
Additional ABI support:.
Local package initialization:.
Additional TCP options:.
Fri Sep 20 13:01:06 EEST 2002
FreeBSD/i386 (pc3.example.org) (ttyv0)
login:Capitolo 3. Basi di Unix
This translation may be out of date. To help with the translations please access the FreeBSD translations instance.
Indice
3.1. Sinossi
Il seguente capitolo tratta i comandi e le funzionalità di base del sistema operativo FreeBSD. Molto di questo materiale è valido anche per altri sistemi operativi UNIX®-like. Sentiti libero di leggere velocemente questo capitolo se hai familiarità con questo materiale. Se sei un utente alle prime armi di FreeBSD, allora dovrai di sicuro leggere questo capitolo attentamente.
Dopo aver letto questo capitolo, saprai:
Come usare le "console virtuali" di FreeBSD.
Come funzionano i permessi dei file UNIX® oltre ad una spiegazione dei flag sotto FreeBSD.
La struttura di default del file system di FreeBSD.
L’organizzazione del disco di FreeBSD.
Come montare e smontare i file system.
Cosa sono i processi, i demoni e i segnali.
Cos’è una shell, e come cambiare il proprio ambiente di login di default.
I principi di base sull’uso degli editor testuali.
Cosa sono i dispositivi e i nodi dei dispositivi.
Quali formati dei binari sono usati in FreeBSD.
Come leggere le pagine man per ottenere maggiori informazioni.
3.2. Console Virtuali e Terminali
FreeBSD può essere usato in vari modi. Uno di questi è quello di digitare i comandi tramite un terminale testuale. Quando si utilizza FreeBSD in questo modo si ha velocemente nelle proprie mani molta della flessibilità e della potenza di un sistema operativo UNIX®. Questa sezione descrive cosa sono i "terminali" e le "console", e come si possono utilizzare in FreeBSD.
3.2.1. La console
Se non hai configurato FreeBSD in modo tale da avviare in modo automatico l’ambiente grafico durante l’avvio, il sistema ti fornirà un prompt di login dopo la fase di avvio, esattamente dopo che gli script di avvio sono stati eseguiti. Dovresti vedere qualcosa simile a questo:
I messaggi potrebbero essere leggermente diversi sul tuo sistema, tuttavia dovresti vedere qualcosa di analogo. In questo momento ci interessano le ultime due righe. Analizziamo la penultima riga:
FreeBSD/i386 (pc3.example.org) (ttyv0)
Questa riga contiene alcune informazioni sul sistema che hai appena avviato. Sei di fronte a una console "FreeBSD", che sta girando su un processore Intel o su un processore compatibile con l’architettura x86. Il nome di questa macchina (tutte le macchine UNIX® hanno un nome) è pc3.example.org, e in questo momento sei di fronte alla sua console di sistema-il terminale ttyv0.
Infine, l’ultima riga è sempre:
login:
Qui devi digitare il tuo "username" per loggarti in FreeBSD. La prossima sezione descrive come fare ad effettuare il login su FreeBSD.
3.2.2. Loggarsi in FreeBSD
FreeBSD è un sistema multi-utente e multi-processo. Questa è la descrizione formale che viene usualmente attribuita a un sistema che può essere usato da diverse persone, le quali eseguono contemporaneamente molti programmi su una singola macchina.
Ogni sistema multi-utente necessita di qualche metodo che distingua un "utente" in modo univoco. In FreeBSD (e in tutti i sistemi operativi UNIX®-like), questo viene realizzato richiedendo che ogni utente debba "loggarsi" nel sistema prima che possa eseguire qualche programma. Ogni utente ha un nome univoco (lo "username"), uno personale e una chiave segreta (la "password"). FreeBSD richiede entrambe queste due cose prima di dare la possibilità ad un utente di eseguire qualche programma.
Appena dopo la fase di avvio di FreeBSD e quando gli script di avvio sono stati eseguiti, ti viene presentato un prompt dove inserire un valido username:
login:Giusto per questo esempio, assumiamo che il tuo username sia john. Al prompt digita john e premi Invio. Ti verrà presentato un prompt dove inserire la "password":
login: john
Password:Digita la password di john, e premi Invio. La password non viene visualizzata! Non ti devi preoccupare di questo per ora. È sufficiente sapere che è una questione di sicurezza.
Se hai digitato la tua password in modo corretto, dovresti essere loggato in FreeBSD e sei quindi pronto per provare tutti i comandi disponibili.
Dovresti inoltre vedere il messaggio del giorno (MOTD) seguito da un prompt dei comandi (un carattere #, $, o %). Ciò indica che sei a tutti gli effetti loggato su FreeBSD.
3.2.3. Console Multiple
Eseguire comandi UNIX® in una sola console va bene, tuttavia FreeBSD può eseguire più programmi alla volta. Avere una sola console dove poter digitare i comandi può essere un pò uno spreco quando un sistema operativo come FreeBSD è in grado di eseguire dozzine di programmi contemporaneamente. È in questo caso che le "console virtuali" possono essere molto utili.
FreeBSD può essere configurato in modo tale da poter utilizzare differenti console virtuali. Puoi passare da una console virtuale ad un’altra digitando un paio di tasti sulla tastiera. Ogni console ha il proprio canale di output indipendente, e FreeBSD si occupa di redirigere correttamente l’input della tastiera e l’output del monitor quando passi da una console virtuale in un’altra.
In FreeBSD alcune combinazioni speciali di tasti sono state riservate per il passaggio tra le console. Puoi usare Alt+F1, Alt+F2, fino a Alt+F8 per cambiare console su FreeBSD.
Quando passi da una console ad un’altra, FreeBSD si preoccupa di salvare e ripristinare l’output a video. Il risultato è l'"illusione" di avere più schermi e più tastiere "virtuali" che puoi utilizzare per dare in pasto a FreeBSD dei comandi. I programmi che lanci su una console virtuale rimarranno in esecuzione anche quando la console non è visibile. L’esecuzione di questi programmi continua quando passi in un’altra console virtuale.
3.2.4. Il File /etc/ttys
La configurazione di default di FreeBSD prevede l’avvio del sistema con otto console virtuali. Comunque questo non è un settaggio obbligatorio, e puoi facilmente personalizzare la tua installazione in modo tale da avviare il sistema con qualche console virtuale in più o in meno. Il numero e i settaggi delle console virtuali sono configurati nel file /etc/ttys.
Puoi usare il file /etc/ttys per configurare le console virtuali di FreeBSD. In questo file ogni riga non commentata (le righe che non iniziano con il carattere #) contiene i settaggi di un singolo terminale o di una singola console. La versione di default di questo file contenuta in FreeBSD configura nove console virtuali, ed abilita otto di queste. Sono le righe che iniziano con ttyv:
# name getty type status comments # ttyv0 "/usr/libexec/getty Pc" cons25 on secure # Terminali virtuali ttyv1 "/usr/libexec/getty Pc" cons25 on secure ttyv2 "/usr/libexec/getty Pc" cons25 on secure ttyv3 "/usr/libexec/getty Pc" cons25 on secure ttyv4 "/usr/libexec/getty Pc" cons25 on secure ttyv5 "/usr/libexec/getty Pc" cons25 on secure ttyv6 "/usr/libexec/getty Pc" cons25 on secure ttyv7 "/usr/libexec/getty Pc" cons25 on secure ttyv8 "/usr/X11R6/bin/xdm -nodaemon" xterm off secure
Per una descrizione più dettagliata su ogni colonna di questo file e per tutte le opzioni che puoi utilizzare per settare le console virtuali, consulta la pagina man ttys(5).
3.2.5. Console in Modalità Single User
Una descrizione dettagliata del significato della "modalità single user" può essere trovata nella Modalità Singolo Utente. È bene notare che c’è un’unica console quando avvii FreeBSD in modalità single user. Le console virtuali non sono disponibili. Anche i settaggi della console in modalità single user possono essere trovati nel file /etc/ttys. Guarda la riga che inizia con console:
# name getty type status comments # # Se la console è definita "insecure", allora il processo init richiederà la password di root # quando entrerai in modalità single-user. console none unknown off secure
Come riportato nel commento sopra la riga Pensaci comunque due volte a settare il parametro |
3.2.6. Modifica delle Modalità Video della Console
La modalità video di default della console di FreeBSD può essere impostata a 1024x768, 1280x1024, o ad un altra risoluzione supportata dalla tua scheda grafica e dal tuo monitor. Per usare una modalità video differente, devi prima ricompilare il tuo kernel aggiungendo due opzioni:
options VESA options SC_PIXEL_MODE
Quando il kernel è stato ricompilato con queste due opzioni, puoi determinare quali modalità video sono supportate dal tuo hardware usando l’utility vidcontrol(1). Per ottenere una lista delle modalità video supportate, digita il seguente comando:
# vidcontrol -i modeL’output di questo comando è una lista delle modalità video che sono supportate dal tuo hardware. Puoi usare una nuova modalità video indicandola a vidcontrol(1) in una console root:
# vidcontrol MODE_279Se la nuova modalità è soddisfacente, può essere impostata in modo permanente ad ogni avvio nel file /etc/rc.conf:
allscreens_flags="MODE_279"
3.3. I Permessi
FreeBSD, essendo un discendente diretto dello UNIX® BSD, si basa su molti concetti chiave di UNIX®. Il primo e il più affermato è che FreeBSD è un sistema operativo multi-utente. Il sistema può gestire diversi utenti che lavorano contemporaneamente su operazioni indipendenti. Il sistema è responsabile della gestione e della suddivisione appropriata delle richieste di utilizzo dei dispositivi hardware, delle periferiche, della memoria, e del tempo di CPU in modo equo per ogni utente.
Poichè il sistema è in grado di supportare più utenti, tutto ciò che il sistema gestisce possiede un insieme di permessi che determinano chi può leggere, scrivere, ed eseguire la risorsa. Questi permessi sono memorizzati mediante tre ottetti suddivisi in tre parti, una per il proprietario del file, una per il gruppo al quale il file appartiene, e una per tutti gli altri. Questa rappresentazione numerica funziona in questo modo:
| Valore | Permessi | Listato nella Directory |
|---|---|---|
0 | Lettura no, scrittura no, esecuzione no |
|
1 | Lettura no, scrittura no, esecuzione |
|
2 | Lettura no, scrittura, esecuzione no |
|
3 | Lettura no, scrittura, esecuzione |
|
4 | Lettura, scrittura no, esecuzione no |
|
5 | Lettura, scrittura no, esecuzione |
|
6 | Lettura, scrittura, esecuzione no |
|
7 | Lettura, scrittura, esecuzione |
|
Puoi usare l’opzione -l del comando ls(1) per visualizzare un lungo listato della directory che include una colonna contenente le informazioni sui permessi del file per il proprietario, per il gruppo, e per gli altri. Per esempio, digitando ls -l in una arbitraria directory:
% ls -l
total 530
-rw-r--r-- 1 root wheel 512 Sep 5 12:31 myfile
-rw-r--r-- 1 root wheel 512 Sep 5 12:31 otherfile
-rw-r--r-- 1 root wheel 7680 Sep 5 12:31 email.txt
...Ecco come è suddivisa la prima colonna dell’output del comando ls -l:
-rw-r--r--Il primo carattere (partendo da sinistra) indica se il file in questione è un file regolare, una directory, un file speciale per dispositivi a caratteri, una socket, o un file speciale per altri dispositivi. Nel nostro caso, il - indica un file regolare. I tre caratteri successivi, che in questo esempio sono rw-, indicano i permessi per il proprietario del file. Seguono altri tre caratteri, r--, che indicano i permessi del gruppo al quale il file appartiene. Gli ultimi tre caratteri, r--, indicano i permessi per il resto del mondo. Un trattino significa che il permesso non viene concesso. Nel caso di questo file, i permessi sono settati affinchè il proprietario possa leggere e scrivere il file, il gruppo possa leggere il file, e il resto del mondo possa solamente leggere il file. In accordo con la precedente tabella, i permessi per questo file sono 644, dove ogni cifra rappresenta una delle tre parti che costituiscono i permessi del file.
D’accordo, ma in che modo il sistema controlla i permessi sui dispositivi? FreeBSD tratta molti dispositivi hardware esattamente come un file che i programmi possono aprire, leggere, e scrivere dei dati proprio come avviene con gli altri file. Questi file speciali per i dispositivi sono memorizzati nella directory /dev.
Anche le directory sono trattate come file. Queste hanno permessi di lettura, scrittura e di esecuzione. Il bit riferito al permesso di esecuzione per una directory ha un significato leggermente differente rispetto a quello dei file. Quando una directory ha il permesso di esecuzione abilitato, significa che si ha accesso alla directory, ossia è possibile eseguire il comando "cd" (cambio di directory) per entrarci. Inoltre questo significa che all’interno della directory è possibile accedere ai file dei quali si conosce il nome (naturalmente a condizione dei permessi degli stessi file).
In particolare, per visualizzare il contenuto di una directory, deve essere abilitato il permesso di lettura sulla stessa, mentre per eliminare un file di cui si conosce il nome, è necessario che la directory contenente il file abbia i permessi di scrittura e di esecuzione abilitati.
Ci sono altri bit per permessi particolari, ma sono in genere usati in circostanze speciali come il permesso di setuid per i binari e quello di sticky per le directory. Se vuoi avere più informazioni sui permessi dei file e su come settarli, guarda la pagina man di chmod(1).
3.3.1. Permessi Simbolici
I permessi simbolici, qualche volta chiamati espressioni simboliche, usano caratteri al posto dei numeri ottali per assegnare i permessi a file o directory. Le espressioni simboliche usano la sintassi (chi) (azione) (permessi), con i seguenti valori:
| Opzione | Lettera | Cosa rappresenta/Cosa fa |
|---|---|---|
(chi) | u | Utente |
(chi) | g | Gruppo di appartenenza |
(chi) | o | Altri |
(chi) | a | Tutti (tutto il "mondo") |
(azione) | + | Aggiunge i permessi |
(azione) | - | Rimuove i permessi |
(azione) | = | Setta esplicitamente i permessi |
(permessi) | r | Lettura |
(permessi) | w | Scrittura |
(permessi) | x | Esecuzione |
(permessi) | t | Bit sticky |
(permessi) | s | Setta UID o GID |
Questi valori sono usati con il comando chmod(1) come esposto in precedenza, ma con le lettere. Per esempio, puoi usare il seguente comando per impedire agli altri utenti l’accesso a FILE:
% chmod go= FILESe si ha la necessità di realizzare più di una modifica ai settaggi di un file si può usare una lista di settaggi separati da virgola. Per esempio il seguente comando rimuoverà il permesso di scrittura su FILE al gruppo di appartenenza del file e al resto del "mondo", e inoltre aggiungerà il permesso di esecuzione per tutti:
% chmod go-w,a+x FILE3.3.2. Flag dei File in FreeBSD
Oltre ai permessi dei file discussi in precedenza, FreeBSD supporta l’uso dei "flag dei file". Queste flag aggiungono un ulteriore livello di sicurezza e di controllo sui file, ma non per le directory.
Queste flag dei file aggiungono un ulteriore livello di controllo sui file, assicurando in alcuni casi che persino root non possa rimuovere o alterare file.
Le flag dei file sono alterate usando l’utility chflags(1), tramite una semplice sintassi. Per esempio, per abilitare la flag di sistema di non-cancellabilità sul file file1, si può usare il comando seguente:
# chflags sunlink file1E per disabilitare la stessa flag, si può usare semplicemente il comando precedente con "no" davanti a sunlink. Ecco come:
# chflags nosunlink file1Per vedere le flag del file di esempio, usa il comando ls(1) con le flag -lo:
# ls -lo file1L’output dovrebbe assomigliare al seguente:
-rw-r--r-- 1 trhodes trhodes sunlnk 0 Mar 1 05:54 file1
Diverse flag possono essere aggiunte o rimosse sui file solo tramite l’utente root. Negli altri casi, il proprietario dei file può settare queste flag. Si raccomanda di leggere le pagine man chflags(1) e chflags(2) per maggiori informazioni.
3.4. Struttura delle Directory
La gerarchia delle directory di FreeBSD è fondamentale per ottenere una comprensione globale del sistema. Il concetto più importante da cogliere al volo è quello relativo alla directory root, "/". Questa directory è la prima ad essere montata all’avvio e contiene gli elementi fondamentali del sistema necessari per predisporre il sistema operativo al funzionamento multi-utente. Inoltre la directory root contiene i punti di mount per gli altri file system che sono montati durante la transizione per il funzionamento multi-utente.
Un punto di mount è una directory dove dei file system aggiuntivi possono essere innestati sul file system padre (in genere il file system root). Questo è ulteriormente descritto nella Organizzazione del Disco. Alcuni punti di mount standard sono /usr, /var, /tmp, /mnt, e /cdrom. Queste directory compaiono in genere negli elementi del file /etc/fstab. Il file /etc/fstab è una tabella di file system e punti di mount che viene consultata dal sistema. Molti dei file system riferiti nel file /etc/fstab sono montati in modo automatico all’avvio tramite lo script rc(8) a meno che essi sia stati dichiarati con l’opzione noauto. Maggiori dettagli possono essere trovati nella Il File fstab.
Una descrizione completa della gerarchia del file system è disponibile nella pagina man hier(7). Per ora, è sufficiente una breve panoramica generale delle directory più comuni.
| Directory | Descrizione |
|---|---|
/ | Directory root del file system. |
/bin/ | Utilità fondamentali per l’utente sia in ambiente mono-utente sia in ambiente multi-utente. |
/boot/ | Programmi e file di configurazione utilizzati durante la fase di avvio del sistema operativo. |
/boot/defaults/ | File di configurazione di avvio di default; consultare loader.conf(5). |
/dev/ | Nodi di dispositivo; consultare intro(4). |
/etc/ | Script e file di configurazione del sistema. |
/etc/defaults/ | File di configurazione di default del sistema; consultare rc(8). |
/etc/mail/ | File di configurazione per gli MTA (Mail Transfer Agent, agente di trasferimento della posta elettronica) come sendmail(8). |
/etc/namedb/ | File di configurazione di |
/etc/periodic/ | Script che sono eseguiti giornalmente, settimanalmente, e mensilmente tramite cron(8); consultare periodic(8). |
/etc/ppp/ | File di configurazione di |
/mnt/ | Directory vuota usata comunemente dagli amministratori di sistema come punto di mount temporaneo. |
/proc/ | File system dedicato ai processi; consultare procfs(5), mount_procfs(8). |
/rescue/ | Programmi linkati staticamente per situazioni di emergenza; consultare rescue(8). |
/root/ | Directory home per l’account |
/sbin/ | Programmi di sistema e utilità di amministrazione fondamentali sia in ambiente mono-utente sia in ambiente multi-utente. |
/tmp/ | File temporanei. Il contenuto di /tmp di solito NON è preservato dopo un riavvio del sistema. Spesso un file system basato sulla memoria viene montato in /tmp. Questo può essere automatizzato usando le variabili relative a tmpmfs di rc.conf(5) (o con un entry in /etc/fstab; consultare mdmfs(8)). |
/usr/ | La maggior parte delle applicazioni e delle utilità dell’utente. |
/usr/bin/ | Utilità, strumenti di programmazione, e applicazioni comuni. |
/usr/include/ | File include standard del C. |
/usr/lib/ | Archivio di librerie. |
/usr/libdata/ | Archivio di dati per utilità varie. |
/usr/libexec/ | Demoni di sistema & utilità di sistema (eseguiti da altri programmi). |
/usr/local/ | Eseguibili locali, librerie locali, ecc. Usata anche come destinazione di default per la struttura dei port di FreeBSD. All’interno di /usr/local, viene usato lo stesso schema generale descritto in hier(7) per la directory /usr. Le eccezioni sono la directory man, che è posta direttamente sotto /usr/local piuttosto che sotto /usr/local/share, e la documentazione dei port che è in share/doc/port. |
/usr/obj/ | Albero degli elementi dipendenti dal tipo di architettura dell’elaboratore prodotto dalla costruzione dell’albero /usr/src. |
/usr/ports | Collezione dei port di FreeBSD (opzionale). |
/usr/sbin/ | Demoni di sistema & utilità di sistema (eseguiti dagli utenti). |
/usr/shared/ | File indipendenti dal tipo di architettura dell’elaboratore. |
/usr/src/ | File sorgenti di BSD e/o sorgenti proprietari. |
/usr/X11R6/ | Eseguibili, librerie, ecc. riguardanti la distribuzione X11R6 (opzionale). |
/var/ | File log di vario genere, file temporanei, file transitori, e file di spool. Qualche volta un file system basato sulla memoria è montato in /var. Questo può essere automatizzato usando le variabili relative a varmfs di rc.conf(5) (o con un entry in /etc/fstab; consultare mdmfs(8)). |
/var/log/ | File di log del sistema di vario genere. |
/var/mail/ | File delle caselle di posta degli utenti. |
/var/spool/ | Directory di spool per stampanti e per la posta elettronica del sistema. |
/var/tmp/ | File temporanei. I file sono di solito preservati dopo un riavvio del sistema, a meno che /var sia un file system basato sulla memoria. |
/var/yp | Mappe NIS. |
3.5. Organizzazione del Disco
La più piccola unità di organizzazione che FreeBSD usa per ricercare file è il nome del file. I nomi dei file sono case-sensitive, ciò significa che readme.txt e README.TXT sono due file distinti. FreeBSD non usa l’estensione (es. .txt) di un file per determinare se il file è un programma, un documento, o qualche altra forma di dati.
I file sono memorizzati in directory. Una directory può contenere centinaia di file o non contenerne affatto. Inoltre una directory può contenere altre directory, consentendo di costruire una gerarchia di directory all’interno di un’altra. Tutto questo rende più facile l’organizzazione dei tuoi dati.
Ci si riferisce a file e directory attraverso il nome del file o della directory, seguito da uno slash in avanti, /, a sua volta seguito da altri nomi di directory necessari. Se hai una directory di nome foo, la quale contiene la directory bar, che a sua volta contiene il file readme.txt, allora il nome completo, chiamato anche il percorso del file è foo/bar/readme.txt.
Le directory e i file sono memorizzati in un file system. Ogni file system contiene esattamente una directory al livello più alto, chiamata la directory root di quel file system. Questa directory root può contenere altre directory.
Fin qui è probabilmente tutto simile ad altri sistemi operativi che hai usato. Tuttavia ci sono alcune differenze; per esempio, MS-DOS® usa il carattere \ per separare i nomi di file e directory, mentre Mac OS® usa :.
FreeBSD non usa lettere di dispositivi, o altri nomi di dispositivi nel path. In FreeBSD non dovrai mai scrivere c:/foo/bar/readme.txt.
Piuttosto, un file system è designato come il file system root. La directory root del file system root è riferita con /. Ogni altro file system è montato sotto il file system root. Non importa quanti dischi hai sul tuo sistema FreeBSD, ogni directory è come se fosse parte dello stesso disco.
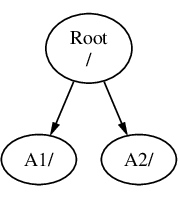
Supponiamo che tu abbia tre file system, chiamati A, B, e C. Ogni file system ha una directory root, la quale contiene altre due directory, chiamate A1, A2 (e nello stesso modo B1, B2 e C1, C2).
Sia A il file system root. Se usi il comando ls per visualizzare il contenuto di questa directory dovresti vedere due sottodirectory, A1 e A2. L’albero delle directory assomiglia a questo:
Un file system deve essere montato su una directory di un altro file system. Supponiamo ora che tu monti il file system B sulla directory A1. La directory root di B rimpiazza A1, e di conseguenza appariranno le directory di B:
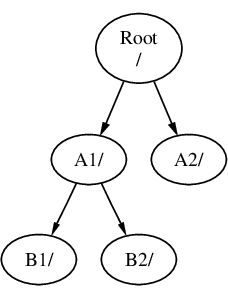
I file contenuti nelle directory B1 o B2 possono essere raggiunti con il path /A1/B1 o /A1/B2. I file che erano in /A1 sono stati temporaneamente nascosti. Questi riappariranno quando B sarà smontato da A.
Se B è stato montato su A2 allora il diagramma assomiglierà a questo:
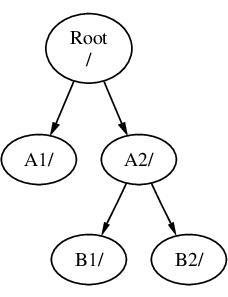
e i percorsi saranno rispettivamente /A2/B1 e /A2/B2.
I file system possono essere montati in cima ad altri file system. Continuando con l’ultimo esempio, il file system C può essere montato in cima alla directory B1 nel file system B, arrivando a questa sistemazione:
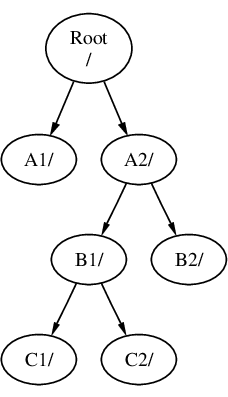
Oppure C potrebbe essere montato direttamente sul file system A, sotto la directory A1:
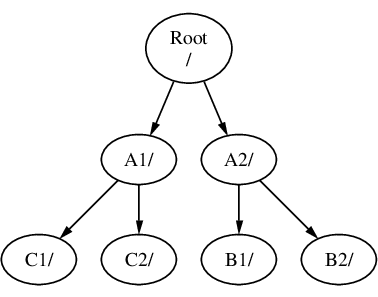
Se hai familiarità con MS-DOS®, questo è simile, ma non identico, al comando join.
Di solito non ti devi occupare direttamente di questi aspetti. Tipicamente quando installi FreeBSD crei i file system e decidi dove montarli, e da quel momento non avrai più la necessità di modificarli a meno che installi un nuovo disco.
È possibile avere un unico file system root, senza avere la necessità di crearne altri. Esistono alcuni svantaggi utilizzando questo approccio, e un solo vantaggio.
Benefici con File system Multipli
Filesystem diversi possono avere opzioni di mount diverse. Per esempio, in un’attenta progettazione, il file system root potrebbe essere montato in modalità di sola lettura, rendendo impossibile la cancellazione accidentale o la modifica di un file critico. Inoltre, separando i file system scrivibili dall’utente, come /home, da altri file system permette di montare i primi con l’opzione nosuid; questa opzione non permette il settaggio dei bit suid/guid sui file eseguibili memorizzati sul file system che ha tale opzione di mount attivata, migliorando l’aspetto sicurezza.
FreeBSD ottimizza in modo automatico la disposizione dei file sul file system, a seconda di come è usato il file system. Quindi un file system che contiene molti file piccoli che sono scritti di frequente avrà un’ottimizzazione diversa rispetto ad un altro file system che contiene pochi file di grandi dimensioni. Utilizzando un solo grande file system questa ottimizzazione viene a mancare.
I file system di FreeBSD reagiscono bene ad una violenta perdita di energia elettrica. Tuttavia, una perdita di energia in un punto critico potrebbe sempre danneggiare la struttura del file system. Splittando i tuoi dati su file system multipli sarà più probabile che il sistema riparta, dandoti la possibilità di ripristinare un precedente backup se necessario.
Benefici di un File system Singolo
I file system sono a dimensione fissa. Se crei un solo file system quando installi FreeBSD e gli assegni una data dimensione, in futuro potresti scoprire che necessiti di creare una partizione più grande. Questo non è facilmente realizzabile se non effettuando un backup dei dati, ricreando il file system con la nuova dimensione, e quindi ripristinando il backup di dati.
FreeBSD ha il comando growfs(8), con il quale è possibile incrementare la dimensione del file system al volo, rimuovendo questa limitazione.
I file system sono contenuti all’interno di partizioni. Qui il significato del termine partizione si discosta dall’uso comune di questo termine (partizioni MS-DOS®, per esempio), a causa dell’eredità UNIX® di FreeBSD. Ogni partizione è identificata da una lettera partendo dalla a fino alla h. Ogni partizione può contenere solo un file system, il che significa che i file system sono spesso identificati sia dal loro punto di mount nella gerarchia del file system, sia dalla lettera della partizione nella quale sono contenuti.
Inoltre FreeBSD usa parte del disco per lo spazio di swap. Lo spazio di swap fornisce a FreeBSD la funzionalità di memoria virtuale. Questo permette al tuo computer di comportarsi come se avesse più memoria di quella che ha realmente. Quando FreeBSD esaurisce la memoria muove alcuni dati presenti in memoria che non sono utilizzati in quel momento nello spazio di swap, e li riporta in memoria (spostando nello spazio di swap qualche altro dato) non appena necessari.
Alcune partizioni hanno certe convenzioni a loro associate.
| Partizione | Convenzione |
|---|---|
| In genere contiene il file system root |
| In genere contiene lo spazio di swap |
| Di solito rappresenta l’intera dimensione della slice. Questo permette a utility che necessitano di lavorare sull’intera slice (per esempio, uno scanner di blocchi difettosi) di lavorare sulla partizione |
| La partizione |
Ogni partizione contenente un file system è memorizzata in ciò che FreeBSD chiama slice. Slice è un termine di FreeBSD per identificare ciò che comunemente viene chiamato partizione, e di nuovo, questo è dovuto dal background UNIX® di FreeBSD. Le slice sono numerate, partendo da 1 e arrivando fino a 4.
I numeri di slice seguono il nome del dispositivo, preceduti da una s, e partendo da 1. Quindi "da0s1" è la prima slice sul primo disco SCSI. Ci possono essere solo quattro slice fisiche su un disco, ma puoi avere slice logiche all’interno di slice fisiche di un appropriato tipo. Queste slice estese sono numerate a partire da 5, quindi "ad0s5" è la prima slice estesa sul primo disco IDE. Questi stratagemmi sono usati per i file system che si aspettano di occupare una slice.
Le slice, i dispositivi fisici "pericolosamente dedicati", e altri dispositivi contengono partizioni, le quali sono rappresentate tramite lettere dalla a fino alla h. Queste lettere seguono il nome del dispositivo, quindi "da0a" è la partizione a sul primo dispositivo da, il quale è "pericolosamente dedicato". "ad1s3e" è la quinta partizione nel terza slice del secondo disco IDE.
In fine, ogni disco sul sistema è identificato. Un nome di un disco incomincia con un codice che indica il tipo di disco, seguito da un numero, che indica quale disco esso sia. A differenza delle slice, i numeri riferiti al disco incominciano da 0. Puoi vedere dei codici generici in Codici dei Dispositivi Disco.
Quando fai riferimento a una partizione di FreeBSD devi specificare anche il nome della slice e del disco che contengono la partizione, e quando fai riferimento a una slice dovresti specificare anche il nome del disco. Per riferirti ad una partizione specifica quindi il nome del disco, il carattere s, il numero di slice, e infine la lettera della partizione. Alcuni esempi sono mostrati nell'Esempi di Nomi di Dischi, di Slice, e di Partizioni.
L'Modello Concettuale di un Disco mostra un modello concettuale di struttura di un disco che dovrebbe aiutare a chiarire le cose.
Per installare FreeBSD devi prima configurare le slice del disco, creare le partizioni all’interno della slice che vuoi usare per FreeBSD, e quindi creare un file system (o spazio di swap) in ogni partizione, e decidere dove il file system deve essere montato.
| Codice | Significato |
|---|---|
ad | disco ATAPI (IDE) |
da | disco ad accesso diretto SCSI |
acd | CDROM ATAPI (IDE) |
cd | CDROM SCSI |
fd | Disco floppy |
Esempio 1. Esempi di Nomi di Dischi, di Slice, e di Partizioni
| Nome | Significato |
|---|---|
| La prima partizione ( |
| La quinta partizione ( |
Esempio 2. Modello Concettuale di un Disco
Questo diagramma mostra come FreeBSD vede il primo disco IDE attaccato al sistema. Si assuma che il disco sia di 4 GB, e che contenga due slice da 2 GB (equivalenti come significato a due partizioni MS-DOS®). La prima slice contiene un disco MS-DOS®, C:, e la seconda slice contiene un’installazione di FreeBSD. In questo esempio l’installazione di FreeBSD ha tre partizioni dati più una di swap.
Le tre partizioni conterranno ognuna un file system. La partizione a sarà usata per il file system root, la e per la gerarchia di directory /var, e la partizione f per la gerarchia di directory /usr.

3.6. Montaggio e Smontaggio dei File system
Il file system è raffigurato in maniera ottimale da un albero, radicato, per così dire, in /. Le directory /dev, /usr, e le altre directory che stanno all’interno della directory root sono i rami, i quali possono essere a loro volta ramificati, come in /usr/local, e così via.
Esistono varie ragioni per mantenere alcune di queste directory su file system separati. La directory /var contiene le directory log/, spool/, e vari tipi di file temporanei, e come tale, può riempirsi. Riempire il file system root non è una buona idea, quindi scindere la directory /var da / è spesso vantaggioso.
Un’altra motivazione per mantenere certi alberi di directory su altri file system è quando questi alberi sono alloggiati su dischi fisici separati, o sono dischi virtuali separati, come avviene per i mount del Network File System, o dei dispositivi CDROM.
3.6.1. Il File fstab
Durante la fase di avvio, i file system elencati nel file /etc/fstab sono montati in modo automatico (a meno che siano specificati con l’opzione noauto).
Il file /etc/fstab contiene una serie di righe il cui formato è il seguente:
device /mount-point fstype options dumpfreq passno
deviceIl nome del dispositivo (che deve esistere), come spiegato nella Device Names.
mount-pointLa directory (che deve esistere), sulla quale montare il file system.
fstypeIl tipo di file system da passare a mount(8). Il file system di default di FreeBSD è
ufs.optionsrwper file system leggibili-scrivibili, oppureroper file system solamente leggibili, seguite da altre opzioni che potrebbero essere necessarie. Un’opzione comune ènoautoper i file system che normalmente non sono montati durante la sequenza di avvio. Altre opzioni sono elencate nella pagina man di mount(8).dumpfreqViene usato da dump(8) per determinare quali file system richiedono un dump. Se non si specifica nulla, viene assunto il valore zero.
passnoDetermina l’ordine secondo il quale i file system vengono controllati. I file system che devono saltare il controllo devono avere i loro
passnosettati a zero. Il file system root (che deve essere controllato prima di qualsiasi altra cosa) deve avere il suopassnosettato a uno, e ipassnodegli altri file system devono essere settati a valori maggiori di uno. Se più di un file system ha lo stessopassnoallora fsck(8) tenterà di controllare i file system in parallelo.
Per maggiori informazioni sul formato del file /etc/fstab e sulle opzioni che esso contiene consulta la pagina man fstab(5).
3.6.2. Il Comando mount
Il comando mount(8) è ciò che in definitiva viene usato per montare i file system.
La sua forma di utilizzo elementare è:
# mount device mountpointEsistono molte opzioni, come spiegato nella pagina man di mount(8), ma le più comuni sono:
Opzioni di Mount
-aMonta tutti i file system elencati nel file /etc/fstab. Le eccezioni sono quei file system specificati come "noauto", quelli esclusi dalla flag
-t, o quei file system che sono già montati.-dFà tutto ad eccezione della attuale system call di mount. Questa opzione risulta utile in congiunzione con la flag
-vper determinare quello che mount(8) sta effettivamente tentando di fare.-fForza il mount di un file system non correttamente smontato (pericoloso), o forza la revoca di accesso in scrittura quando si declassa lo stato di mount di un file system da lettura-scrittura a lettura solamente.
-rMonta il file system in sola lettura. Questo è identico ad usare l’argomento
ro(rdonlyper versioni di FreeBSD dopo la 5.2) con l’opzione-o.-tfstypeMonta il dato file system secondo il tipo di file system specificato, oppure, se affiancato dall’opzione
-a, monta solamente i file system di un dato tipo."ufs" è il tipo di file system di default.
-uAggiorna le opzioni di mount sul file system.
-vModalità verbosa.
-wMonta il file system in lettura-scrittura.
L’opzione -o accetta una lista di argomenti separati da una virgola, inclusi i seguenti:
- noexec
Non permette l’esecuzione di binari su questo file system. Questa è un’altra utile opzione di sicurezza.
- nosuid
Non permette l’interpretazione delle flag setuid o setgid sul file system. Anche questa è un’utile opzione di sicurezza.
3.6.3. Il Comando umount
Il comando umount(8) accetta, come unico parametro, un punto di mount, un nome di dispositivo, l’opzione -a o l’opzione -A.
Tutte queste modalità accettano l’opzione -f per forzare la smontatura, e l’opzione -v per la modalità verbosa. Sei avvisato che l’opzione -f non è in generale un buona idea. Smontare in modo forzato i file system può mandare in crash il computer o danneggiare i dati sul file system.
Le opzioni -a e -A sono usate per smontare tutti i file system, con la possibilità di specificare i tipi di file system elencandoli dopo la flag -t. Tuttavia, l’opzione -A non tenta di smontare il file system root.
3.7. I Processi
FreeBSD è un sistema operativo multi-tasking. Con questa capacità il sistema è come se potesse eseguire più di un programma alla volta. Ogni programma in esecuzione in un dato istante è chiamato processo. Ogni volta che esegui un comando fai partire almeno un nuovo processo, e ci sono molti processi di sistema che sono sempre in esecuzione, che permettono il corretto funzionamento del sistema.
Ogni processo è identificato in modo univoco da un numero chiamato process ID, o PID, e, come avviene per i file, ogni processo ha un proprietario e un gruppo. Le informazioni sul proprietario e sul gruppo sono usate per determinare, tramite il meccanismo dei permessi dei file discusso precedentemente, quali file e quali dispositivi il processo può aprire. Inoltre molti processi hanno un processo padre. Tale processo è il processo che li ha generati. Per esempio, se stai digitando dei comandi in shell allora la shell è un processo, così come lo sono i comandi che esegui. Ogni processo che esegui in questo modo avrà come suo processo padre la tua shell. L’eccezione a questo meccanismo è un processo speciale chiamato init(8). Il processo init è sempre il primo processo, quindi il suo PID è sempre 1. init viene avviato in modo automatico dal kernel quando si avvia FreeBSD.
Due comandi sono particolarmente utili per monitorare i processi sul sistema, ps(1) e top(1). Il comando ps è usato per mostrare una lista statica dei processi che sono in esecuzione in quel momento, e può mostrare i loro PID, quanta memoria stanno usando, la linea di comando che li ha avviati, e altro ancora. Il comando top visualizza tutti i processi in esecuzione, e aggiorna queste informazioni ogni qualche secondo, in modo che puoi vedere interattivamente cosa sta facendo il tuo computer.
Di default, ps mostra solo i tuoi comandi che sono in quel momento in esecuzione. Per esempio:
% ps
PID TT STAT TIME COMMAND
298 p0 Ss 0:01.10 tcsh
7078 p0 S 2:40.88 xemacs mdoc.xsl (xemacs-21.1.14)
37393 p0 I 0:03.11 xemacs freebsd.dsl (xemacs-21.1.14)
48630 p0 S 2:50.89 /usr/local/lib/netscape-linux/navigator-linux-4.77.bi
48730 p0 IW 0:00.00 (dns helper) (navigator-linux-)
72210 p0 R+ 0:00.00 ps
390 p1 Is 0:01.14 tcsh
7059 p2 Is+ 1:36.18 /usr/local/bin/mutt -y
6688 p3 IWs 0:00.00 tcsh
10735 p4 IWs 0:00.00 tcsh
20256 p5 IWs 0:00.00 tcsh
262 v0 IWs 0:00.00 -tcsh (tcsh)
270 v0 IW+ 0:00.00 /bin/sh /usr/X11R6/bin/startx -- -bpp 16
280 v0 IW+ 0:00.00 xinit /home/nik/.xinitrc -- -bpp 16
284 v0 IW 0:00.00 /bin/sh /home/nik/.xinitrc
285 v0 S 0:38.45 /usr/X11R6/bin/sawfishCome puoi vedere in questo esempio, l’output di ps(1) è organizzato in molte colonne. La colonna PID si riferisce al process ID discusso poco fà. I PID sono assegnati partendo dal numero 1, andando fino al 99999, e ricominciando dall’inizio una volta esauriti (se disponibili). La colonna TT mostra su quale tty il programma è in esecuzione, e può essere benissimo ignorata per il momento. La colonna STAT mostra lo stato del programma, e di nuovo, può essere benissimo ignorata. La colonna TIME indica per quanto tempo il programma è stato in esecuzione sulla CPU-di solito non indica il tempo trascorso da quando hai avviato il programma, poichè la maggior parte dei programmi trascorrono molto tempo in attesa per faccende che accadono prima che questi possano trascorrere del tempo in CPU. Infine, la colonna COMMAND indica la riga di comando che è stata utilizzata per eseguire il programma.
Il comando ps(1) supporta varie opzioni per cambiare le informazioni da visualizzare. Uno dei gruppi di opzioni più utili è auxww. L’opzione a mostra le informazioni riguardo a tutti i processi in esecuzione, non solo quelli che ti appartengono. L’opzione u mostra il nome utente del proprietario del processo, come pure la memoria utilizzata dal processo. L’opzione x mostra le informazioni riguardo ai processi demoni, e l’opzione ww indica a ps(1) di visualizzare la linea di comando completa che ha avviato il processo, piuttosto che troncarla quando è troppo lunga per essere adattata sullo schermo.
L’output di top(1) è simile. Un esempio di esecuzione assomiglia a questo:
% top
last pid: 72257; load averages: 0.13, 0.09, 0.03 up 0+13:38:33 22:39:10
47 processes: 1 running, 46 sleeping
CPU states: 12.6% user, 0.0% nice, 7.8% system, 0.0% interrupt, 79.7% idle
Mem: 36M Active, 5256K Inact, 13M Wired, 6312K Cache, 15M Buf, 408K Free
Swap: 256M Total, 38M Used, 217M Free, 15% Inuse
PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU COMMAND
72257 nik 28 0 1960K 1044K RUN 0:00 14.86% 1.42% top
7078 nik 2 0 15280K 10960K select 2:54 0.88% 0.88% xemacs-21.1.14
281 nik 2 0 18636K 7112K select 5:36 0.73% 0.73% XF86_SVGA
296 nik 2 0 3240K 1644K select 0:12 0.05% 0.05% xterm
48630 nik 2 0 29816K 9148K select 3:18 0.00% 0.00% navigator-linu
175 root 2 0 924K 252K select 1:41 0.00% 0.00% syslogd
7059 nik 2 0 7260K 4644K poll 1:38 0.00% 0.00% mutt
...L’output è diviso in due sezioni. La parte superiore (le prime cinque linee) mostra il PID dell’ultimo processo eseguito, il carico medio del sistema (che è un indice di quanto il sistema sia impegnato), il tempo di vita del sistema (il tempo passato dall’ultimo reboot) e l’ora corrente. I restanti numeri nella parte superiore riportano quanti processi sono in esecuzione (47 in questo caso), quanta memoria di sistema e quanta memoria di swap è stata utilizzata, e quanto tempo il sistema sta trascorrendo nei vari stati di CPU.
Sotto ci sono una serie di colonne che contengono simili informazioni a quelle contenute nell’output di ps(1). Come prima puoi vedere il PID, il nome utente, quanto tempo di CPU è stato utilizzato, e il comando che era stato eseguito. Inoltre il comando top(1) di default ti mostra quanta memoria è stata concessa al processo. Questa informazione è suddivisa in due colonne, una per la dimensione totale, e l’altra per la dimensione attuale-la dimensione totale è la quantità di memoria che l’applicazione ha richiesto, e la dimensione attuale è la quantità di memoria che sta utilizzando in quel momento. In questo esempio puoi vedere che Netscape ha richiesto quasi 30 MB di RAM, ma al momento ne sta usando solo 9 MB.
Il comando top(1) aggiorna in modo automatico queste informazioni ogni due secondi; questo lasso temporale può essere modificato con l’opzione s.
3.8. I Demoni, i Segnali, e come Uccidere i Processi
Quando esegui un editor risulta semplice averne il controllo, dirgli di caricare file, e così via. Tutto questo può essere fatto poichè l’editor fornisce delle agevolazioni in questo senso, e anche perchè l’editor è collegato a un terminale. Alcuni programmi non sono stati progettati per essere eseguiti con un continuo input dell’utente, e perciò questi programmi si disconnettono dal terminale alla prima occasione. Per esempio, un server web trascorre tutto il giorno rispondendo a richieste web, e normalmente non necessita di alcun input da parte tua. I programmi che trasportano la posta elettronica da un sito a un altro sito sono un altro esempio di questa classe di applicazioni.
Chiamiamo questi programmi demoni. I demoni erano dei personaggi della mitologia greca: nè buoni nè cattivi, erano piccoli spiriti custodi che, nel complesso, risultavano essere utili per l’umanità, molto similmente i server web e quelli di posta elettronica di oggi fanno cose utili. Ecco il motivo per cui la mascotte di BSD è stata per molto tempo, e lo è ancora, l’allegro demone con le scarpe da tennis e con il forcone.
Esiste la convenzione di chiamare i programmi che normalmente sono eseguiti come demoni con una "d" finale. BIND sta per Berkeley Internet Name Domain, ma il nome effettivo del programma che viene eseguito è named; il nome del programma Apache, un server web, è httpd; il demone dello spool di stampa è lpd e così via. Questa è una convenzione, non è una regola ferrea; per esempio, il principale demone di posta elettronica per l’applicazione Sendmail è chiamato sendmail, e non maild, come potresti aspettarti.
A volte puoi aver bisogno di comunicare con un processo demone. Un modo per farlo è di mandare a esso (o ad altri processi in esecuzione), un segnale. Esistono svariati segnali che puoi inviare-alcuni di questi hanno un significato specifico, altri sono interpretabili dall’applicazione, e la documentazione dell’applicazione ti dirà come l’applicazione stessa interpreta i segnali. Puoi mandare un segnale solo ai processi che ti appartengono. Se mandi un segnale a un processo che non ti appartiene con il comando kill(1) o kill(2), il permesso ti sarà negato. L’eccezione a questa regola riguarda l’utente root, che può mandare segnali a processi di chiunque.
Inoltre in alcune circostanze FreeBSD invia segnali alle applicazioni. Se un’applicazione è stata scritta malamente, e tenta di accedere alla memoria che non gli compete, FreeBSD manda al processo il segnale di Violazione della Segmentazione (SIGSEGV). Se un’applicazione ha utilizzato la system call alarm(3) in modo tale da essere avvisata dopo un certo periodo di tempo trascorso allora FreeBSD invierà a questa applicazione il segnale di Allarme (SIGALRM), e così via.
Per fermare un processo possono essere utilizzati due segnali, SIGTERM e SIGKILL. SIGTERM è il modo cortese di terminare un processo; il processo può catturare il segnale, capire che vuoi abbatterlo, chiudere i file di log che potrebbe avere aperto, e in genere terminare qualunque cosa che stava facendo prima dell’interruzione. Nei casi in cui un processo sia coinvolto in qualche compito che non può essere interrotto allora questo processo può persino ignorare SIGTERM.
Il segnale SIGKILL non può essere ignorato da un processo. Questo è il segnale che dice "Non mi interessa cosa stai facendo, fermati subito". Se mandi il segnale SIGKILL a un processo allora FreeBSD fermerà subito il processo.
Altri segnali che potresti aver bisogno di usare sono SIGHUP, SIGUSR1, e SIGUSR2. Questi sono segnali a scopo generico, e differenti applicazioni possono fare cose diverse quando catturano questi segnali.
Supponiamo che hai cambiato il file di configurazione del tuo server web-hai bisogno di dire al server web di rileggere la sua configurazione. Potresti fermare e riavviare httpd, ma questo porterebbe a un breve periodo di interruzione del tuo server web, che potrebbe non essere gradito. Molti demoni sono stati scritti per rispondere al segnale SIGHUP tramite la rilettura dei loro file di configurazione. In questo modo invece di terminare e riavviare httpd potresti inviare il segnale SIGHUP. Poichè non esiste un modo standard di trattare questi segnali, differenti demoni potrebbero avere un comportamento diverso, quindi assicurati di leggere la documentazione per il demone in questione.
I segnali sono inviati utilizzando il comando kill(1), come mostra questo esempio.
Procedure: Inviare un Segnale a un Processo
Questo esempio mostra come inviare un segnale a inetd(8). Il file di configurazione di inetd è /etc/inetd.conf, e inetd rilegge questo file di configurazione quando riceve il segnale SIGHUP.
Cerca il process ID del processo a cui vuoi mandare il segnale. Puoi utilizzare ps(1) e grep(1) per farlo. Il comando grep(1) viene utilizzato per perlustrare attraverso l’output, cercando la stringa da te specificata. Questo comando viene eseguito in modalità utente, e inetd(8) viene eseguito in modalità
root, quindi le opzioni da dare a ps(1) sonoax.% ps -ax | grep inetd 198 ?? IWs 0:00.00 inetd -wWUsa il comando kill(1) per inviare il segnale. Poichè inetd(8) viene eseguito in modalità
rootprima devi usare il comando su(1) per diventareroot.% su Password: # /bin/kill -s HUP 198Come avviene per la maggior parte dei comandi UNIX®, il comando kill(1) non stampa il risultato dell’operazione se questa ha avuto successo. Se mandi un segnale a un processo del quale non sei il proprietario allora vedrai il messaggio
kill: PID: Operation not permitted. Se sbagli il PID invierai il segnale al processo sbagliato, il che potrebbe essere dannoso, o, se hai fortuna, manderai il segnale a un PID che in quel momento non è in uso, e in questo caso vedrai il messaggiokill: PID: No such process.Perchè Usare/bin/kill?Molte shell forniscono il comando
killcome comando built-in; ossia, la shell invia il segnale in modo diretto, senza dover eseguire /bin/kill. Tutto ciò può essere molto utile, ma le diverse shell hanno una sintassi diversa per specificare il nome del segnale da inviare. Invece di cercare di imparare tutte queste sintassi, può essere più semplice usare direttamente il comando/bin/kill ….
L’invio di altri segnali è analogo, basta sostituire all’occorrenza TERM o KILL nella linea di comando.
Terminare processi in modo random su un sistema può essere una cattiva idea. In particolare, il processo init(8), con process ID 1, è un caso molto speciale. Eseguire |
3.9. Le Shell
In FreeBSD, la maggior parte del lavoro di tutti i giorni viene svolto tramite un’interfaccia a riga di comando chiamata shell. Uno dei compiti principali di una shell è quello di prendere in input dei comandi ed eseguirli. Inoltre molte shell hanno delle funzioni built-in (incorporate) utili nei lavori ordinari come la gestione dei file, la sostituzione dei nomi dei file, la modifica della riga di comando, la creazione di macro di comandi, e la gestione delle variabili d’ambiente. FreeBSD si propone con una serie di shell, come la Shell Bourne, sh, e la versione successiva della C-shell, tcsh. Molte altre shell sono disponibili nella FreeBSD Ports Collection, come le shell zsh e bash.
Quale shell devi usare? È veramente una questione di gusti. Se sei un programmatore di C potresti sentirti a tuo agio con una shell C-like come la tcsh. Se vieni da Linux o non sei pratico dell’interfaccia a riga di comando di UNIX® potresti provare la bash. Il fatto è che ogni shell ha delle caratteristiche che possono o meno combaciare con il tuo ambiente di lavoro preferito, e quindi devi scegliere tu stesso quale shell utilizzare.
Una caratteristica comune in una shell è il completamento dei nomi dei file. Dopo aver digitato alcuni dei primi caratteri di un comando o di un nome di file, la shell di solito può completare in modo automatico il resto del comando o del nome del file tramite la pressione del tasto Tab sulla tastiera. Ecco un esempio. Supponiamo che hai due file chiamati foobar e foo.bar. Vuoi cancellare foo.bar. Quello che dovresti digitare sulla tastiera è: rm fo[Tab].[Tab].
La shell dovrebbe visualizzare rm foo[BEEP].bar.
Il [BEEP] è la campanella della console, che mi segnala che la shell è incapace di completare interamente il nome del file poichè esiste più di una sola corrispondenza. Sia foobar che foo.bar iniziano con fo, tuttavia la shell è riuscita a completarlo in foo. A questo punto premendo ., e poi di nuovo Tab, la shell sarà in grado di completare da sola il resto del nome del file.
Un altro aspetto di una shell è l’uso delle variabili d’ambiente. Le variabili d’ambiente sono una coppia di valori mutevoli memorizzati nello spazio dell’ambiente della shell. Questo spazio può essere letto dai programmi invocati dalla shell, e di conseguenza questo spazio può contenere le configurazioni di molti programmi. Qui sotto c’è una lista delle variabili d’ambiente più comuni con il loro rispettivo significato:
| Variabile | Descrizione |
|---|---|
| Il nome dell’utente attualmente loggato. |
| Lista di directory separate da due punti utilizzate per la ricerca dei binari. |
| Nome di rete del display X11 a cui connettersi, se disponibile. |
| La shell corrente. |
| Il nome del tipo di terminale dell’utente. Usato per determinare le capacità del terminale. |
| Serie di elementi di codici di escape del terminale utilizzati per realizzare svariate funzioni del terminale. |
| Il tipo di sistema operativo. FreeBSD, ad esempio. |
| L’architettura della CPU su cui il sistema gira. |
| L’editor di testo preferito dall’utente. |
| L’impaginatore di testo preferito dall’utente. |
| Lista di directory separate da due punti utilizzate nella ricerca delle pagine man. |
Il modo di settare una variabile d’ambiente varia leggermente a seconda della shell utilizzata. Per esempio, nelle shell C-Style come tcsh e csh, puoi usare setenv per settare le variabili d’ambiente. Sotto le shell Bourne come sh e bash, puoi usare export per settare le tue variabili d’ambiente correnti. Per esempio, per settare o modificare la variabile d’ambiente EDITOR a /usr/local/bin/emacs, sotto csh o tcsh si può utilizzare il comando:
% setenv EDITOR /usr/local/bin/emacsSotto le shell Bourne:
% export EDITOR="/usr/local/bin/emacs"Con la maggior parte delle shell puoi inoltre creare un’espansione di una variabile d’ambiente mettendo sulla riga di comando il simbolo $ davanti al nome della variabile stessa. Per esempio, echo $TERM visualizzerà ciò che corrisponde a $TERM, poichè la shell espande $TERM e passa il risultato a echo.
Le shell trattano molti caratteri speciali, chiamati meta-caratteri come rappresentazioni speciali di dati. Il più comune di questi è il simbolo *, che rappresenta diverse istanze di caratteri in un nome di file. Questi meta-caratteri possono essere usati per la sostituzione dei nomi di file. Per esempio, digitando echo * è quasi come aver digitato ls poichè la shell prende tutti i file che corrispondono a * e li mette sulla riga di comando con echo che quindi li visualizza.
Per impedire alla shell di interpretare questi caratteri speciali, questi possono essere messi in escape mettendo subito prima di essi un backslash (\). echo $TERM visualizza il tipo del tuo terminale. echo \$TERM visualizza $TERM così com’è.
3.9.1. Cambiare la Propria Shell
Il modo più semplice per cambiare la propria shell è quello di usare il comando chsh. Eseguendo chsh verrà invocato l’editor definito nella tua variabile d’ambiente EDITOR; nel caso in cui questa non sia stata settata, verrà invocato vi. Modifica la riga "Shell:" in base alle tue esigenze.
Puoi anche eseguire chsh con l’opzione -s; in questo modo verrà settata la shell in modo diretto, senza che sia necessario invocare l’editor. Per esempio, se vuoi cambiare la tua shell in bash, potresti digitare il seguente comando:
% chsh -s /usr/local/bin/bashLa shell che desideri utilizzare deve essere presente nel file /etc/shells. Se hai installato una shell dalla collezione dei port, allora la nuova shell dovrebbe essere già stata inserita nel suddetto file in modo automatico. Se installi una shell manualmente, questo lavoro lo devi fare tu. Per esempio, se installi Dopo averlo fatto riavvia |
3.10. Editor di Testo
La maggior parte del lavoro di configurazione in FreeBSD viene fatto tramite la modifica di file di testo. Perciò, è una buona idea familiarizzare con un editor di testo. FreeBSD si presenta con alcuni editor come parte base del sistema, e molti altri sono disponibili nella collezione dei port.
L’editor più semplice e più facile da imparare si chiama ee, che sta per easy editor. Per avviare ee, puoi digitare sulla riga di comando ee filename dove filename è il nome del file che deve essere modificato. Per esempio, per modificare /etc/rc.conf, devi digitare ee /etc/rc.conf. Una volta all’interno di ee, tutti i comandi per azionare le funzioni dell’editor sono elencati nella parte superiore del video. Il carattere ^ è il tasto Ctrl della tastiera, quindi ^e si riferisce alla combinazione di tasti Ctrl+e. Per uscire da ee, premi il tasto Esc, quindi conferma l’uscita dall’editor. Se il file ha subito delle modifiche ti verrà chiesto se le vuoi salvare.
FreeBSD ha come parte base del sistema anche editor di testo più potenti come vi, mentre altri editor, come Emacs e vim, sono inclusi nella FreeBSD Ports Collection (editors/emacs e editors/vim). Questi editor offrono molte più funzionalità e molta più potenza a costo di essere un poco più complicati da imparare ad utilizzare. Comunque se intendi utilizzare in modo intensivo un editor, imparando ad utilizzare un editor potente come vim o Emacs risparmierai a lungo andare un sacco di tempo.
3.11. Dispositivi e Nodi di Dispositivo
Il termine dispositivo viene usato prevalentemente per specificare le unità hardware all’interno di un sistema, come i dischi, le stampanti, le schede grafiche, e le tastiere. Durante la fase di avvio di FreeBSD, la maggior parte delle cose che vengono visualizzate da FreeBSD riguardano i dispositivi che sono stati rilevati. Puoi riesaminare questi messaggi di avvio guardando il file /var/run/dmesg.boot.
Per esempio, acd0 è il primo drive CDROM IDE, mentre kbd0 rappresenta la tastiera.
In un sistema operativo UNIX® la maggior parte di questi dispositivi sono accessibili tramite dei file speciali chiamati nodi di dispositivo, i quali sono posti nella directory /dev.
3.11.1. Creare i Nodi di Dispositivo
Quando aggiungi un nuovo dispositivo al tuo sistema, o ricompili il kernel per supportare dispositivi aggiuntivi, devono essere creati nuovi nodi di dispositivo.
3.11.1.1. DEVFS (DEVice File System)
Il file system device, o DEVFS, fornisce la disponibilità dello spazio dei nomi dei dispositivi del kernel allo spazio dei nomi globale del file system. Invece di dover creare o modificare i nodi di dispositivo, DEVFS mantiene in modo automatico questo particolare file system.
Guarda la pagina man di devfs(5) per maggiori informazioni.
3.12. Formati dei Binari
Per comprendere il motivo per cui FreeBSD usa il formato elf(5), devi prima conoscere un pò i tre attuali formati eseguibili "dominanti" per UNIX®:
Il più vecchio e "classico" formato oggetto di UNIX®. Usa un’intestazione corta e compatta con un numero magico all’inizio che è spesso usato per caratterizzare il formato (vedere a.out(5) per maggiori dettagli). Contiene tre segmenti caricabili: .text, .data, e .bss più una tabella di simboli e una di stringhe.
COFF
Il formato oggetto di SVR3. Poichè l’intestazione include una porzione di tabella, puoi avere molto di più delle sole sezioni .text, .data, e .bss.
Il successore di COFF, caratterizzato da sezioni multiple e da possibili valori a 32-bit o 64-bit. Uno dei maggiori svantaggi: ELF fu progettato con l’assunzione che ci doveva essere solo un ABI per ogni tipo di architettura dei sistemi. Tale assunzione è in realtà piuttosto sbagliata, e non è vera nemmeno nel mondo commerciale di SYSV (che ha almeno tre ABI: SVR4, Solaris, SCO).
FreeBSD tenta di aggirare questo problema fornendo un utility per marchiare un eseguibile ELF con informazioni sull’ABI per il quale è stato costruito. Guarda la pagina man brandelf(1) per maggiori informazioni.
FreeBSD proviene dalla scuola "classica" e ha usato il formato a.out(5), una tecnologia sperimentata ed utilizzata attraverso molte generazioni delle release BSD, fino agli inizi del ramo 3.X. Sebbene fino ad allora era possibile costruire ed eseguire su un sistema FreeBSD binari (e kernel) del formato ELF, inizialmente FreeBSD si oppose al "salto" di cambiamento al formato ELF come formato di default. Per quale motivo? Dunque, quando la scuola Linux fece il suo doloroso passaggio a ELF, questo non era sufficiente per abbandonare il formato eseguibile a.out a causa del loro rigido meccanismo a salto-di-tabella basato sulla libreria condivisa, il quale rendeva la costruzione di librerie condivise un compito molto difficile tanto per i venditori che per gli sviluppatori. Tuttavia, quando gli strumenti di ELF furono in grado di offrire una soluzione al problema della libreria condivisa e quando furono visti come "la strada imminente", il costo della migrazione fu accettato poichè necessario e avvenne così la transizione. Il meccanismo di libreria condivisa di FreeBSD è basato sullo stile più restrittivo del meccanismo di libreria condivisa degli SunOS™ di Sun, e come tale, è molto facile da utilizzare.
Quindi, perchè ci sono così tanti formati differenti?
In passato l’hardware era semplice. Questo hardware semplice sosteneva un sistema semplice e piccolo. Il formato a.out era del tutto adatto per rappresentare i binari su questo semplice sistema (un PDP-11). Nonostante le persone fecero il port di UNIX® da questo semplice sistema, esse mantennero il formato a.out poichè era sufficiente per un primo port di UNIX® verso architetture come Motorola 68k, VAXen, ecc.
All’epoca alcuni ingegneri hardware di spicco stabilirono che se tale formato poteva forzare il software a fare alcuni trucchi sporchi, allora esso sarebbe stato in grado di abbattere alcune barriere di progettazione e permettere al core della CPU di andare più veloce. Benchè il formato a.out fu progettato per lavorare con questo nuovo tipo di hardware (conosciuto ai giorni d’oggi come RISC), esso fu appena sufficiente per questo hardware, quindi furono sviluppati altri formati per ottenere delle prestazioni da questo hardware migliori di quelle che il limitato e semplice formato a.out era in grado di offrire. Furono inventati formati come il COFF, l’ECOFF, e alcuni altri e furono esaminate le loro limitazioni prima che fu prodotto l’ELF.
Per di più, le dimensioni dei programmi stavano diventando enormi e i dischi (e la memoria fisica) erano ancora relativamente piccoli, e quindi il concetto di libreria condivisa prese piede. Inoltre il sistema di VM (Memoria Virtuale) divenne più sofisticato. Benchè ognuno di questi miglioramenti fu fatto utilizzando il formato a.out, la sua utilità si distese sempre più con ogni nuova caratteristica. In aggiunta, la gente voleva caricare alcune cose in modo dinamico al tempo di esecuzione, o anche scartare parte dei loro programmi dopo l’esecuzione del codice iniziale al fine di salvare memoria e spazio di swap. I linguaggi divennero più sofisticati e le persone desideravano che il codice venisse chiamato dopo il main in modo automatico. Furono apportati molte migliorie al formato a.out per permettere tutte queste cose, e sostanzialmente tutto funzionò per un dato periodo. Col passare del tempo, il formato a.out non fu più in grado di gestire tutti questi problemi senza apportare dei miglioramenti al codice con un conseguente aumento della complessità. Benchè il formato ELF risolveva molti di questi problemi, era doloroso migrare da un sistema che tutto sommato funzionava. Quindi il formato ELF attese fino a quando fu meno doloroso rimanere con il formato a.out piuttosto che migrare al formato ELF.
Tuttavia, il tempo passò, e gli strumenti di costruzione che FreeBSD derivò dai loro strumenti di costruzione (in particolare l’assemblatore ed il loader) evolsero in due tronconi paralleli. L’albero di FreeBSD aggiunse le librerie condivise e sistemò alcuni bug. Il popolo di GNU che in origine aveva scritto questi programmi li riscrisse e aggiunse un semplice supporto per la costruzione di compilatori cross, la possibilità di produrre formati diversi a piacimento, e così via. Da quando molte persone vollero costruire compilatori cross per FreeBSD, questi furono delusi poichè i vecchi sorgenti che FreeBSD aveva per as e ld non erano pronti per questo lavoro. La nuova serie di strumenti di GNU (binutils) supportavano la compilazione cross, ELF, le librerie condivise, le estensioni C++, ecc. Inoltre molti venditori stanno rilasciando binari ELF, ed è una buona cosa per FreeBSD eseguirli.
Il formato ELF è più espressivo di quello a.out e permette una maggiore estensibilità nel sistema base. Gli strumenti di ELF sono meglio mantenuti, e offrono un supporto alla compilazione cross, che sta a cuore a molte persone. ELF può essere un pò meno veloce di a.out, ma tentare di misurarne le prestazioni non è molto semplice. Ci sono anche numerosi dettagli che sono diversi tra i due formati nel modo in cui essi mappano le pagine, gestiscono il codice iniziale, ecc. Questi dettagli non sono molto importanti, ma tra i due esistono delle differenze. Nel tempo il supporto per il formato a.out verrà rimosso dal kernel GENERIC, e alla fine sarà rimosso completamente dal kernel non appena non ci sarà più la necessità di eseguire programmi con il formato a.out.
3.13. Per Maggiori Informazioni
3.13.1. Le Pagine Man
La documentazione più esauriente su FreeBSD è costituita dalle pagine man. Quasi tutti i programmi sul sistema hanno un piccolo manuale di riferimento che spiega il funzionamento di base e i vari argomenti del programma stesso. Questi manuali possono essere visualizzati con il comando man. L’uso del comando man è semplice:
% man comandocomando è il nome del comando di cui desideri maggiori informazioni. Per esempio, per sapere di più circa il comando ls digita:
% man lsIl manuale in linea è diviso in sezione numerate:
Comandi utente.
System call e codici di errore.
Funzioni della libreria C.
Driver dei dispositivi.
Formati di file.
Giochi e altri passatempo.
Informazioni varie.
Comandi di mantenimento e di funzionamento del sistema.
Sviluppo del kernel.
In qualche caso, lo stesso soggetto può apparire in più di una sezione del manuale in linea. Per esempio, esiste un comando utente chmod e una system call chmod(). In questo caso, puoi dire al comando man quale vuoi specificando la sezione:
% man 1 chmodIn questo caso verrà visualizzata la pagina man del comando utente chmod. I riferimenti di una sezione particolare del manuale in linea sono tradizionalmente posti tra parentesi all’interno della documentazione, quindi chmod(1) fa riferimento al comando utente chmod e chmod(2) fa riferimento alla system call.
Tutto questo va bene se conosci il nome del comando e desideri semplicemente sapere come usarlo, ma cosa succede se non ricordi il nome del comando? Puoi usare man con l’opzione -k per ricercare tramite parole chiavi nelle descrizioni dei comandi:
% man -k mailCon questo comando ti verrà presentata una lista di comandi che hanno la parola chiave "mail" nella loro descrizione. Di fatto questo meccanismo funziona proprio come il comando apropos.
Stai dando un’occhiata a tutti quei comandi fantastici che si trovano in /usr/bin ma non hai la più pallida idea di cosa fanno la maggior parte di essi? Semplicemente digita:
% cd /usr/bin
% man -f *oppure
% cd /usr/bin
% whatis *che è la stessa cosa.
3.13.2. I File Info di GNU
FreeBSD include molte applicazioni e utility prodotti dalla Free Software Foundation (FSF). Oltre alle pagine man, questi programmi hanno dei più ampi documenti in ipertesto chiamati file info che possono essere visualizzati con il comando info, o se hai installato emacs, con la modalità info di emacs.
Per usare il comando info(1), digita semplicemente:
% infoPer una breve introduzione, digita h. Per un rapido riferimento dei comandi, digita ?.
Ultima modifica: 18 febbraio 2025 da Fernando Apesteguía