
foobar:R9DT/Fa1/LV9U:1000:1000::0:0:Foo Bar:/home/foobar:/usr/local/bin/tcsh
Capítulo 14. Seguridad
This translation may be out of date. To help with the translations please access the FreeBSD translations instance.
Tabla de contenidos
14.1. Sinopsis
Este capítulo contiene una introducción básica a los conceptos de seguridad del sistema, unas cuantas normas básicas de uso y algunos avanzados del tema en FreeBSD. Muchos de los temas expuestos se aplican a la seguridad del sistema y de Internet en general. Internet ya no es aquél lugar "amistoso" en el que todo el mundo se comportaba como un buen ciudadano. Si quiere proteger sus datos, su propiedad intelectual, su tiempo y muchas más cosas de manos malintencionadas debe hacer que su sistema sea seguro.
FreeBSD proporciona un variado arsenal de utilidades y mecanismos para asegurar la integridad y la seguridad de su sistema y red.
Después de leer este capítulo:
conocerá conceptos básicos de la seguridad relacionados con FreeBSD.
Tendrá información sobre los diversos mecanismos de cifrado disponibles en FreeBSD, entre los cuales están DES y MD5.
Sabrá cómo configurar la autentificación de contraseñas de un solo uso.
Sabrá cómo configurar TCP Wrappers y usarlos con
inetd.Sabrá cómo instalar KerberosIV en versiones de FreeBSD anteriores a 5.0.
Sabrá cómo instalar Kerberos5 en versiones de FreeBSD posteriores a 5.0.
Podrá configurar IPsec y crear una VPN entre máquinas FreeBSD/Windows®.
Sabrá cómo configurar y utilizar OpenSSH, la implementación de SSH en FreeBSD.
Sabrá en qué consisten las ACL del sistema de ficheros y cómo utilizarlas.
Sabrá cómo usar Portaudit, con la que podrá auditar el software que instale desde la desde la colección de ports.
Sabrá cómo sacar partido de los avisos de seguridad que publica FreeBSD.
Podrá hacerse una idea clara de en qué consiste la contabilidad de procesos y de cómo activarla en FreeBSD.
Antes de leer este capítulo:
Comprender conceptos básicos de FreeBSD e Internet.
En otras secciones de este manual se cubren aspectos adicionales sobre seguridad. Por ejemplo, MAC (controles de acceso obligatorio) se explica en el Mandatory Access Control y los cortafuegos en el Cortafuegos.
14.2. Introducción
La seguridad es un trabajo que que comienza y termina en el administrador de sistema. Aunque que los sistemas multiusuario BSD UNIX® posean una seguridad inherente, el trabajo de construir y mantener mecanismos de seguridad adicionales para que los usuarios sean aún más "honestos" es probablemente una de las mayores tareas de la administración de sistemas. Los sistemas son tan seguros como uno los haga, y no hay que olvidar que los problemas de seguridad compiten con la comodidad a la que tendemos los humanos. Los sistemas UNIX® son capaces de ejecutar una gran cantidad de procesos simultáneamente, muchos de los cuales son servidores, lo que significa que las entidades externas pueden conectarse y "hablar" con ellos. Del mismo modo que las minicomputadoras de ayer se convirtieron en los sistemas de escritorio de hoy en día, la seguridad se va convirtiendo en un problemas más y más acuciante.
La seguridad bien entendida se implementa en capas, a la manera de una "cebolla". Básicamente lo que se hace es crear la mayor cantidad posible de capas de seguridad, para más tarde monitorizar el sistema en busca de intrusos. No es conveniente exagerar la seguridad, ya que interferiría con la detección, y la detección es uno de los aspectos más importantes de cualquier mecanismo de seguridad. Por ejemplo, no tiene mucho sentido activar la bandera schg (consulte chflags(1)) en cada binario del sistema, ya que aunque protegería en cierto modo los binarios, haría que cualquier cambio que pudiera realizar un atacante una vez dentro del sistema fuera más difícil de detectar o incluso hacerlo del todo imposible.
La seguridad del sistema depende también de estar preparados para distintos tipos de ataque, incluyendo intentos de "tirar" la máquina o dejarla en un estado inutilizable, pero que no impliquen intentos de comprometer el usuario root Los problemas de seguridad pueden dividirse en diferentes categorías:
Ataques de denegación de servicio (DoS).
Comprometer cuentas de usuarios.
Comprometer root a través de servidores accesibles.
Comprometer root desde cuentas de usuario.
Creación de puertas traseras ("Backdoors").
Un ataque de denegación de servicio es una acción que priva al sistema de los recursos requeridos para su funcionamiento normal. Generalmente, los ataques DoS son mecanismos de fuerza bruta que intentan "tumbar" el sistema o hacerlo inutilizable sobrecargando la capacidad de sus servidores o de la pila de red. Algunos ataques DoS intentan aprovechar errores en la pila de red para "tumbar" el sistema con un solo paquete. Estos últimos únicamente pueden solucionarse aplicando al kernel una actualización que subsane el error. Los ataques a servidores muchas veces pueden solucionarse configurando las opciones apropiadas para limitar la carga del sistema en condiciones adversas. Los ataques de fuerza bruta a redes son más complicados. Los ataques con paquetes enmascarados, por ejemplo, son casi imposibles de detener, a menos que desconecte el sistema de Internet. Puede ser que no "tiren" el sistema, pero saturarán la conexión a Internet.
Comprometer una cuenta de usuario es mucho más común que un ataque DoS. Muchos administradores de sistemas todavía ejecutan servidores estándar telnetd, rlogind, rshd y ftpd en sus máquinas. Estos servidores, por defecto no operan a través de conexiones cifradas. El resultado es que se si se tiene una base de usuarios de tamaño medio, tarde o temprando la contraseña de uno (o más) de sus usuarios será descubierta durante sus accesos al sistema desde ubicaciones remotas.(que es, por otra parte, la forma más común y más cómoda de acceder a un sistema). El administrador de sistemas atento analizará sus logs de acceso remoto en busca de direcciones origen spspechosas, incluso entre los accesos al sistema.
Se debe asumir siempre que, una vez que el atacante tiene acceso a una cuenta de usuario, el atacante puede comprometer la cuenta root. En realidad en un sistema bien mantenido y asegurado el acceso a una cuenta de usuario no necesariamente da al atacante acceso a root. Esta precisión es importante porque sin acceso a root el atacante difícilmente podrá esconder sus huellas; podrá, como mucho, hacer poco más que sembrar el caos en los ficheros del usuario o "tirar" la máquina. Comprometer cuentas de usuario es muy común porque los usuarios tienden a no tomar las precauciones que toma el administrador.
Los administradores de sistemas deben tener presente que existen muchas formas potenciales de comprometer la cuenta root de una máquina. El atacante puede conocer la contraseña de root, el atacante puede encontrar un error en un servidor que se ejecuta como root y ser capaz de comprometer root a través de una conexión de red a ese servidor; puede ser que el atacante sepa de la existencia de un error en un programa suid-root que le permita comprometer root una vez dentro de una cuenta de usuario. Si un atacante encuentra la manera de comprometer la cuenta root de una máquina puede que no necesite instalar una puerta trasera. Muchos de los agujeros root encontrados y cerrados hasta la fecha implican una cantidad considerable de trabajo para el atacante limpiando todo después del ataque, así que la mayoría de los atacantes instalan puertas traseras. Una puerta trasera facilita al atacante una forma sencilla de recuperar el acceso de root al sistema, pero también proporciona al administrador de sistemas inteligente una forma de detectar la intrusión. Si hace imposible a un atacante la instalación de una puerta trasera puede estar actuando en detrimento de su seguridad, porque no cerrará el agujero que el atacante encontró para accder al sistema la primera vez que lo hizo.
Las medidas de seguridad se implementan en un modelo multicapa (tipo "cebolla"), que puede categorizarse del siguiente modo:
Asegurar
rooty cuentas administrativas.Asegurar los servidores que se ejecuten como
rootlos binarios suid/sgid.Asegurar cuentas de usuario.
Asegurar el fichero de contraseñas.
Asegurar el núcleo del kernel, los dispositivos en bruto y el sistema de ficheros.
Detección rápida de cambios hechos al sistema.
Paranoia.
La siguiente sección de este capítulo tratará los puntos de arriba con mayor profundidad.
14.3. Asegurar FreeBSD
Orden vs. protocolo En este capítulo usaremos el texto en negrita para referirnos a una orden o aplicación, y una fuente en |
Las siguientes secciones cubren los métodos a seguir para asegurar su sistema FreeBSD que se mencionados en la sección anterior de este capítulo.
14.3.1. Asegurar la cuenta root y las cuentas administrativas
En primer lugar, no se moleste en asegurar las cuentas administrativas (o "staff") si no ha asegurado la cuenta root. La mayoría de los sistemas tienen una contraseña asignada para la cuenta root. Lo primero que se hace es asumir que la contraseña está siempre amenazada. Esto no significa que deba eliminar la contraseña. La contraseña es casi siempre necesaria para el acceso por consola a la máquina; significa que no se debe permitir el uso de la contraseña fuera de la consola o, mejor aún, mediante su(1). Por ejemplo, asegúrese de que sus ptys aparezcan como inseguras en el fichero /etc/ttys, con lo que hará que los accesos como root vía telnet o rlogin no sean posibles. Si utiliza otros tipos de login como sshd asegúrese de que los accesos al sistema como root estén también deshabilitados. Para ello edite su /etc/ssh/sshd_config y asegúrese de que PermitRootLogin esté puesto a NO. Estudie cada método de acceso: hay servicios como FTP que frecuentemente son origen de grietas en la estructura del sistema. El acceso directo como usuario root sólamente debe permitirse a través de la consola.
Es evidente que, como administrador del sistema, debe usted tener la posibilidad de acceder a root, así que tendrá que abrir algunos agujeros, pero debe asegurarse de que estos agujeros necesiten contraseñas adicionales para verificar su correcto uso. Puede hacer que root sea accesible añadiendo cuentas administrativas al grupo wheel (en /etc/group). El personal que administra los sistemas que aparezcan en el grupo en el grupo wheel pueden hacer su a root. Nunca debe de proporcionar al personal administrativo el acceso nativo a wheel poniéndolos en el grupo wheel en su entrada de contraseña. Las cuentas administrativas deben colocarse en un grupo staff, y agregarse después al grupo wheel en /etc/group. Sólo aquellos administradores que realmente necesiten acceder a root deben pertenecer al grupo wheel. También es posible, mediante un método de autentificación como Kerberos, usar el fichero .k5login en la cuenta root para permitir un ksu(1) a root sin tener que colocar a nadie en el grupo wheel. Puede ser una mejor solución, ya que el mecanismo wheel aún permite a un atacante comprometer root si el intruso ha conseguido el fichero de contraseñas y puede comprometer una cuenta de administración. Recurrir al mecanismo wheel es mejor que no tener nada, pero no es necesariamente la opción más segura.
Una manera indirecta de asegurar las cuentas de staff y el acceso a root es utilizar un método de acceso alternativo: es lo que se conoce como "estrellar" las contraseñas cifradas de las cuentas administrativas. Use vipw(8) para reemplazar cada contraseña cifrada por un sólo caracter asterisco (“*”). Esto actualizará /etc/master.passwd y la base de datos de usuario/contraseña y deshabilitará los accesos al sistema validados mediante contraseñas.
Veamos una cuenta administrativa típica:
y cómo debería quedar:
foobar:*:1000:1000::0:0:Foo Bar:/home/foobar:/usr/local/bin/tcsh
Este cambio evitará que se efectúen logins normales, ya que la contraseña cifrada nunca se corresponderá con “*”. Hecho esto, el personal de administración tendrá que usar otro mecanismo de validación como kerberos(1) o ssh(1) que use un par de llave pública/privada. Si decide usar algo como Kerberos tendrá que asegurar la máquina que ejecuta los servidores Kerberos y su estación de trabajo. Si usa un par de llave pública/privada con ssh, debe asegurar la máquina desde desde la que se hace el login (normalmente nuestra estación de trabajo). Puede añadir una capa adicional de protección al par de llaves protegiéndolas con contraseña al crearlo con ssh-keygen(1). El "estrellado" de las contraseñas administrativas también garantiza que dicho personal sólo pueda entrar a través de métodos de acceso que haya usted configurado. Así obligará al personal administrativo a usar conexiones seguras, cifradas, en todas sus sesiones, lo que cierra un importante agujero de seguridad al que recurren muchos intrusos: usar un sniffer (olfateador) de red desde una máquina que le permita hacer tal cosa.
Los mecanismos de seguridad más indirectos también asumen que está validando su identidad desde un servidor más restrictivo un servidor menos restrictivo. Por ejemplo, si su máquina principal ejecuta toda clase de servidores su estación de trabajo no debe ejecutar ninguno. Para que su estación de trabajo sea razonablemente segura debe ejecutar los mínimos servidores posibles, si es posible ninguno, y debe usar un salvapantallas protegido por contraseña. Es evidente que un atancante con acceso físico al sistema puede romper cualquier barrera de seguridad que se disponga. Es un problema a tener en cuenta, pero la mayoría de las intrusiones tienen lugar de forma remota, a través de la red, por parte de gente que no tiene acceso físico a su estación de trabajo ni a sus servidores.
Usar Kerberos le ofrece también el poder de deshabilitar o cambiar la contraseña para una cuenta administrativa en un lugar, y que tenga un efecto inmediato en todas las máquinas en las cuales ese administrador pueda tener una cuenta. Si una de esas cuentas se ve comprometida la posibilidad para cambiar instantáneamente su contraseña en todas las máquinas no debe ser desestimada. Con contraseñas distintas, el cambio de una contraseña en N máquinas puede ser un problema. También puede imponer restricciones de re-contraseñas con Kerberos: no sólo se puede hacer un ticket de Kerberos que expire después de un tiempo, sino que el sistema Kerberos puede requerir al usuario que escoja una nueva contraseña después de cierto tiempo (digamos una vez al mes).
14.3.2. Asegurar servidores que se ejecutan como root y binarios SUID/SGID
Un administrador de sistemas prudente sólo ejecutará los servidores que necesita, ni uno más ni uno menos. Dese cuenta de que los servidores ajenos son los más propensos a contener errores. Por ejemplo, ejecutando una versión desfasada de imapd o popper es como dar una entrada universal de root al mundo entero. Nunca ejecute un servidor que no haya revisado cuidadosamente. Muchos servidores no necesitan ejecutarse como root. Por ejemplo, los dæmons ntalk, comsat y finger pueden ejecutarse en una caja de arena (sandbox) especial de usuario. Una caja de arena no es perfecta, a menos que pase por muchos problemas, pero la aproximación de cebolla a la seguridad prevalece aún y todo: Si alguien es capaz de penetrar a través de un servidor ejecutándose en una caja de arena, todavía tendrá que salir de la caja de arena. Cuantas más capas tenga que romper el atacante menor será la posibilidad de éxito que tenga. Se han encontrado vías de entrada a root en virtualmente todos los servidores que se haya ejecutado como root, incluyendo servidores básicos del sistema. Si está tiene una máquina a través de la cual la gente sólo entra por sshd, y nunca entra por telnetd, rshd, o rlogind apague esos servicios.
FreeBSD ejecuta por defecto ntalkd, comsat y finger en una caja de arena. Otro programa que puede ser candidato para ejecutarse en una caja de arena es named(8). /etc/defaults/rc.conf contiene las directrices necesarias (con comentarios) para usar named en una caja de arena. Dependiendo de si está instalando un nuevo sistema o actualizando un sistema ya existente, las cuentas especiales de usuario que usan estas cajas de arena puede que no estén instaladas. El administrador de sistemas prudente debe investigar e implementar cajas de arena para servidores siempre que sea posible.
Existen numerosos servidores que no se suelen ejecutar en cajas de arena: sendmail, imapd, ftpd, y otros. Existen alternativas para algunos de ellos, pero instalarlas puede requerir más trabajo del que tal vez esté dispuesto a realizar (el factor comodidad ataca de nuevo). Tal vez tenga que ejecutar estos servidores como root y depender de otros mecanismos para detectar intrusiones que puedan tener lugar a través de ellos.
Los otros grandes agujeros potenciales de root que encontramos en un sistema son los binarios suid-root y sgid. La mayoría de estos binarios, como rlogin, están en /bin, /sbin, /usr/bin o /usr/sbin. Aunque no hay nada absolutamente seguro los binarios suid y sgid del sistema por defecto pueden considerarse razonablemente seguros. Aún así, de vez en cuando aparecen agujeros root en estos binarios. En 1998 se encontró un agujero root en Xlib, que hacía a xterm (que suele ser suid) vulnerable. Es mejor prevenir que curar, y el administrador de sistemas prudente restringirá los binarios suid, que sólo el personal de administración debe ejecutar, a un grupo especial al que sólo dicho personal pueda acceder, y deshacerse de cualquier binario suid (chmod 000) que no se use. Un servidor sin pantalla generalmente no necesita un binario xterm. Los binarios sgid pueden ser igual de peligrosos. Si un intruso logra comprometer un binario sgid-kmem, el intruso podría leer /dev/kmem y llegar a leer el fichero cifrado de contraseñas, poniendo en compromiso potencial cualquier cuenta con contraseña. Por otra parte, un intruso que comprometa el grupo kmem puede monitorizar las pulsaciones de teclado que se envien a través de ptys, incluyendo las ptys a las que acceden usuarios que emplean métodos seguros. Un intruso que comprometa el grupo tty puede escribir en la pty de casi cualquier usuario. Si un usuario ejecuta un programa de terminal o un emulador capaz de simular un teclado, el intruso podría generar un flujo de datos que provoque que la terminal del usuario muestre una orden en pantalla, orden que el usuario ejecutará.
14.3.3. Asegurar las cuentas de usuario
Las cuentas de usuario suelen ser las más difíciles de asegurar. Aunque puede imponer restricciones de acceso draconianas a su personal administrativo y "estrellar" sus contraseñas, tal vez no pueda hacerlo con todas las cuentas de todos sus usuarios. Si mantiene el control en un grado suficiente quizás lo logre y sea capaz de hacer que las cuentas de sus usuarios sean seguras. Si no, tendrá que ser más cuidadoso (aún) en la monitorización de esas cuentas. Usar ssh y Kerberos en cuentas de usuario da más problemas debido al soporte técnico y administrativo que requerirá, pero sigue siendo mejor solución que un fichero de contraseñas cifradas.
14.3.4. Asegurar el fichero de contraseñas
La única manera segura es ponerle * a tantas contraseñas como sea posible y utilizar ssh o Kerberos para acceder a esas cuentas. Aunque el fichero cifrado de contraseñas (/etc/spwd.db) sólo puede ser legible para root, puede que un intruso consiga acceso de lectura a ese fichero, incluso sin haber alcanzado el acceso de escritura como root.
Sus "scripts" de seguridad deben buscar siempre cambios en el fichero de contraseñas (consulte Revisión de integridad de ficheros más abajo) e informar de ellos.
14.3.5. Asegurar el Kernel, dispositivos en bruto y el sistema sistema de ficheros
Si un atacante compromete root puede hacer cualquier cosa, pero hay ciertas cosas que puede usted preparar para "curarse en salud". Por ejemplo, la mayoría de los kernel modernos tienen un dispositivo de los Kernels modernos tienen un integrado un dispositivo de paquetes. En FreeBSD se llama bpf. Un intruso típico tratará de ejecutar un "sniffer" de paquetes en una máquina comprometida. No debería darle a ese intruso tal recurso, y la mayoría de los sistemas no necesitan el dispositivo bpf.
Pero si desactiva el dispositivo bpf todavía tendrá que preocuparse por /dev/mem y /dev/kmem. Desde ellos el intruso podría en dispositivos de disco en bruto. También hay que tener muy en cuenta una opción del kernel llamada cargador de módulos, kldload(8). Un intruso con iniciativa puede usar un módulo KLD para instalar su propio dispositivo bpf, u otro dispositivo que le permita el "sniffing" en un kernel en ejecución. Para prevenir estos problemas debe ejecutar el kernel en un nivel de seguridad mayor, al menos en securelevel 1. Puede configurar el securelevel mediante una sysctl en la variable kern.securelevel. Una vez que tiene su securelevel a 1, los accesos de escritura a dispositivos en bruto se denegarán y se impondrán las banderas especiales schg. También debe cerciorarse de activar la bandera schg en binarios críticos para el arranque, directorios y scripts (dicho de otro modo, todo aquello que se ejecuta antes de que se active el securelevel). Puede ser que todo esto sea una exageración, sobre todo teniendo en cuenta que la actualización del sistema se complica bastante a medida que se incrementa el nivel de seguridad. Puede ejecutar el sistema a un nivel de seguridad superior pero no activar la bandera schg en cada fichero y directorio del sistema. Otra posibilidad es montar / y /usr como sólo lectura. Recuerde que siendo demasiado draconiano en aquello que busca proteger puede dificultar mucho la detección de una intrusión.
14.3.6. Revisión de integridad de ficheros: binarios, ficheros de configuración, etc.
Cuando se piensa de proteccón, sólo se puede proteger la configuración central del sistema y los ficheros de control hasta el momento en el que el factor comodidad salta a la palestra. Por ejemplo, si usa chflags para activar el bit schg en la mayoría de los ficheros de / y /usr probablemente sea contraproducente; puede proteger los ficheros haciéndolo, pero también cierra una vía de detección. La última capa de su modelo de seguridad tipo cebolla es quizás la más importante: la detección. El resto de su estructura de seguridad será inútil (o peor aún, le proporcionará un sentimiento de seguridad totalmente infundado) si no puede detectar posibles intrusiones. La mitad del trabajo de la cebolla es alentar al atacante, en lugar de detenerlo, para darle a la parte de la ecuación de detección una oportunidad de atraparlo con las manos en la masa.
La mejor manera de detectar una intrusión es buscar ficheros modificados, perdidos, o cuya presencia o estado sea inesperado. La mejor forma de buscar ficheros modificados es desde otro sistema (que muchas veces es centralizado) con acceso restringido. Escribir sus "scripts" de seguridad en un sistema "extraseguro" y con acceso restringido los hace casi invisibles a posibles atacantes, y esto es algo muy importante. potenciales, y esto es importante. Para poderle sacar el máximo partido debe proporcionar a esa máquina con acceso restringido un acceso preferente al contenido de las otras máquinas de su entorno; suele hacerse mediante la importación vía NFS de sólo lectura de las demás máquinas, o configurando pares de llaves ssh para acceder a las otras máquinas desde la que tiene el acceso restringido. Si exceptuamos el tráfico de red, NFS es el método menos visible y le permite monitorizar los sistemas de ficheros de cada máquina cliente de forma prácticamente indetectable. Si su servidor de acceso restringido está conectado a las máquinas clientes a través de un concentrador o a través de varias capas de encaminamiento el método NFS puede ser muy inseguro, por lo que ssh puede ser la mejor opción, incluso con las huellas de auditoría que ssh va dejando.
Una vez que le da a una máquina de acceso restringido (al menos) acceso de lectura a los sistemas cliente que va a monitorizar, tendrá que escribir "scripts" para efectuar la monitorización. Si va a usar un montaje NFS puede escribir "scripts" utilizando simples herramientas del sistema como find(1) y md5(1). Es aconsejable ejecutar MD5 físicamente en los ficheros de las máquinas cliente al menos una vez al día, y comprobar los ficheros de control (los que hay en /etc y /usr/local/etc) con una frecuencia incluso mayor. Si aparecen discrepancias al compararlos con la información basada en MD5 que la máquina de acceso restringido usa como base debe hacer una comprobación inmediata y profunda. Un buen "script" también debe buscar binarios que sean suid sin razón aparente, y ficheros nuevos o borrados en particiones del sistema como / y /usr.
Si usa ssh en lugar de NFS será mucho más complicado escribir el "script" de seguridad. En esencia, tiene que pasar por scp los "scripts" a la máquina cliente para poder ejecutarlos, haciéndolos visibles; por seguridad, también tendrá que pasar vía scp los binarios (por ejemplo find) que utilizan dichos "scripts". El cliente ssh de la máquina cliente puede estar ya bajo el control del intruso. Con todo y con eso, puede ser necesario usar ssh si trabaja sobre enlaces inseguros, también es mucho más difícil de manejar.
Un buen "script" de seguridad buscará también cambios en la configuración de los ficheros de acceso de usuarios y miembros del personal de administración: .rhosts, .shosts, .ssh/authorized_keys, etc; en resumen, ficheros fuera del rango de revisión MD5.
Si tiene que vérselas con una cantidad enorme de espacio en disco para usuarios le llevará mucho tiempo recorrer cada fichero de cada partición. En su caso sería una buena idea configurar mediante opciones de montaje la deshabilitación de binarios y dispositivos suid en esas particiones. Revise las opciones nodev y nosuid de mount(8). Debería comprobarlos de todas maneras al menos una vez por semana, ya que el objeto de esta capa es detectar intrusiones, efectivas o no.
La contabilidad de procesos (vea accton(8)) es una opción con una carga relativamente ligera para el sistema operativo, y puede ayudarle como mecanismo de evaluación tras una intrusión. Es especialmente útil para rastrear cómo consiguión realmente acceder el intruso al sistema (asumiendo que el fichero esté intacto después de la intrusión).
Los "scripts" de seguridad deben procesar los logs, y los propios logs deben generarse de la forma más segura posible: un syslog remoto puede ser muy útil. Un intruso trata de cubrir sus huellas, los logs son un recurso crítico cuando el administrador de sistemas intenta determinar la hora y el método de la intrusión inicial. La ejecución de la consola del sistema en un puerto serie y recolectar la información de forma periódica en una máquina segura de monitorización de consolas es una forma de cumplir esta tarea.
14.3.7. Paranoia
Un poco de paranoia nunca está de más. Como norma, un administrador de sistemas puede añadir cualquier tipo de mecanismo de seguridad siempre y cuando no afecte a la comodidad, y puede añadir mecanismos de seguridad que sí afecten a la comodidad si tiene una buena razón para hacerlo. Más aún, un administrador de seguridad debe mezclar un poco de ambas cosas: si sigue al pie de la letra las recomendaciones que se dan en este documento también está sirviendo en bandeja de plata al posible atancante su metodología. Ese posible atacante también tiene acceso a este documento.
14.3.8. Ataques de denegación de servicio
Esta sección cubre ataques de denegación de servicio. Un ataque DoS suele consistir en un ataque mediante paquetes. NO hay mucho que pueda hacerse contra un ataque mediante paquetes falsificados ("spoofed") que busque saturar su red, pero puede limitar el daño asegurándose de que los ataques no tiren sus servidores.
Limitación de forks en el servidor.
Limitación de ataques "springboard" (ataques de respuesta ICMP, ping broadcast, etc.)
Caché de rutas del kernel.
Un típico ataque DoS contra un servidor con instancias (forks) sería tratar de provocar que el servidor consuma procesos, descriptores de fichero y memoria hasta tirar la máquina. inetd (consulte inetd(8)) dispone de varias opciones para limitar este tipo de ataque. Recuerde que aunque es posible evitar que una máquina caiga, generalmente no es posible evitar que un servicio sea vea interrumpido a causa el ataque. Consulte la página de manual de inetd atentamente y sobre todo estudie las las opciones -c, -C, y -R. Observe que los ataques con direcciones IP falsificadas sortearán la opción -C de inetd, así que debe usar una combinación de opciones. Algunos servidores autónomos ("standalone") cuentan con parámetros de autolimitación de instancias.
Sendmail tiene la opción -OMaxDaemonChildren, que tiende a funcionar mucho mejor que las opciones de límite de carga de sendmail debido al retraso que provoca la carga. Debe especificar un parámetro MaxDaemonChildren al inicio de sendmail que sea lo suficientemente alto como para gestionar la carga esperada, pero no tan alto que la computadora no pueda absorber tal número de sendmails sin caerse de boca. También es prudente ejecutar sendmail en modo de cola (-ODeliveryMode=queued) y ejecutar el dæmon (sendmail -bd) de manera independiente de las ejecuciones de cola (sendmail -q15m). Si a pesar de todo necesita entregas en tiempo real puede ejecutar la cola a un intervalo menor, como -q1m, pero asegúrese de especificar una opción MaxDaemonChildren razonable para ese sendmail y así evitar fallos en cascada.
Syslogd puede recibir ataques directos y se recomienda encarecidamente que utilice la opción -s siempre que sea posible, y si no la opción -a.
También debe ser extremadamente cuidadoso con servicios de conexión inversa como el ident inverso de TCP Wrapper, que puede recibir ataques directos. No se suele usar el ident inverso de TCP Wrapper por esa misma razón.
Es una muy buena idea proteger los servicios internos de acceso externo protegiéndolos vía con un cortafuegos en los routers de frontera. La idea es prevenir ataques de saturación desde el exterior de la LAN, y no tanto para proteger servicios internos de compromisos root basados en red. Configure siempre un cortafuegos exclusivo, esto es, "restringir todo menos los puertos A, B, C, D y M-Z". De esta manera restringirá todos sus puertos con números bajos excepto ciertos servicios específicos como named (si es el servidor primario de una zona), ntalkd, sendmail, y otros servicios accesibles desde Internet. Si configura el cortafuegos de la otra manera (como un cortafuegos inclusivo o permisivo), tiene grandes posibilidades de que olvide "cerrar" un par de servicios, o de que agregue un nuevo servicio interno y olvide actualizar el cortafuegos. Puede incluso abrir el rango de números de puerto altos en el cortafuegos para permitir operaciones de tipo permisivo sin comprometer sus puertos bajos. Recuerde también que FreeBSD le permite controlar el rango de números de puerto utilizados para asignación dinámica a través de las numerosas net.inet.ip.portrange de sysctl (sysctl -a | fgrep portrange), lo cual también facilita la complejidad de la configuración de su cortafuegos. Por ejemplo, puede utilizar un rango normal primero/último de 4000 ó 5000, y un rango de puerto alto de 49152 a 65535; bloquée todo por debajo de 4000 (excepto para ciertos puertos específicos accesibles desde Internet, por supuesto).
Otro ataque DoS común es llamado ataque "springboard": atacar un servidor de forma que genere respuestas que lo sobrecarguen, sobrecarguen la red local o alguna otra máquina. Los ataques más comunes de este tipo son los ataques ICMP ping broadcast. El atacante falsifica paquetes ping enviados a la dirección broadcast de su LAN simulando que la dirección IP origen es la de la máquina que desean atacar. Si sus routers de frontera no están configurados para lidiar con pings a direcciones de broadcast su LAN termina generando suficientes respuestas a la dirección origen falsificada como para saturar a la víctima, especialmente cuando el atacante utiliza el mismo truco en varias docenas de direcciones broadcast en varias docenas de redes diferentes a la vez. Se han medido ataques de broadcast de más de ciento veinte megabits. Un segundo tipo de ataque "springboard" bastante común se da contra el sistema de informe de error de ICMP. Un atacante puede saturar la conexión entrante de red de un servidor mediante la construcción de paquetes que generen respuestas de error ICMP, provocando que el servidor sature su conexión saliente de red con respuestas ICMP. Este tipo de ataque también puede tumbar el servidor agotando sus "mbufs", especialmente si el servidor no puede drenar lo suficientemente rápido las respuestas ICMP que genera. El kernel de FreeBSD tiene una opción de compilación llamada ICMP_BANDLIM, que limita la efectividad de este tipo de ataques. La última gran categoría de ataques "springboard" está relacionada con ciertos servicios de inetd, como el servicio de eco udp. El atacante simplemente imita un paquete UDP con el puerdo de eco del servidor A como dirección de origen, y el puerto eco del servidor B como dirección de destino, estando ambos servidores en la misma LAN. Un atacante puede sobrecargar ambos servidores y la propia LAN inyectando simplemente un par de paquetes. Existen problemas similares con el puerto chargen. Un administrador de sistemas competente apagará todos estos servicios internos de verificación de inetd.
Los ataques con paquetes falsificados pueden utilizarse también para sobrecargar la caché de rutas del kernel. Consulte los parámetros de sysctl net.inet.ip.rtexpire, rtminexpire, y rtmaxcache. Un ataque de paquetes falsificados que utiliza una dirección IP origen aleatoria provocará que el kernel genere una ruta temporal en caché en su tabla de rutas, visible con netstat -rna | fgrep W3. Estas rutas suelen expiran en 1600 segundos más o menos. Si el kernel detecta que la tabla de rutas en caché es ya demasiado grande reducirá dinámicamente rtexpire, pero nunca la reducirá a un valor que sea menor que rtminexpire. Esto nos presenta dos problemas:
El kernel no reacciona con suficiente rapidez cuando un servidor ligeramente cargado es atacado.
El
rtminexpireno es lo suficientemente bajo para que el kernel sobreviva a un ataque sostenido.
Si sus servidores están conectados a Internet mediante mediante una línea T3 o superior puede ser prudente corregir manualmente rtexpire y rtminexpire por medio de sysctl(8). Nunca ponga ambos parámetros a cero (a menos que desée estrellar la máquina). Configurar ambos parámetros a 2 segundos debería bastar para proteger de ataques la tabla de rutas.
14.3.9. Otros aspectos del acceso con Kerberos y SSH
Existen un par de detalles con respecto a Kerberos y ssh que debe analizar sy pretende usarlos. Kerberos V es un excelente protocolo de protocolo de autentificación, pero hay errores en la versión kerberizada de telnet y rlogin que las hacen inapropiadas para gestionar flujos binarios. Ademé Kerberos no cifra por defecto una sesión a menos que utilice la opción -x. ssh cifra todo por defecto.
ssh funciona bastante bien en todos los casos, con la sola salvedad de que por defecto reenvía llaves de cifrado. Esto significa que si usted tiene una estación de trabajo segura, que contiene llaves que le dan acceso al resto del sistema, y hace ssh a una máquina insegura, sus llaves se pueden utilizar. Las llaves en sí no se exponen, pero ssh crea un puerto de reenvío durante el login, y si un atacante ha comprometido el root de la máquina insegura, puede utilizar ese puerto para usar sus llaves y obtener acceso a cualquier otra máquina que sus llaves abran.
Le recomendamos que, siempre que sea posible, use ssh combinado con Kerberos en los login de su personal de administración. para logins de staff. Puede compilar ssh con soporte de Kerberos. Esto reducirá su dependencia de llaves ssh expuestas, al mismo tiempo que protege las contraseñas vía Kerberos. Las llaves ssh deben usarse sólamente para tareas automáticas desde máquinas seguras (algo que Kerberos no hace por incompatibilidad). Recomendamos también que desactive el reenvío de llaves en la configuración de ssh, o que use la opción from=IP/DOMAIN que ssh incluye en authorized_keys; así la llave sólo podrá ser utilizada por entidades que se validen desde máquinas específicas.
14.4. DES, MD5 y Crypt
Cada usuario de un sistema UNIX® tiene una contraseña asociada a su cuenta. Parece obvio que estas contraseñas sólo deben ser conocidas por el usuario y por el sistema operativo. Para que estas contraseñas permanezcan en secreto se cifran con lo que se conoce como un "hash de una pasada", esto es, sólo pueden ser fácilmente cifradas pero no descifradas. En otras palabras, lo que acabamos de decir es tan obvio que ni siguiera es verdad: el propio sistema operativo no sabe cuál es realmente la contraseña. Lo único que conoce es la versión cifrada de la contrasenña. La única manera de obtener la contraseña en "texto plano" es por medio de una búsqueda de fuerza bruta en el espacio de contraseñas posibles.
Por desgracia la única manera segura de cifrar contraseñas cuando UNIX® empezó a hacerlo estaba basada en DES, ("Data Encryption Standard", "estándar de cifrado de datos"). Esto no era un gran problema para usuarios residentes en los EEUU, pero el código fuente de FreeBSD no se podía exportar desde los EEUU, así que FreeBSD hubo de buscar una forma de complir las leyes de EEUU y al mismo tiempo mantener la compatibilidad con otras variantes de UNIX® que que todavía utilizaban DES.
La solución fué dividir las bibliotecas de cifrado para que los usuarios de EEUU pudieran instalar las bibliotecas DES pero los usuarios del resto del mundo tuvieran un método de cifrado que pudiera ser exportado. Así es como FreeBSD comenzó a usar MD5 como su método de cifrado por defecto. MD5 se considera más seguro que DES, así que se mantiene la opción de poder instalar DES por motivos de compatibilidad.
14.4.1. Cómo reconocer su mecanismo de cifrado
En versiones anteriores a FreeBSD 4.4 libcrypt.a era un enlace simbólico que apuntaba a la biblioteca que se usaba para el cifrado. En FreeBSD 4.4 se cambió libcrypt.a para ofrecer una biblioteca hash configurable de validación de contraseñas. Actualmente la biblioteca permite funciones hash DES, MD5 y Blowfish. FreeBSD utiliza por defecto MD5 para cifrar contraseñas.
Es muy sencillo identificar qué método usa FreeBSD para cifrar. Una forma es examinando las contraseñas cifradas en /etc/master.passwd. Las contraseñas cifradas con el hash MD5 son más largas que las cifradas con el hash DES, y también comienzan por los caracteres $1$. Las contraseñas que comienzan por $2a$ están cifradas con la función hash de Blowfish. Las contraseñas DES no tienen ninguna característica particular, pero son más cortas que las contraseñas MD5, y están codificadas en un alfabeto de 64 caracteres que no incluye el caracter $; es por esto que una cadena relativamente corta que comience con un signo de dólar es muy probablemente una contraseña DES.
El formato de contraseña a usar en nuevas contraseñas se define en /etc/login.conf mediante passwd_format, pudiendo tener los valores des, md5 o blf. Consulte la página de manual login.conf(5) para más información.
14.5. Contraseñas de un solo uso
S/Key es un esquema de contraseña de un solo uso basado en una función de hash de sentido único. FreeBSD utiliza el hash MD4 por compatibilidad, pero otros sistemas usan MD5 y DES-MAC. S/Key forma parte del sistema base de FreeBSD desde la versión 1.1.5 y se usa también en un número creciente de otros sistemas operativos. S/Key es una marca registrada de Bell Communications Research, Inc.
A partir de la versión 5.0 de FreeBSD S/Key fué reemplazado por su equivalente OPIE ("One-time Passwords In Everything", "Contraseñas de un solo uso para todo"). OPIE usa por defecto hash MD5.
En esta sección se explican tres tipos de contraseña. La primera es la típica contraseña al estilo UNIX® o Kerberos; las llamaremos "contraseñas UNIX®". El segundo tipo es la contraseña de un solo uso, que se genera con el programa key de S/Key o con opiekey(1) de OPIE, y que aceptan los programas keyinit, opiepasswd(1), y el prompt de login; llamaremos a esta una "contraseña de un solo uso". El último tipo de contraseña es la contraseña secreta que le da usted a los programas key/opiekey (y a veces keyinit/opiepasswd), que se usa para generar contraseñas de un solo uso; a estas las llamaremos "contraseñas secretas", o simplemente "contraseña".
La contraseña secreta no tiene nada que ver con su contraseña UNIX®; pueden ser la misma, pero no es recomendable. Las contraseñas secretas S/Key y OPIE no están limitadas a 8 caracteres como las contraseñas UNIX® antiguas, pueden ser tan largas como se quiera. Las contraseñas con frases de seis o siete palabras muy largas son bastante comunes. El funcionamiento del sistema S/Key o el OPIE es en gran parte completamente independiente del sistema de contraseñas UNIX®.
Además de la contraseña hay dos datos que son importantes para S/Key y OPIE. Uno es lo que se conoce como "semilla" o "llave", que consiste en dos letras y cinco dígitos. El otro dato importante se llama la "cuenta de iteración", que es un número entre 1 y 100. S/Key genera la contraseña de un solo uso concatenando la semilla y la contraseña secreta, aplica el hash MD4/MD5 tantas veces como especifique la cuenta de iteración y convierte el resultado en seis palabras cortas en inglés. Estas seis palabras en inglés son su contraseña de un solo uso. El sistema de autentificación (principalmente PAM) mantiene un registro del uso de contraseñas de un solo uso, y el usuario puede validarse si el hash de la contraseña que proporciona es igual a la contraseña previa. Como se utiliza un hash de sentido único es imposible generar futuras contraseñas de un solo uso si una contraseña que ya ha sido usada fuera capturada; la cuenta de iteración se reduce después de cada login correcto para sincronizar al usuario con el programa login. Cuanto la iteración llega a 1, S/Key y OPIE deben reinicializar.
Hay tres programas involucrados en cada uno de estos sistemas. Los programas key y opiekey aceptan una cuenta iterativa, una semilla y una contraseña secreta, y generan una contraseña de un solo uso o una lista consecutiva de contraseñas de un solo uso. Los programas keyinit y opiepasswd se usan respectivamente para inicializar S/Key y OPIE, y para cambiar contraseñas, cuentas iterativas o semillas; toman ya sea una frase secreta, o una cuenta iterativa y una contraseña de un solo uso. Los programas keyinfo y opieinfo examinan los ficheros de credenciales correspondientes (/etc/skeykeys o /etc/opiekeys) e imprimen la cuenta iterativa y semilla del usuario invocante.
Explicaremos cuatro tipos de operaciones diferentes. La primera es usar keyinit o opiepasswd a través de una conexión segura para configurar contraseñas de un solo uso por primera vez, o para cambiar su contraseña o semilla. La segunda operación es utilizar keyinit o opiepasswd a través de una conexión insegura, además de usar key u opiekey sobre una conexión segura para hacer lo mismo. La tercera es usar key/opiekey para conectarse a través de una conexión insegura. La cuarta es usar opiekey o key para generar numerosas llaves, que pueden ser escritas para llevarlas con usted al ir a algún lugar desde el que no se puedan hacer conexiones seguras a ningún sitio.
14.5.1. Inicialización de conexiones seguras
Para inicializar S/Key por primera vez cambie su contraseña, o cambie su semilla mientras está conectado a través de una conexión segura (esto es, en la consola de una máquina o vía ssh); use keyinit sin ningún parámetro:
% keyinit
Adding unfurl:
Reminder - Only use this method if you are directly connected.
If you are using telnet or rlogin exit with no password and use keyinit -s.
Enter secret password:
Again secret password:
ID unfurl s/key is 99 to17757
DEFY CLUB PRO NASH LACE SOFTEn OPIE se utiliza opiepasswd:
% opiepasswd -c
[grimreaper] ~ $ opiepasswd -f -c
Adding unfurl:
Only use this method from the console; NEVER from remote. If you are using
telnet, xterm, or a dial-in, type ^C now or exit with no password.
Then run opiepasswd without the -c parameter.
Using MD5 to compute responses.
Enter new secret pass phrase:
Again new secret pass phrase:
ID unfurl OTP key is 499 to4268
MOS MALL GOAT ARM AVID COEDEn Enter new secret pass phrase: o Enter secret password:, debe introducir una contraseña o frase. Recuerde que no es la contraseña que utilizará para entrar, se usará para generar sus llaves de un solo uso. La línea "ID" da los parámetros de su instancia en particular: su nombre de login, la cuenta iterativa y semilla. En el momento del login el sistema recordará estos parámetros y los presentará de nuevo para que no tenga que recordarlos. La última línea proporciona las contraseéas de un solo uso que corresponden a esos parámetros y su contraseña secreta; si fuera a hacer login de manera inmediata, debería usar esta contraseña de una sola vez.
14.5.2. Inicialización de conexiones inseguras
Para inicializar o cambiar su contraseña secreta a través de una conexión insegura, necesitará tener alguna conexión segura a algún lugar donde pueda ejecutar key u opiekey; puede ser gracias a un accesorio de escritorio o en una Macintosh®, o un prompt de shell en una máquina en la que confíe. Necesitará también una cuenta iterativa (100 probablemente sea un buen valor), y puede usar su propia semilla, o usar una generada aleatoriamente. Siguiendo con la conexión insegura (hacia la máquina que está inicializando), ejecute keyinit -s:
% keyinit -s
Updating unfurl:
Old key: to17758
Reminder you need the 6 English words from the key command.
Enter sequence count from 1 to 9999: 100
Enter new key [default to17759]:
s/key 100 to 17759
s/key access password:
s/key access password:CURE MIKE BANE HIM RACY GOREEn OPIE debe usar opiepasswd:
% opiepasswd
Updating unfurl:
You need the response from an OTP generator.
Old secret pass phrase:
otp-md5 498 to4268 ext
Response: GAME GAG WELT OUT DOWN CHAT
New secret pass phrase:
otp-md5 499 to4269
Response: LINE PAP MILK NELL BUOY TROY
ID mark OTP key is 499 gr4269
LINE PAP MILK NELL BUOY TROYPara aceptar la semilla por defecto (la que el programa keyinit llama key, "llave", para terminar de complicar las cosas), pulse Enter. Antes de introducir una una contraseña de acceso cambie a su conexión o accesorio de escritorio S/Key y dele el mismo parámetro:
% key 100 to17759
Reminder - Do not use this program while logged in via telnet or rlogin.
Enter secret password: <secret password>
CURE MIKE BANE HIM RACY GOREO para OPIE:
% opiekey 498 to4268
Using the MD5 algorithm to compute response.
Reminder: Don't use opiekey from telnet or dial-in sessions.
Enter secret pass phrase:
GAME GAG WELT OUT DOWN CHATVuelva a la conexión insegura y copie la contraseña de un solo uso generada al programa que quiera usar.
14.5.3. Generación una sola contraseña de un solo uso
Una vez que ha inicializado S/Key u OPIE, cuando haga login verá un "prompt" parecido al siguiente:
% telnet ejemplo.com
Trying 10.0.0.1...
Connected to ejemplo.com
Escape character is '^]'.
FreeBSD/i386 (ejemplo.com) (ttypa)
login: <username>
s/key 97 fw13894
Password:O, en el caso de OPIE:
% telnet ejemplo.com
Trying 10.0.0.1...
Connected to ejemplo.com
Escape character is '^]'.
FreeBSD/i386 (ejemplo.com) (ttypa)
login: <nombre_de_usuario>
otp-md5 498 gr4269 ext
Password:Como una nota aparte, el "prompt" de S/Key y OPIE cuenta con una opción útil (que no se muestra aquí): si pulsa Enter en el "prompt" de contraseña el "prompt" activará el eco para que pueda ver en pantalla lo que teclea. Esto puede ser extremadamente útil si está tecleando una contraseña a a mano o desde un la lista impresa.
Ahora necesitará generar su contraseña de un sólo uso para responder a este "prompt" de login. Debe hacerlo en un sistema digno de confianza y en el que pueda ejecutar key u opiekey. Existen versiones DOS, Windows® y también para Mac OS®. Ambos usarán la cuenta iterativa y la semilla como opciones de línea de órdenes. Puede cortarlas y pegarlas desde el "prompt" de login de la máquina en la que se está identificando.
En el sistema de confianza:
% key 97 fw13894
Reminder - Do not use this program while logged in via telnet or rlogin.
Enter secret password:
WELD LIP ACTS ENDS ME HAAGCon OPIE:
% opiekey 498 to4268
Using the MD5 algorithm to compute response.
Reminder: Don't use opiekey from telnet or dial-in sessions.
Enter secret pass phrase:
GAME GAG WELT OUT DOWN CHATAhora que tiene su contraseña de un solo uso puede proceder con el login:
login: <nombre_de_usuario>
s/key 97 fw13894
Password: <Enter para activar el eco>
s/key 97 fw13894
Password [echo on]: WELD LIP ACTS ENDS ME HAAG
Last login: Tue Mar 21 11:56:41 from 10.0.0.2 ...14.5.4. Generación de múltiples contraseñas de un solo uso
A veces usted hay que ir a lugares donde no hay acceso a una máquina de fiar o a una conexión segura. En estos casos, puede utilizar key y opiekey para generar previamente numerosas contraseñas de un solo uso para, una vez impresas, llevárselas a donde hagan falta. Por ejemplo:
% key -n 5 30 zz99999
Reminder - Do not use this program while logged in via telnet or rlogin.
Enter secret password: <secret password>
26: SODA RUDE LEA LIND BUDD SILT
27: JILT SPY DUTY GLOW COWL ROT
28: THEM OW COLA RUNT BONG SCOT
29: COT MASH BARR BRIM NAN FLAG
30: CAN KNEE CAST NAME FOLK BILKO para OPIE:
% opiekey -n 5 30 zz99999
Using the MD5 algorithm to compute response.
Reminder: Don't use opiekey from telnet or dial-in sessions.
Enter secret pass phrase: <secret password>
26: JOAN BORE FOSS DES NAY QUIT
27: LATE BIAS SLAY FOLK MUCH TRIG
28: SALT TIN ANTI LOON NEAL USE
29: RIO ODIN GO BYE FURY TIC
30: GREW JIVE SAN GIRD BOIL PHIEl -n 5 pide cinco llaves en secuencia, la opción 30 especifica que ese debe ser el último número de iteración. Observe que se imprimen en el orden inverso de uso. Si es realmente paranoico escriba los resultados a mano; si no, puede enviar la salida a lpr. Observe que cada línea muestra la cuenta iterativa y la contraseña de un solo uso; puede ir tachando las contraseñas según las vaya utilizando.
14.5.5. Restricción del uso de contraseñas UNIX®
S/Key puede implantar restricciones en el uso de contraseñas UNIX® basándose en el nombre de equipo, nombre de usuario, puerto de terminal o dirección IP de una sesión de login. Consulte el fichero de configuración /etc/skey.access. La página de manual de skey.access(5) contiene más información sobre el formato del fichero y detalla también algunas precauciones de seguridad que hay que tener en cuenta antes de basar nuestra seguridad en este fichero.
Si /etc/skey.access no existiera (por defecto es así en sistemas FreeBSD 4.X) todos los usuarios podrán disponer de contraseñas UNIX®. Si el fichero existe se exigirá a todos los usuarios el uso de S/Key, a menos que se configure de otro modo en skey.access. En todos los casos las contraseñas UNIX® son admiten en consola.
Aquí hay un ejemplo del fichero de configuración skey.access que muestra las tres formas más comunes de configuración:
permit internet 192.168.0.0 255.255.0.0 permit user fnord permit port ttyd0
La primera línea (permit internet) permite a usuarios cuyas direcciones IP origen (las cuales son vulnerables a una falsificación) concuerden con los valores y máscara especificados utilizar contraseñas UNIX®. Esto no debe usarse como mecanismo de seguridad, sino como medio de recordarle a los usuarios autorizados que están usando una red insegura y necesitan utilizar S/Key para la validación.
La segunda línea (permit user) permite al nombre de usuario especificado, en este caso fnord, utilizar contraseñas UNIX® en cualquier momento. Hablando en general, esto solo debe ser usado por gente que no puede usar el programa key, como aquellos con terminales tontas o refractarios al aprendizaje.
La tercera línea (permit port) permite a todos los usuarios validados en la línea de terminal especificada utilizar contraseñas UNIX®; esto puede usarse para usuarios que se conectan mediante "dial-ups".
OPIE puede restringir el uso de contraseñas UNIX® basándose en la dirección IP de una sesión de login igual que lo haría S/Key. El fichero que gestiona esto es /etc/opieaccess, que está incluído por defecto en sistemas FreeBSD 5.0 o posteriores. Revise opieaccess(5) para más información sobre este fichero y qué consideraciones de seguridad debe tener presentes a la hora de usarlo.
Veamos un ejemplo de opieaccess:
permit 192.168.0.0 255.255.0.0
Esta línea permite a usuarios cuya dirección IP de origen (vulnerable a falsificación) concuerde con los valores y máscara especificados, utilizar contraseñas UNIX® en cualquier momento.
Si no concuerda ninguna regla en opieaccess se niegan por defecto los logins no-OPIE.
14.6. TCP Wrappers
Cualquiera que esté familiarizado con inetd(8) probablemente haya oído hablar de TCP Wrappers, pero poca gente parece comprender completamente su utilidad en un entorno de red. Parece que todos quieren instalar un cortafuegos para manejar conexiones de red. Aunque un cortafuegos tiene una amplia variedad de usos hay cosas que un cortafuegos no es capaz de gestionar, como el envío de texto como respuesta al creador de la conexión. El software TCP hace esto y más. En las siguientes secciones se explicarán unas cuantas opciones de TCP Wrappers y, cuando sea necesario, se mostrarán ejemplos de configuraciones.
El software TCP Wrappers extiende las habilidades de inetd para ofrecer soporte para cada servidor dæmon bajo su control. Utilizando este método es posible proveer soporte de logs, devolver mensajes a conexiones, permitir a un dæmon aceptar solamente conexiones internas, etc. Aunque algunas de estas opciones pueden conseguirse gracias a un cortafuegos, no sólo añadirá una capa extra de seguridad, sino que irá más allá del nivel de control ue un cortafuegos puede ofrecerle.
Las brillantes capacidades de TCP Wrappers no deben considerarse una alternativa a un buen cortafuegos. TCP Wrappers puede usarse conjuntamente con un cortafuegos u otro sistema de de seguridad, pues ofrece una capa extra de protección para el sistema.
Ya que es una extensión de la configuración de inetd, se da por hecho que el lector ha leído la sección configuración de inetd.
Aunque los programas ejecutados por inetd(8) no son exactamente "dæmons" tradicionalmente han recibido ese nombre. Dæmon es, por tanto, el término que usaremos en esta sección. |
14.6.1. Configuración inicial
El único requisito para usar TCP Wrappers en FreeBSD es que el servidor inetd se inicie desde rc.conf con la opción -Ww (es la configuración por defecto). Por descontado, se presupone que /etc/hosts.allow estará correctamente configurado, pero syslogd(8) enviará mensajes a los logs del sistema si no es así.
A diferencia de otras implementaciones de TCP Wrappers, se ha dejado de usar hosts.deny. Todas las opciones de configuración deben ir en /etc/hosts.allow. |
En la configuración más simple las políticas de conexión de dæmons están configuradas ya sea a permitir o bloquear, dependiendo de las opciones en /etc/hosts.allow. La configuración por defecto en FreeBSD consiste en permitir una conexión a cada dæmon iniciado por inetd. Es posible modificar esta configuración, pero explicaremos cómo hacerlo después de exponer la configuración básica.
La configuración básica tiene la estructura dæmon : dirección : acción, donde dæmon es el nombre de dæmon que inicia inetd. La dirección puede ser un nombre de equipo válido, una dirección IP o IPv6 encerrada en corchetes ([ ]). El campo acción puede ser permitir o denegar para el dar el acceso apropiado. Tenga presente que la configuración funciona en base a la primera regla cuya semántica concuerde; esto significa que el fichero de configuración se lee en orden ascendente hasta que concuerde una regla. Cuando se encuentra una concordancia se aplica la regla y el proceso se detendrá.
Existen muchas otras opciones pero estas se explican en una sección posterior. Una línea de configuración simple puede generarse mediante datos así de simples. Por ejemplo, para permitir conexiones POP3 mediante el dæmon mail/qpopper, añada las siguientes líneas a hosts.allow:
# This line is required for POP3 connections: qpopper : ALL : allow
Despues de añadir esta línea tendrá que reiniciar inetd. Use kill(1) o use el parámetro restart de /etc/rc.d/inetd.
14.6.2. Configuración avanzada
Las opciones avanzadas de TCP Wrappers le permiten un mayor control sobre la gestión de conexiones. En algunos casos puede convenir el enío de un comentario a ciertos equipos o conexiones de dæmons. En otros casos, quizás se deba registrar una entrada en un log o enviar un correo al administrador. Otro tipo de situaciones pueden requerir el uso de un servicio solamente para conexiones locales. Todo esto es posible gracias al uso de unas opciones de configuración conocidas como comodines, caracteres de expansión y ejecución de órdenes externas. Las siguientes dos secciones intentarán cubrir estas situaciones.
14.6.2.1. Órdenes externas
Imaginemos una situación en la que una conexión debe ser denegada pero se debe mandar un motivo a quien intentó establecer esa conexión. ?Cómo? Mediante la opción twist. Ante un intento de conexión se invoca a twist, que ejecuta una orden de shell o un "script". Tiene un ejemplo en el fichero hosts.allow:
# The rest of the daemons are protected.
ALL : ALL \
: severity auth.info \
: twist /bin/echo "No se permite utilizar %d desde %h."Este ejemplo muestra que el mensaje, "No se permite utilizar dæmon desde nombre de equipo." se enviará en el caso de cualquier dæmon no configurado previamente en el fichero de acceso. Esto es extremadamente útil para enviar una respuesta al creador de la conexión justo después de que la conexión establecida es rechazada. Observe que cualquier mensaje que se desee enviar debe ir entre comillas "; esta regla no tiene excepciones.
Es posible lanzar un ataque de denegación de servicio al servidor si un atacante o grupo de atacantes pueden llegar a sobrecargar estos dæmons con peticiones de conexión. |
Otra posibilidad en estos casos es usar la opción spawn. Igual que twist, spawn niega implícitamente la conexión, y puede usarse para ejecutar órdenes de shell externos o "scripts". A diferencia de twist, spawn no enviará una respuesta al origen de la conexión. Veamos un ejemplo; observe la siguiente línea de configuración:
# No permitimos conexiones desde ejemplo.com: ALL : .ejemplo.com \ : spawn (/bin/echo %a desde %h intento acceder a %d >> \ /var/log/connections.log) \ : deny
Esto denegará todos los intentos de conexión desde el dominio *.ejemplo.com; simultáneamente creará una entrada con el nombre del equipo, dirección IP y el dæmon al que intentó conectarse al fichero /var/log/connections.log.
Además de la sustitución de caracteres ya expuesta más arriba (por ejemplo %a) existen unas cuantas más. Si quiere ver la lista completa consulte la página de manual hosts_access(5).
14.6.2.2. Opciones comodín
Hasta ahora se ha usado ALL en todos los ejemplos, pero hay otras opciones interesantes para extender un poco más la funcionalidad. Por ejemplo, ALL puede usarse para concordar con cualquier instancia ya sea un dæmon, dominio o dirección IP. Otro comodín es PARANOID, que puede utilizarse para concordar con cualquier equipo que presente una dirección IP que pueda estar falsificada. En otras palabras, paranoid puede usarse para definir una acción a tomar siempre que tenga lugar una conexión desde una dirección IP que difiera de su nombre de equipo. Quizás todo se vea más claro con el siguiente ejemplo:
# Bloquear peticiones posiblemente falsificadas a sendmail: sendmail : PARANOID : deny
En ese ejemplo todas las peticiones de conexión a sendmail que tengan una dirección IP que varíe de su nombre de equipo serán denegadas.
Utilizando |
Consulte hosts_access(5) si quiere saber más sobre los comodines y sus posibilidades de uso.
Si quiere que cualquiera de los ejemplos citados funcione debe comentar la primera línea de hosts.allow (tal y como se dijo al principio de la sección.
14.7. KerberosIV
Kerberos es un sistema/protocolo de red agregado que permite a los usuarios identificarse a través de los servicios de un servidor seguro. Los servicios como login remoto, copia remota, copias de ficheros de un sistema a otro y otras tantas tareas arriesgadas pasan a ser considerablemente seguras y más controlables.
Las siguientes instrucciones pueden usarse como una guía para configurar Kerberos tal y como se distribuye con FreeBSD. De todas maneras, debe consultar diversas páginas de manual para conocer todos los detalles.
14.7.1. Instalación de KerberosIV
Kerberos es un componente opcional de FreeBSD. La manera más fácil de instalar este software es seleccionando la distribución krb4 o krb5 en sysinstall durante la instalación inicial de FreeBSD. Desde ahí instalará la implementación de Kerberos "eBones" (KerberosIV) o "Heimdal" (Kerberos5). Estas implementaciones se incluyen porque a que han sido desarrolladas fuera de EEUU y Canadá, lo que las convertía en accesibles para administradores de sistemas del resto del mundo durante la época restrictiva de control control de exportaciones de código criptográfico desde EEUU.
También puede instalar la implementación de Kerberos del MIT desde la colección de ports (security/krb5).
14.7.2. Creación de la base de datos inicial
Esto solo debe hacerse en el servidor Kerberos. Lo primero es asegurarse de que no tiene bases de datos de Kerberos anteriores. Entre al directorio /etc/kerberosIV y asegúrese de que solo estén los siguientes ficheros:
# cd /etc/kerberosIV
# ls
README krb.conf krb.realmsSi existe cualquier otro fichero (como principal.* o master_key) utilice kdb_destroy para destruir la base de datos antigua de Kerberos. Si Kerberos no está funcionando simplemente borre los ficheros sobrantes.
Edite krb.conf y krb.realms para definir su dominio Kerberos. En nuestro ejemplo el dominio será EJEMPLO.COM y el servidor es grunt.ejemplo.com. Editamos o creamos krb.conf:
# cat krb.conf
EJEMPLO.COM
EJEMPLO.COM grunt.ejemplo.com admin server
CS.BERKELEY.EDU okeeffe.berkeley.edu
ATHENA.MIT.EDU kerberos.mit.edu
ATHENA.MIT.EDU kerberos-1.mit.edu
ATHENA.MIT.EDU kerberos-2.mit.edu
ATHENA.MIT.EDU kerberos-3.mit.edu
LCS.MIT.EDU kerberos.lcs.mit.edu
TELECOM.MIT.EDU bitsy.mit.edu
ARC.NASA.GOV trident.arc.nasa.govLos demás dominios no deben estar forzosamente en la configuración. Los hemos incluido como ejemplo de cómo puede hacerse que una máquina trabaje con múltiples dominios. Si quiere mantener todo simple puede abstenerse de incluirlos.
La primera línea es el dominio en el que el sistema funcionará. Las demás líneas contienen entradas dominio/equipo. El primer componente de cada línea es un dominio y el segundo es un equipo de ese dominio, que actúa como "centro de distribución de llaves". Las palabras admin server que siguen al nombre de equipo significan que ese equipo también ofrece un servidor de base da datos administrativo. Si quiere consultar una explicación más completa de estos términos consulte las páginas de manual de de Kerberos.
Ahora añadiremos grunt.ejemplo.com al dominio EJEMPLO.COM y también una entrada para poner todos los equipos en el dominio .ejemplo.com Kerberos EJEMPLO.COM. Puede actualizar su krb.realms del siguiente modo:
# cat krb.realms
grunt.ejemplo.com EJEMPLO.COM
.ejemplo.com EJEMPLO.COM
.berkeley.edu CS.BERKELEY.EDU
.MIT.EDU ATHENA.MIT.EDU
.mit.edu ATHENA.MIT.EDUIgual que en caso previo, no tiene por qué incluir los demás dominios. Se han incluido para mostrar cómo puede usar una máquina en múltiples dominios. Puede eliminarlos y simplificar la configuración.
La primera línea pone al sistema específico en el dominio nombrado. El resto de las líneas muestran cómo asignar por defecto sistemas de un subdominio a un dominio Kerberos.
Ya podemos crear la base de datos. Solo se ejecuta en el servidor Kerberos (o centro de distribución de llaves). Ejecute kdb_init:
# kdb_init
Realm name [default ATHENA.MIT.EDU ]: EJEMPLO.COM
You will be prompted for the database Master Password.
It is important that you NOT FORGET this password.
Enter Kerberos master key:Ahora tendremos que guardar la llave para que los servidores en la máquina local puedan recogerla. Utilice kstash:
# kstash
Enter Kerberos master key:
Current Kerberos master key version is 1.
Master key entered. BEWARE!Esto guarda la contraseña cifrada maestra en /etc/kerberosIV/master_key.
14.7.3. Puesta en marcha del sistema
Tendrá que añadir a la base de datos dos entradas en concreto para cada sistema que vaya a usar Kerberos: kpasswd y rcmd. Se hacen para cada sistema individualmente cada sistema, y el campo "instance" es el nombre individual del sistema.
Estos dæmons kpasswd y rcmd permiten a otros sistemas cambiar contraseñas de Kerberos y ejecutar órdenes como rcp(1), rlogin(1) y rsh(1).
Ahora vamos a añadir estas entradas:
# kdb_edit
Opening database...
Enter Kerberos master key:
Current Kerberos master key version is 1.
Master key entered. BEWARE!
Previous or default values are in [brackets] ,
enter return to leave the same, or new value.
Principal name: passwd
Instance: grunt
<Not found>, Create [y] ? y
Principal: passwd, Instance: grunt, kdc_key_ver: 1
New Password: <---- tecleo aleatorio
Verifying password
New Password: <---- tecleo aleatorio
Random password [y] ? y
Principal's new key version = 1
Expiration date (enter yyyy-mm-dd) [ 2000-01-01 ] ?
Max ticket lifetime (*5 minutes) [ 255 ] ?
Attributes [ 0 ] ?
Edit O.K.
Principal name: rcmd
Instance: grunt
<Not found>, Create [y] ?
Principal: rcmd, Instance: grunt, kdc_key_ver: 1
New Password: <---- tecleo aleatorio
Verifying password
New Password: <---- tecleo aleatorio
Random password [y] ?
Principal's new key version = 1
Expiration date (enter yyyy-mm-dd) [ 2000-01-01 ] ?
Max ticket lifetime (*5 minutes) [ 255 ] ?
Attributes [ 0 ] ?
Edit O.K.
Principal name: <---- si introduce datos nulos saldrá del programa14.7.4. Creación del fichero del servidor
Ahora tendremos que extraer todas las instancias que definen los servicios en cada máquina; para ello usaremos ext_srvtab. Esto creará un fichero que debe ser copiado o movido por medios seguros al directorio /etc/kerberosIV de cada cliente Kerberos. Este fichero debe existir en todos los servidores y clientes dada su importancia clave para el funcionamiento de Kerberos.
# ext_srvtab grunt
Enter Kerberos master key:
Current Kerberos master key version is 1.
Master key entered. BEWARE!
Generating 'grunt-new-srvtab'....Esta orden solo genera un fichero temporal al que tendrá que cambiar el nombre a srvtab para que todos los servidores puedan recogerlo. Utilice mv(1) para moverlo al lugar correcto en el sistema original:
# mv grunt-new-srvtab srvtabSi el fichero es para un sistema cliente y la red no puede considerarse segura copie el cliente-new-srvtab en un medio extraíble y transpórtelo por medios físicos seguros. Asegúrese de cambiar su nombre a srvtab en el directorio /etc/kerberosIV del cliente, y asegúrese también de que tiene modo 600:
# mv grumble-new-srvtab srvtab
# chmod 600 srvtab14.7.5. Añadir entradas a la base de datos
Ahora tenemos que añadir entradas de usuarios a la base de datos. Primero vamos a crear una entrada para el usuario jane. Para ello usaremos kdb_edit:
# kdb_edit
Opening database...
Enter Kerberos master key:
Current Kerberos master key version is 1.
Master key entered. BEWARE!
Previous or default values are in [brackets] ,
enter return to leave the same, or new value.
Principal name: jane
Instance:
<Not found>, Create [y] ? y
Principal: jane, Instance: , kdc_key_ver: 1
New Password: <---- introduzca una constraseña segura
Verifying password
New Password: <---- introduzca de nuevo la contraseña
Principal's new key version = 1
Expiration date (enter yyyy-mm-dd) [ 2000-01-01 ] ?
Max ticket lifetime (*5 minutes) [ 255 ] ?
Attributes [ 0 ] ?
Edit O.K.
Principal name: <---- si introduce datos nulos saldrá del programa14.7.6. Prueba del sistema
Primero tenemos que iniciar los dæmons de Kerberos. Tenga en cuenta que si su /etc/rc.conf está configurado correctamente el inicio tendrá ligar cuando reinicie el sistema. Esta prueba solo es necesaria en el servidor Kerberos; los clientes Kerberos tomarán lo que necesiten automáticamente desde el directorio /etc/kerberosIV.
# kerberos &
Kerberos server starting
Sleep forever on error
Log file is /var/log/kerberos.log
Current Kerberos master key version is 1.
Master key entered. BEWARE!
Current Kerberos master key version is 1
Local realm: EJEMPLO.COM
# kadmind -n &
KADM Server KADM0.0A initializing
Please do not use 'kill -9' to kill this job, use a
regular kill instead
Current Kerberos master key version is 1.
Master key entered. BEWARE!Ahora podemos probar a usar kinit para obtener un ticket para el ID jane que creamos antes:
% kinit jane
MIT Project Athena (grunt.ejemplo.com)
Kerberos Initialization for "jane"
Password:Pruebe a listar los tokens con klist para ver si realmente están:
% klist
Ticket file: /tmp/tkt245
Principal: jane@EJEMPLO.COM
Issued Expires Principal
Apr 30 11:23:22 Apr 30 19:23:22 krbtgt.EJEMPLO.COM@EJEMPLO.COMAhora trate de cambiar la contraseña usando passwd(1) para comprobar si el dæmon kpasswd está autorizado a acceder a la base de datos Kerberos:
% passwd
realm EJEMPLO.COM
Old password for jane:
New Password for jane:
Verifying password
New Password for jane:
Password changed.14.7.7. Añadir privilegios de su
Kerberos nos permite dar a cada usuario que necesite privilegios de root su propia contraseña para su(1). Podemos agregar un ID que esté autorizado a ejecutar su(1) root. Esto se controla con una instancia de root asociada con un usuario. Vamos a crear una entrada jane.root en la base de datos, para lo que recurrimos a kdb_edit:
# kdb_edit
Opening database...
Enter Kerberos master key:
Current Kerberos master key version is 1.
Master key entered. BEWARE!
Previous or default values are in [brackets] ,
enter return to leave the same, or new value.
Principal name: jane
Instance: root
<Not found>, Create [y] ? y
Principal: jane, Instance: root, kdc_key_ver: 1
New Password: <---- introduzca una contraseña SEGURA
Verifying password
New Password: <---- introduzca otra vez la constraseña
Principal's new key version = 1
Expiration date (enter yyyy-mm-dd) [ 2000-01-01 ] ?
Max ticket lifetime (*5 minutes) [ 255 ] ? 12 <--- Keep this short!
Attributes [ 0 ] ?
Edit O.K.
Principal name: <---- si introduce datos nulos saldrá del programaAhora trate de obtener los tokens para comprobar que todo funciona:
# kinit jane.root
MIT Project Athena (grunt.ejemplo.com)
Kerberos Initialization for "jane.root"
Password:Hemos de agregar al usuario al .klogin de root:
# cat /root/.klogin
jane.root@EJEMPLO.COMAhora trate de hacer su(1):
% su
Password:y eche un vistazo a qué tokens tenemos:
# klist
Ticket file: /tmp/tkt_root_245
Principal: jane.root@EJEMPLO.COM
Issued Expires Principal
May 2 20:43:12 May 3 04:43:12 krbtgt.EJEMPLO.COM@EJEMPLO.COM14.7.8. Uso de otras órdenes
En un ejemplo anterior creamos un usuario llamado jane con una instancia root. Nos basamos en un usuario con el mismo nombre del "principal" (jane), el procedimiento por defecto en Kerberos: <principal>.<instancia> con la estructura <nombre de usuario>. root permitirá que <nombre de usuario> haga su(1) a root si existen las entradas necesarias en el .klogin que hay en el directorio home de root:
# cat /root/.klogin
jane.root@EJEMPLO.COMDe la misma manera, si un usuario tiene en su directorio home lo siguiente:
% cat ~/.klogin
jane@EJEMPLO.COM
jack@EJEMPLO.COMsignifica que cualquier usuario del dominio EJEMPLO.COM que se identifique como jane o como jack (vía kinit, ver más arriba) podrá acceder a la cuenta de jane o a los ficheros de este sistema (grunt) vía rlogin(1), rsh(1) o rcp(1).
Veamos por ejemplo cómo jane se se identifica en otro sistema mediante Kerberos:
% kinit
MIT Project Athena (grunt.ejemplo.com)
Password:
% rlogin grunt
Last login: Mon May 1 21:14:47 from grumble
Copyright (c) 1980, 1983, 1986, 1988, 1990, 1991, 1993, 1994
The Regents of the University of California. All rights reserved.
FreeBSD BUILT-19950429 (GR386) #0: Sat Apr 29 17:50:09 SAT 1995Aquí jack se identifica con la cuenta de jane en la misma máquina (jane tiene configurado su fichero .klogin como se ha mostrado antes, y la persona encargada de la administración de Kerberos ha configurado un usuario principal jack con una instancia nula):
% kinit
% rlogin grunt -l jane
MIT Project Athena (grunt.ejemplo.com)
Password:
Last login: Mon May 1 21:16:55 from grumble
Copyright (c) 1980, 1983, 1986, 1988, 1990, 1991, 1993, 1994
The Regents of the University of California. All rights reserved.
FreeBSD BUILT-19950429 (GR386) #0: Sat Apr 29 17:50:09 SAT 199514.8. Kerberos5
Cada versión de FreeBSD posterior a FreeBSD-5.1 incluye soporte solamente para Kerberos5. Por esta razón Kerberos5 es la única versión incluida. Su configuración es similar en muchos aspectos a la de KerberosIV. La siguiente información solo atañe a Kerberos5 en versiones de FreeBSD-5.0 o posteriores. Los usuarios que deséen utilizar KerberosIV pueden instalar el port security/krb4.
Kerberos es un sistema/protocolo agregado para red que permite a los usuarios validar su identidad a través de los servicios de un servidor seguro. Los servicios como login remoto, copia remota, copias de fichero de un sistema a otro y otras tareas generalmente consideradas poco seguras pasan a ser considerablemente seguras y más controlables.
Kerberos puede describirse como un sistema proxy identificador/verificador. También puede describirse como un sistema confiable de autentificación de terceros. Kerberos solamente ofrece una función: la validación segura de usuarios a través de una red. No proporciona funciones de autorización (es decir, lo que los usuarios tienen permitido hacer) o funciones de auditoría (lo que esos usuarios hicieron). Después de que un servidor y un cliente han usado Kerberos para demostrar su identidad pueden también cifrar todas sus sus comunicaciones, asegurando de este modo su intimidad y la integridad de sus datos durante su uso del sistema.
Es, por tanto, altamente recomendable que se use Kerberos además de otros métodos de seguridad que ofrezcan servicios de autorización y auditoría.
Puede usar las siguientes instrucciones como una guía para configurar Kerberos tal y como se distribuye en FreeBSD. De todas maneras, debería consultar las páginas de manual adecuadas para tener toda la información.
Vamos a mostrar una instalación Kerberos, para lo cual usaremos los siguientes espacios de nombres:
El dominio DNS ("zona") será ejemplo.org.
El dominio Kerberos (realm) será EJEMPLO.ORG.
Debe utilizar nombres de dominio reales al configurar Kerberos incluso si pretende ejecutarlo internamente. Esto le evitará problemas de DNS y asegura la interoperación con otros dominios Kerberos. |
14.8.1. Historia
Kerberos fué creado en el Massachusetts Institute of Technology (MIT) como una solución a los problemas de seguridad de la red. El protocolo Kerberos utiliza criptografía fuerte para que un cliente pueda demostrar su identidad en un servidor (y viceversa) a través de una conexión de red insegura.
Kerberos es el nombre de un protocolo de autentificación vía red y un adjetivo para describir programas que implementan el programa (Kerberos telnet, por ejemplo, conocido también como el "telnet kerberizado"). La versión actual del protocolo es la 5, descrita en RFC 1510.
Existen diversas implementaciones libres de este protocolo, cubriendo un amplio rango de sistemas operativos. El MIT, donde Kerberos fué desarrollado, continúa desarrollando su propio paquete Kerberos. Suele usarse en los EEUU como producto criptográfico y como tal ha sufrido las regulaciones de exportación de los EEUU. El Kerberos del MIT existe como un port en (security/krb5). Heimdal Kerberos es otra implementación de la versión 5, y fué desarrollada de forma intencionada fuera de los EEUU para sortear las regulaciones de exportación (y por eso puede incluirse en versiones no comerciales de UNIX®). La distribución Heimdal Kerberos está en el port (security/heimdal), y se incluye una instalación mínima en el sistema base de FreeBSD.
Para alcanzar la mayor audiencia estas instrucciones asumen el uso de la distribución Heimdal incluída en FreeBSD.
14.8.2. Configuración de un KDC Heimdal
El centro de distribución de llaves (KDC, Key Distribution Center) es el servicio centralizado de validación que proporciona Kerberos: es el sistema que emite tickets Kerberos. El KDC goza del estátus de ser considerado como "confiable" por las demás computadoras del dominio Kerberos, y por eso tiene consideraciones de seguridad más elevadas.
Tenga en cuenta que, aunque la ejecución del servidor Kerberos requiere muy pocos recursos, se recomienda el uso de una máquina dedicada a KDC por razones de seguridad.
Para empezar a configurar un KDC asegúrese de que su /etc/rc.conf contenga la configuración adecuada para actuar como KDC (tal vez deba ajustar algunas rutas para que cuadren con su sistema):
kerberos5_server_enable="YES" kadmind5_server_enable="YES" kerberos_stash="YES"
|
A continuación configuraremos el fichero de configuración de Kerberos, /etc/krb5.conf:
[libdefaults]
default_realm = EJEMPLO.ORG [realms]
EXAMPLE.ORG = {
kdc = kerberos.ejemplo.org
admin_server = kerberos.ejemplo.org
}
[domain_realm]
.ejemplo.org = EJEMPLO.ORGTenga en cuenta que este /etc/krb5.conf implica que su KDC tendrá el nombre de equipo completo calificado de kerberos.ejemplo.org. Necesitará añadir una entrada CNAME (alias) a su fichero de zona si su KDC tiene un nombre de equipo diferente.
En grandes redes con un servidor DNSBIND bien configurado, el ejemplo de arriba puede quedar del siguiente modo: [libdefaults]
default_realm = EJEMPLO.ORGCon las siguientes líneas agregadas al fichero de zona _kerberos._udp IN SRV 01 00 88 kerberos.ejemplo.org. _kerberos._tcp IN SRV 01 00 88 kerberos.ejemplo.org. _kpasswd._udp IN SRV 01 00 464 kerberos.ejemplo.org. _kerberos-adm._tcp IN SRV 01 00 749 kerberos.ejemplo.org. _kerberos IN TXT EJEMPLO.ORG |
Para que los clientes sean capaces de encontrar los servicios Kerberos debe tener ya sea un /etc/krb5.conf configurado o un /etc/krb5.conf configurado de forma mínima y un servidor DNS configurado correctamente. |
A continuación crearemos la base de datos Kerberos. Esta base de datos contiene las llaves de todos los principales cifradas con una contraseña maestra. No es necesario que recuerde esta contraseña, pues se almacenará en /var/heimdal/m-key. Para crear la llave maestra ejecute kstash e introduzca una contraseña.
Una vez que se ha creado la llave maestra puede inicializar la base de datos usando el programa kadmin con la opción -l (que significa "local"). Esta opción le dice a kadmin que modifique los ficheros de la base de datos directamente en lugar de ir a través del servicio de red kadmind. Esto gestiona el problema del huevo y la gallina de tratar de conectar a la base de datos antes de que ésta exista. Una vez que tiene el "prompt" de kadmin, utilice init para crear su base de datos de dominios iniciales.
Para terminar, mientras está todavía en kadmin puede crear su primer principal mediante add. Utilice las opciones por defecto por ahora, más tarde puede cambiarlas mediante modify. Recuerde que puede usar ? en cualquier "prompt" para consultar las opciones disponibles.
Veamos un ejemplo de sesión de creación de una base de datos:
# kstash
Master key: xxxxxxxx
Verifying password - Master key: xxxxxxxx
# kadmin -l
kadmin> init EJEMPLO.ORG
Realm max ticket life [unlimited]:
kadmin> add tillman
Max ticket life [unlimited]:
Max renewable life [unlimited]:
Attributes []:
Password: xxxxxxxx
Verifying password - Password: xxxxxxxxAhora puede arrancar los servicios KDC. Ejecute /etc/rc.d/kerberos start y /etc/rc.d/kadmind start para levantar dichos servicios. Recuerde que no tendrá ningún dæmon kerberizado ejecutándose pero debe poder confirmar que KDC funciona por el procedimiento de obtener y listar un boleto del principal (usuario) que acaba de crear en la línea de órdenes de KDC:
% k5init tillman
tillman@EJEMPLO.ORG's Password:
% k5list
Credentials cache: FILE:/tmp/krb5cc_500
Principal: tillman@EJEMPLO.ORG
Issued Expires Principal
Aug 27 15:37:58 Aug 28 01:37:58 krbtgt/EJEMPLO.ORG@EJEMPLO.ORG14.8.3. Creación de un servidor Kerberos con servicios Heimdal
Antes de nada necesitaremos una copia del fichero de configuración de Kerberos, /etc/krb5.conf. Cópielo al cliente desde KDC de forma segura (mediante scp(1), o usando un disquete).
A continuación necesitará un fichero /etc/krb5.keytab. Esta es la mayor diferencia entre un servidor que proporciona dæmons habilitados con Kerberos y una estación de trabajo: el servidor debe tener un fichero keytab. Dicho fichero contiene las llaves de equipo del servidor, las cuales le permiten a él y al KDC verificar la identidad entre ellos. Deben transmitirse al servidor de forma segura ya que la seguridad del servidor puede verse comprometida si la llave se hace pública. Por decirlo más claro, transferirla como texto plano a través de la red (por ejemplo por FTP) es una pésima idea.
Lo normal es que transmita su keytab al servidor mediante el programa kadmin. Esto es práctico porque también debe crear el principal del equipo (el KDC que aparece al final de krb5.keytab) usando kadmin.
Tenga en cuenta que ya debe disponer de un ticket, y que este ticket debe poder usar el interfaz kadmin en kadmind.acl. Consulte la sección "administración remota" en la página info de Heimdal (info heimdal), donde se exponen los detalles de diseño de las listas de control de acceso. Si no quiere habilitar acceso remoto kadmin, puede conectarse de forma segura al KDC (por medio de consola local, ssh(1) o telnet(1) Kerberos) y administrar en local mediante kadmin -l.
Después de instalar el fichero /etc/krb5.conf puede usar kadmin desde el servidor Kerberos. add --random-key le permitirá añadir el principal del equipo servidor, y ext le permitirá extraer el principal del equipo servidor a su propio keybat. Por ejemplo:
# kadmin
kadmin> add --random-key host/myserver.ejemplo.org
Max ticket life [unlimited]:
Max renewable life [unlimited]:
Attributes []:
kadmin> ext host/miservidor.ejemplo.org
kadmin> exitTenga en cuenta que ext (contracción de "extract") almacena la llave extraída por defecto en en /etc/krb5.keytab.
Si no tiene kadmind ejecutándose en KDC (posiblemente por razones de seguridad) y por lo tanto carece de acceso remoto a kadmin puede añadir el principal de equipo (host/miservidor.EJEMPLO.ORG) directamente en el KDC y entonces extraerlo a un fichero temporal (para evitar sobreescribir /etc/krb5.keytab en el KDC) mediante algo parecido a esto:
# kadmin
kadmin> ext --keytab=/tmp/ejemplo.keytab host/miservidor.ejemplo.org
kadmin> exitPuede entonces copiar de forma segura el keytab al servidor (usando scp o un diquete). Asegúrese de usar un nombre de keytab diferente para evitar sobreescribir el keytab en el KDC.
Su servidor puede comunicarse con el KDC (gracias a su fichero krb5.conf) y puede probar su propia identidad (gracias al fichero krb5.keytab). Ahora está listo para que usted habilite algunos servicios Kerberos. En este ejemplo habilitaremos el servicio telnet poniendo una línea como esta en su /etc/inetd.conf y reiniciando el servicio inetd(8) con /etc/rc.d/inetd restart:
telnet stream tcp nowait root /usr/libexec/telnetd telnetd -a user
La parte crítica es -a, de autentificación de usuario. Consulte la página de manual telnetd(8) para más información.
14.8.4. Kerberos con un cliente Heimdal
Configurar una computadora cliente es extremadamente fácil. Lo único que necesita es el fichero de configuración de Kerberos que encontrará en /etc/krb5.conf. Simplemente cópielo de forma segura a la computadora cliente desde el KDC.
Pruebe su computadora cliente mediante kinit, klist, y kdestroy desde el cliente para obtener, mostrar y luego borrar un ticket para el principal que creó antes. Debería poder usar aplicaciones Kerberos para conectarse a servidores habilitados con Kerberos, aunque si no funciona y tiene problemas al intentar obtener el boleto lo más probable es que el problema esté en el servidor y no en el cliente o el KDC.
Al probar una aplicación como telnet, trate de usar un "sniffer" de paquetes ( como tcpdump(1)) para confirmar que su contraseña no viaja en claro por la red. Trate de usar telnet con la opción -x, que cifra el flujo de datos por entero (algo parecido a lo que hace ssh).
Las aplicaciones clientes Kerberos principales (llamadas tradicionalmente kinit, klist, kdestroy y kpasswd) están incluidas en la instalación base de FreeBSD. Tenga en cuenta que en las versiones de FreeBSD anteriores a 5.0 reciben los nombres de k5init, k5list, k5destroy, k5passwd y k5stash.
También se instalan por defecto diversas aplicaciones Kerberos que no entran dentro de la categoría de "imprescindibles". Es aquí donde la naturaleza "mínima" de la instalación base de Heimdal salta a la palestra: telnet es el único servicio Kerberos habilitado.
El port Heimdal añade algunas de las aplicaciones cliente que faltan: versiones Kerberos de ftp, rsh, rcp, rlogin y algunos otros programas menos comunes. El port del MIT también contiene una suite completa de aplicaciones cliente de Kerberos.
14.8.5. Ficheros de configuración de usuario: .k5login y .k5users
Suele ser habitual que los usuarios de un dominio Kerberos (o "principales") tengan su usuario (por ejemplo tillman@EJEMPLO.ORG) mapeado a una cuenta de usuario local (por ejemplo un usuario llamado llamado tillman). Las aplicaciones cliente como telnet normalmente no requieren un nombre de usuario o un principal.
Es posible que de vez en cuando quiera dar acceso a una una cuenta de usuario local a alguien que no tiene un principal Kerberos. Por ejemplo, tillman@EJEMPLO.ORG puede necesitar acceso a la cuenta de usuario local webdevelopers. Otros principales tal vez necesiten acceso a esas cuentas locales.
Los ficheros .k5login y .k5users, ubicados en el directorio home del usuario, pueden usarse de un modo similar a una combinación potente de .hosts y .rhosts. Por ejemplo, si pusiera un fichero .k5login con el siguiente contenido
tillman@example.org
jdoe@example.orgen el directorio home del usuario local webdevelopers ambos principales listados tendrían acceso a esa cuenta sin requerir una contraseña compartida.
Le recomendamos encarecidamente la lectura de las páginas de manual de estas órdenes. Recuerde que la página de manual de ksu abarca .k5users.
14.8.6. Kerberos Sugerencias, trucos y solución de problemas
Tanto si utiliza el port de Heimdal o el Kerberos del MIT asegúrese de que su variable de entorno
PATHliste las versiones de Kerberos de las aplicaciones cliente antes que las versiones del sistema.?Todas las computadoras de su dominio Kerberos tienen la hora sincronizada? Si no, la autentificación puede fallar. NTP describe como sincronizar los relojes utilizando NTP.
MIT y Heimdal conviven bien, con la excepción de
kadmin, protocolo no está estandarizado.Si cambia su nombre de equipo debe cambiar también el "apellido" de su principal y actualizar su keytab. Esto también se aplica a entradas especiales en keytab como el principal
www/que usa el www/mod_auth_kerb de Apache.Todos los equipos en su dominio Kerberos deben poder resolverse (tanto en la forma normal normal como en la inversa) en el DNS (o en /etc/hosts como mínimo). Los CNAME funcionarán, pero los registros A y PTR deben ser correctos y estar en su sitio. El mensaje de error que recibirá de no hacerlo así no es muy intuitivo:
Kerberos5 refuses authentication because Read req failed: Key table entry not found.Algunos sistemas operativos que puede usar como clientes de su KDC no activan los permisos para
ksucomo setuidroot. Esto hará queksuno funcione, lo cual es muy seguro pero un tanto molesto. Tenga en cuenta que no se debe a un error de KDC.Si desea permitir que un principal tenga un ticket con una validez más larga que el valor por defecto de diez horas en Kerberos del MIT debe usar
modify_principalenkadminpara cambiar "maxlife" tanto del principal en cuestión como delkrbtgtdel principal. Hecho esto, el principal puede utilizar la opción-lconkinitpara solicitar un boleto con más tiempo de vida.
Si ejecuta un "sniffer" de paquetes en su KDC para ayudar con la resolución de problemas y ejecuta |
Si desea utilizar tickets con un tiempo largo de vida (una semana, por ejemplo) y está utilizando OpenSSH para conectarse a la máquina donde se almacena su boleto asgúrese de que Kerberos
TicketCleanupesté configurado anoen su sshd_config o de lo contrario sus tickets serán eliminados cuando termine la sesión.Recuerde que los principales de equipos también pueden tener tener un tiempo de vida más largo. Si su principal de usuario tiene un tiempo de vida de una semana pero el equipo al que se conecta tiene un tiempo de vida de nueve horas, tendrá un principal de equipo expirado en su caché, y la caché de ticket no funcionará como esperaba.
Cuando esté configurando un fichero krb5.dict pensando específicamente en prevenir el uso de contraseñas defectuosas (la página de manual de de
kadmindtrata el tema brevemente), recuerde que solamente se aplica a principales que tienen una política de contraseñas asignada. El formato de los ficheros krb5.dict es simple: una cadena de texto por línea. Puede serle útil crear un enlace simbólico a /usr/shared/dict/words.
14.8.7. Diferencias con el port del MIT
Las diferencias más grandes entre las instalaciones MIT y Heimdal están relacionadas con kadmin, que tiene un conjunto diferente (pero equivalente) de órdenes y utiliza un protocolo diferente. Esto tiene implicaciones muy grandes si su KDC es MIT, ya que no podrá utilizar el programa kadmin de Heimdal para administrar remotamente su KDC (o viceversa).
Las aplicaciones cliente pueden también disponer de diferentes opciones de línea de órdenes para lograr lo mismo. Le recomendamos seguir las instrucciones de la página web de Kerberos del MIT (http://web.mit.edu/Kerberos/www/). Sea cuidadoso con los parches: el port del MIT se instala por defecto en /usr/local/, y las aplicaciones "normales" del sistema pueden ser ejecutadas en lugar de las del MIT si su variable de entorno PATH lista antes los directorios del sistema.
Si usa el port del MITsecurity/krb5 proporcionado por FreeBSD asegúrese de leer el fichero /usr/local/shared/doc/krb5/README.FreeBSD instalado por el port si quiere entender por qué los login vía |
14.8.8. Mitigación de limitaciones encontradas en Kerberos
14.8.8.1. Kerberos es un enfoque "todo o nada"
Cada servicio habilitado en la red debe modificarse para funcionar con Kerberos (o debe ser asegurado contra ataques de red) o de lo contrario las credenciales de usuario pueden robarse y reutilizarse. Un ejemplo de esto podría ser que Kerberos habilite todos los shells remotos ( vía rsh y telnet, por ejemplo) pero que no cubra el servidor de correo POP3, que envía contraseñas en texto plano.
14.8.8.2. Kerberos está pensado para estaciones de trabajo monousuario
En un entorno multiusuario Kerberos es menos seguro. Esto se debe a que almacena los tickets en el directorio /tmp, que puede ser leído por todos los usuarios. Si un usuario está compartiendo una computadora con varias personas (esto es, si utiliza un sistema multiusuario) es posible que los tickets sean robados (copiados) por otro usuario.
Esto puede solventarse con la opción de línea de órdenes -c nombre-de-fichero o (mejor aún) la variable de entorno KRB5CCNAME, pero raramente se hace. Si almacena los tickets en el directorio home de los usuarios y utiliza sin mucha complicación los permisos de fichero puede mitigar este problema.
14.8.8.3. El KDC es el punto crítico de fallo
Por motivos de diseño el KDC es tan seguro como la base de datos principal de contraseñas que contiene. El KDC no debe ejecutar ningún otro servicio ejecutándose en él y debe ser físicamente seguro. El peligro es grande debido a que Kerberos almacena todas las contraseñas cifradas con la misma llave (la llave "maestra", que a su vez se guarda como un fichero en el KDC).
De todos modos una llave maestra comprometida no es algo tan terrible como parece a primera vista. La llave maestra solo se usa para cifrar la base de datos Kerberos y como semilla para el generador de números aleatorios. Mientras sea seguro el acceso a su KDC un atancante no puede hacer demasiado con la llave maestra.
Además, si el KDC no está disponible (quizás debido a un ataque de denegación de servicio o problemas de red) no se podrán utilizar los servicios de red ya que no se puede efectuar la validación, lo que hace que esta sea una buena forma de lanzar un ataque de denegación de servicio. Este problema puede aliviarse con múltiples KDCs (un maestro y uno o más esclavos) y con una implementación cautelosa de secundarios o autentificación de respaldo (para esto PAM es excelente).
14.8.8.4. Limitaciones de Kerberos
Kerberos le permite a usuarios, equipos y servicios validarse entre sí, pero no dispone de ningún mecanismo para autentificar el KDC a los usuarios, equipos o servicios. Esto significa que una versión (por ejemplo) "troyanizada" kinit puede grabar todos los usuarios y sus contraseñas. Puede usar security/tripwire o alguna otra herramienta de revisión de integridad de sistemas de ficheros para intentar evitar problemas como este.
14.9. OpenSSL
El conjunto de herramientas OpenSSL es una característica de FreeBSD que muchos usuarios pasan por alto. OpenSSL ofrece una capa de cifrada de transporte sobre la capa normal de comunicación, permitiendo la combinación con con muchas aplicaciones y servicios de red.
Algunos usos de OpenSSL son la validación cifrada de clientes de correo, las transacciones basadas en web como pagos con tarjetas de crédito, etc. Muchos ports, como www/apache13-ssl y mail/sylpheed-claws ofrecen soporte de compilación para OpenSSL.
En la mayoría de los casos la colección de ports tratará de compilar el port security/openssl a menos que la variable de make |
La versión de OpenSSL incluida en FreeBSD soporta los protocolos de seguridad de red Secure Sockets Layer v2/v3 (SSLv2/SSLv3) y Transport Layer Security v1 (TLSv1) y puede utilizarse como biblioteca criptográfica general.
OpenSSL soporta el algoritmo IDEA pero estáa deshabilitado por defecto debido a patentes en vigor en los Estados Unidos. Si quiere usarlo debe revisar la licencia, y si las restricciones le parecen aceptables active la variable |
Uno de los usos más comunes de OpenSSL es ofrecer certificados para usar con aplicaciones de software. Estos certificados aseguran que las credenciales de la compañia o individuo son válidos y no son fraudulentos. Si el certificado en cuestión no ha sido verificado por uno de las diversas "autoridades certificadoras" o CA, suele generarse una advertencia al respecto. Una autoridad de certificados es una compañia, como VeriSign, que firma certificados para validar credenciales de individuos o compañias. Este proceso tiene un costo asociado y no es un requisito imprescindible para usar certificados, aunque puede darle un poco de tranquilidad a los usuarios más paranóicos.
14.9.1. Generación de certificados
Para generar un certificado ejecute lo siguiente:
# openssl req -new -nodes -out req.pem -keyout cert.pem
Generating a 1024 bit RSA private key
................++++++
.......................................++++++
writing new private key to 'cert.pem'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:US
State or Province Name (full name) [Some-State]:PA
Locality Name (eg, city) []:Pittsburgh
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Mi compañía
Organizational Unit Name (eg, section) []:Administrador de sistemas
Common Name (eg, YOUR name) []:localhost.ejemplo.org
Email Address []:trhodes@FreeBSD.org
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:UNA CONTRASEÑA
An optional company name []:Otro nombreTenga en cuenta que la respuesta directamente después de "prompt""Common Name" muestra un nombre de dominio. Este "prompt" requiere que se introduzca un nombre de servidor para usarlo en la verificación; si escribe cualquier otra cosa producirá un certificado inválido. Otras opciones, por ejemplo el tiempo de expiración, alternan algoritmos de cifrado, etc. Puede ver una lista completa en la página de manual de openssl(1).
Debería tener dos ficheros en el directorio donde ha ejecutado la orden anterior. La petición de certificado, req.pem, es lo que debe enviar a una autoridad certificadora para que valide las credenciales que introdujo; firmará la petición y le devolverá el certificado. El segundo fichero es cert.pem y es la llave privada para el certificado, que debe proteger a toda costa; si cae en malas manos podrí usarse para suplantarle a usted o a sus servidores.
Si no necesita la firma de una CA puede crear y firmar usted mismo su certificado. Primero, genere la llave RSA:
# openssl dsaparam -rand -genkey -out myRSA.key 1024A continuación genere la llave CA:
# openssl gendsa -des3 -out myca.key myRSA.keyUtilice esta llave para crear el certificado:
# openssl req -new -x509 -days 365 -key myca.key -out new.crtDeberín aparecer dos nuevos ficheros en su directorio: un fichero de firma de autoridad de certificados (myca.key) y el certificado en sí, new.crt. Deben ubicarse en un directorio, que se recomienda que sea /etc, que es legible solo para root. Para terminar, es recomendable asignar permisos 0700 para el fichero con chmod.
14.9.2. Uso de certificados; un ejemplo
?Qué pueden hacer estos ficheros? Cifrar conexiones al MTASendmail es un buen sitio para usarlos. De este modo eliminará el uso de validación mediante texto en claro para los usuarios que envían correo a través del MTA local.
No es el mejor uso en el mundo, ya que algunos MUAs enviarán al usuario un mensaje de error si no tiene instalados localmente los certificados. Consulte la documentación para más datos sobre la instalación de certificados. |
Debe añadir las siguientes líneas en su fichero local .mc:
dnl SSL Options define(`confCACERT_PATH',`/etc/certs')dnl define(`confCACERT',`/etc/certs/new.crt')dnl define(`confSERVER_CERT',`/etc/certs/new.crt')dnl define(`confSERVER_KEY',`/etc/certs/myca.key')dnl define(`confTLS_SRV_OPTIONS', `V')dnl
/etc/certs/ es el directorio destinado a almacenamiento de los ficheros de certificado y llave en local. El último requisito es una reconstrucción del fichero .cf local. Solo tiene que teclear makeinstall en el directorio /etc/mail. A continuación ejecute un makerestart, que debería reiniciar el dæmon Sendmail.
Si todo fué bien no habrá mensajes de error en el fichero /var/log/maillog y Sendmail aparecerá en la lista de procesos.
Puede probarlo todo de una forma muy sencilla; conéctese al servidor de correo mediante telnet(1):
# telnet ejemplo.com 25
Trying 192.0.34.166...
Connected to ejemplo.com.
Escape character is '^]'.
220 ejemplo.com ESMTP Sendmail 8.12.10/8.12.10; Tue, 31 Aug 2004 03:41:22 -0400 (EDT)
ehlo ejemplo.com
250-ejemplo.com Hello ejemplo.com [192.0.34.166], pleased to meet you
250-ENHANCEDSTATUSCODES
250-PIPELINING
250-8BITMIME
250-SIZE
250-DSN
250-ETRN
250-AUTH LOGIN PLAIN
250-STARTTLS
250-DELIVERBY
250 HELP
quit
221 2.0.0 ejemplo.com closing connection
Connection closed by foreign host.Si la línea "STARTTLS" aparece en la salida, todo está funcionando correctamente.
14.10. VPN sobre IPsec
Creación de una VPN entre dos redes, a través de Internet, mediante puertas de enlace ("gateways") FreeBSD.
14.10.1. Qué es IPsec
Esta sección le guiará a través del proceso de configuración de IPsec, y de su uso en un entorno consistente en máquinas FreeBSD y Microsoft® Windows® 2000/XP, para hacer que se comuniquen de manera segura. Para configurar IPsec es necesario que esté familiarizado con los conceptos de construcción de un kernel personalizado (consulte el Configuración del kernel de FreeBSD).
IPsec es un protocolo que está sobre la capa del protocolo de Internet (IP). Le permite a dos o más equipos comunicarse de forma segura (de ahí el nombre). La "pila de red" IPsec de FreeBSD se basa en la implementación KAME, que incluye soporte para las dos familias de protocolos, IPv4 e IPv6.
FreeBSD 5.X contiene una pila IPsec "acelerada por hardware", conocida como "Fast IPsec", que fué obtenida de OpenBSD. Emplea hardware criptográfico (cuando es posible) a través del subsistema crypto(4) para optimizar el rendimiento de IPsec. Este subsistema es nuevo, y no soporta todas las opciones disponibles en la versión KAME de IPsec. Para poder habilitar IPsec acelerado por hardware debe añadir las siguientes opciones al fichero de configuración de su kernel: Tenga en cuenta que no es posible utilizar el subsistema "Fast IPsec" y la implementación KAME de IPsec en la misma computadora. Consulte la página de manual fast_ipsec(4) para más información. |
IPsec consta de dos sub-protocolos:
Encapsulated Security Payload (ESP), que protege los datos del paquete IP de interferencias de terceros, cifrando el contenido utilizando algoritmos de criptografía simétrica (como Blowfish, 3DES).
Authentication Header (AH), que protege la cabecera del paquete IP de interferencias de terceros así como contra la falsificación ("spoofing"), calculando una suma de comprobación criptográfica y aplicando a los campos de cabecera IP una función hash segura. Detrás de todo esto va una cabecera adicional que contiene el hash para permitir la validación de la información que contiene el paquete.
ESP y AH pueden utilizarse conjunta o separadamente, dependiendo del entorno.
IPsec puede utilizarse para cifrar directamente el tráfico entre dos equipos (conocido como modo de transporte) o para construir "túneles virtuales" entre dos subredes, que pueden usarse para comunicación segura entre dos redes corporativas (conocido como modo de túnel). Este último es muy conocido como una red privada virtual (Virtual Private Network, o VPN). ipsec(4) contiene información detallada sobre el subsistema IPsec de FreeBSD.
Si quiere añdir soporte IPsec a su kernel debe incluir las siguientes opciones al fichero de configuración de su kernel:
options IPSEC #IP security
options IPSEC_ESP #IP security (crypto; define w/ IPSEC)Si quiere soporte para la depuración de errores no olvide la siguiente opción:
options IPSEC_DEBUG #debug for IP security14.10.2. El Problema
No existe un estándar para lo que constituye una VPN. Las VPN pueden implementarse utilizando numerosas tecnologías diferentes, cada una de las cuales tiene sus pros y sus contras. Esta sección presenta un escenario, y las estrategias usadas para implementar una VPN para este escenario.
14.10.3. El escenario: dos redes, conectadas por Internet, que queremos que se comporten como una sola
Este es el punto de partida:
Usted tiene al menos dos sitios
Ambos sitios utilizan IP internamente
Ambos sitios están conectados a Internet, a través de una puerta de enlace FreeBSD.
La puerta de enlace de cada red tiene al menos una dirección IP pública.
Las direcciones internas de las dos redes pueden ser direcciones IP públicas o privadas, no importa. Puede ejecutar NAT en la máquina que hace de puerta de enlace si es necesario.
Las direcciones IP internas de las dos redes no colisionan. Aunque espero que sea teóricamente posible utilizar una combinación de tecnología VPN y NAT para hacer funcionar todo esto sospecho que configurarlo sería una pesadilla.
Si lo que intenta es conectar dos redes y ambas usan el mismo rango de direcciones IP privadas (por ejemplo las dos usan 192.168.1.x)debería renumerar una de las dos redes.
La topología de red se parecería a esto:
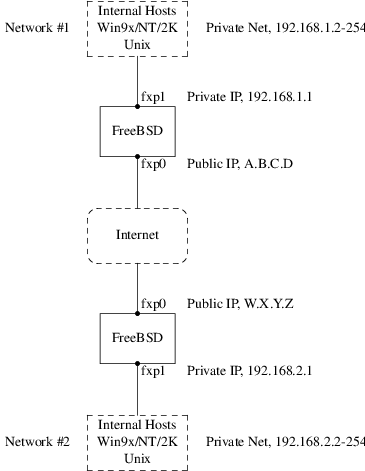
Observe las dos direcciones IP públicas. Usaré letras para referirme a ellas en el resto de este artículo. El cualquier lugar que vea esas letras en este artículo reemplácelas con su propia dirección IP pública. Observe también que internamente las dos máquinas que hacen de puerta de enlace tienen la dirección IP .1, y que las dos redes tienen direcciones IP privadas diferentes (192.168.1.x y 192.168.2.x respectivamente). Todas las máquinas de las redes privadas están configuradas para utilizar la máquina .1 como su puerta de enlace por defecto.
La intención es que, desde el punto de vista de la red, cada red debe ver las máquinas en la otra red como si estuvieran directamente conectadas al mismo router (aunque aunque sea un router ligeramente lento con una tendencia ocasional a tirar paquetes).
Esto significa que (por ejemplo), la máquina 192.168.1.20 debe ser capaz de ejecutar
ping 192.168.2.34
y recibir de forma transparente una respuesta. Las máquinas Windows® deben ser capaces de ver las máquinas de la otra red, acceder a sus ficheros compartidos, etc, exactamente igual que cuando acceden a las máquinas de la red local.
Y todo debe hacerse de forma segura. Esto significa que el tráfico entre las dos redes tiene que ser cifrado.
La creación de una VPN entre estas dos redes es un proceso que requiere varios pasos. Las etapas son estas:
Crear un enlace de red "virtual" entre las dos redes, a través de Internet. Probarlo usando herramientas como ping(8) para asegurarse de que funcione.
Aplicar políticas de seguridad para asegurarse de que el tráfico entre las dos redes sea cifrado y descifrado de forma transparente. Comprobarlo mediante herramientas como tcpdump(1) para asegurarse de que el tráfico esté siendo efectivamente cifrado.
Configurar software adicional en las puertas de enlace FreeBSD para permitir a las máquinas Windows® verse entre ellas a través de la VPN.
14.10.3.1. Paso 1: Creación y prueba de un enlace de red "virtual"
Suponga que está en la puerta de enlace de la red red #1 (con dirección IP pública A.B.C.D, dirección IP privada 192.168.1.1), y ejecuta ping 192.168.2.1, que es la dirección privada de la máquina con dirección IP W.X.Y.Z. ?Qué hace falta para esto?
La puerta de enlace necesita saber cómo alcanzar a
192.168.2.1. En otras palabras, necesita tener una ruta hasta192.168.2.1.Las direcciones IP privadas, como las que están en el rango
192.168.xno deberían aparecer en Internet. Por eso, cada paquete que mande a192.168.2.1necesitará encerrarse dentro de otro paquete. Este paquete debe tener todas las características de haber sido enviado desdeA.B.C.D, y tendrá que ser enviado aW.X.Y.Z. Este proceso recibe el nombre de encapsulado.Una vez que este paquete llega a
W.X.Y.Znecesitará ser "desencapsulado", y entregado a192.168.2.1.
Puede verlo como si necesitara un "túnel" entre las dos redes. Las dos "bocas del túnel" son las direcciones IP A.B.C.D y W.X.Y.Z, y debe hacer que el túnel sepa cuáles serán las direcciones IP privadas que tendrán permitido el paso a través de él. El túnel se usa para transferir tráfico con direcciones IP privadas a través de la Internet pública.
Este túnel se crea mediante la interfaz genérica, o dispositivo gif en FreeBSD. Como puede imaginarse la interfaz gif de cada puerta de enlace debe configurarse con cuatro direcciones IP: dos para las direcciones IP públicas, y dos para las direcciones IP privadas.
El soporte para el dispositivo gif debe compilarse en el kernel de FreeBSD en ambas máquinas añadiendo la línea
device gif
a los ficheros de configuración del kernel de ambas máquinas, compilarlo, instalarlo y reiniciar.
La configuración del túnel es un proceso que consta de dos partes. Primero se le debe decir al túnel cuáles son las direcciones IP exteriores (o públicas) mediante gifconfig(8). Después configure las direcciones IP con ifconfig(8).
En FreeBSD 5.X las funciones de gifconfig(8) se han incluido en ifconfig(8). |
En la puerta de enlace de la red #1 debe ejecutar las siguientes dos órdenes para configurar el túnel.
gifconfig gif0 A.B.C.D W.X.Y.Z ifconfig gif0 inet 192.168.1.1 192.168.2.1 netmask 0xffffffff
En la otra puerta de enlace ejecute las mismas órdenes, pero con el orden las direcciones IP invertido.
gifconfig gif0 W.X.Y.Z A.B.C.D ifconfig gif0 inet 192.168.2.1 192.168.1.1 netmask 0xffffffff
Ahora ejecute:
gifconfig gif0
y podrá ver la configuración. Por ejemplo, en la puerta de enlace de la red #1 vería algo parecido a esto:
# gifconfig gif0
gif0: flags=8011<UP,POINTTOPOINT,MULTICAST> mtu 1280
inet 192.168.1.1 --> 192.168.2.1 netmask 0xffffffff
physical address inet A.B.C.D --> W.X.Y.ZComo puede ver se ha creado un túnel entre las direcciones físicas A.B.C.D y W.X.Y.Z, y el tráfico que puede pasar a través del túnel es entre 192.168.1.1 y 192.168.2.1.
Esto también habrá agregado una entrada en la tabla de rutas de ambas máquinas, que puede examinar con netstat -rn. Esta salida es de la puerta de enlace de la red #1.
# netstat -rn
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
...
192.168.2.1 192.168.1.1 UH 0 0 gif0
...Como el valor de "Flags" lo indica, esta es una ruta de equipo, lo que significa que cada puerta de enlace sabe como alcanzar la otra puerta de enlace, pero no saben cómo llegar al resto de sus respectivas redes. Ese problema se solucionará en breve.
Es posible que disponga de un cortafuegos en ambas máquinas, por lo que tendrá que buscar la forma de que el tráfico de la VPN pueda entrar y salir limpiamente. Puede permitir todo el tráfico de ambas redes, o puede que quiera incluir reglas en el cortafuegos para que protejan ambos extremos de la VPN uno del otro.
Las pruebas se simplifican enormemente si configura el cortafuegos para permitir todo el tráfico a través de la VPN. Siempre puede ajustar las cosas después. Si utiliza ipfw(8) en las puertas de enlace una orden similar a
ipfw add 1 allow ip from any to any via gif0
permitirá todo el tráfico entre los dos extremos de la VPN, sin afectar al resto de reglas del cortafuegos. Obviamente tendrá que ejecutar esta orden en ambas puertas de enlace.
Esto es suficiente para permitir a cada puerta de enlace hacer un ping entre ellas. En 192.168.1.1 deberí poder ejecutar
ping 192.168.2.1
y obtener una respuesta; es obvio que debería poder hacer los mismo en la otra puerte de enlace.
Aún no podrá acceder a las máquinas internas de las redes. El problema está en el encaminamiento: aunque las puertas de enlace saben cómo alcanzarse mútuamente no saben cómo llegar a la red que hay detrás de la otra.
Para resolver este problema debe añadir una ruta estática en cada puerta de enlace. La orden en la primera puerta de enlace podría ser:
route add 192.168.2.0 192.168.2.1 netmask 0xffffff00
Esto significa "Para alcanzar los equipos en la red 192.168.2.0, envía los paquetes al equipo 192.168.2.1". Necesitará ejecutar una orden similar en la otra puerta de enlace, pero obviamente con las direcciones 192.168.1.x.
El tráfico IP de equipos en una red no será capaz de alcanzar equipos en la otra red.
Ya tiene dos tercios de una VPN, puesto que ya es "virtual" y es una "red". Todavía no es privada. Puede comprobarlo con ping(8) y tcpdump(1). Abra una sesión en la puerta de enlace y ejecute
tcpdump dst host 192.168.2.1
En otra sesión en el mismo equipo ejecute
ping 192.168.2.1
Verá algo muy parecido a esto:
16:10:24.018080 192.168.1.1 > 192.168.2.1: icmp: echo request 16:10:24.018109 192.168.1.1 > 192.168.2.1: icmp: echo reply 16:10:25.018814 192.168.1.1 > 192.168.2.1: icmp: echo request 16:10:25.018847 192.168.1.1 > 192.168.2.1: icmp: echo reply 16:10:26.028896 192.168.1.1 > 192.168.2.1: icmp: echo request 16:10:26.029112 192.168.1.1 > 192.168.2.1: icmp: echo reply
Como puede ver los mensajes ICMP van y vienen sin cifrar. Si usa el parámetro -s en tcpdump(1) para tomar más bytes de datos de estos paquetes verá más información.
Obviamente esto es inaceptable. La siguiente sección explicará cómo asegurar el enlace entre las dos redes para que todo el tráfico se cifre automáticamente.
Sumario:
Configure ambos kernel con "pseudo-device gif".
Edite /etc/rc.conf en la puerta de enlace #1 y añada las siguientes líneas (reemplazando las direcciones IP según sea necesario).
gifconfig_gif0="A.B.C.D W.X.Y.Z" ifconfig_gif0="inet 192.168.1.1 192.168.2.1 netmask 0xffffffff" static_routes="vpn" route_vpn="192.168.2.0 192.168.2.1 netmask 0xffffff00"
Edite la configuración de su cortafuegos (/etc/rc.firewall, o lo que corresponda) en ambos equipos y añada
ipfw add 1 allow ip from any to any via gif0
Haga los cambios oportunos en el /etc/rc.conf de la puerta de enlace #2, invirtiendo el orden de las direcciones IP.
14.10.3.2. Paso 2: Asegurar el enlace
Para asegurar el enlace usaremos IPsec. IPsec ofrece un mecanismo para que dos equipos coincidan en una llave de cifrado, y usar esta llave para cifrar los datos entre los dos equipos.
Existen dos áreas de configuración a tener en cuenta:
Debe existir un mecanismo para que los dos equipos se pongan de acuerdo en el mecanismo de cifrado que van a utilizar. Una vez que los dos equipos se han puesto de acuerdo dice que existe una "asociación de seguridad" entre ellos.
Debe existir un mecanismo para especificar que tráfico debe ser cifrado. Obviamente, usted no querrá cifrar todo su tráfico saliente: solo querrá cifrar el tráfico que es parte de la VPN. Las reglas con las que determinará qué tráfico será cifrado se llaman "políticas de seguridad".
Tanto las asociaciones de seguridad como las políticas de seguridad son responsabilidad del kernel, pero pueden ser modificadas desde el espacio de usuario. Antes de poder hacerlo, tendrá que configurar el kernel para que incluya IPsec y el protocolo ESP (Encapsulated Security Payload). Incluya en el fichero de configuración de su kernel lo siguiente:
options IPSEC options IPSEC_ESP
Recompile y resintale su kernel y reinicie. Como se dijo anteriormente, tendrá que hacer lo mismo en el kernel de las dos puertas de enlace.
Tiene dos opciones cuando se trata de configurar asociaciones de seguridad. Puede configurarlas a mano en los dos equipos, lo que significa elegir el algoritmo de cifrado, las llaves de cifrado, etc, o puede utilizar alguno de los dæmons que implementan el protocolo de intercambio de llaves de Internet (IKE, Internet Key Exchange).
Le recomiendo la segunda opción. Aparte de otras consideraciones es más fácil de configurar.
La edición y despliegue se efectúa con setkey(8). Todo esto se entiende mejor con una analogía. setkey es a las tablas de políticas de seguridad del kernel lo que route(8) es a las tablas de rutas del kernel. También puede usar setkey ver las asociaciones de seguridad en vigor, siguiendo con la analogía, igual que puede usar netstat -r.
Existen numerosos dæmons que pueden encargarse de la gestión de asociaciones de seguridad en FreeBSD. En este texto se muestra cómo usar uno de ellos, racoon (que puede instalar desde security/racoon en la colección de ports de FreeBSD.
El software security/racoon debe ejecutarse en las dos puertas de enlace. En cada equipo debe configurar la dirección IP del otro extremo de la VPN y una llave secreta (que usted puede y debe elegir, y debe ser la misma en ambas puertas de enlace).
Los dos dæmons entran en contacto uno con otro, y confirman que son quienes dicen ser (utilizando la llave secreta que usted configuró). Los dæmons generan una nueva llave secreta, y la utilizan para cifrar el tráfico que discurre a través de la VPN. Periódicamente cambian esta llave, para que incluso si un atacante comprometiera una de las llaves (lo cual es teóricamente cercano a imposible) no le serviriía de mucho: para cuando el atacante haya "crackeado" la llave los dæmons ya habrán escogido una nueva.
El fichero de configuración de racoon está en ${PREFIX}/etc/racoon. No debería tener que hacer demasiados cambios a ese fichero. El otro componente de la configuración de racoon (que sí tendrá que modificar) es la "llave pre-compartida".
La configuración por defecto de racoon espera encontrarla en ${PREFIX}/etc/racoon/psk.txt. Es importante saber que la llave precompartida no es la llave que se utilizará para cifrar el tráfico a través del enlace VPN; solamente es una muestra que permite a los dæmons que administran las llaves confiar el uno en el otro.
psk.txt contiene una línea por cada sitio remoto con el que esté tratando. En nuestro ejemplo, donde existen dos sitios, cada fichero psk.txt contendrá una línea (porque cada extremo de la VPN solo está tratando con un sitio en el otro extremo).
En la puerta de enlace #1 esta línea debería parecerse a esta:
W.X.Y.Z secreto
Esto es, la dirección IP pública del extremo remoto, un espacio en blanco, y una cadena de texto que es el secreto en sí. en el extremo remoto, espacio en blanco, y un texto de cadena que proporcina el secreto. Obviamente, no debe utilizar "secret" como su llave; aplique aquí las reglas y recomendaciones habituales para la elección de contraseñas.
En la puerta de enlace #2 la línea se parecería a esta
A.B.C.D secreto
Esto es, la dirección IP pública del extremo remoto, y la misma llave secreta. psk.txt debe tener modo 0600 (es decir, modo de solo lectura/escritura para root) antes de que ejecute racoon.
Debe ejecutar racoon en ambas puertas de enlace. También tendrá que añadir algunas reglas a su cortafuegos para permitir el tráfico IKE, que se transporta sobre UDP al puerto ISAKMP (Internet Security Association Key Management Protocol). Esto debe estar al principio de las reglas de su cortafuegos.
ipfw add 1 allow udp from A.B.C.D to W.X.Y.Z isakmp ipfw add 1 allow udp from W.X.Y.Z to A.B.C.D isakmp
Una vez que ejecute racoon puede tratar de hacer un ping a una puerta de enlace desde la otra. La conexión todavía no está cifrada porque aún no se han creado las asociaciones de seguridad entre los dos equipos: esto puede llevar un poco de tiempo; es posible que advierta un pequeño retraso antes de los ping empiecen responder.
Una vez creadas las asociaciones de seguridad puede verlas utilizando setkey(8). Ejecute
setkey -D
en cualquiera de los equipos para comprobar la información de la asociación de seguridad.
Ya está resuelta la mitad del problema. La otra mitad es configurar sus políticas de seguridad.
Queremos crear una política de seguridad sensata, así que vamos a revisar lo que tenemos configurado hasta el momento. Esta revisión abarca ambos extremos del enlace.
Cada paquete IP que usted manda tiene una cabecera que contiene datos acerca del paquete. La cabecera incluye la dirección IP de destino y del origen. Como ya sabemos, las direcciones IP privadas como el rango 192.168.x.y no deberían aparezcan en Internet. Dado que es a través de Internet por donde los queremos transmitir los debemos encapsular dentro de otro paquete. Este paquete debe contener tanto la dirección IP de destino y origen públicas sustituidas por las direcciones privadas.
Así que si su paquete saliente empezó pareciendose a este:

tras el encapsulado se parecerá bastante a este:
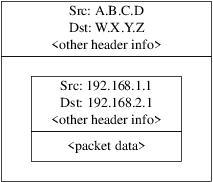
El dispositivo gif se encarga del encapsulado. Como puede ver el paquete tiene una dirección IP real en el exterior, y nuestro paquete original ha sido envuelto como dato dentro del paquete que enviaremos a través de Internet.
Obviamente, queremos que todo el tráfico entre las VPN vaya cifrado. Pongamos esto último en palabras para comprenderlo mejor:
"Si un paquete sale desde A.B.C.D, y tiene como destino W.X.Y.Z, cífralo utilizando las asociaciones de seguridad necesarias."
"Si un paquete llega desde W.X.Y.Z, y tiene como destino A.B.C.D, descífralo utilizando las asociaciones de seguridad necesarias."
Este planteamiento se aproxima bastante, pero no es exactamente lo que queremos hacer. Si lo hiciera así todo el tráfico desde y hacia W.X.Y.Z, incluso el tráfico que no forma parte de la VPN, será cifrado; esto no es lo que queremos. La política correcta es la siguiente:
"Si un paquete sale desde A.B.C.D, y está encapsulando a otro paquete, y tiene como destino W.X.Y.Z, cífralo utilizando las asociaciones de seguridad necesarias."
"Si un paquete llega desde W.X.Y.Z, y está encapsulando a otro paquete, y tiene como destino A.B.C.D, descífralo utilizando las asociaciones de seguridad necesarias."
Un cambio sutil, pero necesario.
Las políticas de seguridad también se imponen utilizando setkey(8). setkey(8) proporciona un lenguaje de configuración para definir la política. Puede introducir las instrucciones de configuración a través de la entrada estándar (stdin), o puede usar la opción -f para especificar un fichero que contenga las instrucciones de configuración.
La configuración en la puerta de enlace #1 (que tiene la dirección IP pública A.B.C.D) para forzar que todo el tráfico saliente hacia W.X.Y.Z vaya cifrado es:
spdadd A.B.C.D/32 W.X.Y.Z/32 ipencap -P out ipsec esp/tunnel/A.B.C.D-W.X.Y.Z/require;
Ponga estas órdenes en un fichero (por ejemplo /etc/ipsec.conf) y ejecute
# setkey -f /etc/ipsec.confspdadd le dice a setkey(8) que queremos añadir una regla a la base de datos de políticas de seguridad. El resto de la línea especifica qué paquetes se ajustarán a esta política. A.B.C.D/32 y W.X.Y.Z/32 son las direcciones IP y máscaras de red que identifican la red o equipos a los que se aplicará esta política. En nuestro caso queremos aplicarla al tráfico entre estos dos equipos. -P out dice que esta política se aplica a paquetes salientes, e ipsec hace que el paquete sea asegurado.
La segunda línea especifica cómo será cifrado este paquete. esp es el protocolo que se utilizará, mientras que tunnel indica que el paquete será después encapsulado en un paquete IPsec. El uso repetido de A.B.C.D y W.X.Y.Z se utiliza para seleccionar la asociación de seguridad a usar, y por último require exige que los paquetes deben cifrarse si concuerdan con esta regla.
Esta regla solo concuerda con paquetes salientes. Necesitará una regla similar para los paquetes entrantes.
spdadd W.X.Y.Z/32 A.B.C.D/32 ipencap -P in ipsec esp/tunnel/W.X.Y.Z-A.B.C.D/require;
Observe el in en lugar del out en este caso, y la inversión necesaria de las direcciones IP.
La otra puerta de enlace (que tiene la dirección IP pública W.X.Y.Z) necesitará reglas similares.
spdadd W.X.Y.Z/32 A.B.C.D/32 ipencap -P out ipsec esp/tunnel/W.X.Y.Z-A.B.C.D/require; spdadd A.B.C.D/32 W.X.Y.Z/32 ipencap -P in ipsec esp/tunnel/A.B.C.D-W.X.Y.Z/require;
Finalmente, necesita añadir reglas a su cortafuegos para permitir la circulación de paquetes ESP e IPENCAP de ida y vuelta. Tendrá que añadir reglas como estas a ambos equipos.
ipfw add 1 allow esp from A.B.C.D to W.X.Y.Z ipfw add 1 allow esp from W.X.Y.Z to A.B.C.D ipfw add 1 allow ipencap from A.B.C.D to W.X.Y.Z ipfw add 1 allow ipencap from W.X.Y.Z to A.B.C.D
Debido a que las reglas son simétricas puede utilizar las mismas reglas en ambas puertas de enlace.
Los paquetes salientes tendrán ahora este aspecto:
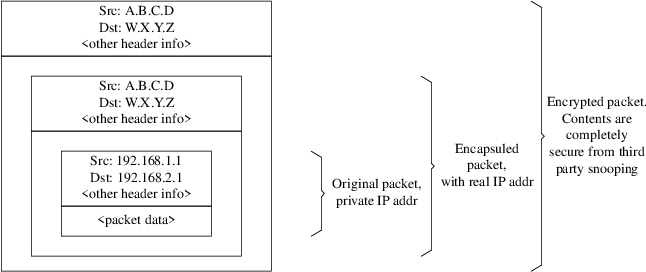
Cuando los paquetes llegan al otro extremo de la VPN serán descifrados (utilizando las asociaciones de seguridad que han sido negociadas por racoon). Después entrarán al interfaz gif, que desenvuelve la segunda capa, hasta que nos quedamos con paquete má interno, que puede entonces viajar a la red interna.
Puede revisar la seguridad utilizando la misma prueba de ping(8) anterior. Primero, inicie una sesión en la puerta de enlace A.B.C.D, y ejecute:
tcpdump dst host 192.168.2.1
En otra sesión en la misma máquina ejecute
ping 192.168.2.1
Debería ver algo similar a lo siguiente:
XXX tcpdump output
ahora, como puede ver, tcpdump(1) muestra los paquetes ESP. Si trata de examinarlos con la opción -s verá basura (aparentemente), debido al cifrado.
Felicidades. Acaba de configurar una VPN entre dos sitios remotos.
Sumario
Configure ambos kernel con:
options IPSEC options IPSEC_ESP
Instale security/racoon. Edite ${PREFIX}/etc/racoon/psk.txt en ambas puertas de enlace añadiendo una entrada para la dirección IP del equipo remoto y una llave secreta que ambos conozcan. Asegúrese de que este fichero esté en modo 0600.
Añada las siguientes líneas a /etc/rc.conf en ambos equipos:
ipsec_enable="YES" ipsec_file="/etc/ipsec.conf"
Crée en ambos equipos un /etc/ipsec.conf que contenga las líneas spdadd necesarias. En la puerta de enlace #1 sería:
spdadd A.B.C.D/32 W.X.Y.Z/32 ipencap -P out ipsec esp/tunnel/A.B.C.D-W.X.Y.Z/require; spdadd W.X.Y.Z/32 A.B.C.D/32 ipencap -P in ipsec esp/tunnel/W.X.Y.Z-A.B.C.D/require;
En la puerta de enlace #2 sería:
spdadd W.X.Y.Z/32 A.B.C.D/32 ipencap -P out ipsec esp/tunnel/W.X.Y.Z-A.B.C.D/require; spdadd A.B.C.D/32 W.X.Y.Z/32 ipencap -P in ipsec esp/tunnel/A.B.C.D-W.X.Y.Z/require;
Añada a su(s) cortafuegos las reglas necesarias para que permita(n) el paso de tráfico IKE, ESP e IPENCAP en ambos equipos:
ipfw add 1 allow udp from A.B.C.D to W.X.Y.Z isakmp ipfw add 1 allow udp from W.X.Y.Z to A.B.C.D isakmp ipfw add 1 allow esp from A.B.C.D to W.X.Y.Z ipfw add 1 allow esp from W.X.Y.Z to A.B.C.D ipfw add 1 allow ipencap from A.B.C.D to W.X.Y.Z ipfw add 1 allow ipencap from W.X.Y.Z to A.B.C.D
Los dos pasos previos deben bastar para levantar la VPN. Las máquinas en cada red seán capaces de dirigirse una a otra utilizando direcciones IP, y todo el tráfico a través del enlace será cifrado de forma automática y segura.
14.11. OpenSSH
OpenSSH es un conjunto de herramientas de conectividad que se usan para acceder a sistemas remotos de forma segura. Puede usarse como sustituto directo de rlogin, rsh, rcp y telnet. Además cualquier otra conexión TCP/IP puede reenviarse o enviarse a través de un túnel a través de SSH. OpenSSH cifra todo el tráfico para eliminar de forma efectiva el espionaje, el secuestro de conexiones, y otros ataques en la capa de red.
OpenSSH está a cargo del proyecto OpenBSD, y está basado en SSH v1.2.12, con todos los errores recientes corregidos y todas las actualizaciones correspondientes. Es compatible con los protocolos SSH 1 y 2. OpenSSH forma parte del sistema base desde FreeBSD 4.0.
14.11.1. Ventajas de utilizar OpenSSH
Normalmente, al utilizar telnet(1) o rlogin(1) los datos se envían a través de la red en limpio, es decir, sin cifrar. Cualquier "sniffer" de red entre el cliente y el servidor puede robar la información de usuario/contraseña o los datos transferidos durante su sesión. OpenSSH ofrece diversos métodos de validación y cifrado para evitar que sucedan estas cosas.
14.11.2. Habilitar sshd
El dæmon sshd está habilitado por defecto FreeBSD 4.X y puede elegir habilitarlo o no durante la instalación en FreeBSD 5.X. Si quiere saber si está habilitado revise si la siguiente línea está en rc.conf:
sshd_enable="YES"Esta línea cargará sshd(8), el programa dæmon de OpenSSH, en el arranque de su sistema. Puede ejecutar el dæmon sshd tecleando sshd en la línea de órdenes.
14.11.3. Cliente SSH
# ssh user@example.com
Host key not found from the list of known hosts.
Are you sure you want to continue connecting (yes/no)? yes
Host 'ejemplo.com' added to the list of known hosts.
usuario@ejemplo.com's password: *******El login continuará como lo haría si fuera una sesión de rlogin o telnet. SSH utiliza un sistema de huellas de llaves para verificar la autenticidad del servidor cuando el cliente se conecta. Se le pide al usuario que introduzca yes solamente la primera vez que se conecta. Todos los intentos futuros de login se verifican contra la huella de la llave guardada la primera vez. El cliente SSH le alertará si la huella guardada difiere de la huella recibida en futuros intentos de acceso al sistema. Las huellas se guardan en ~/.ssh/known_hosts, y en ~/.ssh/known_hosts2 las huellas SSH v2.
Por defecto las versiones recientes de los servidores OpenSSH solamente aceptan conexiones SSH v2. El cliente utilizará la versión 2 si es posible y pasará como respaldo a la versión 1. El cliente puede también ser obligado a utilizar una u otra pasándole -1 o -2, respectivamente para la versión 1 y la versión 2. Se mantiene la compatibilidad del cliente con la versión 1 para mantener la compatibilidad con versiones antiguas.
14.11.4. Copia segura
scp(1) funciona de manera muy similar a rcp(1); copia un fichero desde o hacia un sistema remoto, con la diferencia de que lo hace de una forma segura.
# scp usuario@ejemplo.com:/COPYRIGHT COPYRIGHT
usuario@ejemplo.com's password: *******
COPYRIGHT 100% |*****************************| 4735
00:00
#Ya que la huella se guardó en este equipo durante el ejemplo anterior se verifica ahora al utilizar scp(1).
14.11.5. Configuración
Los ficheros de configuración del sistema tanto para el dæmon OpenSSH como para el cliente están en /etc/ssh.
ssh_config contiene las opciones del cliente, mientras que sshd_config configura el dæmon.
Además las opciones sshd_program (/usr/sbin/sshd por defecto), y sshd_flags de rc.conf ofrecer más niveles de configuración.
14.11.6. ssh-keygen
ssh-keygen(1) le permite validar a un usuario sin pedirle la contraseña:
% ssh-keygen -t dsa
Generating public/private dsa key pair.
Enter file in which to save the key (/home/user/.ssh/id_dsa):
Created directory '/home/user/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/user/.ssh/id_dsa.
Your public key has been saved in /home/user/.ssh/id_dsa.pub.
The key fingerprint is:
bb:48:db:f2:93:57:80:b6:aa:bc:f5:d5:ba:8f:79:17 usuario@host.ejemplo.comssh-keygen(1) creará un par de llaves pública y privada para usar en la validación. La llave privada se guarda en ~/.ssh/id_dsa o en ~/.ssh/id_rsa, mientras que la llave pública se guarda en ~/.ssh/id_dsa.pub o en ~/.ssh/id_rsa.pub, respectivamente para llaves DSA y RSA. La llave pública debe guardarse en el ~/.ssh/authorized_keys de la máquina remota para que la configuración funcione. Las llaves RSA versión 1 deben guardarse en ~/.ssh/authorized_keys.
De este modo permitirá conexiones a la máquina remota mediante llaves SSH en lugar de contraseñas.
Si usa una contraseña al ejecutar ssh-keygen(1), se le pedirá al usuario una contraseña cada vez que quiera utilizar la llave privada. ssh-agent(1) puede evitar la molestia de introducir repetidamente frases largas. esto se explica má adelante, en la ssh-agent y ssh-add.
Las opciones y ficheros pueden ser diferentes según la versión de OpenSSH que tenga en su sistema; para evitar problemas consulte la página de manual ssh-keygen(1). |
14.11.7. ssh-agent y ssh-add
ssh-agent(1) y ssh-add(1) ofrecen métodos para que las llaves SSH se puedan cargar en memoria, permitiendo eliminar la necesidad de teclear la contraseña cada vez que haga falta.
ssh-agent(1) gestionará la validación utilizando la llave (o llaves) privada que le cargue. ssh-agent(1) se usa para lanzar otras aplicaciones. En el nivel más básico puede generar una shell o a un nivel más avanzado un gestor de ventanas.
Para usar ssh-agent(1) en una shell necesitará primero ser invocado como argumento por una shell. Segundo, añada la identidad ejecutando ssh-add(1) y facilitando la contraseña de la llave privada. Completados estos pasos el usuario puede hacer ssh(1) a cualquier equipo que tenga instalada la llave pública correspondiente. Por ejemplo:
% ssh-agent csh
% ssh-add
Enter passphrase for /home/user/.ssh/id_dsa:
Identity added: /home/user/.ssh/id_dsa (/home/user/.ssh/id_dsa)
%Para utilizar ssh-agent(1) en X11 tendrá que incluir una llamada a ssh-agent(1) en ~/.xinitrc. De este modo ofrecerá los servicios de ssh-agent(1) a todos los programas lanzados en X11. Veamos un ejemplo de ~/.xinitrc:
exec ssh-agent startxfce4
Esto lanzaría ssh-agent(1), que a su vez lanzaría XFCE cada vez que inicie X11. Hecho esto y una vez reiniciado X11 para aplicar los cambios puede ejecutar ssh-add(1) para cargar todas sus llaves SSH.
14.11.8. Túneles SSH
OpenSSH permite crear un túnel en el que encapsular otro protocolo en una sesión cifrada.
La siguiente orden le dice a ssh(1) que cree un túnel para telnet:
% ssh -2 -N -f -L 5023:localhost:23 usuario@foo.ejemplo.com
%Veamos las opciones que se le han suministrado a ssh:
-2Obliga a
ssha utilizar la versión 2 del protocolo. (No la use si está trabajando con servidores SSH antiguos)-NIndica que no se ejecutará una orden remota, o solamente túnel. Si se omite,
sshiniciaría una sesión normal.-fObliga a
ssha ejecutarse en segundo plano.-LIndica un túnel local según el esquema puerto local:equipo remoto:puerto remoto.
usuario@foo.ejemplo.comEl servidor SSH remoto.
Un túnel SSH crea un socket que escucha en localhost en el puerto especificado. Luego reenvía cualquier conexión recibida en el puerto/equipo local vía la conexión SSH al puerto o equipo remoto especificado.
En el ejemplo el puerto 5023 en localhost se reenvía al puerto 23 del localhost de la máquina remota. Ya que 23 es telnet, esto crearía una sesión telnet segura a través de un túnel SSH.
Puede usar esto para encapsular cualquier otro protocolo TCP inseguro como SMTP, POP3, FTP, etc.
Ejemplo 1. Uso de SSH para crear un túnel seguro para SMTP
% ssh -2 -N -f -L 5025:localhost:25 usuario@correo.ejemplo.com
usuario@correo.ejemplo.com's password: *****
% telnet localhost 5025
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
220 correo.ejemplo.com ESMTPPuede usar esta técnica junto con ssh-keygen(1) y cuentas adicionales de usuario para crear un entorno más transparente, esto es, más cómodo. Puede usar llaves en lugar de teclear contraseñas y puede ejecutar los túneles de varios usuarios.
14.11.8.1. Ejemplos prácticos de túneles SSH
14.11.8.1.1. Acceso seguro a un servidor POP3
En el trabajo hay un servidor SSH que acepta conexiones desde el exterior. En la misma red de la oficina reside un servidor de correo que ejecuta un servidor POP3. La red, o ruta de red entre su casa y oficina puede o no ser completamente de fiar. Debido a esto necesita revisar su correo electrónico de forma segura. La solución es crear una conexión SSH al servidor SSH de su oficina y llegar por un túnel al servidor de correo.
% ssh -2 -N -f -L 2110:correo.ejemplo.com:110 usuario@servidor-ssh.ejemplo.com
usuario@servidor-ssh.ejemplo.com's password: ******cuando el túnel esté funcionando haga que su cliente de correo envíe peticiones POP3 a localhost en el puerto 2110. La conexión será reenviada de forma totalmente segura a traveés del túnel a correo.ejemplo.com.
14.11.8.1.2. Saltarse un cortafuegos draconiano
Algunos administradores de red imponen reglas de cortafuegos extremadamente draconianas, filtrando no solo las conexiones entrantes, sino también las salientes. Tal vez solo se le otorgue acceso a máquinas remotas a través de los puertos 22 y 80 para ssh y navegar en web.
Tal vez quiera acceder a otros servicios (que tal vez ni siquiera estén relacionados con el trabajo), como un servidor Ogg Vorbis para escuchar música. Si ese servidor Ogg Vorbis transmite en un puerto que no sea el 22 o el 80 no podrá tener acceso a él.
La solución es crear una conexión SSH fuera del cortafuegos de su red y utilizarla para hacer un túnel al servidor Ogg Vorbis.
% ssh -2 -N -f -L 8888:musica.ejemplo.com:8000 usuario@sistema-no-filtrado.ejemplo.org
usuario@sistema-no-filtrado.ejemplo.org's password: *******Haga que el programa con el que suele escuchar música haga peticiones a localhost puerto 8888, que será reenviado a musica.ejemplo.com puerto 8000, evadiendo con éxito el cortafuegos.
14.11.9. La opción de usuarios AllowUsers
Limitar qué usuarios pueden entrar y desde dónde suele ser razonable. La opción AllowUsers le permite configurarlo, por ejemplo, para permitir entrar solamente al usuario root desde 192.168.1.32. Puede hacerlo con algo parecido a esto en /etc/ssh/sshd_config:
AllowUsers root@192.168.1.32
Para permitir al usuario admin la entrada desde cualquier lugar, solamente introduzca el nombre de usuario:
AllowUsers admin
Puede listar múltiples usuarios en la misma línea:
AllowUsers root@192.168.1.32 admin
Es importante que incluya a cada usuario que necesite entrar a esta máquina o no podrán entrar. |
Después de hacer los cambios a b /etc/ssh/sshd_config debe decirle a sshd(8) que cargue de nuevo sus ficheros de configuración ejecutando:
# /etc/rc.d/sshd reload14.12. Listas de control de acceso a sistemas de ficheros
Además de otras mejoras del sistema de ficheros como las instantáneas ("snapshots"), FreeBSD 5.0 y siguientes ofrecen las ACL ("Access Control Lists", listas de control de acceso) como un elemento más de seguridad.
Las listas de control de acceso extienden el modelo de permisos estándar de UNIX® de una manera altamente compatible (POSIX®.1e). Esta opción permite al administrador usar con gran provecho un modelo de seguridad más sofisticado.
Para habilitar soporte de ACL en sistemas de ficheros UFS la siguiente opción:
options UFS_ACL
debe ser compilada en el kernel. Si esta opción no ha sido compilada, se mostrará un mensaje de advertencia si se intenta montar un sistema de ficheros que soporte ACL. Esta opción viene incluida en el kernel GENERIC. Las ACL dependen de los atributos extendidos habilitados en el sistema de ficheros. Los atributos extendidos están incluidos por defecto en la nueva generación de sistemas de ficheros UNIX® UFS2.
Los atributos extendidos pueden usarse también en UFS1 pero requieren una carga de trabajo mucho más elevada que en UFS2. El rendimiento de los atributos extendidos es, también, notablemente mayor en UFS2. Por todo esto si quiere usar ACL le recomendamos encarecidamente que use UFS2. |
LasACL se habilitadan mediante una bandera administrativa durante el montaje, acls, en el fichero /etc/fstab. La bandera de montaje puede también activarse de forma permanente mediante tunefs(8) para modificar una bandera de superbloque ACLs en la cabecera del sistema de ficheros. En general es preferible usar la bandera de superbloque por varios motivos:
La bandera de montaje ACL no puede cambiarse por un remontaje (mount(8)
-u), sino con un completo umount(8) y un mount(8). Esto significa que no se pueden habilitar las ACL en el sistema de ficheros raíz después del arranque. También significa que no se puede cambiar la disposición de un de ficheros una vez que se ha comenzado a usar.Activar la bandera de superbloque provocará que el sistema de ficheros se monte siempre con las ACL habilitadas incluso si no existe una entrada en fstab o si los dispositivos se reordenan. Esto es así para prevenir un montaje accidental del sistema de ficheros sin tener las ACL habilitadas, que podría resultar en que se impongan de forma inadecuada las ACL, y en consecuencia problema de seguridad.
Podemos cambiar el comportamiento de las ACL para permitirle a la bandera ser habilitada sin un mount(8) completo, pero puede salirle el tiro por la culata si activa las ACL, luego las desactiva, y después las vuelve a activar sin configurar desde cero las atributos extendidos. En general, una vez que se han deshabilitado las ACL en un sistema de ficheros no deben dehabilitarse, ya que la protección de ficheros resultante puede no ser compatible las que esperan los usuarios del sistema, y al volver a activar las ACL volver a asignar las ACL a ficheros cuyos permisos hubieran sido cambiados, lo que puede desenbocar en un escenario impredecible. |
Los sistemas de ficheros con ACL habilitadas tienen un signo + (más) al visualizar sus configuraciones de permisos. Por ejemplo:
drwx------ 2 robert robert 512 Dec 27 11:54 private drwxrwx---+ 2 robert robert 512 Dec 23 10:57 directorio1 drwxrwx---+ 2 robert robert 512 Dec 22 10:20 directorio2 drwxrwx---+ 2 robert robert 512 Dec 27 11:57 directorio3 drwxr-xr-x 2 robert robert 512 Nov 10 11:54 public_html
Aquí vemos que los directorios directorio1, directorio2, y directorio3 están usando ACL. El directorio public_html no.
14.12.1. Uso de ACL
Las ACLs del sistema de ficheros pueden comprobarse con getfacl(1). Por ejemplo, para ver las configuraciones de ACL del fichero test, uno podría usar lo siguiente:
% getfacl test
#file:test
#owner:1001
#group:1001
user::rw-
group::r--
other::r--Para cambiar las configuraciones de las ACL en este fichero use setfacl(1). Observe:
% setfacl -k testLa bandera -k eliminará todas las ACLs definidas para un fichero o sistema ficheros. El método preferible sería utilizar -b, ya que deja los campos básicos imprescindibles para que las ACL sigan funcionando.
% setfacl -m u:trhodes:rwx,group:web:r--,o::--- testLa opción -m se usa para modificar las entradas por defecto de las ACL. Debido a que no había entradas predefinidas puesto que fueron eliminadas por la orden anterior, restauraremos las opciones por defecto y asignará las opciones listadas. Tenga en cuenta que si añade un nuevo usuario o grupo aparecerá el error Invalid argument en la salida estándar stdout.
14.13. Monitorización de fallos de seguridad de aplicaciones
En estos últimos años el mundo de la seguridad ha hecho grandes avances en cuanto a la gestión de las vulnerabilidades. La amenaza de asaltos a los sistemas se incrementa cuando se instalan y configuran aplicaciones de muy diversas procedencias en virtualmente cualquier sistema operativo disponible.
La evaluación de vulnerabilidades es un factor clave en la seguridad; aunque FreeBSD libere avisos de seguridad relacionados con el sistema base, llevar la gestión de vulnerabilidades hasta cada aplicación que se puede instalar en FreeBSD va mucho más allá de la capacidad del proyecto FreeBSD. A pesar de esto existe una forma de mitigar las vulnerabilidades de esas aplicaciones y advertir a los administradores sobre los problemas de seguridad a medida que se detectan. Portaudit existe para hacer ese trabajo.
El port security/portaudit consulta una base de datos, actualizada y mantenida por el equipo de seguridad y por los desarrolladores de FreeBSD en busca de incidentes de seguridad que hayan sido detectados.
Si quiere usar Portaudit instálelo desde la colección de ports:
# cd /usr/ports/security/portaudit && make install cleanDurante el proceso de instalación los ficheros de configuración de periodic(8) se actualizan haciendo que Portaudit aparezca en el mensaje sobre la seguridad del sistema que diariamente Recuerde que ese correo (que se envia a la cuenta root es muy importante y debería leerlo. No hay ninguna configuración que deba modificar o crear.
Después de la instalación un administrador debe actualizar la base de datos alojada en local en /var/db/portaudit mediante:
# portaudit -FLa base de datos será actualizada automáticamente durante la ejecución de periodic(8); así que la orden anterior es totalmente opcional. Solo se necesita para los siguientes ejemplos. |
Si quiere comproblar si entre las aplicaciones que haya instalado desde el árbol de ports en su sistema hay problemas de seguridad sólo tiene que ejecutar lo siguiente:
# portaudit -aEste es un ejemplo de la salida:
Affected package: cups-base-1.1.22.0_1 Type of problem: cups-base -- HPGL buffer overflow vulnerability. Reference: <http://www.FreeBSD.org/ports/portaudit/40a3bca2-6809-11d9-a9e7-0001020eed82.html> 1 problem(s) in your installed packages found. You are advised to update or deinstall the affected package(s) immediately.
El administrador del sistema obtendrá mucha más información sobre el problema de seguridad dirigiendo su navegador web a la URL que aparece en el mensaje. Esto incluye versiones afectadas (por versión de port de FreeBSD), junto con otros sitios web que contengan advertencias de seguridad.
En pocas palabras, Portaudit es un programa muy poderoso y extremadamente útil cuando se combina con el port Portupgrade.
14.14. FreeBSD Security Advisories
Como muchos sistemas operativos con calidad de producción, FreeBSD publica "Security Advisories" (advertencias de seguridad. Estas advertencias suelen enviarse por correo a las listas de seguridad e incluidas en la Errata solamente después de que la versión apropiada haya sido corregida. Esta sección tiene como fin explicar en qué consiste una advertencia de seguridad, cómo entenderla y qué medidas hay que tomar para parchear el sistema.
14.14.1. ?Qué aspecto tiene una advertencia de seguridad?
Las advertencias de seguridad de FreeBSD tienen un aspecto similar a la que se muestra aquí. Fué enviada a la lista de correo Lista de correo para anuncios de seguridad que afectan a FreeBSD.
=============================================================================
FreeBSD-SA-XX:XX.UTIL Security Advisory
The FreeBSD Project
Topic: denial of service due to some problem (1)
Category: core (2)
Module: sys (3)
Announced: 2003-09-23 (4)
Credits: Person@EMAIL-ADDRESS (5)
Affects: All releases of FreeBSD (6)
FreeBSD 4-STABLE prior to the correction date
Corrected: 2003-09-23 16:42:59 UTC (RELENG_4, 4.9-PRERELEASE)
2003-09-23 20:08:42 UTC (RELENG_5_1, 5.1-RELEASE-p6)
2003-09-23 20:07:06 UTC (RELENG_5_0, 5.0-RELEASE-p15)
2003-09-23 16:44:58 UTC (RELENG_4_8, 4.8-RELEASE-p8)
2003-09-23 16:47:34 UTC (RELENG_4_7, 4.7-RELEASE-p18)
2003-09-23 16:49:46 UTC (RELENG_4_6, 4.6-RELEASE-p21)
2003-09-23 16:51:24 UTC (RELENG_4_5, 4.5-RELEASE-p33)
2003-09-23 16:52:45 UTC (RELENG_4_4, 4.4-RELEASE-p43)
2003-09-23 16:54:39 UTC (RELENG_4_3, 4.3-RELEASE-p39) (7)
FreeBSD only: NO (8)
For general information regarding FreeBSD Security Advisories,
including descriptions of the fields above, security branches, and the
following sections, please visit
http://www.FreeBSD.org/security/.
I. Background (9)
II. Problem Description (10)
III. Impact (11)
IV. Workaround (12)
V. Solution (13)
VI. Correction details (14)
VII. References (15)| 1 | El campo Topic indica cuál es exactamente el problema. Básicamente es la introducción de la advertencia de seguridad actual e indica el uso malintencionado que puede darse a la vulnerabilidad. |
| 2 | Category se refiere a la parte afectada del sistema, que puede ser core, contrib o ports. La categoría core significa que la vulnerabilidad afecta a un componente central del sistema operativo FreeBSD. La categoría contrib significa que la vulnerabilidad afecta a software que no ha sido desarrollado por el proyecto FreeBSD, como sendmail. La categoría ports indica que la vulnerabilidad afecta a software incluido en la colección de ports. |
| 3 | El campo Module se refiere a la ubicación del componente, por ejemplo sys. En este ejemplo vemos que está afectado el módulo sys; por lo tanto esta vulnerabilidad afecta a componentes utilizados dentro del kernel. |
| 4 | El campo Announced refleja la fecha de publicación de la advertencia de seguridad fué publicada o anunciada al mundo. Esto significa que el equipo de seguridad ha verificado que el que el problema existe y que se ha incluido un parche que soluciona el problema en el repositorio de código fuente de FreeBSD. |
| 5 | El campo Credits le da el crédito al individuo u organización que descubrió y reportó la vulnerabilidad. |
| 6 | El campo Affects explica a qué versiones de FreeBSD afecta esta vulnerabilidad. En el caso del kernel una rápida revisión de la salida de ident en los
ficheros afectados ayudará a determinar la versión. En el caso de de los ports el número de versión aparece después del nombre del port en /var/db/pkg. Si el sistema no se sincroniza con el repositorio CVS de FreeBSD y se reconstruye diariamente, existe la posibilidad de que esté afectado por el problema de seguridad. |
| 7 | El campo Corrected indica la fecha, hora, zona horaria y versión de FreeBSD en que fué corregido. |
| 8 | El campo FreeBSD only indica si la vulnerabilidad afecta solamente a FreeBSD o si afecta también a otros sistemas operativos. |
| 9 | El campo Background informa acerca de qué es exactamente la aplicación afectada. La mayor parte de las veces se refiere a por qué la aplicación existe en
FreeBSD, para qué se usa y un poco de información de cómo llegó llegó a ocupar el lugar que ocupa en el sistema o el árbol de ports. |
| 10 | El campo Problem Description explica el problema de seguridad en profundidad. Puede incluir información del código erróneo, o incluso cómo puede usarse maliciosamente el error para abrir un agujero de seguridad. |
| 11 | El campo Impact describe el tipo de impacto que el problema pueda tener en un sistema. Por ejemplo, esto puede ser desde un ataque de denegación de servicio, hasta una escalada de privilegios de usuario, o incluso ofrecer al atacante acceso de superusuario. |
| 12 | El campo Workaround ofrece una solución temoral posible para los administradores de sistemas que tal vez no puedan actualizar el sistema. Esto puede deberse a la falta de tiempo, disponibilidad de de red, o a muchas otras razones. A pesar de todo la la seguridad no se debe tomar a la ligera y un sistema afectado debe parchearse al menos aplicar una solución temporal para el agujero de seguridad. |
| 13 | El campo Solution ofrece instrucciones para parchear el sistema afectado. Este es un método paso a paso, probado y verificado para parchear un sistema y que trabaje seguro. |
| 14 | El campo Correction Details despliega la rama del CVS o el nombre de la versión con los puntos cambiados a guiones bajos. También muestra el número de revisión de los ficheros afectados dentro de cada rama. |
| 15 | El campo References suele ofrecer fuentes adicionales de información: URL, libros, listas de correo y grupos de noticias. |
14.15. Contabilidad de procesos
La contabilidad de procesos es un método de seguridad en el cual un administrador puede mantener un seguimiento de los recursos del sistema utilizados, su distribución entre los usuarios, ofrecer monitorización del sistema y seguir la pista mínimamente a las órdenes de usuario.
Esto en realidad tiene sus puntos positivos y negativos. Uno de los positivos es que una intrusión puede minimizarse en el momento de producirse. Uno negativo es la cantidad de logs generados por la contabilidad de procesos y el espacio de disco que requieren. Esta sección guiará al administrador a través de los fundamentos de la contabilidad de procesos.
14.15.1. Cómo habilitar y utilizar la contabilidad de procesos
Antes de poder usar la contabilidad de procesos tendrá que habilitarla. Ejecute la siguiente orden:
# touch /var/account/acct
# accton /var/account/acct
# echo 'accounting_enable="YES"' >> /etc/rc.confUna vez habilitada, la contabilidad de procesos empezará a seguir el rastro de estadísticas de la CPU, órdenes, etc. Todos los logs de contabilidad están en un formato ilegible para humanos, pero accesibles para sa(8). Si se ejecuta sin opciones, sa imprimirá información sobre el número de llamadas por usuario, el tiempo total transcurrido expresado en minutos, el tiempo total de CPU y de usuario en minutos, el número medio de operaciones de E/S, etc.
Para ver información acerca de las órdenes que se están ejecutados puede usar la lastcomm(1). lastcomm imprime órdenes ejecutadas por los usuarios en ttys(5) específicas. Veamos un ejemplo:
# lastcomm ls
trhodes ttyp1Imprimiría todas las veces (conocidas) que el usuario trhodes ha usado ls en la terminal ttyp1.
Hay muchas más opciones que pueden serle muy útiles. Si quiere conocerlas consulte las páginas de manual lastcomm(1), acct(5) y sa(8).
Last modified on: 18 de febrero de 2025 by Fernando Apesteguía