módulo en el arranque, escribe la línea apropiada de las siguientes en /boot/loader.conf:
if_urndis_load="YES"
if_cdce_load="YES"
if_ipheth_load="YES"34.7. Bluetooth
Bluetooth es una tecnología inalámbrica para crear redes personales que operen en la banda sin licenciar de 2.4 GHz, con un rago de 10 metros. Las redes se forman normalmente como ad-hoc a partir de dispositivos portátiles como teléfonos móviles, tabletas, y portátiles. A diferencia de la tecnología inalámbrica Wi-Fi, Bluetooth ofrece perfiles de servicio de más alto nivel, como servidores de fichero tipo FTP, envío de ficheros, transporte de voz, emulación de línea serie, y más.
Esta sección describe el uso de un conector USB Bluetooth en un sistema FreeBSD. Después describe varias de las utilidades y protocolos de Bluetooth.
34.7.1. Cargando Soporte Bluetooth
La pila Bluetooth en FreeBSD está implementada utilizando el framework netgraph(4). Una gran variedad de conectores USB Bluetooth se soporta con ng_ubt(4). Los dispositivos Bluetooth basados en Broadcom BCM2033 se soportan mediante los controladores ubtbcmfw(4) y ng_ubt(4). La tarjeta 3Com Bluetooth PC Card 3CRWB60-A está soportada por el controlador ng_bt3c(4). Los dispositivos serie y UART Bluetooth están soportados por sio(4), ng_h4(4), y hcseriald(8).
Antes de conectar un dispositivo, determina cuál de los controladores anteriores utiliza, después carga el controlador. Por ejemplo, si el dispositivo utiliza el controlador ng_ubt(4):
# kldload ng_ubtSi el dispositivo Bluetooth se va a conectar al sistema durante el arranque, éste se puede configurar para cargar el módulo durante el arranque añadiendo el controlador a /boot/loader.conf:
ng_ubt_load="YES"
Una vez que el controlador está cargado, conecta el dispositivo USB. Si el controlador se cargó de forma correcta, en la consola y en /var/log/messages debería aparecer una salida similar a la siguiente:
ubt0: vendor 0x0a12 product 0x0001, rev 1.10/5.25, addr 2
ubt0: Interface 0 endpoints: interrupt=0x81, bulk-in=0x82, bulk-out=0x2
ubt0: Interface 1 (alt.config 5) endpoints: isoc-in=0x83, isoc-out=0x3,
wMaxPacketSize=49, nframes=6, buffer size=294Para iniciar y parar la pila Bluetooth, utiliza su script de arranque. Es una buena idea parar la pila después de desconectar el dispositivo. Arrancar la pila bluetooth podría necesitar que se arranque hcsecd(8). Cuando se arranca la pila, la salida debería ser similar a la siguiente:
# service bluetooth start ubt0
BD_ADDR: 00:02:72:00:d4:1a
Features: 0xff 0xff 0xf 00 00 00 00 00
<3-Slot> <5-Slot> <Encryption> <Slot offset>
<Timing accuracy> <Switch> <Hold mode> <Sniff mode>
<Park mode> <RSSI> <Channel quality> <SCO link>
<HV2 packets> <HV3 packets> <u-law log> <A-law log> <CVSD>
<Paging scheme> <Power control> <Transparent SCO data>
Max. ACL packet size: 192 bytes
Number of ACL packets: 8
Max. SCO packet size: 64 bytes
Number of SCO packets: 834.7.2. Encontrando Otros Dispositivos Bluetooth
El Host Controller Interface (HCI) proporciona un método uniforme para acceder a las capacidades de la banda base de Bluetooth. En FreeBSD, se crea un nodo HCI de netgraph para cada dispositivo Bluetooth. Para más detalles, consulta ng_hci(4).
Una de las tareas más comunes es el descubrimiento de dispositivos Bluetooth dentro del rango de proximidad de RF. Esta operación se llama inquiry (pregunta). Inquiry y otras operaciones HCI relacionadas se ejecutan con hccontrol(8). El ejemplo de abajo muestra cómo encontrar dispositivos Bluetooth que están dentro de rango. La lista de dispositivos debería mostrarse en unos pocos segundos. Ten en cuenta que un dispositivo remoto sólo contestará a la pregunta si está en modo descubrible.
% hccontrol -n ubt0hci inquiry
Inquiry result, num_responses=1
Inquiry result #0
BD_ADDR: 00:80:37:29:19:a4
Page Scan Rep. Mode: 0x1
Page Scan Period Mode: 00
Page Scan Mode: 00
Class: 52:02:04
Clock offset: 0x78ef
Inquiry complete. Status: No error [00]BD_ADDR es la dirección única de un dispositivo Bluetooth, similar a la dirección MAC de una tarjeta de red. Esta dirección es necesaria para la comunicación posterior con el dispositivo y es posible asignarle un valor que se amigable de leer. Hay información acerca de los hosts Bluetooth conocidos en /etc/bluetooth/hosts. El siguiente ejemplo muestra cómo obtener un nombre legible por las personas que ha sido asignado a un dispositivo remoto:
% hccontrol -n ubt0hci remote_name_request 00:80:37:29:19:a4
BD_ADDR: 00:80:37:29:19:a4
Name: Pav's T39Si se realiza una pregunta a un dispositivo Bluetooth remoto, encontrará tu ordenador como "your.host.name (ubt0)". El nombre asignado al dispositivo local se puede cambiar en cualquier momento.
Se puede asignar alias a los dispositivos remotos en /etc/bluetooth/hosts. Se puede encontrar más información acerca de /etc/bluetooth/hosts en bluetooth.hosts(5).
El sistema Bluetooth proporciona conexión punto a punto entre dos unidades Bluetooth, o punto a multipunto que se comparte entre varios dispositivos Bluetooth. El siguiente ejemplo muestra cómo crear una conexión con un dispositivo remoto:
% hccontrol -n ubt0hci create_connection BT_ADDRcreate_connection acepta BT_ADDR así como los alias encontrados en /etc/bluetooth/hosts.
El siguiente ejemplo muestra cómo obtener la lista de conexiones activas en la banda base para el dispositivo local:
% hccontrol -n ubt0hci read_connection_list
Remote BD_ADDR Handle Type Mode Role Encrypt Pending Queue State
00:80:37:29:19:a4 41 ACL 0 MAST NONE 0 0 OPENUn manejador de conexión es útil cuando se requiere la terminación de una conexión de la banda base, aunque normalmente no es necesario hacer esto a mano. La pila terminará automáticamente las conexiones de banda base inactivas.
# hccontrol -n ubt0hci disconnect 41
Connection handle: 41
Reason: Connection terminated by local host [0x16]Teclea hccontrol help para obtener un listado completo de los comandos HCI disponibles. La mayoría de los comandos HCI no requieren privilegios de súper usuario.
34.7.3. Emparejamiento de Dispositivos
Por defecto, la comunicación Bluetooth no está autenticada, y cualquier dispositivo puede hablar con cualquier otro. Un dispositivo Bluetooth, como un teléfono móvil, podría decidir requerir autenticación para proporcionar un servicio particular. La autenticación Bluetooth se hacer normalmente con un código PIN, una cadena ASCII de hasta 16 caracteres. Se requiere que el usuario introduzca el mismo código PIN en ambos dispositivos. Una vez que el usuario ha introducido el código PIN, ambos dispositivos generarán una clave de enlace. Después de eso, la clave de enlace se puede almacenar en los dispositivos o en almacenamiento persistente. La siguiente vez, ambos dispositivos utilizarán las claves de enlace generadas previamente. Este procedimiento se llama emparejamiento. Ten en cuenta que si alguno de los dispositivos pierde la clave de enlace, se tiene que repetir el emparejamiento.
El demonio hcsecd(8) es el responsable de manejar las peticiones de autenticación Bluetooth. El fichero de configuración por defecto es /etc/bluetooth/hcsecd.conf. A continuación se muestra un ejemplo de sección para un teléfono móvil con el PIN establecido a 1234:
device {
bdaddr 00:80:37:29:19:a4;
name "Pav's T39";
key nokey;
pin "1234";
}La única limitación de los códigos PIN es la longitud. Algunos dispositivos, como los auriculares Bluetooth, podrían tener un código PIN fijo de fábrica. La opción -d fuerza a hcsecd(8) a permanecer en primer plano, de forma que es fácil ver lo que está pasando. Establece el dispositivo remoto para que reciba emparejamientos e inicia la conexión Bluetooth con el dispositivo remoto. El dispositivo remoto debería indicar que el emparejamiento ha sido aceptado y solicitar el código PIN. Introduce el mismo código PIN listado en hcsecd.conf. Ahora el ordenador y el dispositivo remoto están emparejados. De forma alternativa, el emparejamiento puede ser iniciado por el dispositivo remoto.
Se puede añadir la siguiente línea a /etc/rc.conf para configurar que hcsecd(8) arranque automáticamente cuando se inicia el sistema:
hcsecd_enable="YES"
Lo siguiente es una muestra de la salida del demonio hcsecd(8):
hcsecd[16484]: Got Link_Key_Request event from 'ubt0hci', remote bdaddr 0:80:37:29:19:a4 hcsecd[16484]: Found matching entry, remote bdaddr 0:80:37:29:19:a4, name 'Pav's T39', link key doesn't exist hcsecd[16484]: Sending Link_Key_Negative_Reply to 'ubt0hci' for remote bdaddr 0:80:37:29:19:a4 hcsecd[16484]: Got PIN_Code_Request event from 'ubt0hci', remote bdaddr 0:80:37:29:19:a4 hcsecd[16484]: Found matching entry, remote bdaddr 0:80:37:29:19:a4, name 'Pav's T39', PIN code exists hcsecd[16484]: Sending PIN_Code_Reply to 'ubt0hci' for remote bdaddr 0:80:37:29:19:a4
34.7.4. Acceso a la Red con Perfiles PPP
Es posible utilizar un perfil DUN (Dial-Up Networking) para configurar un teléfono móvil como un módem inalámbrico para conectarse a un servidor de acceso a Internet. También se puede utilizar para configurar un ordenador para recibir llamadas de datos desde un teléfono móvil.
Se puede usar el acceso a la red mediante un perfil PPP para proporcionar acceso LAN para uno o varios dispositivos Bluetooth. También puede proporcionar conexión PC a PC usando PPP sobre emulación de cable serie.
En FreeBSD, estos perfiles se implementan con ppp(8) y el adaptador rfcomm_pppd(8) que convierte la conexión Bluetooth en algo que PPP puede usar. Antes de que se pueda usar el perfile, se debe crear una nueva etiqueta PPP en /etc/ppp/ppp.conf. Consulta rfcomm_pppd(8) para ver ejemplos.
En este ejemplo, se usa rfcomm_pppd(8) para abrir una conexión con un dispositivo remoto con un BD_ADDR de 00:80:37:29:19:a4 en un canal DUNRFCOMM:
# rfcomm_pppd -a 00:80:37:29:19:a4 -c -C dun -l rfcomm-dialupEl número de canal real se obtendrá del dispositivo remoto usando el protocolo SDP. Es posible especificar el canal RFCOMM a mano, y en este caso rfcomm_pppd(8) no realizará la consulta SDP. Usa sdpcontrol(8) para averiguar el canal RFCOMM en el dispositivo remoto.
Para proporcionar acceso a la red con el servicio PPPLAN, se debe estar ejecutando sdpd(8) y se tienen que crear una nueva entrada para clientes LAN en /etc/ppp/ppp.conf. Consulta rfcomm_pppd(8) para ver ejemplos. Finalmente, arrancar el servidor RFCOMMPPP en un número de canal RFCOMM válido. El servidor RFCOMMPPP registrará automáticamente el servicio LAN Bluetooth con el demonio SDP local. El ejemplo de abajo muestra cómo arrancar el servidor RFCOMMPPP.
# rfcomm_pppd -s -C 7 -l rfcomm-server34.7.5. Protocolos Bluetooth
Esta sección proporciona un resumen de varios protocolos Bluetooth, sus funciones, y sus utilidades asociadas.
34.7.5.1. Logical Link Control and Adaptation Protocol (L2CAP)
El Logical Link Control and Adaptation Protocol (L2CAP) proporciona servicios de datos orientados a conexión así como no orientados a conexión a los protocolos de las capas superiores. L2CAP permite a los protocolos y aplicaciones de niveles más altos transmitir y recibir paquetes de datos L2CAP de hasta 64 kilobytes de longitud.
L2CAP se basa en el concepto de canales. Un canal es una conexión lógica construida sobre una conexión de banda base, donde cada canal está asociado a un sólo protocolo en una forma muchos-a-uno. Se pueden asociar múltiples canales al mismo protocolo, pero un canal no se puede asociar a múltiples protocolos. Cada paquete L2CAP recibido en un canal es redirigido al protocolo de nivel superior apropiado. Varios canales pueden compartir la misma conexión de banda base.
En FreeBSD, se crear un nodo L2CAP de netgraph para cada dispositivo Bluetooth. Este nodo normalmente se conecta con el nodo HCI Bluetooth inferior y los nodos socket Bluetooth superiores. El nombre por defecto para el nodo L2CAP es "devicel2cap". Para más detalles consulta ng_l2cap(4).
Un comando útil es l2ping(8), que puede ser usado para hacer ping a otros dispositivos. Algunas implementaciones Bluetooth podrían no devolver todos los datos que se les envía, de forma que los 0 bytes en el siguiente ejemplo es algo normal.
# l2ping -a 00:80:37:29:19:a4
0 bytes from 0:80:37:29:19:a4 seq_no=0 time=48.633 ms result=0
0 bytes from 0:80:37:29:19:a4 seq_no=1 time=37.551 ms result=0
0 bytes from 0:80:37:29:19:a4 seq_no=2 time=28.324 ms result=0
0 bytes from 0:80:37:29:19:a4 seq_no=3 time=46.150 ms result=0La utilidad l2control(8) se utiliza para realizar varias operaciones sobre los nodos L2CAP. Este ejemplo muestra cómo obtener la lista de conexiones lógicas (canales) y la lista de conexiones de banda base para el dispositivo local:
% l2control -a 00:02:72:00:d4:1a read_channel_list
L2CAP channels:
Remote BD_ADDR SCID/ DCID PSM IMTU/ OMTU State
00:07:e0:00:0b:ca 66/ 64 3 132/ 672 OPEN
% l2control -a 00:02:72:00:d4:1a read_connection_list
L2CAP connections:
Remote BD_ADDR Handle Flags Pending State
00:07:e0:00:0b:ca 41 O 0 OPENOtra herramienta de diagnóstico es btsockstat(1). Es similar a netstat(1), pero para estructuras de datos de red Bluetooth. El ejemplo de abajo muestra la misma conexión lógica como l2control(8) arriba.
% btsockstat
Active L2CAP sockets
PCB Recv-Q Send-Q Local address/PSM Foreign address CID State
c2afe900 0 0 00:02:72:00:d4:1a/3 00:07:e0:00:0b:ca 66 OPEN
Active RFCOMM sessions
L2PCB PCB Flag MTU Out-Q DLCs State
c2afe900 c2b53380 1 127 0 Yes OPEN
Active RFCOMM sockets
PCB Recv-Q Send-Q Local address Foreign address Chan DLCI State
c2e8bc80 0 250 00:02:72:00:d4:1a 00:07:e0:00:0b:ca 3 6 OPEN34.7.5.2. Comunicación por Radio Frecuencia (RFCOMM)
El protocolo RFCOMM proporciona emulación de puertos serie sobre el protocolo L2CAP. RFCOMM es un protocolo de transporte simple, con soporte adicional para emular los 9 circuitos de los puertos serie RS-2332 (EIATIA-232-E). Soporta hasta 60 conexiones simultáneas (canales RFCOMM) entre dos dispositivos Bluetooth.
Para los propósitos de RFCOMM, un camino de comunicación completo incluye dos aplicaciones ejecutándose en los extremos de la comunicación con un segmento de comunicación entre ellos. RFCOMM está pensado para cubrir aplicaciones que hace uso de los puertos serie de los dispositivos en los que se encuentra. El segmento de comunicación es una enlace de conexión Bluetooth directa desde un dispositivo a otro.
RFCOMM sólo se preocupa de la conexión entre los dispositivos en el caso de una conexión directa, o entre un dispositivo y un módem en el caso de red. RFCOMM puede soportar otras configuraciones, como módulos que se comunican vía tecnología inalámbrica Bluetooth en un lado y proporciona un interfaz por cable en el otro lado.
En FreeBSD, RFCOMM está implementado en la capa de sockets Bluetooth.
34.7.5.3. Protocolo de Descubrimiento de Servicios (SDP)
El Protocolo de Descubrimiento de Servicios (SDP) proporciona los medios para que las aplicaciones cliente descubran la existencia de servicios proporcionados por aplicaciones servidoras así como los atributos de dichos servicios. Los atributos de un servicio incluyen el tipo o clase del servicio ofrecido y el mecanismo o protocolo de información necesario para utilizarlo.
SDP incluye comunicación entre un servidor SDP y un cliente SDP. El servidor mantiene una lista de registros de servicio que describe las características de los servicios asociados con el servidor. Cada registro de servicio contiene información acerca de un único servicio. Un cliente puede recuperar información de un registro de servicio mantenido por el servidor SDP realizando una petición SDP. Si el cliente, o una aplicación asociada con el cliente, decide usar un servicio, debe abrir una conexión separada con el proveedor del servicio para poder utilizarlo. SDP proporciona un mecanismo para descubrir servicios y sus atributos, pero no proporciona un mecanismo para utilizar esos servicios.
Normalmente, un cliente SDP busca servicios basándose en alguna característica deseada de los servicios. Sin embargo, a veces es preferible descubrir qué tipos de servicios están descritos por los registros de servicio de un servidor SDP sin ninguna información previa acerca de los servicios. Este proceso de buscar cualquier servicio ofrecido se llama navegación (browsing).
El servidor SDP Bluetooth, sdpd(8), y cliente en línea de comando, sdpcontrol(8), están incluidos en la instalación estándar de FreeBSD. El siguiente ejemplo muestra cómo realizar una petición de navegación SDP.
% sdpcontrol -a 00:01:03:fc:6e:ec browse
Record Handle: 00000000
Service Class ID List:
Service Discovery Server (0x1000)
Protocol Descriptor List:
L2CAP (0x0100)
Protocol specific parameter #1: u/int/uuid16 1
Protocol specific parameter #2: u/int/uuid16 1
Record Handle: 0x00000001
Service Class ID List:
Browse Group Descriptor (0x1001)
Record Handle: 0x00000002
Service Class ID List:
LAN Access Using PPP (0x1102)
Protocol Descriptor List:
L2CAP (0x0100)
RFCOMM (0x0003)
Protocol specific parameter #1: u/int8/bool 1
Bluetooth Profile Descriptor List:
LAN Access Using PPP (0x1102) ver. 1.0Ten en cuenta que cada servicio tiene una lista de atributos, como el canal RFCOMM. Dependiendo del servicio, el usuario podría necesitar anotar algunos de los atributos. Algunas implementaciones de Bluetooth no soportan la navegación de servicios y podrían devolver una lista vacía. En este caso, es posible buscar un servicio específico. El ejemplo inferior muestra cómo buscar el servicio OBEX Object Push (OPUSH):
% sdpcontrol -a 00:01:03:fc:6e:ec search OPUSHOfrecer servicios de FreeBSD a clientes Bluetooth se hace con el servidor sdpd(8). Se puede añadir la siguiente línea a /etc/rc.conf:
sdpd_enable="YES"
El demonio sdpd(8) se puede arrancar con:
# service sdpd startLa aplicación servidora local que quiera proporcionar un servicio Bluetooth a clientes remotos registrará el servicio en el demonio SDP local. Un ejemplo de dicha aplicación es rfcomm_pppd(8). Una vez iniciado, registrará el servicio LAN Bluetooth con el demonio local SDP.
Se puede obtener la lista de servicios registrados en el servidor SDP local realizando una petición de navegación SDP mediante el canal de control local:
# sdpcontrol -l browse34.7.5.4. OBEX Object Push (OPUSH)
Object Exchange (OBEX) es un protocolo ampliamente utilizado para transferencias de ficheros sencillas entre dispositivos móviles. Su principal uso está en la comunicación infrarroja, donde se usa para transferencias de ficheros genéricas entre portátiles o PDAs, y para enviar tarjetas de negocios o entradas de calendario entre teléfonos móviles y otros dispositivos con aplicaciones PIM (Personal Information Manager).
El servidor y cliente OBEX están implementados por obexapp, que se pude instalar usando el paquete o port comms/obexapp.
El cliente OBEX es utilizado para subir y/o bajar objetos del servidor OBEX. Un objeto de ejemplo es una tarjeta de negocio o una cita. El cliente OBEX puede obtener el número de canal RFCOMM del dispositivo remoto vía SDP. Esto se puede hacer especificando el nombre del servicio en lugar del número de canal RFCOMM. Los nombres de servicios soportados son: IrMC, FTRN, y OPUSH. También es posible especificar el canal RFCOMM como un número. Abajo hay un ejemplo de una sesión OBEX donde el objeto de información del dispositivo se descarga desde un teléfono móvil, y un nuevo objeto, la tarjeta de negocio, se sube al directorio del teléfono.
% obexapp -a 00:80:37:29:19:a4 -C IrMC
obex> get telecom/devinfo.txt devinfo-t39.txt
Success, response: OK, Success (0x20)
obex> put new.vcf
Success, response: OK, Success (0x20)
obex> di
Success, response: OK, Success (0x20)Para proporcionar el servicio OPUSH, sdpd(8) debe estar en ejecución y se debe crear una carpeta raíz donde se almacenarán todos los objetos recibidos. La ruta por defecto de la carpeta raíz es /var/spool/obex. Por último, inicia el servidor OBEX en un número de canal RFCOMM válido. El servidor OBEX registrará automáticamente el servicio OPUSH con el demonio SDP local. El ejemplo de abajo muestra cómo iniciar el servidor OBEX.
# obexapp -s -C 1034.7.5.5. Perfil de Puerto Serie (SPP)
El Perfil de Puerto Serie (SPP) permite a los dispositivos Bluetooth realizar emulación de cable serie. Este perfile permite a aplicaciones heredadas utilizar Bluetooth como un sustituto del cable, a través de una abstracción de puerto serie.
En FreeBSD, rfcomm_sppd(1) implementa SPP y un pseudo tty es usado como abstracción de puerto serie virtual. El ejemplo de abajo muestra cómo conectarse al servicio de puerto serie de un dispositivo remoto. No se tiene que especificar un canal RFCOMM ya que rfcomm_sppd(1) puede obtenerlo del dispositivo remoto vía SDP. Para cambiar esto, especifica un canal RFCOMM en la línea de comando.
# rfcomm_sppd -a 00:07:E0:00:0B:CA -t
rfcomm_sppd[94692]: Starting on /dev/pts/6...
/dev/pts/6Una vez conectado, el pseudo tty puede ser usado como un puerto serie:
# cu -l /dev/pts/6El pseudo tty se imprime en stdout y se puede leer mediante scripts:
PTS=`rfcomm_sppd -a 00:07:E0:00:0B:CA -t` cu -l $PTS
34.7.6. Resolución de problemas
Por defecto, cuando FreeBSD está aceptando una nueva conexión, intenta realizar un cambio de roles y convertirse en maestro. Algunos dispositivos Bluetooth más antiguos que no soportan el cambio de roles no serán capaces de conectar. Puesto que el cambio de roles se realiza cuando se establece una nueva conexión, no es posible preguntar al dispositivo remoto si soporta el cambio de roles. Sin embargo, hay una opción HCI para deshabilitar el intercambio de roles en el lado local:
# hccontrol -n ubt0hci write_node_role_switch 0Para mostrar paquetes Bluetooht, usa el paquete de terceros hcidump, que se puede instalar mediante el paquete o port comms/hcidump. Esta utilidad es similar a tcpdump(1) y se puede usar para mostrar el contenido de los paquetes Bluetooth en el terminal y para volcarlos a un fichero.
34.8. Bridging
A veces es útil dividir una red, como un segmento Ethernet, en segmentos de red sin tener que crear subredes IP y utilizar un router para conectar los segmentos entre ellos. Un dispositivo que conecta dos redes juntas de esta forma se llama "bridge".
Un bridge funciona aprendiendo las direcciones MAC de los dispositivos en cada una de sus interfaces de red. Reenvía tráfico entre las redes sólo cuando las direcciones de origen y destino están en diferentes redes. En muchos aspectos, un bridge es como un switch Ethernet con muy pocos puertos. Un sistema FreeBSD como varias interfaces de red puede ser configurado para funcionar como un bridge.
Un bridge puede ser útil en las siguientes situaciones:
- Conectar Redes
La operación básica de un bridge es juntar dos o más segmentos de red. Hay muchas razones para usar un bridge basado en host en lugar de un equipamiento de red, como restricciones en el cableado o los firewalls. Un bridge también puede conectar una interfaz inalámbrica funcionando en modo hostap con una red cableada y actuar como punto de acceso.
- Filtrado/Firewall the Modelado de Tráfico
Se puede usar un bridge cuando se necesita funcionalidad de firewall sin enrutado o traducciones de direcciones de red (NAT, Network Address Translation).
Un ejemplo es una pequeña compañía que está conectada a un ISP mediante DSL o ISDN. Hay trece direcciones IP públicas del ISP y diez ordenadores en la red. En esta situación, usar un firewall basado en un router es difícil por problemas con las subredes. Un firewall basado en bridge se puede configurar sin ningún problema con las direcciones IP.
- Network Tap
Un bridge puede unir dos segmentos de red para inspeccionar todas las tramas Ethernet que pasan entre ellos usando bpf(4) y tcpdump(1) en la interfaz bridge, o enviando una copia de todas las tramas hacia un interfaz adicional conocido como un puerto span.
- VPN en la Capa 2
Dos redes Ethernet se pueden unir mediante un enlace IP uniendo las redes a un túnel EtherIP o a una solución basada en tap(4) como OpenVPN.
- Redundancia en la Capa 2
Una red puede estar conectada con múltiples enlaces y usar el Spanning Tree Protocol (STP) para bloquear caminos redundantes.
Esta sección describe cómo configurar un sistema FreeBSD como un bridge usando if_bridge(4). También hay disponible un driver bridge de netgraph, y se describe en ng_bridge(4).
Se pude usar filtrado de paquetes con cualquier paquete de firewall que se enganche en el framework pfil(9). El bridge se puede usar como un perfilador de tráfico con altq(4) o dummynet(4). |
34.8.1. Habilitando el Bridge
En FreeBSD, if_bridge(4) es un módulo del kernel que se carga automáticamente cuando ifconfig(8) crea un interfaz bridge. También es posible compilar soporte para bridge en un kernel personalizado añadiendo device if_bridge al fichero de configuración del kernel personalizado.
El bridge se crea clonando una interfaz. Para crear la interfaz bridge:
# ifconfig bridge create
bridge0
# ifconfig bridge0
bridge0: flags=8802<BROADCAST,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 96:3d:4b:f1:79:7a
id 00:00:00:00:00:00 priority 32768 hellotime 2 fwddelay 15
maxage 20 holdcnt 6 proto rstp maxaddr 100 timeout 1200
root id 00:00:00:00:00:00 priority 0 ifcost 0 port 0Cuando se crea una interfaz bridge, se le asigna automáticamente una dirección Ethernet generada de forma aleatoria. Los parámetros maxaddr y timeout controlan cuántas direcciones MAC puede mantener el bridge en su tabla de reenvío y cuántos segundos deben pasar para eliminarla desde la última vez que han sido vistas. Los otros parámetros controlan cómo opera STP.
Después, especifica qué interfaces de red añadir como miembros del bridge. Para que el bridge sea capaz de reenviar paquetes, todas las interfaces y el bridge necesitan estar levantadas:
# ifconfig bridge0 addm fxp0 addm fxp1 up
# ifconfig fxp0 up
# ifconfig fxp1 upEl puente ahora puede reenviar tramas Ethernet entre fxp0 y fxp1. Añade las siguientes líneas a /etc/rc.conf de forma que el bridge se cree al arrancar:
cloned_interfaces="bridge0" ifconfig_bridge0="addm fxp0 addm fxp1 up" ifconfig_fxp0="up" ifconfig_fxp1="up"
Si la máquina bridge necesita una dirección IP, establécela en la interfaz del bridge, no en las interfaces que son miembro. La dirección puede establecerse estáticamente o vía DHCP. Este ejemplo establece una dirección IP estática:
# ifconfig bridge0 inet 192.168.0.1/24También es posible establecer una dirección IPv6 al interfaz del bridge. Para hacer los cambios permanentes, añade la información de la dirección a /etc/rc.conf.
Cuando el filtrado de paquetes está habilitado, los paquetes que van por el bridge pasarán a través del filtro de entrada en la interfaz de origen en el interfaz del bridge, y de salida en las interfaces apropiadas. Cualquiera de las dos fases puede deshabilitarse. Cuando la dirección de un paquete es importante, es mejor aplicar el firewall en las interfaces que forman el bridge que en el bridge en sí mismo. El bridge tiene varios valores configurables para pasar paquetes IP y no IP, y firewall the capa 2 con ipfw(8). Consulta if_bridge(4) para más información. |
34.8.2. Activando Spanning Tree
Para que una red Ethernet funcione adecuadamente, sólo debe existir un camino activo entre dos dispositivos. El protocolo STP detecta bucles y pone enlaces redundantes en un estado bloqueado. Si uno de los enlaces activos fallara, STP calcula un árbol diferente y activa uno de los caminos bloqueados para restaurar la conectividad a todos los puntos de la red.
El protocolo Rapid Spanning Tree (RSTP o 802.1w) proporciona compatibilidad hacia atrás con el STP antiguo. RSTP proporciona una convergencia más rápida e intercambia información con switches vecinos para transicionar rápidamente a modo reenvío sin crear bycles. FreeBSD soporta como modos de operación RSTP y STP, siendo RSTP el modo por defecto.
Se puede activar STP en las interfaces miembro usando ifconfig(8). Para un bridge con fxp0 y fxp1 como interfaces actuales, activa STP con:
# ifconfig bridge0 stp fxp0 stp fxp1
bridge0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether d6:cf:d5:a0:94:6d
id 00:01:02:4b:d4:50 priority 32768 hellotime 2 fwddelay 15
maxage 20 holdcnt 6 proto rstp maxaddr 100 timeout 1200
root id 00:01:02:4b:d4:50 priority 32768 ifcost 0 port 0
member: fxp0 flags=1c7<LEARNING,DISCOVER,STP,AUTOEDGE,PTP,AUTOPTP>
port 3 priority 128 path cost 200000 proto rstp
role designated state forwarding
member: fxp1 flags=1c7<LEARNING,DISCOVER,STP,AUTOEDGE,PTP,AUTOPTP>
port 4 priority 128 path cost 200000 proto rstp
role designated state forwardingEste bridge tiene un spanning tree con un ID de 00:01:02:4b:d4:50 y una prioridad de 32768. Como el root id es el mismo, eso indica que es el bridge raíz del árbol.
Otro bridge en la red tiene STP activado:
bridge0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 96:3d:4b:f1:79:7a
id 00:13:d4:9a:06:7a priority 32768 hellotime 2 fwddelay 15
maxage 20 holdcnt 6 proto rstp maxaddr 100 timeout 1200
root id 00:01:02:4b:d4:50 priority 32768 ifcost 400000 port 4
member: fxp0 flags=1c7<LEARNING,DISCOVER,STP,AUTOEDGE,PTP,AUTOPTP>
port 4 priority 128 path cost 200000 proto rstp
role root state forwarding
member: fxp1 flags=1c7<LEARNING,DISCOVER,STP,AUTOEDGE,PTP,AUTOPTP>
port 5 priority 128 path cost 200000 proto rstp
role designated state forwardingLa línea root id 00:01:02:4b:d4:50 priority 32768 ifcost 400000 port 4 muestra que el bridge raíz es 00:01:02:4b:d4:50 y que tiene un camino con coste 400000 desde este bridge. La ruta al brige raíz es vía port 4 que es fxp0.
34.8.3. Parámetros de la Interfaz del Bridge
Varios parámetros de ifconfig son únicos de las interfaces del bridge. Esta sección resume algunos casos comunes para estos parámetros. ifconfig(8) describe la lista completa de parámetros disponibles.
- private
Una interfaz privada no reenvía nada de tráfico a otro puerto que no esté designado como una interfaz privada. El tráfico se bloquea incondicionalmente de forma que las tramas Ethernet no serán reenviadas, incluyendo los paquetes ARP. Si se necesita bloquear el tráfico de forma selectiva, se tiene que usar un firewall.
- span
Un puerto span transmite una copia de cada trama Ethernet recibida en el bridge. El número de puertos span configurados en el bridge es ilimitado, pero si una interfaz es designada como un puerto span, no puede ser usada también como un puerto regular en el bridge. Esto es muy útil para husmear en una red con bridge de forma pasiva en otro host conectado a uno de los puertos span del bridge. Por ejemplo, para enviar una copia de todas las tramas obtenidas de la interfaz fxp4:
# ifconfig bridge0 span fxp4- sticky
Si una interfaz del bridge es marcada como sticky, las entradas de direcciones aprendidas dinámicamente se tratan como entradas estáticas en la caché de reenvío. Las entradas sticky no envejecen nunca en la caché ni son reemplazadas, incluso si la dirección es vista en otra interfaz. Esto ofrece el beneficio de las entradas de direcciones estáticas sin la necesidad de poblar la tabla de reenvío con antelación. Los clientes que se han aprendido de un segmento del bridge en particular no pueden moverse a otro segmento.
Un ejemplo de uso de direcciones sticky es combinar el bridge con VLANs para aislar redes cliente sin gastar espacio de direcciones IP. Considera que
CustomerAestá envlan100,CustomerBestá envlan101, y el bridge tiene la dirección192.168.0.1:# ifconfig bridge0 addm vlan100 sticky vlan100 addm vlan101 sticky vlan101 # ifconfig bridge0 inet 192.168.0.1/24En este ejemplo, ambos clientes ven
192.168.0.1como su gateway por defecto. Puesto que la caché del bridge es sticky, un host no puede falsear la dirección MAC de otro cliente para interceptar su tráfico.Cualquier comunicación entre las VLANs se puede bloquear utilizando un firewall o, como se ve en este ejemplo, usando interfaces privadas:
# ifconfig bridge0 private vlan100 private vlan101Los clientes están completamente aislados entre sí y el rango de direcciones completo
/24se puede reservar sin necesidad de crear subredes.Se puede limitar el número direcciones MAC fuente únicas detrás de una interfaz. Una vez que se alcance el límite, los paquetes que tengan una dirección de origen desconocida serán descartados hasta que una entrada existente de caché en el host que expire o que sea eliminada.
El siguiente ejemplo establece el número máximo de dispositivos Ethernet a 10 para
CustomerAenvlan100:# ifconfig bridge0 ifmaxaddr vlan100 10
Las interfaces del bridge también soportan modo monitor, donde los paquetes son descartados después de haber sido procesados por bpf(4) y no se procesan más ni se reenvían. Esto se puede usar para multiplexar la entrada de dos o más interfaces en un único flujo bpf(4). Esto es útil para reconstruir el tráfico de redes que transmiten las señales RX/TX hacia fuera usando dos interfaces separadas. Por ejemplo, para leer la entrada desde cuatro interfaces de red como un único flujo:
# ifconfig bridge0 addm fxp0 addm fxp1 addm fxp2 addm fxp3 monitor up
# tcpdump -i bridge034.8.4. Monitorización SNMP
El interfaz bridge y los parámetros STP se pueden monitorizar con bsnmpd(1) que se incluye con el sistema base FreeBSD. Las MIBs del bridge exportadas siguen el estándar IETF de forma que se puede usar cualquier cliente SNMP o paquete de monitorización para recuperar los datos.
Para habilitar la monitorización en el bridge, descomenta esta línea en /etc/snmpd.config eliminando el símbolo # al comienzo:
begemotSnmpdModulePath."bridge" = "/usr/lib/snmp_bridge.so"
Podría ser necesario modificar en este fichero otros valores de configuración, como los nombres de la comunidad y listas de acceso. Consulta bsnmpd(1) y snmp_bridge(3). Una vez guardados los cambios, añade esta línea a /etc/rc.conf:
bsnmpd_enable="YES"
Después, arranca bsnmpd(1):
# service bsnmpd startLos siguientes ejemplos usan el software Net-SNMP (net-mgmt/net-snmp) para consultar un bridge desde un sistema cliente. También se puede usar el port net-mgmt/bsnmptools. Desde el cliente SNMP que está ejecutando Net-SNMP, añade las siguientes líneas a $HOME/.snmp/snmp.conf para importar las definiciones MIB del bridge:
mibdirs +/usr/share/snmp/mibs mibs +BRIDGE-MIB:RSTP-MIB:BEGEMOT-MIB:BEGEMOT-BRIDGE-MIB
Para monitorizar un sólo bridge usando IETF BRIDGE-MIB (RFC4188):
% snmpwalk -v 2c -c public bridge1.example.com mib-2.dot1dBridge
BRIDGE-MIB::dot1dBaseBridgeAddress.0 = STRING: 66:fb:9b:6e:5c:44
BRIDGE-MIB::dot1dBaseNumPorts.0 = INTEGER: 1 ports
BRIDGE-MIB::dot1dStpTimeSinceTopologyChange.0 = Timeticks: (189959) 0:31:39.59 centi-seconds
BRIDGE-MIB::dot1dStpTopChanges.0 = Counter32: 2
BRIDGE-MIB::dot1dStpDesignatedRoot.0 = Hex-STRING: 80 00 00 01 02 4B D4 50
...
BRIDGE-MIB::dot1dStpPortState.3 = INTEGER: forwarding(5)
BRIDGE-MIB::dot1dStpPortEnable.3 = INTEGER: enabled(1)
BRIDGE-MIB::dot1dStpPortPathCost.3 = INTEGER: 200000
BRIDGE-MIB::dot1dStpPortDesignatedRoot.3 = Hex-STRING: 80 00 00 01 02 4B D4 50
BRIDGE-MIB::dot1dStpPortDesignatedCost.3 = INTEGER: 0
BRIDGE-MIB::dot1dStpPortDesignatedBridge.3 = Hex-STRING: 80 00 00 01 02 4B D4 50
BRIDGE-MIB::dot1dStpPortDesignatedPort.3 = Hex-STRING: 03 80
BRIDGE-MIB::dot1dStpPortForwardTransitions.3 = Counter32: 1
RSTP-MIB::dot1dStpVersion.0 = INTEGER: rstp(2)El valor dot1dStpTopChanges.0 es dos, lo que indica que la topología STP ha cambiado dos veces. Un cambio de topología significa que uno o más enlaces en la red han cambiado o fallado y se ha tenido que calcular un nuevo árbol. El valor dot1dStpTimeSinceTopologyChange.0 mostrará cuándo sucede esto.
Para monitorizar múltiples interfaces del bridge, se puede usar el BEGEMOT-BRIDGE-MIB privado:
% snmpwalk -v 2c -c public bridge1.example.com
enterprises.fokus.begemot.begemotBridge
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseName."bridge0" = STRING: bridge0
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseName."bridge2" = STRING: bridge2
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseAddress."bridge0" = STRING: e:ce:3b:5a:9e:13
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseAddress."bridge2" = STRING: 12:5e:4d:74:d:fc
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseNumPorts."bridge0" = INTEGER: 1
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseNumPorts."bridge2" = INTEGER: 1
...
BEGEMOT-BRIDGE-MIB::begemotBridgeStpTimeSinceTopologyChange."bridge0" = Timeticks: (116927) 0:19:29.27 centi-seconds
BEGEMOT-BRIDGE-MIB::begemotBridgeStpTimeSinceTopologyChange."bridge2" = Timeticks: (82773) 0:13:47.73 centi-seconds
BEGEMOT-BRIDGE-MIB::begemotBridgeStpTopChanges."bridge0" = Counter32: 1
BEGEMOT-BRIDGE-MIB::begemotBridgeStpTopChanges."bridge2" = Counter32: 1
BEGEMOT-BRIDGE-MIB::begemotBridgeStpDesignatedRoot."bridge0" = Hex-STRING: 80 00 00 40 95 30 5E 31
BEGEMOT-BRIDGE-MIB::begemotBridgeStpDesignatedRoot."bridge2" = Hex-STRING: 80 00 00 50 8B B8 C6 A9Para cambiar la interfaz del bridge que está siendo monitorizada mediante el subárbol mib-2.dot1dBridge:
% snmpset -v 2c -c private bridge1.example.com
BEGEMOT-BRIDGE-MIB::begemotBridgeDefaultBridgeIf.0 s bridge234.9. Agregación de Enlaces y Conmutación
FreeBSD proporciona la interfaz lagg(4) que se puede usar para agregar múltiples interfaces de red en una interfaz virtual para proporcionar tolerancia a fallos ("failover") y agregación de enlaces. El failover permite que el tráfico continúe fluyendo mientras haya al menos una interfaz de red que tenga establecido un enlace. La agregación de enlaces funciona mejor en switches que soportan LACP, ya que este protocolo distribuye el tráfico de forma bidireccional a la vez que responde al fallo de enlaces individuales.
Los protocolos de agregación soportados por el interfaz lagg determinan qué puertos se usan para tráfico saliente y si un puerto específico acepta o no tráfico de entrada. Los siguientes protocolos están soportados por lagg(4):
- failover
Este modo envía y recibe tráfico sólo a través del puerto maestro. Si el puerto maestro no está disponible, se usa el siguiente puerto activo. La primera interfaz añadida a la interfaz virtual es el puerto maestro y todas las interfaces añadidas posteriormente se usan como dispositivos redundantes. Si se produce un cambio a un puerto no maestro, el puerto original se convierte en maestro una vez que esté disponible de nuevo.
- loadbalance
Esto proporciona una configuración estática y no negocia agregación con los pares o intercambia marcos para monitorizar el enlace. Si el switch soporta LACP, se debería usar en su lugar.
- lacp
El protocolo IEEE® 802.3ad Link Aggregation Control Protocol (LACP) negocia un conjunto de enlaces agregables con el par en uno o más grupos "Link Aggregated Groups" (LAGs). Cada LAG se compone de puertos con la misma velocidad, conjunto de operaciones full-duplex, y el tráfico se balancea entre los puertos en el LAG con la velocidad total mayor. Típicamente, sólo hay un LAG que contiene todos los puertos. En el caso de cambios en la conectividad física, LACP convergerá rápido a una nueva configuración.
LACP balancea el tráfico de salida a lo largo de los puestos activos basándose en un hash de la cabecera de información del protocolo y acepta tráfico de entrada de cualquier puerto activo. El hash incluye la fuente Ehternet y la dirección de destino y, si está disponible, la etiqueta VLAN, y las direcciones de fuente y destino IPv4 o IPv6.
- roundrobin
Este modo distribuye el tráfico de salida utilizando un planificador round-robin entre todos los puertos activos y acepta tráfico de entrada desde cualquier puerto activo. Puesto que esto viola el orden de las tramas Ethernet, debería ser usado con precaución.
- broadcast
Este modo envía tráfico de salida a todos los puertos configurados en la interfaz lagg, y recibe tramas desde cualquier puerto.
34.9.1. Ejemplos de Configuración
Esta sección muestra cómo configurar un switch Cisco® y un sistema FreeBSD para hacer balanceado de carga LACP. Después muestra cómo configurar dos interfaces Ethernet en modo failover así como cómo configurar el modo failover entre una interfaz Ethernet y otra inalámbrica.
Ejemplo 1. Agregación LACP con un Switch Cisco®
Este ejemplo conecta dos interfaces Ethernet fcp(4) en una máquina FreeBSD con los dos primeros puertos Ethernet en un switch Cisco® como un enlace único de balanceo de carga y tolerante a fallos. Se pueden añadir más interfaces para incrementar la productividad y la tolerancia a fallos. Reemplaza los nombres de los puertos Cisco®, dispositivos Ethernet, número de grupo del canal, y dirección IP como se muestra en el ejemplo para adaptarlo a la configuración local.
El orden de las tramas es obligatorio en los enlaces Ethernet y cualquier tráfico entre dos estaciones siempre debe fluir por el mismo enlace físico, limitando la velocidad máxima a aquella de un interfaz. El algoritmo de transmisión intenta usar la mayor cantidad de información posible para distinguir entre distintos flujos de tráfico y balancear los flujos entre las interfaces disponibles.
En el switch Cisco®, añade las interfaces FastEthernet0/1 y FastEthernet0/2 al grupo del canal 1:
interface FastEthernet0/1
channel-group 1 mode active
channel-protocol lacp
!
interface FastEthernet0/2
channel-group 1 mode active
channel-protocol lacpEn el sistema FreeBSD, crea el interfaz lagg(4) usando las interfaces físicas fxp0 y fxp1 y levanta las interfaces con la dirección IP 10.0.0.3/24:
# ifconfig fxp0 up
# ifconfig fxp1 up
# ifconfig lagg0 create
# ifconfig lagg0 up laggproto lacp laggport fxp0 laggport fxp1 10.0.0.3/24Después, verifica el estado de la interfaz virtual:
# ifconfig lagg0
lagg0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=8<VLAN_MTU>
ether 00:05:5d:71:8d:b8
inet 10.0.0.3 netmask 0xffffff00 broadcast 10.0.0.255
media: Ethernet autoselect
status: active
laggproto lacp
laggport: fxp1 flags=1c<ACTIVE,COLLECTING,DISTRIBUTING>
laggport: fxp0 flags=1c<ACTIVE,COLLECTING,DISTRIBUTING>Los puertos marcados como ACTIVE forman parte del LAG que se ha negociado con el switch remoto. El tráfico será transmitido y recibido a través de estos puertos activos. Añade -v al comando de arriba para ver los identificadores LAG.
Para ver el estado del puerto en el switch Cisco®:
switch# show lacp neighbor
Flags: S - Device is requesting Slow LACPDUs
F - Device is requesting Fast LACPDUs
A - Device is in Active mode P - Device is in Passive mode
Channel group 1 neighbors
Partner's information:
LACP port Oper Port Port
Port Flags Priority Dev ID Age Key Number State
Fa0/1 SA 32768 0005.5d71.8db8 29s 0x146 0x3 0x3D
Fa0/2 SA 32768 0005.5d71.8db8 29s 0x146 0x4 0x3DPara más detalles, teclea show lacp neighbor detail.
Para mantener esta configuración entre reinicios, añade las siguientes entradas en el fichero [.filename]#/etc/rc.conf#del sistema FreeBSD:
ifconfig_fxp0="up" ifconfig_fxp1="up" cloned_interfaces="lagg0" ifconfig_lagg0="laggproto lacp laggport fxp0 laggport fxp1 10.0.0.3/24"
Ejemplo 2. Modo Failover
El modo failover se puede usar para cambiar a un interfaz secundario si se pierde el enlace en el interfaz maestro. Para configurar failover, asegúrate de que las interfaces físicas están levantadas, después crea el interfaz lagg(4). En este ejemplo, fxp0 es la interfaz maestra, fxp1 es la interfaz secundaria, y el interfaz virtual tiene asignada la dirección IP 10.0.0.15/24:
# ifconfig fxp0 up
# ifconfig fxp1 up
# ifconfig lagg0 create
# ifconfig lagg0 up laggproto failover laggport fxp0 laggport fxp1 10.0.0.15/24La interfaz virtual debería tener un aspecto parecido a este:
# ifconfig lagg0
lagg0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=8<VLAN_MTU>
ether 00:05:5d:71:8d:b8
inet 10.0.0.15 netmask 0xffffff00 broadcast 10.0.0.255
media: Ethernet autoselect
status: active
laggproto failover
laggport: fxp1 flags=0<>
laggport: fxp0 flags=5<MASTER,ACTIVE>El tráfico será transmitido y recibido en fxp0. Si se pierde el enlace en fxp0, fxp1 se convertirá en el enlace activo. Si se restaura el enlace en la interfaz maestra, se convertirá de nuevo en el enlace activo.
Para mantener esta configuración entre reinicios, añade las siguientes entradas en /etc/rc.conf:
ifconfig_fxp0="up" ifconfig_fxp1="up" cloned_interfaces="lagg0" ifconfig_lagg0="laggproto failover laggport fxp0 laggport fxp1 10.0.0.15/24"
Ejemplo 3. Modo Failover Entre Interfaces Ethernet y Wireless
Para los usuarios de portátiles, normalmente es deseable configurar el dispositivo inalámbrico como un secundario que sólo usa cuando la conexión Ethernet no está disponible. Con lagg(4), es posible configurar un failover que prefiera la conexión Ethernet tanto por rendimiento como por razones de seguridad, mientras que se mantiene la posibilidad de transferir datos por la conexión inalámbrica.
Esto se consigue sobrescribiendo la dirección MAC del interfaz Ethernet con el de la interfaz inalámbrica.
En teoría, cualquiera de las dos direcciones MAC (Ethernet o inalámbrica) se puede cambiar para igualarse a la otra. Sin embargo, algunas interfaces inalámbricas populares carecen del soporte para sobrescribir la dirección MAX. Por lo tanto para este propósito recomendamos sobrescribir la dirección MAC Ethernet.
Si el controlador para el interfaz inalámbrico no está cargado en el kernel GENERIC o en el personalizado, y el ordenador está ejecutando FreeBSD12.1, carga el .ko correspondiente en /boot/loader.conf añadiendo driver_load="YES" a ese fichero y después reiniciando. Otra forma mejor es cargar el driver en /etc/rc.conf añadiéndolo a kld_list (consulta rc.conf(5) para los detalles) en ese fichero y reiniciando. Esto es necesario porque de otra forma el controlador no está todavía cargado en el momento en el que se configura el interfaz lagg(4).
En este ejemplo, el interfaz Ethernet, re0, es el maestro y el interfaz inalámbrico, wlan0, es el recambio. El interfaz wlan0 ha sido creado a partir del interfaz inalámbrico físico ath0, y el interfaz Ethernet se configurará con la dirección MAC del interfaz inalámbrico. Primero, levanta el interfaz inalámbrico (reemplaza FR con tu código de país de dos letras), pero no establezcas una dirección IP. Reemplaza wlan0 con el nombre del interfaz inalámbrico del sistema:
# ifconfig wlan0 create wlandev ath0 country FR ssid my_router upAhora puedes saber la dirección MAC del interfaz inalámbrico:
# ifconfig wlan0
wlan0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether b8:ee:65:5b:32:59
groups: wlan
ssid Bbox-A3BD2403 channel 6 (2437 MHz 11g ht/20) bssid 00:37:b7:56:4b:60
regdomain ETSI country FR indoor ecm authmode WPA2/802.11i privacy ON
deftxkey UNDEF AES-CCM 2:128-bit txpower 30 bmiss 7 scanvalid 60
protmode CTS ampdulimit 64k ampdudensity 8 shortgi -stbctx stbcrx
-ldpc wme burst roaming MANUAL
media: IEEE 802.11 Wireless Ethernet MCS mode 11ng
status: associated
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>La línea ether contendrá la dirección MAC del interfaz especificado. Ahora, cambia la dirección MAC del interfaz Ethernet para que concuerde:
# ifconfig re0 ether b8:ee:65:5b:32:59Asegúrate de que el interfaz re0 está levantado, luego crea el interfaz lagg(4) con re0 como maestro con wlan0 como recambio:
# ifconfig re0 up
# ifconfig lagg0 create
# ifconfig lagg0 up laggproto failover laggport re0 laggport wlan0La interfaz virtual debería tener un aspecto parecido a este:
# ifconfig lagg0
lagg0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=8<VLAN_MTU>
ether b8:ee:65:5b:32:59
laggproto failover lagghash l2,l3,l4
laggport: re0 flags=5<MASTER,ACTIVE>
laggport: wlan0 flags=0<>
groups: lagg
media: Ethernet autoselect
status: activeDespués, arranca el cliente DHCP para obtener una dirección IP:
# dhclient lagg0Para mantener esta configuración entre reinicios, añade las siguientes entradas en /etc/rc.conf:
ifconfig_re0="ether b8:ee:65:5b:32:59" wlans_ath0="wlan0" ifconfig_wlan0="WPA" create_args_wlan0="country FR" cloned_interfaces="lagg0" ifconfig_lagg0="up laggproto failover laggport re0 laggport wlan0 DHCP"
34.10. Operación sin Disco con PXE
El Preboot eXecution Environment (PXE) de Intel® permite a un sistema operativo arrancar por red. Por ejemplo, un sistema FreeBSD puede arrancar sobre la red y operar sin un disco local, usando sistemas de ficheros montados desde un servidor NFS. El soporte de PXE normalmente está disponible en la BIOS. Para usar PXE cuando arranca la máquina, selecciona la opción Arrancar desde la red en la configuración de la BIOS o teclea una tecla de función durante la inicialización del sistema.
Para proporcionar a un sistema operativo los ficheros necesarios para que arranque sobre la red, la configuración de PXE también necesita configurar apropiadamente DHCP, TFTP y los servidores NFS, donde:
Parámetros iniciales, como una dirección IP, el nombre del fichero ejecutable de arranque y su localización, el nombre del servidor, y la ruta raíz se obtienen del servidor DHCP.
El fichero del cargador del sistema operativo se obtiene mediante TFTP.
Los sistemas de ficheros se cargan usando NFS.
Cuando un ordenador arranca mediante PXE, recibe información a través de DHCP sobre dónde obtener el fichero inicial del cargador de arranque. Después de que el ordenador recibe esta información, descarga el cargador de arranque vía TFTP y después ejecuta el cargador de arranque. En FreeBSD, el fichero del cargador de arranque es /boot/pxeboot. Después de que /boot/pxeboot se ejecute, se carga el kernel de FreeBSD y el resto de la secuencia de arranque de FreeBSD prosigue su curso como se describe en El Proceso de Arranque de FreeBSD.
Esta sección describe cómo configurar estos servicios en un sistema FreeBSD de forma que otros sistemas puedan arrancar mediante PXE en FreeBSD. Consulta diskless(8) para más información.
Como se ha descrito, el sistema que proporciona estos servicios no es seguro. Debería vivir en un área protegida de la red y otros hosts no deberían confiar en él. |
34.10.1. Configurando el Entorno PXE
Las pasos que se muestran en esta sección configuran los servidores NFS y TFTP incluidos. La siguiente sección muestra cómo instalar y configurar el servidor DHCP. En este ejemplo, el dirección que contendrá los ficheros usados por los usuarios PXE es /b/tftpboot/FreeBSD/install. Es importante que este directorio exista y que el nombre del directorio esté configurado tanto en /etc/inetd.conf como en /usr/local/etc/dhcpd.conf.
Crea el directorio raíz que contendrá la instalación de FreeBSD que será montada por NFS:
# export NFSROOTDIR=/b/tftpboot/FreeBSD/install # mkdir -p ${NFSROOTDIR}Activa el servidor NFS añadiendo esta línea a /etc/rc.conf:
nfs_server_enable="YES"
Exporta el directorio raíz del sistema sin disco vía NFS añadiendo lo siguiente a /etc/exports:
/b -ro -alldirs -maproot=root
Arranca el servidor NFS:
# service nfsd startActiva inetd(8) añadiendo la siguiente línea a /etc/rc.conf:
inetd_enable="YES"
Descomenta la siguiente línea en /etc/inetd.conf asegurándote de que no comienza con un símbolo
#:tftp dgram udp wait root /usr/libexec/tftpd tftpd -l -s /b/tftpboot
Algunas versiones de PXE necesitan la versión TCP de TFTP. En este caso, descomenta la segunda línea
tftpque contienestream tcp.Arranca inetd(8):
# service inetd startInstala el sistema base en ${NFSROOTDIR}, bien descomprimiendo los archivos oficiales o recompilando el kernel de FreeBSD y el espacio de usuario (consulta “Actualizando FreeBSD desde las Fuentes” para instrucciones más detalladas, pero no olvides añadir
DESTDIR=${NFSROOTDIR}cuando ejecutes los comandsmake installkernelymake installworld.Comprueba que el servidor TFTP funciona y que puede descargar el cargador de arranque que se obtendrá vía PXE:
# tftp localhost tftp> get FreeBSD/install/boot/pxeboot Received 264951 bytes in 0.1 secondsEdita ${NFSROOTDIR}/etc/fstab y crea una entrada para montar el sistema de ficheros raíz sobre NFS:
# Device Mountpoint FSType Options Dump Pass myhost.example.com:/b/tftpboot/FreeBSD/install / nfs ro 0 0
Reemplaza myhost.example.com con el nombre de la máquina o la dirección IP del servidor NFS. En este ejemplo, el sistema de ficheros raíz está montado como solo lectura para evitar que los clientes NFS puedan borrar los contenidos del sistema de ficheros raíz.
Establece la contraseña de root en el entorno PXE para las máquinas cliente que están arrancando mediante PXE:
# chroot ${NFSROOTDIR} # passwdSi es necesario, habilita el inicio de sesión de root en ssh(1) para las máquinas cliente que arrancan con PXE editando ${NFSROOTDIR}/etc/ssh/sshd_config y habilitando
PermitRootLogin. Esta opción está documentada en sshd_config(5).Realiza cualquier otra personalización del entorno PXE en ${NFSROOTDIR}. Estas personalizaciones podrían incluir cosas como instalación de paquetes o editar el fichero de contraseñas con vipw(8).
Cuando se arranca desde un volumen raíz NFS, /etc/rc detecta el arranque NFS y ejecuta /etc/rc.initdiskless. En este caso se necesita que /etc y /var estén cargados den memoria de forma que estos directorios sean escribibles pero el directorio raíz NFS sea de sólo escritura:
# chroot ${NFSROOTDIR}
# mkdir -p conf/base
# tar -c -v -f conf/base/etc.cpio.gz --format cpio --gzip etc
# tar -c -v -f conf/base/var.cpio.gz --format cpio --gzip varCuando el sistema arranca, los sistemas de fichero en memoria para /etc y /var se crearán y montarán y el contenido de los ficheros cpio.gz se copiará dentro de ellos. Por defecto, estos sistemas de ficheros tienen una capacidad máxima de 5 megabytes. Si tus archivos no caben, que es habitualmente el caso para /var cuando se han instalado paquetes binarios, solicita más tamaño poniendo el número de sectores de 512 bytes necesarios (por ejemplo, 5 megabytes es 10240 sectores) en ${NFSROOTDIR}/conf/base/etc/md_size y ${NFSROOTDIR}/conf/base/var/md_size para los sistemas de ficheros /etc y /var respectivamente.
34.10.2. Configurando el Servidor DHCP
El servidor DHCP no necesita estar en la misma máquina que los servidores de TFTP y NFS, pero necesita estar accesible en la red.
DHCP no es parte del sistema base de FreeBSD pero se puede instalar usando el port o paquete net/isc-dhcp44-server.
Una vez instalado, edita el fichero de configuración, /usr/local/etc/dhcpd.conf. Configura las opciones next-server, filename, y root-path como se ve en este ejemplo:
subnet 192.168.0.0 netmask 255.255.255.0 {
range 192.168.0.2 192.168.0.3 ;
option subnet-mask 255.255.255.0 ;
option routers 192.168.0.1 ;
option broadcast-address 192.168.0.255 ;
option domain-name-servers 192.168.35.35, 192.168.35.36 ;
option domain-name "example.com";
# IP address of TFTP server
next-server 192.168.0.1 ;
# path of boot loader obtained via tftp
filename "FreeBSD/install/boot/pxeboot" ;
# pxeboot boot loader will try to NFS mount this directory for root FS
option root-path "192.168.0.1:/b/tftpboot/FreeBSD/install/" ;
}La directiva next-server se usa para especificar la dirección IP del servidor TFTP.
La directiva filename define la ruta a /boot/pxeboot. Se usa un nombre de fichero relativo, lo que significa que /b/tftpboot no está incluido en la ruta.
La opción root-path define la ruta al sistema de ficheros raíz NFS.
Una vez salvados los cambios, activa DHCP durante el arranque añadiendo la siguiente línea a /etc/rc.conf:
dhcpd_enable="YES"
Después inicia el servicio DHCP:
# service isc-dhcpd start34.10.3. Depurando problemas en PXE
Una vez que todos los servicios están configurados y arrancados, los clientes PXE deberían ser capaces de cargar automáticamente FreeBSD a través de la red. Si un cliente particular no es capaz de conectar, cuando ese cliente arranque, entra en el menú de configuración de la BIO y confirma que está configurado para arrancar desde la red.
Esta sección describe algunos consejos para resolución de problemas para aislar la fuente del problema de configuración si los clientes no fueran capaces de arrancar mediante PXE.
Usa el paquete o port net/wireshark para depurar el tráfico de red involucrado en el proceso de arranque de PXE, el cual se ilustra en el diagrama inferior.
 Figura 1. Proceso de Arranque de PXE con Punto de Montaje Raíz NFS
Figura 1. Proceso de Arranque de PXE con Punto de Montaje Raíz NFSEl cliente emite un mensaje DHCPDISCOVER.
El servidor DHCP responde con los valores para la dirección IP, next-server, filename y root-path.
El cliente envía una solicitud TFTP a next-server, pidiendo recuperar un nombre de archivo.
El servidor TFTP responde y envía el fichero al cliente.
El cliente ejecuta el fichero, que es pxeboot(8), que luego carga el kernel. Cuando el kernel se ejecuta, el sistema de ficheros raíz especificado por root-path es montado a través de NFS.
En el servidor TFTP, lee /var/log/xferlog para asegurar que se está recuperando pxeboot desde el lugar correcto. Prueba con este ejemplo de configuración:
# tftp 192.168.0.1 tftp> get FreeBSD/install/boot/pxeboot Received 264951 bytes in 0.1 secondsAsegúrate de que el sistema de ficheros raíz se puede montar vía NFS. Puedes probar con esta configuración de ejemplo:
# mount -t nfs 192.168.0.1:/b/tftpboot/FreeBSD/install /mnt
34.11. Common Address Redundancy Protocol (CARP)
El protocolo CARP (Common Address Redundancy Protocol) permite a múltiples hosts compartir la misma dirección IP y VHID (Virtual Host ID) para proporcionar alta disponibilidad para uno o más servicios. Este significa que uno o más hosts pueden fallar, y los otros hosts se harán cargo de forma transparente de forma que los usuarios no verán un fallo de servicio.
Además de la dirección IP compartida, cada host tiene su propia dirección IP para gestión y configuración. Todas las máquinas que comparten una dirección IP tienen el mismo VHID. El VHID para cada dirección IP virtual debe ser única en el dominio broadcast del interfaz de red.
La alta disponibilidad con CARP está incluida en FreeBSD, aunque los pasos para configurarla varían ligeramente dependiendo de la versión de FreeBSD. Esta sección proporciona la misma configuración de ejemplo para versiones anteriores, iguales o posteriores a FreeBSD 10.
Este ejemplo configura soporte para failover con tres hosts, todos con una única dirección IP, pero proporcionando el mismo contenido web. Tiene dos maestros diferentes llamados hosta.example.org y hostb.example.org, con un respaldo compartido llamado hostc.example.org.
Estas máquinas están balanceadas con un DNS con figurado en Round Robin . Las máquinas maestro y el respaldo están configuradas de forma idéntica excepto por los nombres de host y las direcciones IP de gestión. Estos servidores deben tener la misma configuración y ejecutar los mismos servicios. Cuando se produce un failover, las peticiones al servicio en la dirección IP compartida sólo pueden ser contestadas correctamente si el servidor de respaldo tiene acceso al mismo contenido. La máquina de respaldo tiene dos interfaces CARP adicionales, una para cada dirección IP de los servidores maestros. Cuando ocurre un fallo, el servidor de respaldo pillará la dirección IP de la máquina del maestro que haya fallado.
34.11.1. Usando CARP en FreeBSD 10 y Posterior
Activa el soporte de CARP en el arranque añadiendo una entrada para el módulo del kernel carp.ko en /boot/loader.conf:
carp_load="YES"
Para cargar el módulo ahora sin reiniciar:
# kldload carpPara los usuarios que prefieren usar un kernel personalizado, incluye la siguiente línea en el fichero de configuración del kernel personalizado y compila como se describe en Configurando el Kernel de FreeBSD:
device carp
El nombre de host, dirección IP de gestión y su máscara de subred, la dirección IP compartida, y el VHID se configuran añadiendo entradas en /etc/rc.conf. Este ejemplo es para hosta.example.org:
hostname="hosta.example.org" ifconfig_em0="inet 192.168.1.3 netmask 255.255.255.0" ifconfig_em0_alias0="inet vhid 1 pass testpass alias 192.168.1.50/32"
El siguiente conjunto de entradas es para hostb.example.org. Puesto que representa un segundo maestro, utiliza una dirección IP compartida y VHID diferentes. Sin embargo, la contraseña especificada con pass debe ser idéntica ya que CARP sólo escuchará y aceptará notificaciones de las máquinas que tengan la contraseña correcta.
hostname="hostb.example.org" ifconfig_em0="inet 192.168.1.4 netmask 255.255.255.0" ifconfig_em0_alias0="inet vhid 2 pass testpass alias 192.168.1.51/32"
La tercer máquina, hostc.example.org, está configurada para manejar el failover de cualquiera de los maestros. Esta máquina está configurada con dos CARPVHIDS, uno para manejar cada dirección IP virtual de cada host maestro. El desvío de notificaciones CARP, advskew, está configurado para asegurar que el host de respaldo notifica más tarde que el maestro, puesto que advskew controla el orden de precedencia cuando hay varios servidores de reemplazo.
hostname="hostc.example.org" ifconfig_em0="inet 192.168.1.5 netmask 255.255.255.0" ifconfig_em0_alias0="inet vhid 1 advskew 100 pass testpass alias 192.168.1.50/32" ifconfig_em0_alias1="inet vhid 2 advskew 100 pass testpass alias 192.168.1.51/32"
Tener dos CARPVHIDs configurados significa que hostc.example.org se dará cuenta si alguno de los maestros no se encuentra disponible. Si un maestro no es capaz de notificar antes que el servidor de reemplazo, el servidor de reemplazo usará la dirección IP compartida hasta que el maestro esté disponible de nuevo.
Si el maestro original vuelve a estar disponible, |
Una vez completada la configuración, reinicia la red o reinicia cada sistema. Ahora la alta disponibilidad está habilitada.
34.11.2. Usando CARP en FreeBSD 9 y Anteriores
La configuración para estas versiones de FreeBSD es similar a la descrita en la sección previa, excepto que se tiene que crear primero un dispositivo CARP y hacer referencia a él en la configuración.
Activa el soporte de CARP al arrancar cargando el módulo del kernel if_carp.ko en /boot/loader.conf:
if_carp_load="YES"
Para cargar el módulo ahora sin reiniciar:
# kldload carpPara los usuarios que prefieren usar un kernel personalizado, incluye la siguiente línea en el fichero de configuración del kernel personalizado y compila como se describe en Configurando el Kernel de FreeBSD:
device carp
Después, en cada host, crea un dispositivo CARP:
# ifconfig carp0 createEstablece el nombre de host, dirección IP de gestión, dirección IP compartida, y VHID añadiendo las líneas necesarias a /etc/rc.conf. Puesto que se usa un dispositivo CARP virtual en lugar de un alias, se usa la máscara de subred /24 en lugar de /32. Aquí están las entradas para hosta.example.org:
hostname="hosta.example.org" ifconfig_fxp0="inet 192.168.1.3 netmask 255.255.255.0" cloned_interfaces="carp0" ifconfig_carp0="vhid 1 pass testpass 192.168.1.50/24"
En hostb.example.org:
hostname="hostb.example.org" ifconfig_fxp0="inet 192.168.1.4 netmask 255.255.255.0" cloned_interfaces="carp0" ifconfig_carp0="vhid 2 pass testpass 192.168.1.51/24"
La tercera máquina, hostc.example.org, se configura para manejar el failover de cualquiera de los hosts maestros:
hostname="hostc.example.org" ifconfig_fxp0="inet 192.168.1.5 netmask 255.255.255.0" cloned_interfaces="carp0 carp1" ifconfig_carp0="vhid 1 advskew 100 pass testpass 192.168.1.50/24" ifconfig_carp1="vhid 2 advskew 100 pass testpass 192.168.1.51/24"
La preemptividad está deshabilitada en el kernel GENERIC de FreeBSD. Si la preemptividad se ha habilitado con un kernel personalizado Esto se debería hacer en la interfaz carp que se corresponda con el host correcto. |
Una vez completada la configuración, reinicia la red o reinicia cada sistema. Ahora la alta disponibilidad está habilitada.
34.12. VLANs
VLANs son una forma de dividir una red de forma virtual en muchas subredes diferentes, también llamado segmentación. Cada segmento tendrá su dominio broadcast y está aislado de otras VLANs.
En FreeBSD, las VLANs tienen que estar soportadas por el controlador de la tarjeta de red. Para ver qué controladores soportan vlans, consulta la página de manual vlan(4).
Cuando se configura una VLAN, se tienen que conocer un par de datos. Primero, ¿qué interfaz de red? Segundo, ¿cuál es la etiqueta de la VLAN?
Para configurar una VLAN en tiempo de ejecución, con un NIC de em0 y una etiqueta de VLAN de 5 el comando se parecería a este:
# ifconfig em0.5 create vlan 5 vlandev em0 inet 192.168.20.20/24¿Te has fijado en cómo el nombre de la interfaz incluye el nombre del controlador del NIC y la etiqueta VLAN, separados por un punto? Esta es la mejor forma de mantener la configuración de la VLAN sencilla cuando hay muchas VLANs en la máquina. |
Para configurar VLANs en el arranque, se tiene que actualizar /etc/rc.conf. Para duplicar la configuración de arriba, se tiene que añadir lo siguiente:
vlans_em0="5" ifconfig_em0_5="inet 192.168.20.20/24"
Se pueden añadir VLANs adicionales, simplemente añadiendo la etiqueta al campo vlans_em0 y añadiendo una línea adicional configurando la red en la interfaz de esa etiqueta VLAN.
Es útil asignar un nombre simbólico a una interfaz de forma que cuando el hardware asociado cambie, sólo se necesiten actualizar unas pocas variables de configuración. Por ejemplo, las cámaras de seguridad necesitan ejecutarse sobre VLAN 1 en em0. Después, si la tarjeta em0 es reemplazada con una tarjeta que utiliza el controlador ixgb(4), no habrá que cambiar a ixgb0.1 todas las referencias a em0.1.
Para configurar la VLAN 5, en el NIC em0, asigna el nombre de interfaz cameras, y asignar al interfaz la dirección IP 192.168.20.20 con un prefijo de 24 bits, usa este comando:
# ifconfig em0.5 create vlan 5 vlandev em0 name cameras inet 192.168.20.20/24Para un interfaz llamado video, usa lo siguiente:
# ifconfig video.5 create vlan 5 vlandev video name cameras inet 192.168.20.20/24Para aplicar los cambios en el arranque, añade las siguientes líneas a /etc/rc.conf:
vlans_video="cameras" create_args_cameras="vlan 5" ifconfig_cameras="inet 192.168.20.20/24"
Last modified on: 2 de julio de 2026 by Vladlen Popolitov