
Additional ABI support:.
Local package initialization:.
Additional TCP options:.
Fri Sep 20 13:01:06 EEST 2002
FreeBSD/i386 (pc3.ejemplo.org) (ttyv0)
login:Capítulo 3. Conceptos básicos de Unix
This translation may be out of date. To help with the translations please access the FreeBSD translations instance.
Tabla de contenidos
3.1. Sinopsis
El siguiente capítulo comprende la funcionalidad y órdenes básicas del sistema operativo FreeBSD. Gran parte de este material es relevante para cualquier sistema operativo tipo UNIX®. Puede saltarse este capítulo si considera que ya conoce el funcionamiento de UNIX®. Si no tiene experiencia previa con FreeBSD debería leer este capítulo con mucha atención.
Después de leer este capítulo, usted sabrá:
Cómo usar las «consolas virtuales» de FreeBSD.
Cómo funcionan los permisos de fichero UNIX® en relación con las banderas de fichero en FreeBSD.
La disposición de sistemas de ficheros por omisión en FreeBSD.
La organización de disco de FreeBSD.
Cómo montar y desmontar sistemas de ficheros.
Qué son los procesos, dæmons y señales.
Qué es una shell, cómo modificar sus variables de entorno por omisión.
Cómo utilizar editores de texto básicos.
Qué son los dispositivos y nodos de dispositivos.
Qué formato binario se usa en FreeBSD.
Cómo buscar información en las páginas de manual.
3.2. Consolas virtuales y terminales
FreeBSD puede utilizarse de muchas maneras. Una de ellas es tecleando órdenes en una terminal de texto. De este modo, mucha de la flexibilidad y poder de un sistema operativo UNIX® está inmediatamente en sus manos cuando usa FreeBSD. Esta sección describe qué son «terminales» y «consolas» y cómo puede usarlas en FreeBSD.
3.2.1. La consola
Si no ha configurado FreeBSD para ejecutar automáticamente un entorno gráfico en el arranque, el sistema le presentará un «prompt» de entrada después del arranque, inmediatamente después de que los «scripts» de inicio terminen de ejecutarse. Verá algo similar a esto:
Los mensajes pueden ser un poco diferentes en su sistema, pero verá algo similar. Las últimas dos líneas son las que nos interesan por el momento. La penúltima línea dice:
FreeBSD/i386 (pc3.ejemplo.org) (ttyv0)
Esta línea contiene información acerca del sistema que acaba de arrancar. Esta usted ante una consola «FreeBSD» que se ejecuta en un procesador Intel o compatible de la arquitectura x86. El nombre de esta máquina (todas las máquinas UNIX® tiene un nombre) es pc3.ejemplo.org, y usted está ahora ante su consola de sistema (la terminal ttyv0).
Para acabar, la última línea siempre es:
login:
Este es el lugar donde se usted tecleará su «nombre de usuario» para entrar en FreeBSD. La siguiente sección describe cómo hacerlo.
3.2.2. La entrada a FreeBSD
FreeBSD es un sistema multiusuario multiprocesador. Esta es la descripción formal que se suele dar a un sistema que puede ser utilizado por muchas personas diferentes, que simultáneamente ejecutan muchos programas en un sola máquina.
Cada sistema multiusuario necesita algún modo de distinguir a un «usuario» del resto. En FreeBSD (y en todos los sistemas operativos de tipo UNIX®) esto se logra requiriendo que cada usuario «acceda» al sistema antes de poder ejecutar programas. Cada usuario tiene un nombre único (el «nombre de usuario») y una clave secreta, personal (la «contraseña»). FreeBSD preguntará por ambos antes de permitirle a un usuario ejecutar cualquier programa.
Justo después de que FreeBSD arranque y termine de ejecutar sus «scripts» de inicio , le presentará un «prompt» y solicitará un nombre válido de usuario:
login:En este ejemplo vamos a asumir que su nombre de usuario es john. Teclée john en el «prompt» y pulse Intro. Debería presentársele un «prompt» donde introducir una «contraseña»:
login: john
Password:Teclée ahora la contraseña de john y pulse Enter. La contraseña no se muestra en pantalla, pero no debe preocuparse por ello. Esto se hace así por motivos de seguridad.
Si ha tecleado su contraseña correctamente ya está usted en un sistema FreeBSD, listo para probar todas las órdenes disponibles.
Verá el MOTD (mensaje del día) seguido por un «prompt» (un caracter #, $ o %). Esto confirma que ha validado con éxito su usuario en FreeBSD.
3.2.3. Consolas múltiples
Ejecutar órdenes UNIX® en una consola está bien, pero FreeBSD puede ejecutar muchos programas a la vez. Tener una consola donde se pueden teclear órdenes puede ser un desperdicio cuando un sistema operativo como FreeBSD puede ejecutar docenas de programas al mismo tiempo. Aquí es donde las «consolas virtuales» muestran su potencial.
FreeBSD puede configurarse para presentarle diferentes consolas virtuales. Puede cambiar de una de ellas a cualquier otra consola virtual pulsando un par de teclas en su teclado. Cada consola tiene su propio canal de salida, y FreeBSD se ocupa de redirigir correctamente la entrada del teclado y la salida al monitor cuando cambia de una consola virtual a la siguiente.
Se han reservado ciertas combinaciones especiales de teclas para pasar de unas consolas virtuales a otras en FreeBSD . Puede utilizar Alt+F1, Alt+F2 y así sucesivamente hasta Alt+F8 para cambiar a una consola virtual diferente en FreeBSD.
Mientras está cambiando de una consola a la siguiente, FreeBSD se ocupa de guardar y restaurar la salida de pantalla. El resultado es la «ilusión» de tener varias pantallas y teclados «virtuales» que puede utilizar para teclear órdenes para que FreeBSD los ejecute. El programa que usted lanza en una consola virtual no deja de ejecutarse cuando la consola no está visible. Continúan ejecutándose cuando se cambia a una consola virtual diferente.
3.2.4. El fichero /etc/ttys
La configuración por omisión de FreeBSD iniciará con ocho consolas virtuales. No es una configuración estática por hardware, así que puede personalizar fácilmente su sistema para arrancar con más o menos consolas virtuales. El número y propiedades de las consolas virtuales están detallados en /etc/ttys.
En /etc/ttys es donde se configuran las consolas virtuales de FreeBSD. Cada línea no comentada de este fichero (líneas que no comienzan con un caracter #) contiene propiedades para una sola terminal o consola virtual. La versión por omisión de este fichero en FreeBSD configura nueve consolas virtuales y habilita ocho de ellas. Son las líneas que comienzan con ttyv:
# name getty type status comments # ttyv0 "/usr/libexec/getty Pc" cons25 on secure # Virtual terminals ttyv1 "/usr/libexec/getty Pc" cons25 on secure ttyv2 "/usr/libexec/getty Pc" cons25 on secure ttyv3 "/usr/libexec/getty Pc" cons25 on secure ttyv4 "/usr/libexec/getty Pc" cons25 on secure ttyv5 "/usr/libexec/getty Pc" cons25 on secure ttyv6 "/usr/libexec/getty Pc" cons25 on secure ttyv7 "/usr/libexec/getty Pc" cons25 on secure ttyv8 "/usr/X11R6/bin/xdm -nodaemon" xterm off secure
Consulte ttys(5) si quiere una descripción detallada de cada columna en este fichero y todas las opciones que puede usar para configurar las consolas virtuales.
3.2.5. Consola en modo monousuario
En la Modo monousuario encontrará una descripción detallada de lo que es «modo monousuario». No importa que sólo exista una consola cuando ejecuta FreeBSD en modo monousuario. No hay otra consola virtual disponible. Las configuraciones de la consola en modo monousuario se pueden encontrar también en /etc/ttys. Busque la línea que comienza por console:
# name getty type status comments # # Si la consola está marcada como "insecure", entonces init # le pedirá la contraseña de root al entrar a modo monousuario. console none unknown off secure
Tal y como indican los comentarios por encima de la línea Tenga cuidado si cambia esto a |
3.2.6. Cambio del modo de video de la consola
La consola FreeBSD por omisión tiene un modo de video que puede ajustarse a 1024x768, 1280x1024 o cualquier otra resolución que admita su chip gráfico y su monitor. Si quiere utilizar uno diferente tendrá que recompilar su kernel con estas dos opciones añadidas:
options VESA options SC_PIXEL_MODE
Una vez recompilado el kernel con esas dos opciones en él determine qué modos de video admite su hardware; para ello use vidcontrol(1). Con lo siguiente le mostrará una lista de modos de video soportados:
# vidcontrol -i modeLa salida de esta orden es una lista de los modos de que admite su tarjeta. Para elegir uno de ellos tendrá que ejecutar vidcontrol(1) en una consola como root:
# vidcontrol MODE_279Si el modo de video que ha elegido le parece adecuado puede configurarlo de forma permanente haciendo que funcione desde el momento del arranque; para ello debe editar /etc/rc.conf file:
allscreens_flags="MODE_279"
3.3. Permisos
FreeBSD, cuya raíz histórica es el UNIX® BSD, se fundamenta en varios conceptos clave de UNIX. El primero y más importante es que FreeBSD es un sistema operativo multi-usuario. El sistema puede gestionar múltiples usuarios trabajando simultáneamente y en tareas que no guarden relación entre sí. El sistema se encarga de compartir y administrar peticiones de dispositivos de hardware, periféricos, memoria y tiempo de CPU de manera equitativa para cada usuario.
Debido a que el sistema es capaz de soportar múltiples usuarios, todo lo que el sistema administra tiene un conjunto de permisos que usa para decidir quién puede leer, escribir y ejecutar un recurso. Estos permisos se guardan como octetos divididos en tres partes: una para el propietario del fichero, otra para el grupo al que el fichero pertenece, y otra para todos los demás grupos y usuarios. Veamos una representación numérica de esto:
| Valor | Permiso | Listado de directorio |
|---|---|---|
0 | No leer, no escribir, no ejecutar |
|
1 | No leer, no escribir, ejecutar |
|
2 | No leer, escribir, no ejecutar |
|
3 | No leer, escribir, ejecutar |
|
4 | Leer, no escribir, no ejecutar |
|
5 | Leer, no escribir, ejecutar |
|
6 | Leer, escribir, no ejecutar |
|
7 | Leer, escribir, ejecutar |
|
Puede utilizar el parámetro de línea de órdenes -l de ls(1) para ver un listado largo que incluya una columna con información acerca de los permisos de fichero para el propietario, grupo y los demás. Por ejemplo, un ls -l en un directorio puede mostrar algo como esto:
% ls -l
total 530
-rw-r--r-- 1 root wheel 512 Sep 5 12:31 mifichero
-rw-r--r-- 1 root wheel 512 Sep 5 12:31 otrofichero
-rw-r--r-- 1 root wheel 7680 Sep 5 12:31 email.txt
...Aquí está como se divide la primera columna de ls -l:
-rw-r--r--El primer caracter (más a la izquierda) indica si este fichero es un fichero regular, un directorio, un dispositivo especial de caracter, un socket o cualquier otro dispositivo especial pseudo-ficheroa . En este caso, el - un fichero regular. Los siguientes tres caracteres, rw- en este ejemplo, dan los permisos para el propietario del fichero. Los siguientes tres caracteres, r--, dan los permisos para el grupo al que el fichero pertenece. Los últimos tres caracteres, r--, dan los permisos para el resto del mundo. Un guión indica que el permiso está desactivado. En el caso de este fichero, los permisos están asignados de tal manera que el propietario puede leer y escribir en el fichero, el grupo puede leer el fichero, y el resto del mundo sólo puede leer el fichero. De acuerdo con la tabla de arriba, los permisos para este fichero serían 644, donde cada dígito representa las tres partes de los permisos del fichero.
Todo ésto está muy bien, pero ?cómo controla el sistema los permisos de los dispositivos? FreeBSD en realidad trata la mayoría de los dispositivos hardware como un fichero que los programas pueden abrir, leer y en los que pueden escribir datos como si de cualquier otro fichero se tratara. Estos ficheros especiales de dispositivo se encuentran en el directorio /dev.
Los directorios también son tratados como ficheros. Tienen permisos de lectura, escritura y ejecución. El bit de ejecución en un directorio tiene un significado ligeramente distinto que para los ficheros. Cuando un directorio está marcado como ejecutable significa que se puede mirar dentro, se puede hacer un «cd» (cambiar directorio) a él. Esto también significa que dentro del directorio es posible acceder a ficheros cuyos nombres son conocidos (sujeto, claro está, a los permisos de los ficheros mismos).
En particular, para poder realizar un listado de directorio, el permiso de lectura debe ser activado en el directorio, mientras que para borrar un fichero del que se conoce el nombre es necesario tener permisos de escritura y ejecución en el directorio que contiene el fichero.
Existen más permisos, pero se usan principalmente en circunstancias especiales como los binarios ejecutables de tipo setuid y los los directorios de tipo «sticky». Si desea más información acerca de los permisos de ficheros y cómo establecerlos, consulte chmod(1).
3.3.1. Permisos simbólicos
Los permisos simbólicos, también conocidos como expresiones simbólicas, utilizan caracteres en lugar de valores octales para asignar permisos a ficheros o directorios. Las expresiones simbólicas utilizan la sintaxis de (quién) (acción) (permisos) mediante los siguientes valores:
| Opción | Letra | Representa |
|---|---|---|
(quién) | u | Usuario |
(quién) | g | Grupo propietario |
(quién) | o | Otro |
(quién) | a | Todos («todo el mundo») |
(acción) | + | Añadir permisos |
(acción) | - | Quitar permisos |
(acción) | = | Activar permisos explícitamente |
(permisos) | r | Lectura |
(permisos) | w | Escritura |
(permisos) | x | Ejecución |
(permisos) | t | Bit Sticky («pegajoso») |
(permisos) | s | Activar UID o GID |
Estos valores se aplican con chmod(1) de la misma manera que los anteriores, pero con letras. Por ejemplo, podría usar la siguiente orden para bloquear a otros usuarios el acceso a FICHERO:
% chmod go= FICHEROPuede usarse una lista separada por comas cuando se quiera aplicar más de un conjunto de cambios a un fichero. Por ejemplo la siguiente orden eliminará los permisos de escritura de grupo y «mundo» a FICHERO, y añade permisos de ejecución para todos:
% chmod go-w,a+x FILE3.3.2. Banderas de fichero en FreeBSD
Además de los permisos de fichero previamente expuestos, FreeBSD permite el uso de «banderas de fichero». Estas banderas añaden un nivel de seguridad y control adicional a los ficheros, pero no a los directorios.
Las banderas de fichero añaden un nivel adicional de control sobre los ficheros ayudando a asegurar que en algunos casos ni siquiera root pueda eliminar o alterar ficheros.
Las banderas de fichero se modifican mediante chflags(1), gracias a una interfaz muy sencilla. Por ejemplo, para habilitar la bandera imborrable de sistema en fichero1, escriba lo siguiente:
# chflags sunlink fichero1Y para dehabilitar la bandera imborrable de sistema, simplemente escriba la orden previa con «no» antes de sunlink. Observe:
# chflags nosunlink fichero1Para ver las banderas de este fichero, utilice ls(1) con las opciones -lo:
# ls -lo fichero1La salida debería ser como esta:
-rw-r--r-- 1 trhodes trhodes sunlnk 0 Mar 1 05:54 fichero1
Varias banderas solo pueden ser añadidas o retiradas de ficheros por el usuario root. En otros casos, el propietario del fichero puede activar estas banderas. Se recomienda que para más información la persona encargada de la administración del sistema consulte las páginas de manual chflags(1) y chflags(2).
3.3.3. Los permisos setuid, setgid y sticky
Además de los permisos que se han explicado hay más, hay tres tipos más que todos los administradores deberían conocer. Son los permisos setuid, setgid y sticky.
Estos permisos juegan un papel clave en ciertas operaciones UNIX® puesto que facilitan funcionalidades que no se suelen permitir a los usuarios normales. Para comprenderlas totalmente hay que comprender la diferencia entre el ID real del usuario y el ID efectivo.
El ID del usuario real es el UID que arranca (y el propietario) del proceso. El UID efectivo es el ID bajo el que se ejecuta el proceso. Veamos un ejemplo; el programa passwd(1) se ejecuta con el ID real del usuario puesto que el usuario está cambiando su contraseña. Pero para poder manipular la base de datos de contraseñas debe ejecutarse con el ID efectivo del usuario root. De este modo es posible que los usuarios cambien su contraseña sin llegar a ver un error de Permission Denied (permiso denegado).
El permiso setuid puede asignarse colocando un número cuatro (4) antes de los permisos. Se ve mejor con un ejemplo:
# chmod 4755 ejemplosuid.shLos permisos de ejemplosuid.sh deberían ser así:
-rwsr-xr-x 1 trhodes trhodes 63 Aug 29 06:36 ejemplosuid.sh
Fíjese atentamente en la s que ha aparecido en los permisos del fichero, en la parte de los permisos del propietario; esa s está en donde estaría el bit de ejecución. Gracias a esto el funcionamiento de aplicaciones que necesitan permisos elevados, como passwd, pueden funcionar.
Si quiere ver un ejemplo con sus propios ojos abra dos terminales. En una arranque un proceso (ejecute) passwd con un usuario normal. Mientras la aplicación espera a que le de una nueva contraseña busque la información de usuario del proceso passwd en la tabla de procesos.
En la terminal A:
Changing local password for trhodes
Old Password:En la terminal B:
# ps aux | grep passwdtrhodes 5232 0.0 0.2 3420 1608 0 R+ 2:10AM 0:00.00 grep passwd
root 5211 0.0 0.2 3620 1724 2 I+ 2:09AM 0:00.01 passwdTal y como se ha dicho, un usuario normal puede ejecutar passwd, pero en realidad está utilizando el UID efectivo de root.
El permiso setgid actúa del mismo modo que el setuid, pero afecta a los permisos del grupo. Cuando una aplicación funciona con esta configuración lo hace con los permisos del grupo al que pertenece el fichero, no los del usuario que ha arrancado el proceso.
Si quiere utilizar el permiso setgid debe situar un núnmero dos (2) al principio de los permisos que vaya a asignar mediante chmod.
# chmod 2755 ejemplosuid.shLa nueva configuración tiene un aspecto muy similar a la que tenía antes, pero observe que la s de antes está ahora en el campo de los permisos de grupo:
-rwxr-sr-x 1 trhodes trhodes 44 Aug 31 01:49 ejemplosuid.shEn ambos ejemplos, incluso si el «script» en cuestión es ejecutable, no se va a ejecutar con un EUID distinto o un ID efectivo de usuario porque los «scripts» de shell no pueden acceder a la llama del sistema setuid(2). |
Los dos permisos que acabamos de mostrar los bits de permisos (setuid y setgid) pueden reducir el nivel de seguridad haciendo que se escalen los permisos. Pero hay un tercer bit especial de permisos que puede ser de mucha ayuda para reforzar la seguridad del sistema: el sticky bit.
El sticky bit( que podríamos traducir como «bit pegajoso») aplicado a un directorio hace que solamente el propietario de un fichero pueda borrarlo. Esto evita el borrado de ficheros ajenos en directorios públicos como /tmp. Si quiere usarlo coloque un uno (1) antes de los permisos. Veamos un ejemplo:
# chmod 1777 /tmpPara ver el ;sticky bit en acción usamos ls:
# ls -al / | grep tmpdrwxrwxrwt 10 root wheel 512 Aug 31 01:49 tmpEl sticky bit es la letra t al final de los permisos.
3.4. Estructura de directorios
La jerarquía del sistema de ficheros de FreeBSD es fundamental para obtener una compresión completa del sistema. El concepto más importante a entender es el del directorio raíz, «/». Este directorio es el primero en ser montado en el arranque y contiene el sistema básico necesario para preparar el sistema operativo para su funcionamiento en modo multiusuario. El directorio raíz también contiene puntos de montaje para cualquier otro sistema de ficheros que se pretenda montar.
Un punto de montaje es un directorio del que se pueden colgar sistemas de ficheros adicionales en un sistema padre (que suele ser el directorio raíz). Esto se explica con detalle en la Organización de disco. Los puntos de montaje estándar son, por ejemplo, /usr, /var, /tmp, /mnt y /cdrom. Estos directorios suelen corresponderse con entradas en /etc/fstab. /etc/fstab es una tabla que sirve de referencia al sistema y contiene los diferentes sistemas de ficheros y sus respectivos puntos de montaje. La mayoría de los sistemas de ficheros en /etc/fstab se montan automáticamente en el arranque gracias al «script» rc(8), a menos que contengan la opción noauto. Si quiere más información consulte la El fichero fstab.
Veremos ahora una descripción de los directorios más comunes. Si desea información más completa consulte hier(7).
| Directorio | Descripción |
|---|---|
/ | Directorio raíz del sistema de ficheros. |
/bin/ | Utilidades de usuario fundamentales tanto para el ambiente monousuario como para el multiusuario. |
/boot/ | Programas y ficheros de configuración necesarios durante el arranque del sistema operativo. |
/boot/defaults/ | Ficheros de configuración por omisión del arranque; ver loader.conf(5). |
/dev/ | Nodos de dispositivo; ver intro(4). |
/etc/ | Ficheros de configuración y «scripts» del sistema. |
/etc/defaults/ | Ficheros de configuración por omisión del sistema; ver rc(8). |
/etc/mail/ | Ficheros de configuración para agentes de transporte de correo como sendmail(8). |
/etc/namedb/ | Ficheros de configuración de |
/etc/periodic/ | «Scripts» que se ejecutan diariamente, semanalmente y mensualmente mediante cron(8); ver periodic(8). |
/etc/ppp/ | Ficheros de configuración de |
/mnt/ | Directorio vacío utilizado de forma habitual por administradores de sistemas como punto de montaje temporal. |
/proc/ | Sistema de ficheros de procesos; ver procfs(5), mount_procfs(8). |
/rescue/ | Programas enlazados estáticamente para restauraciones de emergencia; ver rescue(8). |
/root/ | Directorio local para la cuenta |
/sbin/ | Programas del sistema y utilidades fundamentales de administración para ambientes monousuario y multiusuario. |
/tmp/ | Ficheros temporales. El contenido de /tmpNO suelen conservarse después de un reinicio del sistema. Los sistemas de ficheros basados en memoria suelen montarse en /tmp Puede automatizarse mediante variables de tmpmfs en rc.conf(5) (o con una entrada en /etc/fstab; ver mdmfs(8), o para FreeBSD 4.X, mfs(8)). |
/usr/ | La mayoría de utilidades y aplicaciones de usuario. |
/usr/bin/ | Aplicaciones comunes, herramientas de programación y otras aplicaciones. |
/usr/include/ | Ficheros «include» estándar de C. |
/usr/lib/ | Bibliotecas. |
/usr/libdata/ | Ficheros de datos con diversas funciones. |
/usr/libexec/ | Dæmons del sistema y utilidades del sistema (ejecutados por otros programas). |
/usr/local/ | Ejecutables locales, bibliotecas, etc. también se usa como destino por omisión de la infraestructura de ports de FreeBSD. Dentro de /usr/local debe seguirse el esquema general definido en hier(7) para /usr. Las excepciones son el directorio man, que está directamente bajo /usr/local en lugar de debajo de /usr/local/share, y la documentación de los ports está en share/doc/port. |
/usr/obj/ | Arbol destino dependiente de arquitectura fruto de la compilación del árbol /usr/src. |
/usr/ports | La colección de Ports de FreeBSD (opcional). |
/usr/sbin/ | Dæmons del sistema y utilidades del sistema (ejecutados por usuarios del sistema). |
/usr/shared/ | Ficheros independientes de arquitectura. |
/usr/src/ | Ficheros fuente BSD y/o local. |
/usr/X11R6/ | Ejecutables de la distribución X11R6, bibliotecas, etc (opcional). |
/var/ | Ficheros multipropósito de log, temporales, en tránsito y de «spool». En ocasiones se monta en /var un sistema de ficheros basado en memoria. |
/var/log/ | Diversos ficheros de log del sistema. |
/var/mail/ | Ficheros de buzones de correo de usuarios. |
/var/spool/ | Directorios diversos del sistema de spool de impresora y correo. |
/var/tmp/ | Ficheros temporales. Suelen conservarse tras el Estos ficheros suelen conservarse tras el reinicio del sistema, a menos que /var sea un sistema de ficheros basado en memoria. |
/var/yp | Mapas NIS. |
3.5. Organización de disco
La unidad más pequeña que FreeBSD utiliza para ubicar ficheros es el nombre de fichero. Los nombres de fichero son sensibles a las mayúsculas, lo que significa que readme.txt y README.TXT son dos ficheros distintos. FreeBSD no utiliza la extensión (.txt) de un fichero para determinar si es un programa, o un documento o alguna otra forma de datos.
Los ficheros se almacenan en directorios. Un directorio puede estar vacío, o puede contener cientos de ficheros. Un directorio también puede contener otros directorios, permitiéndole contruir una jerarquía de directorios dentro de otro. Esto hace mucho más fácil la organización de sus datos.
Para referirse a ficheros o directorios se usa el nombre de archivo o de directorio, seguido por una barra, /, seguido por cualquier otro nombre de directorio que sea necesario. Si tiene un directorio tal, el cual contiene el directorio cual, el cual contiene el fichero readme.txt, entonces el nombre completo o ruta al fichero es tal/cual/readme.txt.
Los directorios y ficheros se almacenan en un sistema de ficheros. Cada sistema de ficheros contiene un sólo directorio en el nivel más elevado, que es el directorio raíz de ese sistema de ficheros. Este directorio raíz puede contener otros directorios.
Lo visto hasta ahora probablemente sea similar a cualquier otro sistema operativo que pueda haber utilizado, pero hay unas cuantas diferencias; por ejemplo, MS-DOS® utiliza \ para separar nombres de fichero y directorio, mientras que Mac OS® usa :.
FreeBSD no utiliza letras de unidades, u otro nombre de unidad en la ruta. Por tanto, no podrá escribir c:/tal/cual/readme.txt en FreeBSD.
En FreeBSD, en cambio, un sistema de ficheros recibe el nombre de sistema de ficheros raíz. El directorio raíz del sistema de ficheros raíz se representa como /. Cualquier otro sistema de ficheros, por tanto, se monta bajo el sistema de ficheros raíz. No importa cuántos discos tenga en su sistema FreeBSD, cada directorio parecerá ser parte del mismo disco.
Suponga que tiene tres sistemas de ficheros, denominados A, B y C. Cada sistema de ficheros tiene un directorio raíz, el cual contiene otros dos directorios, llamados A1, A2 (y de la misma manera B1, B2 y C1, C2).
Usaremos A como sistema de ficheros raíz. Si usara ls para ver el contenido de este directorio vería dos subdirectorios, A1 y A2. El árbol de directorios sería como este:
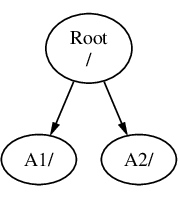
Un sistema de ficheros debe montarse en un directorio de otro sistema de ficheros. Ahora suponga que monta el sistema de ficheros B en el directorio A1. El directorio raíz de B reemplaza a A1, y los directorios en B aparecen de esta manera:
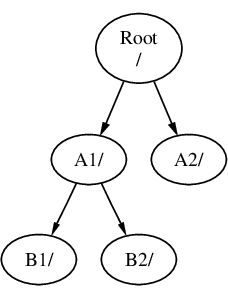
Cualquier fichero que esté en el directorio B1 o B2 puede encontrarse con la ruta /A1/B1 o /A1/B2 según sea necesario. Cualquier fichero que esté en /A1 ha desaparecido temporalmente. Aparecerán de nuevo si B se desmonta de A.
Si B se monta en A2 entonces el diagrama se vería así:
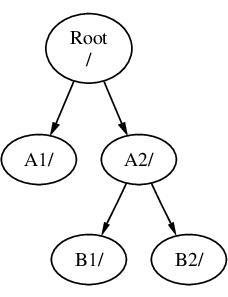
y las rutas serían /A2/B1 y /A2/B2 respectivamente.
Pueden montarse sistemas de ficheros uno sobre otro. Continuando con el ejemplo anterior, el sistema de ficheros C podría montarse en el directorio B1 en el sistema de ficheros B, lo que nos llevaría a esto:
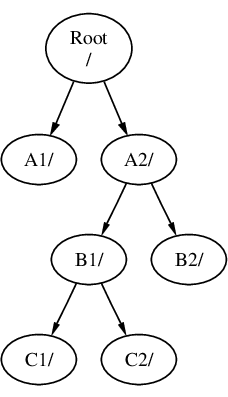
O C podría montarse directamente en el sistema de ficheros A, bajo el directorio A1:
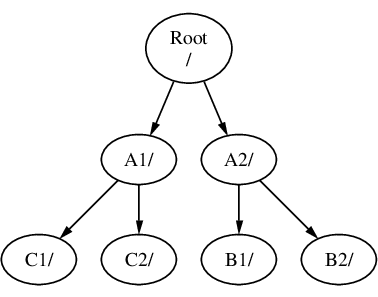
Si está familiarizado con MS-DOS® esto es similar, aunque no idéntico, a utilizar join.
Esto no es algo a lo deba usted dedicar tiempo de forma habitual. Normalmente creará sistemas de ficheros al instalar FreeBSD y decidirá dónde montarlos; lo más habitual es que no los cambie de sitio a menos que agregue un disco nuevo.
Es perfectamente posible tener un sistema de ficheros raíz extenso y no necesitar crear otros. Este esquema tiene unos cuantos inconvenientes y una ventaja:
Ventajas de disponer de múltiples sistemas de ficheros
Si dispone de varios sistemas de ficheros puede optar por usar distintas opciones de montaje. Por ejemplo, gracias a una planificación cuidadosa, el sistema de ficheros raíz puede montarse como sólo-lectura, haciendo imposible borrar sin querer o editar un fichero crítico. Al mantener separados sistemas de ficheros en los que los usuarios pueden escribir, como /home, de otros sistemas de ficheros también le permite montar con la opción nosuid; dicha opción previene que los bits suid/guid en los ejecutables almacenados en el sistema de ficheros tengan efecto, mejorando en cierto modo la seguridad.
FreeBSD optimiza automáticamente el esquema de ficheros en un sistema de ficheros, dependiendo de cómo el sistema de ficheros esté siendo utilizado. Uno que contenga muchos ficheros pequeños tendrá una optimización distinta de uno que contenga menos ficheros y más grandes. Si sólo tiene un gran sistema de ficheros no hay manera de aplicar esta optimización.
Los sistemas de ficheros de FreeBSD son muy robustos en caso de sufrir un caída eléctrica. De todas maneras, un fallo eléctrico en un momento crítico puede dañar la estructura del sistema de ficheros. Si reparte sus datos en múltiples sistemas de ficheros hará que sea más probable que el sistema arranque después de uno de esos fallos, haciéndole además más fácil la tarea de restaurarlo desde un respaldo si fuera necesario.
Ventajas de un sólo sistema de ficheros
Los sistemas de ficheros son de un tamaño fijo. Si crea un sistema de ficheros cuando instala FreeBSD y le da un tamaño específico, tal vez descubra más tarde que necesita hacer la partición más grande. Esto no es fácil de realizar sin hacer una copia de seguridad, crear de nuevo el sistema de ficheros con el nuevo tamaño y entonces restaurar los datos respaldados.
FreeBSD dispone de growfs(8), que permite incrementar el tamanño de un sistema de ficheros «al vuelo», eliminando esta limitación.
Los sistemas de ficheros están alojados en particiones. Este es un detalle muy importante, puesto que el término partición no significa aquí lo mismo que en otros entornos (por ejemplo, en MS-DOS®) debido a la herencia UNIX® de FreeBSD. Cada partición se identifica con una letra desde a hasta h. Cada partición puede contener solamente un sistema de ficheros, lo que significa que los sistemas de ficheros suelen definirse mediante su punto de montaje en la jerarquía del sistema de ficheros o por la letra de la partición en la que están alojados.
FreeBSD también utiliza espacio de disco como espacio de intercambio (swap). El espacio de intercambio le brinda a FreeBSD memoria virtual. Esto permite al su sistema comportarse como si tuviera más memoria de la que realmente tiene. Cuando a FreeBSD se le agota la memoria mueve algunos de los datos que no está utilizando en ese momento al espacio de intercambio, y los vuelve a poner donde estaban (desplazando alguna otra cosa) cuando los necesita.
Algunas particiones tienen ciertas convenciones heredadas.
| Partición | Representación |
|---|---|
| Normalmente contiene el sistema de ficheros raíz |
| Normalmente contiene el espacio de intercambio (swap) |
| Suele tener el mismo tamaño de la «slice» que la encierra. Esto permite a las utilidades que necesitan trabajar en toda la «slice» entera (por ejemplo durante una búsqueda de bloques dañados) trabajar en la partición |
| La partición |
Cada partición que contiene un sistema de ficheros se almacena en lo que FreeBSD llama una «slice». «slice» es en FreeBSD lo que en otros ámbitos se denomina partición; es un hecho que deriva de los orígenes de FreeBSD como ya sabemos basado en UNIX®.
Los números de «slice» muestran el nombre de dispositivo, al que precede una s y un número que puede ser un 1 u otro número mayor. Por lo tanto «da0s1» es la primera slice en la primera unidad SCSI. Sólo puede haber cuatro «slice» físicas en un disco, pero puede haber «slice» lógicas dentro «slice» físicas del tipo apropiado. Estas «slice»extendidas se numeran a partir de 5, así que «ad0s5» es la primera «slice» extendida en el primer disco IDE. Estos dispositivos se usan en sistemas de ficheros que se preve que ocupen una slice.
Tanto las «slice» y las unidades físicas «peligrosamente dedicadas», como otras unidades contienen particiones, que se designan mediante letras desde la a hasta h. Esta letra se añade al nombre del dispositivo. Se verá mucho mejor mediante ejemplos: «da0a» es la partición a en la primera unidad da y es una de esas a las que llamamos «peligrosamente dedicada». «ad1s3e» es la quinta partición en la tercera slice de la segunda unidad de disco IDE.
Para terminar, cada disco en el sistema tiene también su designación. El nombre de disco comienza por un código que indica el tipo de disco, luego un número, que indica qué disco es. A diferencia de las «slice», la numeración de discos comienza desde 0. Puede las numeraciones más comunes en el Códigos de dispositivos de disco.
Cuando se hace referencia a una partición, FreeBSD necesita que también se nombre la «slice» y el disco que contiene la partició. Esto se hace con el nombre de disco, s, el número «slice» y por último la letra de la partición. Tiene varios casos en el Ejemplo de nombres de disco, «slice» y partición.
En el Modelo conceptual de un disco muestra un modelo conceptual del esquema de un disco que debería ayudarle a aclarar las cosas.
Antes de instalar FreeBSD tendrá que configurar las «slice» de disco, después crear particiones dentro de las «slice» que vaya a usar en FreeBSD y luego crear un sistema de ficheros (o swap) en cada partición y luego decidir cuál va a ser el punto de montaje del sistema de ficheros.
| Código | Significado |
|---|---|
ad | Disco ATAPI (IDE) |
da | Disco de acceso directo SCSI |
acd | CDROM ATAPI (IDE) |
cd | CDROM SCSI |
fd | Disquete (floppy) |
Ejemplo 1. Ejemplo de nombres de disco, «slice» y partición
| Nombre | Significado |
|---|---|
| La primera partición ( |
| La quinta partición ( |
Ejemplo 2. Modelo conceptual de un disco
Este diagrama muestra cómo ve FreeBSD el primer disco IDE en el sistema. Se asume que el disco es de 4 GB, y contiene dos «slices» de 2 GB (particiones MS-DOS®). La primera partición contiene un disco MS-DOS®, C:, y la segunda partición contiene una instalación de FreeBSD. Esta instalación de ejemplo tiene tres particiones, y una partición swap.
Cada una de las tres particiones tiene un sistema de ficheros. La partición a se utilizará para el sistema de ficheros raíz, e para la jerarquía del directorio /var, y f para la jerarquía del directorio /usr.

3.6. Montaje y desmontaje de sistemas de ficheros
El sistema de ficheros se visualiza mejor como un árbol enraizado, tal y como esá, en /. /dev, /usr y todos los demás directorios en el directorio raíz son raamas, las cuales pueden tener sus propias ramas, como /usr/local y así sucesivamente.
Existen varias razones para albergar algunos de estos directorios en sistemas de ficheros separados. /var contiene los directorios log/, spool/ y varios tipos de ficheros temporales y pueden llegar a desbordarse. Agotar el espacio del sistema de ficheros raíz no es nada bueno desde cualquier punto de vista, así que separar /var de de / es algo que debería hacerse siempre que sea posible.
Otra razón para meter ciertos árboles de directorios en otros sistemas de ficheros es si van a estar albergados en discos físicos separados, o si son discos virtuales separados, como un montaje por NFS en el caso de unidades de CDROM.
3.6.1. El fichero fstab
Durante el proceso de arranque los sistemas de ficheros listados en /etc/fstab se montan automáticamente (a menos que estén listados con la opción noauto).
/etc/fstab contiene una lista de líneas con el siguiente formato:
dispositivo /punto-de-montaje punto de montaje opciones dumpfreq passno
dispositivoUn nombre de dispositivo (debe existir).
punto-de-montajeUn directorio (que debe existir) en el que montar el sistema de ficheros.
tipo de sistema ficherosEl tipo de sistema de ficheros es un parámetro que interpretará mount(8). El sistema de ficheros por omisión de FreeBSD es
ufs.opcionesYa sea
rwpara sistemas de ficheros de lectura-escritura, oropara sistemas de ficheros de sólo lectura, seguido de cualquier otra opción que sea necesaria. Una opción muy habitual esnoauto, que se suele usar en sistemas de ficheros que no se deben montar durante la secuencia de arranque. Tiene otras opciones en la página de manual de mount(8).dumpfreqdump(8) la usa para determinar qué sistema de ficheros requieren volcado. Si el campo no está declarado se asume un valor de cero.
passnoDetermina el orden en el cual los sistemas de ficheros deben revisarse. Los sistemas de ficheros que hayan de saltarse deben tener su
passnoa cero. El sistema de ficheros raíz (que obviamente debe ser revisado antes que cualquier otro) debe tener supassnopuesto a uno, y los demás sistemas de ficheros deben tener valores mayores que uno. Si más de un sistema de ficheros tiene el mismopassnofsck(8) tratará de revisarlos en paralelo en caso de ser posible.
Consulte la página de manual de fstab(5) para mayor información sobre el formato del fichero /etc/fstab y las opciones que contiene.
3.6.2. La orden mount
mount(8) es al fin y al cabo quien monta los sistemas de ficheros.
En su forma más básica se usa lo siguiente:
# mount dispositivo punto-de-montajeExiste una gran cantidad de opciones (las encontrará todas en mount(8)) pero las más comunes son:
Opciones de montaje
-aMontar todos los sistemas de ficheros que aparezcan en /etc/fstab, excepto aquellos marcados como «noauto», excluidos por el parámetro
-to aquellos que ya estén montados.-dRealizar todo excepto la llamada real de montaje del sistema. Esta opción es muy útil en caso de problemas si se combina con la opción
-vpara determinar qué es lo que mount(8) está haciendo realmente.-fForzar el montaje de un sistema de ficheros inestable (por ejemplo uno que da errores tras un reinicio súbito, algo que es bastante peligroso), o forzar la revocación de accesos de escritura cuando se cambia el estado de un sistema de ficheros de lectura-escritura a solo lectura.
-rMontar el sistema de ficheros como sólo lectura. Esto es idéntico a utilizar el argumento
ro(rdonlypara versiones anteriores a FreeBSD 5.2) en la opción-o.-ttipo de sistema de ficherosMontar un sistema de ficheros dado con el tipo de sistema de ficheros, o montar solamente sistemas de ficheros del tipo dado si se proporciona la opción
-a.«ufs» es el sistema de ficheros por omisión.
-uActualizar puntos de montaje en el sistema de ficheros.
-vMostrar mayor información.
-wMontar el sistema de ficheros como lectura-escritura.
La opción -o toma una lista las siguientes opciones separada por comas:
- nodev
No interpretar dispositivos especiales en el sistema ficheros. Es una opción de seguridad que puede ser muy útil.
- noexec
No permitir la ejecución de binarios en este sistema de ficheros. Esta también es una opción de seguridad útil.
- nosuid
No interpretar bits setuid o setgid en el sistema de ficheros. Esta también es una opción de seguridad útil.
3.6.3. La orden umount
umount(8) toma como parámetro un punto de montaje, un nombre de dispositivo, o la opción -a o -A.
Todas las formas toman -f para forzar el desmontaje y -v para mostrar más información. Tenga muy en cuenta que usar -f no suele ser una forma recomendable de proceder. Desmontar a la fuerza los sistemas de ficheros puede acarrear el congelar la máquina o dañar los datos en el sistema de ficheros.
-a y -A se usan para desmontar todos los sistemas de ficheros montados, con la ventaja de poder elegir el tipo de sistema de ficheros que se use tras -t. De todas maneras -A no trata de desmontar el sistema de ficheros raíz.
3.7. Procesos
FreeBSD es un sistema operativo multitarea. Esto significa que parece como si más de un programa se estuviera ejecutando al mismo tiempo. Cada programa uno de esos programas que se está ejecutando en un momento dado se denomina proceso. Cada orden que ejecuta iniciará al menos un proceso nuevo, y hay muchos procesos que se están que se están ejecutando en todo momento, manteniendo el sistema en funcionamiento.
Cada proceso tiene un identificador individual consistente en un número llamado ID del proceso, o PID, y al igual que sucede con los ficheros, cada proceso tiene un propietario y un grupo. La información de propietario y grupo se usa para determinar qué ficheros y dispositivos puede abrir el proceso mediante los permisos de fichero explicados anteriormente. La mayoría de los procesos también tiene un proceso padre. El proceso padre es el proceso que los inició. Por ejemplo, si está tecleando órdenes en la shell, la shell es un proceso, y cualquier orden que usted ejecute también lo será. De este modo cada proceso que ejecute tendrá como proceso padre a su shell. La excepción es un proceso especial llamado init(8). init es siempre el primer proceso, así que su PID siempre es 1. El kernel arranca automáticamente init en el arranque de FreeBSD.
Hay dos órdenes particularmente útiles para ver los procesos en el sistema, ps(1) y top(1). ps se usa para mostrar una lista estática de los procesos que se ejecutan en el sistema en es momento, y puede mostrar sus PID, cuánta memoria está usando, la línea de órdenes con la que fueron iniciados y muchas más cosas. top despliega todos los procesos que se están ejecutando y actualiza la pantalla cada pocos segundos para que pueda ver lo que está haciendo su sistema.
Por omisión ps solo le muestra las órdenes que están ejecutando y que sean propiedad de su usuario. Por ejemplo:
% ps
PID TT STAT TIME COMMAND
298 p0 Ss 0:01.10 tcsh
7078 p0 S 2:40.88 xemacs mdoc.xsl (xemacs-21.1.14)
37393 p0 I 0:03.11 xemacs freebsd.dsl (xemacs-21.1.14)
48630 p0 S 2:50.89 /usr/local/lib/netscape-linux/navigator-linux-4.77.bi
48730 p0 IW 0:00.00 (dns helper) (navigator-linux-)
72210 p0 R+ 0:00.00 ps
390 p1 Is 0:01.14 tcsh
7059 p2 Is+ 1:36.18 /usr/local/bin/mutt -y
6688 p3 IWs 0:00.00 tcsh
10735 p4 IWs 0:00.00 tcsh
20256 p5 IWs 0:00.00 tcsh
262 v0 IWs 0:00.00 -tcsh (tcsh)
270 v0 IW+ 0:00.00 /bin/sh /usr/X11R6/bin/startx -- -bpp 16
280 v0 IW+ 0:00.00 xinit /home/nik/.xinitrc -- -bpp 16
284 v0 IW 0:00.00 /bin/sh /home/nik/.xinitrc
285 v0 S 0:38.45 /usr/X11R6/bin/sawfishComo puede ver en este ejemplo la salida de ps(1) está organizada en columnas. PID es el ID de proceso anteriormente expuesto. Los PIDs se asignan a partir del 1 y hasta 99999, y vuelven a comenzar desde el 1 otra cuando se terminan los números. La columna TT muestra la tty en la que el programa se está ejecutando; podemos ignorarla tranquilamente por el momento. STAT muestra el estado del programa; de momento también podemos ignorarlo. TIME es la cantidad de tiempo que el programa ha se ha estado ejecutando en la CPU (generalmente no es el tiempo transcurrido desde que se inició el programa, ya que la mayoría de los programas pasan mucho tiempo esperando antes de que necesiten gastar tiempo en la CPU. Finalmente, COMMAND es la línea de órdenes que se empleó para ejecutar el programa.
ps(1) admite muchas opciones sobre la información que se desea ver. Uno de los conjuntos más útiles es auxww. a muestra información acerca de todos los procesos ejecutándose, no solamente los suyos. u despliega el nombre de usuario del propietario del proceso, así como el uso de memoria. x despliega información acerca de los procesos dæmon y ww hace que ps(1) despliegue la línea de órdenes completa, en lugar de truncarla cuando es demasiado larga para caber en la pantalla.
La salida de top(1) es similar. Veamos un ejemplo:
% top
last pid: 72257; load averages: 0.13, 0.09, 0.03 up 0+13:38:33 22:39:10
47 processes: 1 running, 46 sleeping
CPU states: 12.6% user, 0.0% nice, 7.8% system, 0.0% interrupt, 79.7% idle
Mem: 36M Active, 5256K Inact, 13M Wired, 6312K Cache, 15M Buf, 408K Free
Swap: 256M Total, 38M Used, 217M Free, 15% Inuse
PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU COMMAND
72257 nik 28 0 1960K 1044K RUN 0:00 14.86% 1.42% top
7078 nik 2 0 15280K 10960K select 2:54 0.88% 0.88% xemacs-21.1.14
281 nik 2 0 18636K 7112K select 5:36 0.73% 0.73% XF86_SVGA
296 nik 2 0 3240K 1644K select 0:12 0.05% 0.05% xterm
48630 nik 2 0 29816K 9148K select 3:18 0.00% 0.00% navigator-linu
175 root 2 0 924K 252K select 1:41 0.00% 0.00% syslogd
7059 nik 2 0 7260K 4644K poll 1:38 0.00% 0.00% mutt
...La salida está dividida en dos secciones. La cabecera (las primeras cinco líneas) muestra el PID del último proceso en ejecutarse, la carga promedio del sistema (una medida de la carga del sistema), el «uptime» del sistema (tiempo desde el último reinicio) y la hora actual. Las otras cifras en la cabecera se relacionan con cuántos procesos hay en ejecución en el sistema (47 en este caso), cuánta memoria y espacio de intercambio (swap) está en uso, y cuánto tiempo está el sistema en diferentes estados de CPU.
Más abajo hay una serie de columnas con información similar a la salida de ps(1). Igual que antes, puede usted ver el PID, el nombre de usuario, la cantidad de tiempo de CPU en uso y la orden que se ejecutó. top(1) también mostrará por omisión la cantidad de espacio de memoria que emplea cada proceso. Está dividido en dos columnas, una para el tamaño total y otra para el tamaño residente (el tamaño total es cuánta memoria ha necesitado la aplicación y el tamaño residente es cuánta se está usando en ese momento concreto). En este ejemplo puede verse que getenv(3) requerido casi 30 MB de RAM, pero actualmente solo está usando 9 MB.
top(1) actualiza automáticamente el listado cada dos segundos, pero este lapso puede cambiarse mediante la opción s.
3.8. Dæmons, señales y cómo matar procesos
cuando ejecuta un editor es fácil controlarlo, decirle que cargue ficheros y demás. Puede hacerse porque el editor permite ese control y porque el editor depende de una terminal. Algunos programas no están diseñados para ejecutarse entradas continuas por parte del usuario, así que se desconectan de la terminal a la primera oportunidad. Por ejemplo, un servidor web pasa todo el dia respondiendo peticiones web y normalmente no necesita que usted le haga caso. Los programas que transportan correo electrónico de un sitio a otro son otro ejemplo de esta clase de aplicación.
Llamamos a estos programas dæmons. Los Dæmons eran personajes de la mitología griega; no eran ni buenos ni malos, eran pequeños espíritus sirvientes que, en gran medida, hacían cosas útiles por la humanidad. Algo muy parecido a cómo los servidores web y los servidores de correo hacen hoy día tantas cosas útiles para nosotros. Por eso, desde hace mucho tiempo la mascota de BSD es ese dæmon de aspecto tan ufano con su tridente y su cómodo calzado deportivo.
Hay una norma según la cual se da nombre a los programas que suelen ejecutarse como dæmons con una «d» final. BIND es el dæmon de nombres de Berkeley (y el programa que en realidad se ejecuta se llama named); el servidor web Apache se llama httpd, el dæmon de «spool» de impresora de línea es lpd y así sucesivamente. Se trata de un acuerdo, no una ley férrea; por ejemplo el dæmon principal de correo de Sendmail se llama sendmail, y no maild, como podría suponerse visto lo precedente.
Algunas veces necesitará comunicarse con un dæmon. Estas comunicaciones se denominan señales; es posible comunicarse con un dæmon (o con cualquier otro proceso ejecutándose) mandándole una señal. Existen diversos tipos de señales diferentes que puede mandar: algunas tienen un significado especial, otras son interpretadas por la aplicación y la documentación de la aplicación le dirá cómo interpreta la señal esa aplicación). Solamente puede enviar una señal a un del que sea usted propietario. Si manda una señal a un proceso de otro usuario con kill(1) o kill(2) verá un mensaje del sistema en el que se le comunica que no tiene permiso para hacer tal cosa. La excepción a esto es el usuario root, que puede mandar señales a los procesos de cualquier usuario del sistema.
FreeBSD también enviará señales de aplicación en determinados casos. Si una aplicación está mal escrita y trata de acceder a memoria a la que no está previsto que acceda FreeBSD manda al proceso la señal Violación de segmento (SIGSEGV). Si una aplicación ha utilizado la llamada de sistema alarm(3) para ser avisada después de que un periodo de tiempo haya transcurrido se le mandará la señal de alarma (SIGALRM), y así sucesivamente.
Hay dos señales que pueden usarse para detener un proceso, SIGTERM y SIGKILL. SIGTERM es la manera amable de matar un proceso; el proceso puede recibir la señal, darse cuenta que usted quiere que se apague, cerrar cualquier fichero de log que pueda tener abierto y generalmente terminar cualquier tarea que esté realizando en ese momento antes de apagarse. En algunos casos un proceso puede incluso ignorar SIGTERM si se encuentra inmerso en una tarea que no puede ser interrumpida.
Por el contrario, un proceso no puede ignorar una señal SIGKILL. Esta es la señal «No me importa lo que estás haciendo, detente ahora mismo». Si manda un SIGKILL a un proceso FreeBSD detendrá ese proceso inmediatamente..
Otras señales que puede usar: SIGHUP, SIGUSR1 y SIGUSR2. Son señales de propósito general, y aplicaciones diferentes pueden hacer cosas diferentes cuando se utilicen.
Suponga que ha cambiado el fichero de configuración de su servidor web; es un buen momento para decirle al servidor web que lea y aplique la configuración. Podría detener y reiniciar httpd, pero esto implicaría un período breve de suspensión del servicio de su servidor web, lo cual puede no ser asumible. La mayoría de los dæmons fueron creados pensando en que fueran capaces de responder a la señal SIGHUP releyendo su fichero de configuración. En lugar de matar y reiniciar httpd le podría mandar la señal SIGHUP. Dado que no hay una manera estándar para responder a estas señales, diferentes dæmons tendrán diferente comportamiento, así que asegúrese de leer la documentación del dæmon en cuestión.
Las señales se envian mediante kill(1), como puede verse en el siguiente ejemplo.
Procedure: Envío de una señal a un proceso
Este ejemplo muestra como enviar una señal a inetd(8). El fichero de configuración de inetd es /etc/inetd.conf e inetd releerá dicho fichero de configuración cuando se le envíe un SIGHUP.
Identifique el ID de proceso del proceso al que quiere enviarle la señal mediante ps(1) y grep(1). grep(1) se usa para buscar cadenas de texto de su elección en la salida estándar. Puede ejecutarse como un usuario normal, mientras que inetd(8) se ejecuta como
root, así que debe pasarle los parámetrosaxa ps(1).% ps -ax | grep inetd 198 ?? IWs 0:00.00 inetd -wWUtilice kill(1) para enviar la señal. Debido a que inetd(8) está siendo ejecutado po
roottendrá que usar primero su(1) para volverseroot.% su # /bin/kill -s HUP 198Del mismo modo que la mayoría de órdenes UNIX® kill(1) no imprimirá ninguna salida si ha funcionado bien. Si envía una señal a un proceso del que no es el propietario verá lo siguiente:
kill: PID: Operation not permitted. Si no teclea bien el PID puede enviar la señal a un proceso equivocado, lo cual puede ser malo, o si tiene suerte, habrá enviado la señal a un proceso que no está en uso y verá el sistema le dirákill: PID: No such process.
¿Por qué utilizar /bin/kill?Muchas shells incorporan su propio |
El envío de otras señales es muy similar; sustituya TERM o KILL en la línea de órdenes según sea necesario.
3.9. Shells
En FreeBSD gran parte del trabajo diario se hace en una interfaz de línea de órdenes llamada shell. El trabajo principal de la shell es ir recibiendo órdenes mediante un canal de entrada y ejecutarlos. Muchas shells también tienen funciones integradas para ayudar ayudar con las tareas diarias como manipulación de ficheros, gestión de archivos con expresiones regulares, edición en la propia línea de órdenes, macros de órdenes y variables de entorno. FreeBSD incluye diversas shells, como sh, el shell Bourne y tcsh, el shell C mejorado. Hay muchas otras shells disponibles en la colección de ports de FreeBSD, como zsh y bash.
?Qué shell usar? es una cuestión de gustos. Si va a programar en C puede preferir usar una shell tipo C, como tcsh. Si viene del mundo Linux o si es nuevo en la interfaz de línea de órdenes de UNIX® puede probar con bash. Tenga en cuenta que cada shell posee unas propiedades únicas que pueden o no funcionar con su entorno de trabajo preferido y que puede usted elegir qué shell usar.
Una de las propiedades comunes de las shell es que completan los nombres de fichero. Una vez que ha introducido las primeras letras de una orden o del nombre de un fichero, se puede hacer que la shell complete automáticamente el resto de la orden o nombre de fichero pulsando la tecla Tab. Veamos un ejemplo. Suponga que tiene dos ficheros llamados talcual y tal.cual. Usted quiere borrar tal.cual. Lo que habría que teclear es: rm ta[tabulador].[tabulador].
La shell mostraría en pantalla rm ta[BIP].cual.
El [BIP] es la campana de la consola, es decir, la shell está diciéndome que no pudo completar totalmente el nombre de fichero porque hay más de una coincidencia. Tanto talcual como tal.cual comienzan por ta, pero solo se pudo completar hasta tal. Si se teclea ., y de nuevo tabulador la shell es capaz de añadir el resto del nombre de fichero.
Otra función de la shell son las variables de entorno. Las variables de entorno son parejas de valores clave almacenados en el espacio de entorno del shell. Este espacio puede ser leído por cualquier programa invocado por la shell y por lo tanto contiene mucha configuración de programas. Esta es una lista de las variables de entorno más comunes y su significado:
| Variable | Descripción |
|---|---|
| Nombre de usuario en el sistema. |
| Lista de directorios, separados por punto y coma, en los que se buscan ejecutables. |
| Nombre de red de la pantalla X11 a la que conectarse, si está disponible. |
| La shell actual. |
| El nombre de la terminal del usuario. Se usa para determinar las características de la terminal. |
| Base de datos donde encontrar los códigos de escape necesarios para realizar diferentes funciones en la terminal. |
| Tipo de sistema operativo. Por ejemplo, FreeBSD. |
| Arquitectura de CPU en la que se está ejecutando el sistema. |
| El editor de texto preferido por el usuario. |
| El paginador de texto preferido por el usuario. |
| Lista de directorios separados por punto y coma en los que se buscan páginas de manual. |
Establecer una variable de entorno difiere ligeramente de shell a shell. Por ejemplo, en las shells al estilo C como tcsh y csh, se usa setenv para establecer las variables de entorno. Bajo shells Bourne como sh y bash, se usa export para establecer las variables de entorno actuales. Por ejemplo, para establecer o modificar la variable de entorno EDITOR (bajo csh o tcsh) la siguiente orden establece EDITOR como /usr/local/bin/emacs:
% setenv EDITOR /usr/local/bin/emacsBajo shells Bourne:
% export EDITOR="/usr/local/bin/emacs"También se puede hacer que la mayoría de las shells muestren el contenido de una variable de entorno situando el carácter $ delante del nombre de la variable en la línea de órdenes. Por ejemplo, echo $TERM mostrará cualquiera que sea el valor que haya establecido para $TERM, porque la shell expande el valor de $TERM y se lo pasa al programa echo.
Las shells manejan muchos caracteres especiales, llamados metacaracteres, como representaciones especiales de datos. El más común es el caracter *, que representa cualquier número de caracteres en un nombre de fichero. Estos metacaracteres especiales se pueden usar para la expansión de nombres de fichero. Por ejemplo, teclear echo * es casi lo mismo que introducir ls porque la shell toma todos los ficheros que coinciden con * y se los pone en la línea de órdenes para que echo los vea.
Para evitar que la shell interprete estos caracteres especiales pueden escamotearse anteponiéndoles una contrabarra (\). echo $TERM imprime el nombre de terminal que esté usando. echo \$TERM imprime $TERM, literalmente.
3.9.1. Cómo cambiar su shell
La manera más fácil de cambiar de shell es mediante chsh. chsh le colocará dentro del editor que esté configurado en la variable de entorno EDITOR; si no la ha modificado, el sistema ejecutará vi, el editor por omisión. Cambie la línea «Shell:» según sus gustos.
También se le puede suministrar a chsh la opción -s; ésto establecerá la shell sin necesidad de entrar en el editor de texto. Si por ejemplo quiere que bash sea su shell por omisión puede configurarlo del siguiente modo:
% chsh -s /usr/local/bin/bashEjecutar chsh sin parámetros y editar la shell desde ahí también funciona.
La shell que se desee usar debe estar incluida en /etc/shells. Si se ha instalado una shell desde la colección de ports esto deberí estar hecho automáticamente. Si ha instalado la shell manualmente, tendrá usted que realizar el cambio oportuno en /etc/shells. Por ejemplo, si instaló manualmente Hecho esto vuelva a ejecutar |
3.10. Editores de texto
Gran parte de la configuración de FreeBSD se realiza modificando ficheros de texto, así que le conviene familiarizarse con alguno de ellos. FreeBSD viene con unos cuantos como parte del sistema base y encontrará muchos más en la colección de ports.
El editor de textos más sencillo y fácil de aprender es uno llamado ee, cuyo nombre proviene del inglés «easy editor» (editor fácil). Para iniciar ee se debe teclear en la línea de órdenes ee nombre-de-fichero, donde nombre-de-fichero es el nombre del fichero que se quiere editar. Por ejemplo, para editar /etc/rc.conf teclée ee /etc/rc.conf. Una vez dentro de ee todas las órdenes para manipular las funciones del editor están listadas en la parte superior de la pantalla. El caracter ^ representa la tecla Ctrl del teclado, por lo tanto ^e significa la combinación de teclas Ctrl+e. Para salir de ee pulse la tecla Esc y elija abandonar («leave») el editor. El editor preguntará entonces si quiere conservar los cambios si el fichero hubiera sido modificado.
FreeBSD viene también con editores de texto mucho más potentes, como vi, como parte del sistema base, mientras que otros editores, como Emacs y vim son parte de la colección de ports de FreeBSD (editors/emacs y editors/vim). Estos editores son muchísimo más poderosos, pero tienen la desventaja de ser un poco más complicados de aprender a manejar. De cualquier manera si planea hacer mucho trabajo de edición de texto, aprender a usar un editor de texto más poderoso como vim o Emacs le ahorrará muchísimo más tiempo a la larga.
3.11. Dispositivos y nodos de dispositivos
Dispositivo es un término utilizado la mayoría de las veces para actividades relacionadas con hardware del sistema, como discos, impresoras, tarjetas gráficas y teclados. Cuando FreeBSD arranca, la mayoría de lo que FreeBSD despliega son dispositivos en el momento de ser detectados. Si lo desea, puede volver a ver todos los mensajes que el sistema emite durante el arranque consultando /var/run/dmesg.boot.
Por ejemplo, acd0 es la primera unidad CDROM IDE, mientras que kbd0 representa el teclado.
En un sistema operativo UNIX® debe accederse a la mayoría de estos dispositivos a través de ficheros especiales llamados nodos de dispositivo, que se encuentran en el directorio /dev.
3.11.1. Creación de nodos de dispositivo
Cuando agregue un nuevo dispositivo a su sistema, o compile soporte para dispositivos adicionales, puede que necesite crear uno o más nodos de dispositivo.
3.11.1.1. DEVFS Dispositivo de sistema de ficheros (DEVice File System)
El dispositivo de sistema de ficheros, o DEVFS, ofrece acceso a dispositivos del espacio de nombres del kernel en el espacio de nombres del sistema de ficheros global. En lugar de tener que crear y modificar nodos de dispositivo, DEVFS se encarga del mantenimiento dinámico de este sistema de fichero.
Consulte devfs(5) si quiere más información.
3.12. Formatos binarios
Para poder entender por qué FreeBSD utiliza el formato elf(5) primero debe saber ciertas cosas sobre los tres formatos de ejecutables «dominantes» en UNIX®:
El formato objeto de UNIX® más antiguo y «clásico». Utiliza una cabecera corta y compacta con un número mágico al inicio que se usa frecuentemente para identificar el formato (vea a.out(5) para más información). Contiene tres segmentos cargados: .text, .data, y .bss además de una tabla de símbolos y una tabla de cadena («strings»).
COFF
El formato objeto de SVR3. La cabecera consiste en una tabla de sección, para que pueda tener más contenido además de las secciones .text, .data, y .bss.
Es el sucesor de COFF; dispone de secciones múltiples y valores posibles de 32-bits o 64-bits. Una gran desventaja: ELF fué también diseñado asumiendo que solamente existiría una ABI por cada arquitectura de sistema. Esa suposición es en realidad bastante incorrecta y ni siquiera en el mundo comercial SYSV (el cual tiene al menos tres ABIs: SVR4, Solaris y SCO) se puede dar por buena.
FreeBSD trata de solucionar este problema de alguna manera ofreciendo una herramienta para marcar un ejecutable ELF conocido con información acerca de la ABI con la que funciona. Si quiere más información consulte la página de manual de brandelf(1).
FreeBSD viene del campo «clásico» y ha utilizado el formato a.out(5), una tecnología usada y probada en muchas de muchas generaciones de versiones de BSD hasta el inicio de la rama 3.X. Aunque era posible compilar y ejecutar binarios nativos ELF (y kernels) en un sistema FreeBSD desde algún tiempo antes de esto, FreeBSD al principio se mantuvo «contra corriente» y no cambió a ELF como formato por defecto. ?Por qué? Bueno, cuando el mundo Linux efectuó su dolorosa transición a ELF no fué tanto por huir del formato a.out como por su inflexible mecanismo de bibliotecas compartidas basado en tablas de saltos, que hacía igual de difícil la construcción de bibliotecas compartidas tanto para los desarrolladores como para los proveedores. Ya que las herramientas ELF disponibles ofrecían una solución al problema de las bibliotecas compartidas y eran vistas por mucha gente como «la manera de avanzar», el costo de migración fué aceptado como necesario y se realizó la transición. El mecanismo de bibliotecas compartidas de FreeBSD está diseñado de manera más cercana al estilo del sistema de bibliotecas compartidas de SunOS™ de Sun y, como tal, es muy sencillo de utilizar.
Entonces, ?por qué existen tantos formatos diferentes?
En un tiempo muy, muy lejano, existía hardware simple. Este hardware tan simple soportaba un sistema pequeño, simple. a.out era idóneo para el trabajo de representar binarios en este sistema tan simple (un PDP-11). A medida que la gente portaba UNIX® desde este sistema simple, retuvieron el formato a.out debido a que era suficiente para los primeros portes de UNIX® a arquitecturas como 68k de Motorola, VAXen, etc.
Entonces algún brillante ingeniero de hardware decidió que si podía forzar al software a hacer algunos trucos sucios podría sortear ciertos obstáculos del diseño y permitir al núcleo de su CPU correr más rápidamente. Aunque estaba hecho para trabajar con este nuevo tipo de hardware (conocido entonces como RISC), a.out no estaba bien adaptado para este hardware, así que varios formatos fueron desarrollados para obtener un rendimiento mayor de este hardware que el podía extraerse del limitado y simple formato a.out. Así fué cómo COFF, ECOFF y algunos otros formatos más extraños fueron inventados y sus limitaciones exploradas hasta que se fué llegando a la elección de ELF.
Además, el tamaño de los programas estaba volviendose gigante y los discos (y la memoria física) eran relativamente pequeños, así que el concepto de una biblioteca compartida nació. El sistema VM también se volvió más sofisticado. A pesar de que todos estos avances se hicieron utilizando el formato a.out, su utilidad se iba reduciendo paulatinamente con cada nueva opción. Además, la gente quería cargar cosas dinámicamente en el momento de ejecución, o descartar partes de su programa después de que el código de inicio se ejecutara para ahorrar memoria principal y espacio de swap. Al volverse más sofisticados los lenguajes, la gente empezó a ver la necesidad de introducir código antes del inicio del programa de forma automática. Se hicieron muchos hacks al formato a.out para permitir que todas estas cosas sucedieran y lo cierto es que por un tiempo funcionaron. Pero a.out no estaba para solucionar todos estos problemas sin incrementar la carga y complejidad del código. Aunque ELF resolvía muchos de estos problemas, en ese momento hubiera sido terrible dejar de lado un sistema que funcionaba, así que ELF tuvo que esperar hasta que fué más doloroso permanecer con a.out que migrar a ELF.
De todas maneras, con el paso del tiempo las herramientas de compilación de las que FreeBSD derivó las suyas (en especial el ensamblador y el cargador) evolucionaron en dos árboles paralelos. El árbol FreeBSD FreeBSD añadió bibliotecas compartidas y corrigió algunos errores. La gente de GNU (que fueron quienes escribieron estos programas) los reescribió y añadieron una forma más simple de disponer de compiladores cruzados («cross compilers»), el uso de diferentes formatos, etc. Aunque mucha gente quería compiladores cruzados con FreeBSD como «blanco» no hubo suerte, porque los fuentes que que FreeBSD tenía para as y ld no estaban listos para cumplir esa tarea. La nueva cadena de herramientas GNU (binutils) soporta compilación cruzada, ELF, bibliotecas compartidas, extensiones C++, etc. Además, muchos proveedores están liberando binarios ELF y es algo muy bueno que FreeBSD los pueda ejecutar.
ELF es más expresivo que a.out y permite un sistema base más extensible. Las herramientas ELF están mejor mantenidas y ofrecen soporte de compilación cruzada, muy importante para mucha gente. ELF puede ser un poco más lento que a.out, pero tratar de medirlo puede ser difícil. También existen numerosos detalles que son diferentes entre los dos en cómo gestionan páginas, cómo gestionan código de inicio, etc. Ninguna es muy importante, pero las diferencias existen. Con el tiempo, el soporte para a.out será eliminado del kernel GENERIC y es muy posible que se elimine del kernel la posibilidad de ejecutar tales binarios una vez que la necesidad de usar programas a.out haya pasado.
3.13. Más información
3.13.1. Páginas de manual
La documentación más exhaustiva de FreeBSD está en las páginas de manual. Casi todos los programas del sistema vienen con un breve manual de referencia explicando el funcionamiento básico y sus diferentes argumentos. Estos manuales pueden revisarse mediante man. El uso de man es simple:
% man ordenorden es el nombre de la orden sobre la que que desea saber más. Por ejemplo, para más información sobre ls escriba:
% man lsEl manual en línea está dividido en secciones numeradas:
Comandos de usuario.
Llamadas al sistema y números de error.
Funciones en las bibliotecas de C.
Controladores de dispositivo.
Formatos de fichero.
Juegos y demás pasatiempos.
Información sobre temas diversos.
Comandos relacionados con el mantenimiento del sistema y su funcionamiento.
Desarrolladores del Kernel.
En algunos casos, el mismo tema puede aparecer en más de una sección del manual en línea. Por ejemplo, existe una orden de usuario chmod y una llamada del sistema chmod(). En este caso se le puede decir a man cuál desea consultar especificando la sección:
% man 1 chmodEsto desplegará la página de manual de la orden de usuario chmod. Las referencias a una sección concreta del manual en línea tradicionalmente suelen colocarse entre paréntesis en la documentación escrita, por lo tanto chmod(1) se refiere a la orden de usuario chmod y chmod(2) se refiere a la llamada de sistema.
Esto está muy bien si se conoce el nombre del programa y simplemente se quiere saber como usarlo. Pero ?y si no puede recordar el nombre de la orden? Se puede usar man para que realice una búsqueda mediante palabras clave en las descripciones de programas utilizando el argumento -k:
% man -k mailDicha orden mostrará una lista de órdenes que contengan la palabra clave «mail» en sus descripciones. Esto es funcionalmente equivalente a usar apropos.
Así que, ¿está viendo todos esos programas tan atractivos en /usr/bin pero no tiene ni la menor idea de lo que la mayoría de ellos hace? Haga lo siguiente:
% cd /usr/bin
% man -f *o
% cd /usr/bin
% whatis *que hace exactamente lo mismo.
3.13.2. Ficheros de información GNU: info
FreeBSD incluye muchas aplicaciones y utilidades producidas por la FSF (Free Software Foundation). Además de con las correspondientes páginas de manual, estos programas vienen con documentos de hipertexto más detallados, llamados ficheros info, los cuales pueden ser visualizados con info, o si tiene instalado emacs, con el modo info de emacs.
Si quiere utilizar la orden info(1) teclée:
% infoPara una breve introducción teclée h. Cuando necesite una referencia rápida, teclée ?.
Last modified on: 18 de febrero de 2025 by Fernando Apesteguía