
Additional ABI support:.
Local package initialization:.
Additional TCP options:.
Fri Sep 20 13:01:06 EEST 2002
FreeBSD/i386 (pc3.example.org) (ttyv0)
login:Chapitre 3. Quelques bases d'UNIX
This translation may be out of date. To help with the translations please access the FreeBSD translations instance.
Sommaire
3.1. Synopsis
Le chapitre suivant couvrira les commandes et fonctionnalités de base du système d’exploitation FreeBSD. La plupart de ces informations sera valable pour n’importe quel système d’exploitation UNIX®. Soyez libre de passer ce chapitre si vous êtes familier avec ces informations. Si vous êtes nouveau à FreeBSD, alors vous voudrez certainement lire attentivement ce chapitre.
Après la lecture de ce chapitre, vous saurez:
Comment utiliser les "consoles virtuelles" de FreeBSD.
Comment les permissions des fichiers d’UNIX® fonctionnent ainsi que l’utilisation des indicateurs de fichiers sous FreeBSD.
L’architecture par défaut du système de fichiers sous FreeBSD.
L’organisation des disques sous FreeBSD.
Comment monter et démonter des systèmes de fichier.
Ce que sont les processus, daemons et signaux.
Ce qu’est un interpréteur de commande, et comment changer votre environnement de session par défaut.
Comment utiliser les éditeurs de texte de base.
Ce que sont les périphériques et les fichiers spéciaux de périphérique.
Quel est le format des binaires utilisé sous FreeBSD.
Comment lire les pages de manuel pour plus d’information.
3.2. Consoles virtuelles terminaux
FreeBSD peut être utilisé de diverses façons. L’une d’elles est en tapant des commandes sur un terminal texte. Une bonne partie de la flexibilité et de la puissance d’un système d’exploitation UNIX® est directement disponible sous vos mains en utilisant FreeBSD de cette manière. Cette section décrit ce que sont les "terminaux" et les "consoles", et comment les utiliser sous FreeBSD.
3.2.1. La console
Si vous n’avez pas configuré FreeBSD pour lancer automatiquement un environnement graphique au démarrage, le système vous présentera une invite d’ouverture de session après son démarrage, juste après la fin des procédures de démarrage. Vous verrez quelque chose de similaire à:
Les messages pourront être différents sur votre système, mais cela devrait y ressembler. Les deux dernières lignes sont celles qui nous intéressent actuellement. La seconde de ces lignes nous donne:
FreeBSD/i386 (pc3.example.org) (ttyv0)
Cette ligne contient quelques éléments d’information sur le système que vous venez de démarrer. Vous êtes en train de lire une console "FreeBSD", tournant sur un processeur Intel ou compatible de la famille x86. Le nom de cette machine (chaque machine UNIX® a un nom) est pc3.example.org, et vous regardez actuellement sa console système-le terminal ttyv0.
Et enfin, la dernière ligne est toujours:
login:
C’est le moment où vous êtes supposé taper votre "nom d’utilisateur" pour vous attacher au système FreeBSD. La section suivante décrit comment procéder.
3.2.2. Ouvrir une session sur un système FreeBSD
FreeBSD est un système multi-utilisateur, multi-processeur. C’est la description formelle qui est habituellement donnée pour un système qui peut être utilisé par différentes personnes, qui exécutent simultanément de nombreux programmes sur une machine individuelle.
Chaque système multi-utilisateur a besoin d’un moyen pour distinguer un "utilisateur" du reste. Sous FreeBSD (et sous tous les systèmes de type UNIX®), cela est effectué en demandant à chaque utilisateur de "s’attacher" au système avant d’être en mesure d’exécuter des programmes. Chaque utilisateur possède un nom unique (le nom d’utilisateur) et une clé secrète personnelle (le mot de passe). FreeBSD demandera ces deux éléments avant d’autoriser un utilisateur à lancer un programme.
Juste après que FreeBSD ait démarré et en ait terminé avec l’exécution des procédures de démarrage, il présentera une invite et demandera un nom d’utilisateur valide:
login:Pour cet exemple, supposons que votre nom d’utilisateur est john. Tapez john à cette invite puis appuyez sur Entrée. Alors vous devrez être invité à entrer un "mot de passe":
login: john
Password:Tapez maintenant le mot de passe de john, et appuyez sur Entrée. Le mot de passe n’est pas affiché! Vous n’avez pas à vous préoccuper de cela maintenant. Il suffit de penser que cela est fait pour des raisons de sécurité.
Si vous avez tapé correctement votre mot de passe, vous devriez être maintenant attaché au système et prêt à essayer toutes les commandes disponibles.
Vous devriez voir apparaître le MOTD ou message du jour suivi de l’invite de commande (un caractère #, $, ou %). Cela indique que vous avez ouvert avec succès une session sous FreeBSD.
3.2.3. Consoles multiples
Exécuter des commandes UNIX® dans une console est bien beau, mais FreeBSD peut exécuter plusieurs programmes à la fois. Avoir une seule console sur laquelle les commandes peuvent être tapées serait un peu du gaspillage quand un système d’exploitation comme FreeBSD peut exécuter des dizaines de programmes en même temps. C’est ici que des "consoles virtuelles" peuvent être vraiment utiles.
FreeBSD peut être configuré pour présenter de nombreuses consoles virtuelles. Vous pouvez basculer d’une console virtuelle à une autre en utilisant une combinaison de touches sur votre clavier. Chaque console a son propre canal de sortie, et FreeBSD prend soin de rediriger correctement les entrées au clavier et la sortie vers écran quand vous basculez d’une console virtuelle à la suivante.
Des combinaisons de touches spécifiques ont été réservées par FreeBSD pour le basculement entre consoles. Vous pouvez utiliser Alt+F1, Alt+F2, jusqu’à Alt+F8 pour basculer vers une console virtuelle différente sous FreeBSD.
Quand vous basculez d’une console à une autre, FreeBSD prend soin de sauvegarder et restaurer la sortie d’écran. Il en résulte l'"illusion" d’avoir plusieurs écrans et claviers "virtuels" que vous pouvez utiliser pour taper des commandes pour FreeBSD. Les programmes que vous lancez sur une console virtuelle ne cessent pas de tourner quand cette console n’est plus visible. Ils continuent de s’exécuter quand vous avez basculé vers une console virtuelle différente.
3.2.4. Le fichier /etc/ttys
La configuration par défaut de FreeBSD démarre avec huit consoles virtuelles. Cependant ce n’est pas un paramétrage fixe, et vous pouvez aisément personnaliser votre installation pour démarrer avec plus ou moins de consoles virtuelles. Le nombre et les paramétrages des consoles virtuelles sont configurés dans le fichier /etc/ttys.
Vous pouvez utiliser le fichier /etc/ttys pour configurer les consoles virtuelles de FreeBSD. Chaque ligne non-commentée dans ce fichier (les lignes qui ne débutent pas par le caractère #) contient le paramétrage d’un terminal ou d’une console virtuelle. La version par défaut de ce fichier livrée avec FreeBSD configure neuf consoles virtuelles, et en active huit. Ce sont les lignes commençant avec le terme ttyv:
# name getty type status comments # ttyv0 "/usr/libexec/getty Pc" cons25 on secure # Virtual terminals ttyv1 "/usr/libexec/getty Pc" cons25 on secure ttyv2 "/usr/libexec/getty Pc" cons25 on secure ttyv3 "/usr/libexec/getty Pc" cons25 on secure ttyv4 "/usr/libexec/getty Pc" cons25 on secure ttyv5 "/usr/libexec/getty Pc" cons25 on secure ttyv6 "/usr/libexec/getty Pc" cons25 on secure ttyv7 "/usr/libexec/getty Pc" cons25 on secure ttyv8 "/usr/X11R6/bin/xdm -nodaemon" xterm off secure
Pour une description détaillée de chaque colonne de ce fichier et toutes les options que vous pouvez utiliser pour configurer les consoles virtuelles, consultez la page de manuel ttys(5).
3.2.5. Console en mode mono-utilisateur
Une description détaillée de ce qu’est "le mode mono-utilisateur" peut être trouvée dans Mode mono-utilisateur. Il est important de noter qu’il n’y a qu’une console de disponible quand vous exécutez FreeBSD en mode mono-utilisateur. Il n’y a aucune console virtuelle de disponible. Le paramétrage de la console en mode mono-utilisateur peut être également trouvé dans le fichier /etc/ttys. Recherchez la ligne qui commence avec le mot console:
# name getty type status comments # # If console is marked "insecure", then init will ask for the root password # when going to single-user mode. console none unknown off secure
Comme l’indiquent les commentaires au-dessus de la ligne Cependant faites attention quand vous modifiez cela pour |
3.2.6. Modifier la résolution de la console
La résolution (ou encore le mode vidéo) de la console FreeBSD peut être réglée à 1024x768, 1280x1024, ou tout autre résolution supportée par le circuit graphique et le moniteur. Pour utiliser une résolution vidéo différente vous devez en premier lieu recompiler votre noyau en ajoutant deux options supplémentaires:
options VESA options SC_PIXEL_MODE
Une fois votre noyau recompilé avec ces deux options, vous pouvez déterminer quels sont les modes vidéo supportés par votre matériel en utilisant l’outil vidcontrol(1). Pour obtenir une liste des modes supportés, tapez la ligne suivante:
# vidcontrol -i modeLa sortie de cette commande est une liste des modes vidéo que supporte votre matériel. Vous pouvez ensuite décider d’utiliser un nouveau mode en le passant à la commande vidcontrol(1) tout en ayant les droits de root:
# vidcontrol MODE_279Si le nouveau mode vidéo est satisfaisant, il peut être activé au démarrage de manière permanente en le configurant dans le fichier /etc/rc.conf:
allscreens_flags="MODE_279"
3.3. Permissions
FreeBSD, étant un descendant direct de l’UNIX® BSD, est basé sur plusieurs concepts clés d’UNIX®. Le premier, et le plus prononcé, est le fait que FreeBSD est un système d’exploitation multi-utilisateurs. Le système peut gérer plusieurs utilisateurs travaillant tous simultanément sur des tâches complètement indépendantes. Le système est responsable du partage correct et de la gestion des requêtes pour les périphériques matériels, la mémoire, et le temps CPU de façon équitable entre chaque utilisateur.
Puisque le système est capable de supporter des utilisateurs multiples, tout ce que le système gère possède un ensemble de permissions définissant qui peut écrire, lire, et exécuter la ressource. Ces permissions sont stockées sous forme de trois octets divisés en trois parties, une pour le propriétaire du fichier, une pour le groupe auquel appartient le fichier, et une autre pour le reste du monde. Cette représentation numérique fonctionne comme ceci:
| Valeur | Permission | Contenu du répertoire |
|---|---|---|
0 | Pas d’accès en lecture, pas d’accès en écriture, pas d’accès en exécution |
|
1 | Pas d’accès en lecture, pas d’accès en écriture, exécution |
|
2 | Pas d’accès en lecture, écriture, pas d’accès en exécution |
|
3 | Pas d’accès en lecture, écriture, exécution |
|
4 | Lecture, pas d’accès en écriture, pas d’accès en exécution |
|
5 | Lecture, pas d’accès en écriture, exécution |
|
6 | Lecture, écriture, pas d’accès en exécution |
|
7 | Lecture, écriture, exécution |
|
Vous pouvez utiliser l’option -l avec la commande ls(1) pour afficher le contenu du répertoire sous forme une longue et détaillée qui inclut une colonne avec des informations sur les permissions d’accès des fichiers pour le propriétaire, le groupe, et le reste du monde. Par exemple un ls -l dans un répertoire quelconque devrait donner:
% ls -l
total 530
-rw-r--r-- 1 root wheel 512 Sep 5 12:31 myfile
-rw-r--r-- 1 root wheel 512 Sep 5 12:31 otherfile
-rw-r--r-- 1 root wheel 7680 Sep 5 12:31 email.txt
...Voici comment est divisée la première colonne de l’affichage généré par ls -l:
-rw-r--r--Le premier caractère (le plus à gauche) indique si c’est un fichier normal, un répertoire, ou un périphérique mode caractère, une socket, ou tout autre pseudo-périphérique. Dans ce cas, - indique un fichier normal. Les trois caractères suivants, rw- dans cet exemple, donnent les permissions pour le propriétaire du fichier. Les trois caractères qui suivent, r--, donnent les permissions pour le groupe auquel appartient le fichier. Les trois derniers caractères, r--, donnent les permissions pour le reste du monde. Un tiret signifie que la permission est désactivée. Dans le cas de ce fichier, les permissions sont telles que le propriétaire peut lire et écrire le fichier, le groupe peut lire le fichier, et le reste du monde peut seulement lire le fichier. D’après la table ci-dessus, les permissions pour ce fichier seraient 644, où chaque chiffre représente les trois parties des permissions du fichier.
Tout cela est bien beau, mais comment le système contrôle les permissions sur les périphériques? En fait FreeBSD traite la plupart des périphériques sous la forme d’un fichier que les programmes peuvent ouvrir, lire, et écrire des données dessus comme tout autre fichier. Ces périphériques spéciaux sont stockés dans le répertoire /dev.
Les répertoires sont aussi traités comme des fichiers. Ils ont des droits en lecture, écriture et exécution. Le bit d’exécution pour un répertoire a une signification légèrement différente que pour les fichiers. Quand un répertoire est marqué exécutable, cela signifie qu’il peut être traversé, i.e. il est possible d’utiliser "cd" (changement de répertoire). Ceci signifie également qu’à l’intérieur du répertoire il est possible d’accéder aux fichiers dont les noms sont connus (en fonction, bien sûr, des permissions sur les fichiers eux-mêmes).
En particulier, afin d’obtenir la liste du contenu d’un répertoire, la permission de lecture doit être positionnée sur le répertoire, tandis que pour effacer un fichier dont on connaît le nom, il est nécessaire d’avoir les droits d’écriture et d’exécution sur le répertoire contenant le fichier.
Il y a d’autres types de permissions, mais elles sont principalement employées dans des circonstances spéciales comme les binaires "setuid" et les répertoires "sticky". Si vous désirez plus d’information sur les permissions de fichier et comment les positionner, soyez sûr de consulter la page de manuel chmod(1).
3.3.1. Permissions symboliques
Les permissions symboliques, parfois désignées sous le nom d’expressions symboliques, utilisent des caractères à la place de valeur en octal pour assigner les permissions aux fichiers et répertoires. Les expressions symboliques emploient la syntaxe: (qui) (action) (permissions), avec les valeurs possibles suivantes:
| Option | Lettre | Représente |
|---|---|---|
(qui) | u | Utilisateur |
(qui) | g | Groupe |
(qui) | o | Autre |
(qui) | a | Tous ("le monde entier") |
(action) | + | Ajouter des permissions |
(action) | - | Retirer des permissions |
(action) | = | Fixe les permissions de façon explicite |
(permissions) | r | Lecture |
(permissions) | w | Ecriture |
(permissions) | x | Exécution |
(permissions) | t | bit collant (sticky) |
(permissions) | s | Exécuter avec l’ID utilisateur (UID) ou groupe (GID) |
Ces valeurs sont utilisées avec la commande chmod(1) comme précédemment mais avec des lettres. Par exemple, vous pourriez utiliser la commande suivante pour refuser l’accès au fichier FICHIER à d’autres utilisateurs:
% chmod go= FICHIERUne liste séparé par des virgules peut être fournie quand plus d’un changement doit être effectué sur un fichier. Par exemple la commande suivante retirera les permissions d’écriture au groupe et au "reste du monde" sur le fichier FICHIER, puis ajoutera la permission d’exécution pour tout le monde:
% chmod go-w,a+x FICHIER3.3.2. Indicateurs des fichiers sous FreeBSD
En addition des permissions sur les fichiers précédemment présentées, FreeBSD supporte l’utilisation d'"indicateurs de fichiers". Ces indicateurs rajoutent un niveau de contrôle et de sécurité sur les fichiers, mais ne concernent pas les répertoires.
Ces indicateurs ajoutent donc un niveau de contrôle supplémentaire des fichiers, permettant d’assurer que dans certains cas même le super-utilisateur root ne pourra effacer ou modifier des fichiers.
Les indicateurs de fichiers peuvent être modifiés avec l’utilitaire chflags(1), ce dernier présentant une interface simple. Par exemple, pour activer l’indicateur système de suppression impossible sur le fichier file1, tapez la commande suivante:
# chflags sunlink file1Et pour désactiver l’indicateur de suppression impossible, utilisez la commande précédente avec le préfixe "no" devant l’option sunlink:
# chflags nosunlink file1Pour afficher les indicateurs propres à ce fichier, utilisez la commande ls(1) avec l’option -lo:
# ls -lo file1La sortie de la commande devrait ressembler à:
-rw-r--r-- 1 trhodes trhodes sunlnk 0 Mar 1 05:54 file1
Plusieurs indicateurs ne peuvent être positionnés ou retirés que par le super-utilisateur root. Dans les autres cas, le propriétaire du fichier peut activer ces indicateurs. Pour plus d’information, la lecture des pages de manuel chflags(1) et chflags(2) est recommandée à tout administrateur.
3.4. Organisation de l’arborescence des répertoires
L’organisation de l’arborescence des répertoires de FreeBSD est essentielle pour obtenir une compréhension globale du système. Le concept le plus important à saisir est celui du répertoire racine, "/". Ce répertoire est le premier a être monté au démarrage et il contient le système de base nécessaire pour préparer le système d’exploitation au fonctionnement multi-utilisateurs. Le répertoire racine contient également les points de montage pour les autres systèmes de fichiers qui sont montés lors du passage en mode multi-utilisateurs.
Un point de montage est un répertoire où peuvent être greffés des systèmes de fichiers supplémentaires au système de fichiers parent (en général le système de fichiers racine). Cela est décrit plus en détails dans la Organisation des disques. Les points de montage standards incluent /usr, /var, /tmp, /mnt, et /cdrom. Ces répertoires sont en général référencés par des entrées dans le fichier /etc/fstab. /etc/fstab est une table des divers systèmes de fichiers et de leur point de montage utilisé comme référence par le système. La plupart des systèmes de fichiers présents dans /etc/fstab sont montés automatiquement au moment du démarrage par la procédure rc(8) à moins que l’option noauto soit présente. Plus de détails peuvent être trouvés dans la Le fichier fstab.
Une description complète de l’arborescence du système de fichiers est disponible dans la page de manuel hier(7). Pour l’instant, une brève vue d’ensemble des répertoires les plus courants suffira.
| Répertoire | Description |
|---|---|
/ | Répertoire racine du système de fichiers. |
/bin/ | Programmes utilisateur fondamentaux aux deux modes de fonctionnement mono et multi-utilisateurs. |
/boot/ | Programmes et fichiers de configuration utilisés durant le processus de démarrage du système. |
/boot/defaults/ | Fichiers de configuration par défaut du processus de démarrage; voir la page de manuel loader.conf(5). |
/dev/ | Fichiers spéciaux de périphérique; voir la page de manuel intro(4). |
/etc/ | Procédures et fichiers de configuration du système. |
/etc/defaults/ | Fichiers de configuration du système par défaut; voir la page de manuel rc(8). |
/etc/mail/ | Fichiers de configuration pour les agents de transport du courrier électronique comme sendmail(8). |
/etc/namedb/ | Fichiers de configuration de |
/etc/periodic/ | Procédures qui sont exécutées de façon quotidienne, hebdomadaire et mensuelle par l’intermédiaire de cron(8); voir la page de manuel periodic(8). |
/etc/ppp/ | Fichiers de configuration de |
/mnt/ | Répertoire vide habituellement utilisé par les administrateurs système comme un point de montage temporaire. |
/proc/ | Le système de fichiers pour les processus; voir les pages de manuel procfs(5), mount_procfs(8). |
/rescue/ | Programmes liés en statique pour les réparations d’urgence; consultez la page de manuel rescue(8). |
/root/ | Répertoire personnel du compte |
/sbin/ | Programmes systèmes et utilitaires systèmes fondamentaux aux environnements mono et multi-utilisateurs. |
/tmp/ | Fichiers temporaires. Le contenu de /tmp n’est en général PAS préservé par un redémarrage du système. Un système de fichiers en mémoire est souvent monté sur /tmp. Cela peut être automatisé en utilisant les variables rc.conf(5) relatives au système "tmpmfs" (ou à l’aide d’une entrée dans le fichier /etc/fstab; consultez la page de manuel mdmfs(8)). |
/usr/ | La majorité des utilitaires et applications utilisateur. |
/usr/bin/ | Utilitaires généraux, outils de programmation, et applications. |
/usr/include/ | Fichiers d’en-tête C standard. |
/usr/lib/ | Ensemble des bibliothèques. |
/usr/libdata/ | Divers fichiers de données de service. |
/usr/libexec/ | Utilitaires et daemons système (exécutés par d’autres programmes). |
/usr/local/ | Exécutables, bibliothèques, etc… Egalement utilisé comme destination de défaut pour les logiciels portés pour FreeBSD. Dans /usr/local, l’organisation générale décrite par la page de manuel hier(7) pour /usr devrait être utilisée. Exceptions faites du répertoire man qui est directement sous /usr/local plutôt que sous /usr/local/share, et la documentation des logiciels portés est dans share/doc/port. |
/usr/obj/ | Arborescence cible spécifique à une architecture produite par la compilation de l’arborescence /usr/src. |
/usr/ports | Le catalogue des logiciels portés (optionnel). |
/usr/sbin/ | Utilitaires et daemons système (exécutés par les utilisateurs). |
/usr/shared/ | Fichiers indépendants de l’architecture. |
/usr/src/ | Fichiers source FreeBSD et/ou locaux. |
/usr/X11R6/ | Exécutables, bibliothèques etc… de la distribution d’X11R6 (optionnel). |
/var/ | Fichiers de traces, fichiers temporaires, et fichiers tampons. Un système de fichiers en mémoire est parfois monté sur /var. Cela peut être automatisé en utilisant les variables rc.conf(5) relatives au système "varmfs" (ou à l’aide d’une entrée dans le fichier /etc/fstab; consultez la page de manuel mdmfs(8)). |
/var/log/ | Divers fichiers de trace du système. |
/var/mail/ | Boîtes aux lettres des utilisateurs. |
/var/spool/ | Divers répertoires tampons des systèmes de courrier électronique et d’impression. |
/var/tmp/ | Fichiers temporaires. Ces fichiers sont généralement conservés lors d’un redémarrage du système, à moins que /var ne soit un système de fichiers en mémoire. |
/var/yp | Tables NIS. |
3.5. Organisation des disques
Le plus petit élément qu’utilise FreeBSD pour retrouver des fichiers est le nom de fichier. Les noms de fichiers sont sensibles à la casse des caractères, ce qui signifie que readme.txt et README.TXT sont deux fichiers séparés. FreeBSD n’utilise pas l’extension (.txt) d’un fichier pour déterminer si ce fichier est un programme, un document ou une autre forme de donnée.
Les fichiers sont stockés dans des répertoires. Un répertoire peut ne contenir aucun fichier, ou en contenir plusieurs centaines. Un répertoire peut également contenir d’autre répertoires, vous permettant de construire une hiérarchie de répertoires à l’intérieur d’un autre. Cela rend plus simple l’organisation de vos données.
Les fichiers et les répertoires sont référencés en donnant le nom du fichier ou du répertoire, suivi par un slash, /, suivi par tout nom de répertoire nécessaire. Si vous avez un répertoire foo, qui contient le répertoire bar, qui contient le fichier readme.txt, alors le nom complet, ou chemin ("path") vers le fichier est foo/bar/readme.txt.
Les répertoires et les fichiers sont stockés sur un système de fichiers. Chaque système de fichiers contient à son niveau le plus haut un répertoire appelé répertoire racine pour ce système de fichiers. Ce répertoire racine peut alors contenir les autres répertoires.
Jusqu’ici cela est probablement semblable à n’importe quel autre système d’exploitation que vous avez pu avoir utilisé. Il y a quelques différences: par exemple, MS-DOS® utilise \ pour séparer les noms de fichier et de répertoire, alors que MacOS utilise :.
FreeBSD n’utilise pas de lettre pour les lecteurs, ou d’autres noms de disque dans le chemin. Vous n’écrirez pas c:/foo/bar/readme.txt sous FreeBSD.
Au lieu de cela, un système de fichiers est désigné comme système de fichiers racine. La racine du système de fichiers racine est représentée par un /. Tous les autres systèmes de fichiers sont alors montés sous le système de fichiers racine. Peu importe le nombre de disques que vous avez sur votre système FreeBSD, chaque répertoire apparaît comme faisant partie du même disque.
Supposez que vous avez trois systèmes de fichiers, appelés A, B, et C. Chaque système de fichiers possède un répertoire racine, qui contient deux autres répertoires, nommés A1, A2 (et respectivement B1, B2 et C1, C2).
Appelons A le système de fichiers racine. Si vous utilisiez la commande ls pour visualiser le contenu de ce répertoire, vous verriez deux sous-répertoires, A1 et A2. L’arborescence des répertoires ressemblera à ceci:
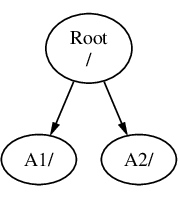
Un système de fichiers doit être monté dans un répertoire d’un autre système de fichiers. Supposez maintenant que vous montez le système de fichiers B sur le répertoire A1. Le répertoire racine de B remplace A1, et les répertoires de B par conséquent apparaissent:
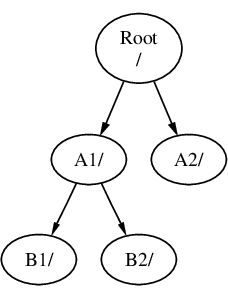
Tout fichier de B1 ou B2 peut être atteint avec le chemin /A1/B1 ou /A1/B2 si nécessaire. Tous les fichiers qui étaient dans A1 ont été temporairement cachés. Ils réapparaîtront si B est démonté de A.
Si B a été monté sur A2 alors le diagramme sera semblable à celui-ci:
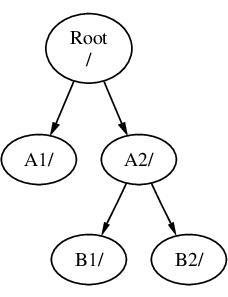
et les chemins seront /A2/B1 et respectivement /A2/B2.
Les systèmes de fichiers peuvent être montés au sommet d’un autre. En continuant l’exemple précédent, le système de fichiers C pourrait être monté au sommet du répertoire B1 dans le système de fichiers B, menant à cet arrangement:
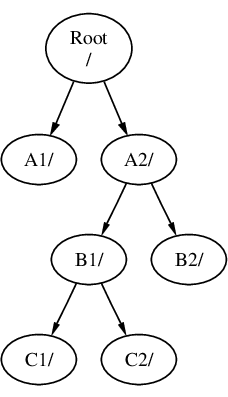
Où C pourrait être monté directement sur le système de fichiers A, sous le répertoire A1:
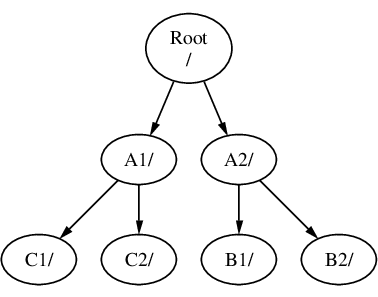
Si vous êtes familier de MS-DOS®, ceci est semblable, bien que pas identique, à la commande join.
Ce n’est normalement pas quelque chose qui doit vous préoccuper. Généralement vous créez des systèmes de fichiers à l’installation de FreeBSD et décidez où les monter, et ensuite ne les modifiez jamais à moins que vous ajoutiez un nouveau disque.
Il est tout à fait possible de n’avoir qu’un seul grand système de fichiers racine, et de ne pas en créer d’autres. Il y a quelques inconvénients à cette approche, et un avantage.
Avantages des systèmes de fichiers multiples
Les différents systèmes de fichiers peuvent avoir différentes options de montage. Par exemple, avec une planification soigneuse, le système de fichiers racine peut être monté en lecture seule, rendant impossible tout effacement par inadvertance ou édition de fichier critique. La séparation des systèmes de fichiers inscriptibles par l’utilisateur permet leur montage en mode nosuid; cette option empêche les bits suid/guid des exécutables stockés sur ce système de fichiers de prendre effet, améliorant peut-être la sécurité.
FreeBSD optimise automatiquement la disposition des fichiers sur un système de fichiers, selon la façon dont est utilisé le système de fichiers. Aussi un système de fichiers contenant beaucoup de petits fichiers qui sont écrits fréquemment aura une optimisation différente à celle d’un système contenant moins, ou de plus gros fichiers. En ayant un seul grand système de fichiers cette optimisation est perdue.
Les systèmes de fichiers de FreeBSD sont très robustes même en cas de coupure secteur. Cependant une coupure secteur à un moment critique pourrait toujours endommager la structure d’un système de fichiers. En répartissant vos données sur des systèmes de fichiers multiples il est plus probable que le système redémarre, vous facilitant la restauration des données à partir de sauvegardes si nécessaire.
Avantage d’un système de fichiers unique
Les systèmes de fichiers ont une taille fixe. Si vous créez un système de fichiers à l’installation de FreeBSD et que vous lui donnez une taille spécifique, vous pouvez plus tard vous apercevoir que vous avez besoin d’une partition plus grande. Cela n’est pas facilement faisable sans sauvegardes, recréation du système de fichiers, et enfin restauration des données.
FreeBSD dispose d’une commande, growfs(8), qui permettra d’augmenter la taille d’un système de fichiers au vol, supprimant cette limitation.
Les systèmes de fichiers sont contenus dans des partitions. Cela n’a pas la même signification que l’utilisation commune du terme partition (par exemple une partition MS-DOS®), en raison de l’héritage Unix de FreeBSD. Chaque partition est identifiée par une lettre de a à h. Chaque partition ne contient qu’un seul système de fichiers, cela signifie que les systèmes de fichiers sont souvent décrits soit par leur point de montage typique dans la hiérarchie du système de fichiers, soit par la lettre de la partition qui les contient.
FreeBSD utilise aussi de l’espace disque pour l’espace de pagination ("swap"). L’espace de pagination fournit à FreeBSD la mémoire virtuelle. Cela permet à votre ordinateur de se comporter comme s’il disposait de beaucoup plus de mémoire qu’il n’en a réellement. Quand FreeBSD vient à manquer de mémoire il déplace certaines données qui ne sont pas actuellement utilisées vers l’espace de pagination, et les rapatrie (en déplaçant quelque chose d’autre) quand il en a besoin.
Quelques partitions sont liées à certaines conventions.
| Partition | Convention |
|---|---|
| Contient normalement le système de fichiers racine |
| Contient normalement l’espace de pagination |
| Normalement de la même taille que la tranche ("slice") contenant les partitions. Cela permet aux utilitaires devant agir sur l’intégralité de la tranche (par exemple un analyseur de blocs défectueux) de travailler sur la partition |
| La partition |
Chaque partition contenant un système de fichiers est stockée dans ce que FreeBSD appelle une tranche ("slice"). Tranche - "slice" est le terme FreeBSD pour ce qui est communément appelé partition, et encore une fois, cela en raison des fondations Unix de FreeBSD. Les tranches sont numérotées, en partant de 1, jusqu’à 4.
Les numéros de tranche suivent le nom du périphérique, avec le préfixe s, et commencent à 1. Donc "da0s1" est la première tranche sur le premier disque SCSI. Il ne peut y avoir que quatre tranches physiques sur un disque, mais vous pouvez avoir des tranches logiques dans des tranches physiques d’un type précis. Ces tranches étendues sont numérotées à partir de 5, donc "ad0s5" est la première tranche étendue sur le premier disque IDE. Elles sont utilisées par des systèmes de fichiers qui s’attendent à occuper une tranche entière.
Les tranches, les disques "en mode dédié", et les autres disques contiennent des partitions, qui sont représentées par des lettres allant de a à h. Cette lettre est ajoutée au nom de périphérique, aussi "da0a" est la partition a sur le premier disque da, qui est en "en mode dédié". "ad1s3e" est la cinquième partition de la troisième tranche du second disque IDE.
En conclusion chaque disque présent sur le système est identifié. Le nom d’un disque commence par un code qui indique le type de disque, suivi d’un nombre, indiquant de quel disque il s’agit. Contrairement aux tranches, la numérotation des disques commence à 0. Les codes communs que vous risquez de rencontrer sont énumérés dans le Codes des périphériques disques.
Quand vous faites référence à une partition, FreeBSD exige que vous nommiez également la tranche et le disque contenant la partition, et quand vous faites référence à une tranche vous devrez également faire référence au nom du disque. On fait donc référence à une partition en écrivant le nom du disque, s, le numéro de la tranche, et enfin la lettre de la partition. Des exemples sont donnés dans l'Exemples d’appellation de disques, tranches et partitions.
L'Modèle conceptuel d’un disque montre un exemple de l’organisation d’un disque qui devrait aider à clarifier les choses.
Afin d’installer FreeBSD vous devez tout d’abord configurer les tranches sur votre disque, ensuite créer les partitions dans la tranche que vous utiliserez pour FreeBSD, et alors créer un système de fichiers (ou espace de pagination) dans chaque partition, et décider de l’endroit où seront montés les systèmes de fichiers.
| Code | Signification |
|---|---|
ad | Disque ATAPI (IDE) |
da | Disque SCSI |
acd | CDROM ATAPI (IDE) |
cd | CDROM SCSI |
fd | Lecteur de disquette |
Exemple 1. Exemples d’appellation de disques, tranches et partitions
| Nom | Signification |
|---|---|
| Première partition ( |
| Cinquième partition ( |
Exemple 2. Modèle conceptuel d’un disque
Ce diagramme montre comment FreeBSD voit le premier disque IDE attaché au système. Supposons que le disque a une capacité de 4 Go, et contient deux tranches de 2 Go (partitions MS-DOS®). La première tranche contient un disque MS-DOS®, C:, et la seconde tranche contient une installation de FreeBSD. Dans cet exemple l’installation de FreeBSD a trois partitions de données, et une partition de pagination.
Les trois partitions accueilleront chacune un système de fichiers. La partition a sera utilisée en tant que système de fichiers racine, la partition e pour le contenu du répertoire /var, et f pour l’arborescence du répertoire /usr.

3.6. Monter et démonter des systèmes de fichiers
Le système de fichiers peut être vu comme un arbre enraciné sur le répertoire /. /dev, /usr, et les autres répertoires dans le répertoire racine sont des branches, qui peuvent avoir leurs propres branches, comme /usr/local, et ainsi de suite.
Il y a diverses raisons pour héberger certains de ces répertoires sur des systèmes de fichiers séparés. /var contient les répertoires log/, spool/, et divers types de fichiers temporaires, et en tant que tels, peuvent voir leur taille augmenter de façon importante. Remplir le système de fichiers racine n’est pas une bonne idée, aussi séparer /var de / est souvent favorable.
Une autre raison courante de placer certains répertoires sur d’autres systèmes de fichiers est s’ils doivent être hébergés sur des disques physiques séparés, ou sur des disques virtuels séparés, comme les systèmes de fichiers réseau, ou les lecteurs de CDROM.
3.6.1. Le fichier fstab
Durant le processus de démarrage, les systèmes de fichiers listés dans /etc/fstab sont automatiquement montés (à moins qu’il ne soient listés avec l’option noauto).
Le fichier /etc/fstab contient une liste de lignes au format suivant:
device /mount-point fstype options dumpfreq passno
deviceUn nom de périphérique (qui devrait exister), comme expliqué dans la Noms des périphériques.
mount-pointUn répertoire (qui devrait exister), sur lequel sera monté le système de fichier.
fstypeLe type de système de fichiers à indiquer à mount(8). Le système de fichiers par défaut de FreeBSD est l'
ufs.optionsSoit
rwpour des systèmes de fichiers à lecture-écriture, soitropour des systèmes de fichiers à lecture seule, suivi par toute option qui peut s’avérer nécessaire. Une option courante estnoautopour les systèmes de fichiers qui ne sont normalement pas montés durant la séquence de démarrage. D’autres options sont présentées dans la page de manuel mount(8).dumpfreqC’est utilisé par dump(8) pour déterminer quels systèmes de fichiers nécessitent une sauvegarde. Si ce champ est absent, une valeur de zéro est supposée.
passnoCeci détermine l’ordre dans lequel les systèmes de fichiers devront être vérifiés. Les systèmes de fichiers qui doivent être ignorés devraient avoir leur
passnopositionné à zéro. Le système de fichiers racine (qui doit être vérifié avant tout le reste) devrait avoir sonpassnopositionné à un, et les optionspassnodes autres systèmes fichiers devraient être positionnées à des valeurs supérieures à un. Si plus d’un système de fichiers ont le mêmepassnoalors fsck(8) essaiera de vérifier les systèmes de fichiers en parallèle si c’est possible.
Consultez la page de manuel de fstab(5) pour plus d’information sur le format du fichier /etc/fstab et des options qu’il contient.
3.6.2. La commande mount
La commande mount(8) est ce qui est finalement utilisé pour monter des systèmes de fichiers.
Dans sa forme la plus simple, vous utilisez:
# mount device mountpointIl y beaucoup d’options, comme mentionné dans la page de manuel mount(8), mais les plus courantes sont:
Options de montage
-aMonte tous les systèmes de fichiers listés dans /etc/fstab. Exception faite de ceux marqués comme "noauto", ou exclus par le drapeau
-t, ou encore ceux qui sont déjà montés.-dTout effectuer à l’exception de l’appel système de montage réel. Cette option est utile conjointement avec le drapeau
-vpour déterminer ce que mount(8) est en train d’essayer de faire.-fForce le montage d’un système de fichiers non propre (dangereux), ou force la révocation de l’accès en écriture quand on modifie l’état de montage d’un système de fichiers de l’accès lecture-écriture à l’accès lecture seule.
-rMonte le système de fichiers en lecture seule. C’est identique à l’utilisation de l’argument
ro(rdonlypour les versions de FreeBSD antérieures à la 5.2) avec l’option-o.-tfstypeMonte le système de fichiers comme étant du type de système donné, ou monte seulement les systèmes de fichiers du type donné, si l’option
-aest précisée."ufs" est le type de système de fichiers par défaut.
-uMets à jour les options de montage sur le système de fichiers.
-vRends la commande prolixe.
-wMonte le système de fichiers en lecture-écriture.
L’option -o accepte une liste d’options séparées par des virgules, dont les suivantes:
- noexec
Ne pas autoriser l’exécution de binaires sur ce système de fichiers. C’est également une option de sécurité utile.
- nosuid
Ne pas prendre en compte les indicateurs setuid ou setgid sur le système de fichiers. C’est également une option de sécurité utile.
3.6.3. La commande umount
La commande umount(8) prend, comme paramètre, un des points de montage, un nom de périphérique, ou l’option -a ou -A.
Toutes les formes acceptent -f pour forcer de démontage, et -v pour le mode prolixe. Soyez averti que l’utilisation de -f n’est généralement pas une bonne idée. Démonter de force des systèmes de fichiers pourrait faire planter l’ordinateur ou endommager les données sur le système de fichiers.
Les options -a et -A sont utilisées pour démonter tous les systèmes de fichiers actuellement montés, éventuellement modifié par les types de systèmes de fichiers listés après l’option -t. Cependant l’option -A, n’essaye pas de démonter le système de fichiers racine.
3.7. Processus
FreeBSD est un système d’exploitation multi-tâches. Cela veut dire qu’il semble qu’il y ait plus d’un programme fonctionnant à la fois. Tout programme fonctionnant à un moment donné est appelé un processus. Chaque commande que vous utiliserez lancera au moins un nouveau processus, et il y a de nombreux processus système qui tournent constamment, maintenant ainsi les fonctionnalités du système.
Chaque processus est identifié de façon unique par un nombre appelé process ID (identifiant de processus), ou PID, et, comme pour les fichiers, chaque processus possède également un propriétaire et un groupe. Les informations sur le propriétaire et le groupe sont utilisées pour déterminer quels fichiers et périphériques sont accessibles au processus, en utilisant le principe de permissions de fichiers abordé plus tôt. La plupart des processus ont également un processus parent. Le processus parent est le processus qui les a lancés. Par exemple, si vous tapez des commandes sous un interpréteur de commandes, alors l’interpréteur de commandes est un processus, et toute commande que vous lancez est aussi un processus. Chaque processus que vous lancez de cette manière aura votre interpréteur de commandes comme processus parent. Une exception à cela est le processus spécial appelé init(8). init est toujours le premier processus, donc son PID est toujours 1. init est lancé automatiquement par le noyau au démarrage de FreeBSD.
Deux commandes sont particulièrement utiles pour voir les processus sur le système, ps(1) et top(1). La commande ps est utilisée pour afficher une liste statique des processus tournant actuellement, et peut donner leur PID, la quantité de mémoire qu’ils utilisent, la ligne de commande par l’intermédiaire de laquelle ils ont été lancés, et ainsi de suite. La commande top(1) affiche tous les processus, et actualise l’affichage régulièrement, de sorte que vous puissiez voir de façon intéractive ce que fait l’ordinateur.
Par défaut, ps(1) n’affiche que les commandes que vous faites tourner et dont vous êtes le propriétaire. Par exemple:
% ps
PID TT STAT TIME COMMAND
298 p0 Ss 0:01.10 tcsh
7078 p0 S 2:40.88 xemacs mdoc.xsl (xemacs-21.1.14)
37393 p0 I 0:03.11 xemacs freebsd.dsl (xemacs-21.1.14)
48630 p0 S 2:50.89 /usr/local/lib/netscape-linux/navigator-linux-4.77.bi
48730 p0 IW 0:00.00 (dns helper) (navigator-linux-)
72210 p0 R+ 0:00.00 ps
390 p1 Is 0:01.14 tcsh
7059 p2 Is+ 1:36.18 /usr/local/bin/mutt -y
6688 p3 IWs 0:00.00 tcsh
10735 p4 IWs 0:00.00 tcsh
20256 p5 IWs 0:00.00 tcsh
262 v0 IWs 0:00.00 -tcsh (tcsh)
270 v0 IW+ 0:00.00 /bin/sh /usr/X11R6/bin/startx -- -bpp 16
280 v0 IW+ 0:00.00 xinit /home/nik/.xinitrc -- -bpp 16
284 v0 IW 0:00.00 /bin/sh /home/nik/.xinitrc
285 v0 S 0:38.45 /usr/X11R6/bin/sawfishComme vous pouvez le voir dans cet exemple, la sortie de ps(1) est organisée en un certain nombre de colonnes. PID est l’identifiant de processus discuté plus tôt. Les PIDs sont assignés à partir de 1, et vont jusqu’à 99999, et puis repassent à 1 quand le maximum est atteint (un PID n’est pas réassigné s’il est déjà utilisé). La colonne TT donne le terminal sur lequel tourne le programme, et peut être pour le moment ignoré sans risque. STAT affiche l’état du programme, peut être également ignoré. TIME est la durée d’utilisation du CPU-ce n’est généralement pas le temps écoulé depuis que vous avez lancé le programme, comme la plupart des programmes passent beaucoup de temps à attendre que certaines choses se produisent avant qu’ils n’aient besoin de dépenser du temps CPU. Et enfin, COMMAND est la ligne de commande qui a été utilisée lors du lancement du programme.
ps(1) supporte un certain nombre d’options différentes pour modifier les informations affichées. Un des ensembles d’options les plus utiles est auxww. a affiche l’information au sujet de tous les processus tournant, et pas seulement les vôtres. u donne le nom de l’utilisateur du propriétaire du processus, ainsi que l’utilisation de la mémoire. x affiche des informations sur les processus "daemon", et ww oblige ps(1) à afficher la ligne de commande complète pour chaque processus, plutôt que de la tronquer quand elle est trop longue pour tenir à l’écran.
La sortie de top(1) est semblable. Un extrait de session ressemble à ceci:
% top
last pid: 72257; load averages: 0.13, 0.09, 0.03 up 0+13:38:33 22:39:10
47 processes: 1 running, 46 sleeping
CPU states: 12.6% user, 0.0% nice, 7.8% system, 0.0% interrupt, 79.7% idle
Mem: 36M Active, 5256K Inact, 13M Wired, 6312K Cache, 15M Buf, 408K Free
Swap: 256M Total, 38M Used, 217M Free, 15% Inuse
PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU COMMAND
72257 nik 28 0 1960K 1044K RUN 0:00 14.86% 1.42% top
7078 nik 2 0 15280K 10960K select 2:54 0.88% 0.88% xemacs-21.1.14
281 nik 2 0 18636K 7112K select 5:36 0.73% 0.73% XF86_SVGA
296 nik 2 0 3240K 1644K select 0:12 0.05% 0.05% xterm
48630 nik 2 0 29816K 9148K select 3:18 0.00% 0.00% navigator-linu
175 root 2 0 924K 252K select 1:41 0.00% 0.00% syslogd
7059 nik 2 0 7260K 4644K poll 1:38 0.00% 0.00% mutt
...La sortie est divisée en deux sections. L’entête (les cinq premières lignes) donne le PID du dernier processus lancé, la charge système moyenne (qui est une mesure de l’occupation du système), la durée de fonctionnement du système (le temps écoulé depuis le dernier redémarrage), et l’heure actuelle. Les autres éléments de l’entête concernent le nombre de processus en fonctionnement (47 dans notre cas), combien d’espace mémoire et d’espace de pagination sont occupés, et combien de temps le système passe dans les différents états du CPU.
En dessous il y a une série de colonnes contenant des informations semblables à celles données par ps(1). Comme précédemment vous pouvez lire le PID, le nom d’utilisateur, la quantité de temps CPU consommée, et la commande qui a été lancée. top(1) vous affiche par défaut la quantité d’espace mémoire utilisée par chaque processus. Cela est divisé en deux colonnes, une pour la quantité totale, et une autre pour la quantité résidente-la quantité totale représente l’espace mémoire dont a eu besoin l’application, et la quantité résidente représente l’espace qui est en fait utilisé actuellement. Dans cet exemple vous pouvez voir que getenv(3) a exigé presque 30 Mo de RAM, mais utilise actuellement seulement 9Mo.
top(1) actualise l’affichage toutes les deux secondes; cela peut être modifié avec l’option s.
3.8. Daemons, signaux, et comment tuer un processus
Quand vous utilisez un éditeur il est facile de le contrôler, de lui dire de charger des fichiers, et ainsi de suite. Vous pouvez faire cela parce que l’éditeur fournit les possibilités de le faire, et parce qu’un éditeur est attaché à un terminal. Certains programmes ne sont pas conçus pour fonctionner avec un dialogue constant avec l’utilisateur, et donc ils se déconnectent du terminal à la première occasion. Par exemple, un serveur web passe son temps à répondre aux requêtes web, il n’attend normalement pas d’entrée de votre part. Les programmes qui transportent le courrier électronique de site en site sont un autre exemple de cette classe d’application.
Nous appelons ces programmes des daemons (démons). Les "daemons" étaient des personnages de la mythologie Grecque: ni bon ni mauvais, c’étaient de petits esprits serviteurs qui, généralement, ont été à l’origine de choses utiles à l’humanité, un peu comme les serveurs web ou de messagerie d’aujourd’hui nous sont utiles. C’est pourquoi la mascotte BSD a été, pendant longtemps, un démon à l’apparence joyeuse portant des chaussures de tennis et une fourche.
Il existe une convention pour nommer les programmes qui fonctionnent normalement en tant que daemons qui est d’utiliser une terminaison en "d". BIND est le "Berkeley Internet Name Domain", mais le programme réel qui est exécuté s’appelle named); le programme correspondant au serveur web Apache est appelé httpd; le daemon de gestion de la file d’attente de l’imprimante est lpd, et ainsi de suite. C’est une convention, mais pas une obligation pure et simple; par exemple le daemon principal de gestion du courrier électronique pour l’application Sendmail est appelé sendmail, et non pas maild, comme vous pourriez l’imaginer.
Parfois vous devrez communiquer avec un processus daemon. Une manière de procéder est de lui (ou à tout processus en cours d’exécution) envoyer ce que l’on appelle un signal. Il existe un certain nombre de signaux différents que vous pouvez envoyer-certains d’entre eux ont une signification précise, d’autres sont interprétés par l’application, et la documentation de l’application vous indiquera comment l’application interprète ces signaux. Vous ne pouvez envoyer de signaux qu’aux processus dont vous êtes le propriétaire. Si vous envoyez un signal à un processus appartenant à quelqu’un d’autre avec kill(1) ou kill(2), vous obtiendrez un refus de permission. Il existe une exception à cela: l’utilisateur root, qui peut envoyer des signaux aux processus de chacun.
Dans certain cas FreeBSD enverra également aux applications des signaux. Si une application est mal écrite, et tente d’accéder à une partie de mémoire à laquelle elle n’est pas supposée avoir accès, FreeBSD envoie au processus le signal de violation de segmentation (SIGSEGV). Si une application a utilisé l’appel système alarm(3) pour être avertie dès qu’une période de temps précise est écoulée alors lui sera envoyé le signal d’alarme (SIGALRM), et ainsi de suite.
Deux signaux peuvent être utilisés pour arrêter un processus, SIGTERM et SIGKILL. SIGTERM est la manière polie de tuer un processus; le processus peut attraper le signal, réaliser que vous désirez qu’il se termine, fermer les fichiers de trace qu’il a peut-être ouvert, et généralement finir ce qu’il était en train de faire juste avant la demande d’arrêt. Dans certains cas un processus peut ignorer un SIGTERM s’il est au milieu d’une tâche qui ne peut être interrompue.
SIGKILL ne peut être ignoré par un processus. C’est le signal "Je me fiche de ce que vous faites, arrêtez immédiatement". Si vous envoyez un SIGKILL à un processus alors FreeBSD stoppera le processus.
Les autres signaux que vous pourriez avoir envie d’utiliser sont SIGHUP, SIGUSR1, et SIGUSR2. Ce sont des signaux d’usage général, et différentes applications se comporteront différemment quand ils sont envoyés.
Supposez que vous avez modifié le fichier de configuration de votre serveur web-vous voudriez dire à votre serveur web de relire son fichier de configuration. Vous pourriez arrêter et relancer httpd, mais il en résulterait une brève période d’indisponibilité de votre serveur web, ce qui peut être indésirable. La plupart des daemons sont écrits pour répondre au signal SIGHUP en relisant leur fichier de configuration. Donc au lieu de tuer et relancer httpd vous lui enverriez le signal SIGHUP. Parce qu’il n’y a pas de manière standard de répondre à ces signaux, différents daemons auront différents comportements, soyez sûr de ce que vous faites et lisez la documentation du daemon en question.
Les signaux sont envoyés en utilisant la commande kill(1), comme cet exemple le montre:
Procedure: Envoyer un signal à un processus
Cet exemple montre comment envoyer un signal à inetd(8). Le fichier de configuration d'inetd est /etc/inetd.conf, et inetd relira ce fichier de configuration quand un signal SIGHUP est envoyé.
Trouvez l’identifiant du processus (PID) auquel vous voulez envoyer le signal. Faites-le en employant ps(1) et grep(1). La commande grep(1) est utilisée pour rechercher dans le résultat la chaîne de caractères que vous spécifiez. Cette commande est lancée en tant qu’utilisateur normal, et inetd(8) est lancé en tant que
root, donc les optionsaxdoivent être passées à ps(1).% ps -ax | grep inetd 198 ?? IWs 0:00.00 inetd -wWUtilisez kill(1) pour envoyer le signal. Etant donné qu’inetd(8) tourne sous les droits de l’utilisateur
rootvous devez utilisez su(1) pour devenir, en premier lieu,root.% su Password: # /bin/kill -s HUP 198Comme la plupart des commandes UNIX®, kill(1) n’affichera rien si la commande est couronnée de succès. Si vous envoyez un signal à un processus dont vous n’êtes pas le propriétaire alors vous verrez
kill: PID: Operation not permitted. Si vous avez fait une erreur dans le PID, vous enverrez le signal soit à un mauvais processus, ce qui peut être mauvais, soit, si vous êtes chanceux, vous enverrez le signal à un PID qui n’est pas actuellement utilisé, et vous verrezkill: PID: No such process.
Pourquoi utiliser /bin/kill?De nombreux interpréteurs de commandes fournissent la commande |
Envoyer d’autres signaux est très semblable, substituez juste TERM ou KILL dans la ligne de commande si nécessaire.
Tuer au hasard des processus sur le système peut être une mauvaise idée. En particulier, init(8), processus à l’identifiant 1, qui est très particulier. Lancer la commande |
3.9. Interpréteurs de commandes - "Shells"
Sous FreeBSD, beaucoup du travail quotidien est effectué sous une interface en ligne de commande appelée interpréteur de commandes ou "shell". Le rôle principal d’un interpréteur de commandes est de prendre les commandes sur le canal d’entrée et de les exécuter. Beaucoup d’interpréteurs de commandes ont également des fonctions intégrées pour aider dans les tâches quotidiennes comme la gestion de fichiers, le mécanisme de remplacement et d’expansion des jokers ("file globbing"), l’édition de la ligne de commande, les macros commandes, et les variables d’environnement. FreeBSD est fournit avec un ensemble d’interpréteurs de commandes, comme sh, l’interpréteur de commandes Bourne, et tcsh, l’interpréteur de commandes C-shell amélioré. Beaucoup d’autres interpréteurs de commandes sont disponibles dans le catalogue des logiciels portés, comme zsh et bash.
Quel interpréteur de commandes utilisez-vous? C’est vraiment une question de goût. Si vous programmez en C vous pourriez vous sentir plus à l’aise avec un interpréteur de commandes proche du C comme tcsh. Si vous venez du monde Linux ou que vous êtes nouveau à l’interface en ligne de commande d’UNIX® vous pourriez essayer bash. L’idée principale est que chaque interpréteur de commandes à des caractéristiques uniques qui peuvent ou ne peuvent pas fonctionner avec votre environnement de travail préféré, et que vous avez vraiment le choix de l’interpréteur de commandes à utiliser.
Une des caractéristiques communes des interpréteurs de commandes est de pouvoir compléter les noms de fichiers ("filename completion"). En tapant les premières lettres d’une commande ou d’un fichier, vous pouvez habituellement faire compléter automatiquement par l’interpréteur de commandes le reste de la commande ou du nom du fichier en appuyant sur la touche Tab du clavier. Voici un exemple. Supposez que vous avez deux fichiers appelés respectivement foobar et foo.bar. Vous voulez effacer foo.bar. Donc ce que vous devriez taper sur le clavier est: rm fo[Tab].[Tab].
L’interpréteur de commandes devrait afficher rm foo[BEEP].bar.
Le [BEEP] est la sonnerie de la console, c’est l’interpréteur de commande indiquant qu’il n’est pas en mesure de compléter totalement le nom du fichier parce qu’il y a plus d’une possibilité. foobar et foo.bar commencent tous les deux par fo, mais il fut capable de compléter jusqu’à foo. Si vous tapez ., puis appuyez à nouveau sur Tab, l’interpréteur de commandes devrait pouvoir compléter le reste du nom du fichier pour vous.
Une autre caractéristique de l’interpréteur de commandes est l’utilisation de variables d’environnement. Les variables d’environnement sont une paire variable/valeur stockées dans l’espace mémoire d’environnement de l’interpréteur de commandes. Cet espace peut être lu par n’importe quel programme invoqué par l’interpréteur de commandes, et contient ainsi beaucoup d’éléments de configuration des programmes. Voici une liste des variables d’environnement habituelles et ce qu’elles signifient:
| Variable | Description |
|---|---|
| Le nom d’utilisateur de la personne actuellement attachée au système. |
| La liste des répertoires, séparés par deux points, pour la recherche des programmes. |
| Le nom réseau de l’affichage X11 auquel on peut se connecter, si disponible. |
| Le nom de l’interpréteur de commandes actuellement utilisé. |
| Le nom du type de terminal de l’utilisateur. Utilisé pour déterminer les capacités du terminal. |
| L’entrée de la base de données des codes d’échappement pour permettre l’exécution de diverses fonctions du terminal. |
| Type du système d’exploitation, e.g. FreeBSD. |
| L’architecture du CPU sur lequel tourne actuellement le système. |
| L’éditeur de texte préferé de l’utilisateur. |
| Le visualisateur de page de texte préferré de l’utilisateur. |
| La liste des répertoires, séparés par deux points, pour la recherche des pages de manuel. |
Fixer une variable d’environnement diffère légèrement d’un interpréteur de commandes à l’autre. Par exemple, dans le style de l’interpréteur de commandes de type C-shell comme tcsh et csh, vous utiliseriez setenv pour fixer le contenu d’une variable d’environnement. Sous les interpréteurs de commandes Bourne comme sh et bash, vous utiliseriez export pour configurer vos variables d’environnement. Par exemple, pour fixer ou modifier la variable d’environnement EDITOR, sous csh ou tcsh une commande comme la suivante fixera EDITOR à /usr/local/bin/emacs:
% setenv EDITOR /usr/local/bin/emacsSous les interpréteurs de commandes Bourne:
% export EDITOR="/usr/local/bin/emacs"Vous pouvez faire afficher à la plupart des interpréteurs de commandes la variable d’environnement en plaçant un caractère $ juste devant son nom sur la ligne de commande. Par exemple, echo $TERM affichera le contenu de $TERM, car l’interpréteur de commande complète $TERM et passe la main à echo.
Les interpréteurs de commandes traitent beaucoup de caractères spéciaux, appelés métacaractères, en tant que représentation particulière des données. Le plus commun est le caractère *, qui représente zéro ou plusieurs caractères dans le nom du fichier. Ces métacaractères spéciaux peuvent être utilisés pour compléter automatiquement le nom des fichiers. Par exemple, taper echo * est presque la même chose que taper ls parce que l’interpréteur de commandes prendra tous les fichiers qui correspondent à * et les passera à echo pour les afficher.
Pour éviter que l’interpréteur de commande n’interprète les caractères spéciaux, ils peuvent être neutralisés en ajoutant un caractère antislash (\) devant. echo $TERM affichera votre type de terminal. echo \$TERM affichera $TERM tel quel.
3.9.1. Changer d’interpréteur de commandes
La méthode la plus simple pour changer votre interpréteur de commandes est d’utiliser la commande chsh. En lançant chsh vous arriverez dans l’éditeur correspondant à votre variable d’environnement EDITOR; si elle n’est pas fixée, cela sera vi. Modifiez la ligne "Shell:" en conséquence.
Vous pouvez également passer le paramètre -s à chsh; cela modifiera votre interpréteur de commandes sans avoir à utiliser un éditeur. Par exemple, si vous vouliez changer votre interpréteur de commandes pour bash, ce qui suit devrait faire l’affaire:
% chsh -s /usr/local/bin/bashL’interpréteur de commandes que vous désirez utiliser doit être présent dans le fichier /etc/shells. Si vous avez installé l’interpréteur de commandes à partir du catalogue des logiciels portés, alors cela a dû déjà être fait pour vous. Si vous avez installé à la main l’interpréteur de commandes, vous devez alors le faire. Par exemple, si vous avez installé Puis relancer |
3.10. Editeurs de texte
Beaucoup de configurations sous FreeBSD sont faites en éditant des fichiers textes. Aussi ce serait une bonne idée de se familiariser avec un éditeur de texte. FreeBSD est fourni avec quelques-uns en tant qu’éléments du système de base, et beaucoup d’autres sont disponibles dans le catalogue des logiciels portés.
L’éditeur de plus facile et le plus simple à apprendre est un éditeur appelé ee, qui signifie l’éditeur facile (easy editor). Pour lancer ee, on taperait sur la ligne de commande ee fichier où fichier est le nom du fichier qui doit être édité. Par exemple, pour éditer /etc/rc.conf, tapez ee /etc/rc.conf. Une fois sous ee, toutes les commandes pour utiliser les fonctions de l’éditeur sont affichées en haut de l’écran. Le caractère ^ représente la touche Ctrl sur le clavier, donc ^e représente la combinaison de touches Ctrl+e. Pour quitter ee, appuyez sur la touche Echap, ensuite choisissez "leave editor". L’éditeur vous demandera s’il doit sauver les changements si le fichier a été modifié.
FreeBSD est également fourni avec des éditeurs de texte plus puissants comme vi en tant qu’élément du système de base, alors que d’autres éditeurs, comme Emacs et vim, en tant qu’élément du catalogue des logiciels portés de FreeBSD (editors/emacs et editors/vim). Ces éditeurs offrent beaucoup plus de fonctionnalités et de puissance aux dépens d’être un peu plus compliqués à apprendre. Cependant si vous projetez de faire beaucoup d’édition de texte, l’étude d’un éditeur plus puissant comme vim ou Emacs vous permettra d’économiser beaucoup plus de temps à la longue.
3.11. Périphériques et fichiers spéciaux de périphérique
Un périphérique est un terme utilisé la plupart du temps pour les activités en rapport avec le matériel présent sur le système, incluant les disques, les imprimantes, les cartes graphiques, et les claviers. Quand FreeBSD démarre, la majorité de ce qu’affiche FreeBSD est la détection des périphériques. Vous pouvez à nouveau consulter les messages de démarrage en visualisant le fichier /var/run/dmesg.boot.
Par exemple, acd0 est le premier lecteur de CDROM IDE, tandis que kbd0 représente le clavier.
La plupart de ces périphériques sous un système d’exploitation UNIX® peuvent être accédés par l’intermédiaire de fichiers appelés fichiers spéciaux de périphérique ("device node"), qui sont situés dans le répertoire /dev.
3.11.1. Créer des fichiers spéciaux de périphérique
Quand vous ajoutez un nouveau périphérique à votre système, ou compilez le support pour des périphériques supplémentaires, de nouveaux fichiers spéciaux de périphérique doivent être créés.
3.11.1.1. DEVFS ("DEVice File System" - Système de fichiers de périphérique)
Le système de fichiers de périphérique, ou DEVFS, fournit un accès à l’espace nom des périphériques du noyau dans l’espace nom du système de fichiers global. Au lieu d’avoir à créer et modifier les fichiers spéciaux de périphérique, DEVFS maintient ce système de fichiers particulier pour vous.
Voir la page de manuel de devfs(5) pour plus d’information.
3.12. Le format des fichiers binaires
Afin de comprendre pourquoi FreeBSD utilise le format elf(5), vous devez d’abord connaître quelques détails concernant les trois formats "dominants" d’exécutables actuellement en vigueur sous UNIX®:
Le plus vieux et le format objet "classique" d’UNIX®. Il utilise une entête courte et compacte avec un nombre magique au début qui est souvent utilisé pour caractériser le format (voir la page de manuel a.out(5) pour plus de détails). Il contient trois segments chargés: .text, .data, et .bss plus une table de symboles et une table de chaînes de caractères.
COFF
Le format objet SVR3. L’entête comprend une table de section, de telle sorte que vous avez plus de sections qu’uniquement .text, .data et .bss.
Le successeur de COFF, qui permet des sections multiples et des valeurs possibles de 32 bits et 64 bits. Un inconvénient majeur: ELF a aussi été conçu en supposant qu’il y aurait qu’un seul ABI par architecture système. Cette hypothèse est en fait assez incorrecte, et même dans le monde SYSV (qui a au moins trois ABIs: SVR4, Solaris, SCO) cela ne se vérifie pas.
FreeBSD essaye de contourner ce problème en fournissant un utilitaire pour marquer un exécutable connu ELF avec des informations sur l’ABI qui va avec. Consultez la page de manuel de brandelf(1) pour plus d’informations.
FreeBSD vient du camp "classique" et a utilisé le format a.out(5), une technologie employée et éprouvée à travers des générations de BSDs, jusqu’aux débuts de la branche 3.X. Bien qu’il fut possible de compiler et d’exécuter des binaires natifs ELF (et noyaux) sous FreeBSD avant cela, FreeBSD a initialement résisté à la "pression" de passer à ELF comme format par défaut. Pourquoi? Bien, quand le camp Linux ont fait leur pénible transition vers ELF, ce n’est pas tant fuir le format a.out qui rendait difficile la construction de bibliothèques partagée pour les développeurs mais le mécanisme de bibliothèques partagées basé sur des tables de sauts inflexible. Puisque les outils ELF disponibles offraient une solution au problème des bibliothèques partagées et étaient perçus comme "le chemin à suivre" de toute façon, le coût de la migration a été accepté comme nécessaire, et la transition a été réalisée. Le mécanisme FreeBSD de bibliothèques partagées se rapproche plus du style de mécanisme de bibliothèques partagées de SunOS™ de Sun, et est très simple à utiliser.
Pourquoi existe-t-il tant de formats différents?
Dans un obscure et lointain passé, il y avait du matériel simple. Ce matériel simple supportait un simple petit système. a.out était complètement adapté pour représenter les binaires sur ce système simple (un PDP-11). Au fur et à mesure que des personnes portaient UNIX® à partir de ce système simple, ils ont maintenus le format a.out parce qu’il était suffisant pour les premiers portages d’UNIX® sur des architectures comme le Motorola 68k, les VAX, etc.
Alors un certain ingénieur matériel brillant a décidé qu’il pourrait forcer le matériel à faire des choses bizarre, l’autorisant ainsi à réduire le nombre de portes logiques et permettant au coeur du CPU de fonctionner plus rapidement. Bien qu’on l’a fait fonctionner avec ce nouveau type de matériel (connu de nos jour sous le nom de RISC), a.out n’était pas adapté à ce matériel, aussi beaucoup de formats ont été développés pour obtenir de meilleures performances de ce matériel que ce que pouvait offrir le simple et limité format qu’était a.out. Des choses comme COFF, ECOFF, et quelques autres obscures formats ont été inventé et leur limites explorées avant que les choses ne se fixent sur ELF.
En outre, les tailles des programmes devenaient énormes alors que les disques (et la mémoire physique) étaient toujours relativement petits, aussi le concept de bibliothèque partagée est né. Le système de VM (mémoire virtuelle) est également devenu plus sophistiqué. Tandis que chacune de ces avancées était faites en utilisant le format a.out, son utilité a été élargie de plus en plus avec chaque nouvelle fonction. De plus les gens ont voulu charger dynamiquement des choses à l’exécution, ou se débarrasser de partie de leur programme après l’initialisation pour économiser de l’espace mémoire et de pagination. Les langages sont devenus plus sophistiqués et les gens ont voulu du code appelé automatiquement avant la partie principale du programme. Beaucoup de modifications ont été apportées au format a.out pour rendre possible toutes ces choses, et cela a fonctionné pendant un certain temps. Avec le temps, a.out n’était plus capable de gérer tous ces problèmes sans une augmentation toujours croissante du code et de sa complexité. Tandis ELF résolvait plusieurs de ces problèmes, il aurait été pénible de quitter un système qui a fonctionné. Ainsi ELF a dû attendre jusqu’au moment où il était plus pénible de rester avec a.out que d’émigrer vers ELF.
Cependant, avec le temps, les outils de compilation desquels ceux de FreeBSD sont dérivés (l’assembleur et le chargeur tout spécialement) ont évolué en parallèle. Les développeurs FreeBSD ajoutèrent les bibliothèques partagées et corrigèrent quelques bogues. Les gens de chez GNU qui ont à l’origine écrit ces programmes, les récrivirent et ajoutèrent un support plus simple pour la compilation multi-plateformes, avec différents formats à volonté, et ainsi de suite. Lorsque beaucoup de personnes ont voulu élaborer des compilateurs multi-plateformes pour FreeBSD, elles n’eurent pas beaucoup de chance puisque les anciennes sources que FreeBSD avait pour as et ld n’étaient pas adaptées à cette tâche. Le nouvel ensemble d’outils de GNU (binutils) supporte la compilation multi-plateformes, ELF, les bibliothèques partagées, les extensions C++, etc. De plus, de nombreux vendeurs de logiciels fournissent des binaires ELF, et c’est une bonne chose pour permettre leur exécution sous FreeBSD.
ELF est plus expressif qu'a.out et permet plus d’extensibilité dans le système de base. Les outils ELF sont mieux maintenus, et offrent un support pour la compilation multi-plateformes, ce qui est important pour de nombreuses personnes. ELF peut être légèrement plus lent qu'a.out, mais tenter de mesurer cette différence n’est pas aisé. Il y a également de nombreux détails qui diffèrent entre les deux dans la façon dont ils mappent les pages mémoire, gère le code d’initialisation, etc. Dans le futur, le support a.out sera retiré du noyau GENERIC, et par la suite retiré des sources du noyau une fois que le besoin d’exécuter d’anciens programmes a.out aura disparu.
3.13. Pour plus d’information
3.13.1. Les pages de manuel
La documentation la plus complète sur FreeBSD est sous la forme de pages de manuel. Presque chaque programme sur le système est fournit avec un court manuel de référence expliquant l’utilisation de base et les diverses options. Ces manuels peuvent être visualisés avec la commande man. L’utilisation de la commande man est simple:
% man commandcommand est le nom de la commande à propos de laquelle vous désirez en savoir plus. Par exemple, pour en savoir plus au sujet de la commande ls tapez:
% man lsLes manuels en ligne sont divisés en sections numérotées:
Commandes utilisateur.
Appels système et numéros d’erreur.
Fonctions des bibliothèques C.
Pilotes de périphérique.
Formats de fichier.
Jeux et autres divertissements.
Information diverse.
Commandes de maintenance et d’utilisation du système.
Information de développement du noyau.
Dans certains cas, le même sujet peut apparaître dans plus d’une section du manuel en ligne. Par exemple, il existe une commande utilisateur chmod et un appel système chmod(). Dans ce cas, vous pouvez préciser à la commande man laquelle vous désirez en spécifiant la section:
% man 1 chmodCela affichera la page de manuel de la commande utilisateur chmod. Les références à une section particulière du manuel en ligne sont traditionnellement placées entre parenthèses, ainsi chmod(1) se rapporte à la commande utilisateur chmod et chmod(2) se rapporte à l’appel système.
C’est parfait si vous connaissez le nom de la commande et vous souhaitez simplement savoir comment l’utiliser, mais qu’en est-il si vous ne pouvez pas vous rappelez du nom de la commande? Vous pouvez utiliser man pour rechercher des mots-clés dans les descriptions de commandes en employant l’option -k:
% man -k mailAvec cette commande on vous affichera la liste des commandes qui ont le mot-clé "mail" dans leurs descriptions. C’est en fait équivalent à l’utilisation de la commande apropos.
Ainsi, vous regardez toutes ces commandes fantaisistes contenues dans /usr/bin mais vous n’avez pas la moindre idée de ce quelles font vraiment? Faites simplement:
% cd /usr/bin
% man -f *ou
% cd /usr/bin
% whatis *ce qui fait la même chose.
3.13.2. Fichiers GNU Info
FreeBSD inclut beaucoup d’applications et d’utilitaires produit par la Fondation pour le Logiciel Libre ( Free Software Foundation). En plus des pages de manuel, ces programmes sont fournis avec des documents hypertexte appelés fichiers info qui peuvent être lus avec la commande info ou, si vous avez installé emacs, dans le mode info d’emacs.
Pour utiliser la commande info(1), tapez simplement:
% infoPour une brève introduction, tapez h. Pour une référence rapide sur la commande, tapez ?.
Last modified on: 9 mars 2024 by Danilo G. Baio