
Primary Mirror Sites
E:\ tools\fdimage floppies\kern.flp A:This translation may be out of date. To help with the translations please access the FreeBSD translations instance.
FreeBSD è un marchio registrato della FreeBSD Foundation.
IBM, AIX, OS/2, PowerPC, PS/2, S/390 e ThinkPad sono marchi della International Business Machines Corporation negli Stati Uniti, in altri paesi, o in entrambi.
IEEE, POSIX e 802 sono marchi registrati dell'Institute of Electrical and Electronics Engineers, Inc. negli Stati Uniti.
Red Hat e RPM sono marchi o marchi registrati della Red Hat, Inc. negli Stati Uniti e in altri paesi.
3Com e HomeConnect sono marchi registrati della 3Com Corporation.
Adobe, Acrobat, Acrobat Reader e PostScript sono marchi o marchi registrati della Adobe Systems Incorporated negli Stati Uniti e/o in altri paesi.
Apple, AirPort, FireWire, Mac, Macintosh, Mac OS, Quicktime e TrueType sono marchi della Apple Computer, Inc., registrati negli Stati Uniti e in altri paesi.
Intel, Celeron, EtherExpress, i386, i486, Itanium, Pentium e Xeon sono marchi o marchi registrati della Intel Corporation o delle sue sussidiarie negli Stati Uniti e in altri paesi.
Linux è un marchio registrato di Linus Torvalds.
Microsoft, IntelliMouse, MS-DOS, Outlook, Windows, Windows Media e Windows NT sono marchi o marchi registrati della Microsoft Corporation negli Stati Uniti e/o in altri paesi.
Motif, OSF/1 e UNIX sono marchi registrati e IT DialTone e The Open Group sono marchi del The Open Group negli Stati Uniti e in altri paesi.
Sun, Sun Microsystems, Java, Java Virtual Machine, JDK, JRE, JSP, JVM, Netra, Solaris, StarOffice e SunOS sono marchi o marchi registrati della Sun Microsystems, Inc. negli Stati Uniti e in altri paesi.
RealNetworks, RealPlayer e RealAudio sono marchi registrati della RealNetworks, Inc.
Oracle è un marchio registrato della Oracle Corporation.
3ware e Escalade sono marchi registrati della 3ware Inc.
ARM è un marchio registrato della ARM Limited.
Adaptec è un marchio registrato della Adaptec, Inc.
Heidelberg, Helvetica, Palatino e Times Roman sono marchi o marchi registrati della Heidelberger Druckmaschinen AG negli Stati Uniti e in altri paesi.
Intuit e Quicken sono marchi registrati e/o marchi di servizi registrati della Intuit Inc., o una delle sue sussidiarie, negli Stati Uniti e in altri paesi.
LSI Logic, AcceleRAID, eXtremeRAID, MegaRAID e Mylex sono marchi o marchi registrati della LSI Logic Corp.
MATLAB è un marchio registrato della The MathWorks, Inc.
SpeedTouch è un marchio di Thomson.
VMware è un marchio della VMware, Inc.
Mathematica è un marchio registrato della Wolfram Research, Inc.
Ogg Vorbis e Xiph.Org sono marchi di Xiph.Org.
XFree86 è un marchio della The XFree86 Project, Inc.
Molti dei nomi identificativi usati dai produttori e dai venditori per distinguere i loro prodotti sono anche dei marchi. Quando questi nomi appaiono nel documento, e il FreeBSD Project è al corrente del marchio, vengono fatti seguire dal simbolo “™” o “®”.
Sommario
Benvenuto in FreeBSD! Questo manuale copre l’installazione e l’uso giorno per giorno di FreeBSD 11.2-RELEASE e FreeBSD 12.0-RELEASE. Questo manuale è un progetto in evoluzione ed è il frutto del lavoro di molti singoli. Come tale alcun sezioni potrebbero richiedere degli aggiornamenti poichè datate. Se sei interessato ad aiutare questo progetto, invia un’email alla mailing list sul progetto di documentazione di FreeBSD. L’ultima versione di questo documento è sempre disponibile sul sito web di FreeBSD (versioni precedenti di questo manuale possono essere trovate all’indirizzo seguente http://docs.FreeBSD.org/doc/). Inoltre può essere scaricata in una varietà di formati e tipi di compressione dal server FTP di FreeBSD o da uno dei numerosi siti mirror. Se preferisci avere una copia rilegata del manuale, puoi comprarne una su FreeBSD Mall. Puoi anche voler cercare nel manuale.
Gli utenti alla prime armi con FreeBSD scopriranno che la prima sezione di questo libro guida l’utente attraverso il processo di installazione di FreeBSD e introduce delicatamente i concetti e le convenzioni su cui si basa UNIX®. Affrontare questa sezione richiede poco più che il desiderio di esplorare, e l’abilità di far propri i nuovi concetti appena vengono introdotti.
Una volta superata questa distanza, la seconda sezione, ben più grande, del Manuale è una guida di riferimento completa a tutti i tipi di argomenti di interesse per l’amministratore di un sistema FreeBSD. Alcuni di questi capitoli suggeriscono di effettuare prima la lettura di qualche altro capitolo, e questo è evidenziato nel sommario all’inizio di ogni capitolo.
Per una lista di fonti di informazioni aggiuntive, guarda l’Bibliografia.
La traduzione di questo manuale sta vedendo impegnate numerose persone facenti parte del FreeBSD Italian Documentation Project. Il progetto è partito da una iniziativa del Gruppo Utenti FreeBSD Italia (GUFI) ed è coordinato da Alex Dupre <ale@FreeBSD.org>, con l’ausilio della mailing list traduzioni@gufi.org.
Come puoi vedere, il lavoro di traduzione è ancora in corso ed è portato avanti esclusivamente da volontari. Le persone che hanno contribuito (o stanno contribuendo) alla realizzazione del progetto sono, in ordine sparso:
Alex Dupre <ale@FreeBSD.org>
Daniele Mari <daniele@cct.it>
Eugenio Modesti <eugenio@openbeer.it>
Fulvio Mariola <freedom_3@virgilio.it>
Gabriele Framarin <gabrielef@zeropiu.it>
Gianmarco Giovannelli <gmarco@scotty.masternet.it>
Gianluca Sordiglioni <inzet@gufi.org>
Gian Marco Auzas <kaosweb@yahoo.it>
Lapo Luchini <lapo@lapo.it>
Luca Cardone <luca@xunil.it>
Marco Trentini <mark@remotelab.org>
Matteo Riondato <rionda@gufi.org>
Massimiliano Stucchi <max@gufi.org>
Nicola Vitale <nivit@libero.it>
Dario Billo <rodario@libero.it>
Rudy Lamarca <rudy@tzone.it>
Salvo Bartolotta <bartequi@neomedia.it>
Gabriele Renzi <surrender_it@yahoo.it>
Valerio Daelli <valerio.daelli@gmail.com>
Davide Cittaro <daweonline@gmail.com>
Questo libro è diviso in cinque sezioni distinte logicamente. La prima sezione, Per Cominciare, copre l’installazione e l’uso basilare di FreeBSD. Ci si aspetta che il lettore segua questi capitoli in sequenza, possibilmente saltando i capitoli che trattano argomenti familiari. La seconda sezione, Compiti Comuni copre alcune funzionalità di FreeBSD frequentemente utilizzate. Questa sezione, e tutte le sezioni successive, possono essere lette non in ordine. Ogni capitolo inizia con un succinto sommario che descrive ciò che il capitolo copre e ciò che il lettore dovrebbe aspettarsi di conoscere dopo la lettura dello stesso. Questo ha l’intenzione di permettere al lettore di trovare velocemente i capitoli di proprio interesse. La terza sezione, Amministrazione del Sistema, copre argomentazioni di amministrazione. La quarta sezione Comunicazione di Rete, copre argomenti di rete e relativi servizi. La quinta sezione contiene appendici con informazioni di riferimento.
Introduce FreeBSD ai nuovi utenti. Descrive la storia del FreeBSD Project, gli obbiettivi e il modello di sviluppo.
Segue l’utente attraverso l’intera procedura di installazione. Sono trattati alcuni argomenti avanzati di installazione, come l’installazione attraverso la console seriale.
Tratta i comandi e le funzionalità di base del sistema operativo FreeBSD. Se hai familiarità con Linux® o con altri tipi di UNIX® allora puoi probabilmente saltare questo capitolo.
Copre l’installazione del software di terze parti sia con l’innovativo "Ports Collection" di FreeBSD che con i comuni pacchetti binari.
Descrive X Window System in generale e l’uso di X11 su FreeBSD in particolare. Inoltre descrive i comuni ambienti desktop KDE e GNOME.
Elenca le più comuni applicazioni desktop, come browser web e suite di produttività, e descrive come installarle su FreeBSD.
Mostra come configurare il supporto audio/video per il sistema. Inoltre descrive alcune applicazioni di esempio.
Spiega perché potresti aver bisogno di configurare un nuovo kernel e fornisce istruzioni dettagliate per la configurazione, la creazione, e l’installazione di un kernel personalizzato.
Spiega come gestire le stampanti su FreeBSD, incluse informazioni sulle pagine banner, sull’accounting di stampa, e sulla configurazione iniziale.
Descrive le caratteristiche di compatibilità con Linux® di FreeBSD. Inoltre fornisce dettagliate istruzioni sull’installazione di molte comuni applicazioni Linux® come Oracle®, SAP® R/3®, e Mathematica®.
Descrive i parametri disponibili agli amministratori di sistema per ottimizzare le performance di un sistema FreeBSD. Inoltre descrive i vari file di configurazione usati in FreeBSD e dove trovarli.
Descrive la procedura di avvio di FreeBSD e spiega come controllare questo processo con le opzioni di configurazione.
Descrive la creazione e la manipolazione degli account degli utenti. Inoltre parla delle limitazioni delle risorse che possono essere impostate sugli utenti e di altri compiti di gestione degli account.
Elenca vari tool disponibili per aiutarti a mantenere il tuo sistema FreeBSD sicuro, inclusi Kerberos, IPsec, OpenSSH.
Descrive il funzionamento delle jail, e i miglioramenti rispetto al tradizionale supporto chroot di FreeBSD.
Descrive il Controllo di Accesso Vincolato (MAC) e come questo meccanismo può essere usato per fortificare un sistema FreeBSD.
Descrive cos’è il Controllo degli Eventi di FreeBSD, come può essere abilitato, configurato, e come i log possano essere ispezionati o monitorati.
Descrive come gestire i dispositivi di archiviazione e i file system con FreeBSD. Questo include dischi fisici, array RAID, dispositivi ottici e a nastro, dischi di memoria, e file system di rete.
Descrive cos’è il framework GEOM in FreeBSD e come configurare vari livelli di RAID supportati.
Descrive come usare Vinum, un gestore di volumi che permette di creare dischi logici indipendenti dal dispositivo, con supporto RAID-0, RAID-1 e RAID-5 via software.
Descrive cosa offrono i sistemi di virtualizzazione, e come possano essere usati con FreeBSD.
Descrive come usare FreeBSD in altre lingue oltre all’inglese. Copre la localizzazione a livello sia del sistema che applicativo.
Spiega le differenze tra FreeBSD-STABLE, FreeBSD-CURRENT, e le release FreeBSD. Descrive quali utenti possano trarre beneficio seguendo un sistema di sviluppo e spiega come effettuare questa procedura.
Spiega come connettere terminali e modem al tuo sistema FreeBSD sia per connessioni in ingresso che in uscita.
Descrive come usare PPP, SLIP, o PPP over Ethernet per connettersi a sistemi remoti con FreeBSD.
Spiega i differenti componenti di un mail server e introduce semplici configurazioni per il mail server più comune: sendmail.
Fornisce istruzioni dettagliate e file di configurazione di esempio per erigere la tua macchina FreeBSD come un server NFS (Network File System), un server per la risoluzione dei nomi, un server NIS (Network Information System), o un server per la sincronizzazione dell’ora.
Illustra la filosofia dei firewall software e fornisce informazioni dettagliate sulla configurazione dei diversi firewall disponibili su FreeBSD.
Descrive molti argomenti sul networking, incluso come condividere una connessione a Internet con altri computer sulla stessa LAN, argomenti di routing avanzati, rete wireless, Bluetooth®, ATM, IPv6, e altro ancora.
Elenca varie fonti per ottenere FreeBSD su CD-ROM o DVD così come vari siti su Internet che permettono di scaricare e installare FreeBSD.
Questo libro tocca svariati argomenti che possono lasciarti desideroso di spiegazioni più dettagliate. La bibliografia elenca molti ottimi libri che sono referenziati nel testo.
Elenca i numerosi forum disponibili per gli utenti FreeBSD dove poter inviare domande e intraprendere conversazioni tecniche su FreeBSD.
Elenca i fingerprint PGP di molti sviluppatori di FreeBSD.
Per fornire un testo consistente e facile da leggere, sono state seguite numerose convenzioni in tutto il libro.
Un font italico è per i nomi dei file, per gli URL, per il testo enfatizzato, e per il primo utilizzo dei termini tecnici.
MonospazioUn font monospazio è usato per i messaggi di errore, i comandi, le variabili di ambiente, i nomi dei port, i nomi di host, i nomi degli utenti, i nomi dei gruppi, i nomi dei device, le variabili, e i frammenti di codice.
Un font in grassetto è per le applicazioni, i comandi, e i tasti.
I tasti sono visualizzati in grassetto per differenziarli dal testo normale. Le combinazioni di tasti che devono essere digitate contemporaneamente sono visualizzate con un + tra i tasti, come:
Ctrl+Alt+Del
Significa che l’utente deve premete i tasti Ctrl, Alt, e Del nello stesso momento.
I tasti che devono essere digitati in sequenza saranno separati da virgole, come per esempio:
Ctrl+X, Ctrl+S
Vuol dire che l’utente deve digitare i tasti Ctrl e X contemporaneamente e poi i tasti Ctrl e S.
Gli esempi che iniziano con E:\ indicano un comando MS-DOS®. A meno di note specifiche, questi comandi possono essere eseguiti da una finestra "Prompt dei comandi" in un moderno ambiente Microsoft® Windows®.
E:\ tools\fdimage floppies\kern.flp A:Gli esempi che iniziano con # indicano un comando che deve essere invocato dal superuser in FreeBSD. Puoi effettuare il login come root per digitare il comando, o loggarti con il tuo normale account e usare su(1) per acquisire i privilegi da superuser.
# dd if=kern.flp of=/dev/fd0Gli esempi che iniziano con % indicano un comando che deve essere eseguito da un normale utente. Dove non indicato, è usata la sintassi C-shell per impostare variabili di ambiente e altri comandi di shell.
% topIl libro che stai leggendo rappresenta gli sforzi di molte centinaia di persone in tutto il mondo. Sia che abbiano inviato correzioni per errori di battitura, sia che abbiano inviato interi capitoli, tutti i contributi sono stati utili.
Molte società hanno supportato lo sviluppo di questo documento pagando gli autori per lavorarci sopra a tempo pieno, pagando per la pubblicazione, ecc. In particolare BSDi (successivamente acquisita da Wind River Systems) ha pagato i membri del FreeBSD Documentation Project per lavorare a tempo pieno sul miglioramento di questo libro fino alla pubblicazione della prima edizione inglese stampata nel Marzo 2000 (ISBN 1-57176-241-8). Wind River Systems poi ha pagato numerosi autori aggiuntivi per fare una serie di miglioramenti all’infrastruttura di stampa e per aggiungere altri capitoli al testo. Questo lavoro è culminato nella pubblicazione della seconda edizione inglese stampata nel Novembre 2001 (ISBN 1-57176-303-1). Nel 2003-2004, FreeBSD Mall, Inc, ha pagato diversi contributori per migliorare il Manuale in preparazione per la terza edizione inglese cartacea.
Questa parte del Manuale di FreeBSD è per gli utenti e gli amministratori che si affacciano a FreeBSD. Questi capitoli:
Ti introdurranno a FreeBSD.
Ti guideranno attraverso il processo di installazione.
Ti insegneranno le basi e i fondamenti di UNIX®.
Ti mostreranno come installare la varietà delle applicazioni di terze parti disponibili per FreeBSD.
Ti introdurranno a X, il sistema a finestre di UNIX®, e ti spiegheranno come configurare un ambiente desktop che ti renda più produttivo.
Abbiamo cercato di mantenere il numero di riferimenti in avanti nel testo al minimo così che tu possa leggere questa sezione del Manuale dall’inizio alla fine con il minimo scorrimento di pagine possibile.
Grazie per il tuo interesse per FreeBSD! Il seguente capitolo tratta vari aspetti del FreeBSD Project, come la sua storia, gli obiettivi, il modello di sviluppo e così via.
Dopo aver letto questo capitolo, saprai:
Come si relazione FreeBSD rispetto agli altri sistemi operativi per computer.
La storia del FreeBSD Project.
Gli obiettivi del FreeBSD Project.
Le basi del modello di sviluppo open source di FreeBSD.
E naturalmente: da dove deriva il nome "FreeBSD".
FreeBSD è un sistema operativo basato su 4.4BSD-Lite per computer Intel (x86 e Itanium®), DEC Alpha™, e Sun UltraSPARC®. Port verso altre architetture sono stati avviati. Puoi anche leggere la storia di FreeBSD, o la release corrente. Se sei interessato a contribuire in qualche modo al progetto (codice, hardware, fondi), leggi l’articolo Contribuire a FreeBSD.
FreeBSD ha molte caratteristiche degne di nota. Alcune di queste sono:
Multitasking preemptive con adattamento dinamico della priorità per assicurare una condivisione regolare ed equa del computer ad applicazioni e utenti, persino sotto i carichi più pesanti.
Facility multiutente che permettono a molte persone di usare un sistema FreeBSD contemporaneamente per cose diverse. Questo significa, per esempio, che le periferiche di sistema come stampanti e unità a nastro sono correttamente condivise tra tutti gli utenti sul sistema o sulla rete e che possono essere posti limiti individuali ad utenti o gruppi di utenti sulla risorsa, proteggendo le risorse di sistema critiche dall’uso eccessivo.
Un solido sistema di rete TCP/IP con supporto a standard industriali quali SCTP, DHCP, NFS, NIS, PPP, SLIP, IPsec, e IPv6. Questo significa che la tua macchina FreeBSD può interagire facilmente con altri sistemi ed anche agire come server aziendale, fornendo funzioni vitali come NFS (accesso remoto ai file) e servizi e-mail oppure mettere la tua organizzazione su Internet con servizi WWW, FTP, routing e firewall (sicurezza).
La protezione della memoria assicura che le applicazioni (o gli utenti) non possano interferire l’una con l’altra. Una applicazione che andrà in crash non influirà sulle altre in alcun modo.
FreeBSD è un sistema operativo a 32 bit (64 bit su Alpha Itanium®, AMD64, e UltraSPARC®) ed è stato progettato come tale sin dall’inizio.
Lo standard industriale X Window System (X11R7) fornisce una interfaccia grafica utente (GUI) al costo di una comune scheda VGA ed un monitor e viene fornito con i sorgenti.
Compatibilità binaria con molti programmi sviluppati per Linux, SCO, SVR4, BSDI e NetBSD.
Nella collezione di port e package per FreeBSD sono disponibili migliaia di applicazioni pronte a partire. Perché cercare sulla rete quando puoi trovare qui tutto quello che ti serve?
Su Internet sono disponibili migliaia di applicazioni aggiuntive e facili da portare. FreeBSD è compatibile a livello di codice sorgente con la maggior parte dei sistemi UNIX® commerciali e così la maggior parte delle applicazioni richiedono poche modifiche per essere compilate, se non nessuna.
La memoria virtuale paginata su richiesta e il progetto con "VM/buffer cache" integrati soddisfa efficientemente le applicazioni con grandi appetiti di memoria mantenendo ancora la risposta interattiva per altri utenti.
Il supporto SMP per macchine con CPU multiple.
una dotazione completa di strumenti di sviluppo per C, C++, e Fortran. Sono inoltre disponibili molti linguaggi aggiuntivi per ricerca avanzata e sviluppo nella collezione di port e package.
Avere il codice sorgente dell’intero sistema significa avere un alto grado di controllo sull’ambiente. Perché essere vincolati ad una soluzione proprietaria alla mercé del tuo fornitore quando puoi avere un sistema veramente aperto?
Estesa documentazione online.
E molto altro!
FreeBSD è basato sulla release 4.4BSD-Lite del Computer Systems Research Group (CSRG) dell’Università della California di Berkeley, e porta avanti l’inconfondibile tradizione di sviluppo dei sistemi BSD. In aggiunta all’ottimo lavoro fornito dal CSRG, il FreeBSD Project ha speso molte centinaia di ore nella fine regolazione del sistema per le massime prestazioni e affidabilità nelle situazioni di carico che si possono trovare nella vita reale. Mentre molti giganti commerciali hanno difficoltà nel campo dei sistemi operativi per PC con queste caratteristiche, prestazioni e affidabilità, FreeBSD le può offrire ora!
Le applicazioni nelle quali FreeBSD può essere impiegato sono veramente limitate solo dalla tua immaginazione. Dallo sviluppo software all’automazione in fabbrica, dal controllo dell’inventario alla correzione dell’azimut delle antenne remote dei satelliti; se può essere fatto con un prodotto UNIX® commerciale allora è più che probabile che puoi farlo anche con FreeBSD! FreeBSD beneficia significativamente anche da letteralmente migliaia di applicazioni di alta qualità sviluppate da centri di ricerca e università di tutto il mondo, spesso disponibili a poco prezzo o gratuite. Sono anche disponibili applicazioni commerciali e compaiono in numero maggiore ogni giorno.
Poiché il codice sorgente dello stesso FreeBSD è normalmente disponibile, il sistema può anche essere personalizzato ad un livello inimmaginabile per applicazioni o progetti particolari, e in modi non generalmente possibili con i sistemi operativi della maggior parte dei produttori commerciali. Ecco solo alcuni esempi di alcune delle applicazioni nelle quali attualmente la gente sta usando FreeBSD:
Servizi Internet: Il robusto sistema di rete TCP/IP di FreeBSD lo rende una piattaforma ideale per una varietà di servizi Internet quali:
server FTP
server World Wide Web (standard o sicuri [SSL])
instradamento IPv4 e IPv6
Firewall e gateway NAT ("mascheramento dell’IP").
server di Posta Elettronica
USENET News o Bulletin Board Systems
E altro…
Con FreeBSD, puoi facilmente partire in piccolo con un PC a buon mercato della classe 386 e aggiornare poi ad un quadri-processore Xeon con dischi RAID se la tua azienda cresce.
Insegnamento: Sei uno studente di informatica o legato al campo dell’ingegneria? Non c’è miglior modo di imparare i sistemi operativi, l’architettura dei computer e il networking che l’esperienza pratica e in profondità che FreeBSD può fornire. Il numero di pacchetti di CAD, di progettazione grafica e matematica disponibili gratuitamente lo rendono anche estremamente utile per coloro il cui interesse principale nei computer è vedere altro lavoro svolto!
Ricerca: Con il codice sorgente disponibile per l’intero sistema, FreeBSD è una eccellente piattaforma per la ricerca nei sistemi operativi come pure per altre branche dell’informatica. La natura di libera circolazione di FreeBSD rende anche possibile a gruppi distanti di collaborare sulle idee o condividere lo sviluppo senza aver da preoccuparsi di accordi di licenza speciali o limitazioni su quello che può essere discusso in un forum pubblico.
Networking: Ti serve un nuovo router? Un server dei nomi (DNS)? Un firewall per tenere la gente fuori dalla tua rete interna? FreeBSD può facilmente tramutare quel 386 inutilizzato o quel PC 486 che giace nell’angolo in un router avanzato con sofisticate capacità di filtraggio dei pacchetti.
Stazione di lavoro con X Window: FreeBSD è un’ottima scelta come soluzione per un terminale X economico, usando il server X11 liberamente disponibile. Diversamente da un terminale X, FreeBSD permette a molte applicazioni di girare localmente se desiderato, sollevando così il carico da un server centrale. FreeBSD può anche partire "senza disco", rendendo le stazioni individuali persino più economiche e facili da amministrare.
Sviluppo Software: Di base FreeBSD arriva con un pieno complemento di strumenti di sviluppo incluso il rinnovato compilatore GNU C/C++ e il debugger.
FreeBSD è disponibile sia in forma sorgente che binaria su CDROM, DVD e via FTP anonimo. Guarda l’Ottenere FreeBSD per maggiori informazioni su come ottenere FreeBSD.
La sezione seguente fornisce alcune informazioni relative al progetto, includendo una breve storia, gli obiettivi, e il modello di sviluppo.
Il FreeBSD Project ebbe la sua genesi nella prima parte del 1993, come una sorta di crescita oltremisura del "Patchkit Non Ufficiale di 386BSD" dagli ultimi tre coordinatori del patchkit: Nate Williams, Rod Grimes e me stesso.
Il nostro obiettivo originario era di produrre uno snapshot intermedio di 386BSD allo scopo di risolvere una serie di problemi che il meccanismo del patchkit non era semplicemente in grado di risolvere. Alcuni di voi potranno ricordare che il primo titolo funzionante per il progetto fu "386BSD 0.5" o "386BSD Interim" in riferimento a quel fatto.
386BSD era il sistema operativo di Bill Jolitz, che era arrivato a questo punto soffrendo piuttosto pesantemente di quasi un anno di disinteresse. Visto che il patchkit si gonfiava sempre più scomodamente con il passare dei giorni, fummo d’accordo all’unanimità che doveva essere fatto qualcosa e decidemmo di provare ad assistere Bill fornendo questo snapshot ad interim "ripulito". Questi piani ebbero un brusco arresto quando Bill Jolitz improvvisamente decise di ritirare la sua approvazione al progetto senza nessuna chiara indicazione di cosa invece doveva essere fatto.
Non ci volle molto per decidere che l’obiettivo rimaneva utile, persino senza il supporto di Bill, e così adottammo il nome "FreeBSD", coniato da David Greenman. I nostri obiettivi iniziali furono decisi dopo esserci consultati con gli utenti dell’epoca del sistema e, una volta che divenne chiaro che il progetto era sulla strada giusta e forse stava persino diventando una realtà, contattai la Walnut Creek CDROM con un occhio verso il miglioramento dei canali distributivi di FreeBSD per quei molti sfortunati che non avevano facile accesso a Internet. La Walnut Creek CDROM non solo supportò l’idea di distribuire FreeBSD su CD ma andò anche più lontano fornendo al progetto una macchina per lavorarci su e una connessione ad Internet veloce. Senza il grado di fiducia quasi senza precedenti della Walnut Creek CDROM in quello che era, a quel tempo, un progetto completamente sconosciuto, è abbastanza improbabile che FreeBSD sarebbe andato così lontano, così velocemente, come è oggi.
La prima distribuzione su CDROM (e largamente disponibile sulla rete) fu FreeBSD 1.0, rilasciata nel dicembre del 1993. Questa era basata su un nastro della 4.3BSD-Lite ("Net/2") della U.C. Berkeley, con molti componenti forniti anche da 386BSD e dalla Free Software Foundation. Fu un successo abbastanza ragionevole per una prima offerta, e lo seguimmo dal grande successo di FreeBSD release 1.1 nel maggio del 1994.
Circa in questo periodo si formarono all’orizzonte alcune nuvole temporalesche piuttosto inaspettate allorché Novell e U.C. Berkeley risolsero la loro lunga causa civile sullo stato legale del nastro di Berkeley Net/2. Una condizione di quell’accordo era la concessione di U.C. Berkeley che vaste parti di Net/2 erano codice "ingombrante" e di proprietà di Novell, che lo aveva infine acquistato da AT&T qualche tempo addietro. Quello che Berkeley ottenne in cambio fu la "benedizione" di Novell che la release 4.4BSD-Lite, quando fu finalmente rilasciata, fosse dichiarata non ingombrante e che tutti gli utenti Net/2 esistenti fossero fortemente incoraggiati a cambiare. Questo incluse FreeBSD, e al progetto fu dato tempo fino alla fine di luglio 1994 per fermare la spedizione del proprio prodotto basato su Net/2. Sotto i termini di quell’accordo, fu permesso al progetto un ultimo rilascio prima della scadenza, e quella release fu FreeBSD 1.1.5.1
FreeBSD allora si accinse nell’arduo compito di letteralmente reinventare se stesso da un insieme di bit di 4.4BSD-Lite completamente nuovo e piuttosto incompleto. Le release "Lite" erano light (leggere) in parte perché il CSRG di Berkeley aveva rimosso grandi sezioni di codice richiesto per costruire effettivamente un sistema funzionante in grado di partire (dovuto a varie richieste legali) e in parte al fatto che il port per Intel della 4.4 era altamente incompleto. Al progetto ci volle fino al novembre del 1994 per fare questa transizione; a quel punto rilasciò FreeBSD 2.0 sulla rete e su CDROM (nel tardo dicembre). A dispetto del fatto di essere ancora più che un po' ruvida ai bordi, la release fu un successo significativo e fu seguita dalla release FreeBSD 2.0.5 più robusta e semplice da installare nel giugno del 1995.
Rilasciammo FreeBSD 2.1.5 nell’agosto del 1996, e parve essere abbastanza popolare tra gli ISP e le comunità commerciali tanto che si meritò un’altra release nel corso del ramo 2.1-STABLE. Questa era FreeBSD 2.1.7.1, rilasciata nel febbraio 1997 e apoteosi dello sviluppo principale sulla 2.1-STABLE. Attualmente in modalità di manutenzione, su questo ramo (RELENG_2_1_0) verranno sviluppati solo miglioramenti della sicurezza e correzioni degli errori.
FreeBSD 2.2 fu derivato dallo sviluppo della linea principale ("-CURRENT") nel novembre 1996 come ramo RELENG_2_2, e la prima release completa (2.2.1) fu rilasciata nell’aprile 1997. Furono rilasciate ulteriori release del ramo 2.2 nell’estate e nell’autunno del '97, l’ultima delle quali (2.2.8) apparve nel novembre 1998. La prima release 3.0 ufficiale apparve nell’ottobre 1998 e segnò l’inizio della fine per il ramo 2.2.
L’albero si ramificò ancora il 20 gennaio 1999, dividendosi nei rami 4.0-CURRENT e 3.X-STABLE. Dalla 3.X-STABLE, la 3.1 fu rilasciata il 15 febbraio 1999, la 3.2 il 15 maggio 1999, la 3.3 il 16 settembre 1999, la 3.4 il 20 dicembre 1999 e la 3.5 il 24 giugno 2000, seguita pochi giorni dopo da un aggiornamento di punto inferiore alla release 3.5.1 per incorporare alcune correzioni dell’ultimo minuto a Kerberos sulla sicurezza. Questa sarà l’ultima release del ramo 3.X.
Ci fu un’altra ramificazione il 13 marzo 2000, che vide l’apparizione del ramo 4.X-STABLE. Ci sono state numerose release da allora: la 4.0-RELEASE fu introdotta nel marzo 2000, e l’ultima 4.11-RELEASE è stata rilasciata nel gennaio 2005.
La tanto attesa 5.0-RELEASE è stata annunciata il 19 gennaio 2003. Il culmine di quasi tre anni di lavoro, questa release ha iniziato FreeBSD nel percorso del supporto avanzato al multiprocessore e ai thread nelle applicazioni e ha introdotto il supporto per le piattaforme UltraSPARC® e ia64. Questa release è stata seguita dalla 5.1 nel giugno del 2003. La più recente release 5.X dal ramo -CURRENT è 5.2.1-RELEASE, introdotta nel Febbraio del 2004.
Il ramo RELENG_5, creato in Agosto del 2004, seguito da quello 5.3-RELEASE, segna l’inizio del ramo delle release 5-STABLE. Il più recente ramo 11.2-RELEASE è uscito in data June 28, 2018. Non ci saranno ulteriori release per il ramo RELENG_5.
Nel giugno 2005 l’albero è stato taggato per la RELENG_6. 6.0-RELEASE, la prima release del ramo 6.X è stata rilasciata nel novembre del 2005. La più recente 12.0-RELEASE è stata rilasciata nel December 11, 2018. Ci saranno ulteriori release per il ramo RELENG_6.
Per ora, lo sviluppo dei progetti a lungo termine continua ad aver luogo nell’albero 7.X-CURRENT, e release SNAPshot della 7.X su CDROM (e, naturalmente, sulla rete) sono continuamente rese disponibili sul server snapshot mentre il lavoro procede.
Gli obiettivi del FreeBSD Project sono di fornire software che può essere usato per qualunque scopo senza vincoli. Molti di noi hanno fatto un investimento significativo nel codice (e nel progetto) e certamente non dovrebbero essere interessati ad un piccolo compenso finanziario qua e là, ma non siamo sicuramente preparati ad insistere su questo. Noi crediamo che la nostra prima e prioritaria "missione" sia di fornire codice a tutti i partecipanti, presenti e futuri, e per qualunque scopo, così che il codice abbia un uso il più possibile ampio e fornisca i più ampi benefici. Questo è, io credo, uno degli obiettivi fondamentali del Software Libero (Free Software) e che noi supportiamo entusiasticamente.
Quel codice nel nostro albero dei sorgenti che cade sotto la GNU General Public Licence (GPL) o la GNU Lesser General Public License (LGPL) ha un po' più di vincoli, sebbene almeno dal lato di rafforzare l’accesso piuttosto che l’opposto. Date le complessità aggiuntive che possono risultare dall’uso commerciale di software GPL noi preferiamo, tuttavia, software rilasciato sotto il più rilassato copyright BSD quando è una scelta ragionevole farlo.
Lo sviluppo di FreeBSD è un processo molto aperto e flessibile, essendo costruito dal contributo di centinaia di persone di tutto il mondo, come puoi vedere dalla nostra lista dei collaboratori. L’infrastruttura di sviluppo di FreeBSD permette a queste centinaia di sviluppatori di collaborare su Internet. Siamo costantemente alla ricerca di nuovi sviluppatori e idee, e quelli interessati a essere coinvolti maggiormente nel progetto devono semplicemente contattarci sulla mailing list di discussioni tecniche su FreeBSD. La mailing list di annunci su FreeBSD è anche disponibile a quelli che vogliono informare altri utenti FreeBSD delle principali aree di lavoro.
Cose utili da sapere sul FreeBSD Project e il suo processo di sviluppo, sia lavorando in modo indipendente che in stretta cooperazione:
L’albero centrale dei sorgenti FreeBSD è mantenuto tramite CVS (Concurrent Versions System, ovvero Sistema di Versioni Concorrenti), uno strumento di controllo dei codici sorgenti liberamente disponibile che viene distribuito con FreeBSD. Il principale repository CVS risiede su una macchina a Santa Clara CA, USA da dove è replicato su numerose macchine speculari in tutto il mondo. L’albero CVS, che contiene gli alberi -CURRENT e -STABLE, possono essere facilmente replicati anche sulla tua macchina. Fai riferimento alla sezione Sincronizzazione dei Tuoi Sorgenti per maggiori informazioni su come fare.
I committer sono persone che hanno permesso di scrivere nell’albero CVS, e sono autorizzate ad apportare modifiche ai sorgenti di FreeBSD (il termine "committer" viene dal comando commit di cvs(1), che è usato per portare i nuovi cambiamenti al repository CVS). Il modo migliore di sottoporre modifiche alla revisione da parte della lista dei committer è usare il comando send-pr(1). Se qualcosa appare inceppato nel sistema, allora puoi anche raggiungerli mandando un messaggio alla mailing list dei committer di FreeBSD.
Il core team di FreeBSD dovrebbe essere equivalente al consiglio dirigente se il FreeBSD Project fosse una azienda. Il compito principale del core team è assicurarsi che il progetto, nella sua interezza, sia in buona salute e sia diretto nella giusta direzione. Una delle funzioni del core team è invitare sviluppatori responsabili e dedicati a unirsi al nostro gruppo di committer come altri ne escono. L’attuale core team è stato eletto da un insieme di candidati committer nel giugno 2006. Le elezioni vengono tenute ogni 2 anni.
Alcuni membri del core team hanno anche aree specifiche di responsabilità, significando che sono impegnati ad assicurare che grandi porzioni del sistema funzionino come annunciato. Per una lista completa degli sviluppatori di FreeBSD e le loro aree di responsabilità, guarda la Contributors List
Molti membri del core team sono volontari per quanto riguarda lo sviluppo di FreeBSD e non beneficiano finanziariamente dal progetto, così pure l'"impegno" non dovrebbe essere frainteso come "supporto garantito". Allo stesso modo; l’analogia con il "consiglio direttivo" non è molto calzante, e può essere più corretto dire che queste sono persone che hanno rinunciato alle loro vite in favore di FreeBSD, contro il loro senso del giudizio! |
Non da ultimo, il più grande gruppo di sviluppatori sono gli stessi utenti che ci forniscono feedback e correzioni di bug quasi costantemente. Il modo principale di tenersi in contatto con lo sviluppo non centralizzato di FreeBSD è iscriversi alla mailing list di discussioni tecniche su FreeBSD dove queste cose vengono discusse. Guarda il Risorse su Internet per maggiori informazioni sulle varie mailing list di FreeBSD.
La Lista dei Collaboratori di FreeBSD è lunga e cresce continuamente, quindi perché non entri a far parte di essa contribuendo e dando tu qualcosa a FreeBSD?
Fornire codice non è il solo modo di contribuire al progetto, per una lista completa di cose che serve fare, fai riferimento al sito web del FreeBSD Project.
In conclusione, il nostro modello di sviluppo è organizzato come un insieme sciolto di cerchi concentrici. Il modello centralizzato è progettato per agevolare gli utenti di FreeBSD, ai quali viene fornito un modo semplice per tenere traccia di una base di codice centrale, non per tenere fuori potenziali collaboratori! È nostro desiderio presentare un sistema operativo stabile con un ampio insieme di programmi applicativi coerenti che gli utenti possono facilmente installare ed usare - questo modello funziona molto bene per realizzare ciò.
Tutto quello che chiediamo a quelli che vogliono unirsi a noi come sviluppatori di FreeBSD è un po' della stessa dedizione che hanno le attuali persone al suo continuo successo!
FreeBSD è liberamente disponibile, è basato tutto su sorgenti 4.4BSD-Lite, è rilasciato per computer Intel i386™, i486™, Pentium®, Pentium® Pro, Celeron®, Pentium® II, Pentium® III, Pentium® 4 (o compatibili), Xeon™, DEC Alpha™ e Sun UltraSPARC®. È basato principalmente su software del gruppo CSRG della U.C. Berkeley, con alcuni miglioramenti presi da NetBSD, OpenBSD, 386BSD, e dalla Free Software Foundation.
Dalla nostra release di FreeBSD 2.0 nel lontano 1994, le prestazioni, l’insieme di caratteristiche, e la stabilità di FreeBSD sono migliorate notevolmente. Il più grande cambiamento è stato la riscrittura del sistema di memoria virtuale con una VM/file buffer cache integrata che non solo incrementa le prestazioni, ma anche riduce la richiesta di memoria di FreeBSD, rendendo una configurazione con 5 MB un minimo accettabile. Altri miglioramenti includono il completo supporto a client e server NIS, il supporto delle transazioni TCP, la chiamata-su-richiesta di PPP, il supporto integrato del DHCP, un sottosistema SCSI migliorato, il supporto ISDN, il supporto per ATM, FDDI, per gli adattatori Fast e Gigabit Ethernet (1000 Mbit), un supporto migliorato degli ultimi controller Adaptec, e molte migliaia di correzioni di bug.
In aggiunta alla distribuzione di base, FreeBSD offre una collezione di software portato con migliaia di programmi comunemente cercati. Alla data di stampa, ci sono oltre FreeBSD.numports; port! La lista dei port comprende server http (WWW), giochi, linguaggi, editor e quasi tutto quello che sta in mezzo. L’intera collezione dei port richiede approssimativamente 3 GB di spazio, essendo tutti i port espressi come "delta" dei loro sorgenti originari. Questo rende più facile per noi aggiornare i port, e riduce di molto la domanda di spazio su disco dalla vecchia collezione 1.0 dei port. Per compilare un port, vai semplicemente nella directory che vuoi installare, digita make install e lascia che il sistema faccia il resto. La distribuzione originale completa per ogni port che compili viene presa dinamicamente dal CDROM o da un sito FTP locale, così hai bisogno solo lo spazio su disco sufficiente per compilare il port che vuoi. Quasi ogni port viene fornito di un "package" precompilato che può essere installato con un semplice comando (pkg_add) da coloro che non vogliono compilare i propri port dai sorgenti. Maggiori informazioni sui package e sui port possono essere trovate nel Installazione delle Applicazioni. Port e Package.
Un numero di documenti aggiuntivi che puoi trovare molto utili nel processo di installazione e di utilizzo di FreeBSD ora può essere trovato anche nella directory /usr/shared/doc su ogni recente macchina FreeBSD. Puoi vedere i manuali installati localmente con qualsiasi browser HTML usando i seguenti URL:
Puoi vedere anche le copie originali (e aggiornate più frequentemente) su http://www.FreeBSD.org/.
FreeBSD è fornito di un programma di installazione basato su testo, facile da usare, chiamato sysinstall. Questo è il programma di installazione di default di FreeBSD, sebbene i fornitori siano liberi di usare la loro suite di installazione se preferiscono. Questo capitolo descrive come usare sysinstall per installare FreeBSD.
Dopo aver letto questo capitolo, saprai:
Come creare i dischi di installazione di FreeBSD.
Come FreeBSD fa riferimento, e suddivide i tuoi hard disk.
Come far partire sysinstall.
Le domande che sysinstall ti farà, cosa vogliono dire, e come rispondere.
Prima di leggere capitolo, dovresti:
Leggere la lista dell’hardware supportato inclusa nella versione di FreeBSD che stai installando, e verificare che il tuo hardware sia supportato.
In generale, queste istruzioni di installazione sono scritte per computer con architettura i386™ ("PC compatibile"). Dove richiesto, saranno fornite istruzioni specifiche per altre piattaforme (ad esempio, Alpha). Sebbene questa guida sia aggiornata il più possibile, potresti trovare piccole differenze tra la procedura di installazione e quello che viene mostrato qui. È consigliato usare questo capitolo come una guida generale piuttosto che un manuale di installazione vero e proprio. |
Prima di installare FreeBSD dovresti fare un inventario dei componenti del tuo computer. Durante l’installazione di FreeBSD ti verranno mostrati tutti i componenti (hard disk, schede di rete, CDROM, e così via), il loro modello e chi li fabbrica. FreeBSD tenterá di determinare la configurazione corretta per i vari dispositivi, incluse le informazioni riguardo la corretta configurazione sia dell’IRQ che delle porte I/O da usare. A causa della varietà di hardware dei PC non è detto che il processo venga completato con successo, quindi potrai avere bisogno di modificare la tua configurazione.
Se hai già un altro sistema operativo installato, ad esempio Windows® o Linux, potrebbe essere una buona idea vedere come è configurato l’hardware su quei sistemi operativi. Se non sei sicuro della configurazione usata da una certa scheda di espansione, potresti trovare la configurazione stampata sulla scheda stessa. I numeri IRQ più comuni sono 3, 5 e 7,e le porte di indirizzo I/O sono di norma scritte in numeri esadecimali, come 0x330.
Raccomandiamo di scrivere o di stampare queste informazioni prima di installare FreeBSD. Può essere d’aiuto usare una tabella, come questa:
| Nome Dispositivo | IRQ | porte di I/O | Note |
|---|---|---|---|
Primo hard disk | N/A | N/A | 40 GB, fabbricato da Seagate, primo IDE master |
CDROM | N/A | N/A | Primo IDE slave |
Secondo hard disk | N/A | N/A | 20 GB, fabbricato da IBM, secondo IDE master |
Primo controller IDE | 14 | 0x1f0 | |
Scheda di rete | N/A | N/A | Intel® 10/100 |
Modem | N/A | N/A | 3Com® 56K faxmodem, su COM1 |
… | … | … | … |
Se il computer dove installerai FreeBSD contiene dati importanti, fai un backup dei dati, quindi verifica il backup prima di iniziare un’installazione di FreeBSD. La procedura di installazione di FreeBSD ti avviserà prima di scrivere dati sul tuo disco, ma una volta confermato il processo questo non può più essere annullato.
Se vuoi usare l’intero disco per installare FreeBSD, puoi saltare tranquillamente questa sezione.
Altrimenti, se vuoi che FreeBSD coesista con altri sistemi operativi allora hai bisogno di una conoscenza basilare di come i dati sono organizzati sul disco.
Un disco di un PC può essere suddiviso in diverse parti. Queste parti vengono chiamate partizioni. Per sua natura, un PC supporta solo quattro partizioni per disco. Queste partizioni sono chiamate partizioni primarie. Per aggirare questa limitazione e avere più di quattro partizioni, è stata progettata un nuovo tipo di partizione, la partizione estesa. Un disco può contenere una sola partizione estesa. All’interno di questa partizione estesa possono essere create partizioni speciali, chiamate partizioni logiche.
Ogni partizione ha un'ID di partizione, che è un numero usato per identificare il tipo di dati nella partizione. L’ID di partizione di FreeBSD è 165.
In generale, ogni sistema operativo che usi identificherà le sue partizioni in un modo particolare. Per esempio, il DOS, e i suoi discendenti, come Windows®, assegnano ad ogni partizione primaria e logica una lettera di dispositivo, cominciando con C:.
FreeBSD deve essere installato su una partizione primaria. I dati di FreeBSD, inclusi i tuoi file, possono risiedere tutti su questa unica partizione. Comunque, se hai più dischi, puoi creare una partizione FreeBSD su tutti i dischi (o su parte di essi). Quando installi FreeBSD, devi avere una partizione disponibile. Questa potrebbe essere una nuova partizione che hai preparato, o potrebbe essere una partizione esistente che contiene dati che non ti interessano più.
Se già usi tutte le partizioni di ogni tuo disco, dovrai liberare una partizione per FreeBSD utilizzando i programmi forniti dagli altri sistemi operativi che usi (es., fdisk su DOS o Windows®).
Se hai una partizione libera puoi usare quella. Comunque, potresti avere la necessità di restringere una o più delle tue partizioni.
Un’installazione minima di FreeBSD richiede un piccolo spazio di 100 MB sull’hard disk. Comunque, questa è proprio un’installazione minima, che non lascia molto spazio per altri tuoi file. Una partizione minima più realistica è di 250 MB, senza ambiente grafico, e di 350 MB o anche di più se vuoi un’interfaccia grafica. Se hai intenzione di installare diverso software di terze parti, avrai bisogno di molto più spazio.
Puoi usare programmi commerciali come ad esempio PartitionMagic® o programmi free come GParted per ridimensionare le tue partizioni e creare spazio per FreeBSD. La directory tools sul CDROM contiene due software gratuiti che possono eseguire questo compito, FIPS e PResizer. La documentazione per entrambi questi strumenti è disponibile nella stessa directory. FIPS, PResizer, e PartitionMagic® possono ridimensionare partizioni FAT16 e FAT32 - usate da MS-DOS® fino a Windows® ME. Sia PartitionMagic® che GParted sono noti per maneggiare anche partizioni NTFS.
L’uso scorretto di questi programmi può causare la perdita di dati nel tuo hard disk. Assicurati di avere un backup recente e funzionante prima di usare questi strumenti. |
Supponiamo che tu abbia un computer con un singolo disco di 4 GB con già installato una versione di Windows®, e che tu abbia suddiviso il disco in due lettere di dispositivo, C: e D:, ognuno dei quali ha dimensioni pari a 2 GB. Hai 1 GB di dati su C:, e 0.5 GB di dati su D:.
Questo significa che il tuo disco ha due partizioni, una per lettera. Puoi copiare tutti i tuoi dati da D: a C:, in modo da liberare la seconda partizione, pronta per FreeBSD.
Supponiamo che tu abbia un computer con un singolo disco da 4 GB dove è già installata una versione di Windows®. Quando hai installato Windows® hai creato un’unica grande partizione, il dispositivo C: con capacità pari a 4 GB. Hai usato 1.5 GB di spazio, e vorresti usarne 2 GB per FreeBSD.
Per installare FreeBSD hai due differenti possibilità:
Fare il backup dei tuoi dati in Windows®, e installarlo di nuovo, occupando solamente 2 GB.
Utilizzare uno strumento come PartitionMagic®, come descritto in precedenza, per restringere la partizione di Windows®.
Dovrai dedicare un intero disco per FreeBSD su Alpha. Attualmente non è possibile condividere un disco con altri sistemi operativi. A seconda della macchina Alpha che possiedi, il disco può essere sia SCSI che IDE, sempre che la tua macchina sia capace di fare il boot da essi.
Seguendo la convenzione dei manuali della Digital / Compaq tutti gli input SRM sono maiuscoli. SRM è case insensitive.
Per determinare i nomi e i tipi dei dischi nella tua macchina, usa il comando SHOW DEVICE dal prompt della console SRM:
>>>SHOW DEVICE
dka0.0.0.4.0 DKA0 TOSHIBA CD-ROM XM-57 3476
dkc0.0.0.1009.0 DKC0 RZ1BB-BS 0658
dkc100.1.0.1009.0 DKC100 SEAGATE ST34501W 0015
dva0.0.0.0.1 DVA0
ewa0.0.0.3.0 EWA0 00-00-F8-75-6D-01
pkc0.7.0.1009.0 PKC0 SCSI Bus ID 7 5.27
pqa0.0.0.4.0 PQA0 PCI EIDE
pqb0.0.1.4.0 PQB0 PCI EIDEQuesto esempio è stato preso da una Digital Personal Workstation 433au e mostra tre dischi collegati alla macchina. Il primo è un lettore CDROM chiamato DKA0, mentre gli altri due dischi sono chiamati rispettivamente DKC0 e DKC100.
I nomi dei dischi del tipo DKx , sono dischi SCSI. Per esempio DKA100 è riferito al disco SCSI con ID 1 sul primo bus SCSI (A), mentre DKC300 si riferisce al disco SCSI con ID 3 sul terzo bus SCSI ©. Il nome del dispositivo PKx si riferisce all’adattatore SCSI. Come visto nell’output di SHOW DEVICE i CDROM SCSI sono trattati come dischi SCSI.
I dischi IDE hanno un nome del tipo DQx, mentre ai nomi PQx sono associati i controller IDE.
Se intendi installare FreeBSD tramite una connessione di rete (per esempio, un’installazione tramite FTP, oppure un server NFS), allora dovrai conoscere la tua configurazione di rete. Ti verranno richieste queste informazioni durante l’installazione in modo che FreeBSD possa connettersi alla rete e completare l’installazione.
Se hai la possibilità di connetterti a una rete Ethernet, o se hai una connessione a Internet tramite un adattatore Ethernet via cavo o DSL, allora avrai bisogno delle seguenti informazioni:
Indirizzo IP
Indirizzo IP del gateway di default
Il nome host (hostname)
Indirizzi IP dei server DNS
Maschera di Rete
Se non conosci queste informazioni, puoi chiederle al tuo amministratore di sistema oppure al tuo provider. Potrebbero dirti che queste informazioni sono assegnate automaticamente, usando DHCP. Se così fosse, prendi nota.
Se ti connetti al tuo ISP usando un modem puoi installare FreeBSD da Internet, e questo richiederà molto tempo.
In questo caso dovrai sapere:
Il numero di telefono per la connessione del tuo ISP
La porta COM: sulla quale il tuo modem è connesso
Il nome utente e relativa password del tuo account dell’ISP
Sebbene il progetto di FreeBSD si impegna per assicurare che ogni release di FreeBSD sia stabile il più possibile, può capitare che ogni tanto qualche bug sfugga durante il processo di costruzione della release. In rare occasioni questi bug interessano il processo di installazione. Non appena questi problemi sono scoperti e fixati, gli stessi sono segnalati nella FreeBSD Errata, che è possibile trovare sul sito web di FreeBSD. Dovresti verificare questo documento prima di iniziare l’installazione in modo tale da essere a conoscenza dei bug esistenti.
Le informazioni sulle varie release, inclusi i vari errata per ogni release, possono essere trovati nella sezione informazioni di release sul sito web di FreeBSD.
Il processo di installazione di FreeBSD può installare FreeBSD prendendo file da una delle seguenti fonti:
Un CDROM o DVD
Una partizione DOS sullo stesso computer
Un nastro magnetico SCSI o QIC
Floppy disk
Un sito FTP, passando attraverso un firewall, o usando un proxy HTTP, a seconda della necessità
Un server NFS
Una connessione parallela o seriale dedicata
Se hai comprato il CD o il DVD di FreeBSD allora hai già tutto ciò che necessiti, e dovresti passare alla prossima sezione (Preparare i Media per il Boot).
Se non ti sei procurato i file di installazione di FreeBSD dovresti saltare alla Preparare i Propri Media di Installazione che spiega come prepararsi all’installazione di FreeBSD. Dopo aver letto quella sezione, puoi tornare indietro e leggere la Preparare i Media per il Boot.
Il processo di installazione di FreeBSD ha inizio avviando il tuo computer nel programma di installazione di FreeBSD-non è un programma che puoi avviare da un altro sistema operativo. Normalmente il tuo computer fa il boot usando il sistema operativo installato sul tuo hard disk, ma puoi configurare il tuo computer affinchè faccia il boot da floppy disk "avviabili". Inoltre la maggior parte dei computer odierni possono fare il boot da CDROM.
Se possiedi FreeBSD su CDROM o su DVD (sia che l’hai comprato o preparato per conto tuo), ed il tuo computer consente di fare il boot da CDROM o DVD (solitamente tramite un’opzione del BIOS chiamata "Boot Order" o simili), allora puoi saltare questa sezione. Le immagini CDROM o DVD di FreeBSD sono avviabili e possono essere utilizzate per installare FreeBSD senza altre preparazioni particolari. |
Per creare un’immagine floppy avviabile, segui i seguenti passi :
Ottenere l’Immagine Floppy Avviabile
I dischi avviabili sono disponibili nel tuo media di installazione nella directory floppies/, inoltre possono essere scaricate dalla directory floppies/, ftp://ftp.FreeBSD.org/pub/FreeBSD/releases/<arch>/<version>-RELEASE/floppies/. Sostituisci <arch> e <version> rispettivamente con l’architettura e il numero di versione che vuoi installare. Per esempio, le immagini floppy avviabili per FreeBSD 12.0-RELEASE per i386™ sono disponibili in ftp://ftp.FreeBSD.org/pub/FreeBSD/releases/i386/12.0-RELEASE/floppies/.
Le immagini floppy hanno l’estensione .flp. La directory floppies/ contiene diverse immagini, a seconda della versione di FreeBSD che vuoi installare, e in alcuni casi, a seconda dell’hardware che possiedi. Nella maggior parte dei casi avrai bisogno di tre floppy, boot.flp, kern1.flp, e kern2.flp. Consulta il file README.TXT che puoi trovare nella stessa directory al fine di avere maggiori informazioni riguardanti le immagine floppy.
Possono essere necessari driver di dispositivi aggiuntivi per sistemi 5.X più vecchi di FreeBSD 5.3. Queste driver sono forniti dall’immagine drivers.flp. |
Il tuo programma FTP deve usare la modalità binaria per poter scaricare queste immagini floppy. Alcuni browser web usano la modalità testo (chiamata anche ASCII), e ti accorgerai di questo se non riuscirai ad avviare da floppy. |
Preparare i Dischetti Floppy
Devi preparare un disco floppy per ogni immagine che hai scaricato. Questi dischetti non devono avere difetti. Il metodo più semplice per verificare ciò è formattare i dischi. Non avere fiducia dei dischetti pre-formattati. Lo strumento di formattazione in Windows® non segnala l’eventuale presenza di blocchi danneggiati, semplicemente li segna come "difettosi" e li ignora. È consigliabile usare dei nuovi dischetti floppy se hai in mente di procedere con questo tipo di installazione.
Se stai tentando di installare FreeBSD ed il programma di installazione crasha, freeza, o non procede come dovrebbe, la prima cosa da sospettare sono proprio i floppy. Prova a scrivere i file di immagine floppy su nuovi dischi e riprova. |
Scrivere i File Immagine sui Floppy Disk
I file .flpnon sono dei file regolari da copiare sul dischetto. Sono immagini di un contenuto completo di un dischetto. Questo significa che non puoi copiare semplicemente i file da un dischetto ad un altro. Invece, devi usare uno strumento specifico per scrivere le immagini direttamente sul dischetto.
Se stai creando i floppy su un computer con in esecuzione MS-DOS®/Windows®, allora puoi usare l’utility chiamata fdimage.
Se vuoi usare le immagini che stanno nel CDROM, ed il CDROM è sul dispositivo E:, puoi impartire questo comando:
E:\> tools\fdimage floppies\kern.flp A:Ripeti questo comando per ogni file .flp, sostituendo ogni volta il disco floppy, e poi assicurati di etichettare ogni floppy con il nome del file che hai copiato. Aggiusta il comando come necessario, a seconda di dove hai collocato i file .flp. Se non hai il CDROM, puoi scaricare fdimage dalla directory tools sul sito FTP di FreeBSD.
Se stai creando i floppy su sistema UNIX® (come un altro sistema FreeBSD) puoi usare il comando dd(1) per scrivere i file immagine direttamente sul disco. Su FreeBSD, dovresti eseguire:
# dd if=kern.flp of=/dev/fd0Su FreeBSD, /dev/fd0 è riferito al primo floppy disk (il dispositivo A:). /dev/fd1 sarebbe il dispositivo B:, e cosi via. Altre varianti UNIX® potrebbero avere nomi differenti per i dispositivi floppy disk, e se necessario consulta la documentazione del sistema che stai usando.
Adesso sei pronto per iniziare ad installare FreeBSD.
Per default, l’installazione non apporterà nessun cambiamento sul tuo disco (o dischi) fino a quando non vedi questo messaggio: Last Chance: Are you SURE you want continue the installation? If you're running this on a disk with data you wish to save then WE STRONGLY ENCOURAGE YOU TO MAKE PROPER BACKUPS before proceeding! We can take no responsibility for lost disk contents! Il processo di installazione può essere sospeso in qualunque momento prima dell’avvertimento finale senza cancellare dati sul tuo hard disk. Se ti sei accorto di aver configurato qualcosa di sbagliato puoi ancora spegnere il computer prima di quel avvertimento, senza che venga creato alcun danno. |
Iniziamo con il computer spento.
Accendi il computer. Appena acceso dovrebbe visualizzare un’opzione per entrare nel menù di sistema, chiamato anche BIOS, solitamente tramite tasti come F2, F10, Del, o Alt+S. Usa la combinazione di tasti indicata sullo schermo. In alcuni casi il tuo computer può visualizzare un’immagine durante la fase di avvio. In genere, premendo Esc l’immagine sparirà e sarai in grado di vedere i messaggi di avvio.
Trova il settaggio che controlla da quali dispositivi il sistema tenta l’avvio. Di solito questo settaggio viene identificato con "Boot Order" e in genere mostra una lista di dispositivi, come Floppy, CDROM, First Hard Disk, e così via.
Se vuoi partire con il boot da floppy, assicurati di avere selezionato il floppy disk come primo dispositivo di avvio. Se invece vuoi partire con il boot da CDROM allora seleziona questo come primo dispositivo di avvio. In caso di dubbio, puoi consultare il manuale che ti hanno dato assieme al computer, e/o con la scheda madre.
Una volta apportato la modifica, salva ed esci dal BIOS. Il computer dovrebbe fare un riavvio.
Se hai bisogno di preparare i floppy di boot, come descritto nella Preparare i Media per il Boot, allora uno di questi sarà il primo dischetto di boot, probabilmente quello contenente l’immagine kern.flp. Metti questo disco nel tuo floppy.
Se vuoi fare il boot da CDROM, allora dovrai accendere il computer, e inserire il CDROM prima che puoi.
Se il computer parte normalmente e carica il sistema operativo già esistente, allora: .. I dischi non sono stati inseriti prima dell’inizio della fase di avvio. Lasciali inseriti, e riavvia il computer. .. I recenti cambiamenti apportati nel BIOS non sono corretti. Dovresti rifare i passaggi fino a quando avrai successo. .. Il tuo BIOS non supporta il boot dal tuo media desiderato.
FreeBSD si avvierà. Se hai scelto di partire da CDROM probabilmente vedrai schermate come queste (le informazioni sulla versione sono state omesse):
Verifying DMI Pool Data ........
Boot from ATAPI CD-ROM :
1. FD 2.88MB System Type-(00)
Uncompressing ... done
BTX loader 1.00 BTX version is 1.01
Console: internal video/keyboard
BIOS drive A: is disk0
BIOS drive B: is disk1
BIOS drive C: is disk2
BIOS drive D: is disk3
BIOS 639kB/261120kB available memory
FreeBSD/i386 bootstrap loader, Revision 0.8
/kernel text=0x277391 data=0x3268c+0x332a8 |
|
Hit [Enter] to boot immediately, or any other key for command prompt.
Booting [kernel] in 9 seconds... _Se hai fatto il boot da floppy, vedrai simili informazioni sul tuo schermo (le informazioni sulla versione sono state omesse):
Verifying DMI Pool Data ........
BTX loader 1.00 BTX version is 1.01
Console: internal video/keyboard
BIOS drive A: is disk0
BIOS drive C: is disk1
BIOS 639kB/261120kB available memory
FreeBSD/i386 bootstrap loader, Revision 0.8
/kernel text=0x277391 data=0x3268c+0x332a8 |
Please insert MFS root floppy and press enter:Segui queste istruzioni, rimuovi il disco kern.flp, inserisci il disco mfsroot.flp, e premi Invio. FreeBSD 5.3 e superiori hanno ulteriori dischi, come descritto nella sezione precedente. Avvia dal primo floppy; quando indicato, inserisci gli altri dischi.
Indipendentemente se hai fatto il boot da floppy o da CDROM, il processo di avvio arriverà a questo punto:
Hit [Enter] to boot immediately, or any other key for command prompt.
Booting [kernel] in 9 seconds... _Aspetta dieci secondi o premi Invio
Iniziamo con il computer spento.
Accendi il computer e attendi che arrivi al prompt di avvio.
Se hai la necessità di preparare i floppy di avvio, come descritto nella Preparare i Media per il Boot allora uno di questi sarà il primo disco di avvio, probabilmente quello che contiene kern.flp. Inserisci questo disco nel tuo floppy e digita il seguente comando per avviare da dischetto (sostituisci il nome del tuo floppy se necessario):
>>>BOOT DVA0 -FLAGS '' -FILE ''Se stai avviando da CDROM, inserisci il CDROM nel lettore e digita il seguente comando per avviare l’installazione (sostituisci il nome del lettore CDROM se necessario):
>>>BOOT DKA0 -FLAGS '' -FILE ''In fase di avvio partirà FreeBSD. Se hai fatto il boot tramite floppy, ad un certo punto vedrai questo messaggio:
Please insert MFS root floppy and press enter:Segui queste istruzioni e rimuovi il disco kern.flp, inserisci il disco mfsroot.flp, poi premi Invio.
Indipendentemente se hai fatto il boot da floppy o da CDROM, il processo di avvio arriverà a questo punto:
Hit [Enter] to boot immediately, or any other key for command prompt.
Booting [kernel] in 9 seconds... _Puoi sia aspettate dieci secondi, oppure premere Invio. In questo modo verrà caricato il menù di configurazione del kernel.
Le ultime cento righe che sono state visualizzate sullo schermo sono memorizzate e possono essere riviste.
Per rivedere il buffer, premi Scroll Lock. Ti permetterà di scorrere nel video. Puoi usare i tasti freccia, oppure PageUp e PageDown per vedere i risultati. Premi di nuovo Scroll Lock per fermare lo scrolling.
Usa questa tecnica per rivedere i messaggi che sono stati visualizzati quando il kernel ha effettuato il probe dei dispositivi. Vedrai del testo simile alla Risultati Tipo del Probe dei Dispositivi, anche se questo potrebbe essere diverso a seconda dei dispositivi che hai nel tuo computer.
avail memory = 253050880 (247120K bytes)
Preloaded elf kernel "kernel" at 0xc0817000.
Preloaded mfs_root "/mfsroot" at 0xc0817084.
md0: Preloaded image </mfsroot> 4423680 bytes at 0xc03ddcd4
md1: Malloc disk
Using $PIR table, 4 entries at 0xc00fde60
npx0: <math processor> on motherboard
npx0: INT 16 interface
pcib0: <Host to PCI bridge> on motherboard
pci0: <PCI bus> on pcib0
pcib1:<VIA 82C598MVP (Apollo MVP3) PCI-PCI (AGP) bridge> at device 1.0 on pci0
pci1: <PCI bus> on pcib1
pci1: <Matrox MGA G200 AGP graphics accelerator> at 0.0 irq 11
isab0: <VIA 82C586 PCI-ISA bridge> at device 7.0 on pci0
isa0: <iSA bus> on isab0
atapci0: <VIA 82C586 ATA33 controller> port 0xe000-0xe00f at device 7.1 on pci0
ata0: at 0x1f0 irq 14 on atapci0
ata1: at 0x170 irq 15 on atapci0
uhci0 <VIA 83C572 USB controller> port 0xe400-0xe41f irq 10 at device 7.2 on pci
0
usb0: <VIA 83572 USB controller> on uhci0
usb0: USB revision 1.0
uhub0: VIA UHCI root hub, class 9/0, rev 1.00/1.00, addr1
uhub0: 2 ports with 2 removable, self powered
pci0: <unknown card> (vendor=0x1106, dev=0x3040) at 7.3
dc0: <ADMtek AN985 10/100BaseTX> port 0xe800-0xe8ff mem 0xdb000000-0xeb0003ff ir
q 11 at device 8.0 on pci0
dc0: Ethernet address: 00:04:5a:74:6b:b5
miibus0: <MII bus> on dc0
ukphy0: <Generic IEEE 802.3u media interface> on miibus0
ukphy0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, auto
ed0: <NE2000 PCI Ethernet (RealTek 8029)> port 0xec00-0xec1f irq 9 at device 10.
0 on pci0
ed0 address 52:54:05:de:73:1b, type NE2000 (16 bit)
isa0: too many dependant configs (8)
isa0: unexpected small tag 14
orm0: <Option ROM> at iomem 0xc0000-0xc7fff on isa0
fdc0: <NEC 72065B or clone> at port 0x3f0-0x3f5,0x3f7 irq 6 drq2 on isa0
fdc0: FIFO enabled, 8 bytes threshold
fd0: <1440-KB 3.5" drive> on fdc0 drive 0
atkbdc0: <Keyboard controller (i8042)> at port 0x60,0x64 on isa0
atkbd0: <AT Keyboard> flags 0x1 irq1 on atkbdc0
kbd0 at atkbd0
psm0: <PS/2 Mouse> irq 12 on atkbdc0
psm0: model Generic PS/@ mouse, device ID 0
vga0: <Generic ISA VGA> at port 0x3c0-0x3df iomem 0xa0000-0xbffff on isa0
sc0: <System console> at flags 0x100 on isa0
sc0: VGA <16 virtual consoles, flags=0x300>
sio0 at port 0x3f8-0x3ff irq 4 flags 0x10 on isa0
sio0: type 16550A
sio1 at port 0x2f8-0x2ff irq 3 on isa0
sio1: type 16550A
ppc0: <Parallel port> at port 0x378-0x37f irq 7 on isa0
pppc0: SMC-like chipset (ECP/EPP/PS2/NIBBLE) in COMPATIBLE mode
ppc0: FIFO with 16/16/15 bytes threshold
plip0: <PLIP network interface> on ppbus0
ad0: 8063MB <IBM-DHEA-38451> [16383/16/63] at ata0-master UDMA33
acd0: CD-RW <LITE-ON LTR-1210B> at ata1-slave PIO4
Mounting root from ufs:/dev/md0c
/stand/sysinstall running as init on vty0Analizza attentamente i risultati del probe per assicurarti che FreeBSD ha trovato tutti i dispositivi che ti aspetti. Se non è stato trovato un dispositivo, allora questo non sarà in elenco. Se il driver del dispositivo richiede la configurazione di IRQ e indirizzi di porta allora assicurati di averli inseriti correttamente.
Se hai la necessità di modificare dei settaggi per il probe dei dispositivi indicati nell’UserConfig, esci dal programma sysinstall e ricomincia da capo. Questo è anche un modo per prendere confidenza con il processo.
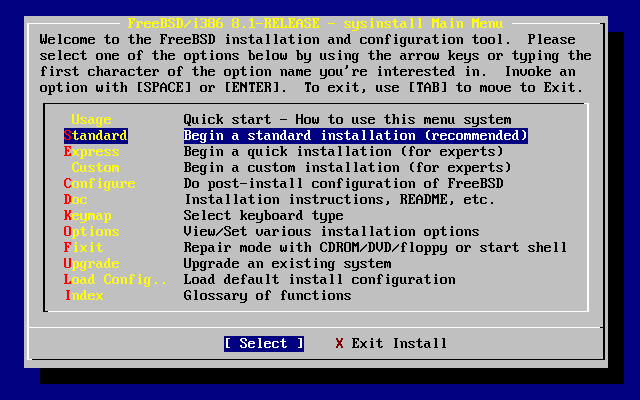
Usa i tasti freccia per selezionare dal menù principale di installazione. Ti apparirà il seguente messaggio:
User Confirmation Requested
Are you sure you wish to exit? The system will reboot
(be sure to remove any floppies from the drives).
[ Yes ] NoIl programma d’installazione partirà nuovamente se il CDROM è ancora nel driver ed è selezionata yes.
Se hai avviato da floppy sarà necessario rimuovere il floppy mfsroot.flp e mettere kern.flp prima di riavviare.
L’utility sysinstall è l’applicazione di installazione fornita dal FreeBSD Project. È basata sulla console ed è suddivisa in diversi menù e schermate che puoi usare per configurare e controllare il processo di installazione.
Il sistema a menù di sysinstall è governabile tramite i tasti freccia, Invio, Spazio, e altri tasti. Una descrizione dettagliata di questi tasti e ciò che essi fanno sono contenuti nel documento sull’uso di sysinstall.
Per vedere queste informazioni, assicurati che sia evidenziata l’entry e che sia selezionato il bottone Select, come mostrato in Come Selezionare Usage dal Menù Principale di Sysinstall, quindi premi Invio.
In questo modo verranno visualizzate le istruzioni per usare il sistema a menù. Premi Invio per ritornare al menù principale.
Dal menù principale, seleziona con i tasti freccia e premi Invio.
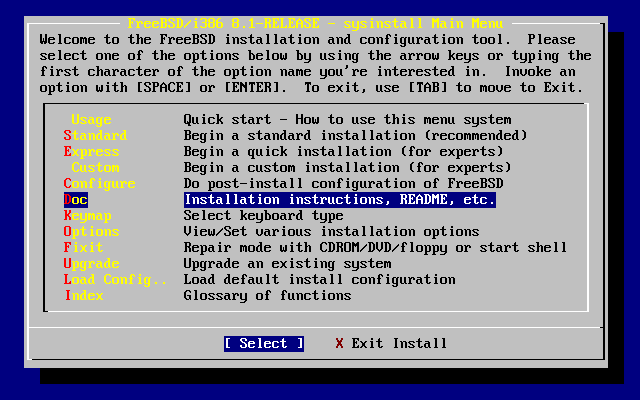
Verrà mostrato il menù della documentazione.

È importante leggere la documentazione.
Per visualizzare un documento, selezionalo con i tasti freccia e premi Invio. Quando hai finito di leggere il documento, premi Invio per ritornare al menù della documentazione.
Per ritornare al Menù di Installazione Principale, seleziona con i tasti freccia e premi Invio.
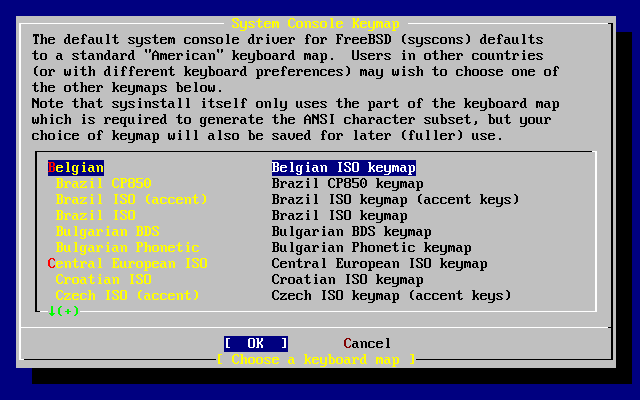
Per cambiare la mappatura della tastiera, usa i tasti freccia per selezionare dal menù e premi Invio. Questo è richiesto solo se stati usando una tastiera non-standard o una tastiera non americana.
Una diversa mappatura della tastiera può essere selezionata nel menù usando i tasti freccia e premendo Spazio. Premi di nuovo Spazio per deselezionare la tua scelta. Quando hai finito, scegli OK usando i tasti freccia e premi Invio.
Nel successivo screen-shot ne viene mostrata una lista parziale. Se selezioni Cancel premendo Tab userai la mappatura di default e ritornerai al Menù dell’Installazione Principale.
Seleziona e premi Invio.
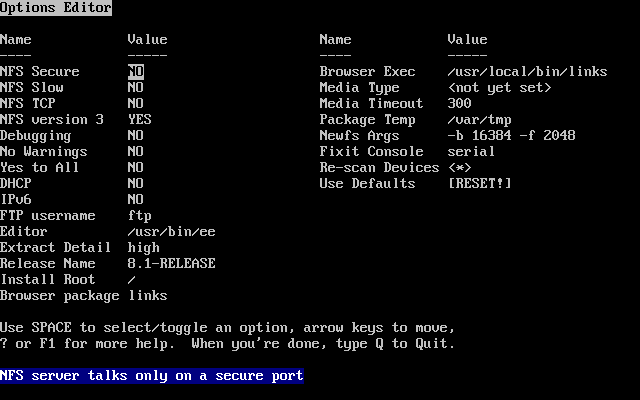
I valori di default sono adeguati per la maggior parte degli utenti e solitamente non necessitano modifiche. Il nome della release varierà a seconda della versione che si sta installando.
La descrizione dell’elemento selezionato apparirà illuminato in blu in fondo alla schermata. Nota che una di queste opzioni è per resettare tutti i valori ai rispettivi valori di default.
Premi F1 per leggere la schermata di aiuto delle varie opzioni.
Premendo Q ritornerai al Menù di Installazione Principale.
Prima di tutto devi allocare dello spazio su disco per FreeBSD, ed etichettare quello spazio in modo tale che sysinstall possa utilizzarlo. Per fare questo devi conoscere come FreeBSD si aspetta di trovare le informazioni sul disco.
Prima di installare e configurare FreeBSD sul tuo sistema, c’è una cosa importante che devi sapere, specialmente se hai più dischi.
In un PC con un sistema operativo dipendente dal BIOS come MS-DOS® o Microsoft® Windows®, il BIOS è in grado di ricavare il corretto ordine dei dischi, e il sistema operativo concorda con un eventuale cambiamento. Questo consente all’utente di effettuare il boot da un disco diverso dal "master primario". Questo è conveniente soprattutto per alcuni utenti che hanno convenuto che il modo più semplice e conveniente per mantenere un sistema di backup è di comperare un secondo disco identico al primo, e effettuare consuete copie del primo disco sul secondo usando Ghost o XCOPY. Quindi, se il primo disco fa fiasco, è sotto le minacce di un virus, o è scarabocchiato da un’imperfezione del sistema operativo stesso, può essere facilmente recuperato istruendo il BIOS a swappare logicamente i due dischi. È come cambiare i cavi sui dischi, ma senza dover aprire il case.
I sistemi più costosi con controller SCSI spesso includono delle estensioni del BIOS che consentono di riordinare i dischi SCSI in modo simile a quanto sopra esposto per un massimo di sette dispositivi.
Un utente che è abituato ad usare queste caratteristiche può rimanere sorpreso quando vede che i risultati con FreeBSD non sono quelli che si aspettava. FreeBSD non usa il BIOS, e non sa nulla riguardo alla "mappatura logica dei dispositivi del BIOS". Questo può portare a delle situazioni che lasciano perplessi, in particolar modo quando i dischi hanno un’identica geometria fisica, e sono dei clone di un altro disco.
Quando si ha a che fare con FreeBSD, ripristinare sempre il BIOS alla numerazione naturale prima di installare FreeBSD, e lasciarla in quel modo. Se hai bisogno di scambiare i dispositivi, fallo, ma fallo fisicamente, aprendo il case e cambiando i cavi e jumper in modo opportuno.
Bill distrugge una vecchia box Wintel per fare una box FreeBSD per Fred. Bill installa un solo disco SCSI come l’unità zero SCSI ed installa FreeBSD su di esso.
Fred inizia ad usare il sistema, ma dopo alcuni giorni nota che il vecchio disco SCSI riporta numerosi errori e riferisce questo fatto a Bill.
Dopo un pò, Bill decide di risolvere la situazione, così prende un disco SCSI identico nella stanza dell'"archivio" di dischi. Una scansione iniziale indica che il disco funziona bene, dunque Bill installa questo disco come la quarta unità SCSI e crea una copia dell’immagine del disco zero nel disco quattro. Ora che il nuovo disco è installato e funziona bene, Bill decide che è una buona idea iniziare ad usarlo, quindi usa le funzionalità nel BIOS SCSI per riordinare i dischi in modo tale che il sistema effettui il boot dal disco quattro. FreeBSD viene avviato e funziona in modo corretto.
Fred continua il suo lavoro per parecchi giorni, quando Bill e Fred decidono che è ora di una nuova avventura - tempo di aggiornare ad una nuova versione di FreeBSD. Bill rimuove l’unità SCSI zero perchè era un pò fiacca e la sostituisce con un’altra unità disco identica prendendola dall'"archivio". Bill quindi installa la nuova versione di FreeBSD nella nuova unità SCSI zero usando i floppy FTP di Internet di Fred. L’installazione ha successo.
Fred usa la nuova versione di FreeBSD per alcuni giorni, e si convince che è sufficientemente buona per usarla nel dipartimento di ingegneria. È ora di copiare tutto il suo lavoro della vecchia versione. Fred monta la quarta unità SCSI (l’ultima copia della vecchia versione di FreeBSD). Fred è costernato dal fatto che nulla del suo precedente lavoro è presente nella quarta unità SCSI.
Dove sono andati i dati?
Quando Bill ha fatto una copia dell’immagine dell’unità SCSI zero di origine sulla quarta unità SCSI, la quarta unità divenne un "clone". Quando Bill ha riordinato il BIOS SCSI affinchè si poteva effettuare il boot dalla quarta unità SCSI, ha solo ingannato se stesso. FreeBSD stava ancora girando sull’unità SCSI zero. Questo tipo di modifica al BIOS farà in modo che tutto il codice di boot e del loader sia prelevato dal dispositivo indicato nel BIOS, ma quando i driver del kernel di FreeBSD prendono il controllo, la numerazione dei dispositivi del BIOS sarà ignorata, e FreeBSD considererà la numerazione standard dei dispositivi. Nel nostro esempio, il sistema ha continuato ad operare sull’unità SCSI zero originale, e tutti i dati di Fred erano lì, e non sulla quarta unità SCSI. Il fatto che il sistema sembrava in esecuzione sulla quarta unità SCSI era semplicemente un artificio delle aspettative umane.
Siamo contenti di dire che nessun dato è stato cancellato o artefatto dalla scoperta di questo fenomeno. L’unità zero SCSI utilizzata in precedenza è stata recuperata dalla pila di hard disk, ed è stato recuperato tutto il lavoro di Fred, (e ora Bill sa che puè contare anche sull’unità zero).
Sebbene siano stati utilizzati dispositivi SCSI in questo esempio, lo stesso concetto si applica ai dispositivi IDE.
Tutte le modifiche che fai ora non saranno scritte su disco. Se pensi di aver fatto un errore e vuoi ricominciare dall’inizio puoi usare il menù di sysinstall per uscire e tentare un’altra volta o premere il tasto U per usare l’opzione . Se sei confuso e non riesci a capire come uscire dall’applicazione puoi sempre riavviare il computer. |
Dopo aver scelto un’installazione standard in sysinstall ti verrà mostrato questo messaggio:
Message
In the next menu, you will need to set up a DOS-style ("fdisk")
partitioning scheme for your hard disk. If you simply wish to devote
all disk space to FreeBSD (overwriting anything else that might be on
the disk(s) selected) then use the (A)ll command to select the default
partitioning scheme followed by a (Q)uit. If you wish to allocate only
free space to FreeBSD, move to a partition marked "unused" and use the
(C)reate command.
[ OK ]
[ Press enter or space ]Premi Invio come segnalato. Ti verrà mostrato un elenco di tutti gli hard disk che il kernel ha trovato quando ha effettuato il probe dei dispositivi. La Come Selezionare il Dispositivo per FDisk mostra un esempio con un sistema con due dischi IDE. Questi sono chiamati ad0 e ad2.
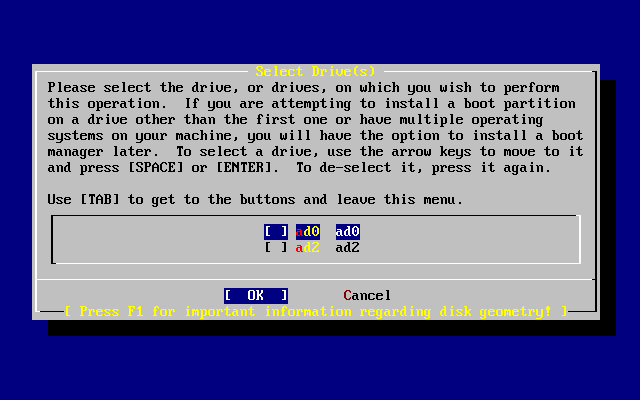
Ti potresti chiedere perchè ad1 non è elencato nella lista. Perchè è stato omesso?
Considera ciò che succederebbe se hai due hard disk IDE, uno come master sul primo controller IDE, ed uno come master sul secondo controller IDE. Se FreeBSD li enumera come li trova, allora saranno ad0 e ad1.
Ma se vuoi aggiungere un terzo hard disk, come dispositivo slave sul primo controller IDE, allora questo sarà ad1, ed il precedente ad1 diventerà ad2. Poichè i nome dei dispositivi (come ad1s1a) sono usati per determinare i filesystem, potresti improvvisamente scoprire che alcuni dei tuoi filesystem non appaiono più correttamente, e avrai necesità di modificare la tua configurazione di FreeBSD.
Per aggirare questo problema, il kernel può essere configurato per denominare i dischi IDE in base alla loro posizione, e non in base all’ordine di rilevamento degli stessi. Con questo schema il disco master sul secondo controller IDE sarà sempread2, anche se non sono presenti i dispositivi ad0 e ad1.
Questa configurazione è di default per il kernel di FreeBSD, ed è per questo che il display visualizza ad0 e ad2. La macchina sulla quale è stato preso questo screenshot aveva dischi IDE su entrambi i canali master dei controller IDE, e nessun disco sui canali slave.
Dovresti selezionare il disco sul quale vuoi installare FreeBSD, poi premi OK. Verrà avviato FDisk, con una schermata simile a quella nella Partizioni Tipiche in Fdisk prima delle Modifiche.
La schermata di FDisk è divisa in tre sezioni.
La prima sezione, comprendente le prime due linee della schermata, mostra i dettagli dell’hard disk selezionato, includendo il nome di FreeBSD, la geometria del disco, e la sua capacità.
La seconda sezione mostra le slice che sono attualmente sul disco, dove esse cominciano e dove finiscono, quanto sono grandi, il nome assegnato da FreeBSD, la loro descrizione ed il loro tipo. Questo esempio mostra due piccole slice inutilizzate, che sono uno degli artefatti degli schemi di progetto del PC. Mostra anche una grande slice FAT, che apparirà quasi certamente come C: in MS-DOS® / Windows®, ed una slice estesa, che può contenere altre lettere dei dispositivi per MS-DOS® / Windows®.
La terza sezione mostra i comandi che sono disponibili in FDisk.
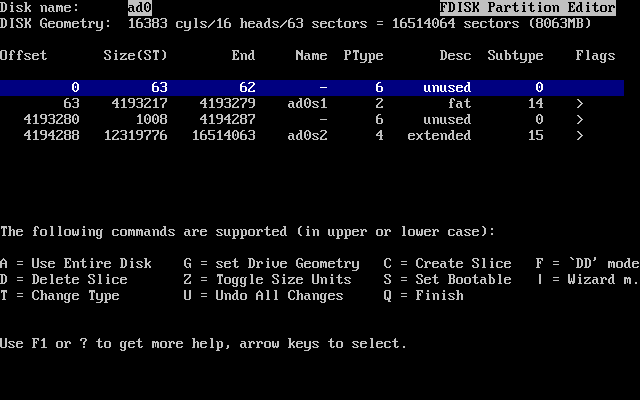
Cosa farai ora dipende da come vuoi splittare il tuo disco.
Se vuoi usare FreeBSD su tutto il tuo disco (cancellerai tutti gli altri dati su questo disco quando confermerai in sysinstall che vuoi continuare il processo di installazione) allora premi A, che corrisponde all’opzione . Le slice esistenti saranno rimosse, e sostituite con una piccola area etichettata come unused (ancora, un artefatto della progettazione del disco del PC), e una grande slice per FreeBSD. Fatto questo, dovresti selezionare la slice di FreeBSD che hai appena creato usando i tasti freccia, e quindi premere S affinchè la slice sia avviabile. La schermata avrà un aspetto del tutto simile alla Partizionare con Fdisk Usando l’Intero Disco. Nota la A nella colonna dei Flag, che indica che la slice è active, e verrà avviata al boot.
Se vuoi cancellare una slice esistente per fare spazio a FreeBSD allora devi selezionare la slice con i tasti freccia, e quindi premere D. Quindi premi C, e ti verrà chiesto la dimensione della slice che vuoi creare. Scegli la dimensione appropriata e premi Invio. Il valore predefinito in questo riquadro rappresenta la dimensione massima che la tua slice può avere, che potrebbe essere il blocco contiguo più lungo di spazio non ancora allocato oppure l’intero disco.
Se hai già creato lo spazio per FreeBSD (magari usando un tool come PartitionMagic®) allora puoi premere C per creare una nuova slice. Di nuovo, ti verrà chiesta la dimensione della slice che vorresti creare.

Quando hai finito, premi Q. Le tue modifiche saranno salvate da sysinstall, ma non saranno ancora applicate al disco.
Ora hai due scelte per installare il boot manager. In generale, potresti installare il boot manager di FreeBSD se:
Hai più di un disco, ed hai installato FreeBSD su un disco diverso dal primo.
Hai installato FreeBSD accanto ad un altro sistema operativo sullo stesso disco, e vorresti scegliere se avviare FreeBSD o l’altro sistema operativo quando accendi il computer.
Se FreeBSD è il solo sistema operativo sulla macchina, installato sul primo hard disk, allora il boot manager sarà sufficiente. Scegli se stai usando un boot manager di terze parti capace di avviare FreeBSD.
Fai la tua scelta e premi Invio.
Per l’aiuto in linea, puoi premere F1, dove troverai informazioni sui problemi che potresti incontrare quando tenti di condividere un hard disk tra più sistemi operativi.
Se hai più di un dispositivo, ritornerai alla schermata di Selezione dei Dispositivi dopo la scelta del boot manager. Se desideri installare FreeBSD su più di un disco, a questo punto puoi selezionare un altro disco e ripetere la fase di partizionamento usando FDisk.
Se non stai installando FreeBSD sul primo dispositivo, allora il boot manager di FreeBSD deve essere installato su entrambi i dispositivi. |
Con Tab puoi saltare tra l’ultimo disco selezionato, OK, e Cancel.
Premi Tab una volta per selezionare OK, quindi premi Invio per continuare l’installazione.
Ora devi creare alcune partizioni all’interno di ogni slice che hai appena creato. Ricorda che ogni partizione è etichettata da lettere, dalla a fino alla h, e le partizioni b, c, e d hanno dei significati formali ai quali dovresti attenerti.
Certe applicazioni possono trarre beneficio da alcuni schemi di partizioni particolari, soprattutto se le puoi collocare su più dischi. Comunque, per la tua prima installazione di FreeBSD, non hai bisogno di dare troppo peso a come partizionare il disco. È più importante che installi FreeBSD ed impari ad usarlo. Puoi sempre reinstallare FreeBSD per cambiare il tuo schema delle partizioni quando avrai più familiarità con il sistema operativo.
Questo schema caratterizza quattro partizioni -una per lo swap, e le altre tre per i filesystem.
| Partizione | filesystem | Dimensione | Descrizione |
|---|---|---|---|
| / | 100 MB | Questo è il filesystem root. Ogni altro filesystem sarà montato da qualche parte sotto di esso. 100 MB è una dimensione ragionevole per questo filesystem. Non memorizzerai troppi dati su di esso, per un’installazione regolare di FreeBSD ci saranno circa 40 MB di dati. Lo spazio rimanente è per i dati temporanei, e lascia anche una spazio di scorta nel caso in cui le versioni future di FreeBSD dovessero richiedere più spazio in /. |
| N/A | 2-3 x RAM | Lo spazio di swap del sistema è su questa partizione. Scegliere la giusta quantità di swap può non essere così semplice. Una buona regola è che il tuo spazio di swap dovrebbe essere due o tre volte maggiore della tua memoria fisica (RAM). Dovresti avere almeno 64 MB di swap, quindi se nel tuo computer hai meno di 32 MB di RAM allora setta lo swap a 64 MB. Se hai più di un disco puoi mettere lo spazio swap su ogni disco. FreeBSD userà ogni disco per lo swap, velocizzando le azioni di swapping. In questo caso, calcola l’ammontare totale di swap di cui necessiti (per esempio, 128 MB), e quindi dividi questo numero per il numero di dischi che hai (per esempio, due dischi) per ottenere l’ammontare di spazio che dovresti settare su ogni disco, in questo esempio, 64 MB di swap per ogni disco. |
| /var | 50 MB | La directory /var contiene dei file che variano costantemente; i file di log, e gli altri file di amministrazione. Molti di questi file sono letti o scritti frequentemente durante l’esecuzione giornaliera di FreeBSD. Mettere questi file su un altro filesystem consente a FreeBSD di ottimizzare l’accesso a questi file senza coinvolgere altri file in altre directory che non hanno lo stesso tipo di accesso. |
| /usr | Il Resto del disco | Tutti gli altri file saranno tipicamente memorizzati in /usr e sotto le sue sotto directory. |
Se installi FreeBSD su più dischi devi creare anche delle partizioni nelle altre slice che configuri. La maniera più facile di fare questo è creare due partizioni su ogni disco, una per lo spazio di swap, ed una per il filesystem.
| Partizione | Filesystem | Dimensione | Descrizione |
|---|---|---|---|
| N/A | Guarda la descrizione | Come già discusso, puoi dividere lo swap su ogni disco. Anche se la partizione |
| /diskn | Il resto del disco | Il resto del disco è messo in una grande partizione. Questo potrebbe essere facilmente messo sulla partizione |
Avendo scelto il tuo schema di partizionamento lo puoi creare con sysinstall. Vedrai questo messaggio:
Message
Now, you need to create BSD partitions inside of the fdisk
partition(s) just created. If you have a reasonable amount of disk
space (200MB or more) and don't have any special requirements, simply
use the (A)uto command to allocate space automatically. If you have
more specific needs or just don't care for the layout chosen by
(A)uto, press F1 for more information on manual layout.
[ OK ]
[ Press enter or space ]Premi Invio per avviare l’editor delle partizioni di FreeBSD, chiamato Disklabel.
La Editor di Disklabel in Sysinstall mostra la schermata quando avvii Disklabel. Il display è diviso in tre sezioni.
Le prime linee mostrano il nome del disco sul quale stai lavorando attualmente, e la slice che contiene le partizioni che stai creando (a questo punto Disklabel usa il termine Nome della Partizione piuttosto che nome della slice). Questa schermata mostra anche la quantità di spazio libero nella slice; cioè lo spazio che è stato allocato per la slice, anche se ancora non è stato assegnato ad una partizione.
Al centro della schermata sono mostrate le partizioni che sono state create, il nome del filesystem che ogni partizione contiene, la loro dimensione, ed alcune opzioni attinenti alla creazione del filesystem.
La parte bassa dello schermo mostra le combinazioni di tasti valide in Disklabel.
Disklabel può creare automaticamente le partizioni ed assegnare loro una dimensione di default. Prova questa funzione premendo A. Vedrai una schermata simile a quella mostrata in L’Editor Disklabel di Sysinstall con i Valori di Default. A seconda della dimensione del disco che stai usando, i valori di default potrebbero essere differenti. Questo non è fatale, poichè puoi anche non accettare i valori di default .
Il partizionamento di default predispone alla directory /tmp una propria partizione al posto di essere inclusa nella partizione /. Questo evita il possibile riempimento della partizione / con i file temporanei. |
Se scegli di non usare le partizioni di default e desideri sostituirle con quelle che vuoi tu, usa i tasti freccia per selezionare la prima partizione, e premi D per cancellarla. Ripeti questa operazione per cancellare tutte le partizioni che ritieni opportune.
Per creare la prima partizione (a, montata come / - root), assicurati che sia selezionata in cima allo schermo la slice corretta e premi C. Apparirà una finestra di dialogo per inserire la dimensione della nuova partizione (come mostrato nella Spazio per la Partizione Root). Puoi immettere la dimensione come il numero di blocchi del disco che vuoi usare, o come un numero seguito da M per megabyte, da G per gigabyte, da C per cilindri.
A partire da FreeBSD 5.X, gli utenti possono: selezionare UFS2 (che è di default per FreeBSD 5.1 e superiori) usando l’opzione |
La grandezza di default mostrata creerà una partizione che prende il resto della slice. Se stai usando le dimensioni di partizioni usate nell’esempio precedente, allora cancella la figura esistente usando Backspace, e poi digita 64M, come è mostrato in Modifica della Dimensione della Partizione di Root. Poi premi OK.
Dopo aver scelto la dimensione della partizione ti verrà chiesto se la partizione conterrà una filesystem o uno spazio di swap. La finestra di dialogo è mostrata nella Scelta del Tipo della Partizione Root. La prima partizione conterrà un filesystem, quindi assicurati che sia selezionato e premi Invio.
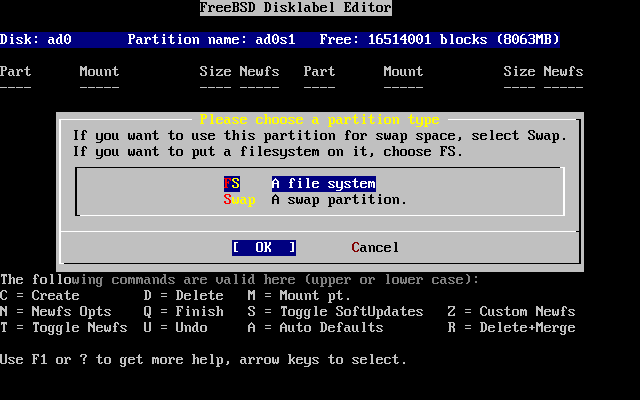
Alla fine, poichè stai creando un filesystem, devi dire a Disklabel dove sarà montato il filesystem. La finestra di dialogo è mostrata nella Scelta del Punto di Mount della Root. Il punto di mount del filesystem root è /, dunque digita /, e poi premi Invio.
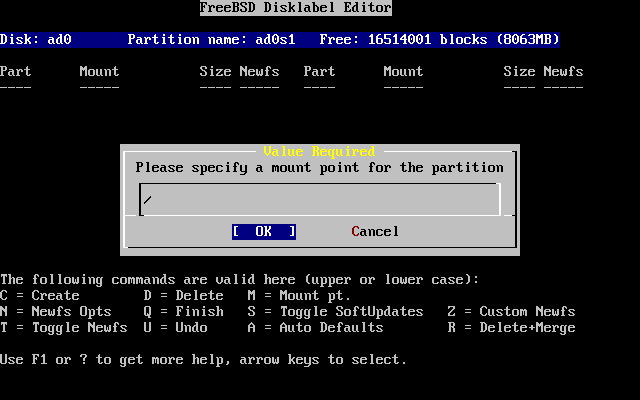
Lo schermo sarà aggiornato e ti mostrerà la partizione appena creata. Devi ripete questa procedura per le altre partizioni. Quando crei la partizione di swap, non ti verrà richiesto di inserire il punto di mount del filesystem, poichè le partizioni di swap non sono mai montate. Quando crei l’ultima partizione, /usr, puoi lasciare la dimensione suggerita, per usare il rimanente spazio della slice.
La schermata finale dell’Editor DiskLabel di FreeBSD sarà simile alla L’Editor Disklabel di Sysinstall, sebbene i valori scelti potrebbero essere differenti. Premi Q per finire.
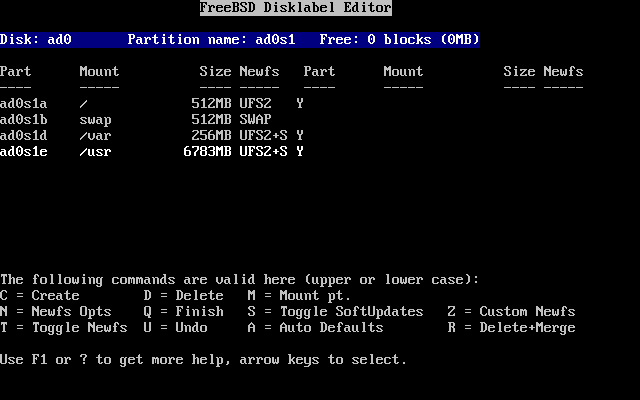
Scegliere quale tipo di distribuzione installare dipenderà in maggior parte dall’uso del sistema e di quanto spazio hai disponibile. Le opzioni predefinite spaziano da installare la configurazione più leggera possibile fino ad arrivare ad installare ogni cosa. Quelli che sono nuovi di UNIX® e/o di FreeBSD dovrebbero quasi certamente selezionare una di queste opzioni inscatolate. La personalizzazione di un tipo di distribuzione è roba da utenti un pò più esperti.
Premi F1 per avere più informazioni sulle opzioni del tipo di distribuzione e ciò che contengono. Quando hai finito con l’help, premendo Invio ritornerai al Menu di Selezione della Distribuzione.
Se desideri un’interfaccia grafica allora dovresti scegliere un tipo di distribuzione preceduto da una X. La configurazione del server X e la selezione di un desktop di default deve essere fatta dopo l’installazione di FreeBSD. Maggiori informazioni riguardo la configurazione di un server X possono essere trovate nel L’X Window System.
La versione di default di X11 che viene installata dipende dalla versione di FreeBSD che stai installando. Per le versioni di FreeBSD precedenti alla 5.3, viene installato XFree86™ 4.X. Per FreeBSD 5.3 e successive, viene installato di default Xorg.
Se pensi di compilare un kernel custom, seleziona un’opzione che include il codice sorgente. Per altre informazioni sul perchè dovrebbe essere costruito un kernel custom o su come costruirlo, guarda il Configurazione del Kernel di FreeBSD.
Ovviamente, il sistema più versatile è quello che include tutto. Se c’è abbastanza spazio su disco, seleziona come mostrato nella Scegliere le Distribuzioni usando i tasti freccia e premi Invio. Se hai qualche preoccupazione per lo spazio di disco usa un’opzione che ti è più conveniente per la tua situazione. Non cercare la scelta perfetta, poichè potrai aggiungere altre distribuzioni anche dopo l’installazione.
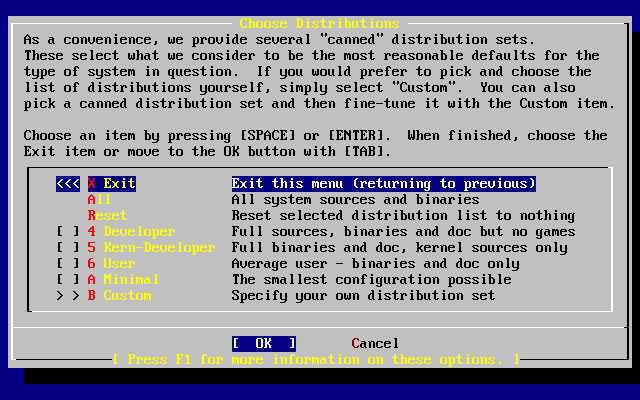
Dopo aver selezionato la distribuzione desiderata, ti viene data l’opportunità di installare la FreeBSD Port Collection. La collezione dei port è un modo semplice e conveniente di installare software. La collezione dei port non contiene il codice sorgente necessario per compilare il software. Invece, è una collezione di file che automatizza il download, la compilazione e l’installazione delle applicazioni di terze-parti. Il Installazione delle Applicazioni. Port e Package, discute su come usare la collezione dei port.
Il programma di installazione non verifica se hai lo spazio adeguato. Scegli questa opzione soltanto se hai uno spazio sul disco rigido sufficiente. Per FreeBSD 12.0, la FreeBSD Ports Collection occupa circa 3 GB di spazio su disco. Puoi assumere un valore più grande per le versioni di FreeBSD più recenti.
User Confirmation Requested
Would you like to install the FreeBSD ports collection?
This will give you ready access to over 24,000 ported software packages,
at a cost of around 500 MB of disk space when "clean" and possibly much
more than that if a lot of the distribution tarballs are loaded
(unless you have the extra CDs from a FreeBSD CD/DVD distribution
available and can mount it on /cdrom, in which case this is far less
of a problem).
The ports collection is a very valuable resource and well worth having
on your /usr partition, so it is advisable to say Yes to this option.
For more information on the ports collection & the latest ports,
visit:
http://www.FreeBSD.org/ports
[ Yes ] NoSeleziona yes con i tasti freccia per installare la collezione dei port, oppure no per saltare questa opzione. Premi Invio per continuare. Verrà visualizzato il menu della scelta della distribuzione.
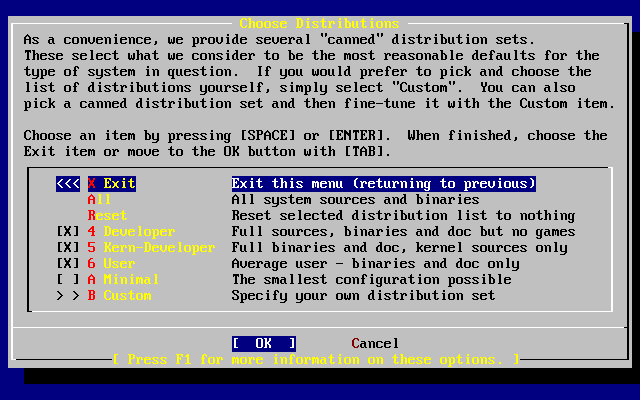
Se sei soddisfatto delle opzioni, seleziona con i tasti freccia, assicurati che OK sia selezionato, quindi premi Invio per continuare.
Se vuoi installare da CDROM o da DVD, usa i tasti freccia per evidenziare . Assicurati che OK sia evidenziato, e poi premi Invio per procedere con l’installazione.
Per gli altri metodi di installazione, scegli l’opzione appropriata e segui le istruzioni.
Premi F1 per visualizzare l’help in linea sui media di installazione. Premi Invio per tornare al menù di selezione dei media.
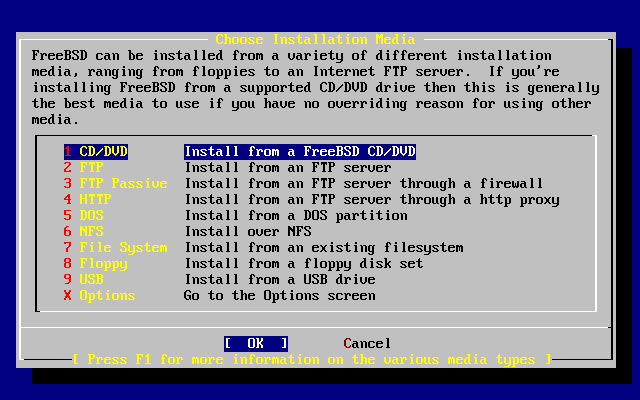
Modi di Installazione via FTP Ci sono tre modi di installazione via FTP che puoi scegliere: FTP attivo, FTP passivo, o via un proxy HTTP.
Per un proxy FTP server, dovresti di solito dare il nome del server che realmente vuoi come parte del nome utente, seguito dal carattere "@". Il server proxy quindi "raggira" il server reale. Per esempio, assumiamo che vuoi installare da In questo caso, vai alle opzioni del menù, setta il nome utente FTP come Poichè /pub/FreeBSD da |
Se lo desideri l’installazione può ora procedere. Questa è anche l’ultima opportunità per interrompere l’installazione per impedire cambiamenti al disco.
User Confirmation Requested
Last Chance! Are you SURE you want to continue the installation?
If you're running this on a disk with data you wish to save then WE
STRONGLY ENCOURAGE YOU TO MAKE PROPER BACKUPS before proceeding!
We can take no responsibility for lost disk contents!
[ Yes ] NoSeleziona yes e premi Invio per procedere.
Il tempo di installazione varierà a seconda della distribuzione che hai scelto, dei media di installazione, e della velocità del computer. Verranno visualizzati una serie di messaggi indicanti lo stato.
L’installazione è completa quando viene visualizzato il seguente messaggio:
Message
Congratulations! You now have FreeBSD installed on your system.
We will now move on to the final configuration questions.
For any option you do not wish to configure, simply select No.
If you wish to re-enter this utility after the system is up, you may
do so by typing: /stand/sysinstall .
[ OK ]
[ Press enter to continue ]Premi Invio per procedere con la configurazione post-installazione.
Seleziona no e premi Invio per interrompere l’installazione in modo tale che nessuna modifica venga effettuata sul tuo sistema. Apparirà il seguente messaggio
Message
Installation complete with some errors. You may wish to scroll
through the debugging messages on VTY1 with the scroll-lock feature.
You can also choose "No" at the next prompt and go back into the
installation menus to retry whichever operations have failed.
[ OK ]Questo messaggio viene visualizzato quando non installi nulla. Premi Invio per ritornare al menù di installazione principale per uscire dall’installazione.
Dopo una corretta installazione segue la configurazione di varie opzioni. Un’opzione può essere configurata rientrando nelle opzioni di configurazione prima dell’avvio del nuovo sistema FreeBSD o dopo l’installazione usando sysinstall (/stand/sysinstall nelle versioni di FreeBSD prima della 5.2) e selezionando .
Se hai configurato precedentemente PPP per l’installazione FTP, questa schermata non sarà visualizzata ora ma puoi configurarlo più avanti come descritto sotto.
Per informazioni dettagliate riguardo alla LAN e alla configurazione di FreeBSD come gateway/router fai riferimento al capitolo Networking Avanzato.
User Confirmation Requested
Would you like to configure any Ethernet or SLIP/PPP network devices?
[ Yes ] NoPer configurare un dispositivo di rete, seleziona yes e premi Invio. Altrimenti, seleziona no per continuare.
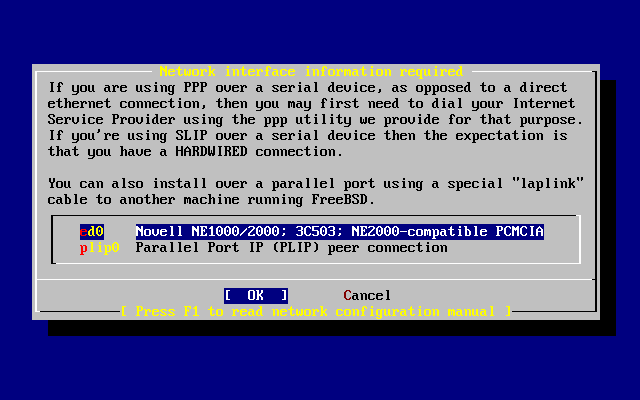
Seleziona con i tasti freccia l’interfaccia che deve essere configurata e premi Invio.
User Confirmation Requested
Do you want to try IPv6 configuration of the interface?
Yes [ No ]In questa LAN privata, il corrente protocollo di Internet (IPv4) era già sufficiente e è stato selezionato no con i tasti freccia ed è stato premuto Invio.
Se sei connesso ad una rete IPv6 già esistente con un server RA, puoi selezionare yes e premere Invio. Lo scan dei server RA impiegherà un pò di secondi.
User Confirmation Requested
Do you want to try DHCP configuration of the interface?
Yes [ No ]Se il DHCP (Dynamic Host Configuration Protocol) non è usato seleziona no con i tasti freccia e premi Invio.
Selezionando yes si avvierà dhclient, e se tutto va bene, setterà in automatico le informazioni sulla configurazione della rete. Fai riferimento alla Configurazione Automatica della Rete (DHCP), per altre informazioni.
La seguente schermata di configurazione della rete mostra la configurazione di un dispositivo Ethernet per un sistema che funzionerà da gateway per una LAN.
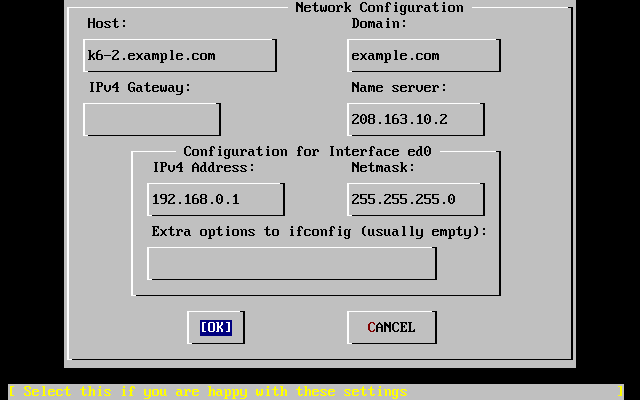
Usa il Tab per selezionare i campi e riempili con le giuste informazioni:
Il nome host assoluto, come k6-2.example.com in questo caso.
Il nome del dominio nel quale si trova la tua macchina, come example.com in questo caso.
L’indirizzo IP dell’host che inoltra i pacchetti verso destinazioni non locali. Devi settarlo se la tua macchina è un nodo di una rete. Lascia questo campo vuoto se la macchina è il gateway di Internet per la rete. Il gateway IPv4 è anche conosciuto come il gateway di default o l’instradamento di default.
L’indirizzo IP del tuo server DNS locale. Su questa lan privata non c’è un server DNS locale quindi è stato usato l’indirizzo IP del server DNS del provider (208.163.10.2).
L’indirizzo IP in uso su questa interfaccia è 192.168.0.1
Il blocco di indirizzi in uso per questa lan è un blocco di classe C (192.168.0.0 - 192.168.255.255). La netmask di default per una rete di classe C è (255.255.255.0).
Altre opzioni di ifconfig per l’interfaccia di rete che potresti voler aggiungere. In questo caso nessuna.
Usa il Tab per selezionare OK quando hai finito e poi premi Invio.
User Confirmation Requested
Would you like to Bring Up the ed0 interface right now?
[ Yes ] NoSelezionando yes e premendo Invio si porterà la macchina all’interno della rete pronta per l’uso. Comunque, questo non è fondamentale durante l’installazione, poichè la macchina deve essere riavviata.
User Confirmation Requested
Do you want this machine to function as a network gateway?
[ Yes ] NoSe la macchina dovrà essere utilizzata come gateway per una LAN inoltrando pacchetti tra altre macchine allora seleziona yes e premi Invio. Se la macchina è un nodo di una rete allora seleziona no e premi Invio per continuare.
User Confirmation Requested
Do you want to configure inetd and the network services that it provides?
Yes [ No ]Se selezioni no, diversi servizi tipo telnetd non saranno avviati. Questo significa che gli utenti remoti non saranno in grado di fare una sessione telnet su questa macchina. Gli utenti locali saranno tuttavia in grado di accedere alla macchina con telnet.
Questi servizi possono essere avviati dopo l’installazione editando /etc/inetd.conf con l’editor di testo che preferisci. Leggi la Uno sguardo d’insieme per più informazioni.
Seleziona yes se desideri configurare questi servizi durante l’installazione. Ti verrà proposta un’ulteriore conferma:
User Confirmation Requested
The Internet Super Server (inetd) allows a number of simple Internet
services to be enabled, including finger, ftp and telnetd. Enabling
these services may increase risk of security problems by increasing
the exposure of your system.
With this in mind, do you wish to enable inetd?
[ Yes ] NoSeleziona yes per continuare.
User Confirmation Requested
inetd(8) relies on its configuration file, /etc/inetd.conf, to determine
which of its Internet services will be available. The default FreeBSD
inetd.conf(5) leaves all services disabled by default, so they must be
specifically enabled in the configuration file before they will
function, even once inetd(8) is enabled. Note that services for
IPv6 must be separately enabled from IPv4 services.
Select [Yes] now to invoke an editor on /etc/inetd.conf, or [No] to
use the current settings.
[ Yes ] NoScegliendo yes ti sarà consentito aggiungere servizi eliminando # all’inizio delle relative linee.
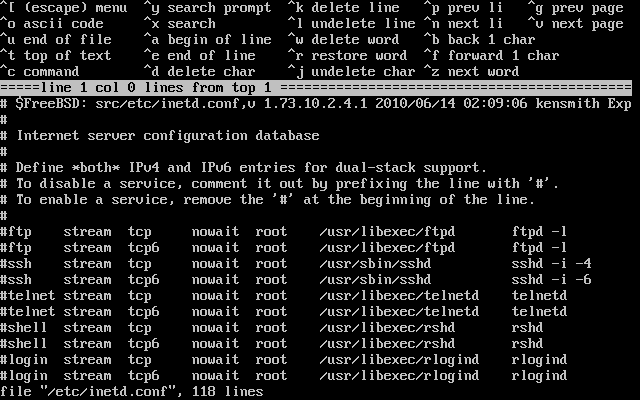
Dopo che hai aggiunto i servizi desiderati, premendo Esc ti verrà mostrato un menù che ti consente di uscire salvando i cambiamenti che hai apportato.
User Confirmation Requested
Do you want to have anonymous FTP access to this machine?
Yes [ No ]Selezionando no e premendo Invio consentirai a chi ha un account con password di usare l’FTP per accedere alla macchina.
Chiunque può accedere alla tua macchina se permetti connessioni FTP anonime. Dovrebbero essere considerate alcune implicazioni di sicurezza prima di abilitare questa opzione. Per altre informazioni sulla sicurezza guarda il Sicurezza.
Per consentire l’FTP anonimo, usa i tasti freccia e seleziona yes e premi Invio. Ti verrà visualizzato il seguente messaggio:

Premendo F1 visualizzerai l’help in linea:
This screen allows you to configure the anonymous FTP user.
The following configuration values are editable:
UID: The user ID you wish to assign to the anonymous FTP user.
All files uploaded will be owned by this ID.
Group: Which group you wish the anonymous FTP user to be in.
Comment: String describing this user in /etc/passwd
FTP Root Directory:
Where files available for anonymous FTP will be kept.
Upload subdirectory:
Where files uploaded by anonymous FTP users will go.Di default la directory root dell’ftp sarà /var. Se prevedi che lo spazio FTP non sia sufficiente, potresti usare la directory /usr settando la directory root dell’FTP a /usr/ftp.
Quando sei soddisfatto delle modifiche, premi Invio per continuare.
User Confirmation Requested
Create a welcome message file for anonymous FTP users?
[ Yes ] NoSe selezioni yes e premi Invio, verrà avviato un editor che ti permetterà di modificare il messaggio di benvenuto.
L’editor è ee. Usa le istruzioni per cambiare il messaggio oppure cambia il messaggio più tardi usando un editor di testo a tua scelta. Nota il nome/locazione del file in fondo alla schermata dell’editor.
Premendo Esc un menù pop-up ti sceglierà di default . Premi Invio per uscire e continuare. Premi di nuovo Invio per salvare gli eventuali cambiamenti.
NFS (Network File System) consente la condivisione di file attraverso una rete. Una macchina può essere configurata come server, client, o entrambi. Fai riferimento alla Network File System (NFS) per altre informazioni.
User Confirmation Requested
Do you want to configure this machine as an NFS server?
Yes [ No ]Se non c’è bisogno di un server NFS, seleziona no e premi Invio.
Se scegli yes, ti apparirà un messaggio che dice che il file exports deve essere creato.
Message
Operating as an NFS server means that you must first configure an
/etc/exports file to indicate which hosts are allowed certain kinds of
access to your local filesystems.
Press [Enter] now to invoke an editor on /etc/exports
[ OK ]Premi Invio per continuare. Verrà avviato un editor di testo al fine di creare ed editare il file exports.
Usa le istruzione per aggiungere i filesystem che desideri esportare oppure fallo dopo l’installazione con il tuo editor preferito. Nota il nome/locazione del file in fondo alla schermata dell’editor.
Premi Invio e ti verrà mostrato un menù con selezionato . Premi Invio per uscire e continuare.
Un "profilo della sicurezza" è un insieme di opzioni di configurazione che tentano di raggiungere il desiderato rapporto sicurezza/convenienza abilitando o disabilitando certi programmi e settaggi. Con il profilo di sicurezza più severo, pochi programmi saranno abilitati di default. Questo è uno dei principi basi per la sicurezza: non mandare in esecuzione nulla se non quello che usi.
Per cortesia nota che il profilo di sicurezza è giusto una configurazione di default. Tutti i programmi possono essere abilitati o disabilitati dopo che hai installato FreeBSD modificando o aggiungendo le appropriate linee in /etc/rc.conf. Per altre informazioni, consulta la magina man rc.conf(5).
La seguente tabella descrive la configurazione di ogni profilo di sicurezza. Le colonne sono i profili di sicurezza che puoi scegliere, e le righe sono i programmi o le caratteristiche che il rispettivo profilo abilita o disabilita.
| Extreme | Moderate | |
|---|---|---|
NO | SI | |
NO | SI | |
NO | FORSE (Il portmapper è abilitato se la macchina è stata configurata in precedenza come un client o server NFS.) | |
NFS server | NO | SI |
YES (Se hai scelto un profilo di sicurezza che regola il securelevel a "Extreme" o "High", devi essere consapevole delle implicazioni. Per favore leggi prima la pagina man init(8) e poni particolare attenzione al significato dei livelli di sicurezza, o potresti incontrare grossi problemi in seguito!) | NO |
User Confirmation Requested
Do you want to select a default security profile for this host (select
No for "medium" security)?
[ Yes ] NoSelezionando no e premendo Invio setterai il profilo di sicurezza su medio.
Selezionando yes e premendo Invio ti sarà consentito selezionare un diverso profilo di sicurezza.
Premi F1 per visualizzare l’help in linea. Premi Invio per ritornare al menù di selezione.
Usa i tasti freccia per scegliere a meno di essere sicuro che necessiti di un altro livello di sicurezza. Con OK selezionato, premi Invio.
Verrà visualizzato un messaggio di conferma a seconda del settaggio di sicurezza che hai scelto.
Message
Moderate security settings have been selected.
Sendmail and SSHd have been enabled, securelevels are
disabled, and NFS server setting have been left intact.
PLEASE NOTE that this still does not save you from having
to properly secure your system in other ways or exercise
due diligence in your administration, this simply picks
a standard set of out-of-box defaults to start with.
To change any of these settings later, edit /etc/rc.conf
[OK] Message
Extreme security settings have been selected.
Sendmail, SSHd, and NFS services have been disabled, and
securelevels have been enabled.
PLEASE NOTE that this still does not save you from having
to properly secure your system in other ways or exercise
due diligence in your administration, this simply picks
a more secure set of out-of-box defaults to start with.
To change any of these settings later, edit /etc/rc.conf
[OK]Premi Invio per continuare con la post-installazione.
Il profilo di sicurezza non è una soluzione miracolosa! Anche se usi il settaggio estremo, devi stare al passo con i problemi di sicurezza leggendo la mailing lista appropriata (Mailing Lists), usando ottime password e frasi-password, e attenendosi alle comuni prassi di sicurezza. Qui semplicemente setti il desiderato rapporto sicurezza/convenienza della macchina. |
Ci sono parecchie opzioni disponibili per personalizzare la console di sistema.
User Confirmation Requested
Would you like to customize your system console settings?
[ Yes ] NoPer vedere e configurare le opzioni, seleziona yes e premi Invio.
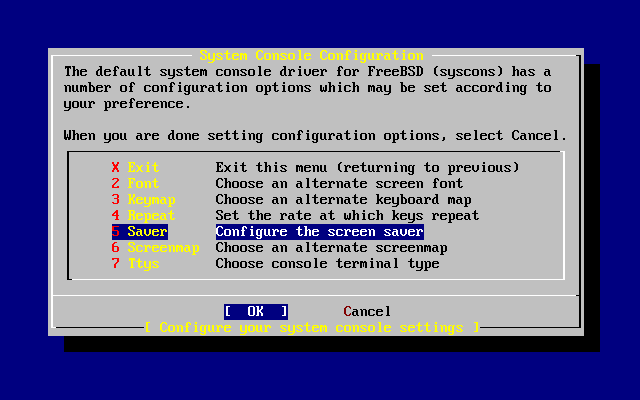
Un’opzione comunemente usata è lo screen saver. Usa i tasti freccia per selezionare e premi Invio.
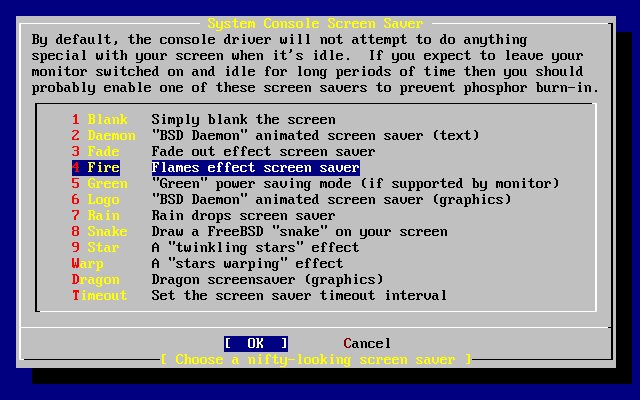
Scegli lo screen saver che desideri usando i tasti freccia e quindi premi Invio. Verrà mostrato il menù di Configurazione della Console di Sistema.
Il tempo di inattesa di default è di 300 secondi. Per modificare l’intervallo di tempo, seleziona di nuovo. Nel menù delle opzioni dello Screen Saver, seleziona usando i tasti freccia e premi Invio. Verrà mostrato un menù:
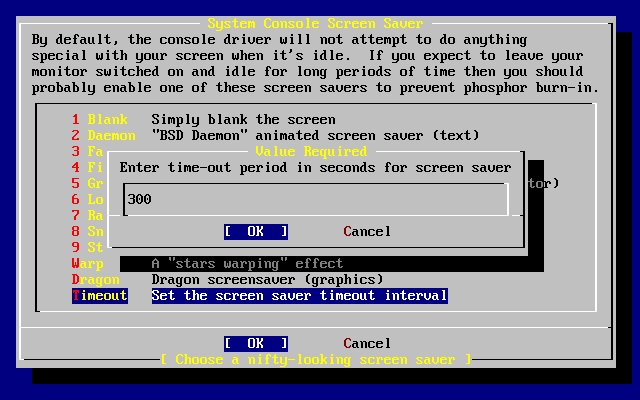
Puoi cambiare il valore, quindi seleziona OK e premi Invio per ritornare al menù di Configurazione della Console di Sistema.
Selezionando e premendo Invio continuerai con le configurazioni post-installazione.
Il settaggio della zona di fuso orario per la tua macchina ti consentirà di correggere automaticamente i cambiamenti di tempo regionali e di realizzare altre funzioni relative al fuso orario.
L’esempio mostrato è per una macchina situata nella zona di fuso orario orientale degli stati Uniti. La tua selezione dipenderà dalla tua locazione geografica.
User Confirmation Requested
Would you like to set this machine's time zone now?
[ Yes ] NoSeleziona yes e premi Invio per settare la zona di fuso orario.
User Confirmation Requested
Is this machine's CMOS clock set to UTC? If it is set to local time
or you don't know, please choose NO here!
Yes [ No ]Seleziona yes o no a seconda di come è configurato l’orologio della macchina e poi premi Invio.
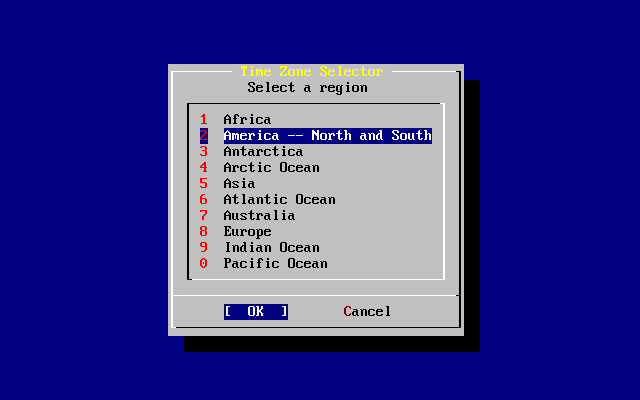
La regione appropriata viene selezionata usando i tasti freccia e quindi premendo Invio.
Scegli la nazione appropriata usando i tasti freccia e premi Invio.
La zona di fuso orario appropriata viene selezionata usando i tasti freccia e premendo Invio.
Confirmation
Does the abbreviation 'EDT' look reasonable?
[ Yes ] NoViene richiesta una conferma per l’abbreviazione per la zona di fuso orario. Se va bene, premi Invio per continuare con la configurazione post-installazione.
User Confirmation Requested
Would you like to enable Linux binary compatibility?
[ Yes ] NoSelezionando yes e premendo Invio, potrai eseguire applicazioni Linux su FreeBSD. Verranno installati i package per la compatibilità Linux.
Se stai facendo l’installazione via FTP, la macchina necessiterà di collegarsi a Internet. A volte il sito remoto non ha tutte le distribuzioni così come la compatibilità Linux binaria. Puoi sempre installarlo più tardi.
Questa opzione ti consentirà di tagliare ed incollare il testo nella console e nei programmi utenti con un mouse a 3 pulsanti. Se usi un mouse a 2 pulsanti, fai riferimento alla pagina man, moused(8), dopo l’installazione per i dettagli sull’emulazione del terzo pulsante. Questo esempio descrive una configurazione di un mouse non USB (come un mouse PS/2 o via porta COM):
User Confirmation Requested
Does this system have a non-USB mouse attached to it?
[ Yes ] NoSeleziona yes per un mouse non-USB o no per un mouse USB e poi premi Invio.
Usa i tasti freccia per selezionare e premi Invio.
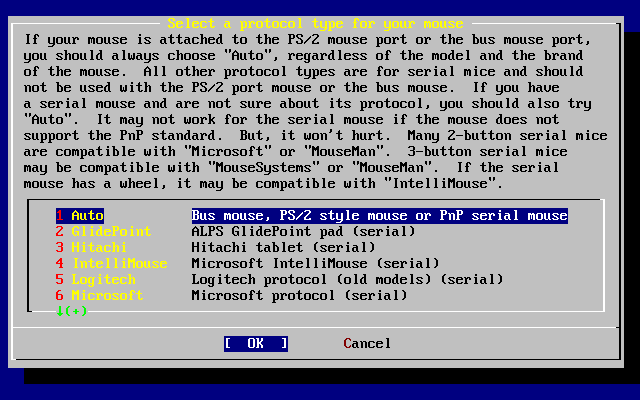
Il mouse usato in questo esempio è di tipo PS/2, quindi l’opzione di default era appropriata. Per cambiare il protocollo, usa i tasti freccia e seleziona un’altra opzione. Assicurati che OK sia selezionato e premi Invio per uscire da questo menù.
Usa i tasti freccia per selezionare e premi Invio.
Questo sistema aveva un mouse PS/2, dunque l’opzione di default andava bene. Per cambiare la porta, usa i tasti freccia e premi Invio.
Per ultimo, usa i tasti freccia per selezionare , e premi Invio per abilitare e testare il demone del mouse.
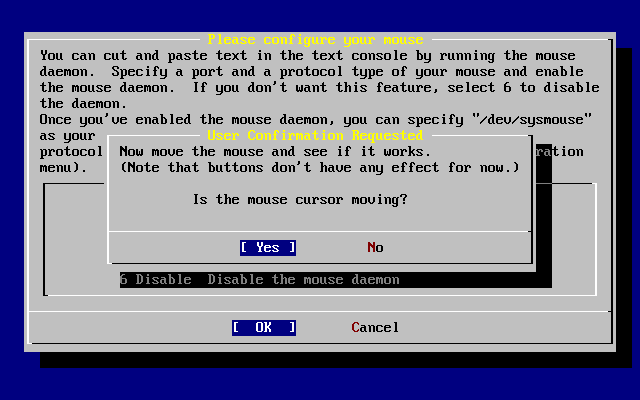
Muovi il cursore sullo schermo e verifica che il cursore risponda in modo appropriato. Se lo fa, seleziona yes e premi Invio. Se non lo fa, allora il mouse non è stato configurato correttamente - seleziona no e prova ad usare delle differenti opzioni di configurazione.
Seleziona con i tasti freccia e premi Invio per continuare con la configurazione di post-installazione.
La configurazione dei servizi di rete può spaventare i nuovi utenti se questi non hanno alle spalle una conoscenza in quest’area. La rete, Internet incluso, è cruciale per tutti i moderni sistemi operativi FreeBSD incluso; detto ciò, è del tutto utile conoscere le grandi capacità di rete di FreeBSD. Fare questo durante l’installazione permetterà agli utenti di avere alcune conoscenze dei vari servizi che sono disponibili.
I servizi di rete sono programmi che accettano input da qualunque posto sulla rete. Sono stati fatti molti sforzi per assicurare che questi programmi non fanno nulla di "dannoso". Sfortunatamente, i programmatori non sono perfetti e in passato ci sono stati casi dove alcuni bug nei servizi di rete sono stati sfruttati da aggressori per fare cose maligne. È importante che abiliti sono i servizi di rete che sai di aver bisogno. Se sei nel dubbio è meglio non abilitare un servizio di rete fino a quando scopri di averlo bisogno. Lo puoi sempre abilitare successivamente ri-avviando sysinstall o usando le funzionalità fornite dal file /etc/rc.conf.
Selezionando l’opzione Networking verrà visualizzato un menù simile a questo:
La prima opzione, , è stata trattata precedentemente durante la Configurazione del Dispositivo di Rete, e quindi questa opzione può essere tranquillamente ignorata.
Selezionando l’opzione verrà aggiunto il supporto per l’utility di mount automatica di BSD. Di solito questo viene usato in combinazione con il protocollo NFS (vedi sotto) per montare automaticamente i filesystem remoti. Non è richiesta alcuna configurazione speciale.
La linea successiva è l’opzione . Quando selezionata, viene visualizzato un menù per settare delle flag specifiche di AMD. Il menù contiene già una serie di opzioni di default:
-a /.amd_mnt -l syslog /host /etc/amd.map /net /etc/amd.mapL’opzione -a setta la locazione di mount di default che è qui specificata come /.amd_mnt. L’opzione -l specifica il file di log; di default; comunque, quando viene usato syslogd tutte le attività di log saranno inviate al demone di log del sistema. La directory /host è usata per montare un filesystem esportato da un host remoto, mentre la directory /net è usata per montare un filesystem esportato da un indirizzo IP. Il file /etc/amd.map definisce le opzioni di default per le esportazioni AMD.
L’opzione permette connessioni FTP anonime. Seleziona questa opzione per rendere questa macchina un server FTP anonimo. Sii consapevole dei rischi di sicurezza che questa opzione comporta. Verrà visualizzato un altro menù nel quale vengono spiegati più nel dettaglio i rischi di sicurezza e la configurazione.
Il menù di configurazione configurerà la macchina per essere un gateway come spiegato in precedenza. Lo puoi usare per deselezionare l’opzione se l’hai selezionata sbadatamente nel processo di installazione.
L’opzione può essere usata per configurare o disabilitare completamente il demone inetd(8) come discusso sopra.
L’opzione è usata per configurare l’MTA (Mail Transfer Agent) di default per il sistema. Selezionando questa opzione apparirà il seguente menù:
Ti viene data una scelta per quale MTA di default installare e configurare. Un MTA non è altro che un server di posta che consegna email agli utenti sul sistema o via Internet.
Selezionando verrà installato il famoso server sendmail, di default per FreeBSD. L’opzione imposterà sendmail per essere l’MTA di default, ma disabilita la sua funzionalità di ricevere email in ingresso provenienti da Internet. Le alternative, e si comportano in modo simile a . Sono entrambi distributori di email; ad ogni modo, alcuni utenti preferiscono queste alternative all’MTAsendmail.
Dopo aver scelto o meno un MTA, apparirà il menù di configurazione della rete con la prossima opzione .
L’opzione configurerà il sistema per comunicare con un server tramite NFS. Un server NFS rende i filesystem disponibili a altre macchine sulla rete tramite il protocollo NFS. Se questa è una macchina a se stante, questa opzione può non essere selezionata. Il sistema può richiedere un’ulteriore configurazione in seguito; consulta la Network File System (NFS) per maggiori informazioni sulla configurazione riguardo client e server.
Sotto all’opzione precedente c’è l’opzione , che ti permette di configurare il sistema come un server NFS. Questo aggiunge le informazioni richieste per avviare RPC, servizi di chiamata a procedura remota. RPC è usato per coordinare le connessioni tra host e i programmi.
La prossima linea è l’opzione , che tratta la sincronizzazione del tempo. Quando selezionato, viene mostrato un menù come questo:
Da questo menù, seleziona il server più vicino alla tua posizione. Selezionando il più vicino renderai la sincronizzazione del tempo più accurata poichè un server lontano dalla tua posizione potrebbe avere una latenza di connessione maggiore.
La prossima opzione è PCNFSD. Questa opzione installerà il package net/pcnfsd dalla collezione dei port. Questa è un’utilità che fornisce servizi di autenticazione NFS per i sistemi che sono incapaci di fornirne dei propri, come il sistema operativo MS-DOS® della Microsoft.
Adesso scorri in giù per vedere le altre opzioni:
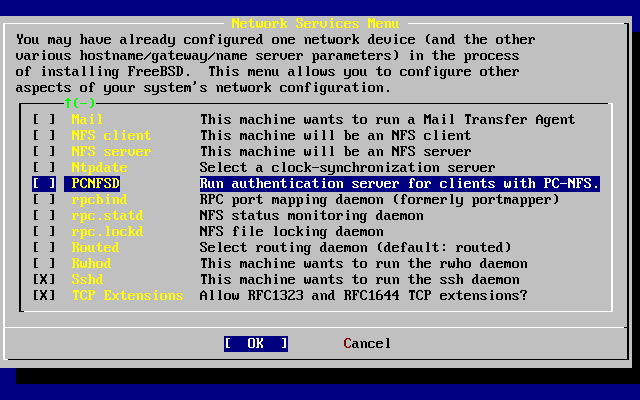
Le utility rpcbind(8), rpc.statd(8), e rpc.lockd(8) sono tutte usate per RPC (Chiamate a Procedura Remote). L’utility rpcbind gestisce la comunicazione con server e client NFS, ed è richiesta per i server NFS per operare correttamente. Il demone rpc.statd interagisce con il demone rpc.statd su altri host per fornire un controllo sullo stato. Lo stato riportato è solitamente tenuto nel file /var/db/statd.status. La prossima opzione qui elencata è l’opzione , che, quando selezionata, fornisce servizi di locking dei file. Viene solitamente usato con rpc.statd per controllare quali host stanno richiedendo lock e con quale frequenza. Mentre queste ultime due opzioni sono meravigliose per il debugging, non sono richieste per i client e server NFS per operare correttamente.
Come puoi vedere avanzando nella lista il prossimo elemento è , che è il demone di instradamento. L’utility routed(8) gestisce le tabelle di instradamento di rete, trova router multicast, e fornisce una copia della tabella di instradamento ad ogni host fisicamente connesso previa richiesta via rete. Questo è principalmente usato per le macchine che fungono da gateway per una lan. Quando selezionato, verrà visualizzato un menù che richiede la locazione di default dell’utility. La locazione di default è già definita e può essere selezionata con il tasto Invio. Poi ti sarà presentato un altro menù, questa volta per impostare le flag che desideri passare a routed. Sullo schermo dovrebbe apparire la flag di default -q.
La prossima linea è l’opzione che, quando selezionata, avvierà il demone rwhod(8) durante l’inizializzazione del sistema. L’utility rwhod invia periodicamente via rete messaggi di sistema broadcast, o in modalità "consumatore" li colleziona. Altre informazioni possono essere trovate nella pagine man ruptime(1) e rwho(1).
L’ultima opzione della lista è per il demone sshd(8). Questo è il server di shell sicuro di OpenSSH ed è altamente raccomandato al posto dei server telnet e FTP. Il server sshd è usato per creare una connessione sicura da un host ad un altro usando connessioni cifrate.
In fine c’è l’opzione . Questo abilita le estensioni TCP definite nelle RFC 1323 e RFC 1644. Mentre su molti host questo può velocizzare le connessioni, potrebbe anche causare la perdita di alcune connessioni. Non è raccomandato per server, ma può essere un beneficio per macchine a se stanti.
Ora che hai configurato i servizi di rete, puoi scorrere in alto fino all’opzione e continuare con la prossima sezione di configurazione.
A partire da FreeBSD 5.3-RELEASE, la configurazione del server X è stata rimossa da sysinstall, devi installare e configurare il server X dopo l’installazione di FreeBSD. Maggiori informazioni riguardo all’installazione e alla configurazione del server X possono essere trovate nel L’X Window System. Puoi saltare questa sezione se non stai installando una versione di FreeBSD antecedente la 5.3-RELEASE. |
Per usare un’interfaccia utente grafica come ad esempio KDE, GNOME, o altri, hai bisogno di configurare il server X.
Per far girare XFree86™ come utente non |
Per vedere se la tua scheda video è supportata, vai sul sito di XFree86™.
User Confirmation Requested
Would you like to configure your X server at this time?
[ Yes ] NoÈ necessario conoscere le specifiche del tuo monitor e alcune informazioni della scheda video. Settaggi non corretti potrebbero creare danni all’attrezzatura. Se non hai queste informazioni, seleziona no e quando hai le informazioni esegui la configurazione dopo l’installazione usando |
Se hai le informazioni della scheda grafica e del monitor, seleziona yes e premi Invio per procedere alla configurazione del server X.
Ci sono diversi modi per configurare il server X. Usa i tasti freccia per selezionarne uno e premi Invio. Assicurati di leggere tutte le istruzioni attentamente.
I metodi xf86cfg e xf86cfg -textmode potrebbero richiedere alcuni secondi all’avvio con uno schermo nero. Abbiate pazienza.
Di seguito verrà illustrato l’uso del tool di configurazione xf86config. Le scelte di configurazione che farai dipenderanno dall’hardware nel sistema e quindi le tue scelte saranno probabilmente diverse da quelle qui mostrate:
Message
You have configured and been running the mouse daemon.
Choose "/dev/sysmouse" as the mouse port and "SysMouse" or
"MouseSystems" as the mouse protocol in the X configuration utility.
[ OK ]
[ Press enter to continue ]Questo indica che è stato rilevato il demone del mouse precedentemente configurato. Premi Invio per continuare.
Avviando xf86config verrà visualizzata una breve introduzione:
This program will create a basic XF86Config file, based on menu selections you
make.
The XF86Config file usually resides in /usr/X11R6/etc/X11 or /etc/X11. A sample
XF86Config file is supplied with XFree86; it is configured for a standard
VGA card and monitor with 640x480 resolution. This program will ask for a
pathname when it is ready to write the file.
You can either take the sample XF86Config as a base and edit it for your
configuration, or let this program produce a base XF86Config file for your
configuration and fine-tune it.
Before continuing with this program, make sure you know what video card
you have, and preferably also the chipset it uses and the amount of video
memory on your video card. SuperProbe may be able to help with this.
Press enter to continue, or ctrl-c to abort.Premendo Invio comincerà la configurazione del mouse. Assicurati di seguire le istruzioni e usa "Mouse Systems" come protocollo e /dev/sysmouse come porta del mouse; l’uso di un mouse PS/2 è mostrato a titolo illustrativo.
First specify a mouse protocol type. Choose one from the following list:
1. Microsoft compatible (2-button protocol)
2. Mouse Systems (3-button protocol) & FreeBSD moused protocol
3. Bus Mouse
4. PS/2 Mouse
5. Logitech Mouse (serial, old type, Logitech protocol)
6. Logitech MouseMan (Microsoft compatible)
7. MM Series
8. MM HitTablet
9. Microsoft IntelliMouse
If you have a two-button mouse, it is most likely of type 1, and if you have
a three-button mouse, it can probably support both protocol 1 and 2. There are
two main varieties of the latter type: mice with a switch to select the
protocol, and mice that default to 1 and require a button to be held at
boot-time to select protocol 2. Some mice can be convinced to do 2 by sending
a special sequence to the serial port (see the ClearDTR/ClearRTS options).
Enter a protocol number: 2
You have selected a Mouse Systems protocol mouse. If your mouse is normally
in Microsoft-compatible mode, enabling the ClearDTR and ClearRTS options
may cause it to switch to Mouse Systems mode when the server starts.
Please answer the following question with either 'y' or 'n'.
Do you want to enable ClearDTR and ClearRTS? n
You have selected a three-button mouse protocol. It is recommended that you
do not enable Emulate3Buttons, unless the third button doesn't work.
Please answer the following question with either 'y' or 'n'.
Do you want to enable Emulate3Buttons? y
Now give the full device name that the mouse is connected to, for example
/dev/tty00. Just pressing enter will use the default, /dev/mouse.
On FreeBSD, the default is /dev/sysmouse.
Mouse device: /dev/sysmouseIl prossimo oggetto da configurare è la tastiera. Un modello generico a 101 tasti è mostrato a titolo di esempio. Si possono usare diversi nomi per le varianti o semplicemente premi Invio per accettare il valore di default.
Please select one of the following keyboard types that is the better
description of your keyboard. If nothing really matches,
choose 1 (Generic 101-key PC)
1 Generic 101-key PC
2 Generic 102-key (Intl) PC
3 Generic 104-key PC
4 Generic 105-key (Intl) PC
5 Dell 101-key PC
6 Everex STEPnote
7 Keytronic FlexPro
8 Microsoft Natural
9 Northgate OmniKey 101
10 Winbook Model XP5
11 Japanese 106-key
12 PC-98xx Series
13 Brazilian ABNT2
14 HP Internet
15 Logitech iTouch
16 Logitech Cordless Desktop Pro
17 Logitech Internet Keyboard
18 Logitech Internet Navigator Keyboard
19 Compaq Internet
20 Microsoft Natural Pro
21 Genius Comfy KB-16M
22 IBM Rapid Access
23 IBM Rapid Access II
24 Chicony Internet Keyboard
25 Dell Internet Keyboard
Enter a number to choose the keyboard.
1
Please select the layout corresponding to your keyboard
1 U.S. English
2 U.S. English w/ ISO9995-3
3 U.S. English w/ deadkeys
4 Albanian
5 Arabic
6 Armenian
7 Azerbaidjani
8 Belarusian
9 Belgian
10 Bengali
11 Brazilian
12 Bulgarian
13 Burmese
14 Canadian
15 Croatian
16 Czech
17 Czech (qwerty)
18 Danish
Enter a number to choose the country.
Press enter for the next page
1
Please enter a variant name for 'us' layout. Or just press enter
for default variant
us
Please answer the following question with either 'y' or 'n'.
Do you want to select additional XKB options (group switcher,
group indicator, etc.)? nOra, procediamo alla configurazione del monitor. Non eccedere alla potenza del tuo monitor. Potrebbero accadere dei danni. Se hai alcuni dubbi, fai la configurazione quando hai le informazioni.
parameters are the vertical refresh rate, which is the rate at which the
whole screen is refreshed, and most importantly the horizontal sync rate,
which is the rate at which scanlines are displayed.
The valid range for horizontal sync and vertical sync should be documented
in the manual of your monitor. If in doubt, check the monitor database
/usr/X11R6/lib/X11/doc/Monitors to see if your monitor is there.
Press enter to continue, or ctrl-c to abort.
You must indicate the horizontal sync range of your monitor. You can either
select one of the predefined ranges below that correspond to industry-
standard monitor types, or give a specific range.
It is VERY IMPORTANT that you do not specify a monitor type with a horizontal
sync range that is beyond the capabilities of your monitor. If in doubt,
choose a conservative setting.
hsync in kHz; monitor type with characteristic modes
1 31.5; Standard VGA, 640x480 @ 60 Hz
2 31.5 - 35.1; Super VGA, 800x600 @ 56 Hz
3 31.5, 35.5; 8514 Compatible, 1024x768 @ 87 Hz interlaced (no 800x600)
4 31.5, 35.15, 35.5; Super VGA, 1024x768 @ 87 Hz interlaced, 800x600 @ 56 Hz
5 31.5 - 37.9; Extended Super VGA, 800x600 @ 60 Hz, 640x480 @ 72 Hz
6 31.5 - 48.5; Non-Interlaced SVGA, 1024x768 @ 60 Hz, 800x600 @ 72 Hz
7 31.5 - 57.0; High Frequency SVGA, 1024x768 @ 70 Hz
8 31.5 - 64.3; Monitor that can do 1280x1024 @ 60 Hz
9 31.5 - 79.0; Monitor that can do 1280x1024 @ 74 Hz
10 31.5 - 82.0; Monitor that can do 1280x1024 @ 76 Hz
11 Enter your own horizontal sync range
Enter your choice (1-11): 6
You must indicate the vertical sync range of your monitor. You can either
select one of the predefined ranges below that correspond to industry-
standard monitor types, or give a specific range. For interlaced modes,
the number that counts is the high one (e.g. 87 Hz rather than 43 Hz).
1 50-70
2 50-90
3 50-100
4 40-150
5 Enter your own vertical sync range
Enter your choice: 2
You must now enter a few identification/description strings, namely an
identifier, a vendor name, and a model name. Just pressing enter will fill
in default names.
The strings are free-form, spaces are allowed.
Enter an identifier for your monitor definition: HitachiOra tocca alla selezione della scheda video da una lista. Se passi la tua scheda dalla lista, continua a premere Invio e la lista ricomincerà da capo. Viene mostrato solo uno stralcio della lista.
Now we must configure video card specific settings. At this point you can
choose to make a selection out of a database of video card definitions.
Because there can be variation in Ramdacs and clock generators even
between cards of the same model, it is not sensible to blindly copy
the settings (e.g. a Device section). For this reason, after you make a
selection, you will still be asked about the components of the card, with
the settings from the chosen database entry presented as a strong hint.
The database entries include information about the chipset, what driver to
run, the Ramdac and ClockChip, and comments that will be included in the
Device section. However, a lot of definitions only hint about what driver
to run (based on the chipset the card uses) and are untested.
If you can't find your card in the database, there's nothing to worry about.
You should only choose a database entry that is exactly the same model as
your card; choosing one that looks similar is just a bad idea (e.g. a
GemStone Snail 64 may be as different from a GemStone Snail 64+ in terms of
hardware as can be).
Do you want to look at the card database? y
288 Matrox Millennium G200 8MB mgag200
289 Matrox Millennium G200 SD 16MB mgag200
290 Matrox Millennium G200 SD 4MB mgag200
291 Matrox Millennium G200 SD 8MB mgag200
292 Matrox Millennium G400 mgag400
293 Matrox Millennium II 16MB mga2164w
294 Matrox Millennium II 4MB mga2164w
295 Matrox Millennium II 8MB mga2164w
296 Matrox Mystique mga1064sg
297 Matrox Mystique G200 16MB mgag200
298 Matrox Mystique G200 4MB mgag200
299 Matrox Mystique G200 8MB mgag200
300 Matrox Productiva G100 4MB mgag100
301 Matrox Productiva G100 8MB mgag100
302 MediaGX mediagx
303 MediaVision Proaxcel 128 ET6000
304 Mirage Z-128 ET6000
305 Miro CRYSTAL VRX Verite 1000
Enter a number to choose the corresponding card definition.
Press enter for the next page, q to continue configuration.
288
Your selected card definition:
Identifier: Matrox Millennium G200 8MB
Chipset: mgag200
Driver: mga
Do NOT probe clocks or use any Clocks line.
Press enter to continue, or ctrl-c to abort.
Now you must give information about your video card. This will be used for
the "Device" section of your video card in XF86Config.
You must indicate how much video memory you have. It is probably a good
idea to use the same approximate amount as that detected by the server you
intend to use. If you encounter problems that are due to the used server
not supporting the amount memory you have (e.g. ATI Mach64 is limited to
1024K with the SVGA server), specify the maximum amount supported by the
server.
How much video memory do you have on your video card:
1 256K
2 512K
3 1024K
4 2048K
5 4096K
6 Other
Enter your choice: 6
Amount of video memory in Kbytes: 8192
You must now enter a few identification/description strings, namely an
identifier, a vendor name, and a model name. Just pressing enter will fill
in default names (possibly from a card definition).
Your card definition is Matrox Millennium G200 8MB.
The strings are free-form, spaces are allowed.
Enter an identifier for your video card definition:Andando ancora avanti, sono settate le modalità video per la risoluzione desiderata. Tipicamente, utili range sono 640x480, 800x600 e 1024x768, ma questi sono in funzione delle capacità della scheda video, della dimensione del monitor, e del comfort degli occhi. Quando selezioni una profondità di colore, seleziona la più alta che la tua scheda supporta.
For each depth, a list of modes (resolutions) is defined. The default
resolution that the server will start-up with will be the first listed
mode that can be supported by the monitor and card.
Currently it is set to:
"640x480" "800x600" "1024x768" "1280x1024" for 8-bit
"640x480" "800x600" "1024x768" "1280x1024" for 16-bit
"640x480" "800x600" "1024x768" "1280x1024" for 24-bit
Modes that cannot be supported due to monitor or clock constraints will
be automatically skipped by the server.
1 Change the modes for 8-bit (256 colors)
2 Change the modes for 16-bit (32K/64K colors)
3 Change the modes for 24-bit (24-bit color)
4 The modes are OK, continue.
Enter your choice: 2
Select modes from the following list:
1 "640x400"
2 "640x480"
3 "800x600"
4 "1024x768"
5 "1280x1024"
6 "320x200"
7 "320x240"
8 "400x300"
9 "1152x864"
a "1600x1200"
b "1800x1400"
c "512x384"
Please type the digits corresponding to the modes that you want to select.
For example, 432 selects "1024x768" "800x600" "640x480", with a
default mode of 1024x768.
Which modes? 432
You can have a virtual screen (desktop), which is screen area that is larger
than the physical screen and which is panned by moving the mouse to the edge
of the screen. If you don't want virtual desktop at a certain resolution,
you cannot have modes listed that are larger. Each color depth can have a
differently-sized virtual screen
Please answer the following question with either 'y' or 'n'.
Do you want a virtual screen that is larger than the physical screen? n
For each depth, a list of modes (resolutions) is defined. The default
resolution that the server will start-up with will be the first listed
mode that can be supported by the monitor and card.
Currently it is set to:
"640x480" "800x600" "1024x768" "1280x1024" for 8-bit
"1024x768" "800x600" "640x480" for 16-bit
"640x480" "800x600" "1024x768" "1280x1024" for 24-bit
Modes that cannot be supported due to monitor or clock constraints will
be automatically skipped by the server.
1 Change the modes for 8-bit (256 colors)
2 Change the modes for 16-bit (32K/64K colors)
3 Change the modes for 24-bit (24-bit color)
4 The modes are OK, continue.
Enter your choice: 4
Please specify which color depth you want to use by default:
1 1 bit (monochrome)
2 4 bits (16 colors)
3 8 bits (256 colors)
4 16 bits (65536 colors)
5 24 bits (16 million colors)
Enter a number to choose the default depth.
4In fine, devi salvare la configurazione. Assicurati di digitare /etc/X11/XF86Config come la locazione per salvare la configurazione.
I am going to write the XF86Config file now. Make sure you don't accidently
overwrite a previously configured one.
Shall I write it to /etc/X11/XF86Config? ySe la configurazione fallisce, puoi provare a rifarla selezionando yes quando appare il seguente messaggio:
User Confirmation Requested
The XFree86 configuration process seems to have
failed. Would you like to try again?
[ Yes ] NoSe hai difficoltà a configurare XFree86™, seleziona no e premi Invio e prosegui con il processo di installazione. Dopo l’installazione puoi usare xf86cfg -textmode oppure xf86config come root per accedere alle utility di configurazione a linea di comando. C’è un altro metodo per configurare XFree86™, descritto nel L’X Window System. Se hai deciso di non configurare XFree86™ il prossimo menù sarà per la selezione dei package.
Il settaggio di default che permette di killare il server è la sequenza di tasti Ctrl+Alt+Backspace. Puoi usarla se qualcosa nel settaggio del server è sbagliato prevenendo danni all’hardware.
Il settaggio di default che permette di saltare da una modalità video all’altra mentre X è in esecuzione è la sequenza di tasti Ctrl+Alt++ o Ctrl+Alt+-.
Dopo che hai XFree86™ in esecuzione, puoi aggiustare la schermata in altezza, larghezza o centrarla usando xvidtune.
Ci sono avvisi che segnalano che settaggi impropri possono danneggiare il tuo equipaggiamento. Considerali. Se sei in dubbio, non farlo. Invece, usa i controlli del monitor per aggiustare la schermata per X Window. Così facendo ci potrebbero essere delle incongruenze di visualizzazione quando passi alla modalità testo, ma questo è meglio rispetto al danneggiamento dell’equipaggiamento.
Leggi la pagina man di xvidtune(1) prima di fare qualsiasi regolazione.
Al seguito di una configurazione di XFree86™ andata a buon fine, si procederà alla selezione di un desktop di default.
A partire da FreeBSD 5.3-RELEASE, la possibilità di selezione del desktop X è stata rimossa da sysinstall, devi configurare il desktop X dopo l’installazione di FreeBSD. Maggiori informazioni riguardo all’installazione e configurazione di un desktop X possono essere trovate nel L’X Window System. Puoi saltare questa sezione se non stai installando una versione di FreeBSD precedente a 5.3-RELEASE. |
Sono disponibili diversi gestori di finestre. Essi spaziano da ambienti veramente basilari fino a ambienti con desktop completi che includono diverse applicazioni. Alcuni richiedono uno spazio di disco minimo e poca memoria mentre altri con maggiori funzionalità richiedono più risorse. Il miglior modo per determinare quale gestore di finestre utilizzare è provarne alcuni. Sono disponibili dalla collezione dei port o come package e possono essere aggiunti dopo l’installazione.
Puoi selezionare uno dei desktop più popolari e sarà installato ed configurato come il desktop di default. Ciò ti permetterà di avviarlo appena dopo l’installazione.
Usa i tasti freccia per selezionare un desktop e premi Invio. Verrà avviata l’installazione del desktop selezionato.
I package sono binari pre-compilati e risultano essere un modo conveniente per installare applicazioni.
A scopo illustrativo viene mostrata l’installazione di un package. Puoi installare ulteriori package se lo desideri. Dopo l’installazione puoi usare sysinstall (/stand/sysinstall nelle versioni di FreeBSD dopo la 5.2) per aggiungere ulteriori package.
User Confirmation Requested
The FreeBSD Package collection is a collection of hundreds of
ready-to-run applications, from text editors to games to WEB servers
and more. Would you like to browse the collection now?
[ Yes ] NoSelezionando yes e premendo Invio verranno visualizzate le seguenti schermate per la selezione dei package:
Soltanto i package che risiedono sul media di installazione corrente sono disponibili per l’installazione in un dato istante.
Se si seleziona saranno visualizzati tutti i package disponibili oppure puoi selezionare una categoria particolare. Evidenzia la tua selezione con i tasti freccia e premi Invio.
Verrà visualizzato un menù con i package disponibili in base alla selezione effettuata:
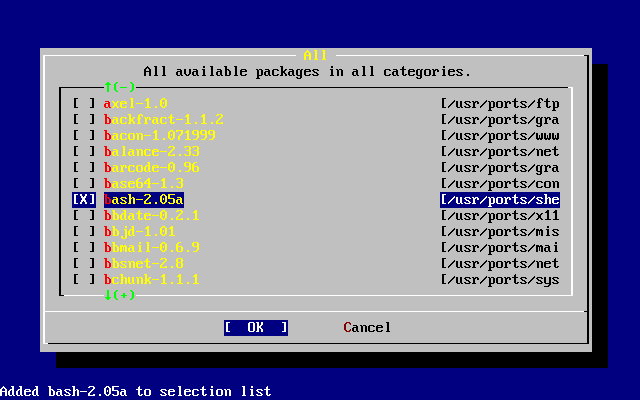
È stata selezionata la shell bash. Puoi selezionare altre cose portandoti sul package e premendo il tasto Spazio. Apparirà una breve descrizione di ogni package nell’angolo in basso a sinistra dello schermo.
Premendo il tasto Tab passerai ciclicamente dall’ultimo package selezionato, da OK, e da Cancel.
Quando hai finito di selezionare i package che vuoi installare, premi Tab una volta per andare a OK e premi Invio per tornare al menù della selezione dei package.
Con i tasti freccia sinistra e destra puoi passare tra OK e Cancel. Questo metodo può essere anche usato per selezionare OK e premere Invio per tornare al menù di selezione dei package.
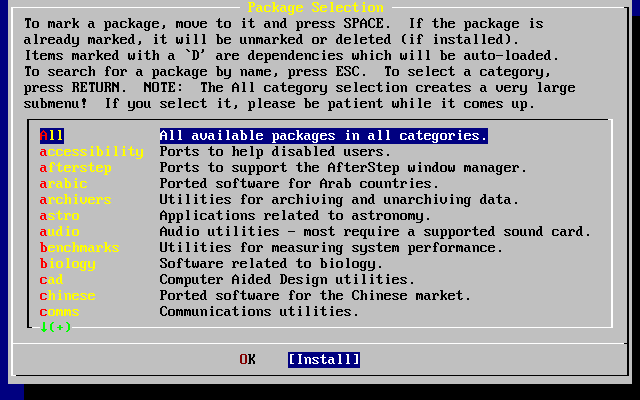
Usa Tab e con i tasti freccia seleziona Install e premi Invio. Dovrai confermare l’installazione dei package:
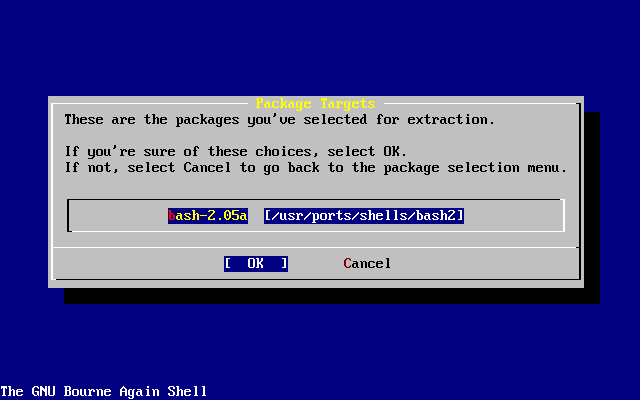
Selezionando OK e premendo Invio inizierà l’installazione dei package. Appariranno dei messaggi di installazione fino al completamento della stessa. Prendi nota se c’è qualche messaggio di errore.
La configurazione finale continua dopo che i package sono stati installati. Se decidi di non selezionare alcun package, e vuoi ritornare alla configurazione finale, seleziona comunque Install.
Dovresti aggiungere almeno un utente durante l’installazione in modo che puoi usare il sistema senza doverti loggare come root. La partizione root è generalmente di dimensioni ridotte ed eseguire applicazione da root può riempirla facilmente. Viene segnalato un pericolo:
User Confirmation Requested
Would you like to add any initial user accounts to the system? Adding
at least one account for yourself at this stage is suggested since
working as the "root" user is dangerous (it is easy to do things which
adversely affect the entire system).
[ Yes ] NoSeleziona yes e premi Invio per continuare nell’aggiunta di un utente.
Seleziona con i tasti freccia e premi Invio.
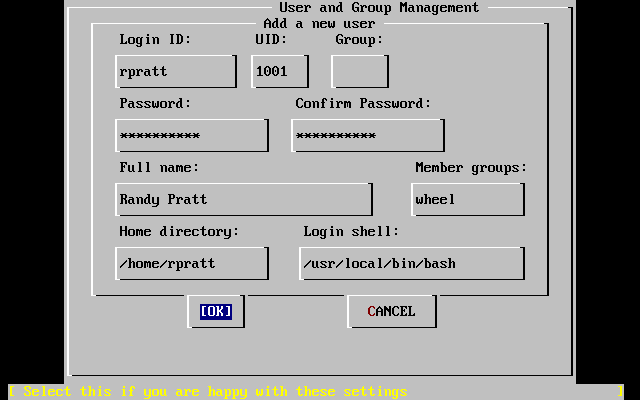
Le seguenti descrizioni appariranno nella parte bassa dello schermo ogni qual volta gli elementi sono selezionati con Tab per assistere all’immissione delle informazioni richieste:
Il nome di login del nuovo utente (obbligatorio).
L’ID numerico per questo utente (lasciare bianco per una scelta automatica).
Il nome del gruppo di login per questo utente (lasciate bianco per una scelta automatica).
La password per questo utente (inserisci questo campo con cura!).
Il nome completo dell’utente (commento).
I gruppi a cui questo utente appartiene (cioè i diritti di accesso concessi).
La directory home dell’utente (lasciare in bianco per il default).
La shell di login dell’utente (lasciare in bianco per il default, per esempio /bin/sh).
La shell di login è stata modificata da /bin/sh a /usr/local/bin/bash per usare la shell bash che è stata in precedenza installata come package. Non tentare di usare una shell che non esiste o non sarai in grado di effettuare il login. La shell più comune usata nel mondo-BSD è la schell C, che può essere indicata come /bin/tcsh.
L’utente è stata aggiunto al gruppo wheel al fine di poter diventare un superutente con privilegi di root.
Quando sei soddisfatto, premi OK e ti verrà visualizzato il menù di gestione degli utenti e dei gruppi:
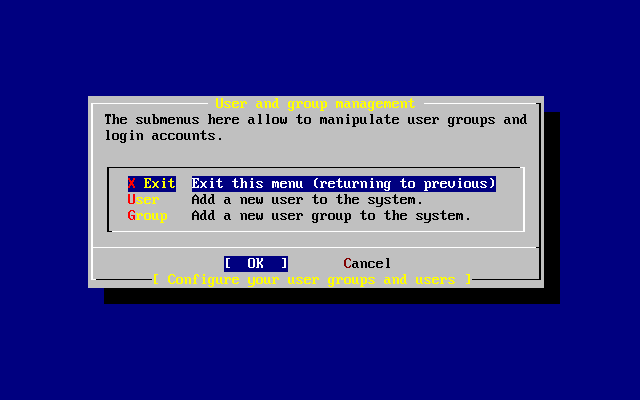
I gruppi possono essere aggiunti anche adesso se necessario. Altrimenti, puoi farlo usando sysinstall (/stand/sysinstall nelle versioni di FreeBSD dopo la 5.2) dopo che hai completato l’installazione.
Quando hai terminato di aggiungere gli utenti, seleziona con i tasti freccia e premi Invio per continuare l’installazione.
root Message
Now you must set the system manager's password.
This is the password you'll use to log in as "root".
[ OK ]
[ Press enter to continue ]Premi Invio per settare la password di root.
La password dovrà essere battuta correttamente per due volte. Inutile a dirsi, assicurati di avere un modo di trovare la password nel caso dovessi dimenticarla. Nota che la password che digiti non è mostrata, e non vengono visualizzati neppure gli asterischi.
Changing local password for root.
New password :
Retype new password :L’installazione continuerà dopo che la password è stata inserita correttamente.
Se hai bisogno di configurare altri dispositivi di rete o altre configurazioni, lo puoi fare a questo punto o dopo con sysinstall (/stand/sysinstall nelle versioni di FreeBSD dopo la 5.2).
User Confirmation Requested
Visit the general configuration menu for a chance to set any last
options?
Yes [ No ]Seleziona no con i tasti freccia e premi Invio per tornare al menù di Installazione Principale.
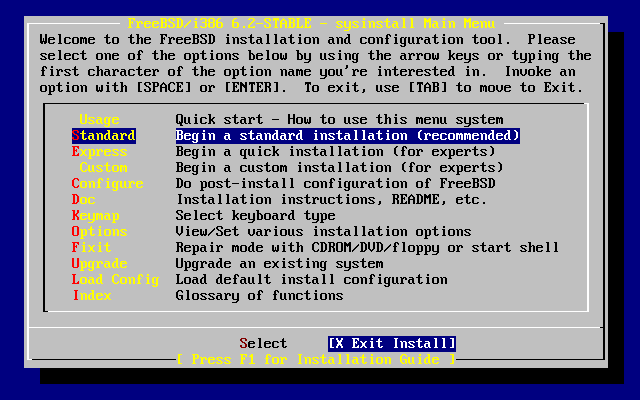
Seleziona con i tasti freccia X Exit Install e premi Invio. Ti sarà chiesto di confermare l’uscita dall’installazione:
User Confirmation Requested
Are you sure you wish to exit? The system will reboot (be sure to
remove any floppies from the drives).
[ Yes ] NoSeleziona yes e rimuovi il floppy se hai avviato tramite floppy. Il CDROM è bloccato fino a quando la macchina non verrà riavviata. Il CDROM verrà quindi sbloccato e il disco può essere rimosso dal dispositivo (velocemente).
Il sistema verrà riavviato, guarda eventuali messaggi di errore che potrebbero apparire.
Se tutto è andato bene, vedrai alcuni messaggi scorrere sullo schermo a arriverai al prompt di login. Puoi controllare il contenuto dei messaggi premendo Scroll-Lock e usando PgUp e PgDn. Premendo Scroll-Lock un’altra volta ritornerai al prompt.
Il messaggio completo non può essere visualizzato (per limitazioni del buffer) ma può essere visto dalla linea di comando dopo aver effettuato il login digitando al prompt dmesg.
Accedi usando il nome utente e la password che hai settato durante l’installazione (rpratt, in questo esempio). Evita di loggarti come root se non ne hai bisogno.
Tipici messaggi di avvio (le informazioni sulla versione sono state omesse):
Copyright (c) 1992-2002 The FreeBSD Project.
Copyright (c) 1979, 1980, 1983, 1986, 1988, 1989, 1991, 1992, 1993, 1994
The Regents of the University of California. All rights reserved.
Timecounter "i8254" frequency 1193182 Hz
CPU: AMD-K6(tm) 3D processor (300.68-MHz 586-class CPU)
Origin = "AuthenticAMD" Id = 0x580 Stepping = 0
Features=0x8001bf<FPU,VME,DE,PSE,TSC,MSR,MCE,CX8,MMX>
AMD Features=0x80000800<SYSCALL,3DNow!>
real memory = 268435456 (262144K bytes)
config> di sn0
config> di lnc0
config> di le0
config> di ie0
config> di fe0
config> di cs0
config> di bt0
config> di aic0
config> di aha0
config> di adv0
config> q
avail memory = 256311296 (250304K bytes)
Preloaded elf kernel "kernel" at 0xc0491000.
Preloaded userconfig_script "/boot/kernel.conf" at 0xc049109c.
md0: Malloc disk
Using $PIR table, 4 entries at 0xc00fde60
npx0: <math processor> on motherboard
npx0: INT 16 interface
pcib0: <Host to PCI bridge> on motherboard
pci0: <PCI bus> on pcib0
pcib1: <VIA 82C598MVP (Apollo MVP3) PCI-PCI (AGP) bridge> at device 1.0 on pci0
pci1: <PCI bus> on pcib1
pci1: <Matrox MGA G200 AGP graphics accelerator> at 0.0 irq 11
isab0: <VIA 82C586 PCI-ISA bridge> at device 7.0 on pci0
isa0: <ISA bus> on isab0
atapci0: <VIA 82C586 ATA33 controller> port 0xe000-0xe00f at device 7.1 on pci0
ata0: at 0x1f0 irq 14 on atapci0
ata1: at 0x170 irq 15 on atapci0
uhci0: <VIA 83C572 USB controller> port 0xe400-0xe41f irq 10 at device 7.2 on pci0
usb0: <VIA 83C572 USB controller> on uhci0
usb0: USB revision 1.0
uhub0: VIA UHCI root hub, class 9/0, rev 1.00/1.00, addr 1
uhub0: 2 ports with 2 removable, self powered
chip1: <VIA 82C586B ACPI interface> at device 7.3 on pci0
ed0: <NE2000 PCI Ethernet (RealTek 8029)> port 0xe800-0xe81f irq 9 at
device 10.0 on pci0
ed0: address 52:54:05:de:73:1b, type NE2000 (16 bit)
isa0: too many dependant configs (8)
isa0: unexpected small tag 14
fdc0: <NEC 72065B or clone> at port 0x3f0-0x3f5,0x3f7 irq 6 drq 2 on isa0
fdc0: FIFO enabled, 8 bytes threshold
fd0: <1440-KB 3.5" drive> on fdc0 drive 0
atkbdc0: <keyboard controller (i8042)> at port 0x60-0x64 on isa0
atkbd0: <AT Keyboard> flags 0x1 irq 1 on atkbdc0
kbd0 at atkbd0
psm0: <PS/2 Mouse> irq 12 on atkbdc0
psm0: model Generic PS/2 mouse, device ID 0
vga0: <Generic ISA VGA> at port 0x3c0-0x3df iomem 0xa0000-0xbffff on isa0
sc0: <System console> at flags 0x1 on isa0
sc0: VGA <16 virtual consoles, flags=0x300>
sio0 at port 0x3f8-0x3ff irq 4 flags 0x10 on isa0
sio0: type 16550A
sio1 at port 0x2f8-0x2ff irq 3 on isa0
sio1: type 16550A
ppc0: <Parallel port> at port 0x378-0x37f irq 7 on isa0
ppc0: SMC-like chipset (ECP/EPP/PS2/NIBBLE) in COMPATIBLE mode
ppc0: FIFO with 16/16/15 bytes threshold
ppbus0: IEEE1284 device found /NIBBLE
Probing for PnP devices on ppbus0:
plip0: <PLIP network interface> on ppbus0
lpt0: <Printer> on ppbus0
lpt0: Interrupt-driven port
ppi0: <Parallel I/O> on ppbus0
ad0: 8063MB <IBM-DHEA-38451> [16383/16/63] at ata0-master using UDMA33
ad2: 8063MB <IBM-DHEA-38451> [16383/16/63] at ata1-master using UDMA33
acd0: CDROM <DELTA OTC-H101/ST3 F/W by OIPD> at ata0-slave using PIO4
Mounting root from ufs:/dev/ad0s1a
swapon: adding /dev/ad0s1b as swap device
Automatic boot in progress...
/dev/ad0s1a: FILESYSTEM CLEAN; SKIPPING CHECKS
/dev/ad0s1a: clean, 48752 free (552 frags, 6025 blocks, 0.9% fragmentation)
/dev/ad0s1f: FILESYSTEM CLEAN; SKIPPING CHECKS
/dev/ad0s1f: clean, 128997 free (21 frags, 16122 blocks, 0.0% fragmentation)
/dev/ad0s1g: FILESYSTEM CLEAN; SKIPPING CHECKS
/dev/ad0s1g: clean, 3036299 free (43175 frags, 374073 blocks, 1.3% fragmentation)
/dev/ad0s1e: filesystem CLEAN; SKIPPING CHECKS
/dev/ad0s1e: clean, 128193 free (17 frags, 16022 blocks, 0.0% fragmentation)
Doing initial network setup: hostname.
ed0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 192.168.0.1 netmask 0xffffff00 broadcast 192.168.0.255
inet6 fe80::5054::5ff::fede:731b%ed0 prefixlen 64 tentative scopeid 0x1
ether 52:54:05:de:73:1b
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x8
inet6 ::1 prefixlen 128
inet 127.0.0.1 netmask 0xff000000
Additional routing options: IP gateway=YES TCP keepalive=YES
routing daemons:.
additional daemons: syslogd.
Doing additional network setup:.
Starting final network daemons: creating ssh RSA host key
Generating public/private rsa1 key pair.
Your identification has been saved in /etc/ssh/ssh_host_key.
Your public key has been saved in /etc/ssh/ssh_host_key.pub.
The key fingerprint is:
cd:76:89:16:69:0e:d0:6e:f8:66:d0:07:26:3c:7e:2d root@k6-2.example.com
creating ssh DSA host key
Generating public/private dsa key pair.
Your identification has been saved in /etc/ssh/ssh_host_dsa_key.
Your public key has been saved in /etc/ssh/ssh_host_dsa_key.pub.
The key fingerprint is:
f9:a1:a9:47:c4:ad:f9:8d:52:b8:b8:ff:8c:ad:2d:e6 root@k6-2.example.com.
setting ELF ldconfig path: /usr/lib /usr/lib/compat /usr/X11R6/lib
/usr/local/lib
a.out ldconfig path: /usr/lib/aout /usr/lib/compat/aout /usr/X11R6/lib/aout
starting standard daemons: inetd cron sshd usbd sendmail.
Initial rc.i386 initialization:.
rc.i386 configuring syscons: blank_time screensaver moused.
Additional ABI support: linux.
Local package initialization:.
Additional TCP options:.
FreeBSD/i386 (k6-2.example.com) (ttyv0)
login: rpratt
Password:La generazione delle chiavi RSA e DSA può richiedere un pò di tempo sulle macchine lente. Questo succede solo al primo avvio di una nuova installazione. I successivi avvii saranno più veloci.
Se è stato configurato il server X ed è stato scelto un Desktop di default, questo può essere avviato digitando sulla linea di comando startx.
Una volta finita la procedura di installazione, sarai in grado di avviare FreeBSD scrivendo qualcosa di simile a questo nel prompt SRM:
>>>BOOT DKC0Questo istruisce il firmware ad avviare il disco specificato. Per avviare FreeBSD in automatico in futuro, usa questi comandi:
>>> SET BOOT_OSFLAGS A
>>> SET BOOT_FILE ''
>>> SET BOOTDEF_DEV DKC0
>>> SET AUTO_ACTION BOOTI messaggi di avvio saranno simili (ma non identici) a quelli prodotti dall’avvio di FreeBSD su i386™.
È importante spegnere (effettuare lo shutdown) in modo adeguato il sistema operativo. Non farlo rimuovendo l’alimentazione. Innanzitutto, diventa superuser digitando su dalla linea di comando ed inserendo la password di root. Questo funziona solo se l’utente è un membro del gruppo wheel. Altrimenti, loggati come root e usa shutdown -h now.
The operating system has halted.
Please press any key to reboot.Quando appare il messaggio "Please press any key to reboot" puoi togliere con sicurezza l’alimentazione. Se premi qualunque tasto invece di premere il bottone per togliere l’alimentazione, il sistema verrà riavviato.
Potresti anche usare la combinazione di tasti Ctrl+Alt+Del per riavviare il sistema, comunque questo non è raccomandato durante un normale funzionamento.
FreeBSD attualmente gira su una varietà di PC con bus ISA, VLB, EISA, e PCI con processori Intel, AMD, Cyrix, o processori NexGen "x86", così come su diverse macchine basate sul processore Compaq Alpha. Supporta configurazioni generiche di dispositivi IDE o ESDI, svariati controller SCSI, schede PCMCIA, dispositivi USB, e schede seriale e di rete. FreeBSD supporta anche il bus microchannel (MCA) di IBM.
Un elenco di hardware supportato da FreeBSD è fornito con ogni release di FreeBSD nell’Hardware Note di FreeBSD. Questo documento può essere trovato nel file HARDWARE.TXT, nella directory root di una distribuzione CDROM o FTP o nel menù di documentazione di sysinstall. Per ogni architettura, vengono elencati i dispositivi hardware che sono noti essere supportati dalla release di FreeBSD. Copie della lista dell’hardware supportato per diverse release ed architetture possono essere trovate nella pagina del sito Web di FreeBSD Informazioni di Release.
Questa sezione copre la localizzazione di alcuni problemi riguardo all’installazione, come problemi comuni che sono stati segnalati dagli utenti. Ci sono anche alcune domande e risposte per le persone che desiderano avere FreeBSD e MS-DOS® sulla stessa macchina.
A causa di varie limitazioni dell’architettura del PC, è impossibile che la fase di probe sia accurata al 100%, comunque ci sono alcune cose che puoi fare se il probe fallisce.
Controlla il documento Hardware Note per la tua versione di FreeBSD per assicurarti che il tuo hardware sia supportato.
Se il tuo hardware è supportato e continui ad avere esperienze di blocco o altri problemi, resetta il computer, e quando ti viene data la possibilità entra nella configurazione visuale del kernel. Il kernel sui dischetti di avvio è configurato assumendo che la maggior parte dei dispositivi hardware sono nella loro configurazioni di fabbrica in termini di IRQ, indirizzi di IO, e canali DMA. Se il tuo hardware è stato riconfigurato, probabilmente hai bisogno di usare l’editor di configurazione per dire a FreeBSD dove trovare le cose.
È anche possibile che un probe di un dispositivo non presente porti a un fallimento di un successivo probe per un dispositivo presente. In questo caso, i probe per i driver che vanno in conflitto dovrebbero essere disabilitati.
Alcuni problemi di installazione possono essere evitati o alleviati con un aggiornamento del firmware dei vari componenti hardware, scheda madre in primis. Il firmware della scheda madre può anche essere chiamato BIOS e la maggior parte dei produttori di schede madri o di computer hanno un sito web dove poter localizzare gli aggiornamenti e le relative informazioni. La maggior parte dei produttori non consiglia l’aggiornamento del BIOS della scheda madre a meno che ci sia una buona ragione per farlo, che potrebbe essere una sorta di aggiornamento critico. Il processo di aggiornamento può non andare per il verso giusto, causando danni permanenti al chip del BIOS. |
Non disabilitare alcuni driver di cui avrai bisogno durante l’installazione, come quello per lo schermo (sc0). Se l’installazione si ferma o fallisce misteriosamente dopo aver lasciato l’editor di configurazione, probabilmente hai rimosso o modificato qualcosa che non dovevi. Riavvia e prova di nuovo. |
Nella modalità di configurazione, puoi:
Elencare i driver dei dispositivi installati nel kernel.
Disabilitare i driver dei dispositivi per l’hardware che non è presente nel tuo sistema.
Cambiare IRQ, DRQ, e gli indirizzi delle porte di IO usati da un driver di dispositivo.
Dopo che hai sistemato il kernel in base alla tua configurazione hardware, premi Q per avviare con i nuovi settaggi. Una volta completata l’installazione, ogni modifica che hai fatto nella modalità di configurazione sarà permanente in modo tale che non devi riconfigurare ogni volta che avvii. Tuttavia è molto probabile che tu voglia costruirti un kernel su misura.
Molti utenti desiderano installare FreeBSD su un PC popolato da sistemi operativi Microsoft®. Per queste situazioni, FreeBSD ha un utility di nome FIPS. Questa utility può essere trovata nella directory tools su CD-ROM di installazione, o può essere scaricata da uno dei vari mirror di FreeBSD.
L’utility FIPS ti consente di suddividere una partizione MS-DOS® esistente in due pezzi, preservando la partizione originale e permettendo di installare FreeBSD nella seconda parte libera. Prima devi deframmentare la tua partizione MS-DOS® usando l’utility di Windows® Deframmentazione dei Dischi (vai in Explorer, clicca con il destro sull’hard disk, e scegli di deframmentarlo), oppure usando Norton Disk Tools. Adesso puoi eseguire l’utility FIPS. Ti verranno mostrate delle informazioni di supporto, segui le informazioni a video. Fatto ciò, puoi riavviare ed installare FreeBSD sulla nuova slice libera. Guarda il menù per una stima di quanto spazio libero necessiti per il tipo di installazione voluto.
Esiste anche un prodotto molto utile della PowerQuest (http://www.powerquest.com) chiamato PartitionMagic®. Questa applicazione ha più funzionalità di FIPS, ed è altamente raccomandato se hai intenzione di aggiungere/rimuovere spesso sistemi operativi. È a pagamento, quindi se hai intenzione di installare in modo permanente FreeBSD, FIPS probabilmente fa al caso tuo.
A tutt’oggi, FreeBSD non supporta filesystem compressi con l’utility Double Space™. Quindi il filesystem dovrà essere decompresso prima che FreeBSD possa accedere ai dati. Questo può essere fatto eseguendo l’Agente di Compressione raggiungibile da > > .
FreeBSD supporta filesystem basati su MS-DOS®. Questo richiede di usare il comando mount_msdosfs(8) con i parametri opportuni. L’uso più comune è:
# mount_msdosfs /dev/ad0s1 /mntIn questo esempio, il filesystems MS-DOS® è localizzato sulla prima partizione dell’hard disk primario. La tua situazione potrebbe essere differente, verifica l’output dei comandi dmesg, e mount. Questi, dovrebbero produrre abbastanza informazioni per darti un’idea del layout della partizione.
I filesystem MS-DOS® estesi in genere sono mappati dopo le partizioni di FreeBSD. In altre parole, il numero della slice potrebbe essere più alto di quello usato da FreeBSD. Per esempio, la prima partizione MS-DOS® potrebbe essere /dev/ad0s1, la partizione di FreeBSD potrebbe essere /dev/ad0s2, con la partizione MS-DOS® estesa in /dev/ad0s3. Per alcuni, tutto ciò potrebbe causare della confusione all’inizio. |
Le partizioni NTFS possono essere montate in modo simile usando il comando mount_ntfs(8).
Questa sezione risponde ad alcune questioni comuni relative all’installazione di FreeBSD su sistemi Alpha.
Questa sezione descrive come installare FreeBSD in casi speciali.
Questo tipo di installazione è chiamata "installazione headless", poichè la macchina sulla quale stai cercando di installare FreeBSD non ha un monitor, o non ha neanche un output VGA. Come è possibile ti chiederai? Usando una console seriale. Una console seriale sostanzialmente usa un’altra macchina per fungere da monitor e tastiera primari per un sistema. Per fare questo, segui le fasi per creare i floppy di installazione, come spiegato nella Preparare i Media per il Boot.
Per modificare questi floppy per avviare in una console seriale, segui questi passi:
Abilitare i Floppy di Avvio per Avviare in una Console Seriale
Se hai avviato con i floppy che hai appena creato, FreeBSD dovrebbe avviare la sua modalità di installazione standard. Noi vogliamo che FreeBSD avvii un console seriale per la nostra installazione. Per fare questo, devi montare il floppy kern.flp nel tuo sistema FreeBSD usando il comando mount(8).
# mount /dev/fd0 /mntAdesso che hai il tuo floppy montato, portati nella directory /mnt:
# cd /mntÈ qui che devi configurare il floppy per avviare una console seriale. Devi creare un file di nome boot.config contenente /boot/loader -h. Tutto quello che fa è passare un flag al bootloader per avviare una console seriale.
# echo "/boot/loader -h" > boot.configAdesso che hai il tuo floppy configurato correttamente, devi smontare il floppy usando il comando umount(8):
# cd /
# umount /mntAdesso puoi rimuovere il floppy.
Connettere il Cavo Null-Modem
Devi connettere un cavo null-modem tra le due macchine. Connetti il cavo alla porta seriale delle due macchine. Un cavo seriale normale non funzionerà, hai bisogno di un cavo null-modem perchè ha alcuni segnali incrociati.
Avviare per l’Installazione
È tempo di andare avanti e cominciare con l’installazione. Inserisci il floppy kern.flp nella macchina sulla quale vuoi fare l’installazione headless, e accendila.
Connettersi alla Macchina Headless
Adesso devi connetterti alla macchina con cu(1):
# cu -l /dev/cuaa0Ci siamo! Dovresti essere in grado di controllare la macchina headless attraverso la tua sessione cu. Ti verrà chiesto di inserire mfsroot.flp, e poi dovrai scegliere il tipo di terminale da usare. Seleziona la console a colori di FreeBSD e procedi con la tua installazione!
Per evitare ripetizioni, "il disco di FreeBSD" in questo contesto significa il CDROM o DVD che ti sei procurato. |
Ci possono essere delle situazioni in cui hai bisogno di creare dei media di installazione di FreeBSD e/o delle fonti per l’installazione. Potrebbe essere un media fisico, come un nastro, o una fonte che sysinstall può usare per recuperare i file, come un sito FTP locale, o una partizione MS-DOS®.
Per esempio:
Hai molte macchine connesse alla tua rete locale, e un disco di FreeBSD. Vuoi creare un sito FTP locale usando il contenuto del disco di FreeBSD, e quindi dare la possibilità alle tue macchine di usare questo sito FTP locale senza la necessità di doversi collegare a Internet.
Hai un disco di FreeBSD, e FreeBSD non riconosce il tuo lettore CD/DVD, ma MS-DOS®/Windows® lo riconosce. Vuoi copiare i file di installazione di FreeBSD su una partizione DOS posta sul medesimo computer, e quindi installare FreeBSD usando quei file.
Il computer sul quale vuoi installare FreeBSD non ha un lettore CD/DVD ne una scheda di rete, ma puoi connettere un cavo "Laplink-style" seriale o parallelo ad un altro computer fornito di quei supporti.
Vuoi creare un nastro che può essere usato per installare FreeBSD.
Come parte di ogni release, il progetto FreeBSD mette a disposizione due immagini CDROM ("immagini ISO"). Queste immagini possono essere scritte ("burnate") su CD se hai un masterizzatore, e quindi possono essere usate per installare FreeBSD. Se hai un masterizzatore, e la banda di rete è conveniente, allora questo è il modo più semplice per installare FreeBSD.
Scaricare le Immagini ISO Corrette
Le immagini ISO per ogni release possono essere scaricate da ftp://ftp.FreeBSD.org/pub/FreeBSD/ISO-IMAGES-arch/version o dal mirror più vicino. Sostituisci arch e versione in modo appropriato.
Quella directory normalmente contiene le seguenti immagini:
| Nome del File | Contenuto |
|---|---|
version-RELEASE-arch-miniinst.iso | Tutto quello di cui hai bisogno per installare FreeBSD. |
version-RELEASE-arch-disc1.iso | Tutto quello di cui hai bisogno per installare FreeBSD, e anche molti package addizionali di terze parti che potresti provare. |
version-RELEASE-arch-disc2.iso | Un "filesystem live", usato in congiunzione con l’utility "Repair" di sysinstall. Una copia dell’albero CVS di FreeBSD. Sul disco anche altri package addizionali di terze parti. |
| Nome del File | Contenuto |
|---|---|
version-RELEASE-arch-bootonly.iso | Tutto ciò di cui hai bisogno per avviare il kernel di FreeBSD e partire con l’interfaccia di installazione. I file di installazione devono essere messi su FTP o su altre fonti di supporto. |
version-RELEASE-arch-miniinst.iso | Tutto ciò di cui hai bisogno per installare FreeBSD. |
version-RELEASE-arch-disc1.iso | Tutto ciò di cui hai bisogno per installare FreeBSD e un "live filesystem", che è usato in congiunzione con l’utility "Repair" in sysinstall. |
version-RELEASE-arch-disc2.iso | La documentazione di FreeBSD e molte applicazioni di terze parti. |
Devi scaricare o l’immagine ISO miniinst, o l’immagine del disco uno. Non le scaricare entrambe, poichè l’immagine del disco uno contiene tutto ciò che contiene l’immagine ISO miniinst.
L’immagine ISO miniinst è solo disponibile per le release antecedenti la 5.4-RELEASE. |
Usa la miniinst ISO se l’accesso ad Internet è costoso per te. Ti permetterà di installare FreeBSD, e puoi sempre installare i package di terze parti scaricandoli usando il sistema dei port/package (guarda il Installazione delle Applicazioni. Port e Package,) se necessario.
Usa l’immagine del disco uno se vuoi installare una release di FreeBSD e se vuoi anche un modesto assortimento di package di terze parti.
Le altre immagini sono utili, ma non essenziali, soprattutto se hai un accesso ad Internet ad alta velocità.
Scrivere i CD
Devi scrivere le immagini dei CD sul disco. Se hai intenzione di farlo da un’altra macchina FreeBSD allora guarda la Creating and Using Optical Media (CDs & DVDs) per maggiori informazioni (in particolare, la burncd e la cdrecord).
Se lo fai su un’altra piattaforma allora devi usare qualche utility per controllare il tuo masterizzatore di CD esistente su tale piattaforma. Le immagini fornite sono nel formato standard ISO, supportato da molte applicazioni di masterizzazione dei CD.
Se sei interessato a costruirti una release di FreeBSD personalizzata, guarda l’Articolo di Progettazione delle Release. |
I dischi di FreeBSD sono strutturati alla stessa maniera di un sito FTP. Questo rende semplice la creazione di un sito FTP locale che può essere usato da altre macchine sulla tua rete per installare FreeBSD.
Sul computer FreeBSD che ospiterà il sito FTP, assicurati che il CDROM è nel lettore, e montato su /cdrom.
# mount /cdromCrea un account per FTP anonimo in /etc/passwd. Fallo editando /etc/passwd usando vipw(8) aggiungendo questa linea:
ftp:*:99:99::0:0:FTP:/cdrom:/nonexistent
Assicurati che il servizio FTP sia abilitato in /etc/inetd.conf.
Chiunque che possa connettersi via rete alla tua macchina può ora scegliere il tipo di media FTP digitando ftp://tua macchina dopo aver selezionato "Altro" nel menù dei siti FTP durante l’installazione.
Se il media di avvio (di solito dischetti floppy) usato dai tuoi client FTP non è della stessa versione fornita dal sito FTP locale, allora sysinstall non ti lascierà completare l’installazione. Se le versioni non sono simili e vuoi comunque procedere, devi andare nel menù Options e modificare il nome della distribuzione in . |
Questo approccio è OK per una macchina sulla tua rete locale, che è protetta dal tuo firewall. Offrire servizi FTP ad altre macchine su Internet (non sulla tua lan) espone il tuo computer all’attenzione dei cracker e di altri maligni. Raccomandiamo fortemente di seguire buone norme di sicurezza. |
Se devi installare da floppy disk (che suggeriamo di non fare), a causa di hardware non supportato o semplicemente perchè insisti nel fare le cose tenacemente, devi prima preparare un pò di floppy per l’installazione.
Come minimo, avrai bisogno di molti floppy da 1.44 MB o da 1.2 MB per contenere tutti i file della directory bin (distribuzione binaria). Se stai preparando i floppy da DOS, allora questi devono essere formattati usando il comando FORMAT di MS-DOS®. Se stai usando Windows® usa Explorer per formattare i dischi (clicca con il tasto destro sul dispositivo A:, e scegli "Format").
Non fidarti dei floppy pre-formattati di fabbrica. Formattali di nuovo, per essere sicuro. In passato molti problemi riportati dai nostri utenti si sono poi rilevati causati dall’uso di media non correttamente formattati, ecco perchè stiamo mettendo in evidenzia questo fatto.
Se crei i floppy su un’altra macchina FreeBSD, un format è ancora una buona idea, benchè non devi necessariamente mettere un filesystem DOS su ogni floppy. Puoi usare i comandi bsdlabel e newfs per mettere un filesystem UFS su ogni flopply, come mostra la seguente sequenza di comandi (per un floppy da 3.5" 1.44 MB):
# fdformat -f 1440 fd0.1440
# bsdlabel -w -r fd0.1440 floppy3
# newfs -t 2 -u 18 -l 1 -i 65536 /dev/fd0Usa |
Puoi montarli e scriverci come qualsiasi altro tipo di file ystem.
Dopo che hai formattato i flopply, dovrai copiarvi i file necessari. I files della distribuzione sono splittati in pezzi di dimensioni tali che cinque di essi possono stare su un singolo floppy convenzionale da 1.44 MB. Crea tutti i tuoi floppy, fino a quando avrai tutte le distribuzioni disponibili in questo formato. Ogni distribuzione dovrebbe andare in una sotto directory del floppy, esempio: a:\bin\bin.aa, a:\bin\bin.ab, e così via.
Una volta che arrivi alla schermata dei Media durante il processo di installazione, seleziona e segui le indicazioni che ti saranno fornite.
Per preparare un’installazione da una partizione MS-DOS®, devi copiare i file dalla distribuzione in una directory chiamata freebsd nella directory root della partizione. Per esempio, c:\freebsd. La struttura della directory del CDROM o del sito FTP deve essere parzialmente riprodotta in questa directory, dunque consigliamo di usare il comando xcopy del DOS se stai copiando da un CD. Per esempio, per preparare un’installazione minima di FreeBSD:
C:\> md c:\freebsd
C:\> xcopy e:\bin c:\freebsd\bin\ /s
C:\> xcopy e:\manpages c:\freebsd\manpages\ /sAssumendo che C: è dove hai spazio libero e E: è il CDROM.
Se non hai un lettore CDROM, puoi scaricare la distribuzione da ftp.FreeBSD.org. Ogni distribuzione è nella propria directory; per esempio, la distribuzione base può essere trovata nella directory 12.0/base/.
Se desideri installare diverse distribuzioni da una partizione MS-DOS® (ed hai lo spazio per farlo), installa ciascuna distribuzione in c:\freebsd - la distribuzione BIN è la sola richiesta per un’installazione minima.
Installare da un nastro magnetico è probabilmente un metodo più facile e breve rispetto a un’installazione da FTP o da CDROM. Il programma di installazione si aspetta che i file siano semplicemente magnetizzati su nastro. Dopo che hai ottenuto tutti i file della distribuzione a cui sei interessato, semplicemente fai un tar su nastro:
# cd /freebsd/distdir
# tar cvf /dev/rwt0 dist1 ... dist2Quando fai l’installazione, assicurati di lasciare abbastanza spazio in qualche directory temporanea (che ti sarà consentito scegliere) per disporre il contenuto completo del nastro che hai creato. A causa di un accesso non-random dei nastri, questo metodo di installazione richiede un pò di tempo per la memorizzazione temporanea.
Quando comincia l’installazione, il nastro deve essere nel lettore prima dell’avvio da floppy. Altrimenti il probe dell’installazione potrebbe fallire nel tentativo di cercarlo. |
Sono disponibili tre tipi di installazioni di rete. Via porta seriale (SLIP o PPP), via porta parallela (PLIP (cavo laplink)), o via Ethernet (un controller Ethernet standard (inclusi alcuni PCMCIA)).
Il supporto SLIP è piuttosto vecchio, e limitato principalmente a link connessi fisicamente, come con un cavo seriale cablato tra un computer portatile e un altro computer. Il collegamento dovrebbe essere fisico poichè SLIP a tutt’oggi non offre una capacità di chiamata remota; questa caratteristica è fornita dall’utility PPP, che dovrebbe essere usata al posto di SLIP quando possibile.
Se userai un modem, allora PPP è quasi certamente la tua unica scelta. Assicurati di avere le informazioni del tuo provider a portata di mano che ti saranno richieste nel processo di installazione.
Se usi PAP o CHAP per la connessione al tuo ISP (in altre parole, se puoi connetterti all’ISP in Windows® senza usare uno script), allora tutto quello che dovrai fare è digitare dial nel prompt di ppp. Altrimenti, avrai bisogno di sapere come chiamare il tuo ISP usando "comandi AT" specifici del tuo modem, poichè PPP fornisce solo un semplice emulatore di terminale. Per cortesia fai riferimento al manuale per il ppp-utente e alle FAQ. Se hai problemi, puoi mandare i log a video usando il comando set log local ….
Se è disponibile una connessione fisica ad un altro FreeBSD (2.0-R o successivi), potresti considerare l’installazione via cavo parallelo "laplink". La velocità di trasferimento di dati via porta parallela è molto più alta rispetto a quella realizzabile via seriale (fino a 50 kbyte/sec), ottenendo quindi un’installazione rapida.
Alla fine, per un’installazione più veloce possibile via rete, un adattatore Ethernet è sempre una buona scelta! FreeBSD supporta le più comuni schede di rete Ethernet per PC; una tabella di schede supportate (e i rispettivi settaggi richiesti) viene fornita nell’Hardware Note per ogni release di FreeBSD. Se usi una delle scheda PCMCIA Ethernet supportate, assicurati di inserirla prima di accendere il portatile! FreeBSD, sfortunatamente, non supporta ancora l’inserimento a caldo di una scheda PCMCIA durante l’installazione.
Inoltre dovrai sapere il tuo indirizzo IP della rete, il valore della netmask per la tua classe di indirizzi, e il nome della tua macchina. Se stai installando tramite una connessione PPP e non hai un IP statico, non temere, l’indirizzo IP può essere dinamicamente assegnato dal tuo ISP. Il tuo amministratore di sistema ti dirà quali valori usare per il tuo setup di rete. Se farai riferimento ad altri host tramite nomi piuttosto che tramite indirizzi IP, avrai bisogno di conoscere anche il server dns e forse anche l’indirizzo di un gateway (se stai usando PPP, è l’indirizzo IP del tuo provider) per poter comunicare con il server dns. Se vuoi installare via FTP passando per un proxy HTTP, avrai bisogno anche dell’indirizzo del proxy. Se non conosci tutte o in parte queste informazioni, dovrai parlare con il tuo amministratore di sistema o con l’ISP prima di tentare questo tipo di installazione.
L’installazione tramite NFS è abbastanza semplice. Devi copiare semplicemente i file della distribuzione interessata in un server NFS e quindi puntare il media al server NFS.
Se questo server supporta solo "porte privilegiate" (come in genere succede nelle workstation di Sun), dovrai settare l’opzione NFS Secure nel menì Options prima di procedere con l’installazione.
Se hai una scheda Ethernet di scarsa qualità con dei trasferimenti di rete molto lenti, potresti anche selezionare il flag NFS Slow.
Affinchè l’installazione NFS abbia successo, il server deve supportare il mount di sotto directory, per esempio, se la directory della distribuzione di FreeBSD 12.0 è in: ziggy:/usr/archive/stuff/FreeBSD, allora ziggy dovrà permettere il mount diretto di /usr/archive/stuff/FreeBSD, e non solo di /usr o di /usr/archive/stuff.
Nel file /etc/exports di FreeBSD, questo comportamento è controllato dalle opzioni -alldirs. Altri server NFS potrebbero avere diverse regole. Se ottieni il messaggio "permesso negato" dal server, allora è probabile che non hai abilitato queste opzioni.
Il seguente capitolo tratta i comandi e le funzionalità di base del sistema operativo FreeBSD. Molto di questo materiale è valido anche per altri sistemi operativi UNIX®-like. Sentiti libero di leggere velocemente questo capitolo se hai familiarità con questo materiale. Se sei un utente alle prime armi di FreeBSD, allora dovrai di sicuro leggere questo capitolo attentamente.
Dopo aver letto questo capitolo, saprai:
Come usare le "console virtuali" di FreeBSD.
Come funzionano i permessi dei file UNIX® oltre ad una spiegazione dei flag sotto FreeBSD.
La struttura di default del file system di FreeBSD.
L’organizzazione del disco di FreeBSD.
Come montare e smontare i file system.
Cosa sono i processi, i demoni e i segnali.
Cos’è una shell, e come cambiare il proprio ambiente di login di default.
I principi di base sull’uso degli editor testuali.
Cosa sono i dispositivi e i nodi dei dispositivi.
Quali formati dei binari sono usati in FreeBSD.
Come leggere le pagine man per ottenere maggiori informazioni.
FreeBSD può essere usato in vari modi. Uno di questi è quello di digitare i comandi tramite un terminale testuale. Quando si utilizza FreeBSD in questo modo si ha velocemente nelle proprie mani molta della flessibilità e della potenza di un sistema operativo UNIX®. Questa sezione descrive cosa sono i "terminali" e le "console", e come si possono utilizzare in FreeBSD.
Se non hai configurato FreeBSD in modo tale da avviare in modo automatico l’ambiente grafico durante l’avvio, il sistema ti fornirà un prompt di login dopo la fase di avvio, esattamente dopo che gli script di avvio sono stati eseguiti. Dovresti vedere qualcosa simile a questo:
Additional ABI support:.
Local package initialization:.
Additional TCP options:.
Fri Sep 20 13:01:06 EEST 2002
FreeBSD/i386 (pc3.example.org) (ttyv0)
login:I messaggi potrebbero essere leggermente diversi sul tuo sistema, tuttavia dovresti vedere qualcosa di analogo. In questo momento ci interessano le ultime due righe. Analizziamo la penultima riga:
FreeBSD/i386 (pc3.example.org) (ttyv0)
Questa riga contiene alcune informazioni sul sistema che hai appena avviato. Sei di fronte a una console "FreeBSD", che sta girando su un processore Intel o su un processore compatibile con l’architettura x86. Il nome di questa macchina (tutte le macchine UNIX® hanno un nome) è pc3.example.org, e in questo momento sei di fronte alla sua console di sistema-il terminale ttyv0.
Infine, l’ultima riga è sempre:
login:
Qui devi digitare il tuo "username" per loggarti in FreeBSD. La prossima sezione descrive come fare ad effettuare il login su FreeBSD.
FreeBSD è un sistema multi-utente e multi-processo. Questa è la descrizione formale che viene usualmente attribuita a un sistema che può essere usato da diverse persone, le quali eseguono contemporaneamente molti programmi su una singola macchina.
Ogni sistema multi-utente necessita di qualche metodo che distingua un "utente" in modo univoco. In FreeBSD (e in tutti i sistemi operativi UNIX®-like), questo viene realizzato richiedendo che ogni utente debba "loggarsi" nel sistema prima che possa eseguire qualche programma. Ogni utente ha un nome univoco (lo "username"), uno personale e una chiave segreta (la "password"). FreeBSD richiede entrambe queste due cose prima di dare la possibilità ad un utente di eseguire qualche programma.
Appena dopo la fase di avvio di FreeBSD e quando gli script di avvio sono stati eseguiti, ti viene presentato un prompt dove inserire un valido username:
login:Giusto per questo esempio, assumiamo che il tuo username sia john. Al prompt digita john e premi Invio. Ti verrà presentato un prompt dove inserire la "password":
login: john
Password:Digita la password di john, e premi Invio. La password non viene visualizzata! Non ti devi preoccupare di questo per ora. È sufficiente sapere che è una questione di sicurezza.
Se hai digitato la tua password in modo corretto, dovresti essere loggato in FreeBSD e sei quindi pronto per provare tutti i comandi disponibili.
Dovresti inoltre vedere il messaggio del giorno (MOTD) seguito da un prompt dei comandi (un carattere #, $, o %). Ciò indica che sei a tutti gli effetti loggato su FreeBSD.
Eseguire comandi UNIX® in una sola console va bene, tuttavia FreeBSD può eseguire più programmi alla volta. Avere una sola console dove poter digitare i comandi può essere un pò uno spreco quando un sistema operativo come FreeBSD è in grado di eseguire dozzine di programmi contemporaneamente. È in questo caso che le "console virtuali" possono essere molto utili.
FreeBSD può essere configurato in modo tale da poter utilizzare differenti console virtuali. Puoi passare da una console virtuale ad un’altra digitando un paio di tasti sulla tastiera. Ogni console ha il proprio canale di output indipendente, e FreeBSD si occupa di redirigere correttamente l’input della tastiera e l’output del monitor quando passi da una console virtuale in un’altra.
In FreeBSD alcune combinazioni speciali di tasti sono state riservate per il passaggio tra le console. Puoi usare Alt+F1, Alt+F2, fino a Alt+F8 per cambiare console su FreeBSD.
Quando passi da una console ad un’altra, FreeBSD si preoccupa di salvare e ripristinare l’output a video. Il risultato è l'"illusione" di avere più schermi e più tastiere "virtuali" che puoi utilizzare per dare in pasto a FreeBSD dei comandi. I programmi che lanci su una console virtuale rimarranno in esecuzione anche quando la console non è visibile. L’esecuzione di questi programmi continua quando passi in un’altra console virtuale.
La configurazione di default di FreeBSD prevede l’avvio del sistema con otto console virtuali. Comunque questo non è un settaggio obbligatorio, e puoi facilmente personalizzare la tua installazione in modo tale da avviare il sistema con qualche console virtuale in più o in meno. Il numero e i settaggi delle console virtuali sono configurati nel file /etc/ttys.
Puoi usare il file /etc/ttys per configurare le console virtuali di FreeBSD. In questo file ogni riga non commentata (le righe che non iniziano con il carattere #) contiene i settaggi di un singolo terminale o di una singola console. La versione di default di questo file contenuta in FreeBSD configura nove console virtuali, ed abilita otto di queste. Sono le righe che iniziano con ttyv:
# name getty type status comments # ttyv0 "/usr/libexec/getty Pc" cons25 on secure # Terminali virtuali ttyv1 "/usr/libexec/getty Pc" cons25 on secure ttyv2 "/usr/libexec/getty Pc" cons25 on secure ttyv3 "/usr/libexec/getty Pc" cons25 on secure ttyv4 "/usr/libexec/getty Pc" cons25 on secure ttyv5 "/usr/libexec/getty Pc" cons25 on secure ttyv6 "/usr/libexec/getty Pc" cons25 on secure ttyv7 "/usr/libexec/getty Pc" cons25 on secure ttyv8 "/usr/X11R6/bin/xdm -nodaemon" xterm off secure
Per una descrizione più dettagliata su ogni colonna di questo file e per tutte le opzioni che puoi utilizzare per settare le console virtuali, consulta la pagina man ttys(5).
Una descrizione dettagliata del significato della "modalità single user" può essere trovata nella Modalità Singolo Utente. È bene notare che c’è un’unica console quando avvii FreeBSD in modalità single user. Le console virtuali non sono disponibili. Anche i settaggi della console in modalità single user possono essere trovati nel file /etc/ttys. Guarda la riga che inizia con console:
# name getty type status comments # # Se la console è definita "insecure", allora il processo init richiederà la password di root # quando entrerai in modalità single-user. console none unknown off secure
Come riportato nel commento sopra la riga Pensaci comunque due volte a settare il parametro |
La modalità video di default della console di FreeBSD può essere impostata a 1024x768, 1280x1024, o ad un altra risoluzione supportata dalla tua scheda grafica e dal tuo monitor. Per usare una modalità video differente, devi prima ricompilare il tuo kernel aggiungendo due opzioni:
options VESA options SC_PIXEL_MODE
Quando il kernel è stato ricompilato con queste due opzioni, puoi determinare quali modalità video sono supportate dal tuo hardware usando l’utility vidcontrol(1). Per ottenere una lista delle modalità video supportate, digita il seguente comando:
# vidcontrol -i modeL’output di questo comando è una lista delle modalità video che sono supportate dal tuo hardware. Puoi usare una nuova modalità video indicandola a vidcontrol(1) in una console root:
# vidcontrol MODE_279Se la nuova modalità è soddisfacente, può essere impostata in modo permanente ad ogni avvio nel file /etc/rc.conf:
allscreens_flags="MODE_279"
FreeBSD, essendo un discendente diretto dello UNIX® BSD, si basa su molti concetti chiave di UNIX®. Il primo e il più affermato è che FreeBSD è un sistema operativo multi-utente. Il sistema può gestire diversi utenti che lavorano contemporaneamente su operazioni indipendenti. Il sistema è responsabile della gestione e della suddivisione appropriata delle richieste di utilizzo dei dispositivi hardware, delle periferiche, della memoria, e del tempo di CPU in modo equo per ogni utente.
Poichè il sistema è in grado di supportare più utenti, tutto ciò che il sistema gestisce possiede un insieme di permessi che determinano chi può leggere, scrivere, ed eseguire la risorsa. Questi permessi sono memorizzati mediante tre ottetti suddivisi in tre parti, una per il proprietario del file, una per il gruppo al quale il file appartiene, e una per tutti gli altri. Questa rappresentazione numerica funziona in questo modo:
| Valore | Permessi | Listato nella Directory |
|---|---|---|
0 | Lettura no, scrittura no, esecuzione no |
|
1 | Lettura no, scrittura no, esecuzione |
|
2 | Lettura no, scrittura, esecuzione no |
|
3 | Lettura no, scrittura, esecuzione |
|
4 | Lettura, scrittura no, esecuzione no |
|
5 | Lettura, scrittura no, esecuzione |
|
6 | Lettura, scrittura, esecuzione no |
|
7 | Lettura, scrittura, esecuzione |
|
Puoi usare l’opzione -l del comando ls(1) per visualizzare un lungo listato della directory che include una colonna contenente le informazioni sui permessi del file per il proprietario, per il gruppo, e per gli altri. Per esempio, digitando ls -l in una arbitraria directory:
% ls -l
total 530
-rw-r--r-- 1 root wheel 512 Sep 5 12:31 myfile
-rw-r--r-- 1 root wheel 512 Sep 5 12:31 otherfile
-rw-r--r-- 1 root wheel 7680 Sep 5 12:31 email.txt
...Ecco come è suddivisa la prima colonna dell’output del comando ls -l:
-rw-r--r--Il primo carattere (partendo da sinistra) indica se il file in questione è un file regolare, una directory, un file speciale per dispositivi a caratteri, una socket, o un file speciale per altri dispositivi. Nel nostro caso, il - indica un file regolare. I tre caratteri successivi, che in questo esempio sono rw-, indicano i permessi per il proprietario del file. Seguono altri tre caratteri, r--, che indicano i permessi del gruppo al quale il file appartiene. Gli ultimi tre caratteri, r--, indicano i permessi per il resto del mondo. Un trattino significa che il permesso non viene concesso. Nel caso di questo file, i permessi sono settati affinchè il proprietario possa leggere e scrivere il file, il gruppo possa leggere il file, e il resto del mondo possa solamente leggere il file. In accordo con la precedente tabella, i permessi per questo file sono 644, dove ogni cifra rappresenta una delle tre parti che costituiscono i permessi del file.
D’accordo, ma in che modo il sistema controlla i permessi sui dispositivi? FreeBSD tratta molti dispositivi hardware esattamente come un file che i programmi possono aprire, leggere, e scrivere dei dati proprio come avviene con gli altri file. Questi file speciali per i dispositivi sono memorizzati nella directory /dev.
Anche le directory sono trattate come file. Queste hanno permessi di lettura, scrittura e di esecuzione. Il bit riferito al permesso di esecuzione per una directory ha un significato leggermente differente rispetto a quello dei file. Quando una directory ha il permesso di esecuzione abilitato, significa che si ha accesso alla directory, ossia è possibile eseguire il comando "cd" (cambio di directory) per entrarci. Inoltre questo significa che all’interno della directory è possibile accedere ai file dei quali si conosce il nome (naturalmente a condizione dei permessi degli stessi file).
In particolare, per visualizzare il contenuto di una directory, deve essere abilitato il permesso di lettura sulla stessa, mentre per eliminare un file di cui si conosce il nome, è necessario che la directory contenente il file abbia i permessi di scrittura e di esecuzione abilitati.
Ci sono altri bit per permessi particolari, ma sono in genere usati in circostanze speciali come il permesso di setuid per i binari e quello di sticky per le directory. Se vuoi avere più informazioni sui permessi dei file e su come settarli, guarda la pagina man di chmod(1).
I permessi simbolici, qualche volta chiamati espressioni simboliche, usano caratteri al posto dei numeri ottali per assegnare i permessi a file o directory. Le espressioni simboliche usano la sintassi (chi) (azione) (permessi), con i seguenti valori:
| Opzione | Lettera | Cosa rappresenta/Cosa fa |
|---|---|---|
(chi) | u | Utente |
(chi) | g | Gruppo di appartenenza |
(chi) | o | Altri |
(chi) | a | Tutti (tutto il "mondo") |
(azione) | + | Aggiunge i permessi |
(azione) | - | Rimuove i permessi |
(azione) | = | Setta esplicitamente i permessi |
(permessi) | r | Lettura |
(permessi) | w | Scrittura |
(permessi) | x | Esecuzione |
(permessi) | t | Bit sticky |
(permessi) | s | Setta UID o GID |
Questi valori sono usati con il comando chmod(1) come esposto in precedenza, ma con le lettere. Per esempio, puoi usare il seguente comando per impedire agli altri utenti l’accesso a FILE:
% chmod go= FILESe si ha la necessità di realizzare più di una modifica ai settaggi di un file si può usare una lista di settaggi separati da virgola. Per esempio il seguente comando rimuoverà il permesso di scrittura su FILE al gruppo di appartenenza del file e al resto del "mondo", e inoltre aggiungerà il permesso di esecuzione per tutti:
% chmod go-w,a+x FILEOltre ai permessi dei file discussi in precedenza, FreeBSD supporta l’uso dei "flag dei file". Queste flag aggiungono un ulteriore livello di sicurezza e di controllo sui file, ma non per le directory.
Queste flag dei file aggiungono un ulteriore livello di controllo sui file, assicurando in alcuni casi che persino root non possa rimuovere o alterare file.
Le flag dei file sono alterate usando l’utility chflags(1), tramite una semplice sintassi. Per esempio, per abilitare la flag di sistema di non-cancellabilità sul file file1, si può usare il comando seguente:
# chflags sunlink file1E per disabilitare la stessa flag, si può usare semplicemente il comando precedente con "no" davanti a sunlink. Ecco come:
# chflags nosunlink file1Per vedere le flag del file di esempio, usa il comando ls(1) con le flag -lo:
# ls -lo file1L’output dovrebbe assomigliare al seguente:
-rw-r--r-- 1 trhodes trhodes sunlnk 0 Mar 1 05:54 file1
Diverse flag possono essere aggiunte o rimosse sui file solo tramite l’utente root. Negli altri casi, il proprietario dei file può settare queste flag. Si raccomanda di leggere le pagine man chflags(1) e chflags(2) per maggiori informazioni.
La gerarchia delle directory di FreeBSD è fondamentale per ottenere una comprensione globale del sistema. Il concetto più importante da cogliere al volo è quello relativo alla directory root, "/". Questa directory è la prima ad essere montata all’avvio e contiene gli elementi fondamentali del sistema necessari per predisporre il sistema operativo al funzionamento multi-utente. Inoltre la directory root contiene i punti di mount per gli altri file system che sono montati durante la transizione per il funzionamento multi-utente.
Un punto di mount è una directory dove dei file system aggiuntivi possono essere innestati sul file system padre (in genere il file system root). Questo è ulteriormente descritto nella Organizzazione del Disco. Alcuni punti di mount standard sono /usr, /var, /tmp, /mnt, e /cdrom. Queste directory compaiono in genere negli elementi del file /etc/fstab. Il file /etc/fstab è una tabella di file system e punti di mount che viene consultata dal sistema. Molti dei file system riferiti nel file /etc/fstab sono montati in modo automatico all’avvio tramite lo script rc(8) a meno che essi sia stati dichiarati con l’opzione noauto. Maggiori dettagli possono essere trovati nella Il File fstab.
Una descrizione completa della gerarchia del file system è disponibile nella pagina man hier(7). Per ora, è sufficiente una breve panoramica generale delle directory più comuni.
| Directory | Descrizione |
|---|---|
/ | Directory root del file system. |
/bin/ | Utilità fondamentali per l’utente sia in ambiente mono-utente sia in ambiente multi-utente. |
/boot/ | Programmi e file di configurazione utilizzati durante la fase di avvio del sistema operativo. |
/boot/defaults/ | File di configurazione di avvio di default; consultare loader.conf(5). |
/dev/ | Nodi di dispositivo; consultare intro(4). |
/etc/ | Script e file di configurazione del sistema. |
/etc/defaults/ | File di configurazione di default del sistema; consultare rc(8). |
/etc/mail/ | File di configurazione per gli MTA (Mail Transfer Agent, agente di trasferimento della posta elettronica) come sendmail(8). |
/etc/namedb/ | File di configurazione di |
/etc/periodic/ | Script che sono eseguiti giornalmente, settimanalmente, e mensilmente tramite cron(8); consultare periodic(8). |
/etc/ppp/ | File di configurazione di |
/mnt/ | Directory vuota usata comunemente dagli amministratori di sistema come punto di mount temporaneo. |
/proc/ | File system dedicato ai processi; consultare procfs(5), mount_procfs(8). |
/rescue/ | Programmi linkati staticamente per situazioni di emergenza; consultare rescue(8). |
/root/ | Directory home per l’account |
/sbin/ | Programmi di sistema e utilità di amministrazione fondamentali sia in ambiente mono-utente sia in ambiente multi-utente. |
/tmp/ | File temporanei. Il contenuto di /tmp di solito NON è preservato dopo un riavvio del sistema. Spesso un file system basato sulla memoria viene montato in /tmp. Questo può essere automatizzato usando le variabili relative a tmpmfs di rc.conf(5) (o con un entry in /etc/fstab; consultare mdmfs(8)). |
/usr/ | La maggior parte delle applicazioni e delle utilità dell’utente. |
/usr/bin/ | Utilità, strumenti di programmazione, e applicazioni comuni. |
/usr/include/ | File include standard del C. |
/usr/lib/ | Archivio di librerie. |
/usr/libdata/ | Archivio di dati per utilità varie. |
/usr/libexec/ | Demoni di sistema & utilità di sistema (eseguiti da altri programmi). |
/usr/local/ | Eseguibili locali, librerie locali, ecc. Usata anche come destinazione di default per la struttura dei port di FreeBSD. All’interno di /usr/local, viene usato lo stesso schema generale descritto in hier(7) per la directory /usr. Le eccezioni sono la directory man, che è posta direttamente sotto /usr/local piuttosto che sotto /usr/local/share, e la documentazione dei port che è in share/doc/port. |
/usr/obj/ | Albero degli elementi dipendenti dal tipo di architettura dell’elaboratore prodotto dalla costruzione dell’albero /usr/src. |
/usr/ports | Collezione dei port di FreeBSD (opzionale). |
/usr/sbin/ | Demoni di sistema & utilità di sistema (eseguiti dagli utenti). |
/usr/shared/ | File indipendenti dal tipo di architettura dell’elaboratore. |
/usr/src/ | File sorgenti di BSD e/o sorgenti proprietari. |
/usr/X11R6/ | Eseguibili, librerie, ecc. riguardanti la distribuzione X11R6 (opzionale). |
/var/ | File log di vario genere, file temporanei, file transitori, e file di spool. Qualche volta un file system basato sulla memoria è montato in /var. Questo può essere automatizzato usando le variabili relative a varmfs di rc.conf(5) (o con un entry in /etc/fstab; consultare mdmfs(8)). |
/var/log/ | File di log del sistema di vario genere. |
/var/mail/ | File delle caselle di posta degli utenti. |
/var/spool/ | Directory di spool per stampanti e per la posta elettronica del sistema. |
/var/tmp/ | File temporanei. I file sono di solito preservati dopo un riavvio del sistema, a meno che /var sia un file system basato sulla memoria. |
/var/yp | Mappe NIS. |
La più piccola unità di organizzazione che FreeBSD usa per ricercare file è il nome del file. I nomi dei file sono case-sensitive, ciò significa che readme.txt e README.TXT sono due file distinti. FreeBSD non usa l’estensione (es. .txt) di un file per determinare se il file è un programma, un documento, o qualche altra forma di dati.
I file sono memorizzati in directory. Una directory può contenere centinaia di file o non contenerne affatto. Inoltre una directory può contenere altre directory, consentendo di costruire una gerarchia di directory all’interno di un’altra. Tutto questo rende più facile l’organizzazione dei tuoi dati.
Ci si riferisce a file e directory attraverso il nome del file o della directory, seguito da uno slash in avanti, /, a sua volta seguito da altri nomi di directory necessari. Se hai una directory di nome foo, la quale contiene la directory bar, che a sua volta contiene il file readme.txt, allora il nome completo, chiamato anche il percorso del file è foo/bar/readme.txt.
Le directory e i file sono memorizzati in un file system. Ogni file system contiene esattamente una directory al livello più alto, chiamata la directory root di quel file system. Questa directory root può contenere altre directory.
Fin qui è probabilmente tutto simile ad altri sistemi operativi che hai usato. Tuttavia ci sono alcune differenze; per esempio, MS-DOS® usa il carattere \ per separare i nomi di file e directory, mentre Mac OS® usa :.
FreeBSD non usa lettere di dispositivi, o altri nomi di dispositivi nel path. In FreeBSD non dovrai mai scrivere c:/foo/bar/readme.txt.
Piuttosto, un file system è designato come il file system root. La directory root del file system root è riferita con /. Ogni altro file system è montato sotto il file system root. Non importa quanti dischi hai sul tuo sistema FreeBSD, ogni directory è come se fosse parte dello stesso disco.
Supponiamo che tu abbia tre file system, chiamati A, B, e C. Ogni file system ha una directory root, la quale contiene altre due directory, chiamate A1, A2 (e nello stesso modo B1, B2 e C1, C2).
Sia A il file system root. Se usi il comando ls per visualizzare il contenuto di questa directory dovresti vedere due sottodirectory, A1 e A2. L’albero delle directory assomiglia a questo:
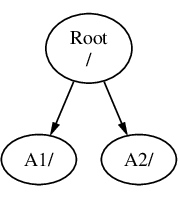
Un file system deve essere montato su una directory di un altro file system. Supponiamo ora che tu monti il file system B sulla directory A1. La directory root di B rimpiazza A1, e di conseguenza appariranno le directory di B:
I file contenuti nelle directory B1 o B2 possono essere raggiunti con il path /A1/B1 o /A1/B2. I file che erano in /A1 sono stati temporaneamente nascosti. Questi riappariranno quando B sarà smontato da A.
Se B è stato montato su A2 allora il diagramma assomiglierà a questo:
e i percorsi saranno rispettivamente /A2/B1 e /A2/B2.
I file system possono essere montati in cima ad altri file system. Continuando con l’ultimo esempio, il file system C può essere montato in cima alla directory B1 nel file system B, arrivando a questa sistemazione:
Oppure C potrebbe essere montato direttamente sul file system A, sotto la directory A1:
Se hai familiarità con MS-DOS®, questo è simile, ma non identico, al comando join.
Di solito non ti devi occupare direttamente di questi aspetti. Tipicamente quando installi FreeBSD crei i file system e decidi dove montarli, e da quel momento non avrai più la necessità di modificarli a meno che installi un nuovo disco.
È possibile avere un unico file system root, senza avere la necessità di crearne altri. Esistono alcuni svantaggi utilizzando questo approccio, e un solo vantaggio.
Filesystem diversi possono avere opzioni di mount diverse. Per esempio, in un’attenta progettazione, il file system root potrebbe essere montato in modalità di sola lettura, rendendo impossibile la cancellazione accidentale o la modifica di un file critico. Inoltre, separando i file system scrivibili dall’utente, come /home, da altri file system permette di montare i primi con l’opzione nosuid; questa opzione non permette il settaggio dei bit suid/guid sui file eseguibili memorizzati sul file system che ha tale opzione di mount attivata, migliorando l’aspetto sicurezza.
FreeBSD ottimizza in modo automatico la disposizione dei file sul file system, a seconda di come è usato il file system. Quindi un file system che contiene molti file piccoli che sono scritti di frequente avrà un’ottimizzazione diversa rispetto ad un altro file system che contiene pochi file di grandi dimensioni. Utilizzando un solo grande file system questa ottimizzazione viene a mancare.
I file system di FreeBSD reagiscono bene ad una violenta perdita di energia elettrica. Tuttavia, una perdita di energia in un punto critico potrebbe sempre danneggiare la struttura del file system. Splittando i tuoi dati su file system multipli sarà più probabile che il sistema riparta, dandoti la possibilità di ripristinare un precedente backup se necessario.
I file system sono a dimensione fissa. Se crei un solo file system quando installi FreeBSD e gli assegni una data dimensione, in futuro potresti scoprire che necessiti di creare una partizione più grande. Questo non è facilmente realizzabile se non effettuando un backup dei dati, ricreando il file system con la nuova dimensione, e quindi ripristinando il backup di dati.
FreeBSD ha il comando growfs(8), con il quale è possibile incrementare la dimensione del file system al volo, rimuovendo questa limitazione. |
I file system sono contenuti all’interno di partizioni. Qui il significato del termine partizione si discosta dall’uso comune di questo termine (partizioni MS-DOS®, per esempio), a causa dell’eredità UNIX® di FreeBSD. Ogni partizione è identificata da una lettera partendo dalla a fino alla h. Ogni partizione può contenere solo un file system, il che significa che i file system sono spesso identificati sia dal loro punto di mount nella gerarchia del file system, sia dalla lettera della partizione nella quale sono contenuti.
Inoltre FreeBSD usa parte del disco per lo spazio di swap. Lo spazio di swap fornisce a FreeBSD la funzionalità di memoria virtuale. Questo permette al tuo computer di comportarsi come se avesse più memoria di quella che ha realmente. Quando FreeBSD esaurisce la memoria muove alcuni dati presenti in memoria che non sono utilizzati in quel momento nello spazio di swap, e li riporta in memoria (spostando nello spazio di swap qualche altro dato) non appena necessari.
Alcune partizioni hanno certe convenzioni a loro associate.
| Partizione | Convenzione |
|---|---|
| In genere contiene il file system root |
| In genere contiene lo spazio di swap |
| Di solito rappresenta l’intera dimensione della slice. Questo permette a utility che necessitano di lavorare sull’intera slice (per esempio, uno scanner di blocchi difettosi) di lavorare sulla partizione |
| La partizione |
Ogni partizione contenente un file system è memorizzata in ciò che FreeBSD chiama slice. Slice è un termine di FreeBSD per identificare ciò che comunemente viene chiamato partizione, e di nuovo, questo è dovuto dal background UNIX® di FreeBSD. Le slice sono numerate, partendo da 1 e arrivando fino a 4.
I numeri di slice seguono il nome del dispositivo, preceduti da una s, e partendo da 1. Quindi "da0s1" è la prima slice sul primo disco SCSI. Ci possono essere solo quattro slice fisiche su un disco, ma puoi avere slice logiche all’interno di slice fisiche di un appropriato tipo. Queste slice estese sono numerate a partire da 5, quindi "ad0s5" è la prima slice estesa sul primo disco IDE. Questi stratagemmi sono usati per i file system che si aspettano di occupare una slice.
Le slice, i dispositivi fisici "pericolosamente dedicati", e altri dispositivi contengono partizioni, le quali sono rappresentate tramite lettere dalla a fino alla h. Queste lettere seguono il nome del dispositivo, quindi "da0a" è la partizione a sul primo dispositivo da, il quale è "pericolosamente dedicato". "ad1s3e" è la quinta partizione nel terza slice del secondo disco IDE.
In fine, ogni disco sul sistema è identificato. Un nome di un disco incomincia con un codice che indica il tipo di disco, seguito da un numero, che indica quale disco esso sia. A differenza delle slice, i numeri riferiti al disco incominciano da 0. Puoi vedere dei codici generici in Codici dei Dispositivi Disco.
Quando fai riferimento a una partizione di FreeBSD devi specificare anche il nome della slice e del disco che contengono la partizione, e quando fai riferimento a una slice dovresti specificare anche il nome del disco. Per riferirti ad una partizione specifica quindi il nome del disco, il carattere s, il numero di slice, e infine la lettera della partizione. Alcuni esempi sono mostrati nell'Esempi di Nomi di Dischi, di Slice, e di Partizioni.
L'Modello Concettuale di un Disco mostra un modello concettuale di struttura di un disco che dovrebbe aiutare a chiarire le cose.
Per installare FreeBSD devi prima configurare le slice del disco, creare le partizioni all’interno della slice che vuoi usare per FreeBSD, e quindi creare un file system (o spazio di swap) in ogni partizione, e decidere dove il file system deve essere montato.
| Codice | Significato |
|---|---|
ad | disco ATAPI (IDE) |
da | disco ad accesso diretto SCSI |
acd | CDROM ATAPI (IDE) |
cd | CDROM SCSI |
fd | Disco floppy |
| Nome | Significato |
|---|---|
| La prima partizione ( |
| La quinta partizione ( |
Questo diagramma mostra come FreeBSD vede il primo disco IDE attaccato al sistema. Si assuma che il disco sia di 4 GB, e che contenga due slice da 2 GB (equivalenti come significato a due partizioni MS-DOS®). La prima slice contiene un disco MS-DOS®, C:, e la seconda slice contiene un’installazione di FreeBSD. In questo esempio l’installazione di FreeBSD ha tre partizioni dati più una di swap.
Le tre partizioni conterranno ognuna un file system. La partizione a sarà usata per il file system root, la e per la gerarchia di directory /var, e la partizione f per la gerarchia di directory /usr.

Il file system è raffigurato in maniera ottimale da un albero, radicato, per così dire, in /. Le directory /dev, /usr, e le altre directory che stanno all’interno della directory root sono i rami, i quali possono essere a loro volta ramificati, come in /usr/local, e così via.
Esistono varie ragioni per mantenere alcune di queste directory su file system separati. La directory /var contiene le directory log/, spool/, e vari tipi di file temporanei, e come tale, può riempirsi. Riempire il file system root non è una buona idea, quindi scindere la directory /var da / è spesso vantaggioso.
Un’altra motivazione per mantenere certi alberi di directory su altri file system è quando questi alberi sono alloggiati su dischi fisici separati, o sono dischi virtuali separati, come avviene per i mount del Network File System, o dei dispositivi CDROM.
Durante la fase di avvio, i file system elencati nel file /etc/fstab sono montati in modo automatico (a meno che siano specificati con l’opzione noauto).
Il file /etc/fstab contiene una serie di righe il cui formato è il seguente:
device /mount-point fstype options dumpfreq passno
deviceIl nome del dispositivo (che deve esistere), come spiegato nella Device Names.
mount-pointLa directory (che deve esistere), sulla quale montare il file system.
fstypeIl tipo di file system da passare a mount(8). Il file system di default di FreeBSD è ufs.
optionsrw per file system leggibili-scrivibili, oppure ro per file system solamente leggibili, seguite da altre opzioni che potrebbero essere necessarie. Un’opzione comune è noauto per i file system che normalmente non sono montati durante la sequenza di avvio. Altre opzioni sono elencate nella pagina man di mount(8).
dumpfreqViene usato da dump(8) per determinare quali file system richiedono un dump. Se non si specifica nulla, viene assunto il valore zero.
passnoDetermina l’ordine secondo il quale i file system vengono controllati. I file system che devono saltare il controllo devono avere i loro passno settati a zero. Il file system root (che deve essere controllato prima di qualsiasi altra cosa) deve avere il suo passno settato a uno, e i passno degli altri file system devono essere settati a valori maggiori di uno. Se più di un file system ha lo stesso passno allora fsck(8) tenterà di controllare i file system in parallelo.
Per maggiori informazioni sul formato del file /etc/fstab e sulle opzioni che esso contiene consulta la pagina man fstab(5).
mountIl comando mount(8) è ciò che in definitiva viene usato per montare i file system.
La sua forma di utilizzo elementare è:
# mount device mountpointEsistono molte opzioni, come spiegato nella pagina man di mount(8), ma le più comuni sono:
-aMonta tutti i file system elencati nel file /etc/fstab. Le eccezioni sono quei file system specificati come "noauto", quelli esclusi dalla flag -t, o quei file system che sono già montati.
-dFà tutto ad eccezione della attuale system call di mount. Questa opzione risulta utile in congiunzione con la flag -v per determinare quello che mount(8) sta effettivamente tentando di fare.
-fForza il mount di un file system non correttamente smontato (pericoloso), o forza la revoca di accesso in scrittura quando si declassa lo stato di mount di un file system da lettura-scrittura a lettura solamente.
-rMonta il file system in sola lettura. Questo è identico ad usare l’argomento ro (rdonly per versioni di FreeBSD dopo la 5.2) con l’opzione -o.
-t fstypeMonta il dato file system secondo il tipo di file system specificato, oppure, se affiancato dall’opzione -a, monta solamente i file system di un dato tipo.
"ufs" è il tipo di file system di default.
-uAggiorna le opzioni di mount sul file system.
-vModalità verbosa.
-wMonta il file system in lettura-scrittura.
L’opzione -o accetta una lista di argomenti separati da una virgola, inclusi i seguenti:
Non permette l’esecuzione di binari su questo file system. Questa è un’altra utile opzione di sicurezza.
Non permette l’interpretazione delle flag setuid o setgid sul file system. Anche questa è un’utile opzione di sicurezza.
umountIl comando umount(8) accetta, come unico parametro, un punto di mount, un nome di dispositivo, l’opzione -a o l’opzione -A.
Tutte queste modalità accettano l’opzione -f per forzare la smontatura, e l’opzione -v per la modalità verbosa. Sei avvisato che l’opzione -f non è in generale un buona idea. Smontare in modo forzato i file system può mandare in crash il computer o danneggiare i dati sul file system.
Le opzioni -a e -A sono usate per smontare tutti i file system, con la possibilità di specificare i tipi di file system elencandoli dopo la flag -t. Tuttavia, l’opzione -A non tenta di smontare il file system root.
FreeBSD è un sistema operativo multi-tasking. Con questa capacità il sistema è come se potesse eseguire più di un programma alla volta. Ogni programma in esecuzione in un dato istante è chiamato processo. Ogni volta che esegui un comando fai partire almeno un nuovo processo, e ci sono molti processi di sistema che sono sempre in esecuzione, che permettono il corretto funzionamento del sistema.
Ogni processo è identificato in modo univoco da un numero chiamato process ID, o PID, e, come avviene per i file, ogni processo ha un proprietario e un gruppo. Le informazioni sul proprietario e sul gruppo sono usate per determinare, tramite il meccanismo dei permessi dei file discusso precedentemente, quali file e quali dispositivi il processo può aprire. Inoltre molti processi hanno un processo padre. Tale processo è il processo che li ha generati. Per esempio, se stai digitando dei comandi in shell allora la shell è un processo, così come lo sono i comandi che esegui. Ogni processo che esegui in questo modo avrà come suo processo padre la tua shell. L’eccezione a questo meccanismo è un processo speciale chiamato init(8). Il processo init è sempre il primo processo, quindi il suo PID è sempre 1. init viene avviato in modo automatico dal kernel quando si avvia FreeBSD.
Due comandi sono particolarmente utili per monitorare i processi sul sistema, ps(1) e top(1). Il comando ps è usato per mostrare una lista statica dei processi che sono in esecuzione in quel momento, e può mostrare i loro PID, quanta memoria stanno usando, la linea di comando che li ha avviati, e altro ancora. Il comando top visualizza tutti i processi in esecuzione, e aggiorna queste informazioni ogni qualche secondo, in modo che puoi vedere interattivamente cosa sta facendo il tuo computer.
Di default, ps mostra solo i tuoi comandi che sono in quel momento in esecuzione. Per esempio:
% ps
PID TT STAT TIME COMMAND
298 p0 Ss 0:01.10 tcsh
7078 p0 S 2:40.88 xemacs mdoc.xsl (xemacs-21.1.14)
37393 p0 I 0:03.11 xemacs freebsd.dsl (xemacs-21.1.14)
48630 p0 S 2:50.89 /usr/local/lib/netscape-linux/navigator-linux-4.77.bi
48730 p0 IW 0:00.00 (dns helper) (navigator-linux-)
72210 p0 R+ 0:00.00 ps
390 p1 Is 0:01.14 tcsh
7059 p2 Is+ 1:36.18 /usr/local/bin/mutt -y
6688 p3 IWs 0:00.00 tcsh
10735 p4 IWs 0:00.00 tcsh
20256 p5 IWs 0:00.00 tcsh
262 v0 IWs 0:00.00 -tcsh (tcsh)
270 v0 IW+ 0:00.00 /bin/sh /usr/X11R6/bin/startx -- -bpp 16
280 v0 IW+ 0:00.00 xinit /home/nik/.xinitrc -- -bpp 16
284 v0 IW 0:00.00 /bin/sh /home/nik/.xinitrc
285 v0 S 0:38.45 /usr/X11R6/bin/sawfishCome puoi vedere in questo esempio, l’output di ps(1) è organizzato in molte colonne. La colonna PID si riferisce al process ID discusso poco fà. I PID sono assegnati partendo dal numero 1, andando fino al 99999, e ricominciando dall’inizio una volta esauriti (se disponibili). La colonna TT mostra su quale tty il programma è in esecuzione, e può essere benissimo ignorata per il momento. La colonna STAT mostra lo stato del programma, e di nuovo, può essere benissimo ignorata. La colonna TIME indica per quanto tempo il programma è stato in esecuzione sulla CPU-di solito non indica il tempo trascorso da quando hai avviato il programma, poichè la maggior parte dei programmi trascorrono molto tempo in attesa per faccende che accadono prima che questi possano trascorrere del tempo in CPU. Infine, la colonna COMMAND indica la riga di comando che è stata utilizzata per eseguire il programma.
Il comando ps(1) supporta varie opzioni per cambiare le informazioni da visualizzare. Uno dei gruppi di opzioni più utili è auxww. L’opzione a mostra le informazioni riguardo a tutti i processi in esecuzione, non solo quelli che ti appartengono. L’opzione u mostra il nome utente del proprietario del processo, come pure la memoria utilizzata dal processo. L’opzione x mostra le informazioni riguardo ai processi demoni, e l’opzione ww indica a ps(1) di visualizzare la linea di comando completa che ha avviato il processo, piuttosto che troncarla quando è troppo lunga per essere adattata sullo schermo.
L’output di top(1) è simile. Un esempio di esecuzione assomiglia a questo:
% top
last pid: 72257; load averages: 0.13, 0.09, 0.03 up 0+13:38:33 22:39:10
47 processes: 1 running, 46 sleeping
CPU states: 12.6% user, 0.0% nice, 7.8% system, 0.0% interrupt, 79.7% idle
Mem: 36M Active, 5256K Inact, 13M Wired, 6312K Cache, 15M Buf, 408K Free
Swap: 256M Total, 38M Used, 217M Free, 15% Inuse
PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU COMMAND
72257 nik 28 0 1960K 1044K RUN 0:00 14.86% 1.42% top
7078 nik 2 0 15280K 10960K select 2:54 0.88% 0.88% xemacs-21.1.14
281 nik 2 0 18636K 7112K select 5:36 0.73% 0.73% XF86_SVGA
296 nik 2 0 3240K 1644K select 0:12 0.05% 0.05% xterm
48630 nik 2 0 29816K 9148K select 3:18 0.00% 0.00% navigator-linu
175 root 2 0 924K 252K select 1:41 0.00% 0.00% syslogd
7059 nik 2 0 7260K 4644K poll 1:38 0.00% 0.00% mutt
...L’output è diviso in due sezioni. La parte superiore (le prime cinque linee) mostra il PID dell’ultimo processo eseguito, il carico medio del sistema (che è un indice di quanto il sistema sia impegnato), il tempo di vita del sistema (il tempo passato dall’ultimo reboot) e l’ora corrente. I restanti numeri nella parte superiore riportano quanti processi sono in esecuzione (47 in questo caso), quanta memoria di sistema e quanta memoria di swap è stata utilizzata, e quanto tempo il sistema sta trascorrendo nei vari stati di CPU.
Sotto ci sono una serie di colonne che contengono simili informazioni a quelle contenute nell’output di ps(1). Come prima puoi vedere il PID, il nome utente, quanto tempo di CPU è stato utilizzato, e il comando che era stato eseguito. Inoltre il comando top(1) di default ti mostra quanta memoria è stata concessa al processo. Questa informazione è suddivisa in due colonne, una per la dimensione totale, e l’altra per la dimensione attuale-la dimensione totale è la quantità di memoria che l’applicazione ha richiesto, e la dimensione attuale è la quantità di memoria che sta utilizzando in quel momento. In questo esempio puoi vedere che Netscape ha richiesto quasi 30 MB di RAM, ma al momento ne sta usando solo 9 MB.
Il comando top(1) aggiorna in modo automatico queste informazioni ogni due secondi; questo lasso temporale può essere modificato con l’opzione s.
Quando esegui un editor risulta semplice averne il controllo, dirgli di caricare file, e così via. Tutto questo può essere fatto poichè l’editor fornisce delle agevolazioni in questo senso, e anche perchè l’editor è collegato a un terminale. Alcuni programmi non sono stati progettati per essere eseguiti con un continuo input dell’utente, e perciò questi programmi si disconnettono dal terminale alla prima occasione. Per esempio, un server web trascorre tutto il giorno rispondendo a richieste web, e normalmente non necessita di alcun input da parte tua. I programmi che trasportano la posta elettronica da un sito a un altro sito sono un altro esempio di questa classe di applicazioni.
Chiamiamo questi programmi demoni. I demoni erano dei personaggi della mitologia greca: nè buoni nè cattivi, erano piccoli spiriti custodi che, nel complesso, risultavano essere utili per l’umanità, molto similmente i server web e quelli di posta elettronica di oggi fanno cose utili. Ecco il motivo per cui la mascotte di BSD è stata per molto tempo, e lo è ancora, l’allegro demone con le scarpe da tennis e con il forcone.
Esiste la convenzione di chiamare i programmi che normalmente sono eseguiti come demoni con una "d" finale. BIND sta per Berkeley Internet Name Domain, ma il nome effettivo del programma che viene eseguito è named; il nome del programma Apache, un server web, è httpd; il demone dello spool di stampa è lpd e così via. Questa è una convenzione, non è una regola ferrea; per esempio, il principale demone di posta elettronica per l’applicazione Sendmail è chiamato sendmail, e non maild, come potresti aspettarti.
A volte puoi aver bisogno di comunicare con un processo demone. Un modo per farlo è di mandare a esso (o ad altri processi in esecuzione), un segnale. Esistono svariati segnali che puoi inviare-alcuni di questi hanno un significato specifico, altri sono interpretabili dall’applicazione, e la documentazione dell’applicazione ti dirà come l’applicazione stessa interpreta i segnali. Puoi mandare un segnale solo ai processi che ti appartengono. Se mandi un segnale a un processo che non ti appartiene con il comando kill(1) o kill(2), il permesso ti sarà negato. L’eccezione a questa regola riguarda l’utente root, che può mandare segnali a processi di chiunque.
Inoltre in alcune circostanze FreeBSD invia segnali alle applicazioni. Se un’applicazione è stata scritta malamente, e tenta di accedere alla memoria che non gli compete, FreeBSD manda al processo il segnale di Violazione della Segmentazione (SIGSEGV). Se un’applicazione ha utilizzato la system call alarm(3) in modo tale da essere avvisata dopo un certo periodo di tempo trascorso allora FreeBSD invierà a questa applicazione il segnale di Allarme (SIGALRM), e così via.
Per fermare un processo possono essere utilizzati due segnali, SIGTERM e SIGKILL. SIGTERM è il modo cortese di terminare un processo; il processo può catturare il segnale, capire che vuoi abbatterlo, chiudere i file di log che potrebbe avere aperto, e in genere terminare qualunque cosa che stava facendo prima dell’interruzione. Nei casi in cui un processo sia coinvolto in qualche compito che non può essere interrotto allora questo processo può persino ignorare SIGTERM.
Il segnale SIGKILL non può essere ignorato da un processo. Questo è il segnale che dice "Non mi interessa cosa stai facendo, fermati subito". Se mandi il segnale SIGKILL a un processo allora FreeBSD fermerà subito il processo.
Altri segnali che potresti aver bisogno di usare sono SIGHUP, SIGUSR1, e SIGUSR2. Questi sono segnali a scopo generico, e differenti applicazioni possono fare cose diverse quando catturano questi segnali.
Supponiamo che hai cambiato il file di configurazione del tuo server web-hai bisogno di dire al server web di rileggere la sua configurazione. Potresti fermare e riavviare httpd, ma questo porterebbe a un breve periodo di interruzione del tuo server web, che potrebbe non essere gradito. Molti demoni sono stati scritti per rispondere al segnale SIGHUP tramite la rilettura dei loro file di configurazione. In questo modo invece di terminare e riavviare httpd potresti inviare il segnale SIGHUP. Poichè non esiste un modo standard di trattare questi segnali, differenti demoni potrebbero avere un comportamento diverso, quindi assicurati di leggere la documentazione per il demone in questione.
I segnali sono inviati utilizzando il comando kill(1), come mostra questo esempio.
Procedure: Inviare un Segnale a un Processo
Questo esempio mostra come inviare un segnale a inetd(8). Il file di configurazione di inetd è /etc/inetd.conf, e inetd rilegge questo file di configurazione quando riceve il segnale SIGHUP.
Cerca il process ID del processo a cui vuoi mandare il segnale. Puoi utilizzare ps(1) e grep(1) per farlo. Il comando grep(1) viene utilizzato per perlustrare attraverso l’output, cercando la stringa da te specificata. Questo comando viene eseguito in modalità utente, e inetd(8) viene eseguito in modalità root, quindi le opzioni da dare a ps(1) sono ax.
% ps -ax | grep inetd
198 ?? IWs 0:00.00 inetd -wWUsa il comando kill(1) per inviare il segnale. Poichè inetd(8) viene eseguito in modalità root prima devi usare il comando su(1) per diventare root.
% su
Password:
# /bin/kill -s HUP 198Come avviene per la maggior parte dei comandi UNIX®, il comando kill(1) non stampa il risultato dell’operazione se questa ha avuto successo. Se mandi un segnale a un processo del quale non sei il proprietario allora vedrai il messaggio kill: PID: Operation not permitted. Se sbagli il PID invierai il segnale al processo sbagliato, il che potrebbe essere dannoso, o, se hai fortuna, manderai il segnale a un PID che in quel momento non è in uso, e in questo caso vedrai il messaggio kill: PID: No such process.
Perchè Usare /bin/kill?Molte shell forniscono il comando |
L’invio di altri segnali è analogo, basta sostituire all’occorrenza TERM o KILL nella linea di comando.
Terminare processi in modo random su un sistema può essere una cattiva idea. In particolare, il processo init(8), con process ID 1, è un caso molto speciale. Eseguire |
In FreeBSD, la maggior parte del lavoro di tutti i giorni viene svolto tramite un’interfaccia a riga di comando chiamata shell. Uno dei compiti principali di una shell è quello di prendere in input dei comandi ed eseguirli. Inoltre molte shell hanno delle funzioni built-in (incorporate) utili nei lavori ordinari come la gestione dei file, la sostituzione dei nomi dei file, la modifica della riga di comando, la creazione di macro di comandi, e la gestione delle variabili d’ambiente. FreeBSD si propone con una serie di shell, come la Shell Bourne, sh, e la versione successiva della C-shell, tcsh. Molte altre shell sono disponibili nella FreeBSD Ports Collection, come le shell zsh e bash.
Quale shell devi usare? È veramente una questione di gusti. Se sei un programmatore di C potresti sentirti a tuo agio con una shell C-like come la tcsh. Se vieni da Linux o non sei pratico dell’interfaccia a riga di comando di UNIX® potresti provare la bash. Il fatto è che ogni shell ha delle caratteristiche che possono o meno combaciare con il tuo ambiente di lavoro preferito, e quindi devi scegliere tu stesso quale shell utilizzare.
Una caratteristica comune in una shell è il completamento dei nomi dei file. Dopo aver digitato alcuni dei primi caratteri di un comando o di un nome di file, la shell di solito può completare in modo automatico il resto del comando o del nome del file tramite la pressione del tasto Tab sulla tastiera. Ecco un esempio. Supponiamo che hai due file chiamati foobar e foo.bar. Vuoi cancellare foo.bar. Quello che dovresti digitare sulla tastiera è: rm fo[Tab].[Tab].
La shell dovrebbe visualizzare rm foo[BEEP].bar.
Il [BEEP] è la campanella della console, che mi segnala che la shell è incapace di completare interamente il nome del file poichè esiste più di una sola corrispondenza. Sia foobar che foo.bar iniziano con fo, tuttavia la shell è riuscita a completarlo in foo. A questo punto premendo ., e poi di nuovo Tab, la shell sarà in grado di completare da sola il resto del nome del file.
Un altro aspetto di una shell è l’uso delle variabili d’ambiente. Le variabili d’ambiente sono una coppia di valori mutevoli memorizzati nello spazio dell’ambiente della shell. Questo spazio può essere letto dai programmi invocati dalla shell, e di conseguenza questo spazio può contenere le configurazioni di molti programmi. Qui sotto c’è una lista delle variabili d’ambiente più comuni con il loro rispettivo significato:
| Variabile | Descrizione |
|---|---|
| Il nome dell’utente attualmente loggato. |
| Lista di directory separate da due punti utilizzate per la ricerca dei binari. |
| Nome di rete del display X11 a cui connettersi, se disponibile. |
| La shell corrente. |
| Il nome del tipo di terminale dell’utente. Usato per determinare le capacità del terminale. |
| Serie di elementi di codici di escape del terminale utilizzati per realizzare svariate funzioni del terminale. |
| Il tipo di sistema operativo. FreeBSD, ad esempio. |
| L’architettura della CPU su cui il sistema gira. |
| L’editor di testo preferito dall’utente. |
| L’impaginatore di testo preferito dall’utente. |
| Lista di directory separate da due punti utilizzate nella ricerca delle pagine man. |
Il modo di settare una variabile d’ambiente varia leggermente a seconda della shell utilizzata. Per esempio, nelle shell C-Style come tcsh e csh, puoi usare setenv per settare le variabili d’ambiente. Sotto le shell Bourne come sh e bash, puoi usare export per settare le tue variabili d’ambiente correnti. Per esempio, per settare o modificare la variabile d’ambiente EDITOR a /usr/local/bin/emacs, sotto csh o tcsh si può utilizzare il comando:
% setenv EDITOR /usr/local/bin/emacsSotto le shell Bourne:
% export EDITOR="/usr/local/bin/emacs"Con la maggior parte delle shell puoi inoltre creare un’espansione di una variabile d’ambiente mettendo sulla riga di comando il simbolo $ davanti al nome della variabile stessa. Per esempio, echo $TERM visualizzerà ciò che corrisponde a $TERM, poichè la shell espande $TERM e passa il risultato a echo.
Le shell trattano molti caratteri speciali, chiamati meta-caratteri come rappresentazioni speciali di dati. Il più comune di questi è il simbolo *, che rappresenta diverse istanze di caratteri in un nome di file. Questi meta-caratteri possono essere usati per la sostituzione dei nomi di file. Per esempio, digitando echo * è quasi come aver digitato ls poichè la shell prende tutti i file che corrispondono a * e li mette sulla riga di comando con echo che quindi li visualizza.
Per impedire alla shell di interpretare questi caratteri speciali, questi possono essere messi in escape mettendo subito prima di essi un backslash (\). echo $TERM visualizza il tipo del tuo terminale. echo \$TERM visualizza $TERM così com’è.
Il modo più semplice per cambiare la propria shell è quello di usare il comando chsh. Eseguendo chsh verrà invocato l’editor definito nella tua variabile d’ambiente EDITOR; nel caso in cui questa non sia stata settata, verrà invocato vi. Modifica la riga "Shell:" in base alle tue esigenze.
Puoi anche eseguire chsh con l’opzione -s; in questo modo verrà settata la shell in modo diretto, senza che sia necessario invocare l’editor. Per esempio, se vuoi cambiare la tua shell in bash, potresti digitare il seguente comando:
% chsh -s /usr/local/bin/bashLa shell che desideri utilizzare deve essere presente nel file /etc/shells. Se hai installato una shell dalla collezione dei port, allora la nuova shell dovrebbe essere già stata inserita nel suddetto file in modo automatico. Se installi una shell manualmente, questo lavoro lo devi fare tu. Per esempio, se installi Dopo averlo fatto riavvia |
La maggior parte del lavoro di configurazione in FreeBSD viene fatto tramite la modifica di file di testo. Perciò, è una buona idea familiarizzare con un editor di testo. FreeBSD si presenta con alcuni editor come parte base del sistema, e molti altri sono disponibili nella collezione dei port.
L’editor più semplice e più facile da imparare si chiama ee, che sta per easy editor. Per avviare ee, puoi digitare sulla riga di comando ee filename dove filename è il nome del file che deve essere modificato. Per esempio, per modificare /etc/rc.conf, devi digitare ee /etc/rc.conf. Una volta all’interno di ee, tutti i comandi per azionare le funzioni dell’editor sono elencati nella parte superiore del video. Il carattere ^ è il tasto Ctrl della tastiera, quindi ^e si riferisce alla combinazione di tasti Ctrl+e. Per uscire da ee, premi il tasto Esc, quindi conferma l’uscita dall’editor. Se il file ha subito delle modifiche ti verrà chiesto se le vuoi salvare.
FreeBSD ha come parte base del sistema anche editor di testo più potenti come vi, mentre altri editor, come Emacs e vim, sono inclusi nella FreeBSD Ports Collection (editors/emacs e editors/vim). Questi editor offrono molte più funzionalità e molta più potenza a costo di essere un poco più complicati da imparare ad utilizzare. Comunque se intendi utilizzare in modo intensivo un editor, imparando ad utilizzare un editor potente come vim o Emacs risparmierai a lungo andare un sacco di tempo.
Il termine dispositivo viene usato prevalentemente per specificare le unità hardware all’interno di un sistema, come i dischi, le stampanti, le schede grafiche, e le tastiere. Durante la fase di avvio di FreeBSD, la maggior parte delle cose che vengono visualizzate da FreeBSD riguardano i dispositivi che sono stati rilevati. Puoi riesaminare questi messaggi di avvio guardando il file /var/run/dmesg.boot.
Per esempio, acd0 è il primo drive CDROM IDE, mentre kbd0 rappresenta la tastiera.
In un sistema operativo UNIX® la maggior parte di questi dispositivi sono accessibili tramite dei file speciali chiamati nodi di dispositivo, i quali sono posti nella directory /dev.
Quando aggiungi un nuovo dispositivo al tuo sistema, o ricompili il kernel per supportare dispositivi aggiuntivi, devono essere creati nuovi nodi di dispositivo.
DEVFS (DEVice File System)Il file system device, o DEVFS, fornisce la disponibilità dello spazio dei nomi dei dispositivi del kernel allo spazio dei nomi globale del file system. Invece di dover creare o modificare i nodi di dispositivo, DEVFS mantiene in modo automatico questo particolare file system.
Guarda la pagina man di devfs(5) per maggiori informazioni.
Per comprendere il motivo per cui FreeBSD usa il formato elf(5), devi prima conoscere un pò i tre attuali formati eseguibili "dominanti" per UNIX®:
Il più vecchio e "classico" formato oggetto di UNIX®. Usa un’intestazione corta e compatta con un numero magico all’inizio che è spesso usato per caratterizzare il formato (vedere a.out(5) per maggiori dettagli). Contiene tre segmenti caricabili: .text, .data, e .bss più una tabella di simboli e una di stringhe.
COFF
Il formato oggetto di SVR3. Poichè l’intestazione include una porzione di tabella, puoi avere molto di più delle sole sezioni .text, .data, e .bss.
Il successore di COFF, caratterizzato da sezioni multiple e da possibili valori a 32-bit o 64-bit. Uno dei maggiori svantaggi: ELF fu progettato con l’assunzione che ci doveva essere solo un ABI per ogni tipo di architettura dei sistemi. Tale assunzione è in realtà piuttosto sbagliata, e non è vera nemmeno nel mondo commerciale di SYSV (che ha almeno tre ABI: SVR4, Solaris, SCO).
FreeBSD tenta di aggirare questo problema fornendo un utility per marchiare un eseguibile ELF con informazioni sull’ABI per il quale è stato costruito. Guarda la pagina man brandelf(1) per maggiori informazioni.
FreeBSD proviene dalla scuola "classica" e ha usato il formato a.out(5), una tecnologia sperimentata ed utilizzata attraverso molte generazioni delle release BSD, fino agli inizi del ramo 3.X. Sebbene fino ad allora era possibile costruire ed eseguire su un sistema FreeBSD binari (e kernel) del formato ELF, inizialmente FreeBSD si oppose al "salto" di cambiamento al formato ELF come formato di default. Per quale motivo? Dunque, quando la scuola Linux fece il suo doloroso passaggio a ELF, questo non era sufficiente per abbandonare il formato eseguibile a.out a causa del loro rigido meccanismo a salto-di-tabella basato sulla libreria condivisa, il quale rendeva la costruzione di librerie condivise un compito molto difficile tanto per i venditori che per gli sviluppatori. Tuttavia, quando gli strumenti di ELF furono in grado di offrire una soluzione al problema della libreria condivisa e quando furono visti come "la strada imminente", il costo della migrazione fu accettato poichè necessario e avvenne così la transizione. Il meccanismo di libreria condivisa di FreeBSD è basato sullo stile più restrittivo del meccanismo di libreria condivisa degli SunOS™ di Sun, e come tale, è molto facile da utilizzare.
Quindi, perchè ci sono così tanti formati differenti?
In passato l’hardware era semplice. Questo hardware semplice sosteneva un sistema semplice e piccolo. Il formato a.out era del tutto adatto per rappresentare i binari su questo semplice sistema (un PDP-11). Nonostante le persone fecero il port di UNIX® da questo semplice sistema, esse mantennero il formato a.out poichè era sufficiente per un primo port di UNIX® verso architetture come Motorola 68k, VAXen, ecc.
All’epoca alcuni ingegneri hardware di spicco stabilirono che se tale formato poteva forzare il software a fare alcuni trucchi sporchi, allora esso sarebbe stato in grado di abbattere alcune barriere di progettazione e permettere al core della CPU di andare più veloce. Benchè il formato a.out fu progettato per lavorare con questo nuovo tipo di hardware (conosciuto ai giorni d’oggi come RISC), esso fu appena sufficiente per questo hardware, quindi furono sviluppati altri formati per ottenere delle prestazioni da questo hardware migliori di quelle che il limitato e semplice formato a.out era in grado di offrire. Furono inventati formati come il COFF, l’ECOFF, e alcuni altri e furono esaminate le loro limitazioni prima che fu prodotto l’ELF.
Per di più, le dimensioni dei programmi stavano diventando enormi e i dischi (e la memoria fisica) erano ancora relativamente piccoli, e quindi il concetto di libreria condivisa prese piede. Inoltre il sistema di VM (Memoria Virtuale) divenne più sofisticato. Benchè ognuno di questi miglioramenti fu fatto utilizzando il formato a.out, la sua utilità si distese sempre più con ogni nuova caratteristica. In aggiunta, la gente voleva caricare alcune cose in modo dinamico al tempo di esecuzione, o anche scartare parte dei loro programmi dopo l’esecuzione del codice iniziale al fine di salvare memoria e spazio di swap. I linguaggi divennero più sofisticati e le persone desideravano che il codice venisse chiamato dopo il main in modo automatico. Furono apportati molte migliorie al formato a.out per permettere tutte queste cose, e sostanzialmente tutto funzionò per un dato periodo. Col passare del tempo, il formato a.out non fu più in grado di gestire tutti questi problemi senza apportare dei miglioramenti al codice con un conseguente aumento della complessità. Benchè il formato ELF risolveva molti di questi problemi, era doloroso migrare da un sistema che tutto sommato funzionava. Quindi il formato ELF attese fino a quando fu meno doloroso rimanere con il formato a.out piuttosto che migrare al formato ELF.
Tuttavia, il tempo passò, e gli strumenti di costruzione che FreeBSD derivò dai loro strumenti di costruzione (in particolare l’assemblatore ed il loader) evolsero in due tronconi paralleli. L’albero di FreeBSD aggiunse le librerie condivise e sistemò alcuni bug. Il popolo di GNU che in origine aveva scritto questi programmi li riscrisse e aggiunse un semplice supporto per la costruzione di compilatori cross, la possibilità di produrre formati diversi a piacimento, e così via. Da quando molte persone vollero costruire compilatori cross per FreeBSD, questi furono delusi poichè i vecchi sorgenti che FreeBSD aveva per as e ld non erano pronti per questo lavoro. La nuova serie di strumenti di GNU (binutils) supportavano la compilazione cross, ELF, le librerie condivise, le estensioni C++, ecc. Inoltre molti venditori stanno rilasciando binari ELF, ed è una buona cosa per FreeBSD eseguirli.
Il formato ELF è più espressivo di quello a.out e permette una maggiore estensibilità nel sistema base. Gli strumenti di ELF sono meglio mantenuti, e offrono un supporto alla compilazione cross, che sta a cuore a molte persone. ELF può essere un pò meno veloce di a.out, ma tentare di misurarne le prestazioni non è molto semplice. Ci sono anche numerosi dettagli che sono diversi tra i due formati nel modo in cui essi mappano le pagine, gestiscono il codice iniziale, ecc. Questi dettagli non sono molto importanti, ma tra i due esistono delle differenze. Nel tempo il supporto per il formato a.out verrà rimosso dal kernel GENERIC, e alla fine sarà rimosso completamente dal kernel non appena non ci sarà più la necessità di eseguire programmi con il formato a.out.
La documentazione più esauriente su FreeBSD è costituita dalle pagine man. Quasi tutti i programmi sul sistema hanno un piccolo manuale di riferimento che spiega il funzionamento di base e i vari argomenti del programma stesso. Questi manuali possono essere visualizzati con il comando man. L’uso del comando man è semplice:
% man comandocomando è il nome del comando di cui desideri maggiori informazioni. Per esempio, per sapere di più circa il comando ls digita:
% man lsIl manuale in linea è diviso in sezione numerate:
Comandi utente.
System call e codici di errore.
Funzioni della libreria C.
Driver dei dispositivi.
Formati di file.
Giochi e altri passatempo.
Informazioni varie.
Comandi di mantenimento e di funzionamento del sistema.
Sviluppo del kernel.
In qualche caso, lo stesso soggetto può apparire in più di una sezione del manuale in linea. Per esempio, esiste un comando utente chmod e una system call chmod(). In questo caso, puoi dire al comando man quale vuoi specificando la sezione:
% man 1 chmodIn questo caso verrà visualizzata la pagina man del comando utente chmod. I riferimenti di una sezione particolare del manuale in linea sono tradizionalmente posti tra parentesi all’interno della documentazione, quindi chmod(1) fa riferimento al comando utente chmod e chmod(2) fa riferimento alla system call.
Tutto questo va bene se conosci il nome del comando e desideri semplicemente sapere come usarlo, ma cosa succede se non ricordi il nome del comando? Puoi usare man con l’opzione -k per ricercare tramite parole chiavi nelle descrizioni dei comandi:
% man -k mailCon questo comando ti verrà presentata una lista di comandi che hanno la parola chiave "mail" nella loro descrizione. Di fatto questo meccanismo funziona proprio come il comando apropos.
Stai dando un’occhiata a tutti quei comandi fantastici che si trovano in /usr/bin ma non hai la più pallida idea di cosa fanno la maggior parte di essi? Semplicemente digita:
% cd /usr/bin
% man -f *oppure
% cd /usr/bin
% whatis *che è la stessa cosa.
FreeBSD include molte applicazioni e utility prodotti dalla Free Software Foundation (FSF). Oltre alle pagine man, questi programmi hanno dei più ampi documenti in ipertesto chiamati file info che possono essere visualizzati con il comando info, o se hai installato emacs, con la modalità info di emacs.
Per usare il comando info(1), digita semplicemente:
% infoPer una breve introduzione, digita h. Per un rapido riferimento dei comandi, digita ?.
FreeBSD è distribuito con una ricca collezione di strumenti di sistema come parte base del sistema. Comunque, c’è molto che si può fare prima che sia necessario installare un’applicazione aggiuntiva di terze parti. FreeBSD fornisce due tecnologie complementari per installare software di terze parti sul tuo sistema: la FreeBSD Ports Collection (per installare dai sorgenti), ed i package (per installare da binari pre-compilati). Puoi usare entrambi questi sistemi per installare l’ultima versione della tua applicazione preferita dai dispositivi locali o direttamente dalla rete.
Dopo aver letto questo capitolo, saprai:
Come installare i package contenenti i binari delle applicazioni di terze parti.
Come compilare le applicazioni di terze parti dai sorgenti usando la collezione dei port.
Come rimuovere i package o i port installati in precedenza.
Come modificare i valori di default utilizzati dalla collezione dei port.
Come trovare un package specifico.
Come aggiornare le tue applicazioni.
Se hai già usato un sistema UNIX® prima d’ora saprai che la procedura tipica per installare software di terze parti è simile a questa:
Scaricare il software, che potrebbe essere distribuito sotto forma di codice sorgente, o come binario.
Scompattare il software dal suo formato di distribuzione (tipicamente un tarball compresso con compress(1), gzip(1), o con bzip2(1)).
Individuare la documentazione (probabilmente un file INSTALL o un file README, o qualche file nella sottodirectory doc/) e leggere come installare il software.
Se il software è stato distribuito sotto forma di sorgente, compilarlo. Questa fase può coinvolgere la modifica di un Makefile, oppure l’esecuzione di uno script configure, e qualche altro lavoro.
Installare e testare il software.
E questo se tutto va bene. Se stai installando del software di cui non è stato deliberatamente effettuato il porting in FreeBSD potresti perfino dover modificare il codice per farlo funzionare correttamente.
Se vuoi, puoi continuare ad installare il software su FreeBSD nel modo "tradizionale". Comunque, FreeBSD fornisce due tecnologie che possono farti risparmiare molti sforzi: i package e i port. Nel momento in cui scrivo, sono disponibili più di FreeBSD.numports; applicazioni di terze parti tramite questi due metodi.
Per ogni applicazione, il package di FreeBSD per quella applicazione consiste in un singolo file che devi scaricare. Il package contiene una copia pre-compilata di tutti i comandi dell’applicazione, così come i file di configurazione e di documentazione. Una volta scaricato il package, questo può essere manipolato con i comandi di gestione dei package di FreeBSD, come pkg_add(1), pkg_delete(1), pkg_info(1), e così via. L’installazione di una nuova applicazione può essere fatta con un singolo comando.
In FreeBSD un port di un’applicazione è un insieme di file predisposti per automatizzare il processo di compilazione dell’applicazione partendo dal codice sorgente.
Ricorda che ci sono molte fasi che normalmente devi eseguire se vuoi compilare un programma autonomamente (scaricare, scompattare, correggere, compilare, installare). I file che costituiscono un port contengono tutte le informazioni necessarie per permettere al sistema di fare questo lavoro al posto tuo. Tu esegui una manciata di semplici comandi e il codice sorgente dell’applicazione viene automaticamente scaricato, estratto, corretto, compilato, ed installato.
Di fatto, il sistema dei port può anche essere usato per generare package che possono essere successivamente manipolati con pkg_add ed altri comandi di gestione dei package che saranno presentati tra poco.
Sia i package che i port comprendono il meccanismo delle dipendenze. Supponiamo che tu voglia installare un’applicazione che dipende da un specifica libreria. Sia l’applicazione che la libreria sono disponibili in FreeBSD come port o come package. Se usi il comando pkg_add o il sistema dei port per installare l’applicazione, entrambi noteranno che la libreria non è installata, e automaticamente la installeranno per prima.
Dato che le due tecnologie sono abbastanza simili, probabilmente vorrai sapere perché FreeBSD le usa entrambe. I package e i port hanno i loro punti forte, e l’utilizzo dell’uno o dell’altro dipende dalle proprie preferenze personali.
Il tarball compresso di un package è tipicamente più piccolo del tarball compresso contenente il codice sorgente della stessa applicazione.
I package non richiedono alcuna compilazione aggiuntiva. Per grandi applicazioni, come Mozilla, KDE, oppure GNOME questo può essere importante, sopra tutto se usi un sistema lento.
I package non richiedono la conoscenza del processo di compilazione del software su FreeBSD.
I package sono normalmente compilati con opzioni conservative, poiché devono poter funzionare su un parco macchine il più ampio possibile. Con l’installazione dai port, puoi aggiustare le opzioni di compilazione per produrre (per esempio) del codice che sia specifico per un Pentium IV o un processore Athlon.
Alcune applicazioni hanno delle opzioni attivabili al tempo di compilazione che permettono di modificare il comportamento delle applicazioni stesse. Per esempio, Apache può essere configurato con un’ampia varietà di differenti opzioni built-in. Effettuando la compilazione dal port non sei costretto ad accettare le opzioni di default, e puoi settarle tu stesso.
In alcuni casi, ci possono essere più package per la stessa applicazione a seconda dei settaggi ivi contenuti. Per esempio, Ghostscript è disponibile come package ghostscript e come package ghostscript-nox11, a seconda che tu abbia o meno installato un server X11. Questa sorta di adattamento è possibile con i package, ma diviene impossibile nel caso in cui un’applicazione ha più di una o due diverse opzioni che si possono dare al tempo di compilazione.
Le condizioni di licenza di alcune distribuzioni di software proibiscono la distribuzione dei binari. Tali software devono essere distribuiti come codice sorgente.
Alcune persone non si fidano della distribuzione dei binari. Con il codice sorgente, puoi (in teoria) controllare il codice e cercare i suoi potenziali problemi.
Se hai delle patch, hai bisogno del sorgente per applicarle.
Ad alcune persone piace avere il codice sorgente, in modo tale da poterlo leggerlo se sono annoiati, hackerarlo, prenderne in prestito delle parti (licenza permettendo, naturalmente), e così via.
Per tenersi al corrente sugli aggiornamenti dei port, iscriviti alla mailing list sui port di FreeBSD e alla mailing list sui bug dei port di FreeBSD.
Prima di installare qualche applicazione, dovresti verificare http://vuxml.freebsd.org/ per eventuali problemi di sicurezza relativi alla tua applicazione. Inoltre puoi installare il port security/portaudit che verificherà in modo automatico tutte le applicazioni installate a caccia di vulnerabilità note; una verifica verrà fatta anche prima della compilazione dei port. Puoi usare il comando |
Il resto del capitolo spiegherà come usare i package ed i port per installare e gestire il software di terze parti su FreeBSD.
Prima di poter installare delle applicazioni devi sapere quale applicazione ti serve, e come viene chiamata.
La lista delle applicazioni disponibili su FreeBSD cresce continuamente. Fortunatamente, ci sono diversi sistemi per trovare quello che ti serve:
Il sito web di FreeBSD mantiene all’indirizzo http://www.FreeBSD.org/ports/ una lista aggiornata in cui puoi cercare tutte le applicazioni correntemente disponibili. I port sono divisi in categorie, e puoi sia cercare un’applicazione in base al nome (se lo conosci), sia visionare tutte le applicazioni disponibili in una data categoria.
Dan Langille mantiene FreshPort, all’indirizzo http://www.FreshPorts.org/. FreshPort segue in tempo reale i cambiamenti delle applicazioni nell’albero dei port, permettendoti di "controllare" uno o più port, e dandoti la possibilità di essere avvisato tramite email quando questi vengono aggiornati.
Se non conosci il nome dell’applicazione che desideri, prova ad usare un sito come FreshMeat (http://www.freshmeat.net/) per trovare l’applicazione, quindi controlla sul sito di FreeBSD per vedere se è già stato effettuato il porting.
Se sei a conoscenza del nome esatto del port, ma non sai in quale categoria esso sia, puoi usare il comando whereis(1) Semplicemente digita whereis file, dove file è il programma che vuoi installare. Se viene trovato sul tuo sistema, ti verrà indicato dove si trova, in modo simile a quanto segue:
# whereis lsof
lsof: /usr/ports/sysutils/lsofQuesto ci dice che lsof (un’utility di sistema) si trova nella directory /usr/ports/sysutils/lsof.
Un altro modo per trovare un determinato port è quello di usare il meccanismo di ricerca contenuto nella collezione dei port. Per usare questo servizio di ricerca, devi posizionarti nella directory /usr/ports. Una volta in quella directory, lancia make search name=nome-programma dove nome-programma è il nome del programma che vuoi cercare. Per esempio, se vuoi cercare lsof:
# cd /usr/ports
# make search name=lsof
Port: lsof-4.56.4
Path: /usr/ports/sysutils/lsof
Info: Elenca informazioni sui file aperti (simile a fstat(1))
Maint: obrien@FreeBSD.org
Index: sysutils
B-deps:
R-deps:La parte di output sulla quale devi porre particolare attenzione è la riga "Path:", che ti dice dove puoi trovare il port. Le altre informazioni riportate non sono necessarie per installare il port, e quindi non saranno trattate in questa sede.
Inoltre per una ricerca più complessa puoi usare make search key=stringa dove stringa fa parte del testo da cercare. Questo ricerca nei nomi dei port, nei commenti, nelle descrizioni e nelle dipendenze e può essere usato per cercare port che si riferiscono ad un argomento particolare anche se non conosci il nome del programma che stai cercando.
In entrambi i casi, la stringa di ricerca è case-insensitive. La ricerca per "LSOF" produrrà gli stessi risultati della ricerca per "lsof".
Puoi usare l’utility pkg_add(1) per installare un package di FreeBSD da un file locale o da un server sulla rete.
# ftp -a ftp2.FreeBSD.org
Connected to ftp2.FreeBSD.org.
220 ftp2.FreeBSD.org FTP server (Version 6.00LS) ready.
331 Guest login ok, send your email address as password.
230-
230- This machine is in Vienna, VA, USA, hosted by Verio.
230- Questions? E-mail freebsd@vienna.verio.net.
230-
230-
230 Guest login ok, access restrictions apply.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> cd /pub/FreeBSD/ports/packages/sysutils/
250 CWD command successful.
ftp> get lsof-4.56.4.tgz
local: lsof-4.56.4.tgz remote: lsof-4.56.4.tgz
200 PORT command successful.
150 Opening BINARY mode data connection for 'lsof-4.56.4.tgz' (92375 bytes).
100% |**************************************************| 92375 00:00 ETA
226 Transfer complete.
92375 bytes received in 5.60 seconds (16.11 KB/s)
ftp> exit
# pkg_add lsof-4.56.4.tgzSe non hai una raccolta di package locale (per esempio il set dei CDROM di FreeBSD) allora probabilmente ti risulterà più facile usare pkg_add(1) con l’opzione -r. In questo modo pkg_add(1) determina automaticamente la corretta release e il giusto formato dell’oggetto, quindi scarica il package da un sito FTP e lo installa.
# pkg_add -r lsofL’esempio qui sopra scarica il giusto package e lo installa senza nessun ulteriore intervento. Se vuoi specificare un sito mirror dei package di FreeBSD alternativo, invece del sito di distibuzione principale, devi settare la variabile PACKAGESITE come desiderato, in modo tale da sovrascrivere i settaggi di default. pkg_add(1) usa fetch(3) per scaricare i file, il quale rispetta varie variabili d’ambiente, incluse FTP_PASSIVE_MODE, FTP_PROXY, e FTP_PASSWORD. Puoi aver bisogno di settarne qualcuna se la tua macchina è dietro un firewall, o se utilizzi un proxy FTP/HTTP. Leggi fetch(3) per la lista completa. Nell’esempio precedente si può anche notare che viene usato lsof al posto di lsof-4.56.4. Quando viene usata la modalità di prelevamento da remoto, il numero di versione del package non deve essere specificato. pkg_add(1) prenderà automaticamente l’ultima versione dell’applicazione.
pkg_add(1) scaricherà la versione più recente della tua applicazione solo se stai usando FreeBSD.current; o FreeBSD.stable;. Se stai utilizzando una versione -RELEASE, allora verrà scaricata la versione del package che è stato costruito per la tua release. Tuttavia è possibile cambiare questo comportamento modificando la variabile di ambiente |
I file dei package sono distribuiti nel formato .tgz. Puoi trovarli in ftp://ftp.FreeBSD.org/pub/FreeBSD/ports/packages/, oppure sui CDROM della distribuzione di FreeBSD. Ogni CD contenuto nel set dei quattro CD (e nel PowerPak, ecc.) contiene i package nella directory /packages. La disposizione dei package è simile a quella dell’albero /usr/ports. Ogni categoria ha la propria directory, ed ogni package può essere trovato dentro la directory All.
La struttura delle directory del sistema dei package eguaglia quella dei port; questi due sistemi lavorano l’uno con l’altro per formare l’intero sistema dei package/port.
L’utility pkg_info(1) elenca e descrive i vari package installati.
# pkg_info
cvsup-16.1 Un comune sistema di distribuzione dei file in rete ottimizzato per CVS
docbook-1.2 Meta-port delle varie versioni del DTD DocBook
...L’utility pkg_version(1) riassume le versioni di tutti i package installati. Paragona le versioni dei package con le versioni correnti trovate nell’albero dei port.
# pkg_version
cvsup =
docbook =
...I simboli nella seconda colonna indicano il risultato del confronto tra la versione installata e quella disponibile in locale nell’albero dei port.
| Simbolo | Significato |
|---|---|
= | Le versioni del package installato e di quello disponibile in locale nell’albero dei port sono uguali. |
< | La versione installata è precedente a quella disponibile nell’albero dei port. |
> | La versione installata è più aggiornata di quella trovata in locale nell’albero dei port. (L’albero dei port locale è probabilmente da aggiornare) |
? | Il package installato non può essere trovato nell’indice dei port. (Questo può succedere, per esempio, se un port installato viene rimosso dalla collezione dei port oppure viene rinominato.) |
* | Ci sono più versioni del package. |
Per rimuovere un package installato in precedenza, usa l’utility pkg_delete(1).
# pkg_delete xchat-1.7.1Le sezioni seguenti forniscono le istruzioni basilari sull’uso della collezione dei port per installare e rimuovere programmi dal tuo sistema.
Prima che tu possa installare i port, devi procurarti la collezione dei port-che essenzialmente è un set di Makefiles, patch, e file di descrizione collocati in /usr/ports.
Durante l’installazione del tuo sistema FreeBSD, sysinstall ti ha chiesto se volevi installare la collezione dei port. Se hai rifiutato, puoi seguire queste istruzioni per ottenerla:
Procedure: Il Metodo Sysinstall
Questo metodo richiede ancora l’uso di sysinstall per installare manualmente la collezione dei port.
Esegui da root sysinstall (/stand/sysinstall nelle versioni di FreeBSD precedenti alla 5.2) come mostrato qui sotto:
# sysinstallScorri verso il basso e seleziona , premi Invio.
Scorri verso il basso e seleziona , premi Invio.
Scorri verso il basso fino a , premi Spazio.
Scorri verso l’alto fino a , premi Invio.
Seleziona il modo di installazione desiderato, come CDROM, FTP, e così via.
Scorri verso l’alto fino a e premi Invio.
Premi X per uscire da sysinstall.
Un altro metodo per ottenere la tua collezione dei port e per mantenerla aggiornata consiste nell’utilizzo di CVSup. Dai un’occhiata al file di CVSup riguardante i port, /usr/shared/examples/cvsup/ports-supfile. Guarda Usare CVSup (Uso di CVSup) per maggiori informazioni sull’uso di CVSup e del file menzionato.
Procedure: Il Metodo CVSup
Questo è un rapido metodo che utilizza CVSup per ottenere la collezione dei port. Se vuoi mantenere il tuo albero dei port aggiornato, o imparare di più su CVSup, leggi la sezione menzionata in precedenza.
Installa il package net/cvsup-without-gui:
# pkg_add -r cvsup-without-guiGuarda Installazione di CVSup (Installazione) per maggiori dettagli.
Esegui cvsup:
# cvsup -L 2 -h cvsup.FreeBSD.org /usr/shared/examples/cvsup/ports-supfileCambia cvsup.FreeBSD.org in un server CVSup vicino a te. Guarda Mirror CVSup (Siti CVSup) per una lista completa dei siti mirror.
Qualcuno potrebbe voler usare il suo ports-supfile, per esempio per evitare di passare il server CVSup su linea di comando.
|
Poco dopo aver eseguito il comando cvsup(1) verranno scaricate e applicate alla tua collezione dei port tutte le modifiche recenti, anche se di fatto i port già compilati sul tuo sistema non verranno aggiornati.
La prima cosa che dovrebbe essere chiara quando si ha a che fare con la collezione dei port è l’effettivo significato di "scheletro" di un port. Brevemente, lo scheletro di un port è un insieme minimo di file che dice al tuo sistema FreeBSD come compilare ed installare un programma in modo pulito. Ogni scheletro di un port include:
Un Makefile. Il Makefile contiene varie espressioni che specificano come l’applicazione deve essere compilata e dove deve essere installata sul tuo sistema.
Un file distinfo. Questo file contiene informazioni sui file che devono essere scaricati per la compilazione del port e sui loro checksum (somme di controllo), utilizzati per verificare che quei file non siano stati corrotti durante il download.
Una directory files. Questa directory contiene le patch utilizzate per la compilazione e per l’installazione del programma sul tuo sistema FreeBSD. Le patch sono sostanzialmente piccoli file che specificano come modificare alcuni file. Sono in puro formato di testo, e in modo grossolano dicono "Rimuovi la riga 10" o "Cambia la riga 26 in …". Le patch sono anche conosciute con il termine "diff" poichè sono generate dal programma diff(1).
Questa directory può anche contenere altri file utilizzati per la costruzione del port.
Un file pkg-descr. Questo file contiene una descrizione del programma più dettagliata, spesso su più righe di testo.
Un file pkg-plist. Questo file contiene l’elenco di tutti i file che saranno installati dal port. Dice anche al sistema dei port quale file rimuovere durante la disinstallazione.
Alcuni port hanno altri file, come pkg-message. Il sistema dei port li usa per affrontare speciali situazioni. Se vuoi maggiori dettagli su questi file, e sui port in generale, leggi attentamente il Manuale del Porter di FreeBSD.
Il port include istruzioni su come compilare il codice sorgente, ma non include il codice sorgente stesso. Devi prendere il codice sorgente da un CDROM o da Internet. L’autore del codice sorgente può distribuirlo come desidera. Quasi sempre è un file di archivio tar compresso con gzip, ma potrebbe essere stato compresso con un altro tool o perfino potrebbe essere non compresso. Il codice sorgente del programma, in qualsiasi forma sia, è chiamato con il termine "distfile". I due metodi per installare un port di FreeBSD sono descritti qui sotto.
Devi essere |
Prima di installare qualche port, dovresti assicurarti di avere l’albero della collezione dei port aggiornato e dovresti verificare http://vuxml.freebsd.org/ per eventuali problemi di sicurezza relativi alla tua applicazione. Una verifica delle vulnerabilità di sicurezza può essere fatta in modo automatico con portaudit prima dell’installazione di nuove applicazioni. Questo strumento può essere trovato nella collezione dei port (security/portaudit). Esegui |
Le immagini ufficiali su CDROM del progetto FreeBSD non includono più i distfile. Occupano molto spazio che è meglio utilizzato per i package precompilati. I prodotti su CDROM come il FreeBSD PowerPak includono i distfile, e puoi ordinare questi set da un venditore come FreeBSD Mall. Questa sezione presuppone che tu abbia un simile set di CDROM di FreeBSD.
Metti il tuo CDROM di FreeBSD nell’apposito lettore. Montalo su /cdrom. (Se usi un punto di mount differente, setta la variabile make CD_MOUNTPTS.) Per prima cosa, vai nella directory del port che vuoi installare:
# cd /usr/ports/sysutils/lsofUna volta dentro la directory lsof, vedrai lo scheletro del port. Il prossimo passo riguarda la compilazione, o "costruzione", del port. Questo viene fatto semplicemente digitando make al prompt. Una volta che hai fatto questo, dovresti vedere qualcosa simile a quanto segue:
# make
>> lsof_4.57D.freebsd.tar.gz doesn't seem to exist in /usr/ports/distfiles/.
>> Attempting to fetch from file:/cdrom/ports/distfiles/.
===> Extracting for lsof-4.57
...
[l'output dell'estrazione è stato tagliato]
...
>> Checksum OK for lsof_4.57D.freebsd.tar.gz.
===> Patching for lsof-4.57
===> Applying FreeBSD patches for lsof-4.57
===> Configuring for lsof-4.57
...
[l'output della configurazione è stato tagliato]
...
===> Building for lsof-4.57
...
[l'output della compilazione è stato tagliato]
...
#Nota che una volta terminata la compilazione ritornerai al tuo prompt. Il prossimo passo riguarda l’installazione del port. Per installarlo, devi semplicemente affiancare una parola al comando make, e questa parola è install:
# make install
===> Installing for lsof-4.57
...
[l'output dell'installazione è stato tagliato]
...
===> Generating temporary packing list
===> Compressing manual pages for lsof-4.57
===> Registering installation for lsof-4.57
===> SECURITY NOTE:
I binari di questo port richiedono l'esecuzione con alti privilegi.
#Quando ritornerai al tuo prompt, dovresti essere in grado di eseguire l’applicazione che hai appena installato. Siccome lsof è un programma che lavora con alti privilegi, viene mostrato un avvertimento di sicurezza. Durante la compilazione e l’installazione dei port, dovresti fare attenzione ad ogni avvertimento che appare.
Potresti anche evitare un passaggio lanciando solamente |
Alcune shell mantengono una cache dei comandi che sono disponibili nelle directory elencate nella variabile d’ambiente |
Per cortesia sii consapevole che le licenze di alcuni port non permettono l’inclusione degli stessi sul CDROM. Questa limitazione potrebbe essere dovuta dalla necessità di compilare un form di registrazione prima di scaricare il software, o perché la ridistribuzione non è permessa, o per altre ragioni. Se desideri installare un port non incluso nel CDROM, dovrai essere collegato ad Internet per farlo (vedi la prossima sezione). |
Questa sezione presuppone che tu abbia una connessione ad Internet funzionante. Se non ce l’hai, dovrai utilizzare l’installazione da CDROM, oppure dovrai copiare manualmente il distfile in /usr/ports/distfiles.
L’installazione di un port da Internet viene fatta nello stesso modo con cui viene fatta l’installazione da CDROM. L’unica differenza tra i due modi è che il distfile del port viene preso da Internet invece che dal CDROM.
I passi richiesti sono gli stessi:
# make install
>> lsof_4.57D.freebsd.tar.gz doesn't seem to exist in /usr/ports/distfiles/.
>> Attempting to fetch from ftp://ftp.FreeBSD.org/pub/FreeBSD/ports/distfiles/.
Receiving lsof_4.57D.freebsd.tar.gz (439860 bytes): 100%
439860 bytes transferred in 18.0 seconds (23.90 kBps)
===> Extracting for lsof-4.57
...
[l'output dell'estrazione è stato tagliato]
...
>> Checksum OK for lsof_4.57D.freebsd.tar.gz.
===> Patching for lsof-4.57
===> Applying FreeBSD patches for lsof-4.57
===> Configuring for lsof-4.57
...
[l'output della configurazione è stato tagliato]
...
===> Building for lsof-4.57
...
[l'output della compilazione è stato tagliato]
...
===> Installing for lsof-4.57
...
[l'output dell'installazione è stato tagliato]
...
===> Generating temporary packing list
===> Compressing manual pages for lsof-4.57
===> Registering installation for lsof-4.57
===> SECURITY NOTE:
I binari di questo port richiedono l'esecuzione con alti privilegi.
#Come puoi vedere, la sola differenza sta nella riga che dice da dove il sistema sta ottenendo il distfile del port.
Il sistema dei port usa fetch(1) per scaricare i file, il quale rispetta varie variabili d’ambiente, incluse FTP_PASSIVE_MODE, FTP_PROXY, e FTP_PASSWORD. Puoi aver bisogno di settarne qualcuna se sei dietro a un firewall, o se usi un proxy FTP/HTTP. Guarda fetch(3) per la lista completa.
Gli utenti che non possono essere sempre connessi ad Internet possono usare l’opzione make fetch. Esegui tale comando in cima alla directory (/usr/ports) e i file richiesti saranno scaricati. Questo comando funziona anche nelle categorie di livello inferiore, per esempio: /usr/ports/net. Nota che se un port dipende da una libreria o da altri port, quel comando non preleverà anche i distfile di questi port. Sostituisci fetch con fetch-recursive se vuoi prelevare anche tutte le dipendenze di un port.
Puoi compilare tutti i port di una categoria o perfino tutti i port eseguendo |
In alcuni casi rari, gli utenti potrebbero voler acquisire i tarball da un sito diverso dal MASTER_SITES (la locazione di default dove i file sono scaricati). Puoi sovrascrivere l’opzione MASTER_SITES con il comando seguente:
# cd /usr/ports/directory
# make MASTER_SITE_OVERRIDE= \
ftp://ftp.FreeBSD.org/pub/FreeBSD/ports/distfiles/ fetchIn questo esempio abbiamo settato MASTER_SITES a ftp.FreeBSD.org/pub/FreeBSD/ports/distfiles/.
Alcuni port permettono (o perfino richiedono) l’impostazione di alcune opzioni di compilazione che abilitano/disabilitano parti dell’applicazione opzionali, settaggi di sicurezza, e altre personalizzazioni. Alcune applicazioni che mi vengono in mente sono www/mozilla, security/gpgme, e mail/sylpheed-claws. Quando sono disponibili simili opzioni viene visualizzato un messaggio. |
Qualche volta è utile (o necessario) utilizzare directory per i distfile e i port diverse da quelle di default. Le variabili PORTSDIR e PREFIX possono sovrascrivere le directory di default. Per esempio:
# make PORTSDIR=/usr/home/example/ports installcompilerà il port in /usr/home/example/ports e installerà ogni cosa sotto /usr/local.
# make PREFIX=/usr/home/example/local installcompilerà in /usr/ports ed installerà in /usr/home/example/local.
E naturalmente,
# make PORTSDIR=../ports PREFIX=../local installè una combinazione dei due (è troppo lungo da scrivere per intero su questa pagina, ma dovrebbe darti lo stesso un’idea generale).
Alternativamente, queste variabili potrebbero essere settate nel tuo ambiente. Leggi la pagina man della tua shell per sapere come fare.
imakeAlcuni port che usano imake (una parte dell’X Window System) non funzionano bene con PREFIX, e si ostinano ad installarsi sotto /usr/X11R6. In modo analogo, alcuni port di Perl ignorano PREFIX e si installano nell’albero del Perl. Far rispettare a questi port PREFIX è spesso un lavoro difficile o persino impossibile.
Ora che sai come installare i port, probabilmente ti chiederai come rimuoverli, caso mai ne installassi uno e successivamente ti accorgessi che hai installato il port sbagliato. Rimuoveremo il port utilizzato nel nostro esempio precedente (che era lsof se non sei stato attento). Come con l’installazione dei port, la prima cosa che devi fare è andare nella directory del port, /usr/ports/sysutils/lsof. Dopo aver cambiato directory, sei pronto per disinstallare lsof. Questo viene fatto con il comando make deinstall:
# cd /usr/ports/sysutils/lsof
# make deinstall
===> Deinstalling for lsof-4.57È stato abbastanza facile. In questo modo hai rimosso lsof dal tuo sistema. Se volessi reinstallarlo, puoi farlo lanciando make reinstall dalla directory /usr/ports/sysutils/lsof.
Le sequenze make deinstall e make reinstall non funzionano più una volta che hai dato un make clean. Se vuoi disinstallare un port dopo un make clean, usa pkg_delete(1) come discusso nella sezione del Manuale riguardante i Package.
Usando la collezione dei port con il passare del tempo puoi facilmente esaurire lo spazio del tuo disco. Infatti compilando ed installando software con i port, l’albero dei port tende ad aumentare in dimensioni, quindi dovresti sempre ricordarti di ripulire le directory temporanee work usando il comando make clean. Questo rimuoverà la directory work dopo che un port è stato compilato ed installato. Inoltre puoi rimuovere i file sorgenti della distribuzione dalla directory distfiles, e rimuovere i port installati che non sono più utilizzati.
Alcuni utenti limitano le categorie dei port disponibili mettendo un elemento nel file refuse. In questo modo, quando viene eseguita l’applicazione CVSup, questa non scaricherà i file delle categorie specificate nel file refuse. Maggiori informazioni riguardo il file refuse possono essere trovate nella Il File refuse.
Dopo che hai aggiornato la tua collezione dei port, prima di tentare di aggiornare un port, dovresti verificare il file /usr/ports/UPDATING. Questo file riporta alcuni problemi che gli utenti potrebbero incontrare durante l’aggiornamento di un port con le relative soluzioni. |
Mantenere i tuoi port aggiornati può essere un lavoro noioso. Per esempio, per aggiornare dovresti andare nella directory del port, compilare il port, disinstallare il vecchio port, installare quello nuovo, e quindi ripulire la directory di lavoro. Immagina di fare tutto ciò per cinque port, noioso vero? Questo era uno dei maggiori problemi per gli amministratori di sistema, e ora abbiamo strumenti che fanno questo lavoro per noi. Per esempio l’utility sysutils/portupgrade fa tutto questo! Installalo come qualsiasi altro port, usando il comando make install clean.
Ora crea un database con il comando pkgdb -F. Verrà letta la lista dei port installati e verrà creato un file database nella directory /var/db/pkg. D’ora in avanti, quando esegui portupgrade -a, questo leggerà il database e il file dei port INDEX. Infine, portupgrade incomincerà a scaricare, compilare, effettuare backup, installare, e ripulire i port che devono essere aggiornati. portupgrade è fornito di molte opzioni a seconda dei casi di utilizzo, tra i quali uno è particolarmente importante.
Se vuoi aggiornare solo una determinata applicazione, e non il database completo, usa portupgrade pkgname, con l’opzione -r se portupgrade dovrebbe agire anche su tutti i package che dipendono dal dato package, o con l’opzione -R per agire su tutti i package richiesti dal dato package.
Per usare i package invece dei port nell’installazione, usa l’opzione -P. Con questa opzione portupgrade cerca nelle directory locali elencate in PKG_PATH, o, se non sono stati trovati localmente, scarica i package da un sito. Se i package non sono stati trovati localmente ne è stato possibile scaricarli in remoto, portupgrade userà i port. Per impedire l’uso dei port, usa l’opzione -PP.
Per scaricare solo i distfile (o i package, se è stata specificata l’opzione -P) senza compilare o installare nulla, usa l’opzione -F. Per maggiori informazioni guarda la pagina man di portupgrade(1).
È importante aggiornare in modo regolare il database dei package usando il comando |
Esistono altre utility che fanno simili lavori, controlla la directory ports/sysutils e guarda se ti viene qualche idea.
Di solito dopo aver installato una nuova applicazione dovresti leggere la documentazione che potrebbe essere stata inclusa, modificare qualche file di configurazione, assicurarti che l’applicazione parta nella fase di avvio (se è un demone), e così via;.
I passi precisi che devi seguire per configurare un’applicazione sono ovviamente diversi da applicazione a applicazione. Comunque, se hai appena installato una nuova applicazione e ti stai chiedendo "Cosa faccio ora?" questi consigli potrebbero aiutarti:
Usa pkg_info(1) per scoprire quali file sono stati installati, e dove sono stati installati. Per esempio, se hai appena installato la versione 1.0.0 di FooPackage, allora questo comando
# pkg_info -L foopackage-1.0.0 | lessmostrerà tutti i file installati dal package. Fai molta attenzione ai file nelle directory man/, che sono le pagine man, a quelli nella directory etc/, che sono i file di configurazione, e a quelli in doc/, che forniscono una documentazione più esauriente.
Se non sei sicuro della versione dell’applicazione che hai appena installato, questo comando
# pkg_info | grep foopackagetroverà tutti i package installati che contengono nel nome foopackage. Rimpiazza foopackage nella tua riga di comando a seconda delle tue necessità.
Una volta che hai scoperto dove sono state posizionate le pagine man dell’applicazione, esaminale usando man(1). Analogamente, esamina i file di configurazione d’esempio, ed ogni ulteriore documentazione che può essere stata fornita.
Se l’applicazione ha un sito web, cerca della documentazione aggiuntiva, le domande più frequenti (FAQ), ed altro ancora. Se non sei sicuro dell’indirizzo del sito web questo potrebbe essere presente nell’output di
# pkg_info foopackage-1.0.0Una riga contenete WWW:, se presente, dovrebbe fornire l’URL del sito dell’applicazione.
I port che dovrebbero avviarsi in fase di avvio (come i server Internet) di solito installano uno script di esempio in /usr/local/etc/rc.d. Dovresti verificare questo script ed eventualmente modificarlo o rinominarlo. Vedi la sezione Avvio dei Servizi per maggiori informazioni.
Se ti dovessi imbattere in un port che per te non funziona, ci sono alcune cose che puoi fare, tra le quali:
Scopri se c’è una soluzione pendente per il port nel database dei Report dei Problemi. Se c’è, potresti usare la soluzione proposta.
Chiedi aiuto a colui che mantiene il port. Digita make maintainer o leggi il Makefile per trovare il suo indirizzo email. Ricorda di includere nel messaggio il nome e la versione del port (manda la riga $FreeBSD: del Makefile) e l’output che descrive l’errore.
Alcuni port non sono mantenuti da singole persone ma invece da una mailing list. La maggior parte di questi indirizzi sono simili a freebsd-listname@FreeBSD.org. Tieni conto di questo quando mandi le tue questioni. In particolare, i port mantenuti da freebsd-ports@FreeBSD.org in realtà non sono mantenuti da nessuno. Il supporto e i fix, se ce ne sono, arrivano dalla comunità facente parte di quella mailing list. Sono necessari altri volontari! |
Se non ottieni una risposta, puoi usare send-pr(1) per segnalare un bug report (guarda l’articolo Come Scrivere i Report dei Problemi per FreeBSD).
Aggiustarlo! Il Manuale del Porter contiene informazioni dettagliate sull’infrastruttura dei "Port" affinchè tu possa aggiustare quel port che occasionalmente non funziona o perfino proporne uno tutto tuo!
Prendi il package da un sito FTP vicino a te. La "principale" collezione dei package è su ftp.FreeBSD.org nella directory dei package, ma prima assicurati di controllare il tuo mirror locale! È più probabile che funzionino i package rispetto alla compilazione dal sorgente e sono anche molto più sbrigativi. Usa il programma pkg_add(1) per installare i package sul tuo sistema.
FreeBSD usa X11 per fornire agli utenti una potente interfaccia grafica. X11 è una implementazione gratuita dell’X Window System che è stata implementata sia in Xorg che in XFree86™ (ed altri pacchetti di software che qui non menzioneremo). Le versioni di FreeBSD fino alla FreeBSD 5.2.1-RELEASE inclusa troveranno come installazione di default XFree86™, il server X11 rilasciato dal Progetto XFree86™. A partire da FreeBSD 5.3-RELEASE, la versione di default ed ufficiale è stata cambiata in Xorg, il server X11 sviluppato dalla Fondazione X.Org sotto una licenza molto simile a quella usata da FreeBSD. Sono disponibili per FreeBSD anche X server commerciali.
Questo capitolo copre l’installazione e la configurazione di X11 con enfasi su Xorg release 7.7. Per ulteriori informazioni sulla configurazione di XFree86™ (ad esempio su vecchie release di FreeBSD dove XFree86™ era la distribuzione di default di X11) o release precedenti di Xorg è sempre possibile riferirsi alla versione archiviata del Manuale di FreeBSD consultabile a questo indirizzo http://docs.FreeBSD.org/doc/.
Per maggiori informazioni sull’hardware video che X11 supporta, controlla il sito web Xorg.
Dopo aver letto questo capitolo, conoscerai:
I diversi componenti dell’X Window system, e come questi cooperano.
Come installare e configurare X11.
Come installare ed usare diversi window manager.
Come usare i font TrueType® in X11.
Come impostare il tuo sistema per il login grafico ( XDM).
Prima di leggere questo capitolo, dovresti:
Sapere come installare del software di terze parti (Installazione delle Applicazioni. Port e Package).
Usare X per la prima volta può essere talvolta scioccante per quelli che hanno familiarità con altri ambienti grafici, come Microsoft® Windows® e Mac OS®.
Seppure non sia necessario capire tutti i dettagli dei diversi componenti di X e come interagiscono, tuttavia una qualche conoscenza di base rende possibile avvantaggiarsi delle funzionalità di X.
X non è il primo window manager scritto per UNIX®, ma è il più popolare. Il gruppo di sviluppo originale di X aveva già lavorato ad un altro sistema grafico prima di scrivere X. Il nome di quel sistema era "W" (per "Window"). X era semplicemente la lettera seguente nell’alfabeto Romano.
X può essere chiamato "X", "X Window System", "X11", e in altri modi. Chiamare X11 "X Windows" potrebbe dare fastidio a della gente; per ulteriori dettagli su questo, consulta X(7).
X è stato progettato fin dall’inizio per essere incentrato sulla rete ed adotta un modello "client-server".
Nel modello di X, il "server X" funziona sul computer che ha tastiera, monitor e mouse attaccati. Il server è responsabile di operazioni come il controllo del display, la gestione dell’input dalla tastiera e dal mouse, e di altri dispositivi di input o di output (es. una "tavoletta" può essere usata come dispositivo di input, e un proiettore video può essere un dispositivo di output alternativo). Ogni applicazione X (come XTerm, o getenv(3)) è un "client". Un client spedisce messaggi al server come "Per favore disegna una finestra a queste coordinate", e il server risponde con messaggi quali "L’utente ha appena premuto il bottone OK".
In una casa o in un piccolo ufficio, il server X e i client X di solito funzioneranno sullo stesso computer. Ad ogni modo, è perfettamente possibile far funzionare il server X su un desktop meno potente, e far funzionare le applicazioni X (i client) su di una potente e costosa macchina che serve l’ufficio. In questo scenario le comunicazioni tra il client X e il server hanno luogo attraverso la rete.
Questo confonde certa gente, perchè la terminologia di X è proprio l’opposto di quello che ci si possa aspettare di solito. Normalmente ci si aspetta che il "server X" sia la grossa e potente macchina in fondo alla sala, e il "client X" sia la macchina sulla propria scrivania.
È importante ricordare che il server X è la macchina con il monitor e la tastiera, e i client X sono i programmi che mostrano le finestre.
Non c’è nulla nel protocollo che obbliga la macchina client e quella server ad utilizzare lo stesso sistema operativo, oppure a funzionare sullo stesso tipo di computer. È certamente possibile far funzionare un server X su Microsoft® Windows® o Mac OS® di Apple, e ci sono diverse applicazioni free o commerciali che fanno esattamente questo.
La filosofia di design di X è molto simile a quella di UNIX® "strumenti, non regole". Questo significa che X non prova a dire come una azione debba essere compiuta. Invece, vengono forniti degli strumenti all’utente, ed è quindi responsabilità dell’utente decidere come usare questi strumenti.
Questa filosofia si estende al fatto che X non dice come le finestre debbano comparire sullo schermo, né come queste debbano essere spostate con il mouse, né quali tasti servano per muoversi attraverso le finestre (ad esempio, Alt+Tab, nel caso di Microsoft® Windows®), né che aspetto devono avere le barre sopra ogni finestra, se queste hanno o meno bottoni di chiusura, e così via.
Al contrario X delega questa responsabilità ad una applicazione chiamata "Window Manager". Ci sono dozzine di window manager disponibili per X; AfterStep, Blackbox, ctwm, Enlightenment, fvwm, Sawfish, twm, Window Maker, ed altri. Ciascuno di questi window manager fornisce un diverso aspetto ed ambiente; alcuni di questi supportano i "virtual desktop"; alcuni consentono di avere delle combinazioni di tasti predefinite per gestire il desktop; altri hanno un pulsante "Start" o simile; altri possono avere dei "temi", permettendo un cambio completo di aspetto e funzionalità applicando un nuovo tema. Questi window manager, e molti altri, sono disponibili nella categoria x11-wm dei Port.
Inoltre, i desktop environments KDE e GNOME hanno tutti e due il proprio window manager che si integra con il desktop.
Ciascun window manager inoltre ha a un proprio meccanismo di configurazione; alcuni si aspettano di avere un file di configurazione scritto a mano, altri hanno delle interfacce grafiche per molti dei compiti di configurazione; almeno uno (Sawfish) ha un file di configurazione scritto in un dialetto del linguaggio Lisp.
Regole di fuoco Un’altra caratteristica per la quale il window manager deve avere responsabilità è la cosiddetta "focus policy", o Regola di fuoco. Ogni sistema a finestre necessita di un modo per scegliere la finestra che deve essere attiva e che deve ricevere le comunicazioni da tastiera, e dovrebbe anche indicare in modo visibile quale finestra è attiva in un determinato momento. Una Focus policy familiare è chiamata "click-to-focus". Questo è il modello utilizzato da Microsoft® Windows®, nel quale una finestra diventa attiva dopo aver ricevuto un click del mouse. X non supporta alcuna focus policy particolare. È invece il Window Manager che controlla quale finestra è attiva in un determinato momento. Diversi Window manager supporteranno diversi metodi di focus. Tutti supportano il click-to-focus, e la maggioranza di questi ne supporta molti altri. Le regole di fuoco più popolari sono:
Molti window manager supportano altre policy, come possono avere variazioni sul tema. Per maggiori informazioni vi preghiamo di consultare la documentazione stessa del window manager. |
L’approccio di X di fornire strumenti e non regole si estende anche ai widget visti sullo schermo in ogni applicazione.
"Widget" è un termine usato per tutte quelle parti nell’interfaccia utente che possono essere cliccate o manipolate in un certo modo; bottoni, checkboxes, radio buttons, icone, liste, e così via. Microsoft® Windows® li chiama "controlli".
Sia Microsoft® Windows® che Apple Mac OS® hanno delle regole strette per i widget. Gli sviluppatori devono assicurarsi che tutte le loro applicazioni condividano lo stesso stile e lo stesso aspetto. Con X, non si è sentito un particolare bisogno di obbligare ad avere un particolare stile grafico, o settare widgets a cui aderire.
Come risultato, non aspettatevi che le applicazioni per X abbiano lo stesso stile e lo stesso aspetto. Ci sono alcuni widgets popolari e le loro variazioni, come l’originale Athena sviluppato dal MIT, Motif® (dal quale è stato modellato il widget presente su Microsoft® Windows®, tutti angoli a doppio livello e tre sfumature di grigio), OpenLook, ed altri.
Molte applicazioni nuove di X di oggi usano un widget con sembianze moderne, probabilmente Qt, usato da KDE, o GTK+, usato da GNOME. Rispetto a questo, c’è un accenno di convergenza nell’aspetto dei desktop UNIX, il che facilita le cose ai nuovi utenti.
Xorg è l’implementazione di default di X11 per FreeBSD. Xorg è l’implementazione dell’X server dell’X Window System rilasciato dalla Fondazione X.Org. Xorg è basato sul codice di XFree86™ 4.4RC2 e X11R6.6. La versione di Xorg disponibile al momento nella Collezione dei Ports è 7.7.
Per compilare ed installare Xorg dalla Collezione dei Ports digita:
# cd /usr/ports/x11/xorg
# make install cleanPer compilare Xorg nella sua interezza, accertati di avere almeno 4 GB di spazio libero disponibile. |
In alternativa, X11 può essere installato direttamente dai pacchetti. Per X11 sono disponibili anche pacchetti binari da usare con pkg_add(1). Quando si usa il download da remoto di pkg_add(1), il numero di versione deve essere rimosso. pkg_add(1) scaricherà automaticamente l’ultima versione dell’applicazione.
Quindi per scaricare ed installare il pacchetto di Xorg, semplicemente digita:
# pkg_add -r xorgGli esempi sopra riportati installeranno la distribuzione completa di X11 inclusi i server, i client, i font etc. Sono anche disponibili pacchetti e port separati di X11. |
Il resto del capitolo spiegherà come configurare X11 e come impostare un desktop enviroment produttivo
Prima di configurare X11 è necessario avere le seguenti informazioni sul sistema:
Specifiche del Monitor
Chipset della Scheda Video
Memoria della Scheda Video
Le specifiche del monitor sono usate da X11 per determinare la risoluzione ed il refresh rate ai quali girare. Queste specifiche possono essere di solito ottenute dalla documentazione che è arrivata con il monitor o dal sito web del produttore. Ci sono i due intervalli di numeri di cui è necessario conoscere il valore, l’horizontal scan rate ed il vertical scan rate.
Il chipset della scheda video determina quale modulo driver X11 usa per parlare con l’hardware grafico. Con la maggior parte dei chipset, questo può essere determinato automaticamente, ma è ancora utile conoscerlo caso mai la ricerca automatica non funzioni correttamente.
La memoria della scheda video determina la risoluzione e la profondità dei colori ai quali il sistema può funzionare. È importante conoscerlo cosicchè l’utente conosca i limiti del sistema.
A partire dalla versione 7.3, Xorg può spesso lavorare senza un file di configurazione particolare semplicemnte digitando al prompt:
% startxSe non funziona, o se la configurazione di default non è accettabile, allora X11 deve essere configurato manualmente. La configurazione di X11 è un processo dai molti passi. Il primo passo è creare un file di configurazione iniziale. Come super utente digita semplicemente:
# Xorg -configureQuesto genererà uno scheletro di configurazione di X11 nella directory /root chiamato xorg.conf.new (il fatto che tu abbia fatto un su(1) o che tu abbia fatto una login diretta determina la variabile ereditata $HOME). Il programma X11 cercherà di determinare l’hardware grafico usato sul sistema e scriverà un file di configurazione per caricare i driver corretti per l’hardware presente sul sistema.
Il prossimo passo è testare la configurazione esistente per verificare che Xorg possa funzionare con l’hardware grafico sul sistema. Per eseguire questo passo, digita:
# Xorg -config xorg.conf.newSe appare una griglia bianca e nera con un cursore del mouse ad X, la configurazione ha avuto successo. Per uscire dal testo, premi Ctrl+Alt+Backspace simultaneamente.
Se il mouse non funziona, devi configurarlo prima di continuare. Leggi Configurazione del Mouse nel capitolo di installazione di FreeBSD. |
Quindi, fai il tuning di xorg.conf.new a piacere. Apri il file in un editor come emacs(1) o ee(1). Per prima cosa aggiungi le frequenze per il monitor del sistema. Queste sono di solito espresse come synchronization rate orizzontali e verticali. Questi valori sono aggiunti al file xorg.conf.new sotto la sezione "Monitor":
Section "Monitor"
Identifier "Monitor0"
VendorName "Monitor Vendor"
ModelName "Monitor Model"
HorizSync 30-107
VertRefresh 48-120
EndSectionLe parole chiave HorizSync e VerRefresh possono mancare sul file di configurazione. Se mancano, è necessario aggiungerle con la corretta horizontal synchronization rate dopo la parola chiave HorizSync e la vertical synchronization rate dopo la parola chiave VertRefresh. Nell’esempio sopra sono stati immessi i valori corretti per il sistema di riferimento.
X permette che siano usate le feature di DPMS (Energy Star) con i monitor che ne dispongono. Il programma xset(1) controlla i timeout e può forzare lo standby, la sospensione o lo spegnimento. Se desideri abilitare features di DPMS per il tuo monitor, devi aggiungere le seguenti linee alla sezione del monitor:
Option "DPMS"
Mentre il file di configurazione xorg.conf.new è ancora aperto in un editor, seleziona la risoluzione di default e la profondità del colore desiderata. Questa è definita nella sezione "Screen":
Section "Screen"
Identifier "Screen0"
Device "Card0"
Monitor "Monitor0"
DefaultDepth 24
SubSection "Display"
Viewport 0 0
Depth 24
Modes "1024x768"
EndSubSection
EndSectionla parola chiave DefaultDepth descrive la profondità dei colori da usare di default. Questa opzione può essere sovrascritta con l’opzione da command line -depth di Xorg(1). La parola chiave Modes descrive la risoluzione sotto cui girare per una data profondità di colori. Nota che solo i modi standard VESA sono supportati come definito dall’hardware grafico del sistema. Nell’esempio di prima, la risoluzione accettata è 1024 per 768 pixels.
Alla fine, scrivi il file di configurazione e testalo usando la modalità test spiegata in precedenza.
Uno dei tool disponibili per assisterti durante la fase di risoluzione dei problemi sono i log file di X11, che contengono l’informazione su ogni device a cui il server X11 si collega. I nomi dei log file di Xorg sono nel formato /var/log/Xorg.0.log. Il nome esatto del log può variare da Xorg.0.log a Xorg.8.log e così via. |
Se è andato tutto bene, il file di configurazione deve essere installato in una directory dove Xorg(1) possa trovarlo. Questa è tipicamente /etc/X11/xorg.conf o /usr/local/etc/X11/xorg.conf.
# cp xorg.conf.new /etc/X11/xorg.confIl processo di configurazione di X11 è ora completo. Xorg può ora essere avviato con la utility startx(1). Il server X11 può essere anche avviato con l’uso di xdm(1).
Esiste anche un tool di configurazione grafico, xorgcfg(1) che viene distribuito con X11. Ti permette di di definire la tua configurazione scegliendo i driver appropriati e le impostazioni. Questo programma può essere invocato dalla console, digitando In alternativa c’è anche un tool chiamato xorgconfig(1). Questo programma è una utility della console che è meno user friendly, ma potrebbe funzionare in situazioni nelle quali gli altri tool non funzionano. |
La configurazione dei chipset integrati Intel® i810 richiede l’interfaccia di programmazione AGP agpgart perchè X11 possa usare la scheda. Consulta la pagina di manuale del driver agp(4) per maggiori informazioni.
Questo permetterà la configurazione dell’hardware come ogni altra scheda grafica. Nota che su sistemi senza il driver agp(4) compilato nel kernel, cercare di caricare il modulo con kldload(8) non funzionerà. Questo driver deve essere nel kernel al momento del boot, o compilandolo nel kernel, o usando /boot/loader.conf.
Questa sezione assume una conoscenza della configurazione un pò avanzata. Se i tentativi di usare gli strumenti di configurazione standard descritti in precedenza non hanno avuto successo, ci sono abbastanza informazioni nei file di log utile per fare funzionare l’installazione. Sarà necessario un editor testuale.
Al momento i formati a tutto schermo (WSXGA, WSXGA+, WUXGA, WXGA, WXGA+, et.al.) supportano i formati 16:10 e 10:9 o frazioni dell’aspetto grafico che possono essere problematiche. Esempi di alcune risoluzioni del monitor comuni per la frazione dell’aspetto grafico sono:
2560x1600
1920x1200
1680x1050
1440x900
1280x800
In futuro, questo compito sarà semplice come aggiungere una di queste risoluzioni come possibile Mode nella Section "Screen", come viene mostrato di seguito:
Section "Screen"
Identifier "Screen0"
Device "Card0"
Monitor "Monitor0"
DefaultDepth 24
SubSection "Display"
Viewport 0 0
Depth 24
Modes "1680x1050"
EndSubSection
EndSectionXorg è abbastanza furbo da ottenere le informazioni di risoluzione dal widescreen via I2C/DDC, così conosce quali formati il monitor possa gestire come frequenze e risoluzioni.
Se quelle ModeLines non esistono nei driver, uno potrebbe avere necessità di dare ad Xorg un piccolo aiuto. Usando /var/log/Xorg.0.log uno può estrarre abbastanza informazioni da creare manualmente una Modeline che funziona. Basta cercare linee che assomigliano a queste:
(II) MGA(0): Supported additional Video Mode: (II) MGA(0): clock: 146.2 MHz Image Size: 433 x 271 mm (II) MGA(0): h_active: 1680 h_sync: 1784 h_sync_end 1960 h_blank_end 2240 h_border: 0 (II) MGA(0): v_active: 1050 v_sync: 1053 v_sync_end 1059 v_blanking: 1089 v_border: 0 (II) MGA(0): Ranges: V min: 48 V max: 85 Hz, H min: 30 H max: 94 kHz, PixClock max 170 MHz
Questa informazione è chiamata informazione EDID. Creare una ModeLine da questa è solo questione di mettere i numeri nell’ordine giusto:
ModeLine <name> <clock> <4 horiz. timings> <4 vert. timings>
Così la ModeLine nella sezione "Monitor" in questo esempio somiglierebbe a questa:
Section "Monitor"
Identifier "Monitor1"
VendorName "Bigname"
ModelName "BestModel"
ModeLine "1680x1050" 146.2 1680 1784 1960 2240 1050 1053 1059 1089
Option "DPMS"
EndSectionAdesso, dopo aver completato questi semplici passi con l’editor, X dovrebbe partire sul tuo monitor a tutto schermo.
I font di default che vengono distribuite con X11 non sono certo ideali per il tipico desktop di pubblicazione. I font grandi delle presentazioni appaiono confuse e non professionali, e i piccoli font in getenv(3) sono quasi illeggibili. Comunque, ci sono molti font Type1 gratis e di alta qualità (PostScript®) disponibili che possono essere usate subito con X11. Ad esempio la collezione dei font URW (x11-fonts/urwfonts) include versioni di alta qualità di font standard type1 (Times Roman™, Helvetica™, Palatino™ ed altre). La collezione Freefonts (x11-fonts/freefonts) include molti altri font, ma la maggior parte di loro sono fatte per essere usate con software grafico come Gimp e non sono abbastanza complete per essere usate come font di schermo. Inoltre, X11 può essere configurato per usare i font TrueType® con un minimo sforzo. Per ulteriori dettagli leggi la pagina di manuale di X(7) o la sezione sui font TrueType®.
Per installare la collezione dei font Type1 sopra citate, esegui il seguente comando:
# cd /usr/ports/x11-fonts/urwfonts
# make install cleanE in maniera analoga per freefont o altre collezioni. Per fare sì che l’X server usi questi font, aggiungi una linea appropriata al file di configurazione dell’X server (/etc/X11/xorg.conf), simile a questa:
FontPath "/usr/local/lib/X11/fonts/URW/"
Alternativamente, alla command line in una sessione di X esegui:
% xset fp+ /usr/local/lib/X11/fonts/URW
% xset fp rehashQuesto funzionerà ma sarà perso quando la sessione X viene chiusa, a meno che non sia aggiunto al file di startup (~/.xinitrc per una normale sessione startx, o ~/.xsession quando ci si logga attraverso un login manager grafico come XDM). Un terzo modo è usare il nuovo file /usr/local/etc/fonts/local.conf: consulta la sezione su anti-aliasing.
Xorg ha il supporto nativo per rendere i font TrueType®. Ci sono due differenti moduli che possono abilitare questa funzionalità. Il modulo freetype è usato in questo esempio perchè è più consistente con gli altri back-end di rendering degli altri font. Per abilitare il modulo freetype basta che aggiungi la seguente linea nella sezione "Module" del file /etc/X11/xorg.conf:
Load "freetype"
Adesso crea una directory per i font TrueType® (ad esempio /usr/local/lib/X11/fonts/TrueType) e copia tutte i font TrueType® in questa directory. Ricordati che i font TrueType® non possono essere prese direttamente da un Macintosh®, devono essere in formato UNIX®/MS-DOS®/Windows® per essere usate da X11. Una volta che i file sono stati copiati in questa directory, usa il comando ttmkfdir per creare un file fonts.dir, così che il renderer di font X sappia che questi nuovi file sono stati installati. ttmkfdir è disponibile dalla Collezione dei Ports di FreeBSD come x11-fonts/ttmkfdir.
# cd /usr/local/lib/X11/fonts/TrueType
# ttmkfdir -o fonts.dirAdesso aggiungi la directory TrueType® al percorso dei font. È lo stesso procedimento seguito sopra per i font Type1, ovvero usa
% xset fp+ /usr/local/lib/X11/fonts/TrueType
% xset fp rehasho aggiungi una linea FontPath al file xorg.conf.
Questo è tutto. Adesso getenv(3), Gimp, StarOffice™ e tutte le altre applicazioni X dovrebbero riconoscere i font TrueType® installate. I font molto piccoli (come del testo mostrato in alta risoluzione su una pagina web) e font estremamente grandi (all’interno di StarOffice™) avranno un’apparenza molto migliore.
L’anti-aliasing dei font è stato disponibile per X11 a partire da XFree86™ 4.0.2. Tuttavia la configurazione dei font era complicata prima dell’introduzione di XFree86™ 4.3.0. A partire da XFree86™ 4.3.0, tutte i font in X11 che sono trovati sotto le directory /usr/local/lib/X11/fonts/ e ~/.fonts/ sono automaticamente resi disponibili per l’anti aliasing ad applicazioni con supporto per Xft. Non tutte le applicazioni lo hanno, ma molte hanno ricevuto supporto per Xft. Esempi di applicazioni con supporto per Xft includono Qt 2.3 e successivi (il toolkit per il desktop KDE), GTK+ 2.0 e successivi (il toolkit per il desktop GNOME) e Mozilla 1.2 e successivi.
Per controllare quali font sono anti-aliased, o per configurare delle proprietà anti-alias, crea (o edita, se esiste già) il file /usr/local/etc/fonts/local.conf. Molte caratteristiche avanzate del sistema di font Xft possono essere configurate usando questo file; questa sezione descrive solo alcune semplici possibilità. Per ulteriori dettagli, consulta fonts-conf(5).
Questo file deve essere in formato XML. Presta particolare attenzione al case, e accertati che tutti i tag siano chiusi propriamente. Il file inizia con l’header usuale XML seguito da una definizione DOCTYPE, poi usa il tag <fontconfig>:
<?xml version="1.0"?> <!DOCTYPE fontconfig SYSTEM "fonts.dtd"> <fontconfig>
Come ricordato in precedenza, tutti i font in /usr/local/lib/X11/fonts/ così come quelli in ~/.fonts/ sono già resi disponibili alle applicazioni pronte per Xft. Se desideri aggiungere un’altra directory fuori da queste due alberature di directory, aggiungi una linea simile a questa in /usr/local/etc/fonts/local.conf:
<dir>/path/to/my/fonts</dir>
Dopo aver aggiunto i nuovi font, e specialmente nuove directory, dovresti eseguire questo comando per ricostruire la cache dei font:
# fc-cache -fL’anti-aliasing rende i bordi un pò confusi, il che rende il testo piccolo più leggibile e rimuove le "scale" dal testo grande, ma può causare una cattiva visuale se applicato al testo normale. Per escludere i font di dimensione minore di 14 punti dall’anti-aliasing includi le seguenti linee:
<match target="font">
<test name="size" compare="less">
<double>14</double>
</test>
<edit name="antialias" mode="assign">
<bool>false</bool>
</edit>
</match>
<match target="font">
<test name="pixelsize" compare="less" qual="any">
<double>14</double>
</test>
<edit mode="assign" name="antialias">
<bool>false</bool>
</edit>
</match>Anche lo spazio per alcuni font a spazio singolo potrebbe essere inappropriato con l’anti-aliasing. Questo pare che sia un problema in particolare con KDE. Una possibile soluzione a questo è forzare lo spazio di questi font a 100. Aggiungi le seguenti linee:
<match target="pattern" name="family">
<test qual="any" name="family">
<string>fixed</string>
</test>
<edit name="family" mode="assign">
<string>mono</string>
</edit>
</match>
<match target="pattern" name="family">
<test qual="any" name="family">
<string>console</string>
</test>
<edit name="family" mode="assign">
<string>mono</string>
</edit>
</match>(questo crea un alias per altri nomi comuni di font a dimensione fissa come "mono"), e poi aggiungi:
<match target="pattern" name="family">
<test qual="any" name="family">
<string>mono</string>
</test>
<edit name="spacing" mode="assign">
<int>100</int>
</edit>
</match>Alcuni font, come Helvetica, potrebbero avere un problema quando sono resi anti-alias. In genere questo si manifesta come un font che sembra tagliato in verticale. Nella peggiore delle ipotesi, questo potrebbe causare il crash delle applicazioni come Mozilla. Per evitarlo, considera di aggiungere queste linee a local.conf:
<match target="pattern" name="family">
<test qual="any" name="family">
<string>Helvetica</string>
</test>
<edit name="family" mode="assign">
<string>sans-serif</string>
</edit>
</match>Quando hai finito di editare il file local.conf accertati di mettere alla fine del file il tag </fontconfig>. Se non lo fai le tue modifiche saranno ignorate.
Il set di font che viene di default con X11 non è molto desiderabile quando viene reso sotto anti-alias. Un set molto migliore può essere trovato nel port x11-fonts/bitstream-vera. Questo port installerà un file /usr/local/etc/fonts/local.conf se non esiste già. Se il file esiste, il port creerà un file /usr/local/etc/fonts/local.conf-vera. Unisci il contenuto di questo file in /usr/local/etc/fonts/local.conf e i font Bitstream automaticamente rimpiazzeranno le X11 Serif di default, Sans Serif, e Monospaced.
Alla fine, gli utenti possono aggiungere le loro impostazioni attraverso i loro file personali .fonts.conf. Per farlo, ogni utente dovrebbe crearsi semplicemente un file ~/.fonts.conf. Anche questo file dovrebbe essere in formato XML.
Un ultimo punto: con uno schermo LCD, potrebbe essere desiderabile una resa sub-pixel. In sostanza questo tratta le componenti rosse, verdi e blu in modo separato per migliorare la risoluzione orizzontale; il risultato è notevole. Per abilitarlo, aggiungi queste linee da qualche parte nel file local.conf:
<match target="font">
<test qual="all" name="rgba">
<const>unknown</const>
</test>
<edit name="rgba" mode="assign">
<const>rgb</const>
</edit>
</match>A seconda del tipo di display, |
L’anti-aliasing dovrebbe essere abilitato la prossima volta che il server X sarà avviato. Comunque, i programmi devono sapere come avvantaggiarsene. Al momento, il toolkit Qt lo sa, così l’intero ambiente KDE può usare font anti-aliased. GTK+ e GNOME possono essere rese compatibili con l’anti-aliasing attraverso il capplet "Font" (leggi Font anti-aliased con GNOME per dettagli). Di default Mozilla 1.2 e successivi sapranno come usare automaticamente l’anti-aliasing. Per disabilitarlo, ricompila Mozilla con il flag DWITHOUT_XFT.
L’X Display Manager (XDM) è una parte opzionale dell’X Windows System che è usata per la gestione delle sessioni di login. Questo è utile in molte situazioni, inclusi desktop "X Terminal " minimali, e grandi reti di display server. Dato che l’X Window System è indipendente dalla rete e dal protocollo, c’è una grande moltitudine di configurazioni possibili per eseguire client X e server X su diverse macchine connesse da una rete. XDM fornisce un’interfaccia grafica per scegliere a quale display manager collegarsi, e digitare le informazioni di autenticazione come una combinazione di login e password.
Puoi pensare a XDM come a qualcosa che fornisce all’utente la stessa funzionalità dell’utility getty(8) (vedi ad esempio Configurazione per dettagli). In poche parole, gestisce login di sistema al display al quale si è collegati e quindi esegue un session manager per conto dell’utente (di solito un X Window Manager). XDM quindi attende che questo programma termini, segnalando che l’utente ha finito e che dovrebbe essere mandato fuori dal display. A questo punto XDM può mostrare lo schermo di login e di scelta degli schermi per il prossimo utente.
Il programma demone è situato in /usr/local/bin/xdm. Questo programma può essere avviato in ogni istante come root e inizierà a gestire il display X sulla macchina locale. Se XDM deve essere eseguito ogni volta che la macchina fa il boot, un modo conveniente è quello di farlo aggiungendo una entry a /etc/ttys. Per maggiori informazioni sul formato e l’uso di questo file, consulta Aggiunta di un Elemento in /etc/ttys. C’è una linea nel file di default /etc/ttys per eseguire il demone XDM su un terminale virtuale:
ttyv8 "/usr/local/bin/xdm -nodaemon" xterm off secureDi default questa entry è disabilitata; al fine di abilitarla cambia il campo 5 da off ad on e riavvia init(8) usando le direttive in Come Forzare init a Rileggere /etc/ttys. Il primo campo, il nome del terminale che questo programma gestirà, è ttyv8. Questo significa che XDM si avvierà sul nono terminale virtuale.
La directory di configurazione di XDM è situata in /usr/local/lib/X11/xdm. In questa directory ci sono molti file usati per cambiare il comportamento e l’aspetto di XDM. Tipicamente in questi file sarà trovato:
| File | Descrizione |
|---|---|
Xaccess | Regole di autorizzazione del client. |
Xresources | Valori di default delle risorse X. |
Xservers | Lista dei display locali e remoti da gestire. |
Xsession | Script di default delle sessioni di login. |
Xsetup_* | Script per lanciare applicazioni prima dell’interfaccia di login. |
xdm-config | Configurazione globale per tutti i display che girano su questa macchina. |
xdm-errors | Errori generati dal programma server. |
xdm-pid | L’id di processo dell’XDM che è in esecuzione al momento. |
In questa directory ci sono anche alcuni scripts e programmi usati per impostare il desktop quando XDM è in esecuzione. Lo scopo di ognuno di questi file sarà descritto brevemente. La sintassi esatta e l’uso di tutti questi file è descritto in xdm(1).
La configurazione di default è una semplice finestra di login rettangolare con l’hostname della macchina mostrato in cima a grandi caratteri e sotto un prompt di "Login:" e "Password:". Questo è un buon punto di inizio per cambiare l’aspetto degli schermi XDM.
Il protocollo per connettersi ai display controllati da XDM è chiamato l’X Display Manager Connection Protocol (XDMCP). Questo file è un insieme di regole per controllare le connessioni XDMCP da remoto. È ignorato a meno che xdm-config sia cambiato per restare in ascolto di connessioni remote. Di default non permette a nessun client di connettersi.
Questa è un file di default dell’applicazione per il selettore di display e schermate di login. In questo, l’apparenza del programma di login può essere modificata. Il formato è identico al file app-default descritto nella documentazione di X11.
Questo è una lista dei display remoti che il programma di selezione dovrebbe fornire come scelta.
Questo è lo script di default delle sessioni per XDM da eseguire dopo che un utente si è loggato. Normalmente ogni utente avrà uno script di sessione personalizzato in ~/.xsession che sovrascriverà questo script.
Questi andranno automaticamente in esecuzione prima di mostrare il selettore o le interfacce di login. C’è uno script per ogni display in uso, chiamato Xsetup_ seguito dal numero del display locale (per esempio Xsetup_0). Tipicamente questi script eseguirannno uno o due programmi in background come xconsole.
Questo contiene le impostazioni nella forma di default di applicazioni che sono applicabili ad ogni display che questa installazione gestisce.
Questo contiene l’output di ogni X server che XDM cerca di eseguire. Se un display che XDM gestisce si blocca per qualche motivo, questo è un buon posto per cercare messaggi di errore. Questi stessi messaggi sono anche scritti nel file dell’utente ~/.xsession-errors in base alla sessione.
Affinchè gli altri clienti si connettano al server di display, devi editare le regole di controllo degli accessi ed abilitare il processo in ascolto di connessioni. Di default queste sono impostate a valori conservativi. Per far sì che XDM resti in ascolto in attesa di connessioni, per prima cosa decommenta una linea nel file xdm-config:
! SECURITY: do not listen for XDMCP or Chooser requests
! Comment out this line if you want to manage X terminals with xdm
DisplayManager.requestPort: 0e poi riavvia XDM. Ricordati che i commenti nei file app-default iniziano con un carattere "!", non con l’usuale "#". Possono essere desiderabili controlli degli acccessi più stretti - guarda le entry di esempio in Xaccess, e fai riferimento alla pagina di manuale di xdm(1) per ulteriori informazioni.
Ci sono molti programmi sostitutivi per il classico programma XDM. Uno di questi, kdm (distribuito con KDE) viene descritto successivamente in questo capitolo. Il display manager kdm offre molti miglioramenti visuali e rifiniture grafiche, come anche la possibilità di permettere agli utenti di scegliere il loro window manager al momento del login.
Questa sezione descrive alcuni diversi desktop environment disponibili per X su FreeBSD. Un "desktop environment" può significare tutto ciò che va da un semplice window manager ad una completa suite di applicazioni desktop, come KDE o GNOME.
GNOME è un desktop environment user-friendly che permette agli utenti di usare semplicemente il loro computer e configurarlo. GNOME include un pannello (per avviare le applicazioni e mostrarne lo status), un desktop (dove dati ed applicazioni possono essere posti), un insieme di strumenti da desktop ed applicativi, ed un insieme di convenzioni che rendono semplice per le applicazioni la cooperazione e la consistenza reciproca. Gli utenti di altri sistemi operativi o environment dovrebbero sentirsi a casa loro usando il potente ambiente grafico che GNOME offre. Ulteriori informazioni a proposito di GNOME su FreeBSD possono essere trovate sul sito FreeBSD GNOME Project. Il sito web contiene anche delle FAQ abbastanza estese circa l’installazione, la configurazione, e la gestione di GNOME.
Il software può essere installato facilmente da un pacchetto o dalla collezione dei Ports:
Per installare il pacchetto GNOME dalla rete, semplicemente digita:
# pkg_add -r gnome2Per compilare GNOME da sorgenti, usa l’albero dei ports:
# cd /usr/ports/x11/gnome2
# make install cleanUna volta che GNOME è installato, bisogna dire al server X di avviare GNOME invece del window manager di default.
Il modo più semplice per avviare GNOME è con GDM, il Display Manager di GNOME. GDM, che è installato come parte del desktop GNOME (ma è disabilitato di default) può essere abilitato aggiungendo gdm_enable="YES" a /etc/rc.conf. Una volta che hai rebootato, GNOME partirà automaticamente una volta che ti logghi - nessuna altra configurazione è necessaria.
GNOME può anche essere avviato dalla command-line configurando propriamente un file chiamato .xinitrc. Se un file personalizzato .xinitrc è già al suo posto, semplicemente sostituisci la linea che avvia il window manager corrente con una che invece avvia /usr/local/bin/gnome-session. Se invece non è stato fatto nulla di speciale al file di configurazione, dovrebbe essere sufficiente digitare:
% echo "/usr/local/bin/gnome-session" > ~/.xinitrcQuindi, digita startx e il desktop environment GNOME sarà avviato.
Se un precedente display manager, come XDM, è in uso, questo non funzionerà. Invece, crea un file eseguibile .xsession con lo stesso comando dentro. Per farlo edita il file e sostituisci il window manager esistente con /usr/local/bin/gnome-session: |
% echo "#!/bin/sh" > ~/.xsession
% echo "/usr/local/bin/gnome-session" >> ~/.xsession
% chmod +x ~/.xsessionUn’altra opzione è configurare il display manager per scegliere il window manager al momento di login; la sezione in KDE details spiega come farlo per kdm, il display manager di KDE.
X11 supporta l’anti-aliasing attraverso l’estensione "RENDER". GTK+ 2.0 e successivi (il toolkit usato da GNOME) può fare uso di questa funzionalità. Configurare l’anti-aliasing è descritto in Font Anti-Aliased. Così, con software aggiornato, è possibile usare l’anti-aliasing all’interno del desktop GNOME. Basta che vai in , e selezioni Best shapes, Best contrast, o Subpixel smoothing (LCDs). Per una applicazione GTK+ che non è parte di GNOME, imposta la variabile di ambiente GDK_USE_XFT a 1 prima di avviare il programma.
KDE è un desktop environment facila da usare. Alcune delle caratteristiche che KDE fornisce alll’utente sono:
Un bel desktop moderno
Un desktop che esibisce una totale trasparenza rispetto alla rete.
Un sistema di help integrato che permette accesso conveniente e consistente all’aiuto sull’uso del desktop KDE e le sue applicazioni
Un aspetto delle applicazioni KDE consistente fra loro
Menu e toolbars standardizzate, key-bindings, color-scheme etc.
Internazionalizzazione: KDE è disponibile in più di 40 linguaggi
Configurazione del desktop centralizzata, consistente e guidata da finestre dialog
Un gran numero di utili applicazioni KDE
KDE viene installato con un browser chiamato Konqueror, che è un solido competitore di altri browser esistenti su sistemi UNIX®. Maggiori informazioni su KDE possono essere trovati al sito di KDE. Per informazioni specifiche su FreeBSD e risorse su KDE consulta il sito KDE sul sito del team di FreeBSD.
Proprio come con GNOME o altri desktop environment, il software può essere installato facilmente da pacchetto o dalla Collezione dei Port:
Per installare il pacchetto KDE dalla rete, semplicemente digita:
# pkg_add -r kdepkg_add(1) automaticamente scaricherà l’ultima versione dell’applicazione.
Per compilare KDE dai sorgenti, usa l’albero dei ports:
# cd /usr/ports/x11/kde3
# make install cleanDopo che KDE è stato installato, bisogna dire al server X di avviarlo al posto del window manager di default. Questo si ottiene editando il file .xinitrc:
% echo "exec startkde" > ~/.xinitrcAdesso, ogni volta che l’X Window System è avviato con startx, KDE sarà il desktop.
Se si usa un display manager come XDM, la configurazione è leggermente differente. Devi infatti editare il file .xsession. Le istruzioni per kdm sono descritte di seguito in questo capitolo.
Adesso che KDE è installato sul tuo computer, la maggior parte delle cose le puoi scoprire attraverso le pagine dell’help, o semplicemente puntando e cliccando qualche menu. Gli utenti Windows® e Mac® si sentiranno abbastanza a loro agio.
Il migliore riferimento per KDE è la documentazione on-line. KDE arriva con il suo web browser, Konqueror, dozzine di utili applicazioni e documentazione estesa. Il resto di questa sezione discute dettagli tecnici che sono difficili da imparare da una esplorazione casuale.
Un amministratore di un sistema multiutente può desiderare di avere uno schermo di login grafico per dare il benvenuto agli utenti. XDM può essere usato, come descritto in precedenza. In ogni caso, KDE include un’alternativa, kdm, che è disegnato per essere più attraente ed includere maggiori opzioni di login. In particolare, gli utenti possono facilmente scegliere (attraverso un menu) quale desktop environment (KDE, GNOME o qualcos’altro) avviare dopo essersi loggati.
Per abilitare kdm, la entry ttyv8 in /etc/ttys deve essere adattata. La linea assomiglia a questa:
ttyv8 "/usr/local/bin/kdm -nodaemon" xterm on secure
XFce è un desktop environment basato sul toolkit GTK+ usato da GNOME, ma è molto più snello e disegnato per quelli che vogliono un semplice, efficiente desktop che sia non di meno facile da usare e configurare. Visivamente, assomiglia molto a CDE, il desktop che si trova su sistemi UNIX® commerciali. Alcune delle caratteristiche di XFce sono:
Un semplice desktop, facile da gestire
Interamente configurabile via mouse, con drag and drop, etc.
Pannelli principali simili a CDE, con menu, applets e lanciatori di applicazioni
Window manager integrato, file manager, sound manager, modulo di compatiblità GNOME e altro
I suoi temi si possono configurare (grazie a GTK+)
Veloce, snello ed efficiente: ideale per macchine vecchie/lente o macchine con poca memoria
Maggiori informazioni su XFce possono essere trovate sul sito web XFce.
Esiste un pacchetto binario per XFce al momento in cui scriviamo. Per installarlo, semplicemente digita:
# pkg_add -r xfce4In alternativa, per compilare dai sorgenti, usa la collezione dei ports:
# cd /usr/ports/x11-wm/xfce4
# make install cleanAdesso devi dire all’X server di lanciare XFce la prossima volta che X è avviato. Digita semplicemente questo:
% echo "/usr/local/bin/startxfce4" > ~/.xinitrcLa prossima volta che X è avviato, XFce sarà il desktop. Come prima, se un display manager come XDM è in uso, crea un .xsession, come descritto nella sezione su GNOME, ma con il comando /usr/local/bin/startxfce4; o configura il display manager per permetterti di scegliere un desktop al momento del login, come spiegato su kdm.
Ora che sono stati trattati gli elementi di base, questa parte del Manuale di FreeBSD verterà su alcune funzionalità di FreeBSD che sono usate di frequente. Questi capitoli:
Ti introdurranno utili e conosciute applicazioni desktop: browser, strumenti produttivi, visualizzatori di documenti, ecc.
Ti mostreranno vari strumenti multimediali disponibili per FreeBSD.
Ti spiegheranno il processo di costruzione e di personalizzazione del kernel di FreeBSD, al fine di abilitare funzionalità extra sul tuo sistema.
Ti descriveranno in dettaglio il sistema di stampa, sia per setup di stampanti desktop che per quelle in rete.
Ti mostreranno come eseguire applicazioni Linux sul tuo sistema FreeBSD.
Alcuni di questi capitoli raccomandano di leggere prima altri capitoli per una migliore comprensione degli stessi, e questo è segnalato nella sinossi all’inizio di ogni capitolo.
FreeBSD può far girare una gran varietà di applicazioni desktop, come ad esempio browser per la navigazione ed editor di testi. La maggior parte di questi sono disponibili in pacchetti o possono essere automaticamente installati dalla collezione di port. Molti nuovi utenti si aspettano di trovare questo tipo di applicazioni nei loro desktop. Questo capitolo ti mostrerà come installare alcune popolari applicazioni desktop, dai package o dalla collezione dei port.
Da notare che quando installiamo programmi dalla collezione dei port, questi sono compilati dai sorgenti. Questa operazione potrebbe durare molto tempo, dipende da cosa stai compilando e dalla potenza della tua macchina. Se per te compilare i sorgenti occupa un arco di tempo troppo lungo, puoi installare la maggior parte dei programmi della collezione dei port da pacchetti precompilati.
Visto che FreeBSD è compatibile con i binari di Linux, molte applicazione originariamente scritte per Linux sono disponibili per il tuo desktop. È fortemente raccomandata la lettura del Compatibilità con i Binari di Linux prima di installare qualsiasi applicazione per Linux. La maggior parte dei port che sfruttano la compatibilità con Linux iniziano con "linux-". Ricordatelo quando cerchi un port in particolare, per esempio con whereis(1). Nella parte seguente, si presuppone che tu abbia installato il supporto per la compatibilità con i binari di Linux prima di installare qualsiasi applicazione per Linux.
Queste sono le categorie software trattate in questo capitolo:
Browser (come ad es. Mozilla, Opera, Firefox, Konqueror)
Produttività (come ad es. KOffice, AbiWord, The GIMP, OpenOffice.org)
Visualizzatori di documenti (come ad es. Acrobat Reader®, gv, Xpdf, GQview)
Finance (come ad es. GnuCash, Gnumeric, Abacus)
Prima di leggere questo capitolo, dovresti:
Essere in grado di installare altro software di terze parti (Installazione delle Applicazioni. Port e Package).
Essere in grado di installare altro software per Linux (Compatibilità con i Binari di Linux).
Per informazioni su come avere un ambiente multimediale, leggi il Multimedia. Se vuoi installare e usare l’e-mail, sono presenti riferimenti nel Posta Elettronica.
In FreeBSD non viene preinstallato nessun browser in particolare. Invece, la directory www della collezione dei port contiene molti browser pronti per essere installati. Se non hai il tempo di compilare tutto (in alcuni casi potrebbe occupare molto tempo) molti di questi sono disponibili come package.
KDE e anche GNOME hanno dei browser HTML. Guarda la Desktop Environment per avere informazioni su come installare questi ambienti desktop.
Se stai cercando dei browser leggeri, dovresti controllare la collezione dei port per www/dillo, www/links, oppure www/w3m.
Questa sezione riguarda le seguenti applicazioni:
| Nome dell’applicazione | Livello di risorse necessarie | Installazione dai port | Principali dipendenze |
|---|---|---|---|
Mozilla | pesante | pesante | Gtk+ |
Opera | leggero | leggero | Versione FreeBSD e versione per Linux. La versione per Linux ha come dipendenze la Compatibilità binaria con Linux e linux-openmotif |
Firefox | medio | pesante | Gtk+ |
Konqueror | medio | pesante | Librerie KDE |
Mozilla è un browser moderno, stabile, e completamente supportato da FreeBSD: tra le caratteristiche un motore di visualizzazione di pagine che segue completamente lo standard HTML; ha inoltre un lettore di mail e news. Presenta anche un editor HTML se vuoi comporre della pagine web. Gli utenti di getenv(3) riconosceranno le somiglianze con la suite Communicator, in quanto entrambi i browser condividono parte dello sviluppo.
Su macchine lente, con una velocità di CPU minore di 233MHz o con meno di 64MB di RAM, Mozilla potrebbe utilizzare troppe risorse per essere eseguito al meglio. Potresti invece dare un’occhiata al browser Opera descritto poco più avanti in questo capitolo.
Se non puoi o non vuoi compilare Mozilla, per qualsiasi ragione, il FreeBSD GNOME team l’ha già fatto per te. Devi solo installare il pacchetto dalla rete con:
# pkg_add -r mozillaSe il pacchetto non è disponibile, e hai abbastanza tempo e spazio su disco, puoi prelevare i sorgenti di Mozilla, compilarli e installarli sul tuo sistema. Questo può essere fatto con:
# cd /usr/ports/www/mozilla
# make install cleanPuoi assicurarti una corretta inizializzazione del port di Mozilla attraverso l’esecuzione dell’utility chrome registry setup con i privilegi di root. In ogni caso se vuoi prelevare alcuni add-ons come ad esempio gestori del mouse, dovresti eseguire Mozilla come root per installarli correttamente.
Una volta completata l’installazione di Mozilla, non necessiti di essere ancora root. Puoi avviare Mozilla come browser digitando:
% mozillaPuoi avviarlo direttamente come lettore di mail e news come mostrato qui sotto:
% mozilla -mailFirefox è il browser di nuova generazione basato sul codice di Mozilla. Mozilla è una suite di applicazioni completa, includendo un browser, un client di posta elettronica, un client per chat e altro ancora. Firefox è solo un browser, e ciò lo rende di piccole dimensioni e veloce.
Installa il package con:
# pkg_add -r firefoxPuoi usare anche la collezione dei port se preferisci compilare il codice sorgente:
# cd /usr/ports/www/firefox
# make install cleanIn questa sezione e nella prossima, si presuppone che Firefox o Mozilla siano già installati. |
La FreeBSD Foundation ha una licenza con Sun Microsystems per distribuire i binari di FreeBSD relativi alla Java Runtime Environment (JRE™) e al Java Development Kit (JDK™). I package binari per FreeBSD sono disponibili sul sito web della FreeBSD Foundation.
Per aggiungere il supporto Java™ a Firefox o a Mozilla, devi prima installare il port java/javavmwrapper. Quindi, scarica il package Diablo JRE™ da http://www.freebsdfoundation.org/downloads/java.shtml, e installalo con pkg_add(1).
Avvia il tuo browser, digita about:plugins nella barra degli indirizzi e premi Invio. Verrà visualizzata una pagina con un riepilogo dei plugin installati, tra i quali dovrebbe comparire il plugin di Java™. Se questo non accade, come root, dai il comando seguente:
# ln -s /usr/local/diablo-jre1.5.0/plugin/i386/ns7/libjavaplugin_oji.so \
/usr/local/lib/browser_plugins/quindi riavvia il tuo browser.
Il plugin Flash™ della Macromedia® non è disponibile per FreeBSD. Tuttavia, esiste uno strato applicativo (wrapper) per eseguire una versione Linux del plugin. Questo wrapper inoltre supporta i plugin Adobe® Acrobat®, il plugin RealPlayer® e altri.
Installa il port www/linuxpluginwrapper. Questo port richiede emulators/linux_base che è un port di notevoli dimensioni. Segui le istruzioni a video per inizializzare correttamente il tuo /etc/libmap.conf! Esempi di configurazione sono installati nella directory /usr/local/shared/examples/linuxpluginwrapper/.
Il prossimo passo è installare il port www/linux-flashplugin7. Quando hai installato il plugin, avvia il tuo browser, digita about:plugins nella barra degli indirizzi e premi Invio. Dovrebbe comparire una lista con tutti i plugin disponibili.
Se il plugin di Flash™ non viene elencato, nella maggior parte dei casi si tratta di un link simbolico mancante. Digita i seguenti comandi come root:
# ln -s /usr/local/lib/npapi/linux-flashplugin/libflashplayer.so \
/usr/local/lib/browser_plugins/
# ln -s /usr/local/lib/npapi/linux-flashplugin/flashplayer.xpt \
/usr/local/lib/browser_plugins/Se fai ripartire il browser il plugin dovrebbe ora comparire nella lista menzionata in precedenza.
linuxpluginwrapper funziona solo su architetture i386™. |
Opera è un browser pieno di funzionalità, basato sugli standard attuali. Tra le altre cose include un client di posta, di news, un client IRC e un lettore RSS/Atom. Opera è relativamente leggero e molto veloce. È disponibile in due versioni: una "nativa" per FreeBSD e una che gira sotto emulazione Linux.
Per navigare nel web con la versione per FreeBSD di Opera, installa il package:
# pkg_add -r operaAlcuni siti FTP non hanno tutti i pacchetti, ma è possibile ottenere Opera con la collezione dei port digitando:
# cd /usr/port/www/opera
# make install cleanPer installare la versione Linux di Opera, sostituisci linux-opera al posto di opera nell’esempio sopra. La versione Linux è utile in situazioni che richiedono l’uso di plugin che sono disponibili solo per Linux, come ad esempio Adobe Acrobat Reader®. In tutti gli altri casi, le versioni per FreeBSD e Linux dovrebbero funzionare all stesso modo.
Konqueror fa parte di KDE ma è anche possibile usarlo senza KDE installando x11/kdebase3. Konqueror è molto più che un browser, è anche un file manager e un lettore multimediale.
Esistono alcuni plugin per Konqueror, disponibili in misc/konq-plugins.
Konqueror supporta Flash™; un "How To" per ottenere supporto a Flash™ con Konqueror è disponibile al link http://freebsd.kde.org/howto.php.
Quando si parla di produttività, i nuovi utenti spesso cercano un buon pacchetto office o un facile e completo editor di testi. Non ci sono applicativi di produttività di default, mentre alcuni ambienti desktop come KDE sono muniti di un pacchetto office. FreeBSD dispone di tutto ciò che è necessario, indipendentemente dal tuo ambiente desktop.
Questa sezione riguarda le seguenti applicazioni:
| Nome dell’applicazione | Livello di risorse necessarie | Installazione dai port | Principali dipendenze |
|---|---|---|---|
KOffice | leggero | pesante | KDE |
AbiWord | leggero | leggero | Gtk+ o GNOME |
The Gimp | leggero | pesante | Gtk+ |
OpenOffice.org | pesante | molto pesante | JDK™ 1.4, Mozilla |
La comunità KDE ha fornito il suo ambiente desktop di un pacchetto office che può essere usato all’esterno dell’ambiente KDE. Questo include le quattro principali componenti che sono presenti nelle altre principale suite di office. KWord è l’editor di testi, KSpread è il foglio di calcolo elettronico, KPresenter gestisce presentazioni a slide e Kontour ti permette di disegnare documenti grafici.
Prima di installare l’ultima release di KOffice, assicurati di avere una versione aggiornata di KDE.
Per installare KOffice come pacchetto, inserisci il seguente comando:
# pkg_add -r kofficeSe il pacchetto non è disponibile puoi usare la collezione dei port. Per esempio, per installare KOffice per KDE3, digita:
# cd /usr/ports/editors/koffice-kde3
# make install cleanAbiWord è un editor di testi gratuito simile in aspetto e non solo a Microsoft® Word. È adatto per la digitazione di documenti, lettere, reports, appunti e così via. È molto veloce, contiene molte funzioni, ed è molto facile da usare.
AbiWord può importare ed esportare file di molti tipi, compreso alcuni formati proprietari come i .doc di Microsoft®.
AbiWord è disponibile come package. Puoi installarlo digitando:
# pkg_add -r abiwordSe il pacchetto non è disponibile puoi recuperarlo dalla collezione dei port. La collezione dei port dovrebbe essere molto più aggiornata. Puoi fare come segue:
# cd /usr/ports/editors/abiword
# make install cleanPer il disegno o il ritocco delle immagini, GIMP è un programma di manipolazione immagini molto sofisticato. Può essere usato come un semplice programma di disegno o come un programma di foto-ritocco professionale. Supporta un grande numero di plug-in, funzioni e un’interfaccia di scripting. GIMP può leggere e scrivere una enorme quantità di formati di file. Offre supporto di interfacce per scanner o tavolette.
Puoi installare il pacchetto con il seguente comando:
# pkg_add -r gimpSe il tuo sito FTP non ha il pacchetto, puoi usare la collezione dei port. La directory graphics della collezione dei port contiene anche Il Manuale di Gimp. Di seguito riportiamo come installarli:
# cd /usr/ports/graphics/gimp
# make install clean
# cd /usr/ports/graphics/gimp-manual-pdf
# make install cleanLa directory graphics della collezione dei port contiene la versione di sviluppo di GIMP in graphics/gimp-devel. La versione in formato HTML del Manuale di Gimp è disponibile in graphics/gimp-manual-html. |
OpenOffice.org unisce tutte le applicazioni necessarie in un completo pacchetto office di produttività personale: un editor di testi, un foglio di calcolo, un software per le presentazioni e uno di disegno. La sua interfaccia utente è molto simile alle altre suite di office, può inoltre importare ed esportare file in diversi popolari formati. È disponibile in un gran numero di differenti lingue - l’internazionalizzazione è stata estesa alle interfacce, ai correttori ortografici, e ai dizionari.
L’editor di testi di OpenOffice.org usa come formato di file nativo il formato XML per incrementare la portabilità e la flessibilità. Il foglio di calcolo elettronico incorpora un linguaggio per le macro che può essere interfacciato con un database esterno. OpenOffice.org è stabile e e gira nativamente sotto Windows®, Solaris™, Linux, FreeBSD, e Mac OS® X. Altre informazioni riguardo OpenOffice.org possono essere trovate sul sito web di OpenOffice.org. Per informazioni specifiche su FreeBSD, e per scaricare direttamente i package, usa il sito web del FreeBSD OpenOffice.org Porting Team.
Per installare OpenOffice.org, digita:
# pkg_add -r openoffice.orgQuesto potrebbe funzionare quando hai una versione -RELEASE di FreeBSD. Altrimenti, dovresti dare un’occhiata al sito web del OpenOffice.org Porting Team per scaricare ed installare con pkg_add(1) il package appropriato. Sul sito sono disponibili sia la release corrente che la versione di sviluppo. |
Una volta installato il pacchetto, devi digitare il comando seguente per avviare OpenOffice.org:
% openoffice.orgAl primo avvio ti verrano poste alcune questioni e verrà creata la cartella .openoffice.org2 nella tua directory home. |
Se il pacchetto OpenOffice.org non è disponibile hai ancora la possibilità di compilare il port. Come sempre, devi tenere presente che necessiterai di molto spazio nel tuo hard disk e di molto tempo per la compilazione.
# cd /usr/ports/editors/openoffice.org-2
# make install cleanSe vuoi compilare una versione localizzata, sostituisci la linea di comando precedente con questa: Sostituisci il tuo linguaggio con il codice ISO-code corretto. Una lista di codici di linguaggi supportati è disponibile nel file files/Makefile.localized, posto nella directory del port. |
Fatto ciò, OpenOffice.org può essere avviato con il comando:
% openoffice.orgAlcuni nuovi formati di documenti hanno recentemente guadagnato popolarità dall’avvento di UNIX®; i visualizzatori standard che richiedono potrebbero non essere inclusi nel sistema base. Vedremo come installare questi visualizzatori in questa sezione.
Questa sezione riguarda le seguenti applicazioni:
| Nome dell’applicazone | Livello di risorse necessarie | Installazione dai port | Maggiori dipendenze |
|---|---|---|---|
Acrobat Reader® | leggero | leggero | Supporto per la compatibilità per i binari Linux |
gv | leggero | leggero | Xaw3d |
Xpdf | leggero | leggero | FreeType |
GQview | leggero | leggero | Gtk+ o GNOME |
Molti documenti sono ora distribuiti come documenti in PDF, che significa "Portable Document Format". Uno dei visualizzatori raccomandati per file di questo tipo è Acrobat Reader®, rilasciato da Adobe per Linux. Visto che FreeBSD può eseguire binari per Linux, è disponibile anche per FreeBSD.
Per installare Acrobat Reader® 7 dalla collezione dei port, digita:
# cd /usr/ports/print/acroread7
# make install cleanIl package non è disponibile a causa di restrizioni di licenza.
gv è un visualizzatore per file PostScript® e PDF. Era originariamente basato su ghostview ma ha un look più gradevole grazie alle librerie Xaw3d. È veloce e l’interfaccia è pulita. gv ha molte funzioni, come orientamento, dimensione del foglio, scala, o antialias. Molte di queste operazioni possono essere eseguite sia dalla tastiera che dal mouse.
Per installare gv come pacchetto, digita:
# pkg_add -r gvSe non puoi scaricare il pacchetto puoi utilizzare la collezione dei port:
# cd /usr/ports/print/gv
# make install cleanSe vuoi un piccolo visualizzatore di PDF per FreeBSD, Xpdf è un leggero ed efficiente visualizzatore. Ha bisogno di veramente poche risorse ed è molto stabile. Usa i font standard di X e non ha bisogno di Motif® o di altri toolkit di X.
Per installare il pacchetto Xpdf usa questo comando:
# pkg_add -r xpdfSe il pacchetto non è disponibile o preferisci usare la collezione dei port digita:
# cd /usr/ports/graphics/xpdf
# make install cleanUna volta completata l’installazione, puoi avviare Xpdf e puoi usare il tasto destro del mouse per visualizzare il menù.
GQview è un manager di immagini. Puoi visualizzare un file con un solo click, avviare un editor esterno, visualizzare l’anteprima e molto altro. Consente inoltre di visualizzare l’anteprima delle immagini come diapositive ed alcune basilari operazioni sui file. Puoi gestire le tue collezioni di immagini e trovare facilmente i duplicati. GQview può lavorare in modalità full-screen e ha il supporto internazionale.
Se vuoi installare il pacchetto GQview, digita:
# pkg_add -r gqviewSe il pacchetto non è disponibile o preferisci usare la collezione di port digita:
# cd /usr/ports/graphics/gqview
# make install cleanSe per qualsiasi ragione vorresti gestire il tuo bilancio personale sul tuo desktop FreeBSD, ci sono alcune applicazioni potenti e facili da usare pronti per essere installate. Alcuni di questi sono compatibili con i formati di file più utilizzati, come ad esempio i formati usati da Quicken o Excel per i documenti.
Questa sezione copre questi programmi:
| Nome dell’applicazione | Livello di risorse necessarie | Installazione dai port | Maggiori dipendenze |
|---|---|---|---|
GnuCash | leggero | pesante | GNOME |
Gnumeric | leggero | pesante | GNOME |
Abacus | leggero | leggero | Tcl/Tk |
KMyMoney | leggero | pesante | KDE |
GnuCash è parte del progetto di GNOME per mettere a disposizione degli utenti finali applicazioni facili da usare e potenti. Con GnuCash, puoi tenere traccie delle tue spese e dei tuoi guadagni, del conto bancario, o delle tue attività. Dispone di una interfaccia intuitiva pur rimanendo molto professionale.
GnuCash dispone di un ottimo registro, un sistema di account gerarchico, molte combinazioni di scelta rapida e tecniche di auto completamento. Può dividere una transazione singola in molte parti più dettagliate. GnuCash può importare e unire i file QIF di Quicken. Gestisce inoltre diversi formati esteri di valuta e data.
Per installare GnuCash nel tuo sistema, digita:
# pkg_add -r gnucashSe il pacchetto non è disponibile, puoi usare la collezione dei port:
# cd /usr/ports/finance/gnucash
# make install cleanGnumeric è un programma per foglio di calcolo elettronico, fa parte dell’ambiente desktop GNOME. Dispone di molti automatismi utili, "auto completamento" in base al formato della cella con un sistema di formattazione automatica per molte operazioni. Può importare i files in un gran numero di formati popolari come quelli di Excel, Lotus 1-2-3, o Quattro Pro. Gnumeric supporta l’utilizzo di grafici attraverso il programma di grafica math/guppi. Ha un gran numero di funzioni e permette l’utilizzo di celle formattate come ad esempio nel formato data, valuta, numero, ora, e molti altri.
Per installare Gnumeric come un un pacchetto, digita:
# pkg_add -r gnumericSe il pacchetto non risulta disponibile puoi usare la collezione dei port con:
# cd /usr/ports/math/gnumeric
# make install cleanAbacus è un programma per foglio di calcolo leggero e facile da usare. Include molte funzioni utili in molti campi diversi come ad esempio in statistica, finanza, e matematica. Può importare ed esportare i file in formato Excel. Abacus può esportare anche in formato PostScript®.
Per installare Abacus come pacchetto digitare:
# pkg_add -r abacusSe il pacchetto non è disponibile puoi utilizzare la collezione dei port digitando:
# cd /usr/ports/deskutils/abacus
# make install cleanKMyMoney è un gestore delle finanze personali sviluppato per KDE. KMyMoney intende fornire ed incorporare tutte quelle funzionalità importanti che si possono trovare nelle applicazioni commerciali di gestione delle finanze personali. Inoltre tra le sue caratteristiche pone in risalto la facilità di utilizzo e la caratteristica contabilità di credito e debito. KMyMoney importa file dello standard Quicken Interchange Format (QIF), traccia investimenti, gestisce valute multiple, e fornisce molti report. Tramite un plugin separato è anche possibile importare formati OFX.
Per installare KMyMoney come un pacchetto:
# pkg_add -r kmymoney2Se il pacchetto non è disponibile, puoi usare la collezione dei port:
# cd /usr/ports/finance/kmymoney2
# make install cleanAnche se FreeBSD è molto popolare tra gli ISP per le sue performance e la sua stabilità, è completamente pronto ad essere usato come desktop per l’utilizzo quotidiano. Con diverse migliaia di applicazioni disponibili sotto forma di pacchetti o port, puoi avere un desktop perfetto che soddisfi tutte le tue necessità.
Qui di seguito un piccolo riassunto delle applicazioni trattate in questo capitolo:
| Nome dell’applicazione | Nome del pacchetto | Nome del port |
|---|---|---|
Mozilla |
| |
Opera |
| |
Firefox |
| |
KOffice |
| |
AbiWord |
| |
The GIMP |
| |
OpenOffice.org |
| |
Acrobat Reader® |
| |
gv |
| |
Xpdf |
| |
GQview |
| |
GnuCash |
| |
Gnumeric |
| |
Abacus |
|
FreeBSD supporta una grande varietà di schede audio, permettendoti di apprezzare un output di alta fedeltà dal tuo computer. Questo include l’abilità di registrare e riprodurre suoni nei formati MPEG Audio Layer 3 (MP3), WAV, ed Ogg Vorbis così come in molti altri formati. La FreeBSD Ports Collection contiene inoltre applicazioni che ti permettono di modificare l’audio registrato, aggiungere effetti sonori, e controllare i dispositivi MIDI collegati.
Con un po' di sperimentazione, FreeBSD può supportare la riproduzione di file video e DVD. Il numero di applicazioni per codificare, convertire, e riprodurre i vari formati video è più limitato del numero delle applicazioni audio. Per esempio nel momento in cui sto scrivendo, non esiste nella FreeBSD Ports Collection una buona applicazione per ricodificare che potrebbe essere usata per la conversione tra diversi formati, come c’è con audio/sox. Tuttavia, il panorama software in quest’area sta rapidamente cambiando.
Questo capitolo descriverà i passi necessari per configurare la tua scheda audio. La configurazione e l’installazione di X11 (L’X Window System) si sono già prese cura dei problemi hardware della tua scheda video, sebbene ci possano essere delle ottimizzazioni da applicare per una migliore riproduzione.
Dopo aver letto questo capitolo, saprai:
Come configurare il sistema in modo che la scheda audio venga riconosciuta.
Metodi per verificare che la tua scheda funzioni.
Come risolvere i problemi di configurazione audio.
Come riprodurre e codificare file MP3.
Come sono supportate le applicazioni video dal server X.
Alcuni port per riprodurre/codificare filmati che danno buoni risultati.
Come riprodurre i DVD e i file .mpg e .avi.
Come estrarre i contenuti da CD e DVD su file.
Come configurare una scheda TV.
Come configurare uno scanner di immagini.
Prima di leggere questo capitolo, dovresti:
Sapere come configurare e installare un nuovo kernel (Configurazione del Kernel di FreeBSD).
Provare a montare CD audio con il comando mount(8) produrrà un errore, come minimo, o un kernel panic, alla peggio. Questi formati hanno codifiche particolari che differiscono dal comune file system ISO. |
Prima di iniziare, dovresti conoscere il modello della scheda che possiedi, il chip che utilizza, e se è una scheda PCI o ISA. FreeBSD supporta diverse schede PCI e ISA. Verifica la lista dei dispositivi audio supportati nell' Hardware Notes per vedere se la tua scheda è supportata. Inoltre tale documento ti indicherà quale driver supporta la tua scheda.
Per usare il tuo dispositivo audio, dovrai caricare i driver corretti. Il caricamento del driver del dispositivo può essere fatto in due modi. Il metodo più semplice consiste semplicemente nel caricare un modulo nel kernel per la tua scheda audio con kldload(8) che può essere fatto sia da linea di comando:
# kldload snd_emu10k1sia aggiungendo la riga appropriata al file /boot/defaults/loader.conf come questa:
snd_emu10k1_load="YES"
Questi esempi sono per la scheda audio Creative SoundBlaster® Live!. Altri moduli sonori disponibili sono elencati in /boot/loader.conf. Se hai dei dubbi su quale driver usare, potresti provare a caricare il modulo snd_driver:
# kldload snd_driverQuesto è un metadriver che carica i driver dei dispositivi audio più comuni in un solo colpo. Ciò permette di trovare velocemente il driver corretto. È anche possibile caricare tutti i driver audio attraverso il file /boot/loader.conf.
Se desideri scoprire il driver selezionato per la tua scheda audio dopo aver caricato il metadriver snd_driver, puoi verificare il file /dev/sndstat con il comando cat /dev/sndstat.
Un altro metodo è quello di compilare staticamente il supporto per la tua scheda audio nel kernel. La sezione seguente fornisce le informazioni di cui hai bisogno per aggiungere il supporto al tuo hardware in questo metodo. Per informazioni aggiuntive su come ricompilare il kernel, guarda il Configurazione del Kernel di FreeBSD.
La prima cosa da fare è aggiungere al kernel il driver di framework audio sound(4); per fare ciò devi aggiungere la seguente riga al tuo file di configurazione del kernel:
device sound
Poi, devi aggiungere il supporto per la tua scheda audio. Di conseguenza, devi conoscere quale driver supporta la scheda. Controlla la lista dei dispositivi audio supportati nell’Hardware Notes, per determinare il driver corretto per la tua scheda sonora. Per esempio, la scheda SoundBlaster® Live! della Creative è supportata dal driver snd_emu10k1(4). Per aggiungere il supporto per questa scheda, usiamo la seguente riga:
device snd_emu10k1
Per conoscere la corretta sintassi da usare assicurati di leggere la pagina man del driver. La sintassi corretta per la configurazione del kernel di ogni driver audio supportato può essere trovata nel file /usr/src/sys/conf/NOTES.
Schede ISA non-PnP possono obbligarti a fornire al kernel informazioni su alcuni settaggi della scheda audio (IRQ, porta di I/O, etc), tipico di tutte le scheda ISA non-PnP. Questo può essere realizzato attraverso il file /boot/device.hints. All’avvio del sistema, il loader(8) leggerà questo file e passerà i settaggi al kernel. Per esempio, una vecchia scheda audio SoundBlaster® 16 ISA non-PnP della Creative userà il driver snd_sbc(4) in congiunzione con snd_sb16. Per questa scheda le seguenti linee devono essere aggiunte al file di configurazione del kernel:
device snd_sbc device snd_sb16
e queste nel /boot/device.hints:
hint.sbc.0.at="isa" hint.sbc.0.port="0x220" hint.sbc.0.irq="5" hint.sbc.0.drq="1" hint.sbc.0.flags="0x15"
In questo caso, la scheda usa la porta di I/O 0x220 e l’IRQ 5.
La sintassi usata nel file /boot/device.hints è spiegata nella pagina man di sound(4) e nella pagina man del driver in questione.
Il settaggi qui sopra sono quelli di default. In alcuni casi, potresti avere la necesità di modificare l’IRQ o altri parametri per far funzionare la tua scheda audio. Guarda la pagina man di snd_sbc(4) per maggiori dettagli su questo driver.
Dopo aver riavviato con il nuovo kernel, o dopo aver caricato il modulo richiesto, la scheda audio dovrebbe apparire nel tuo buffer dei messaggi (dmesg(8)) in modo simile a quanto segue:
pcm0: <Intel ICH3 (82801CA)> port 0xdc80-0xdcbf,0xd800-0xd8ff irq 5 at device 31.5 on pci0
pcm0: [GIANT-LOCKED]
pcm0: <Cirrus Logic CS4205 AC97 Codec>Lo stato della scheda audio può essere verificato leggendo il file /dev/sndstat:
# cat /dev/sndstat
FreeBSD Audio Driver (newpcm)
Installed devices:
pcm0: <Intel ICH3 (82801CA)> at io 0xd800, 0xdc80 irq 5 bufsz 16384
kld snd_ich (1p/2r/0v channels duplex default)L’output del tuo sistema potrebbe essere diverso. Se nessun dispositivo pcm viene visualizzato, rivedi ciò che è stato fatto di recente. Ricontrolla ancora una volta il tuo file di configurazione del kernel e assicurati di aver scelto il driver corretto. Alcuni problemi comuni sono elencati nella Problemi Comuni.
Se tutto va bene, ora dovresti avere una scheda audio funzionante. Se i pin di audio-out del tuo drive CD-ROM o DVD-ROM sono collegati correttamente alla scheda audio, puoi inserire un CD nel drive e riprodurlo con cdcontrol(1):
% cdcontrol -f /dev/acd0 play 1Varie applicazioni, come audio/workman possono offrire una migliore interfaccia. Potresti voler installare una applicazione come audio/mpg123 per ascoltare i file audio MP3.
Un altro modo veloce per controllare se la scheda trasmette dati al nodo /dev/dsp è questo:
% cat filename > /dev/dspdove filename può essere qualsiasi file. Questo comando dovrebbe produrre del rumore, confermando che la scheda sonora sta lavorando.
I livelli del mixer della scheda possono essere modificati attraverso il comando mixer(8). Maggiori dettagli possono essere trovati nella pagina man mixer(8).
| Errore | Soluzione |
|---|---|
| Non è stata impostata correttamente la porta di I/O. |
| È stato configurato erroneamente l’IRQ. Assicurati che l’IRQ impostato e quello della scheda siano gli stessi. |
| Non c’è abbastanza memoria disponibile per usare il dispositivo. |
| Controlla con |
È spesso desiderabile avere più sorgenti di audio che siano in grado di suonare contemporaneamente, per esempio quando esound o artsd non supportano la condivisione del dispositivo audio con una certa applicazione.
FreeBSD ti permette di fare questo attraverso i Virtual Sound Channels, che possono essere abilitati con sysctl(8). I canali virtuali permettono di multiplexare i canali di riproduzione della tua scheda audio mixando l’audio nel kernel.
Per impostare il numero dei canali virtuali, ci sono due variabili sysctl che, se sei l’utente root, possono essere impostate così:
# sysctl hw.snd.pcm0.vchans=4
# sysctl hw.snd.maxautovchans=4L’esempio qui sopra alloca quattro canali virtuali, che è un numero adatto all’uso di ogni giorno. hw.snd.pcm0.vchans è il numero dei canali virtuali che ha pcm0, ed è configurabile una volta che il dispositivo è collegato. hw.snd.maxautovchans è il numero dei canali virtuali che vengono dati a un nuovo dispositivo audio quando viene collegato tramite kldload(8). Visto che il modulo pcm può essere caricato indipendentemente dai driver dell’hardware, hw.snd.maxautovchans può contenere tanti canali virtuali quanti ne verranno allocati successivamente ad ogni dispositivo collegato.
Non puoi cambiare il numero di canali virtuali per un dispositivo mentre questo è in uso. Chiudi tutti i programmi che stanno usando quel dispositivo, come player di musica o demoni del suono. |
I valori di default per i diversi canali del mixer sono rigidamente codificati nel codice sorgente del driver pcm(4). Ci sono svariate applicazioni e demoni che ti permettono di settare i valori del mixer memorizzandoli per le successive invocazioni, ma questa non è una soluzione pulita. È possibile settare valori di default del mixer a livello del driver - questo è realizzabile definendo i valori desiderati nel file /boot/device.hints, per esempio:
hint.pcm.0.vol="50"
Questo imposterà il canale volume a un valore di default di 50 non appena il modulo pcm(4) sarà caricato.
Il formato MP3 (Audio MPEG Livello 3) raggiunge una qualità audio vicina a quella dei CD, non lasciandoti motivi per non utilizzarlo sulla tua workstation FreeBSD.
Da tempo, il più famoso lettore MP3 per X11 è XMMS (X Multimedia System). Le skin per Winamp possono essere usate con XMMS visto che la GUI è praticamente identica a quella di Winamp della Nullsoft. XMMS ha inoltre supporto nativo ai plug-in.
XMMS può essere installato dal port o dal package multimedia/xmms.
L’interfaccia di XMMS è intuitiva, comprende una lista di brani da eseguire, un equalizzatore grafico, ed altro. Coloro che sono familiari con Winamp troveranno XMMS semplice da usare.
Il port audio/mpg123 è un lettore MP3 alternativo, da riga di comando.
mpg123 può essere eseguito specificando il dispositivo audio e il nome del file MP3 sulla riga di comando, come mostrato qui sotto:
# mpg123 -a /dev/dsp1.0 Foobar-GreatestHits.mp3
High Performance MPEG 1.0/2.0/2.5 Audio Player for Layer 1, 2 and 3.
Version 0.59r (1999/Jun/15). Written and copyrights by Michael Hipp.
Uses code from various people. See 'README' for more!
THIS SOFTWARE COMES WITH ABSOLUTELY NO WARRANTY! USE AT YOUR OWN RISK!
Playing MPEG stream from Foobar-GreatestHits.mp3 ...
MPEG 1.0 layer III, 128 kbit/s, 44100 Hz joint-stereo/dev/dsp1.0 deve essere sostituito con il dispositivo dsp presente sul tuo sistema.
Prima di codificare un CD o una traccia di CD in MP3, i dati audio sul CD devono essere estratti sul disco fisso. Questo avviene copiando direttamente i dati CDDA (CD Digital Audio) in file WAV.
Il tool cdda2wav, che fa parte della suite sysutils/cdrtools, viene usato per estrarre le informazioni audio dai CD e i dati associati.
Mentre il CD audio è nel lettore, può essere eseguito il seguente comando (come root) per estrarre un intero CD in singoli (per traccia) file WAV:
# cdda2wav -D 0,1,0 -Bcdda2wav supporta anche i lettori CDROM ATAPI (IDE). Per estrarre da un lettore IDE, specifica il nome del dispositivo al posto nel numero dell’unità SCSI. Ad esempio, per estrarre la traccia 7 dal lettore IDE:
# cdda2wav -D /dev/acd0 -t 7Il -D 0,1,0 indica il dispositivo SCSI 0,1,0, che corrisponde all’output di cdrecord -scanbus.
Per estrarre tracce singole, usa l’opzione -t come mostrato:
# cdda2wav -D 0,1,0 -t 7Questo esempio estrae la settima traccia del CD audio. Per estrarre una serie di tracce, per esempio dalla traccia uno alla sette, specifica un intervallo:
# cdda2wav -D 0,1,0 -t 1+7L’utility dd(1) può anche essere usata per estrarre le tracce audio dai drive ATAPI, leggi Duplicating Audio CDs per maggiori informazioni su questa possibilità.
Al giorno d’oggi, il programma di codifica in mp3 da scegliere è lame. Lame può essere trovato in audio/lame nell’albero dei port.
Usando i file WAV estratti, il seguente comando convertirà audio01.wav in audio01.mp3:
# lame -h -b 128 \
--tt "Titolo" \
--ta "Artista" \
--tl "Album" \
--ty "2002" \
--tc "Estratto e codificato da Blah" \
--tg "Genere" \
audio01.wav audio01.mp3128 kbits sembra essere il bitrate standard in uso per gli MP3. Molti preferiscono la qualità maggiore dei 160, o 192. Più alto è il bitrate, più spazio consumerà l’MP3 risultante—ma la qualità sarà maggiore. L’opzione -h attiva il modo "qualità migliore ma un po' più lento"". Le opzioni che iniziano con --t indicano i tag ID3, che solitamente contengono le informazioni sulla canzone, da inserire all’interno del file MP3. Ulteriori opzioni di codifica possono essere trovate consultando la pagina man di lame.
Per masterizzare un CD audio partendo dagli MP3, questi ultimi devono essere convertiti in un formato WAV non compresso. Sia XMMS che mpg123 supportano l’output di un MP3 in un formato non compresso.
Scrittura su Disco con XMMS:
Avvia XMMS.
Clicca con il tasto destro sulla finestra per far comparire il menu di XMMS.
Seleziona Preference sotto Options.
Cambia l’Output Plugin in "Disk Writer Plugin".
Premi Configure.
Inserisci (o scegli browse) la directory in cui salvare i file decompressi.
Carica il file MP3 in XMMS come al solito, con il volume al 100% e le impostazioni dell’equalizzatore disattivate.
Premi Play - XMMS apparirà come se stesse riproducendo l’MP3, ma non si sentirà nessuna musica. Sta riproducendo la musica su un file.
Assicurati di reimpostare l’Output Plugin di default come prima per ascoltare nuovamente gli MP3.
Scrittura su stdout con mpg123:
Esegui mpg123 -s audio01.mp3 > audio01.pcm
XMMS scrive un file nel formato WAV, mentre mpg123 converte l’MP3 direttamente in dati audio PCM. Entrambi questi formati possono essere usati con cdrecord per creare CD audio. Devi utilizzare PCM con burncd(8). Se usi file WAV, noterai un breve ticchettio all’inizio di ogni traccia, questo suono è l’intestazione del file WAV. Puoi semplicemente rimuovere l’intestazione del file WAV con l’utility SoX (può essere installata dal port o dal package audio/sox):
% sox -t wav -r 44100 -s -w -c 2 track.wav track.rawLeggi Creating and Using Optical Media (CDs & DVDs) per ulteriori informazioni su come usare un masterizzatore con FreeBSD.
La riproduzione video è un’area applicativa molto recente e in rapido sviluppo. Sii paziente. Non tutto funzionerà così facilmente come è stato per l’audio.
Prima di iniziare, dovresti conoscere il modello della scheda video che possiedi e il chip che usa. Sebbene Xorg e XFree86™ supportino una vasta varietà di schede video, poche offrono buone prestazioni in riproduzione. Per ottenere una lista di estensioni supportate dall’X server con la tua scheda usa il comando xdpyinfo(1) mentre X11 sta girando.
È una buona idea avere un piccolo file MPEG che possa essere trattato come un file di test per la valutazione di vari riproduttori e opzioni. Visto che alcuni riproduttori di DVD cercheranno di default i DVD in /dev/dvd, o hanno questo nome di dispositivo codificato permanentemente al loro interno, potresti trovare utile creare dei link simbolici al dispositivo corretto:
# ln -sf /dev/acd0 /dev/dvd
# ln -sf /dev/acd0 /dev/rdvdNota che, data la natura del devfs(5), i collegamenti creati a mano come questi non rimarranno se riavvii il sistema. Per creare i collegamenti simbolici automaticamente quando avvii il sistema, aggiungi le seguenti righe in /etc/devfs.conf:
# ln -sf /dev/acd0c /dev/dvd
# ln -sf /dev/acd0c /dev/rdvdIn aggiunta, la decrittazione dei DVD, che richiede l’invocazione di speciali funzioni dei DVD-ROM, richiede il permesso in scrittura sui dispositivi DVD.
Per migliorare l’interfaccia della memoria condivisa di X11, è consigliabile incrementare i valori di alcune variabili sysctl(8):
kern.ipc.shmmax=67108864 kern.ipc.shmall=32768
Ci sono molti modi possibili per visualizzare immagini e filmati con X11. Quello che funzionerà meglio in pratica dipende in gran parte dal tuo hardware. Ogni metodo descritto qui sotto avrà una qualità variabile su hardware differente. In secondo luogo, il rendering video in X11 è un argomento che sta ricevendo un sacco di attenzione ultimamente, e con ogni nuova versione di Xorg, o di XFree86™ ci possono essere notevoli miglioramenti.
Una lista di interfacce video comuni:
X11: normale output di X11 che usa la memoria condivisa.
XVideo: un’estensione all’interfaccia X11 che supporta grafica e filmati in ogni oggetto X11 disegnabile.
SDL: Simple Directmedia Layer.
DGA: Direct Graphics Access.
SVGAlib: interfaccia di basso livello per la grafica da console.
Xorg e XFree86™ 4.X hanno un’estensione chiamata XVideo (aka Xvideo, aka Xv, aka xv) che permette di visualizzare grafica e filmati direttamente negli oggetti disegnabili attraverso una speciale accelerazione. Questa estensione fornisce una riproduzione di ottima qualità anche su macchine poco potenti.
Per controllare se l’estensione sta girando, usa xvinfo:
% xvinfoXVideo è supportato dalla tua scheda se il risultato è simile a:
X-Video Extension version 2.2
screen #0
Adaptor #0: "Savage Streams Engine"
number of ports: 1
port base: 43
operations supported: PutImage
supported visuals:
depth 16, visualID 0x22
depth 16, visualID 0x23
number of attributes: 5
"XV_COLORKEY" (range 0 to 16777215)
client settable attribute
client gettable attribute (current value is 2110)
"XV_BRIGHTNESS" (range -128 to 127)
client settable attribute
client gettable attribute (current value is 0)
"XV_CONTRAST" (range 0 to 255)
client settable attribute
client gettable attribute (current value is 128)
"XV_SATURATION" (range 0 to 255)
client settable attribute
client gettable attribute (current value is 128)
"XV_HUE" (range -180 to 180)
client settable attribute
client gettable attribute (current value is 0)
maximum XvImage size: 1024 x 1024
Number of image formats: 7
id: 0x32595559 (YUY2)
guid: 59555932-0000-0010-8000-00aa00389b71
bits per pixel: 16
number of planes: 1
type: YUV (packed)
id: 0x32315659 (YV12)
guid: 59563132-0000-0010-8000-00aa00389b71
bits per pixel: 12
number of planes: 3
type: YUV (planar)
id: 0x30323449 (I420)
guid: 49343230-0000-0010-8000-00aa00389b71
bits per pixel: 12
number of planes: 3
type: YUV (planar)
id: 0x36315652 (RV16)
guid: 52563135-0000-0000-0000-000000000000
bits per pixel: 16
number of planes: 1
type: RGB (packed)
depth: 0
red, green, blue masks: 0x1f, 0x3e0, 0x7c00
id: 0x35315652 (RV15)
guid: 52563136-0000-0000-0000-000000000000
bits per pixel: 16
number of planes: 1
type: RGB (packed)
depth: 0
red, green, blue masks: 0x1f, 0x7e0, 0xf800
id: 0x31313259 (Y211)
guid: 59323131-0000-0010-8000-00aa00389b71
bits per pixel: 6
number of planes: 3
type: YUV (packed)
id: 0x0
guid: 00000000-0000-0000-0000-000000000000
bits per pixel: 0
number of planes: 0
type: RGB (packed)
depth: 1
red, green, blue masks: 0x0, 0x0, 0x0Inoltre tieni presente che i formati elencati (YUV2, YUV12, ecc) non sono presenti in tutte le implementazioni di XVideo e la loro assenza può ostacolare alcuni programmi.
Se il risultato è:
X-Video Extension version 2.2
screen #0
no adaptors presentAllora XVideo probabilmente non è supportato per la tua scheda.
Se XVideo non è supportato per la tua scheda, questo vuol dire solamente che sarà più difficile soddisfare le richieste computazionali per il rendering video. A seconda della tua scheda video e del tuo processore, comunque, potresti essere ancora in grado di avere un’esperienza soddisfacente. Dovrai probabilmente dare un occhio ai modi per migliorare le prestazioni nella lettura avanzata Ulteriori Letture.
Il Simple Directmedia Layer, SDL, vuole essere un’interfaccia di portabilità tra Microsoft® Windows, BeOS, e UNIX®, che possa permettere di sviluppare applicazioni multi-piattaforma che facciano buon uso di suoni e grafica. L’interfaccia SDL fornisce una astrazione di basso livello all’hardware che può a volte essere più efficiente dell’interfaccia X11.
L’SDL può essere trovata in devel/sdl12.
Direct Graphics Access è un’estensione di X11 che permette a un programma di evitare il server X ed alterare direttamente il buffer video. Siccome si basa su una mappatura di memoria a basso livello per effettuare questa condivisione, i programmi che la usano devono essere avviati da root.
L’estensione DGA può essere testata con dga(1). Quando dga è in esecuzione, cambia i colori del display ogni volta che viene premuto un tasto. Per uscire, premi q.
In questa sezione si discuterà del software disponibile nella FreeBSD Port Collection che possono essere usati per la riproduzione video. La sezione software sulla riproduzione video è in continuo sviluppo, per cui le caratteristiche delle varie applicazioni sono destinate a differire dalla descrizione che segue.
In primo luogo, è importante sapere che molte delle applicazioni video che girano su FreeBSD sono stati sviluppate come applicazioni Linux. Molte di queste applicazioni sono ancora in fase beta. Alcuni dei problemi che puoi incontrare con i package video su FreeBSD comprendono:
Un’applicazione non riesce a riprodurre un file generato da un’altra applicazione.
Un’applicazione non riesce a riprodurre un file che lei stessa ha prodotto.
Lo stesso applicativo posto su due computer diversi, ricompilato su ognuno dei due computer, riproduce lo stesso file in modo diverso.
Da un filtro apparentemente banale quale il ridimensionamento di un’immagine si ottenga un pessimo risultato derivato da una routine di ridimensionamento bacata.
Un’applicazione che genera frequentemente file "core".
La documentazione non viene installata con il port e può essere trovata sul web o nella directory work del port.
Molte di queste applicazioni possono anche esibire "Linuxismi". Ovvero, ci possono essere problemi risultanti dal modo in cui le librerie standard sono state implementate nelle distribuzioni Linux, o alcune modifiche al kernel di Linux che sono state apportate dagli autori delle applicazioni. Questi problemi possono non essere stati notati e aggirati dal mantainer del port, e possono portare comunque a problemi come questi:
L’uso di /proc/cpuinfo per riconoscere le caratteristiche del processore.
Un uso errato dei thread che può portare un programma a bloccare la propria esecuzione piuttosto che terminare correttamente.
Software non ancora presente nella collezione dei port di FreeBSD che è comunemente usato unitamente all’applicazione.
A questo punto, gli sviluppatori di queste applicazioni sono stati collaborativi con i maintainer dei port al fine di minimizzare la ricerca di soluzioni necessarie al processo di porting.
MPlayer è stata sviluppata di recente ed è un player in rapida evoluzione. Gli obbiettivi degli sviluppatori di MPlayer sono la velocità e la flessibilità su Linux e le altre famiglie di UNIX®. Il progetto è partito non appena il fondatore del gruppo si stancò delle prestazioni degli altri riproduttori. C’è chi dice che l’interfaccia grafica sia stata sacrificata per un design essenziale. Tuttavia, una volta che si sono imparate perfettamente le opzioni da riga di comando e le scorciatoie, funziona decisamente bene.
MPlayer è reperibile sotto multimedia/mplayer. MPlayer effettua una serie di controlli sull’hardware durante il processo di compilazione, che ha come risultato un binario che non potrà essere considerato portabile da una piattaforma ad un’altra. Questo è il motivo per cui risulta importante compilarlo usando il port piuttosto che il pacchetto contenente il binario. Inoltre, ulteriori opzioni possono essere specificate nella riga di comando di make, come descritto nel Makefile e all’inizio della compilazione.
# cd /usr/ports/multimedia/mplayer
# make
N - O - T - E
Take a careful look into the Makefile in order
to learn how to tune mplayer towards you personal preferences!
for example,
make WITH_GTK1
builds MPlayer with GTK1-GUI support.
if you want to use the GUI, you can either install
/usr/ports/multimedia/mplayer-skins
or download official skin collections from
http://www.mplayerhq.hu/homepage/dload.htmlLe opzioni di default del port dovrebbero essere sufficienti per la maggior parte degli utenti. Tuttavia, se hai bisogno del codec XviD, devi specificare l’opzione WITH_XVID nella riga di comando. Inoltre puoi definire il dispositivo DVD di default con l’opzione WITH_DVD_DEVICE, altrimenti sarà utilizzato di default /dev/acd0.
Al momento, il port MPlayer creerà la sua documentazione in HTML e due eseguibili mplayer, e mencoder, che è uno strumento per la ri-codifica video.
La documentazione HTML di MPlayer è molto istruttiva. Qualora il lettore trovasse le informazioni sull’hardware e le interfacce video in questo capitolo scarne, la documentazione di MPlayer risulta essere un ottimo supplemento. Se si stanno cercando informazioni riguardo il supporto video sotto UNIX®, sarebbe utile trovare il tempo di leggere in modo preciso la documentazione di MPlayer.
Ogni utente che voglia usare MPlayer deve creare la directory .mplayer sotto la propria home. Per creare questa directory necessaria, puoi digitare il seguente comando:
% cd /usr/ports/multimedia/mplayer
% make install-userLe opzioni del comando mplayer sono elencate nella pagina del manuale. Per qualunque altro dettaglio consulta la documentazione HTML. In questa sezione, descriveremo solamente alcuni degli usi più comuni.
Per riprodurre un file, ad esempio testfile.avi, usando una delle varie interfacce video usa l’opzione -vo:
% mplayer -vo xv testfile.avi% mplayer -vo sdl testfile.avi% mplayer -vo x11 testfile.avi# mplayer -vo dga testfile.avi# mplayer -vo 'sdl:dga' testfile.aviÈ utile provare tutte queste opzioni, considerando che le prestazioni dipendono da svariati fattori e variano in modo considerevole a seconda dell’hardware.
Per riprodurre un DVD, sostituisci testfile.avi con l’opzione dvd://N -dvd-device DISPOSITIVO dove N corrisponde al numero del titolo da riprodurre e DISPOSITIVO al dispositivo che identifica il DVD-ROM. Per esempio, per riprodurre il terzo titolo da /dev/dvd:
# mplayer -vo xv dvd://3 -dvd-device /dev/dvdIl dispositivo DVD di default può essere definito durante la compilazione del port MPlayer tramite l’opzione |
Per interrompere, mettere in pausa, andare avanti e così via, leggi l’elenco delle associazioni dei tasti, che vengono elencati eseguendo mplayer -h o consulta la pagina man.
Ulteriori opzioni utili per la riproduzione sono: -fs -zoom che abilita la modalità schermo intero e -framedrop che aiuta le prestazioni.
Perchè la riga di comando di mplayer non diventi eccessivamente lunga, l’utente può creare il file .mplayer/config ed impostare lì i valori predefiniti:
vo=xv fs=yes zoom=yes
In ultimo, è possibile usare mplayer per estrarre una traccia DVD in un file .vob. Per estrarre la seconda traccia dal DVD, digita questo:
# mplayer -dumpstream -dumpfile out.vob dvd://2 -dvd-device /dev/dvdIl file ottenuto, out.vob, sarà in formato MPEG e potrà manipolato da un’altro programma descritto in questa sezione.
Prima di usare mencoder è una buona idea familiarizzare con le opzioni contenute nella documentazione HTML. Esiste anche una pagina man, ma non è utile senza la documentazione HTML. Esiste un numero considerevole di modi per migliorare la qualità, un bitrate più basso, cambiare codifica ed alcuni di questi trucchi può fare la differenza tra prestazioni più o meno accettabili. Di seguito un paio di esempi per cominciare. Prima di tutto, una semplice copia:
% mencoder input.avi -oac copy -ovc copy -o output.aviCombinazioni errate di opzioni da riga di comando possono portare a file di output irriproducibili perfino con mplayer. Di conseguenza, se si vuole semplicemente estrarre una traccia, usare l’opzione -dumpfile eseguendo in mplayer.
Per convertire il file input.avi in formato MPEG4 con l’audio codificato in MPEG3 (è necessario audio/lame):
% mencoder input.avi -oac mp3lame -lameopts br=192 \
-ovc lavc -lavcopts vcodec=mpeg4:vhq -o output.aviQuesto comando ha creato un file riproducibile con mplayer e xine.
Il parametro input.avi può essere sostituito con dvd://1 -dvd-device /dev/dvd ed eseguire il comando come root per ricodificare il capitolo DVD direttamente. Poichè si sarà certamente poco soddisfatti del risultato la prima volta, è consigliato eseguire il dump del capitolo e lavorare direttamente sul file.
Il riproduttore video xine è un progetto dagli ampi obiettivi e non solo l’essere una soluzione unica per la riproduzione, ma anche una libreria di base riutilizzabile ed un eseguibile modulare che possa essere esteso con i plugin. È disponibile sia come pacchetto che come port, sotto multimedia/xine.
xine è ancora un pò rozzo, ma è chiaramente un buon inizio. In pratica, xine necessita sia di una CPU veloce che di una scheda video veloce o il supporto per l’estensione XVideo. L’interfaccia grafica è utilizzabile, ma ancora mal disegnata.
Allo stato attuale, non ci sono moduli distribuiti con xine che possano riprodurre DVD codificati in CSS. Esistono distribuzioni di terze parti che hanno moduli di questo genere già compilati, ma nessuno di questi esiste nella FreeBSD Ports Collection.
Comparato con MPlayer, xine offre maggiori caratteristiche all’utente ma, allo stesso tempo, non rende disponibile all’utente un controllo più accurato. Il riproduttore video xine funziona molto meglio sulle interfacce XVideo.
Di default, xine si avvierà con un’interfaccia grafica. Si possono quindi usare i menu per aprire per aprire un file specifico:
% xineAlternativamente, può essere invocato per aprire direttamente un file senza l’interfaccia grafica, con il comando:
% xine -g -p mymovie.aviIl software transcode non è un riproduttore, piuttosto un insieme di strumenti per ricodificare file audio e video. Con transcode, si ha la possibilità di unire file video, riparare file corrotti ed utilizzare strumenti da riga di comando con interfaccie che utilizzano i flussi stdin/stdout.
Durante la compilazione del port multimedia/transcode possono essere specificate diverse opzioni, noi ti consigliamo il comando seguente per compilare transcode:
# make WITH_OPTIMIZED_CFLAGS=yes WITH_LIBA52=yes WITH_LAME=yes WITH_OGG=yes \
WITH_MJPEG=yes -DWITH_XVID=yesI settaggi proposti dovrebbero essere sufficienti per la maggior parte degli utenti.
Per illustrare le capacità di transcode, viene dato un esempio che mostra come convertire un file DivX in un file PAL MPEG-1 (PAL VCD):
% transcode -i input.avi -V --export_prof vcd-pal -o output_vcd
% mplex -f 1 -o output_vcd.mpg output_vcd.m1v output_vcd.mpaIl file MPEG risultante, output_vcd.mpg, è pronto per essere letto con MPlayer. Puoi perfino masterizzare il file su un CD-R per creare un Video CD, e in questo caso necessiti di installare ed usare i programmi multimedia/vcdimager e sysutils/cdrdao.
Esiste una pagina man per transcode, ma dovresti anche consultare il wiki di transcode per ulteriori informazioni ed esempi.
I vari package di applicazioni video per FreeBSD si stanno evolvendo rapidamente. È abbastanza possibile che in un futuro vicino molti dei problemi discussi qui saranno risolti. Nel frattempo, chiunque voglia ottenere il massimo dalle capacità A/V di FreeBSD, dovrà unire alla meglio la conoscenza che deriva dalle svariate FAQ e guide con l’uso di queste poche applicazioni. Questa sezione esiste per fornire al lettore indicazioni a queste informazioni aggiuntive.
La Documentazione di MPlayer è molto istruttiva sul piano tecnico. Questa documentazione, probabilmente, dovrà essere consultata da chiunque voglia ottenere un alto grado di conoscenza del video sotto UNIX®. La mailing list di MPlayer risulta abbastanza ostile a chiunque non si sia preoccupato di leggere la documentazione, se si ha intenzione di segnalar loro un bug, RTFM.
L’HOWTO di xine contiene un capitolo su come aumentare le prestazioni che è comune a tutti i riproduttori.
In ultimo, ci sono alcuni applicativi promettenti che il lettore può provare:
Avifile che è anche un port multimedia/avifile.
Ogle che è anche un port multimedia/ogle.
multimedia/dvdauthor, un package open source per la creazione di DVD.
Le schede TV permettono di visualizzare la TV via onde radio o via cavo sul tuo computer. La maggior parte di queste accettano in input video composito tramite connettori RCA o S-video e alcune di queste schede hanno un sintonizzatore radio FM.
FreeBSD fornisce supporto per le schede TV su bus PCI che usano un chip di acquisizione video Brooktree Bt848/849/878/879 o Conexant CN-878/Fusion 878a tramite il driver bktr(4). Devi anche assicurarti che la scheda abbia un sintonizzatore supportato, consulta la pagina man di bktr(4) per una lista dei sintonizzatori supportati.
Per usare la scheda, devi caricare il driver bktr(4), e questo può essere fatto aggiungendo la seguente riga al file /boot/loader.conf in questo modo:
bktr_load="YES"
Alternativamente, puoi compilare staticamente il supporto per la scheda TV nel tuo kernel, in questo caso aggiungi le seguenti righe alla configurazione del tuo kernel:
device bktr device iicbus device iicbb device smbus
Questi driver aggiuntivi sono necessari poiché le componenti della scheda sono interconnesse tramite un bus I2C. Quindi compila ed installa un nuovo kernel.
Una volta che hai aggiunto il supporto al tuo sistema, devi riavviare la macchina. Durante il processo di avvio, la tua scheda TV dovrebbe apparire, come in questo esempio:
bktr0: <BrookTree 848A> mem 0xd7000000-0xd7000fff irq 10 at device 10.0 on pci0 iicbb0: <I2C bit-banging driver> on bti2c0 iicbus0: <Philips I2C bus> on iicbb0 master-only iicbus1: <Philips I2C bus> on iicbb0 master-only smbus0: <System Management Bus> on bti2c0 bktr0: Pinnacle/Miro TV, Philips SECAM tuner.
Ovviamente questi messaggi possono differire a seconda dell’hardware. Tuttavia dovresti controllare se il sintonizzatore viene rilevato correttamente; è sempre possibile modificare alcuni dei parametri rilevati tramite le MIB di sysctl(8) e le opzioni nel file di configurazione del kernel. Ad esempio, se vuoi imporre che il sintonizzatore sia un Philips SECAM, dovresti aggiungere la riga seguente al file di configurazione del kernel:
options OVERRIDE_TUNER=6
o puoi usare direttamente sysctl(8):
# sysctl hw.bt848.tuner=6Guarda la pagina man di bktr(4) e il file /usr/src/sys/conf/NOTES per maggiori dettagli sulle opzioni disponibili.
Per usare la tua scheda TV devi installare una delle seguenti applicazioni:
multimedia/fxtv fornisce capacità di TV-in-una-finestra e acquisizione di immagini/audio/video.
multimedia/xawtv è anch’esso un’applicazione TV, con le stesse caratteristiche di fxtv.
misc/alevt decodifica e visualizza Videotext/Teletext.
audio/xmradio, un’applicazione per usare il sintonizzatore radio FM che hanno alcune schede TV.
audio/wmtune, un’applicazione desktop maneggevole per i sintonizzatori radio.
Altre applicazioni sono disponibili nella FreeBSD Ports Collection.
Se incontri qualche problema con la tua scheda TV, dovresti verificare dapprima se il chip di acquisizione video e il sintonizzatore sono realmente supportati dal driver bktr(4) e se hai usato le corrette opzioni di configurazione. Per maggiore supporto e varie domande sulla tua scheda video potresti voler leggere ed usare gli archivi della mailing list mailing list sulle applicazioni multimediali con FreeBSD.
In FreeBSD, l’accesso agli scanner è fornito dalle API di SANE (Scanner Access Now Easy) disponibili nella collezione dei port di FreeBSD. SANE usa anche alcuni driver dei dispositivi di FreeBSD per accedere all’hardware dello scanner.
FreeBSD supporta sia scanner SCSI che USB. Verifica che il tuo scanner sia supportato da SANE prima di effettuare ogni configurazione. SANE ha una lista di dispositivi supportati, che può fornire informazioni riguardo il supporto per uno scanner ed il suo stato. La pagina man uscanner(4) fornisce una lista di scanner USB supportati.
Come già menzionato, sono supportati sia scanner USB che SCSI. A seconda dell’interfaccia del tuo scanner, sono richiesti diversi driver dei dispositivi.
Il kernel GENERIC di default include i driver dei dispositivi necessari per il funzionamento degli scanner USB. In caso tu voglia usare un kernel custom, accertati che le linee seguenti siano presenti nel tuo file di configurazione del kernel:
device usb device uhci device ohci device uscanner
A seconda del tipo di chipset USB sulla tua scheda madre, hai bisogno solo di una fra le opzioni device uhci e device ohci, comunque avere entrambe le linee nel proprio file di configurazione del kernel non crea problemi.
Se non intendi ricompilare un kernel custom ed il tuo kernel non è il GENERIC, puoi direttamente caricare il modulo del driver del dispositivo di uscanner(4) con il comando kldload(8):
# kldload uscannerPer caricare il modulo ad ogni avvio di sistema, aggiungi la seguente linea al file /boot/loader.conf:
uscanner_load="YES"
Dopo aver riavviato con il kernel corretto, o dopo aver caricato il modulo necessario, attacca il tuo scanner USB. Nel buffer dei messaggi di sistema (dmesg(8)) dovrebbe apparire una riga che mostra il riconoscimento dello scanner:
uscanner0: EPSON EPSON Scanner, rev 1.10/3.02, addr 2Questo mostra che il nostro scanner usa il nodo del dispositivo /dev/uscanner0.
Se il tuo scanner possiede un’interfaccia SCSI, è importante sapere quale controller SCSI usi. A seconda del chipset SCSI usato, dovrai modificare il tuo file di configurazione del kernel. Il kernel GENERIC supporta i più comuni controller SCSI. Accertati di leggere il file di NOTES e aggiungi la linea corretta al tuo file di configurazione del kernel. Oltre al driver dell’interfaccia SCSI, devi avere le seguenti linee nel tuo file di configurazione del kernel:
device scbus device pass
Una volta che il kernel è stato correttamente compilato ed installato, dovresti vedere i dispositivi nel buffer dei messaggi di sistema, al momento del boot:
pass2 at aic0 bus 0 target 2 lun 0
pass2: <AGFA SNAPSCAN 600 1.10> Fixed Scanner SCSI-2 device
pass2: 3.300MB/s transfersSe il tuo scanner non era acceso al momento dell’avvio, è ancora possibile forzare manualmente il riconoscimento attraverso uno scan del bus SCSI con il comando camcontrol(8):
# camcontrol rescan all
Re-scan of bus 0 was successful
Re-scan of bus 1 was successful
Re-scan of bus 2 was successful
Re-scan of bus 3 was successfulA questo punto lo scanner apparirà nella lista dei device SCSI:
# camcontrol devlist
<IBM DDRS-34560 S97B> at scbus0 target 5 lun 0 (pass0,da0)
<IBM DDRS-34560 S97B> at scbus0 target 6 lun 0 (pass1,da1)
<AGFA SNAPSCAN 600 1.10> at scbus1 target 2 lun 0 (pass3)
<PHILIPS CDD3610 CD-R/RW 1.00> at scbus2 target 0 lun 0 (pass2,cd0)Ulteriori dettagli sui dispositivi SCSI sono disponibili nelle pagine man scsi(4) e camcontrol(8).
Il sistema SANE è diviso in due parti: il backend (graphics/sane-backends) ed il frontend (graphics/sane-frontends). La parte backend fornisce accesso allo scanner. La lista dei dispositivi supportati da SANE specifica quale backend supporta il tuo scanner di immagini. È necessario determinare il corretto backend per il tuo scanner se intendi usare il tuo dispositivo. La parte frontend fornisce l’interfaccia grafica allo scanning (xscanimage).
La prima cosa da fare è installare il port o il pacchetto graphics/sane-backends. Quindi, usa il comando sane-find-scanner per verificare il riconoscimento dello scanner da parte del sistema SANE:
# sane-find-scanner -q
found SCSI scanner "AGFA SNAPSCAN 600 1.10" at /dev/pass3L’output mostrerà il tipo di interfaccia dello scanner ed il nodo del dispositivo usato per connettere lo scanner al sistema. La marca ed il nome del modello potrebbero non comparire, non è importante.
Alcuni scanner USB richiedono il caricamento di un firmware, ciò è spiegato nella pagina man del backend. È utile anche leggere le pagine man di sane-find-scanner(1) e di linprocfs(7). |
Adesso dobbiamo verificare se lo scanner sarà identificato da un frontend di scanning. Di default, il backend di SANE fornisce un programma da linea di comando chiamato sane(1). Questo comando ti permette di elencare i dispositivi ed effettuare un’acquisizione di immagini da linea di comando. L’opzione -L è usata per ottenere una lista di scanner:
# scanimage -L
device `snapscan:/dev/pass3' is a AGFA SNAPSCAN 600 flatbed scannerNessun output o un messaggio che dice che nessuno scanner è stato identificato indica che sane(1) non è in grado di identificare lo scanner. Se ciò succede, dovrai editare il file di configurazione del backend ed indicare il driver del dispositivo usato dallo scanner. La directory /usr/local/etc/sane.d/ contiene tutti i file di configurazione del backend. Questo problema di identificazione avviene con alcuni scanner USB.
Ad esempio, usando Interfaccia USB, sane-find-scanner su uno scanner USB otteniamo la seguente informazione:
# sane-find-scanner -q
found USB scanner (UNKNOWN vendor and product) at device
/dev/uscanner0Lo scanner è stato riconosciuto correttamente, usa l’interfaccia USB ed è attaccato al nodo del dispositivo /dev/uscanner0. Ora possiamo testare se lo scanner è correttamente identificato:
# scanimage -L
Nessun scanner è stato identificato. Se ti aspettavi qualcosa di diverso,
verifica che lo scanner sia collegato, accendilo e avvia il tool di
riconoscimento degli scanner di sane (se adatto). Per cortesia leggi la
documentazione fornita con questo software (README, FAQ, pagine man).Dato che lo scanner non è stato identificato, dovremo editare il file /usr/local/etc/sane.d/epson.conf. Il modello di scanner usato è l’EPSON Perfection® 1650, così sappiamo che userà il backend epson. Accertati di leggere i commenti di aiuto nei file di configurazione del backend. Le modifiche alle linee sono abbastanza semplici: commenta tutte le linee che hanno un’interfaccia non adatta al tuo scanner (nel nostro caso, commenteremo tutte le linee che iniziano con la parola scsi dato che il nostro scanner usa l’interfaccia USB), quindi aggiungi alla fine del file una linea che specifica l’interfaccia ed il nodo di dispositivo usato. In questo caso, aggiungiamo la seguente linea:
usb /dev/uscanner0
Sei invitato a leggere i commenti presenti nel file di configurazione del backend così come le pagine man del backend per più dettagli e per la corretta sintassi da usare. Ora possiamo verificare se lo scanner è identificato:
# scanimage -L
device `epson:/dev/uscanner0' is a Epson GT-8200 flatbed scannerIl nostro scanner USB è stato riconosciuto. Non è importante se la marca ed il modello non coincidono con il proprio scanner. Il punto principale a cui prestare attenzione è il campo epson:/dev/uscanner0, che ci dà il corretto nome del backend ed il corretto nodo del dispositvo.
Una volta che il comando scanimage -L è in grado di vedere lo scanner, la configurazione è completa. Il dispositivo ora è in grado di scannerizzare.
Mentre sane(1) ci permette di effettuare l’acquisizione di un’immagine dalla linea di comando, è preferibile usare un’interfaccia grafica per effettuare scansioni di immagini. SANE offre una semplice ma efficace interfaccia grafica: xscanimage (graphics/sane-frontends).
Xsane (graphics/xsane) è un altro comune frontend grafico di scanning. Questo frontend offre caratteristiche avanzate come varie tecniche di scanning (fotocopia, fax, etc.), correzione del colore, scans multipli, etc. Entrambe queste applicazioni sono fruibili come plugin di GIMP.
Tutte le operazioni precedenti sono state compiute con privilegi di root. Tuttavia potresti aver bisogno che altri utenti abbiano accesso allo scanner. L’utente necessiterà permessi di lettura e scrittura sul nodo di dispositivo usato dallo scanner. Per esempio, il nostro scanner USB usa il nodo di dispositivo /dev/uscanner0 che appartiene al gruppo operator. Aggiungendo l’utente joe al gruppo operator gli permetterà di usare lo scanner:
# pw groupmod operator -m joePer maggiori informazioni consulta la pagina man di pw(8). Inoltre devi settare corretamente i permessi di scrittura (0660 o 0664) per il nodo del dispositivo /dev/uscanner0; di default il gruppo operator può solo leggere questo nodo di dispositivo. Tale operazione può essere realizzata aggiungendo la seguente riga al file /etc/devfs.rules:
[system=5] add path uscanner0 mode 660
Quindi aggiungi la seguente riga al file /etc/rc.conf e riavvia la macchina:
devfs_system_ruleset="system"
Ulteriori informazioni riguardo queste righe possono essere trovate nella pagina man di devfs(8).
Chiaramente, per ragioni di sicurezza, dovresti pensarci due volte prima di aggiungere un utente a qualsiasi gruppo, specialmente al gruppo |
Il kernel è una componente fondamentale del sistema operativo FreeBSD. È responsabile di gestire la memoria, applicare controlli di sicurezza, gestire la rete, accesso ai dischi e molto altro. Anche se sempre più parti di FreeBSD diventano configurabili dinamicamente, è ancora necessario talvolta riconfigurare e ricompilare il kernel.
Dopo aver letto questo capitolo, saprai:
Perchè potresti aver bisogno di ricompilare un kernel.
Come scrivere un file di configurazione del kernel, o come alterarne uno esistente.
Come usare il file di configurazione del kernel per creare un nuovo kernel.
Come installare il nuovo kernel.
Come fare del troubleshooting se qualcosa va storto.
Tutti i comandi elencati in questo capitolo negli esempi dovrebbero essere eseguiti come root affinchè abbiano successo.
Tradizionalmente, FreeBSD ha sempre avuto quello che si chiama un kernel "monolitico". Questo significa che il kernel era un programma di grandi dimensioni, supportava una lista fissa di device, e se tu avessi voluto cambiare il comportamento del kernel avresti dovuto compilarne uno nuovo, quindi fare il reboot del tuo computer per caricare il nuovo kernel.
Oggi come oggi, FreeBSD si sta muovendo rapidamente verso un modello dove gran parte delle funzionalità del kernel sono contenute in moduli che possono essere caricati e scaricati dal kernel a seconda delle necessità. Questo permette al kernel di adattarsi a nuovo hardware appena questo diventa disponibile (come ad esempio le carte PCMCIA in un laptop), oppure fa sì che nuove funzionalità siano portate nel kernel, funzionalità che non erano necessarie quando il kernel fu compilato inizialmente. Questo è noto come kernel modulare.
Nonostante questo, è ancora necessario portare avanti delle compilazioni statiche del kernel. In alcuni casi questo è necessario perchè la funzionalità è così legata al kernel che non può essere resa caricabile dinamicamente. In altri casi può essere necessario semplicemente perchè nessuno si è ancora preso il tempo di scrivere un modulo caricabile dinamicamente per quella funzionalità.
Compilare un kernel custom è uno dei più comuni riti di passaggio che quasi ogni utente BSD deve superare. Questo processo, anche se è dispendioso di tempo, offrirà molti benefici al tuo sistema FreeBSD. A differenza del kernel GENERIC, che deve supportare un gran numero di dispositivi hardware, un kernel custom contiene supporto solo per l’hardware del tuo PC. Questo presenta dei vantaggi, fra cui:
Tempo di boot più veloce. Dato che il kernel cercherà di riconoscere solo l’hardware che hai sul tuo sistema, il tempo che ci vuole al tuo sistema per fare boot diminuirà drammaticamente.
Minore uso della memoria. Un kernel custom spesso usa meno memoria del kernel GENERIC, il che è importante dato che il kernel deve sempre essere presente nella memoria reale. Per questo motivo un kernel custom è particolarmente utile su sistemi con poca RAM.
Supporto per hardware addizionale. Un kernel custom ti permette di aggiungere supporto per device che non sono presenti nel kernel GENERIC, come ad esempio sound card.
Per prima cosa, facciamo un breve giro nella directory di compilazione del kernel. Tutte le directory menzionate saranno relative alla directory principale /usr/src/sys, che è accessibile attraverso il path /sys. Ci sono un certo numero di sottodirectory qua che rappresentano parti differenti del kernel, ma la più importante per i nostri scopi è arch/conf, dove editerai il tuo file di configurazione del kernel, e compile, che è l’area di passaggio dove il tuo kernel sarè compilato. arch rappresenta uno fra i386, alpha, amd64, ia64, powerpc, sparc64, o pc98 (un tipo di sviluppo alternativo di hardware PC in Giappone). Tutto ciò che è all’interno di particolare directory di architettura ha a che fare solo con quell’architettura; il resto è codice indipendente dalla macchina, comune a tutte le piattaforme sulle quali FreeBSD potrebbe potenzialmente essere portato. Nota l’organizzazione logica della struttura dele directory, con ogni device supportato, file system e opzioni nelle proprie sottodirectory.
Questo capitolo assume che tu stia usando la architettura i386 negli esempi. Se questo non è il caso, fai gli appropriati aggiustamenti per correggere i percorsi alla tua architettura.
Se non c’è una directory /usr/src/sys sul tuo sistema, significa che i sorgenti del kernel non sono stati installati. Il modo più semplice per farlo è eseguire |
Quindi, entra nella directory arch/conf e copia il file di configurazione del kernel con il nome che vuoi dare al kernel. Ad esempio:
# cd /usr/src/sys/i386/conf
# cp GENERIC MYKERNELTradizionalmente, questo nome è tutto in lettere maiuscole e, se stai mantenendo molte macchine FreeBSD con hardware differente, è una buona idea dargli il nome della macchina. Noi lo chiamemeremo MYKERNEL a titolo di esempio.
Conservare il tuo file di configurazione del kernel direttamente sotto /usr/src può essere una cattiva idea. Se stai incontrando problemi puoi essere tentato di cancellare /usr/src e partire da zero. Dopo averlo fatto, di solito ci vogliono pochi secondi per realizzare che hai appena cancellato il tuo file di configurazione del kernel. Inoltre, non editare GENERIC direttamente, dato che potrebbe essere sovrascritto la prossima volta che aggiorni i tuoi sorgenti, e le tue modifiche andranno perse. Piuttosto tieni il tuo file di configurazione del kernel da qualche altra parte, e crea un link simbolico al file nella directory i386. Ad esempio: |
Ora edita MYKERNEL con il tuo editor favorito. Se stai partendo da zero, il solo editor disponibile sa` probabilmente vi, che è troppo complesso per essere spiegato in questa sede, ma è trattato estesamente in molti libri nella bibliografia. Comunque, FreeBSD offre un semplice editor chiamato ee che, se sei un principiante, dovrebbe essere il tuo editor favorito. Sentiti libero di cambiare le linee di commento in cima al file di configurazione per riflettere le tue configurazioni o i cambiamenti che hai fatto rispetto a GENERIC.
Se hai compilato un kernel sotto SunOS™ o qualche altro sistema BSD, gran parte di questo file ti sarà noto. Se stai arrivando da qualche altro sistema operativo tipo DOS, d’altro canto, il file di configurazione GENERIC ti potrebbe sembrare troppo complesso, così è meglio che segui le descrizioni della sezione File di Configurazione attentamente.
Se tu sincronizzi il tuo albero dei sorgenti con i più recenti sorgenti del progetto FreeBSD, accertati sempre di controllare il file /usr/src/UPDATING prima di eseguire una qualsiasi operazione di aggiornamento. /usr/src/UPDATING viene aggiornato con ogni versione dei sorgenti di FreeBSD, e quindi è più aggiornato di questo manuale. |
A questo punto devi compilare i sorgenti del kernel.
Procedure: Compilare il Kernel
Entra nella directory /usr/src:
# cd /usr/srcCompila il kernel:
# make buildkernel KERNCONF=MYKERNELInstalla il nuovo kernel:
# make installkernel KERNCONF=MYKERNELSi richede la presenza dell’intera struttura dei sorgenti di FreeBSD per compilare il kernel. |
Di default, quando compili un kernel custom, anche tutti i moduli del kernel sono ricompilati. Se vuoi aggiornare il kernel in modo spiccio o se vuoi compilare solo alcuni moduli, dovresti editare /etc/make.conf prima di iniziare la compilazione del kernel: MODULES_OVERRIDE = linux acpi sound/sound sound/driver/ds1 ntfs Questa variabile contiene una lista dei moduli che saranno ricompilati. WITHOUT_MODULES = linux acpi sound/sound sound/driver/ds1 ntfs Questa variabile contiene una lista dei moduli che saranno esclusi dal processo di compilazione. Per altre variabili che potresti trovare utili per il processo di compilazione del kernel, consulta la pagina man make.conf(5). |
Il nuovo kernel sarà copiato nella directory /boot/kernel come /boot/kernel/kernel e il kernel precedente sarà copiato in /boot/kernel.old/kernel. Ora, riavvia il sistema e riparti per usare il tuo nuovo kernel. Se qualcosa va storto, ci sono alcune istruzioni di troubleshooting alla fine del capitolo che puoi trovare utili. Accertati di leggere la sezione in cui si spiega cosa fare in caso il tuo nuovo kernel non faccia il boot.
Altri file relativi al processo di boot, come il boot loader(8) e la configurazione sono conservati in /boot/. Moduli di terze parti o custom possono essere piazzati in /boot/kernel/, anche se gli utenti dovrebbero avere conoscenza del fatto che tenere i moduli sincronizzati col kernel compilato è molto importante. I moduli non creati per interagire col kernel compilato possono risultare in instabilità o comportamenti anomali. |
Il formato generale di un file di configurazione è abbastanza semplice. Ogni linea contiene una parola chiave ed uno o più argomenti. Per semplicità, la maggior parte delle linee contiene solo un argomento. Tutto quello che segue un # è considerato un commento ed ignorato. Le seguenti sezioni descrivono ogni parola chiave, nell’ordine di presenza in GENERIC. Per una lista esaustiva delle opzioni dipendenti dall’architettura e dei devices, leggi il file NOTES nella stessa directory del file GENERIC. Per opzioni indipendenti dall’architettura, leggi /usr/src/sys/conf/NOTES.
Per creare un file che contenga tutte le opzioni disponibili, ad esempio per usi di testing, esegui il seguente comando come |
Il seguente è un esempio del file di configurazione del kernel GENERIC con vari commenti addizionali ove necessari ai fini della chiarezza. Questo esempio dovrebbe corrispondere abbastanza da vicino alla tua copia in /usr/src/sys/i386/conf/GENERIC.
machine i386
Questa è la architettura della macchina. Deve essere una fra alpha, amd64, i386, ia64, pc98, powerpc, o sparc64.
cpu I486_CPU cpu I586_CPU cpu I686_CPU
Quanto riportato sopra specifica il tipo di CPU che hai nella tua macchina. Puoi avere molte istanze di linee di CPU (se, per esempio, non sei sicuro se devi usare la I586_CPU o la I686_CPU), ma per un kernel custom è meglio specificare solo la CPU che hai. Se non sei sicuro di quale sia il tipo della tua CPU, controlla il file /var/run/dmesg.boot per leggere i messaggi di boot.
ident GENERIC
Questo è l’identificativo del kernel. Dovresti cambiarlo nel nome che hai dato al kernel, ad esempio MYKERNEL se hai seguito le istruzioni degli esempi precedenti. Il valore che poni nella stringa ident, sarà emesso a video quando fai il boot del kernel, così è utile dare al nuovo kernel un nome differente se vuoi tenerlo separato dal tuo kernel usuale (ad esempio se vuoi creare un kernel sperimentale).
#To statically compile in device wiring instead of /boot/device.hints #hints "GENERIC.hints" # Default places to look for devices.
L’opzione device.hints(5) è usato per configurare le opzioni dei device driver. La posizione di default che loader(8) cercherà al momento del boot è /boot/device.hints. Usando l’opzione hints puoi compilare queste direttive direttamente nel kernel. Se fai così non c’è bisogno di creare un file device.hints in /boot.
makeoptions DEBUG=-g # Build kernel with gdb(1) debug symbols
Il processo normale di compilazione di FreeBSD include informazioni di debugging quando si compila il kernel con l’opzione -g, che abilita il debugging quando passato a gcc(1).
options SCHED_4BSD # 4BSD scheduler
Lo schedulatore tradizionale per FreeBSD. Tienilo.
options PREEMPTION # Enable kernel thread preemption
Permette ai thread del kernel di essere interrotti da altri thread a priorità più alta. Aiuta con l’interattività e permette ai thread degli interrupt di essere eseguiti prima rispetto invece che attendere.
options INET # InterNETworking
Supporto per la rete. Lascia questa opzione, anche se non intendi connettere il computer ad una rete. La maggior parte dei programmi richiedono almeno rete di loopback (ad esempio fare connessioni di rete dal tuo pc al tuo pc stesso), così questa opzione in sostanza è obbligatoria.
options INET6 # IPv6 communications protocols
Questo abilita il protocollo di comunicazione IPv6.
options FFS # Berkeley Fast Filesystem
Questo è il file system di dischi di base. Lascialo nel kernel se fai il boot da hard disk.
options SOFTUPDATES # Enable FFS Soft Updates support
Questa opzione abilita le Soft Updates nel kernel, aiuterà a velocizzare accesso di scrittura ai dischi. Anche quando questa funzionalità è fornita dal kernel, deve essere attivata per dischi specifici. Rileggi l’output da mount(8) per vedere se Soft Updates sono abilitate per i tuoi dischi di sistema. Se non vedi l’opzione soft-updates potrai abilitarla usando tunefs(8) (per file system già esistenti) o newfs(8) (per nuovi file system).
options UFS_ACL # Support for access control lists
Questa opzione abilita supporto nel kernel per le liste di controllo di accesso. Questo poggia sull’uso degli attributi estesi e UFS2, questa opzione viene descritta in dettaglio in Sicurezza. ACL sono abilitate di default e non dovrebbero essere disabilitate nel kernel se sono state usate precedentemente su un file system, dato che questo rimuoverà le liste di controllo di accesso, cambiando il modo in cui i file sono protetti in modo non predicibile.
options UFS_DIRHASH # Improve performance on big directories
Quest’opzione include funzionalità per accelerare operazioni sui dischi su larghe directory, a costo di uso di memoria. Lo dovresti tenere per un server molto trafficato o workstation interattive, e rimuoverlo se stai usando FreeBSD su piccoli sistemi dove la memoria è scarsa e l’accesso ai dischi è meno importante, come un firewall.
options MD_ROOT # MD is a potential root device
Questa opzione abilita il supporto per un disco virtuale basato sulla memoria da usare come device di root.
options NFSCLIENT # Network Filesystem Client options NFSSERVER # Network Filesystem Server options NFS_ROOT # NFS usable as /, requires NFSCLIENT
Il file system di rete. A meno che tu non intenda montare partizioni da un file server UNIX® sopra TCP/IP, puoi commentare queste righe.
options MSDOSFS # MSDOS Filesystem
Il filesystem MS-DOS®. A meno che non intendi montare un disco formattato DOS al momento del boot, puoi tranquilamente commentare queste opzioni. Sarà automaticamente caricato la prima volta che monti una partizione DOS, come descritto in seguito. Inoltre, l’eccellente software emulators/mtools ti permette di accedere a floppy DOS senza dover montarli e smontarli (e non richiede assolutamente MSDOSFS).
options CD9660 # ISO 9660 Filesystem
Il file system ISO 9660 per CDROM. Commentalo se non hai un drive CDROM o monti CD di dati solo occasionalmente (dato che sarà caricato dinamicamente la prima volta che monti un CD di dati). CD audio non necessitano di questo file system.
options PROCFS # Process filesystem (requires PSUEDOFS)
Il file system dei processi. Questo è un "fittizio" file system montato su /proc che permette a programmi come ps(1) di darti maggiori informazioni su quali processi sono in esecuzione. L’uso di PROCFS non è richiesto nella maggior parte dei casi, dato che la maggior parte dei tool di debugging e di monitoring è stato adattato per funzionare senza PROCFS: la procedura di installazione non monterà questo file system di default.
options PSEUDOFS # Pseudo-filesystem framework
I kernel 6.X che fanno uso del filesystem PROCFS devono anche includere supporto per PSEUDOFS.
options GEOM_GPT # GUID Partition Tables.
Questa opzione fornisce la possibilità di avere un gran numero di partizioni su un singolo disco.
options COMPAT_43 # Compatible with BSD 4.3 [KEEP THIS!]
Compatibilità con 4.3BSD. Lasciala; alcuni programmi si comporteranno in maniera strana se la commenti.
options COMPAT_FREEBSD4 # Compatible with FreeBSD4
Questa opzione è richiesta su FreeBSD 5.X su sistemi i386™ e Alpha per supportare applicazioni compilate su versioni precedenti di FreeBSD che usano vecchie interfacce di system call. Si raccomanda che questa opzione sia usata su tutte le i386™ ed Alpha che possano eseguire vecchie applicazioni; piattaforme che hanno ottenuto supporto solo dall 5.X, come ia64 e sparc64 non richiedono questa opzione.
options COMPAT_FREEBSD5 # Compatible with FreeBSD5
Questa opzione è richiesta per FreeBSD 6.X e superiori per supportare applicazioni compilate su os; 5.X che fanno uso di chiamate di sistema di FreeBSD 5.X.
options SCSI_DELAY=5000 # Delay (in ms) before probing SCSI
Questa opzione fa sì che il kernel faccia una pausa di 5 secondi prima di controllare ogni device SCSI sul tuo sistema. Se hai solo dischi IDE, puoi ignorarla, altrimenti potresti voler diminuire il numero per accelerare il boot. Ovviamente, se fai ciò e FreeBSD ha problemi a riconoscere i tuoi device SCSI, dovrai alzarla di nuovo.
options KTRACE # ktrace(1) support
Questo abilita il tracciamento dei processi nel kernel, che è utile per il debugging.
options SYSVSHM # SYSV-style shared memory
Questa opzione fornisce memoria condivisa di tipo System V. L’uso più comune di questa opzione è l’estensione XSHM in X, grazie alla quale molti programmi ad alta intensità grafica ne trarranno vantaggio per maggior velocità. Se usi X, vorrai sicuramente includere questa opzione.
options SYSVMSG # SYSV-style message queues
Supporto per messaggi stile System V. Questa opzione aggiunge solo poche centinaia di byte al kernel.
options SYSVSEM # SYSV-style semaphores
Supporto per semafori stile System V. Usato meno di frequente ma aggiunge solo poche centinaia di byte al kernel.
L’opzione |
options _KPOSIX_PRIORITY_SCHEDULING # POSIX P1003_1B real-time extensions
Estensioni real-time aggiunte al POSIX® 1993. Alcune applicazioni nella collezione dei Ports usano questa opzione (come StarOffice™).
options KBD_INSTALL_CDEV # install a CDEV entry in /dev
Questa opzione è relativa ala tastiera. Aggiunge una entry CDEV nella directory /dev.
options ADAPTIVE_GIANT # Giant mutex is adaptive.
Giant è il nome di un meccanismo di esclusione reciproca (uno sleep mutex) che protegge gran parte delle risorse del kernel. Al giorno d’oggi è un inaccettabile rallentamento delle performance che si sta attivamente sostituendo con locks che proteggono risorse individuali. L’opzione ADAPTIVE_GIANT fa sì che Giant sia incluso nell’insieme dei mutex da scegliere. Cioè quando un thread vuole fare un lock sul mutex Giant, ma è già bloccato da un thread su un’altra CPU, il primo thread continuerà a girare ed aspetterà che il lock sia rilasciato. Normalmente invece, il thread tornerebbe a dormire e aspetterà la sua prossima occasione per girare. Se non sei sicuro, lascialo dentro.
device apic # I/O APIC
Il device apic abilita l’uso dell’APIC I/O per inviare gli interrupt. Il device apic può essere usato sia su kernel UP che su SMP, ma è richiesto per kernel SMP. Aggiungi option SMP per includere supporto per processori multipli.
Il dispositivo apic esiste sono per l’architettura i386, questa riga di configurazione non deve essere usata per altre architetture. |
device eisa
Includilo se hai una motherboard EISA. Questo abilita supporto per l’auto-rilevazione e configurazione per tutti i device sul bus EISA.
device pci
Includilo se hai una motherboard PCI. Questo abilita l’auto-rilevazione delle carte PCI e operazioni di gateway dal bus PCI al bus ISA.
# Floppy drives device fdc
Questo abilita il supporto al controller del floppy drive.
# ATA and ATAPI devices device ata
Questo driver supporta tutti i device ATA e ATAPI. Hai bisogno solo di una linea device ata per il kernel affinchè rilevi tutti i device PCI ATA/ATAPI su macchine moderne.
device atadisk # ATA disk drives
Questo è necessario assieme a device ata per disk drive ATA.
device ataraid # ATA RAID drives
Questo è necessario assieme a device ata per drive ATA RAID.
device atapicd # ATAPI CDROM drives
Questo è necessario assieme a device ata per drive CDROM ATAPI.
device atapifd # ATAPI floppy drives
Questo è necessario assieme a device ata per drive floppy ATAPI.
device atapist # ATAPI tape drives
Questo è necessario assieme a device ata per drive tape ATAPI.
options ATA_STATIC_ID # Static device numbering
Questo rende il numero di controller statico; senza questo i numeri di device sono allocati dinamicamente.
# SCSI Controllers
device ahb # EISA AHA1742 family
device ahc # AHA2940 and onboard AIC7xxx devices
options AHC_REG_PRETTY_PRINT # Print register bitfields in debug
# output. Adds ~128k to driver.
device ahd # AHA39320/29320 and onboard AIC79xx devices
options AHD_REG_PRETTY_PRINT # Print register bitfields in debug
# output. Adds ~215k to driver.
device amd # AMD 53C974 (Teckram DC-390(T))
device isp # Qlogic family
#device ispfw # Firmware for QLogic HBAs- normally a module
device mpt # LSI-Logic MPT-Fusion
#device ncr # NCR/Symbios Logic
device sym # NCR/Symbios Logic (newer chipsets + those of `ncr')
device trm # Tekram DC395U/UW/F DC315U adapters
device adv # Advansys SCSI adapters
device adw # Advansys wide SCSI adapters
device aha # Adaptec 154x SCSI adapters
device aic # Adaptec 15[012]x SCSI adapters, AIC-6[23]60.
device bt # Buslogic/Mylex MultiMaster SCSI adapters
device ncv # NCR 53C500
device nsp # Workbit Ninja SCSI-3
device stg # TMC 18C30/18C50Controller SCSI. Commentali tutti se non ne hai nessuno sul tuo sistema. Se hai un sistema solo IDE, puoi rimuoverli tutti. Le righe *_REG_PRETTY_PRINT sono opzioni di debug per i loro rispettivi dispositivi.
# SCSI peripherals device scbus # SCSI bus (required for SCSI) device ch # SCSI media changers device da # Direct Access (disks) device sa # Sequential Access (tape etc) device cd # CD device pass # Passthrough device (direct SCSI access) device ses # SCSI Environmental Services (and SAF-TE)
Periferiche SCSI. Ancora, commentali se non ne hai nessuna o se il tuo sistema è solo IDE.
Il driver USB umass(4) e pochi altri driver usano il sottosistema SCSI anche se non sono veri device SCSI. Quindi accertati di non rimuovere il supporto a SCSI, se qualche driver del genere è incluso nella tua configurazione del kernel. |
# RAID controllers interfaced to the SCSI subsystem device amr # AMI MegaRAID device arcmsr # Areca SATA II RAID device asr # DPT SmartRAID V, VI and Adaptec SCSI RAID device ciss # Compaq Smart RAID 5* device dpt # DPT Smartcache III, IV - See NOTES for options device hptmv # Highpoint RocketRAID 182x device rr232x # Highpoint RocketRAID 232x device iir # Intel Integrated RAID device ips # IBM (Adaptec) ServeRAID device mly # Mylex AcceleRAID/eXtremeRAID device twa # 3ware 9000 series PATA/SATA RAID # RAID controllers device aac # Adaptec FSA RAID device aacp # SCSI passthrough for aac (requires CAM) device ida # Compaq Smart RAID device mfi # LSI MegaRAID SAS device mlx # Mylex DAC960 family device pst # Promise Supertrak SX6000 device twe # 3ware ATA RAID
Controller RAID supportati. Se non ne hai nessuno, puoi commentarli o rimuoverli.
# atkbdc0 controls both the keyboard and the PS/2 mouse device atkbdc # AT keyboard controller
Il controller della tastiera (atkbdc) fornisce servizi I/O per la tastiera AT ed il device PS/2. Questo controller è richiesto dal driver della tastiera (atkbd) e dal driver del dispositivo di puntamento PS/2 (psm).
device atkbd # AT keyboard
Il driver atkbd assieme al controller atkbdc, fornisce accesso alla tastiera AT 84 o la tastiera AT migliorata che è connesso al controller della tastiera AT.
device psm # PS/2 mouse
Usa questo device se il tuo mouse si inserisce nella porta PS/2.
device kbdmux # keyboard multiplexer
Supporto base per il multiplexing della tastiera. Se non hai intenzione di usare più di una tastiera sul sistema, puoi tranquillamente rimuovere quella riga.
Supporto base per il multiplexing della tastiera.
device vga # VGA video card driver
Il driver della video card.
# splash screen/screen saver device splash # Splash screen and screen saver support
Schermata slapsh all’avvio! Anche gli screensaver lo richiedono.
# syscons is the default console driver, resembling an SCO console device sc
sc è il driver di default della console, assomiglia ad una console SCO. Dato che molti programmi a schermo intero accedono alla console attraverso una libreria di database di terminali come termcap, non dovrebbe fare differenza se usi questo o vt, il driver compatibile con una console VT220. Quando ti logghi, imposta la tua variabile d’ambiente TERM a scoansi se programmi a schermo intero hanno problemi a girare sotto questa console.
# Enable this for the pcvt (VT220 compatible) console driver #device vt #options XSERVER # support for X server on a vt console #options FAT_CURSOR # start with block cursor
Questo è un driver di console compatibile con VT-220, compatibile all’indietro con VT100/102. Funziona bene su alcuni laptop che hanno incompatibilità hardware con sc. Inoltre imposta la tua variabile TERM a vt100 o vt220 quando ti logghi. Questo driver può essere utile quando ci si connette ad un grande numero di macchine diverse sulla rete, dove le entry termcap o terminfo per il device sc spesso non sono disponibili - vt100 dovrebbe essere disponibile virtualmente su ogni piattaforma.
device agp
Includilo se hai una scheda AGP nel tuo sistema. Questo abiliterà il supporto per AGP, e AGP GART per le motherboard che hanno queste caratteristiche.
# Power management support (see NOTES for more options) #device apm
Supporto Advanced Power Management. Utile per laptop, anche se in FreeBSD 5.X e successivo questo è disabilitato in GENERIC di default.
# Add suspend/resume support for the i8254. device pmtimer
Device driver per eventi di power management, come APM ed ACPI.
# PCCARD (PCMCIA) support # PCMCIA and cardbus bridge support device cbb # cardbus (yenta) bridge device pccard # PC Card (16-bit) bus device cardbus # CardBus (32-bit) bus
Supporto PCMCIA. Includilo se usi un laptop.
# Serial (COM) ports device sio # 8250, 16[45]50 based serial ports
Queste sono le porte seriali chiamate COM nel mondo MS-DOS®/Windows®.
Se hai un modem interno sulla COM4 ed una porta seriale sulla COM2, dovrai cambiare l’IRQ del modem a 2 (per ragioni tecniche oscure IRQ 2=IRQ 9) affinchè tu ci possa accedere da FreeBSD. Se hai una carta seriale multiporta, controlla la pagina di manuale per sio(4) per maggiori informazioni sui valori corretti da aggiungere al tuo /boot/device.hints. Alcune video card (in particolare quelle basate su chip S3) usano indirizzi IO della forma Ogni porta seriale deve avere un IRQ unico (a meno che non stia usando una delle carte multicard dove sono supportati interrupt condivisi), così gli IRQ di default per COM3 e COM4 non possono essere usati. |
# Parallel port device ppc
Questo è l’interfaccia al bus ISA parallelo.
device ppbus # Parallel port bus (required)
Fornisce supporto per il bus della porta parallela.
device lpt # Printer
Supporto per la stampante a porta parallela.
Tutte quest tre sono necessarie per abilitare supporto alla stampante parallela. |
device plip # TCP/IP over parallel
Questo è il driver della interfaccia di rete parallela.
device ppi # Parallel port interface device
L’I/O a scopo generico ("geek port") + IEEE1284 I/O.
#device vpo # Requires scbus and da
Questo è per uno IOMEGA zip drive. Richiede supporto scbus e da. La migliore performance è raggiunta con porte in modo EPP 1.9.
#device puc
Scommenta questo device se ha una seriale "dumb" o carta PCI parallela che è supportata dal driver glue puc(4).
# PCI Ethernet NICs. device de # DEC/Intel DC21x4x (Tulip) device em # Intel PRO/1000 adapter Gigabit Ethernet Card device ixgb # Intel PRO/10GbE Ethernet Card device txp # 3Com 3cR990 (Typhoon) device vx # 3Com 3c590, 3c595 (Vortex)
Vari driver di schede di rete PCI. Commentalo o rimuovilo se nessuno di questi è presente nel tuo sistema.
# PCI Ethernet NICs that use the common MII bus controller code. # NOTE: Be sure to keep the 'device miibus' line in order to use these NICs! device miibus # MII bus support
Supporto bus MII è richiesto per alcune NIC Ethernet 10/100 PCI, in particolare quelle che usano transricevitori compatibili con MII o implementano interfacce di controllo che operano su MII. Aggiungere device miibus al kernel porta con sè il supporto per la generica API miibus e tutti i driver PHY, incluso un generico per PHY che non è specificamente gestito da driver individuali.
device bce # Broadcom BCM5706/BCM5708 Gigabit Ethernet device bfe # Broadcom BCM440x 10/100 Ethernet device bge # Broadcom BCM570xx Gigabit Ethernet device dc # DEC/Intel 21143 and various workalikes device fxp # Intel EtherExpress PRO/100B (82557, 82558) device lge # Level 1 LXT1001 gigabit ethernet device msk # Marvell/SysKonnect Yukon II Gigabit Ethernet device nge # NatSemi DP83820 gigabit ethernet device nve # nVidia nForce MCP on-board Ethernet Networking device pcn # AMD Am79C97x PCI 10/100 (precedence over 'lnc') device re # RealTek 8139C+/8169/8169S/8110S device rl # RealTek 8129/8139 device sf # Adaptec AIC-6915 (Starfire) device sis # Silicon Integrated Systems SiS 900/SiS 7016 device sk # SysKonnect SK-984x & SK-982x gigabit Ethernet device ste # Sundance ST201 (D-Link DFE-550TX) device stge # Sundance/Tamarack TC9021 gigabit Ethernet device ti # Alteon Networks Tigon I/II gigabit Ethernet device tl # Texas Instruments ThunderLAN device tx # SMC EtherPower II (83c170 EPIC) device vge # VIA VT612x gigabit ethernet device vr # VIA Rhine, Rhine II device wb # Winbond W89C840F device xl # 3Com 3c90x (Boomerang, Cyclone)
Driver che usano il codice del controller MII.
# ISA Ethernet NICs. pccard NICs included. device cs # Crystal Semiconductor CS89x0 NIC # 'device ed' requires 'device miibus' device ed # NE[12]000, SMC Ultra, 3c503, DS8390 cards device ex # Intel EtherExpress Pro/10 and Pro/10+ device ep # Etherlink III based cards device fe # Fujitsu MB8696x based cards device ie # EtherExpress 8/16, 3C507, StarLAN 10 etc. device lnc # NE2100, NE32-VL Lance Ethernet cards device sn # SMC's 9000 series of Ethernet chips device xe # Xircom pccard Ethernet # ISA devices that use the old ISA shims #device le
Driver ISA Ethernet. Vedi /usr/src/sys/i386/conf/NOTES per dettagli su quali carte siano supportate da quali driver.
# Wireless NIC cards device wlan # 802.11 support
Supporto generico al 802.11. Questa riga è richiesta per la rete wireless.
device wlan_wep # 802.11 WEP support device wlan_ccmp # 802.11 CCMP support device wlan_tkip # 802.11 TKIP support
Supporto di crittografia per i dispositivi 802.11. Queste righe sono necessarie se intenti usare la codificazione e i protocolli di sicurezza 802.11i.
device an # Aironet 4500/4800 802.11 wireless NICs. device ath # Atheros pci/cardbus NIC's device ath_hal # Atheros HAL (Hardware Access Layer) device ath_rate_sample # SampleRate tx rate control for ath device awi # BayStack 660 and others device ral # Ralink Technology RT2500 wireless NICs. device wi # WaveLAN/Intersil/Symbol 802.11 wireless NICs. #device wl # Older non 802.11 Wavelan wireless NIC.
Supporto per varie carte wireless.
# Pseudo devices device loop # Network loopback
Questo è il generico device loopback per TCP/IP. Se fai telnet o FTP a localhost (anche conosciuto come 127.0.0.1) la connessione ritornerà alla tua stessa macchina attraverso questo device. Questo è obbligatorio.
device random # Entropy device
Generatore casuale sicuro di numeri random.
device ether # Ethernet support
ether è necessario solo se hai una carta Ethernet. Include un codice di protocollo Ethernet.
device sl # Kernel SLIP
sl è per supporto slip. È stato interamente soppiantato da PPP, che è più semplice da installare, più adatto per connessioni modem-to-modem e più potente.
device ppp # Kernel PPP
Questo è per supporto kernel PPP per connessioni dial-up. C’è anche una versione di PPP implementata come applicazione userland che usa tun e offre più flessibilità e caratteristiche aggiuntive come dialing a domanda.
device tun # Packet tunnel.
Questo è usato per software userland PPP. Vedi la sezione PPP di questo libro per maggiori informazioni.
device pty # Pseudo-ttys (telnet etc)
Questo è uno "pseudo-terminal" o porta di login simulato. È usato da sessioni telnet e rlogin, xterm e qualche altra applicazione come Emacs.
device md # Memory disks
Pseudo-device di disco di memoria.
device gif # IPv6 and IPv4 tunneling
Questo implementa il tunneling IPv6 su IPv4, IPv4 su IPv6, IPv4 su IPv4 e IPv6 su IPv6. Il device gif è "autoclonante", e creerà gli altri node come richiesto.
device faith # IPv6-to-IPv4 relaying (translation)
Questo pseudo-device cattura i pacchetti che sono inviati a lui e li distoglie verso il demone di traslazione IPv4/IPv6.
# The `bpf' device enables the Berkeley Packet Filter. # Be aware of the administrative consequences of enabling this! # Note that 'bpf' is required for DHCP. device bpf # Berkeley packet filter
Questo è il Berkeley Packet Filter. Questo pseduo-device permette alle interfacce di rete di essere configurate in modo promiscuo, catturando ogni pacchetto su una rete broadcast (ad esempio una Ethernet). Questi pacchetti possono essere catturati su disco e o esaminati con il programma tcpdump(1).
Il device bpf(4) è anche usato da dhclient(8) per ottenere l’indirizzo IP del default router (gateway) eccetera. Se usi DHCP, lascia questa riga scommentata. |
# USB support device uhci # UHCI PCI->USB interface device ohci # OHCI PCI->USB interface device ehci # EHCI PCI->USB interface (USB 2.0) device usb # USB Bus (required) #device udbp # USB Double Bulk Pipe devices device ugen # Generic device uhid # Human Interface Devices device ukbd # Keyboard device ulpt # Printer device umass # Disks/Mass storage - Requires scbus and da device ums # Mouse device ural # Ralink Technology RT2500USB wireless NICs device urio # Diamond Rio 500 MP3 player device uscanner # Scanners # USB Ethernet, requires mii device aue # ADMtek USB Ethernet device axe # ASIX Electronics USB Ethernet device cdce # Generic USB over Ethernet device cue # CATC USB Ethernet device kue # Kawasaki LSI USB Ethernet device rue # RealTek RTL8150 USB Ethernet
Supporto per vari device USB.
# FireWire support device firewire # FireWire bus code device sbp # SCSI over FireWire (Requires scbus and da) device fwe # Ethernet over FireWire (non-standard!)
Supporto per vari device FireWire.
Per maggiori informazioni e device addizionali supportati da FreeBSD, controlla /usr/src/sys/i386/conf/NOTES.
Macchine con configurazione a memoria estesa richiedono più di 4 gigabyte di limite nello spazio degli indirizzi Virtuale User+Kernel (KVA). A causa di questa limitazione, Intel ha aggiunto supporto per lo spazio degli indirizzi fisico a 36-bit nel Pentium® Pro e linee successive di CPU.
La caratteristica di Physical Address Extension (PAE) dell' Intel® Pentium® Pro e CPU successive permette configurazioni della memoria fino a 64 gigabyte. FreeBSD fornisce supporto per questa caratteristica attraverso l’opzione di configurazione del kernel PAE, disponibile in tutte le versioni correnti di FreeBSD. A causa della limitazione della architettura della memoria Intel, nessuna distinzione è fatta per memorie sopra o sotto i 4 gigabyte. Memoria allocata oltre i 4 gigabyte è semplicemente aggiunta al pool della memoria disponibile.
Per abilitare il supporto PAE nel kernel, aggiungi semplicemente la seguente linea nel tuo file di configurazione del kernel:
options PAE
Il supporto PAE in FreeBSD è disponibile solo per processori Intel® IA-32. Bisogna notare inoltre che il supporto PAE non ha ricevuto test esteso, e dovrebbe essere considerato di qualità beta rispetto alle altre carateristiche stabili di FreeBSD. |
Il supporto per PAE in FreeBSD ha qualche limitazione:
Un processo non è in grado di accedere a più di 4 gigabte di spazio VM.
I moduli KLD non possono essere caricati in un kernel con abilitato PAE, a causa delle differenze nell’ambiente di compilazione di un modulo e del kernel.
Device driver che non usano l’interfaccia bus_dma(9) causeranno corruzione dei dati in un kernel abilitato PAE, e non se ne raccomanda l’uso. Per questo motivo, viene fornito un file di configurazione del kernel PAE, che esclude tutti i driver per i quali non è stato testato il funzionamento in un kernel abilitato PAE.
Alcuni parametri che possono essere settati determinano l’uso delle risorse di memoria a partire dalla quantità di memoria fisica disponibile. Questi parametri possono allocare troppo spazio rispetto alle necessità a causa della dimensione della memoria di un sistema PAE. Un esempio simile è il sysctl kern.maxvnodes, che controlla il massimo numero di vnodes permessi nel kernel. È concesso di aggiustare questo ed altri parametri ad un valore ragionevole.
Può essere necessario aumentare lo spazio degli indirizzi di memoria virtuale del kernel (KVA) o ridurre la quantità di risorse specifiche che sono pesantemente usate (vedi oltre) per evitare esaurimenti di KVA. L’opzione del kernel KVA_PAGES può essere usata per aumentare lo spazio KVA.
Ci sono cinque categorie di problemi che si possono presentare quando si crea un nuovo kernel. Sono:
config fallisceSe il comando config(8) fallisce quando gli passi la descrizione del tuo kernel, hai fatto probabilmente un semplice errore da qualche parte. Fortunatamente config(8) scriverà il numero della linea che ha dato errore, così puoi facilmente trovare la linea errata. Ad esempio, se vedi:
config: line 17: syntax errorAccertati che la parola chiave sia scritta correttamente confrontandola con quella del kernel GENERIC o un altro riferimento.
make fallisceSe il comando make fallisce, di solito segnala un errore nella descrizione del kernel che non è abbastanza grave per config(8). Ancora, controlla la tua configurazione e se ancora non riesci a risolvere il problema, invia una mail a mailing list per le domande generiche su FreeBSD con la tua configurazione del kernel, e dovrebbe essere diagnosticato velocemente.
Se il tuo kernel non fa il boot, o fallisce nel riconoscimento dei tuoi device, non andare in panico! Fortunatamente FreeBSD ha un ottimo meccanismo per ricominciare in questo caso. Semplicemente scegli il kernel da cui vuoi fare il boot dal boot loader FreeBSD. Puoi accedere ad esso quando appare il menu del boot. Seleziona l’opzione "Escape to a loader prompt", la numero sei. Al prompt digita unload kernel e poi digita boot /boot/kernel.old/kernel o il nome del file di un altro kernel da cui puoi bootare correttamente. Quando configuri un kernel, è sempre una buona idea tenere un kernel che si sa che funzioni a portata di mano.
Dopo aver fatto il boot con un kernel funzionante puoi controllare il tuo file di configurazione e cercare di ricompilarlo. Una risorsa utile è il file /var/log/messages che, fra le altre cose, registra tutti messaggi del kernel da ogni boot riuscito. Inoltre, il comando dmesg(8) scriverà i messaggi del kernel dall’ultimo boot.
Se hai problemi a compilare un kernel, accertati di tenere un kernel GENERIC, o qualche altro kernel che sai che funzioni a portata di mano,con un nome diverso cosichè non sia cancellato dalla successiva compilazione. Non puoi affidarti su kernel.old perchè quando installi un nuovo kernel, kernel.old viene cancellato dall’ultimo kernel installato, che poteva essere non funzionanante. Inoltre, appena possibile, sposta il kernel funzionanante nella directory corretta /boot/kernel o comandi come ps(1) potrebbero non funzionare bene. Per farlo, semplicemente rinomina la directory contenente il kernel funzionante: |
Se hai installato una versione del kernel differente da quella delle utilities di sistema, per esempio un kernel -CURRENT ed un sistema -RELEASE, molti comandi di stato del sistema come ps(1) e vmstat(8) non funzioneranno più. Dovresti ricompilare ed installare world con la stessa versione dei sorgenti del tuo kernel. Questa è una ragione per non usare una versione del kernel diversa dal sistema operativo.
FreeBSD fornisce la compatibilità con molti altri sisitemi operativi di tipo UNIX®, compreso linux. A questo punto, potresti chiederti perché FreeBSD dovrebbe essere in grado di far girare binari linux. La risposta a questa domanda è piuttosto semplice. Molte aziende e sviluppatori sviluppano solo per Linux, dal momento che ` l’ultimo "disco caldo" nel mondo dell’informatica. Questo costringe il resto di noi utenti di FreeBSD a lamentarci con queste aziende e questi sviluppatori di distribuire versioni delle loro applicazioni native per FreeBSD. Il problema è che molte di queste aziende non realizzano quante persone userebbero il loro prodotto se ci fosse anche una versione per FreeBSD, e molte continuano a sviluppare solo per Linux. Allora cosa deve fare un utente FreeBSD? E qui entra in giocolo la compatibilità con i binari di Linux.
In breve, la compatibilità permette agli utenti FreeBSD di utilizzare circa il 90% di tutte le applicazioni Linux senza modifiche. Questo include applicazioni come StarOffice™ , la versione Linux di getenv(3), Adobe® Acrobat®, RealPlayer®, VMware, Oracle®, WordPerfect®, Doom, Quake, e tanti altri. È stato riportato che in qualche situazione i binari per Linux sono più prestanti sotto FreeBSD che sotto Linux.
Nonostante questo, ci sono alcune caratteristiche specifiche del sistema operativo Linux che non sono supportate da FreeBSD. I binari di Linux non funzioneranno sotto FreeBSD se usano parecchie chiamate specifiche per i386™, come l’attivazione della modalità 8086 virtuale
Dopo aver letto questo capitolo, saprai:
Come abilitare la compatibilità con i binari Linux sul tuo sistema.
Come installare ulteriori librerie condivise per Linux.
Come installare gli applicativi di Linux sul tuo sistema FreeBSD.
I dettagli dell’implementazione della compatibilità Linux in FreeBSD.
Prima di leggere questo capitolo, dovresti:
Sapere come installare software di terzi (Installazione delle Applicazioni. Port e Package).
La compatibilità con i binari Linux non è normalmente attivata. Il modo più facile per abilitare questa funzionalità è caricare l’oggetto KLD ("Kernel LoaDable object") linux. Puoi caricare questo modulo digitando il comando seguente come root:
# kldload linuxSe vuoi che la compatiblità sia sempre attivata, dovresti aggiungere questa linea a /etc/rc.conf:
linux_enable="YES"
Il comando kldstat(8) può essere usato per verificare se KLD sia stato caricato:
% kldstat
Id Refs Address Size Name
1 2 0xc0100000 16bdb8 kernel
7 1 0xc24db000 d000 linux.koSe per qualche ragione non vuoi o non puoi caricare KLD, puoi collegare staticamente la compatibilità Linux nel kernel aggiungendo options COMPAT_LINUX al file di configurazione del kernel. Fatto questo puoi installare il nuovo kernel come descritto in Configurazione del Kernel di FreeBSD.
Questo può essere fatto in due modi, o usando il port linux_base, oppure installandole manualmente.
Questo è di gran lunga il metodo più facile da usare per installare le librerie runtime. È proprio come installare qualunque altro port dalla Collezione dei Port. Semplicemente fai come segue:
# cd /usr/ports/emulators/linux_base-fc4
# make install distcleanIn questo modo dovresti avere una compatibilità con i binari di Linux funzionante. Alcuni programmi potrebbero lamentarsi per qualche versione minore delle librerie di sistema. In generale, comunque, questo non dovrebbe essere un problema.
Potrebbero essere disponibili più versioni del port emulators/linux_base, corrispondenti a differenti versioni di distribuzioni Linux. Dovresti installare il port che più soddisfa le richieste della applicazione Linux che vuoi installare. |
Se non hai installata la collezione di "ports", puoi comunque installare le librerie manualmente. Hai bisogno delle librerie condivise di Linux da cui il programma dipende e del runtime linker. In più dovrai creare una directory "shadow root", /compat/linux, per le librerie Linux sul tuo sistema FreeBSD. Tutte le librerie condivise aperte da programmi Linux che girano sotto FreeBSD cercheranno prima in questo albero. Per cui, se un programma Linux carica, per esempio, /lib/libc.so, FreeBSD prima cercherà di aprire /compat/linux/lib/libc.so, e se questa non esiste, proverà con /lib/libc.so. Le librerie condivise dovrebbero essere installate nell’albero shadow /compat/linux/lib piuttosto che nei path che riporta ld.so di Linux.
Generalmente avrai bisogno di cercare le librerie condivise da cui dipendono i binari di Linux solo per le prime poche installazioni di programmi Linux sul tuo sistema FreeBSD. Dopo un po' avrai a disposizione sul tuo sistema un insieme sufficiente di librerie condivise per Linux da far girare nuovi binari Linux senza alcun sforzo ulteriore.
Cosa succede se installi il port linux_base e la tua applicazione si lamenta ancora di librerie condivise che mancano? Come fare a sapere quali librerie condivise necessita il binario di Linux e dove trovarle? Essenzialmente ci sono 2 possibilità (per seguire queste istruzioni dovrai essere root sul tuo sistema FreeBSD).
Se hai accesso ad un sistema Linux, guarda quali librerie condivise servono all’applicazione e copiale nel tuo sistema FreeBSD. Guarda all’esempio che segue:
Poniamo che tramite FTP tu abbia recuperato il binario per Linux di Doom, e l’abbia messo su un sistema Linux a cui hai accesso. Puoi controllare quali librerie condivise servono eseguendo ldd linuxdoom, così:
% ldd linuxdoom
libXt.so.3 (DLL Jump 3.1) => /usr/X11/lib/libXt.so.3.1.0
libX11.so.3 (DLL Jump 3.1) => /usr/X11/lib/libX11.so.3.1.0
libc.so.4 (DLL Jump 4.5pl26) => /lib/libc.so.4.6.29Potresti aver bisogno di recuperare tutti i file dall’ultima colonna, e di metterli sotto /compat/linux, con i nomi nella prima colonna come link simbolici che puntino ad essi. Questo significa che alla fine avrai questi file sul tuo sistema FreeBSD:
/compat/linux/usr/X11/lib/libXt.so.3.1.0
/compat/linux/usr/X11/lib/libXt.so.3 -> libXt.so.3.1.0
/compat/linux/usr/X11/lib/libX11.so.3.1.0
/compat/linux/usr/X11/lib/libX11.so.3 -> libX11.so.3.1.0
/compat/linux/lib/libc.so.4.6.29
/compat/linux/lib/libc.so.4 -> libc.so.4.6.29Nota che se hai già una libreria condivisa di Linux con un numero di revisione maggiore di quello della prima colonna dell’output di e vedi che un nuovo binario richiede una versione più recente in base all’output di Se si tratta solo di una o due versioni precedenti in base alla cifra finale allora non preoccuparti di copiare anche /lib/libc.so.4.6.29, perché il programma dovrebbe funzionare bene anche con una versione di poco più vecchia. In ogni caso, se vuoi, puoi decidere di rimpiazzare comunque libc.so, e dovrebbe lasciarti con: |
Il meccanismo dei link simbolici è richiesto solo per i binari di Linux. Il runtime linker di FreeBSD si occupa da solo di cercare corrispondenti numeri di revisione maggiori e non devi preoccuparti di questo. |
I binari ELF possono richiedere un ulteriore passo di "marchiatura". Se provi a far girare un binario ELF non marchiato, incorrerai in un messaggio come il seguente:
% ./my-linux-elf-binary
ELF binary type not known
AbortPer aiutare il kernel di FreeBSD a distinguere un binario ELF di FreeBSD da uno di Linux, usa l’utility brandelf(1).
% brandelf -t Linux my-linux-elf-binaryOggi, la GNU toolchain inserisce automaticamente l’appropriata informazione di marchiatura nei binari ELF, così questo passo dovrebbe divenire sempre meno necessario nel futuro.
Se il DNS non funziona o da questo messaggio:
resolv+: "bind" is an invalid keyword resolv+:
"hosts" is an invalid keywordDovrai configurare un file /compat/linux/etc/host.conf contentente:
order hosts, bind multi on
Qui, l’ordine specifica che /etc/hosts viene cercato per primo e il DNS per secondo. Quando /compat/linux/etc/host.conf non è installato, le applicazioni Linux trovano il /etc/host.conf di FreeBSD e si lamentano della sintassi incompatibile di FreeBSD. Dovresti rimuovere bind se non hai configurato un name server usando il file /etc/resolv.conf.
Questo documento descive il processo di installazione della versione Linux di Mathematica® 5.X su un sistema FreeBSD.
La versione Linux di Mathematica® o di Mathematica® for Students può essere ordinata direttamente da Wolfram all’indirizzo http://www.wolfram.com/.
Prima di tutto, devi indicare a FreeBSD che i binari Linux di Mathematica® usano le ABI di Linux. Il modo più facile di farlo è di settare il tipo di ELF a Linux per tutti i binari non marchiati con il comando:
# sysctl kern.fallback_elf_brand=3In questo modo FreeBSD assume che tutti i binari ELF non marchiati usino l’ABI di Linux e quindi dovresti essere in grado di eseguire l’installer direttamente dal CDROM.
Ora, copia il file MathInstaller sul tuo disco:
# mount /cdrom
# cp /cdrom/Unix/Installers/Linux/MathInstaller /localdir/e in questo file, rimpiazza la prima riga /bin/sh con /compat/linux/bin/sh. Questo assicura che l’installer viene eseguito dalla versione Linux di sh(1). Poi, rimpiazza tutte le occorrenze di Linux) con FreeBSD) utilizzando un editor di testo o lo script mostrato nella prossima sezione. Questo indica all’installer di Mathematica®, che chiama uname -s per determinare il sistema operativo, per trattare FreeBSD come un sistema operativo Linux-like. Invocando MathInstaller verrà installato Mathematica®.
Gli script di shell che Mathematica® crea durante l’installazione devono essere modificati prima di poterli usare. Se hai scelto di mettere gli eseguibili di Mathematica® nella directory /usr/local/bin, troverai in questa directory dei link simbolici chiamati math, mathematica, Mathematica, e MathKernel. In ognuno di questi, sostituisci Linux) con FreeBSD) usando un editor di testo o il seguente script di shell:
#!/bin/sh cd /usr/local/bin for i in math mathematica Mathematica MathKernel do sed 's/Linux)/FreeBSD)/g' $i > $i.tmp sed 's/\/bin\/sh/\/compat\/linux\/bin\/sh/g' $i.tmp > $i rm $i.tmp chmod a+x $i done
Quando avvii Mathematica® per la prima volta, ti verrà richiesta una password. Se non hai ancora ottenuto una password da Wolfram, esegui il programma mathinfo nella directory di installazione per ottenere il tuo "ID di macchina". Questo ID è basato esclusivamente sull’indirizzo MAC della tua prima scheda di Ethernet, quindi non puoi eseguire la tua copia di Mathematica® su macchine diverse.
Quando ti registri alla Wolfram, sia per email, telefono o fax, gli darai il "machine ID" e loro ti restituiranno una password corrispondente che consiste di un gruppo di numeri.
Mathematica® usa alcuni font speciali per visualizzare caratteri non presenti in alcun insieme standard di font (integrali, sommatorie, lettere greche, ecc.). Il protocollo X necessita che questi font siano installati localmente. Questo significa che dovrai fare una copia di questi font sulla tua macchina locale dal CDROM o da un host con Mathematica® installato. Questi font si trovano normalmente in /cdrom/Unix/Files/SystemFiles/Fonts sul CDROM, oppure /usr/local/mathematica/SystemFiles/Fonts sul tuo disco rigido. I font sono nelle sottodirectory Type1 e X. Ci sono molti modi di usarli, come descritto sotto.
Il primo modo è di copiarli dentro una delle directory di font esistenti in /usr/X11R6/lib/X11/fonts. Questo comporterà la modifica del file fonts.dir, aggiungendovi i nomi dei font e cambiando il numero di font nella prima riga. In alternativa, dovresti anche essere in grado di lanciare mkfontdir(1) nella directory in cui li hai copiati.
Il secondo modo di farlo è copiare le directory in /usr/X11R6/lib/X11/fonts:
# cd /usr/X11R6/lib/X11/fonts
# mkdir X
# mkdir MathType1
# cd /cdrom/Unix/Files/SystemFiles/Fonts
# cp X/* /usr/X11R6/lib/X11/fonts/X
# cp Type1/* /usr/X11R6/lib/X11/fonts/MathType1
# cd /usr/X11R6/lib/X11/fonts/X
# mkfontdir
# cd ../MathType1
# mkfontdirPoi aggiungi le nuove directory di font nel tuo path dei font:
# xset fp+ /usr/X11R6/lib/X11/fonts/X
# xset fp+ /usr/X11R6/lib/X11/fonts/MathType1
# xset fp rehashSe stai utilizzando il server Xorg, puoi caricare automaticamente queste directory di font aggiungendole nel file xorg.conf.
Per i server XFree86™, il file di configurazione è XF86Config. |
Se ancora non hai una directory chiamata /usr/X11R6/lib/X11/fonts/Type1, puoi cambiare il nome della directory MathType1 dell’esempio sopra in Type1.
Maple™ è un programma commerciale di matematica simile a Mathematica®. Devi acquistare questo software da http://www.maplesoft.com/ e quindi registrarti per un file di licenza. Per installare questo software su FreeBSD, segui i passi seguenti.
Esegui lo script di shell INSTALL dalla distribuzione del prodotto. Scegli l’opzione "RedHat" quando richiesto dal programma di installazione. Una tipica directory di installazione potrebbe essere /usr/local/maple.
Se ancora non l’hai fatto, ordina una licenza per Maple™ dalla Maple Waterloo Software (http://register.maplesoft.com/) e copiala in /usr/local/maple/license/license.dat.
Installa il gestore della licenza FLEXlm lanciando lo shell script di installazione INSTALL_LIC, distribuito assieme a Maple™. Specifica l’hostname primario della la tua macchina per il server delle licenze.
Modifica il file /usr/local/maple/bin/maple.system.type aggiungendo:
----- snip ------------------
*** maple.system.type.orig Sun Jul 8 16:35:33 2001
--- maple.system.type Sun Jul 8 16:35:51 2001
***************
*** 72,77 ****
--- 72,78 ----
# the IBM RS/6000 AIX case
MAPLE_BIN="bin.IBM_RISC_UNIX"
;;
+ "FreeBSD"|\
"Linux")
# the Linux/x86 case
# We have two Linux implementations, one for Red Hat and
----- snip end of patch -----Nota che dopo "FreeBSD"|\ non ci devono essere altri spazi bianchi.
Questa patch dice a Maple™ di riconoscere "FreeBSD" come un tipo di sistema Linux. Lo shell script bin/maple richiama lo shell script bin/maple.system.type che a sua volta chiama uname -a per determinare il nome del sistema operativo. A seconda del nome del SO capirà quali binari utilizzare.
Avviare il server delle licenze.
Lo script seguente, installato come /usr/local/etc/rc.d/lmgrd.sh è un modo facile per far partire lmgrd:
----- snip ------------
#! /bin/sh
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/usr/X11R6/bin
PATH=${PATH}:/usr/local/maple/bin:/usr/local/maple/FLEXlm/UNIX/LINUX
export PATH
LICENSE_FILE=/usr/local/maple/license/license.dat
LOG=/var/log/lmgrd.log
case "$1" in
start)
lmgrd -c ${LICENSE_FILE} 2>> ${LOG} 1>&2
echo -n " lmgrd"
;;
stop)
llmgrd -c ${LICENSE_FILE} -x lmdown 2>> ${LOG} 1>&2
;;
*)
echo "Usage: `basename $0` {start|stop}" 1>&2
exit 64
;;
esac
exit 0
----- snip ------------Fai un test di avvio di Maple™:
% cd /usr/local/maple/bin
% ./xmapleDovrebbe funzionare. Assicurati di scrivere alla Maplesoft per fargli sapere che vorresti avere una versione nativa per FreeBSD!
Il gestore della licenza FLEXlm può essere uno strumento difficile con cui lavorare. A questo riguardo si può trovare della documentazione in più a http://www.globetrotter.com/.
Si sa che lmgrd è molto esigente riguardo al file della licenza e che va in core dump per qualunque problema. Un buon file della licenza dovrebbe essere così:
# =======================================================
# License File for UNIX Installations ("Pointer File")
# =======================================================
SERVER chillig ANY
#USE_SERVER
VENDOR maplelmg
FEATURE Maple maplelmg 2000.0831 permanent 1 XXXXXXXXXXXX \
PLATFORMS=i86_r ISSUER="Waterloo Maple Inc." \
ISSUED=11-may-2000 NOTICE=" Technische Universitat Wien" \
SN=XXXXXXXXXIl numero seriale e la chiave sono sostituiti dalle 'X'. |
Modificare il file della licenza funziona fino a quando non tocchi la linea "FEATURE" (che è protetta dalla chiave della licenza).
Questo documento descrive il processo di installazione della versione Linux di MATLAB® versione 6.5 su un sistema FreeBSD. Funziona abbastanza bene, con l’eccezione per la Java Virtual Machine™ (vedi Collegare il Java™ Runtime Environment).
La versione Linux di MATLAB® può essere ordinata direttamente dalla MathWorks all’indirizzo http://www.mathworks.com. Assicurati di avere il file della licenza o le istruzioni per crearlo. Già che ci sei, fagli sapere che vorresti una versione nativa per FreeBSD del loro software.
Per installare MATLAB®, fai come segue:
Inserisci il CD di installazione e montalo. Diventa root, come consigliato dallo script di installazione. Per avviare lo script di installazione scrivi:
# /compat/linux/bin/sh /cdrom/installL’installer è grafico. Se ottieni errori riguardo all’impossibilità ad aprire un display, scrivi |
Quando viene chiesta la directory root per MATLAB®, scrivi: /compat/linux/usr/local/matlab.
Per una più facile scrittura nel resto del processo di installazione, scrivi questo nella linea di comando della shell: |
Modifica il file della licenza secondo le istruzioni avute quando hai ottenuto la licenza di MATLAB®.
Puoi preparare questo file in anticipo usando il tuo editor preferito, e copiarlo in $MATLAB/license.dat prima che l’installer ti chieda di modificarlo. |
Completare il processo di installazione.
A questo punto la tua installazione di MATLAB® è completa. I punti seguenti applicano una "colla" per connetterlo al tuo sistema FreeBSD.
Crea dei symlink per gli script del gestore della licenza:
# ln -s $MATLAB/etc/lmboot /usr/local/etc/lmboot_TMW
# ln -s $MATLAB/etc/lmdown /usr/local/etc/lmdown_TMWCrea un file d’avvio in /usr/local/etc/rc.d/flexlm.sh. L’esempio qui sotto è una versione modificata del $MATLAB/etc/rc.lm.glnx86 venduto. I cambiamenti sono le posizioni del file e l’avvio del license manager sotto l’emulazione Linux.
#!/bin/sh
case "$1" in
start)
if [ -f /usr/local/etc/lmboot_TMW ]; then
/compat/linux/bin/sh /usr/local/etc/lmboot_TMW -u username && echo 'MATLAB_lmgrd'
fi
;;
stop)
if [ -f /usr/local/etc/lmdown_TMW ]; then
/compat/linux/bin/sh /usr/local/etc/lmdown_TMW > /dev/null 2>&1
fi
;;
*)
echo "Usage: $0 {start|stop}"
exit 1
;;
esac
exit 0Il file deve essere reso eseguibile: In aggiunta sostituisci username sopra con il nome di un utente valido sul tuo sistema (e non |
Avvia il gestore della licenza con il comando:
# /usr/local/etc/rc.d/flexlm.sh startCambia il link al Java™ Runtime Environment (JRE) con uno che funzioni sotto FreeBSD:
# cd $MATLAB/sys/java/jre/glnx86/
# unlink jre; ln -s ./jre1.1.8 ./jrePoni il seguente script di avvio in /usr/local/bin/matlab:
#!/bin/sh /compat/linux/bin/sh /compat/linux/usr/local/matlab/bin/matlab "$@"
Quindi scrivi il comando chmod +x /usr/local/bin/matlab.
A seconda della tua versione di emulators/linux_base, potresti incorrere in errori quando lanci questo script. Per evitarli, modifica il file /compat/linux/usr/local/matlab/bin/matlab, e cambia la riga che dice: if [ `expr "$lscmd" : '.*->.*'` -ne 0 ]; then (nella versione 13.0.1 è alla riga 410) con questa riga: if test -L $newbase; then |
Quello che segue serve per risolvere un problema con MATLAB® quando non si chiude correttamente.
Crea un file $MATLAB/toolbox/local/finish.m, e scrivici l’unica riga:
! $MATLAB/bin/finish.sh
|
Nella stessa directory troverai i file finishsav.m e finishdlg.m, che permettono di salvare il tuo lavoro all’uscita. Se ne usi uno, inserisci la riga sopra immediatamente dopo il comando |
Crea un file $MATLAB/bin/finish.sh, che contiene ciò che segue:
#!/usr/compat/linux/bin/sh (sleep 5; killall -1 matlab_helper) & exit 0
Rendi il file eseguibile:
# chmod +x $MATLAB/bin/finish.shQuesto documento descrive il processo di installazione per Oracle® 8.0.5 e Oracle® 8.0.5.1 Enterprise Edition per Linux su una macchina FreeBSD.
Assicurati di avere installati sia emulators/linux_base che devel/linux_devtools dalla collezione dei port. Se hai difficoltà con questi port, potresti dover usare i pacchetti o versioni più vecchie disponibili nella collezione dei port.
Se vuoi far girare l’intelligent agent, dovrai anche installare il pacchetto Tcl di Red Hat :tcl-8.0.3-20.i386.rpm. Il comando generale per l’installazione dei pacchetti con il port degli RPM ufficiali (archivers/rpm) è:
# rpm -i --ignoreos --root /compat/linux --dbpath /var/lib/rpm pacchettoL’installazione del pacchetto non dovrebbe generare alcun errore.
Prima di installare Oracle®, devi impostare un ambiente appropriato. Questo documento descrive solo cosa fare in particolare per far girare Oracle® per Linux su FreeBSD, non cosa è descritto nella guida di installazione di Oracle®.
Come viene descritto nella guida di installazione di Oracle®, devi impostare la dimensione massima di memoria condivisa. Non usare SHMMAX sotto FreeBSD. SHMMAX è soltanto calcolato a partire da SHMMAXPGS e PGSIZE. Di conseguenza definisci SHMMAXPGS. Tutte le altre opzioni possono essere usate come descritte nella guida. Per esempio:
options SHMMAXPGS=10000 options SHMMNI=100 options SHMSEG=10 options SEMMNS=200 options SEMMNI=70 options SEMMSL=61
Imposta queste opzioni per ottenere l’uso desiderato di Oracle®.
In più, assicurati di avere le seguenti opzioni nel file di configurazione del tuo kernel:
options SYSVSHM #SysV shared memory options SYSVSEM #SysV semaphores options SYSVMSG #SysV interprocess communication
Crea un account oracle proprio come faresti per creare qualunque altro account. L’account oracle è speciale solo se hai bisogno di usarlo in una shell di Linux. Aggiungi /compat/linux/bin/bash a /etc/shells e imposta la shell per l’account di oracle in /compat/linux/bin/bash.
A fianco dele normali variabili Oracle®, come ORACLE_HOME e ORACLE_SID devi impostare le seguenti variabili d’ambiente:
| Variabile | Valore |
|---|---|
|
|
|
|
|
|
Si raccomanda di impostare tutte le variabili d’ambiente in .profile. Un esempio completo:
ORACLE_BASE=/oracle; export ORACLE_BASE ORACLE_HOME=/oracle; export ORACLE_HOME LD_LIBRARY_PATH=$ORACLE_HOME/lib export LD_LIBRARY_PATH ORACLE_SID=ORCL; export ORACLE_SID ORACLE_TERM=386x; export ORACLE_TERM CLASSPATH=$ORACLE_HOME/jdbc/lib/classes111.zip export CLASSPATH PATH=/compat/linux/bin:/compat/linux/sbin:/compat/linux/usr/bin PATH=$PATH:/compat/linux/usr/sbin:/bin:/sbin:/usr/bin:/usr/sbin PATH=$PATH:/usr/local/bin:$ORACLE_HOME/bin export PATH
A causa di una leggera inconsistenza nell’emulatore Linux, devi creare una directory chiamata .oracle in /var/tmp prima di avviare l’installer. Fallo appartenere dall’utente oracle e dovresti essere in grado di installare Oracle® senza alcun problema. Se hai problemi, controlla prima la tua distribuzione e/o configurazione di Oracle®! Dopo che hai installato Oracle®, applica le patch descritte nelle prossime due sottosezioni.
Un problema frequente è che l’adattatore del protocollo TCP non è installato corretamente. Di conseguenza non puoi avviare alcun listener TCP. Le seguenti azioni aiutano a risolvere questo problema:
# cd $ORACLE_HOME/network/lib
# make -f ins_network.mk ntcontab.o
# cd $ORACLE_HOME/lib
# ar r libnetwork.a ntcontab.o
# cd $ORACLE_HOME/network/lib
# make -f ins_network.mk installNon dimenticarti di eseguire root.sh ancora!
Nell’installazione di Oracle®, alcune azioni, che vanno eseguite come root, sono registrate in uno script di shell chiamato root.sh. Questo script si trova nella directory orainst. Applica questa patch a root.sh, in modo che usi propriamente chown o, in alternativa, esegui lo script in una shell nativa di Linux.
*** orainst/root.sh.orig Tue Oct 6 21:57:33 1998 --- orainst/root.sh Mon Dec 28 15:58:53 1998 *************** *** 31,37 **** # This is the default value for CHOWN # It will redefined later in this script for those ports # which have it conditionally defined in ss_install.h ! CHOWN=/bin/chown # # Define variables to be used in this script --- 31,37 ---- # This is the default value for CHOWN # It will redefined later in this script for those ports # which have it conditionally defined in ss_install.h ! CHOWN=/usr/sbin/chown # # Define variables to be used in this script
Se non installi Oracle® dal CD, puoi aggiungere la patch al sorgente di root.sh. Si chiama rthd.sh e si trova nella directory orainst nell’albero dei sorgenti.
Lo script genclntsh viene usato per creare una singola libreria condivisa del client. Si usa quando si compilano le demo. Applica la patch seguente per decommentare la definizione di PATH:
*** bin/genclntsh.orig Wed Sep 30 07:37:19 1998 --- bin/genclntsh Tue Dec 22 15:36:49 1998 *************** *** 32,38 **** # # Explicit path to ensure that we're using the correct commands #PATH=/usr/bin:/usr/ccs/bin export PATH ! PATH=/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin export PATH # # each product MUST provide a $PRODUCT/admin/shrept.lst --- 32,38 ---- # # Explicit path to ensure that we're using the correct commands #PATH=/usr/bin:/usr/ccs/bin export PATH ! #PATH=/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin export PATH # # each product MUST provide a $PRODUCT/admin/shrept.lst
Le installazioni di sistemi SAP® usando FreeBSD non sono supportate dal team di supporto SAP® - offrono supporto solo per piattaforme certificate.
Questo documento descrive un modo possibile per installare un sistema SAP® R/3® con un database Oracle® per Linux su una macchina FreeBSD, inclusa l’installazione di FreeBSD e Oracle®. Sono descritte due diverse configurazioni:
SAP® R/3® 4.6B (IDES) con Oracle® 8.0.5 su FreeBSD 4.3-STABLE
SAP® R/3® 4.6C con Oracle® 8.1.7 su FreeBSD 4.5-STABLE
Anche se questo documento tenta di descrivere tutti i passi importanti in dettaglio, non è insteso come un sostituto delle guide di installazione di Oracle® e SAP® R/3®.
Per favore, controlla la documentazione unita all’edizione Linux di SAP® R/3® per questioni specifiche su SAP® e Oracle®, e anche le risorse da Oracle® e SAP® OSS.
Sono stati usati i seguenti CD-ROM per le installazioni di SAP®:
| Nome | Numero | Descrizione |
|---|---|---|
KERNEL | 51009113 | SAP Kernel Oracle / Installation / AIX, Linux, Solaris |
RDBMS | 51007558 | Oracle / RDBMS 8.0.5.X / Linux |
EXPORT1 | 51010208 | IDES / DB-Export / Disco 1 di 6 |
EXPORT2 | 51010209 | IDES / DB-Export / Disco 2 di 6 |
EXPORT3 | 51010210 | IDES / DB-Export / Disco 3 di 6 |
EXPORT4 | 51010211 | IDES / DB-Export / Disco 4 di 6 |
EXPORT5 | 51010212 | IDES / DB-Export / Disco 5 di 6 |
EXPORT6 | 51010213 | IDES / DB-Export / Disco 6 di 6 |
Abbiamo usato anche il CD di Oracle® 8 Server (versione preproduzione 8.0.5 per Linux, versione del kernel 2.0.33) che non è non strettamente necessario, e FreeBSD 4.3-STABLE (uscita pochi giorni dopo 4.3 RELEASE).
| Nome | Numero | Descrizione |
|---|---|---|
KERNEL | 51014004 | SAP Kernel Oracle / SAP Kernel Version 4.6D / DEC, Linux |
RDBMS | 51012930 | Oracle 8.1.7/ RDBMS / Linux |
EXPORT1 | 51013953 | Release 4.6C SR2 / Export / Disco 1 di 4 |
EXPORT1 | 51013953 | Release 4.6C SR2 / Export / Disco 2 di 4 |
EXPORT1 | 51013953 | Release 4.6C SR2 / Export / Disco 3 di 4 |
EXPORT1 | 51013953 | Release 4.6C SR2 / Export / Disco 4 di 4 |
LANG1 | 51013954 | Release 4.6C SR2 / Language / DE, EN, FR / Disco 1 di 3 |
Dipendentemente dalle lingue che vuoi installare, potrebbero essere necessari altri CD per le lingue. Qui usiamo solo DE e EN, così da utilizzare solo il primo CD per le lingue. Come piccola nota, i numeri per tutti i quattro CD EXPORT sono uguali. Tutti e tre i CD per le lingue hanno pure lo stesso numero (diversamente dalla numerazione della release 4.6B IDES). Mentre stiamo scrivendo, questa installazione sta girando su FreeBSD 4.5-STABLE (20.03.2002).
Le seguenti note dovrebbero essere lette prima di installare SAP® R/3® e dovrebbero tornare utili durante l’installazione:
| Numero | Titolo |
|---|---|
0171356 | Software SAP su Linux: Commenti Essenziali |
0201147 | INST: 4.6C R/3 Inst. su UNIX - Oracle |
0373203 | Aggiornamento / Migrazione Oracle 8.0.5 -→ 8.0.6/8.1.6 LINUX |
0072984 | Rilascio di Digital UNIX 4.0B per Oracle |
0130581 | R3SETUP passo DIPGNTAB termina |
0144978 | Il tuo sistema non è stato installato correttamente |
0162266 | Domande e suggerimenti per R3SETUP su Windows NT / W2K |
| Numero | Titolo |
|---|---|
0015023 | Inizializzazione della tabella TCPDB (RSXP0004) (EBCDIC) |
0045619 | R/3 con molti linguaggi o caratteri |
0171356 | Software SAP su Linux: Commenti Essenziali |
0195603 | RedHat 6.1 Enterprise version: Problemi Conosciuti |
0212876 | Il nuovo strumento di archiviazione SAPCAR |
0300900 | Linux: Hardware DELL Rilasciato |
0377187 | RedHat 6.2: Note importanti |
0387074 | INST: R/3 4.6C SR2 Installazione su UNIX |
0387077 | INST: R/3 4.6C SR2 Inst. su UNIX - Oracle |
0387078 | Software SAP su UNIX: Dipendenze del SO per 4.6C SR2 |
La strumentazione che segue è sufficiente per l’installazione di un sistema SAP® R/3®. Per un uso in produzione, è necessario un dimensionamento più preciso:
| Componente | 4.6B | 4.6C |
|---|---|---|
Processore | 2 x 800MHz Pentium® III | 2 x 800MHz Pentium® III |
Memoria | 1GB ECC | 2GB ECC |
Spazio sul Disco Fisso | 50-60GB (IDES) | 50-60GB (IDES) |
Per l’uso in produzione si raccomandano processori Xeon™, con una grande cache, dischi ad accesso ad alta velocità (SCSI, controller hardware RAID), sono raccomandati USV e ECC-RAM. La grande quantità di spazio sul disco fisso è dovuta al sistema IDES preconfigurato, che, durante l’installazione, crea 27 GB di file per il database. Questo spazio è sufficiente per sistemi in produzione e per i dati delle applicazioni iniziali.
È stato usato il seguente hardware in disuso: una scheda biprocessore con 2 processori Pentium® III da 800 MHz, adattatore SCSI Adaptec® 29160 Ultra160 (per accedere ad un unità nastro DLT da 40/80 GB e al CDROM), Mylex® AcceleRAID™ (2 canali, firmware 6.00-1-00 con 32 MB RAM). Al controller RAID Mylex® sono attaccati due dischi fissi da 17 GB (mirrored) e quattro dischi fissi da 36 GB (RAID 5).
Per questa installazione è stato usato un Dell™ PowerEdge™ 2500: una scheda biprocessore con due processori Pentium® III da 1000 MHz (256 kB di cache), 2 GB PC133 ECC SDRAM, controller RAID PERC/3 DC PCI con 128 MB, e un drive EIDE DVD-ROM. Al controller RAID controller sono attaccati due dischi fissi da 18 GB (mirrored) e quattro dischi fissi da 36 GB (RAID 5).
Prima devi installare FreeBSD. Ci sono molti modi per farlo, per maggiori informazioni leggi la Preparare i Propri Media di Installazione.
Per farla semplice, abbiamo usato lo stesso layout del disco sia per l’installazione di SAP® R/3® 46B che di SAP® R/3® 46C SR2. Cambiano solo i nomi dei dispositivi, dal momento che le installazioni sono state eseguite su hardware differenti (rispettivamente /dev/da e /dev/amr, così se si usa un AMI MegaRAID®, si vedrà /dev/amr0s1a invece che /dev/da0s1a):
| File system | Dimensione (1k-blocks) | Dimensione (GB) | Montato su |
|---|---|---|---|
/dev/da0s1a | 1.016.303 | 1 | / |
/dev/da0s1b | 6 | swap | |
/dev/da0s1e | 2.032.623 | 2 | /var |
/dev/da0s1f | 8.205.339 | 8 | /usr |
/dev/da1s1e | 45.734.361 | 45 | /compat/linux/oracle |
/dev/da1s1f | 2.032.623 | 2 | /compat/linux/sapmnt |
/dev/da1s1g | 2.032.623 | 2 | /compat/linux/usr/sap |
Configura in anticipo e inizializza i due drive logici con il software Mylex® o PERC/3 RAID. Il software può essere lanciato durante la fase di avvio del BIOS.
Nota che il layout di questo disco differisce leggermente dalle raccomandazioni di SAP®, giacché SAP® suggerisce di montare le sottodirectory di Oracle® (e qualche altra) separatamente - abbiamo deciso di crearle come vere sottodirectory per semplicità.
make world e il Nuovo KernelScarica gli ultimi sorgenti -STABLE. Ricompila world e il tuo kernel personalizzato dopo averne modificato il file di configurazione. In questo dovresti includere anche i parametri del kernel che sono richiesti sia per SAP® R/3® che per Oracle®.
Per primo bisogna installare il port linux_base (come root):
# cd /usr/ports/emulators/linux_base
# make install distcleanÈ richiesto l’ambiente di sviluppo di linux, se vuoi installare Oracle® su FreeBSD secondo la Installazione di Oracle®:
# cd /usr/ports/devel/linux_devtools
# make install distcleanL’ambiente di sviluppo di Linux è stato installato solo durante l’installazione di SAP® R/3® 46B IDES. Non è necessario, se Oracle® DB non è ricollegata sul sistema FreeBSD. Questo è il caso se stai usando il tarball di Oracle® da un sistema Linux.
Per avviare il programma R3SETUP, c’è bisogno del supporto PAM. Durante la prima installazione di SAP® su FreeBSD 4.3-STABLE abbiamo tentato di installare PAM con tutti i pacchetti richiesti: alla fine abbiamo forzato l’installazione del pacchetto di PAM, ed ha funzionato. Per SAP® R/3® 4.6C SR2 abbiamo subito forzato l’installazione degli RPM di PAM, ed ha pure funzionato, sembra quindi che i pacchetti dipendenti non siano necessari:
# rpm -i --ignoreos --nodeps --root /compat/linux --dbpath /var/lib/rpm \
pam-0.68-7.i386.rpmPer fare in modo che Oracle® 8.0.5 avvii l’intelligent agent, dobbiamo anche installare il paccheto Tcl di RedHat tcl-8.0.5-30.i386.rpm (altrimenti il ricollegamento durante l’installazione di Oracle® non funzionerà). Ci sono altri punti riguardanti il ricollegamento di Oracle®, ma è un problema di Oracle® per Linux, non specifico di FreeBSD.
Potrebbe essere una buona idea aggiungere linprocfs a /etc/fstab, per maggiori informazioni guarda la pagina del manuale di linprocfs(5). Un altro parametro da impostare è kern.fallback_elf_brand=3, da fare nel file /etc/sysctl.conf.
Per una installazione semplice è sufficiente creare i seguenti file system:
| punto di mount | dimensione in GB |
|---|---|
/compat/linux/oracle | 45 GB |
/compat/linux/sapmnt | 2 GB |
/compat/linux/usr/sap | 2 GB |
È necessario anche creare qualche collegamento, altrimenti l’installer di SAP® si lamenterà, perché controlla i collegamenti creati:
# ln -s /compat/linux/oracle /oracle
# ln -s /compat/linux/sapmnt /sapmnt
# ln -s /compat/linux/usr/sap /usr/sapPossibili messaggi d’errore durante l’installazione (qui con il sistema PRD e l’installazione di SAP® R/3® 4.6C SR2):
INFO 2002-03-19 16:45:36 R3LINKS_IND_IND SyLinkCreate:200
Checking existence of symbolic link /usr/sap/PRD/SYS/exe/dbg to
/sapmnt/PRD/exe. Creating if it does not exist...
WARNING 2002-03-19 16:45:36 R3LINKS_IND_IND SyLinkCreate:400
Link /usr/sap/PRD/SYS/exe/dbg exists but it points to file
/compat/linux/sapmnt/PRD/exe instead of /sapmnt/PRD/exe. The
program cannot go on as long as this link exists at this
location. Move the link to another location.
ERROR 2002-03-19 16:45:36 R3LINKS_IND_IND Ins_SetupLinks:0
can not setup link '/usr/sap/PRD/SYS/exe/dbg' with content
'/sapmnt/PRD/exe'SAP® R/3® ha bisogno di due utenti e tre gruppi. I nomi degli utenti dipendono dal SAP® system ID (SID) che consta di tre lettere. Alcuni di questi SID sono riservati da SAP® (per esempio SAP e NIX. Per una lista completa controlla la documentazione SAP®). Per l’installazione di IDES abbiamo usato IDS, per l’installazione di 4.6C SR2 PRD, poiché quel sistema è inteso per l’uso in produzione. Abbiamo quindi i seguenti gruppi (gli ID dei gruppi potrebbero differire, questi sono solo i valori che abbiamo usato nella nostra installazione):
| ID del gruppo | nome del gruppo | descrizione |
|---|---|---|
100 | dba | Amministratore del Database |
101 | sapsys | Sistema SAP® |
102 | oper | Operatore del Database |
In una installazione normale di Oracle®, si usa solo il gruppo dba. Come gruppo oper, si usa anche il gruppo dba (per maggiori informazioni, vedi la documentazione di Oracle® e di SAP®).
Abbiamo bisogno anche dei seguenti utenti:
| ID utente | nome utente | nome generico | gruppo | gruppi addizionali | descrizione |
|---|---|---|---|---|---|
1000 | idsadm/prdadm | sidadm | sapsys | oper | Amministratore SAP® |
1002 | oraids/oraprd | orasid | dba | oper | Amministratore Oracle® |
Aggiungere gli utenti con adduser(8) richiede l’inserimento di questo per l'"Amministratore SAP®" (notare la shell e la directory home):
Name: sidadm Password: ****** Fullname: SAP Administrator SID Uid: 1000 Gid: 101 (sapsys) Class: Groups: sapsys dba HOME: /home/sidadm Shell: bash (/compat/linux/bin/bash)
e per l'"Amministratore Oracle®":
Name: orasid Password: ****** Fullname: Oracle Administrator SID Uid: 1002 Gid: 100 (dba) Class: Groups: dba HOME: /oracle/sid Shell: bash (/compat/linux/bin/bash)
Questo dovrebbe includere anche il gruppo oper nel caso tu stia usando entrambi i gruppi dba e oper.
Queste directory solitamente sono create come file system separati, dipende esclusivamente dalle tue necessità. Noi abbiamo scelto di crearle come semplici directory, dal momento che, comunque, si trovano sullo stesso RAID 5:
Prima impostiamo le appartenenze ed i diritti per alcune directory (come utente root):
# chmod 775 /oracle
# chmod 777 /sapmnt
# chown root:dba /oracle
# chown sidadm:sapsys /compat/linux/usr/sap
# chmod 775 /compat/linux/usr/sapSuccessivamente creiamo le directory come utente orasid. Queste saranno tutte le sottodirectory di /oracle/SID:
# su - orasid
# cd /oracle/SID
# mkdir mirrlogA mirrlogB origlogA origlogB
# mkdir sapdata1 sapdata2 sapdata3 sapdata4 sapdata5 sapdata6
# mkdir saparch sapreorg
# exitPer l’installazione di Oracle® 8.1.7 sono necessarie alcune altre directory:
# su - orasid
# cd /oracle
# mkdir 805_32
# mkdir client stage
# mkdir client/80x_32
# mkdir stage/817_32
# cd /oracle/SID
# mkdir 817_32La directory client/80x_32 è usata esattamente con questo nome. Non rimpiazzare la x con dei numeri o altro. |
Nel terzo passo creiamo le directory come sidadm:
# su - sidadm
# cd /usr/sap
# mkdir SID
# mkdir trans
# exitSAP® R/3® richiede alcune definizioni nel file /etc/services, che non sono impostate correttamente durante l’installazione sotto FreeBSD. Aggiungi le seguenti righe (hai bisogno almeno di queste definizioni, corrispondenti al numero di istanza - in questo caso, 00. Non fa danni aggiungere tutte le definizioni da 00 a 99 per dp, gw, sp e ms). Se userai un SAProuter o avrai bisogno di accedere a SAP® OSS, hai bisogno di 99, dal momento che la porta 3299 è normalmente utilizzata per il processo SAProuter sul sistema target:
sapdp00 3200/tcp # SAP Dispatcher. 3200 + Instance-Number sapgw00 3300/tcp # SAP Gateway. 3300 + Instance-Number sapsp00 3400/tcp # 3400 + Instance-Number sapms00 3500/tcp # 3500 + Instance-Number sapmsSID 3600/tcp # SAP Message Server. 3600 + Instance-Number sapgw00s 4800/tcp # SAP Secure Gateway 4800 + Instance-Number
SAP® richiede almeno due internazionalizzazioni che non fanno parte dell’installazione standard di RedHat. SAP® offre gli RPM richiesti, scaricabili dal loro server FTP (che è accessibile solo se sei un cliente con accesso OSS). Vedi la nota 0171356 per una lista degli RPM di cui hai bisogno.
È pure possibile creare solamente i collegamenti appropriati (per esempio da de_DE e en_US ), ma non lo raccomandiamo per un sistema in produzione (anche se ha funzionato con il sistema IDES senza alcun problema). Le seguenti internazionalizzazioni sono necessarie:
de_DE.ISO-8859-1 en_US.ISO-8859-1
Crea i collegamenti come questi:
# cd /compat/linux/usr/shared/locale
# ln -s de_DE de_DE.ISO-8859-1
# ln -s en_US en_US.ISO-8859-1Se non sono presenti, ci sarà qualche problema durante l’installazione. Se vengono ignorati (impostando STATUS dei punti con errore a OK nel file CENTRDB.R3S), sarà impossibile autenticarsi nel sistema SAP® senza qualche ulteriore sforzo.
I sistemi SAP® R/3® necessitano di molte risorse. Di conseguenza abbiamo aggiunto i seguenti parametri al file di configurazione del kernel:
# Set these for memory pigs (SAP and Oracle): options MAXDSIZ="(1024*1024*1024)" options DFLDSIZ="(1024*1024*1024)" # System V options needed. options SYSVSHM #SYSV-style shared memory options SHMMAXPGS=262144 #max amount of shared mem. pages #options SHMMAXPGS=393216 #use this for the 46C inst.parameters options SHMMNI=256 #max number of shared memory ident if. options SHMSEG=100 #max shared mem.segs per process options SYSVMSG #SYSV-style message queues options MSGSEG=32767 #max num. of mes.segments in system options MSGSSZ=32 #size of msg-seg. MUST be power of 2 options MSGMNB=65535 #max char. per message queue options MSGTQL=2046 #max amount of msgs in system options SYSVSEM #SYSV-style semaphores options SEMMNU=256 #number of semaphore UNDO structures options SEMMNS=1024 #number of semaphores in system options SEMMNI=520 #number of semaphore identifiers options SEMUME=100 #number of UNDO keys
I valori minimi sono specificati nella documentazione fornita con SAP®. Dal momento che non v’è alcuna descrizione per Linux, vedi nella sezione HP-UX (32-bit) per ulteriori informazioni. Siccome il sistema per l’installazione di 4.6C SR2 ha più memoria principale, il segmento condiviso può essere più grande sia per SAP® che per Oracle®, quindi scegli un numero maggiore di pagine di memoria condivisa.
Con l’installazione di default di FreeBSD su i386™, lascia |
Ci sono molti CD-ROM da montare e smontare durante l’installazione. Ad avere abbastanza drive CD-ROM, puoi montarli tutti. Abbiamo deciso di copiare i contenuti dei CD-ROM nelle directory corrispondenti:
/oracle/SID/sapreorg/cd-name
dove cd-name era uno tra KERNEL, RDBMS, EXPORT1, EXPORT2, EXPORT3, EXPORT4, EXPORT5 e EXPORT6 per l’installazione di 4.6B/IDES, e KERNEL, RDBMS, DISK1, DISK2, DISK3, DISK4 e LANG per l’installazione di 4.6C SR2. Tutti i nomi dei file sui CD montati dovrebbero essere in lettere maiuscole. In caso contrario usa l’opzione -g per montare, cioè usa questi comandi:
# mount_cd9660 -g /dev/cd0a /mnt
# cp -R /mnt/* /oracle/SID/sapreorg/cd-name
# umount /mntPer prima cosa devi creare una directory install:
# cd /oracle/SID/sapreorg
# mkdir install
# cd installQuindi viene lanciato lo script di installazione, che copia quasi tutti i file rilevanti dentro alla directory install:
# /oracle/SID/sapreorg/KERNEL/UNIX/INSTTOOL.SHL’installazione (4.6B) è data con un sistema di dimostrazione SAP® R/3® completamente personalizzato, per questo ci sono sei CD EXPORT invece che tre. A questo punto il modello CENTRDB.R3S serve per l’installazione di una istanza centrale standard (R/3® e database), non l’instanza centrale IDES, quindi bisogna copiare il corrispondente CENTRDB.R3S dalla directory EXPORT1, altrimenti R3SETUP chiederà solo tre CD EXPORT.
La nuova distribuzione di SAP® 4.6C SR2 viene venduta con quattro CD EXPORT. Il file che controlla i passi dell’installazione è CENTRAL.R3S. Contrariamente alle versioni precedenti non ci sono modelli di installazione per una istanza centrale con o senza database. SAP® usa un modello diverso per l’installazione del database. Per riavviare l’installazione in un secondo momento, è comunque sufficiente riavviare con il file originale.
Durante e dopo l’installazione, SAP® richiede hostname per restituire solamente il nome del computer, non il nome completo del dominio. Quindi imposta l’hostname in questo modo, oppure imposta un alias con alias hostname='hostname -s' per entrambi orasid e sidadm (e per root almeno per i punti eseguiti come root). È anche possibile modificare i file .profile e .login installati di entrambi gli utenti creati durante l’installazione di SAP®.
R3SETUP 4.6BAssicurati che LD_LIBRARY_PATH sia impostato correttamente:
# export LD_LIBRARY_PATH=/oracle/IDS/lib:/sapmnt/IDS/exe:/oracle/805_32/libAvvia R3SETUP come root dalla directory di installazione:
# cd /oracle/IDS/sapreorg/install
# ./R3SETUP -f CENTRDB.R3SLo script, quindi, fa alcune domande (i default sono tra parentesi, seguite dal vero input):
| Domanda | Default | Input |
|---|---|---|
Enter SAP System ID | [C11] | IDSEnter |
Enter SAP Instance Number | [00] | Enter |
Enter SAPMOUNT Directory | [/sapmnt] | Enter |
Enter name of SAP central host | [troubadix.domain.de] | Enter |
Enter name of SAP db host | [troubadix] | Enter |
Select character set | [1] (WE8DEC) | Enter |
Enter Oracle server version (1) Oracle 8.0.5, (2) Oracle 8.0.6, (3) Oracle 8.1.5, (4) Oracle 8.1.6 | 1Enter | |
Extract Oracle Client archive | [1] (Yes, extract) | Enter |
Enter path to KERNEL CD | [/sapcd] | /oracle/IDS/sapreorg/KERNEL |
Enter path to RDBMS CD | [/sapcd] | /oracle/IDS/sapreorg/RDBMS |
Enter path to EXPORT1 CD | [/sapcd] | /oracle/IDS/sapreorg/EXPORT1 |
Directory to copy EXPORT1 CD | [/oracle/IDS/sapreorg/CD4_DIR] | Enter |
Enter path to EXPORT2 CD | [/sapcd] | /oracle/IDS/sapreorg/EXPORT2 |
Directory to copy EXPORT2 CD | [/oracle/IDS/sapreorg/CD5_DIR] | Enter |
Enter path to EXPORT3 CD | [/sapcd] | /oracle/IDS/sapreorg/EXPORT3 |
Directory to copy EXPORT3 CD | [/oracle/IDS/sapreorg/CD6_DIR] | Enter |
Enter path to EXPORT4 CD | [/sapcd] | /oracle/IDS/sapreorg/EXPORT4 |
Directory to copy EXPORT4 CD | [/oracle/IDS/sapreorg/CD7_DIR] | Enter |
Enter path to EXPORT5 CD | [/sapcd] | /oracle/IDS/sapreorg/EXPORT5 |
Directory to copy EXPORT5 CD | [/oracle/IDS/sapreorg/CD8_DIR] | Enter |
Enter path to EXPORT6 CD | [/sapcd] | /oracle/IDS/sapreorg/EXPORT6 |
Directory to copy EXPORT6 CD | [/oracle/IDS/sapreorg/CD9_DIR] | Enter |
Enter amount of RAM for SAP + DB | 850Enter (in Megabytes) | |
Service Entry Message Server | [3600] | Enter |
Enter Group-ID of sapsys | [101] | Enter |
Enter Group-ID of oper | [102] | Enter |
Enter Group-ID of dba | [100] | Enter |
Enter User-ID of sidadm | [1000] | Enter |
Enter User-ID of orasid | [1002] | Enter |
Number of parallel procs | [2] | Enter |
Se non hai copiato i CD in posizioni diverse, l’installer di SAP® non può tyrovare i CD necessari (identificati dal file LABEL.ASC sul CD) e quindi ti chiederà di inserire e montare il CD e di confermare o di inserire il path al mount.
CENTRDB.R3S potrebbe non essere scevro di errori. Nel nostro caso, ha richiesto il CD EXPORT4 un’altra volta ma indicando la chiave corretta (6_LOCATION, quindi 7_LOCATION, ecc.), così bisogna continuare ad inserire i valori corretti.
A parte alcuni problemi sopra menzionati, ogni cosa dovrebbe andare bene fino al punto dove bisogna installare il database Oracle®.
R3SETUP 4.6C SR2Assicurati che LD_LIBRARY_PATH sia impostato correttamente. Ha un valore diverso dall’installazione di 4.6B con Oracle® 8.0.5:
# export LD_LIBRARY_PATH=/sapmnt/PRD/exe:/oracle/PRD/817_32/libAvvia R3SETUP come root dalla directory di installazione:
# cd /oracle/PRD/sapreorg/install
# ./R3SETUP -f CENTRAL.R3SLo script, quindi, fa alcune domande (i default sono tra parentesi, seguite dal vero input):
| Domanda | Default | Input |
|---|---|---|
Enter SAP System ID | [C11] | PRDEnter |
Enter SAP Instance Number | [00] | Enter |
Enter SAPMOUNT Directory | [/sapmnt] | Enter |
Enter name of SAP central host | [majestix] | Enter |
Enter Database System ID | [PRD] | PRDEnter |
Enter name of SAP db host | [majestix] | Enter |
Select character set | [1] (WE8DEC) | Enter |
Enter Oracle server version (2) Oracle 8.1.7 | 2Enter | |
Extract Oracle Client archive | [1] (Yes, extract) | Enter |
Enter path to KERNEL CD | [/sapcd] | /oracle/PRD/sapreorg/KERNEL |
Enter amount of RAM for SAP + DB | 2044 | 1800Enter (in Megabytes) |
Service Entry Message Server | [3600] | Enter |
Enter Group-ID of sapsys | [100] | Enter |
Enter Group-ID of oper | [101] | Enter |
Enter Group-ID of dba | [102] | Enter |
Enter User-ID of | [1002] | Enter |
Enter User-ID of | [1000] | Enter |
LDAP support | 3Enter (no support) | |
Installation step completed | [1] (continue) | Enter |
Choose installation service | [1] (DB inst,file) | Enter |
Al momento la creazione degli utenti genera un errore durante l’installazione nelle fasi OSUSERDBSID_IND_ORA (nel creare l’utente orasid) e OSUSERSIDADM_IND_ORA (nel creare l’utente sidadm).
A parte qualche problema descritto sopra, tutto dovrebbe andare liscio fino al punto dove bisogna installare il database Oracle®.
Per favore, leggi le corrispondenti note di SAP® e i Readme di Oracle® riguardanti Linux e Oracle® DB per possibili problemi. Molti, se non tutti, i problemi nascono da librerie incompatibili.
Per maggiori informazioni riguardo all’installazione di Oracle®, riferirsi al capitolo Installare Oracle®.
orainstSe bisogna usare Oracle® 8.0.5, sono richeste alcune librerie in più per un ricollegamento funzionante, perché Oracle® 8.0.5 è stata collegata con una vecchia glibc (RedHat 6.0), anche se RedHat 6.1 già usa una nuova glibc. Per questo devi installare i seguenti pacchetti per essere sicuro che il collegamento funzioni:
compat-libs-5.2-2.i386.rpm
compat-glibc-5.2-2.0.7.2.i386.rpm
compat-egcs-5.2-1.0.3a.1.i386.rpm
compat-egcs-c++-5.2-1.0.3a.1.i386.rpm
compat-binutils-5.2-2.9.1.0.23.1.i386.rpm
Per maggiori informazioni, leggi le corrispondenti note di SAP® o i Readme di Oracle®. Se non hai questa opzione (al momento dell’installazione non abbiamo avuto abbastanza tempo per controllare), si possono usare i binari originali, oppure usare i binari ricollegati da un sistema RedHat originale.
Per compilare l’intelligent agent, bisogna installare il pacchetto Tcl di RedHat. Se non puoi recuperare tcl-8.0.3-20.i386.rpm, dovrebbe funzionare uno più nuovo come tcl-8.0.5-30.i386.rpm da RedHat 6.1.
A parte il ricollegamento, l’installazione è diretta:
# su - oraids
# export TERM=xterm
# export ORACLE_TERM=xterm
# export ORACLE_HOME=/oracle/IDS
# cd $ORACLE_HOME/orainst_sap
# ./orainstConferma tutti i comandi con Enter fino a che il software non è installato, a parte il Oracle® On-Line Text Viewer, che non è disponibile per Linux. Oracle®, quindi, si ricolleghi con i386-glibc20-linux-gcc invece dei disponibili gcc, egcs o i386-redhat-linux-gcc.
A causa di limitazioni di tempo, abbiamo deciso di usare i binari da una distribuzione di Oracle® 8.0.5 PreProduction, dopo il primo tentativo, fallito, di far funzionare la versione dal CD del RDBMS, e trovare e accedere agli RPM corretti era un incubo in quel momento.
Questa installazione è piuttosto semplice. Monta il CD e avvia l’installer. Ti chiederà l’ubicazione della directory home di Oracle® e vi copierà i file. Noi, comunque, Non abbiamo cancellato ciò che è rimasto dei precedenti tentativi di installazione del RDBMS.
Subito dopo, il database Oracle® può essere lanciato senza problemi.
Prendi il tarball oracle81732.tgz che hai prodotto dalla directory di installazione su un sistema Linux e estrailo in /oracle/SID/817_32/.
Prima controlla le impostazioni d’ambiente degli utenti idsamd (sidadm) e oraids (orasid). Ora dovrebbero avere i file .profile, .login e .cshrc che usano tutti hostname. Nel caso l’hostname del sistema sia il nome completamente qualificato, devi cambiare hostname in hostname -s dentro a tutti i file.
Dopo di ciò, R3SETUP può essere riavviato o continuato (a seconda che se ne sia usciti o no). R3SETUP, quindi, crea le tabelle e carica i dati nel database con R3load (per 46B IDES, da EXPORT1 a EXPORT6, per 46C da DISK1 a DISK4).
Quando il caricamento del database è finito (potrebbe richiedere qualche ora), vengono richieste alcune password. Per installazioni di prova, si possono usare le ben note password di default (usane di diverse se la sicurezza è un problema!):
| Domanda | Input |
|---|---|
Enter Password for sapr3 | sapEnter |
Confirum Password for sapr3 | sapEnter |
Enter Password for sys | change_on_installEnter |
Confirm Password for sys | change_on_installEnter |
Enter Password for system | managerEnter |
Confirm Password for system | managerEnter |
A questo punto abbiamo avuto qualche problema con dipgntab durante l’installazione di 4.6B.
Avvia il listener di Oracle® come utente orasid come segue:
% umask 0; lsnrctl startAltrimenti potresti incorrere nell’errore ORA-12546 poiché i socket non hanno i permessi giusti. Vedi la nota di SAP® 072984.
Se pensi di importare le lingue non-Latin-1 nel sistema SAP®, devi aggiornare le tabelle Multi National Language Support. Questo è descritto nelle note di SAP® OSS 15023 e 45619. Altrimenti puoi saltare questa domanda durante l’installazione di SAP®.
Se non hai bisogno del MNLS, è comunque necessario controllare la tabella TCPDB e inizializzarla se ancora non è stato fatto. Per maggiori informazioni, vedi le note di SAP® 0015023 e 0045619. |
Devi richiedere la tua chiave di licenza per SAP® R/3®. È necessaria, dal momento che la licenza temporanea che è stata usata durante l’installazione era valida solo per quattro settimane. Prima di tutto recupera la chiave hardware. Autenticati come utente idsadm e lancia saplicense:
# /sapmnt/IDS/exe/saplicense -getLanciando saplicense senza paramentri, viene restituita una lista di opzioni. Quando si riceve la chiave di licenza, può essere installata usando:
# /sapmnt/IDS/exe/saplicense -installTi viene richiesto di inserire i seguenti valori:
SAP SYSTEM ID = SID, 3 chars CUSTOMER KEY = hardware key, 11 chars INSTALLATION NO = installation, 10 digits EXPIRATION DATE = yyyymmdd, usually "99991231" LICENSE KEY = license key, 24 chars
Crea un utente dentro il client 000 (richiesto per qualche azione da eseguire dentro al client 000, ma con un utente diverso dagli utenti sap* e ddic). Come nome utente, noi solitamente scegliamo wartung (o servizio in italiano). I profili richiesti sono sap_new e sap_all. Per maggiore sicurezza, le password degli utenti di default dentro a tutti i client dovrebbero essere cambiate (compresi gli utenti sap* e ddic).
Dentro al client 000, per gli utenti diversi da ddic e sap*, fai almeno questo:
| Azione | Transazione |
|---|---|
Configura il Sistema di Trasporto, p.e. come Stand-Alone Transport Domain Entity | STMS |
Crea / Modifica il Profilo per il Sistema | RZ10 |
Controlla le Istanze e i Modi di Operare | RZ04 |
Questi e tutti gli altri punti dopo l’installazione sono estesamente descritti nelle guide di installazione di SAP®.
Il file /oracle/IDS/dbs/initIDS.sap contiene il profilo di backup di SAP®. Qui la dimensione del nastro da usare, il tipo di compressione e tutto il resto sono da definire. Per farlo funzionare con sapdba / brbackup, abbiamo cambiato i seguenti valori:
compress = hardware archive_function = copy_delete_save cpio_flags = "-ov --format=newc --block-size=128 --quiet" cpio_in_flags = "-iuv --block-size=128 --quiet" tape_size = 38000M tape_address = /dev/nsa0 tape_address_rew = /dev/sa0
Spiegazioni:
compress: Il nastro che usiamo è un HP DLT1 che ha compressione hardware .
archive_function: Questa definisce il comportamento normale per salvare i log dell’archivio di Oracle®: i nuovi file di log sono salvati sul nastro, quelli già salvati sono salvati ancora e poi cancellati. Questo previene molti problemi se devi recuperare il database e uno dei nastri d’archivio si è rovinato.
cpio_flags: Di default si usa -B che imposta la dimensione dei blocchi a 5120 Bytes. Per i nastri DLT, HP raccomanda una dimensione dei blocchi di almeno 32 K, per cui abbiamo usato --block-size=128 per 64 K. --format=newc è necessaria perché abbiamo un numero di inode maggiore di 65535. L’ultima opzione --quiet è necessaria perché altrimenti brbackup si lamenta non appena cpio restituisce il numero di blocchi salvato.
cpio_in_flags: Etichetta necessaria per caricare i dati dal nastro. Il formato è riconosciuto automaticamente.
tape_size: Solitamente questo indica la capacità di archiviazione del nastro. Per ragioni di sicurezza (usiamo la compressione hardware), il valore è leggermente più bassp del valore reale.
tape_address: Il dispositivo non riavvolgibile da usare con cpio.
tape_address_rew: Il dispositivo riavvolgibile da usare con cpio.
I seguenti parametri di SAP® dovrebbero essere rivisti dopo l’installazione (esempi per IDES 46B, con 1 GB di memoria):
| Nome | Valore |
|---|---|
ztta/roll_extension | 250000000 |
abap/heap_area_dia | 300000000 |
abap/heap_area_nondia | 400000000 |
em/initial_size_MB | 256 |
em/blocksize_kB | 1024 |
ipc/shm_psize_40 | 70000000 |
Nota SAP® 0013026:
| Nome | Valore |
|---|---|
ztta/dynpro_area | 2500000 |
Nota SAP® 0157246:
| Nome | Valore |
|---|---|
rdisp/ROLL_MAXFS | 16000 |
rdisp/PG_MAXFS | 30000 |
Con i parametri descritti, su un sistema con 1 gigabyte di memoria, si troverà un consumo di memoria simile a: Mem: 547M Active, 305M Inact, 109M Wired, 40M Cache, 112M Buf, 3492K Free |
R3SETUP dopo la Risoluzione di un ProblemaR3SETUP si ferma se incorre in un errore. Se hai guardato al file di log corrispondente e corretto l’errore, devi riavviare R3SETUP, solitamente selezionando REPEAT come opzione per l’ultimo passo per cui R3SETUP si è lamentato.
Per riavviare R3SETUP, avvialo con il corrispondente file R3S:
# ./R3SETUP -f CENTRDB.R3Sper 4.6B, oppure con
# ./R3SETUP -f CENTRAL.R3Sper 4.6C, non importa che errore sia accaduto con CENTRAL.R3S o DATABASE.R3S.
In alcuni punti, Non dimenticarti di avviare ancora il listener di Oracle® (come |
R3SETUPSe R3SETUP si lamentasse a questo punto, modifica il file modello R3SETUP usato prima (CENTRDB.R3S (4.6B) o anche CENTRAL.R3S o DATABASE.R3S (4.6C)). Individua [OSUSERSIDADM_IND_ORA] o cerca solo la definizione STATUS=ERROR e modificala con i seguenti valori:
HOME=/home/sidadm (era vuota) STATUS=OK (era uguale a ERROR)
Quindi puoi riavviare ancora R3SETUP.
R3SETUPR3SETUP potrebbe anche lamentarsi a questo punto. L’errore, qui, è simile a quello nella fase OSUSERSIDADM_IND_ORA. Modifica il file modello R3SETUP usato allora (CENTRDB.R3S (4.6B) oppure CENTRAL.R3S o DATABASE.R3S (4.6C)). Individua [OSUSERDBSID_IND_ORA] o cerca solo la definizione STATUS=ERROR e modifica questi valori in quella sezione:
STATUS=OK
Riavvia, quindi, R3SETUP.
oraview.vrf FILE NOT FOUND Durante l’Installazione di Oracle®Non hai deselezionato Oracle® On-Line Text Viewer prima di cominciare l’installazione. Questo è contrassegnato per l’installazine anche se l’opzione non è disponibile per Linux. Deseleziona questo prodotto nel menù di installazione di Oracle® e riavvia l’installazione.
TEXTENV_INVALID Durante R3SETUP, RFC o l’Avvio di SAPguiSe si incorre in questo errore, allora manca la corretta internazionalizzazione. La nota di SAP® 0171356 elenca gli RPM necessari da installare (p.e. saplocales-1.0-3, saposcheck-1.0-1 per RedHat 6.1). Nel caso tu abbia ignorato tutti i relativi errori ed impostato lo STATUS corrispondente da ERROR a OK (in CENTRDB.R3S) ogni volta che R3SETUP si è lamentato e riavviato R3SETUP, il sistema SAP® non sarà configurato correttamente e non sarai in grado di connetterti al sistema tramite una SAPgui, anche se il sistema può essere avviato. Provando a connetterci con la vecchia SAPgui abbiamo avuto questi messaggi:
Sat May 5 14:23:14 2001 *** ERROR => no valid userarea given [trgmsgo. 0401] Sat May 5 14:23:22 2001 *** ERROR => ERROR NR 24 occured [trgmsgi. 0410] *** ERROR => Error when generating text environment. [trgmsgi. 0435] *** ERROR => function failed [trgmsgi. 0447] *** ERROR => no socket operation allowed [trxio.c 3363] Speicherzugriffsfehler
Questo comportamento è imputabile a SAP® R/3® che non è in grado di assegnare correttamente una internazionalizzazione e che non è ben configurato (definizioni mancanti in alcune tabelle del database). Per essere in grado di connettersi a SAP®, aggiungi queste definizioni nel file DEFAULT.PFL (vedi nota 0043288):
abap/set_etct_env_at_new_mode = 0 install/collate/active = 0 rscp/TCP0B = TCP0B
Riavvia il sistema SAP®. Ora puoi connetterti al sistema, anche se le impostazioni della lingua specifiche per il paese potrebbero non funzionare come desiderato. Dopo aver corretto le impostazioni del paese (e aver fornito le internazionalizzazioni esatte), queste definizioni possono essere riomsse da DEFAULT.PFL e il sistema SAP® può essere riavviato.
Questo errore è accaduto solo con Oracle® 8.1.7 su FreeBSD. La ragione era che il database Oracle® non poteva inizializzarsi correttamente e andava in crash, lasciando i semafori e la memoria condivisa sul sistema. Il tentativo successivo di lanciare il database, ritornava ORA-00001.
Trovali con ipcs -a e rimuovili con ipcrm.
Questo errore è accaduto con Oracle® 8.1.7. Viene riportato se il database è avviato con il solito script startsap (per esempio startsap_majestix_00) come utente prdadm.
Un modo per aggirarlo è lanciare il database come utente oraprd, con svrmgrl:
% svrmgrl
SVRMGR> connect internal;
SVRMGR> startup;
SVRMGR> exitAvvia il listener di Oracle® come utente oraids con i seguenti comandi:
# umask 0; lsnrctl startAltrimenti potresti ottenere ORA-12546 poiché i socket non hanno i permessi corretti. Vedi la nota di SAP® 0072984.
Questo errore è accaduto mentre tentavamo di usare i valori per MAXDSIZ e DFLDSIZ maggiori di 1 GB (1024x1024x1024). In più ci siamo ritrovati Linux Error 12: Cannot allocate memory.
R3SETUPIn generale, vedi la nota di SAP® 0130581 (il punto R3SETUP termina DIPGNTAB). Per qualche ragione, durante l’installazione specifica per IDES, il processo di installazione non usava il giusto nome "IDS" del sistema SAP®, ma piuttosto la stringa vuota "". Questo porta a qualche piccolo problema con l’accesso alle directory, dal momento che i path sono generati dinamicamente usando SID (in questo caso IDS). Quindi, invece di accedere a:
/usr/sap/IDS/SYS/... /usr/sap/IDS/DVMGS00
venivano usati questi path:
/usr/sap//SYS/... /usr/sap/D00
Per continuare con l’installazione, abbiamo creato un collegamento e una direcotry addizionale:
# pwd
/compat/linux/usr/sap
# ls -l
total 4
drwxr-xr-x 3 idsadm sapsys 512 May 5 11:20 D00
drwxr-x--x 5 idsadm sapsys 512 May 5 11:35 IDS
lrwxr-xr-x 1 root sapsys 7 May 5 11:35 SYS -> IDS/SYS
drwxrwxr-x 2 idsadm sapsys 512 May 5 13:00 tmp
drwxrwxr-x 11 idsadm sapsys 512 May 4 14:20 transAbbiamo trovato note di SAP® che descrivono questo comportamento (0029227 e 0008401). Non siamo incorsi in alcuno di questi problemi installando SAP® 4.6C.
R3SETUPDurante l’installazione di SAP® 4.6C, questo errore era la conseguenza di un altro errore avvenuto in precedenza. In questo caso, controlla nei file di log e correggi il vero problema.
Se dopo aver guardato nei log questo errore è effettivamente quello corretto (controlla le note di SAP®), puoi impostare lo STATUS dei punti sbagliati da ERROR a OK (file CENTRDB.R3S) e riavviare R3SETUP. Dopo l’installazione, devi eseguire il rapporto RSWBOINS dalla transazione SE38. Per maggiori informazioni sulle fasi RFCRSWBOINI e RFCRADDBDIF, vedi la nota di SAP® 0162266.
R3SETUPQui si applicano le stesse restrizioni: assicurati di controllare nei file di log che questo errore non sia causato da qualche problema precedente.
Se puoi confermare ciò che dice la nota 0162266 di SAP®, imposta lo STATUS del punto errato da ERROR a OK (file CENTRDB.R3S) e riavvia R3SETUP. Dopo l’installazione, devi eseguire il rapporto RADDBDIF dalla transazione SE38.
Questo errore è avvenuto all’avvio dei processi SAP®disp+work. Se si sta avviando SAP® con lo script startsap, i sottoprocessi avviati si staccano e fanno il lavoro sporco di avviare tutti gli altri processi SAP®. Come risultato, lo script stesso non noterà se qualcosa sia andato storto.
Per controllare se i processi SAP® non sono partiti correttamente, dai un’occhiata al loro stato con ps ax | grep SID, che ti darà una lista di tutti i processi Oracle® e SAP®. Se ti sembra che qualche processo manchi o se non puoi connetterti al sistema SAP®, guarda nei log corrispondenti che possono essere trovati in /usr/sap/SID/DVEBMGSnr/work/. I file in cui guardare sono dev_ms e dev_disp.
Il segnale 31 avviene qui se la quantità di memoria condivisa utilizzata da Oracle® e SAP® supera quella definita nel file di configurazione del kernel e può essere risolto usando un valore maggiore:
# larger value for 46C production systems: options SHMMAXPGS=393216 # smaller value sufficient for 46B: #options SHMMAXPGS=262144
saposcolCi sono alcuni problemi con il programma saposcol (versione 4.6D). Il sistema SAP® usa saposcol per raccogliere dati a proposito delle prestazioni del sistema. Questo programma non è necessario per usare il sistema SAP®, quindi può essere considerato un problema minore. La versione più vecchia (4.6B) funziona, ma non raccoglie tutti i dati (molte chiamate ritorneranno 0, per esempio l’utilizzo della CPU).
Se sei curioso di come funziona la compatibilità con i binari di Linux, questa è la sezione da leggere. Molto di ciò che segue è basato pesantemente su una email scritta a mailing list di chiacchiere su FreeBSD da Terry Lambert tlambert@primenet.com (ID del messaggio: <199906020108.SAA07001@usr09.primenet.com>).
FreeBSD ha una astrazione chiamata un "loader della classe di esecuzione". Questo ` un cuneo nella chiamata di sistema execve(2).
Cosa succede è che FreeBSD ha una lista di loader, piuttosto che un singolo loader con un ritorno nel loader #!, per lanciare qualunque inteprete o script della shell.
Storicamente, l’unico loader nella piattaforma UNIX® esaminava il numero magico (generalmente i primi 4 o 8 byte del file) per vedere se il binario fosse conosciuto dal sistema e, nel caso, invocava il loader del binario.
Se non era un tipo di binario per il sistea, la chiamata execve(2) ritornava un errore, e la shell tentava di avviare eseguendolo come comando della shell.
L’assunzione era un default, "qualunque fosse la shell".
Più tardi, è stato fatto un hack per sh(1) per esaminare i primi due caratteri. Se erano :\n, allora invocava la shell csh(1) (crediamo sia stata SCO a fare per prima questo hack).
Ciò che ora fa FreeBSD è scorrere una lista di loader, con un loader #! generico che riconosce gli interpreti dai caratteri che seguono lo spazio successivo vicino alla fine, seguito da un ritorno a /bin/sh.
Per il supporto alle ABI di Linux, FreeBSD vede il numero magico come un binario ELF (a questo punto non fa distinzione tra FreeBSD, Solaris™, Linux, o qualunque altro SO che ha un tipo di immagine ELF).
Il loader di ELF cerca un marchio specializzato, che ` una sezione di commento nell’immagine ELF e che non è presente sui binari ELF SVR4/Solaris™.
I binari di Linux, per funzionare, devono essere marchiati come tipo Linux da brandelf(1):
# brandelf -t Linux fileQuando viene fatto questo, il loader ELF vedrà il marchio di Linux sul file.
Quando il loader ELF vede il marchio di Linux, il loader sostituisce un puntatore nella struttura proc. Tutte le chiamate di sistema sono indicizzate attraverso questo puntatore (in un sistema UNIX® tradizionale questo sarebbe l’array di strutture sysent[], contentente le chiamate di sistema). In aggiunta;, il processo è etichettato per un trattamento speciale del vettore trappola per il codice del segnale di lancio, e molti altri (minori) aggiustamenti che sono gestiti dal modulo Linux del kernel.
Il vettore delle chiamate di sistema di Linux contiene, tra le altre cose, una lista di valori sysent[] i cui indirizzi risiedono nel modulo del kernel.
Quando una chiamata di sistema è fatta dal binario di Linux, il codice trappola derefereizia il puntatore alla funzione della chiamata di sistema dalla struttura proc, e prende i punti di ingresso delle chiamate di sistema di Linux, non di FreeBSD.
In più, la modalità Linux ridefinisce la root dinamicamente; questo, in effetti, è quello che fa l’opzione union al montaggio del file system (non il tipo di file system unionfs!). Un tentativo viene prima fatto per cercare il file nella directory /compat/linux/original-path, quindi, solo se fallisce, la ricerca ` fatta nella directory /original-path. Questo assicura che possano funzionare i binari che per richiedono altri binari (p.e., la toolchain di Linux può funzionare tutta sotto il supporto ABI di Linux). Questo significa anche che i binari di Linux possono caricare ed eseguire binari di FreeBSD, se non sono presenti i corrispondenti binari di Linux, e che puoi mettere un comando uname(1) nell’albero della directory /compat/linux per essere sicuro che i binari di Linux non possano capire che non stanno girando sotto Linux.
In effeti c’è un kernel Linux nel kernel FreeBSD le varie funzioni sottostanti che implementano tutti i servizi forniti dal kernel sono identiche sia nelle definizioni delle tabelle delle chiamate di sistema di FreeBSD che di Linux: le operazioni sul file system, le operazioni nella memoria virtuale, la consegna dei segnali, le IPC System V, ecc… L’unica differenza è che i binari di FreeBSD prendono le funzioni colla di FreeBSD, e i binari di Linux prendono le funzioni colla di Linux (molti dei vecchi SO hanno solo le loro funzioni colla: gli indirizzi delle funzioni in un array di strutture sysent[] statico globale, invece che indirizzi di funzioni dereferenziate da un puntatore inizializzato dinamicamente nella struttura proc del processo che fa la chiamata).
Qual è la ABI nativa per FreeBSD? Non importa. Essenzialmente l’unica differenza è che (attualmente: questo potrebbe facilmente essere cambiato in distribuzioni future, e probabilmente sarà fatto) le funzioni colla di FreeBSD sono collegate staticamente nel kernel, e le funzioni colla di Linux possono essere collegate staticamente o vi si può accedere attraverso un modulo del kernel.
Si, ma è davvero emulazione? No. è implementazione delle ABI, non emulazione. Non è coinvolto nessun emulatore (o simulatore, per evitare la prossima domanda).
Allora perché talvolta viene chiamata "emulazione Linux"? Per rendere difficile vendere FreeBSD! Seriamente, è perché l’implementazione storica è stata fatta in un momento in cui non c’era altro termine per descrivere ciò che stava succedendo; dire che FreeBSD lanciava i binari di Linux non era vero, se non compilavi il codice o caricavi un modulo, e c’era bisogno di un termine per descrivere cosa veniva caricato- da qui "l’emulatore Linux".
I rimanenti capitoli del Manuale di FreeBSD coprono tutti gli aspetti dell’amministrazione di un sistema FreeBSD. Ogni capitolo inizia descrivendo quello che imparerai dopo aver letto il capitolo, e specifica anche quello che dovresti sapere prima di affrontare il materiale.
Questi capitoli sono studiati per essere letti quando si ha bisogno di un’informazione. Non devi leggerli in un ordine particolare, né devi leggerli tutti prima di poter usare FreeBSD.
Uno degli aspetti importanti di FreeBSD è la configurazione del sistema. Una corretta configurazione del sistema aiuterà a prevenire mal di testa durante futuri aggiornamenti. Questo capitolo spiegherà molti dei processi di configurazione di FreeBSD, inclusi alcuni parametri che possono essere impostati per ottimizzare un sistema FreeBSD.
Dopo aver letto questo capitolo, saprai:
Come lavorare in maniera efficiente con i file system e le partizioni di swap.
Le basi dei sistemi di configurazione rc.conf e di avvio /usr/local/etc/rc.d.
Come configurare e provare una scheda di rete.
Come configurare host virtuali sui dispositivi di rete.
Come usare i vari file di configurazione in /etc.
Come mettere a punto FreeBSD usando le variabili sysctl.
Come ottimizzare la prestazioni del disco e modificare le limitazioni del kernel.
Prima di leggere questo capitolo, dovresti:
Comprendere le basi di UNIX® e di FreeBSD (Basi di UNIX).
Avere dimestichezza nella configurazione/compilazione del kernel (Configurazione del Kernel di FreeBSD).
Nel disegnare il tuo file system con bsdlabel(8) o sysinstall(8), ricorda che i dischi rigidi possono trasferire dati ad un ritmo maggiore dalle tracce esterne rispetto a quelle interne. Quindi i file system più piccoli e con un gran numero di accessi dovrebbero essere più vicini alla parte esterna del disco, mentre le partizioni più ampie, come /usr, dovrebbero essere posizionate verso l’interno. È una buona idea creare le partizioni in un ordine simile al seguente: root, swap, /var, /usr.
Le dimensioni della partizione /var riflettono l’uso che intendi fare della macchina. /var viene usata per mantenere le caselle di posta, i file di log, e gli spool della stampante. Le caselle di posta e file di log potrebbero crescere in maniera imprevedibile in relazione al numero di utenti presenti sul tuo sistema e da quanto a lungo manterrai i file di log. La maggior parte degli utenti non avrà mai bisogno di un gigabyte, ma ricorda che /var/tmp deve essere abbastanza ampia da contenere tutti i pacchetti.
La partizione /usr contiene molti dei file richiesti per far funzionare il sistema, la collezioni dei ports(7) (raccomandata) e il codice sorgente (opzionale). Entrambi sono opzionali al momento dell’installazione. Almeno 2 gigabyte sono raccomandati per questa partizione.
Quando decidi le dimensioni delle partizioni, tieni a mente le richieste di spazio. Esaurire lo spazio in una partizione mentre ne usi poco in un’altra può essere molto fastidioso.
Alcuni utenti hanno scoperto che il dimensionamento |
Come regola generale, la partizione di swap dovrebbe essere tipicamente il doppio della quantità di memoria principale (RAM). Ad esempio, se la macchina avesse 128 megabyte di memoria, il file di swap dovrebbe essere di 256 megabyte. Sistemi con meno memoria potrebbero funzionare meglio con uno swap maggiore. Meno di 256 megabyte di swap non è raccomandato e dovresti pensare ad una espansione della memoria. Gli algoritmi di paginazione sono ottimizzati per funzionare al meglio quando la partizione di swap è almeno due volte la dimensione della memoria principale. Configurare uno swap troppo piccolo potrebbe portare ad una inefficienza nel codice di scansione della VM e potrebbe creare problemi in seguito, nel caso di aggiunta di memoria alla macchina.
Su sistemi più grandi con dischi SCSI multipli (o dischi IDE multipli collegati a diversi controller) è consigliabile che ci sia uno swap per ogni disco (fino a quattro dischi). Le partizioni di swap dovrebbero avere approssimativamente le stesse dimensioni. Il kernel può gestire dimensioni arbitrarie ma internamente le strutture dati scalano meglio fino a quattro volte la dimensione della partizione di swap più ampia. Avere partizioni di swap con dimensioni simili permetterà al kernel di distribuire al meglio lo spazio di swap tra i dischi. Partizioni di swap grandi vanno bene, anche se non vengono usate molto. Potrebbe essere più semplice recuperare il sistema da un programma impazzito prima di essere costretti a riavviare.
Molti utenti pensano che un’unica grande partizione vada bene, ma ci sono molte ragioni per cui questa è una cattiva idea. Primo, ogni partizione ha differenti caratteristiche operative e separarle permette ai file system di ottimizzare se stessi di conseguenza. Ad esempio, le partizioni root e /usr sono per lo più usate in lettura, senza molte operazioni di scrittura. Un sacco di letture e scritture potrebbero esserci in /var e /var/tmp.
Partizionando in maniera appropriata il sistema, la frammentazione introdotta nelle partizioni più piccole, con più carico in scrittura, non inciderà sulle partizioni per lo più di lettura. Mantenere le partizioni con maggiore carico in scrittura vicine al bordo del disco aumenterà le prestazioni di I/O nelle partizioni dove ne hai più bisogno. Ora, sebbene potresti avere bisogno di prestazioni di I/O anche nelle partizioni più ampie, spostarle verso il bordo del disco non porterebbe nessun miglioramento significativo delle prestazioni, al contrario dello spostamento di /var all’esterno. Infine, ci sono problemi riguardanti la sicurezza. Una piccola, simpatica partizione di root che è essenzialmente di sola lettura ha ottime possibilità di sopravvivere intatta a un brutto crash.
Il posto principale per le informazioni di configurazione del sistema è in /etc/rc.conf. Questo file contiene un’ampia gamma di informazioni di configurazione, usate principalmente all’avvio della macchina per la configurazione del sistema. Il suo nome è autoesplicativo; si tratta di informazioni di configurazione per i file rc*.
Un amministratore dovrebbe aggiungere dei campi nel file rc.conf per cambiare le impostazioni predefinite di /etc/defaults/rc.conf. Il file predefinito non dovrebbe essere semplicemente copiato in /etc - esso contiene valori di default, non esempi. Tutti i cambiamenti specifici del sistema dovrebbero essere effettuati nel file rc.conf stesso.
Nelle applicazioni cluster possono essere adottate differenti strategie per separare le configurazioni generali da quelle specifiche del sistema in maniera da mantenere basso l’impegno di amministrazione. L’approccio raccomandato è di porre le configurazioni generali in un altro file, ad esempio /etc/rc.conf.site, e poi includerlo in /etc/rc.conf, che conterrà solo le informazioni specifiche del sistema.
Visto che rc.conf viene letto da sh(1) è semplice farlo. Ad esempio:
rc.conf:
. /etc/rc.conf.site
hostname="node15.example.com"
network_interfaces="fxp0 lo0"
ifconfig_fxp0="inet 10.1.1.1"rc.conf.site:
defaultrouter="10.1.1.254"
saver="daemon"
blanktime="100"Il file rc.conf.site potrà poi essere distribuito su ogni sistema usando rsync o un programma simile, mentre il file rc.conf rimarrà unico.
L’aggiornamento del sistema tramite sysinstall(8) o make world non sovrascriverà il file rc.conf, quindi le configurazioni del sistema non andranno perse.
Tipicamente, le applicazioni installate hanno i propri file di configurazione, con la loro sintassi, ecc. È importante che questi file siano tenuti separati dal sistema di base, in maniera da essere facilmente individuati e gestiti dagli strumenti di gestione dei pacchetti.
In genere, questi file vengono installati in /usr/local/etc. Nel caso in cui un’applicazione abbia un grande numero di file di configurazione, verrà creata una sottodirectory per contenerli.
Normalmente, quando viene installato un pacchetto, vengono installati anche file di configurazione d’esempio. In genere questi vengono identificati da un suffisso .default. Se non ci sono file di configurazione esistenti per l’applicazione, verranno creati copiando i file .default.
Ad esempio, considera il contenuto della directory /usr/local/etc/apache:
-rw-r--r-- 1 root wheel 2184 May 20 1998 access.conf -rw-r--r-- 1 root wheel 2184 May 20 1998 access.conf.default -rw-r--r-- 1 root wheel 9555 May 20 1998 httpd.conf -rw-r--r-- 1 root wheel 9555 May 20 1998 httpd.conf.default -rw-r--r-- 1 root wheel 12205 May 20 1998 magic -rw-r--r-- 1 root wheel 12205 May 20 1998 magic.default -rw-r--r-- 1 root wheel 2700 May 20 1998 mime.types -rw-r--r-- 1 root wheel 2700 May 20 1998 mime.types.default -rw-r--r-- 1 root wheel 7980 May 20 1998 srm.conf -rw-r--r-- 1 root wheel 7933 May 20 1998 srm.conf.default
Le differenze nelle dimensioni dei file mostrano che solo srm.conf è stato modificato. Una successiva installazione di Apache dai port non sovrascriverà questo file modificato.
Molti utenti scelgono di installare software di terze parti in FreeBSD attraverso la collezione dei port. Nell magior parte dei casi potrebbe essere necessario configurare il software in un modo tale che sia avviato all’inizializzazione di sistema. Servizi, come mail/postfix o www/apache13 sono solo due fra i molti pacchetti software che possono essere avviati durante l’inizializzazione di sistema. Questa sezione spiega le procedure disponibili per avviare software di terze parti.
In FreeBSD, molti servizi inclusi, come cron(8), sono avviati attraverso gli script di startup. Questi script possono differire a seconda della verione di FreeBSD o del produttore; comunque il più importante aspetto da considerare è che la configurazione di startup può essere gestita tramite semplici script di inizializzazione.
Prima dell’avvento di rc.d, gli applicativi lasciavano un semplice script di avvio nella directory /usr/local/etc/rc.d che sarebbe stato poi letto dagli script di inizializzazione di sistema. Questi script sarebbero poi eseguiti durante la fase di avvio del sistema.
Mentre molti individui hanno speso ore cercando di integrare il vecchio stile di configurazione nel nuovo sistema, resta il fatto che qualche utility di terze parti necessita ancora di uno script semplicemente lasciato nella succitata directory. Le sottili differenze negli script dipendono dal fatto se rc.d sia usato o meno. Prima di FreeBSD 5.1 viene usato il vecchio metodo di configurazione ed in quasi tutti i casi uno script di nuovo tipo funzionerebbe perfettamente.
Mentre ogni script deve rispettare alcuni requisiti minimi, il più delle volte questi requisiti sono indipendenti dalla versioni di FreeBSD. Ogni script deve avere una estensione .sh appesa alla fine ed ogni script deve essere eseguibile dal sistema. L’ultima richiesta può essere soddisfatta usando il comando chmod e impostando i permessi a 755. Ci dovrebbe essere, come minimo, un’opzione per fare lo start dell’applicativo ed un’opzione per farne lo stop.
Il più semplice script di avvio probabilmente sembrerebbe simile al seguente:
#!/bin/sh
echo -n ' utility'
case "$1" in
start)
/usr/local/bin/utility
;;
stop)
kill -9 `cat /var/run/utility.pid`
;;
*)
echo "Usage: `basename $0` {start|stop}" >&2
exit 64
;;
esac
exit 0Questo script fornisce un’opzione stop e start per l’applicazione a cui ci riferiamo semplicemente come utility.
Potrebbe essere avviata manualmente con:
# /usr/local/etc/rc.d/utility.sh startMentre non tutto il software di terze parti richiede la linea in rc.conf, quasi ogni giorno un nuovo port viene modificato per accettare questa configurazione. Controlla l’output finale dell’installazione per maggiori informazioni su un applicativo specifico. Ci sarà del software di terze parti che fornisce script di avvio che permettono all’applicativo di essere usato con rc.d; tuttavia, questo sarà discusso nella successiva sezione.
Ora che FreeBSD include rc.d, la configurazione dell’avvio degli applicativi è diventata più semplice, e più flessibile. Usando le parole chiave discusse nella sezione rc.d, gli applicativi ora possono essere configurati dopo certi altri servizi come ad esempio il DNS; possono permettere che siano passati flag extra nel codice attraverso rc.conf al posto di flag statici negli script di avvio, e molto altro. Uno script basilare potrebbe assomigliare al seguente:
#!/bin/sh
#
# PROVIDE: utility
# REQUIRE: DAEMON
# KEYWORD: shutdown
. /etc/rc.subr
name=utility
rcvar=utility_enable
command="/usr/local/sbin/utility"
load_rc_config $name
#
# DO NOT CHANGE THESE DEFAULT VALUES HERE
# SET THEM IN THE /etc/rc.conf FILE
#
utility_enable=${utility_enable-"NO"}
pidfile=${utility_pidfile-"/var/run/utility.pid"}
run_rc_command "$1"Questo script assicurerà che utility partirà dopo il servizio daemon. Fornisce inoltre un metodo per settare e tracciare il PID, o il file dell’ID di processo.
Questa applicazione potrebbe avere le seguenti linee piazzate in /etc/rc.conf:
utility_enable="YES"
Questo metodo permette inoltre una semplice manipolazione degli argomenti di linea di comando, incluse le funzioni di default definite in /etc/rc.subr, compatibilità con l’utility rcorder(8) e fornisce una più semplice configurazione attraverso il file rc.conf.
Altri servizi, come i demoni POP3, IMAP, etc. potrebbero essere avviati usando inetd(8). Questo implica l’installazione del servizio dalla collezione dei port e l’aggiunta di una linea di configurazione al file /etc/inetd.conf o togliendo dei commenti in una delle linee di configurazione del file stesso. L’uso di inetd e la sua configurazione è descritto in dettaglio nella sezione inetd.
In alcuni casi, potrebbe essere più plausibile usare il demone cron(8) per avviare i servizi di sistema. Questo approccio ha alcuni vantaggi poichè cron esegue questi processi come l’utente proprietario del file crontab. Questo permette ad utenti regolari di avviare e mantenere alcuni applicativi.
Il comando cron fornisce una caratteristica unica, @reboot, che potrebbe essere usato al posto della specifica del tempo. Questo farà sì che il job sia eseguito quando cron(8) è avviato, normalmente durante l’inizializzazione di sistema.
cronUno dei comandi più utili presenti in FreeBSD è cron(8). L’utility cron viene eseguita in background e controlla costantemente il file /etc/crontab. cron controlla anche la directory /var/cron/tabs, alla ricerca di nuovi file crontab. Questi file crontab contengono informazioni sulle specifiche funzioni che ci si aspetta vengano compiute da cron a determinati intervalli temporali.
L’utility cron usa due differenti tipi di file di configurazione, il crontab di sistema ed il crontab utente. La sola differenza fra questi due file è nel sesto campo. Nel crontab di sistema, il sesto campo è il nome dell’utente sotto il quale viene eseguito il comando. Questo dà al crontab di sistema la capacità di eseguire comandi come ogni utente. Nel crontab utente, il sesto campo è il comando da eseguire, e tutti i comandi vengono eseguiti come l’utente che ha creato il crontab; questa è un’importante caratteristica di sicurezza.
I crontab utenti permettono ad utenti individuali di schedulare task senza i privilegi di L’utente |
Diamo un’occhiata al file /etc/crontab (il crontab di sistema):
# /etc/crontab - il crontab di root per FreeBSD # # $FreeBSD: src/etc/crontab,v 1.32 2002/11/22 16:13:39 tom Exp $ #(1) # SHELL=/bin/sh PATH=/etc:/bin:/sbin:/usr/bin:/usr/sbin (2) HOME=/var/log # # #minute hour mday month wday who command (3) # # */5 * * * * root /usr/libexec/atrun (4)
| 1 | Come in molti file di configurazione di FreeBSD, il carattere # rappresenta un commento. Un commento può essere posto nel file come una nota su cosa si desidera fare con un certo comando. I commenti non possono essere nella stessa linea di un comando o saranno interpretati come parte di un comando; devono trovarsi su una linea a sè. Le linee vuote vengono ignorate. |
| 2 | Anzitutto, deve essere definito l’ambiente. I segni di uguale (=) vengono usati per definire ogni impostazione dell’ambiente, come viene fatto in questo esempio per SHELL, PATH, e HOME. Se la linea relativa alla shell viene omessa, cron userà quella di default, che è sh. Se si omette la variabile PATH, non verrà usato nessun default e le locazioni dei file dovranno essere assolute. Se viene omessa HOME, cron userà la home directory dello user che lo ha richiamato. |
| 3 | Questa linea definisce un totale di sette campi. Qui sono elencati i valori minute, hour, mday, month, wday, who, e command. Questi nomi sono più o meno autoesplicativi. minute è il tempo in minuti al quale dovrà essere eseguito il comando. hour è uguale, ma per le ore. mday rappresenta il giorno del mese. month è simile ad hour e minute, ma rappresenta il mese. L’opzione wday rappresenta il giorno della settimana. Tutti questi campi devono avere un valore numerico, e seguire l’orario di ventiquattro ore. Il campo who è speciale, ed esiste solo nel file /etc/crontab. Questo campo specifica l’utente con il quale deve essere eseguito il comando. Quando un utente installa il suo file crontab, non avrà a disposizione questa opzione. Infine, viene elencata l’opzione command. Questo è l’ultimo campo, e naturalmente indica il comando che deve essere eseguito. |
| 4 | Quest’ultima linea definirà i valori discussi prima. Notate che abbiamo un /5, seguito da parecchi caratteri * significano "dalla prima all’ultima volta", e possono essere interpretati come ogni volta. Dunque, basandosi su questa linea, sembra che il comando atrun debba essere invocato da root ogni cinque minuti, prescindendo da quale giorno o mese sia. Per maggiori informazioni sul comando atrun, vedere la pagina di manuale atrun(8).I comandi possono essere richiamati con qualsiasi numero di flag; i comandi che si estendono per più righe potrebbero però avere bisogno di essere spezzati con il carattere di continuazione "\". |
Questa è l’impostazione di base per ogni file crontab, anche se c’è qualcosa di particolare in questo. Il sesto campo, dove abbiamo specificato il nome utente, esiste solo nel file di sistema /etc/crontab. Questo campo dovrebbe venire omesso nei crontab dei vari utenti.
Non devi usare la procedura descritta qui per editare/installare il crontab di sistema. Semplicemente usa il tuo editor favorito: l’utility |
Per installare un crontab appena scritto, prima usa il tuo editor preferito per creare un file nel formato corretto, e poi usa l’utility crontab. L’uso più corretto è:
% crontab crontab-fileIn questo esempio, crontab-file è il nome di un file crontab che era stato creato in precedenza.
C’è anche un’opzione per elencare i file crontab già installati: passate semplicemente -l a crontab e date un’occhiata all’output.
Per gli utenti che desiderino scrivere il proprio file crontab da zero, senza usare un template, è disponibile crontab -e. Questa opzione permetterà loro di invocare l’editor prescelto su un file vuoto. Quando il file verrà salvato, esso verrà automaticamente installato dal comando crontab.
Se successivamente vuoi rimuovere il tuo crontab completamente, usa crontab con l’opzione -r.
Nel 2002 FreeBSD ha integrato il sistema di inizializzazione rc.d di NetBSD. Gli utenti dovrebbero aver notato i file elencati nella cartella /etc/rc.d. Molti di questi file sono servizi di base che possono essere controllati con opzioni start, stop, e restart. Ad esempio, sshd(8) può essere riavviato con il comando seguente:
# /etc/rc.d/sshd restartQuesta procedura è simile a quella per altri servizi. Naturalmente, i servizi in genere vengono avviati automaticamente in fase di avvio secondo quanto specificato in rc.conf(5). Ad esempio, per abilitare il demone per il NAT (Network Address Translation) all’avvio basta aggiungere la linea seguente a /etc/rc.conf:
natd_enable="YES"
Se esiste già una linea natd_enable="NO", allora basta cambiare il valore da NO a YES. Gli script rc caricheranno automaticamente ogni altro servizio durante il riavvio seguente, come descritto più avanti.
Poichè il sistema di rc.d è inteso prevalentemente per avviare/bloccare i servizi al momento dell’accensione/spegnimento, le opzioni standard start, stop e restart avranno il comportamento appropriato solo seè stata impostata la variabile appropriata in /etc/rc.conf. Ad esempio il comando precedente sshd restart funzionerà solo se in /etc/rc.conf è stata impostata l’opzione sshd_enable a YES. Per avviare (start), fermare (stop) o riavviare (restart) un servizio, ignorandole impostazioni in /etc/rc.conf, i comandi devono avere il prefisso "one". Ad esempio per riavviare sshd trascurando le impostazioni esistenti in /etc/rc.conf, impartite il comando seguente:
# /etc/rc.d/sshd onerestartÈ semplice controllare se un servizio è stato abilitato in /etc/rc.conf eseguendo lo script appropriato in rc.d con l’opzione rcvar. Dunque, un amministratore può controllare che sshd sia effettivamente abilitato in /etc/rc.conf eseguendo:
# /etc/rc.d/sshd rcvar
# sshd
$sshd_enable=YESLa seconda linea ( |
Per determinare se un servizio è attivo, è disponibile l’opzione status. Ad esempio per verificare che sshd sia effettivamente avviato:
# /etc/rc.d/sshd status
sshd is running as pid 433.In alcuni case è anche possibile effettuare il reload di un servizio. Questo tenterà di inviare un segnale al servizio, per fargli ricaricare il suo file di configurazione. Nella maggior parte dei casi si tratterà del segnale SIGHUP. Il supporto per questa caratteristica non è garantito per tutti i servizi.
La struttura di rc.d non viene usata solo per i servizi di rete, ma contribuisce anche per buona parte all’inizializzazione del sistema. Ad esempio, considerate il file bgfsck. Quando lo script viene eseguito, esso stamperà il seguente messaggio:
Starting background file system checks in 60 seconds.Dunque questo file viene usato per il controllo del file system in background, che avviene solo durante l’inizializzazione del sistema.
Molti servizi di sistema dipendono da altri servizi per poter funzionare in maniera appropriata. Ad esempio, il NIS ed altri servizi basati sulle RPC potrebbero non funzionare in assenza di rpcbind (portmapper). Per risolvere il problema, nei commenti all’inizio di ogni script di avvio ci sono informazioni sulle dipendenze ed altri metadati. Il programma rcorder(8) viene poi utilizzato per effettuare il parsing di questi commenti durante l’inizializzazione di sistema e per determinare l’ordine con il quale questi servizi devono essere avviati per avere le proprie dipendenze soddisfatte. In cima ad ogni file di avvio possono essere incluse le seguenti parole:
PROVIDE: Specifica i servizi forniti dal file.
REQUIRE: Elenca i servizi richiesti per far funzionare correttamente questo servizio. Questo file verrà eseguito dopo i tali servizi.
BEFORE: Elenca i servizi che dipendono da questo. Questo file verrà lanciato prima dei servizi specificati.
Usando questo metodo, un amministratore può controllare facilmente i servizi di sistema senza il fastidio dei "runlevel" come alcuni altri sistemi operativi UNIX®.
Informazioni addizionali sul sistema rc.d possono essere trovate nelle pagine man di rc(8) e rc.subr(8). Se sei interessato a scrivere un tuo script rc.d o a migliorarne uno esisente, ti può essere utile questo articolo.
Al giorno d’oggi non riusciamo a pensare ad un computer senza pensare ad una connessione di rete. Aggiungere e configurare una scheda di rete è un compito comune per ogni amministratore di FreeBSD.
Prima di cominciare, dovresti conoscere il modello della scheda di rete che possiedi, il chip che usa, e se si tratta di una scheda PCI o ISA. FreeBSD supporta un’ampia varietà sia di schede PCI che ISA. Verifica l’Hardware Compatibility List della tua release per vedere se la scheda è supportata.
Una volta sicuro che la tua scheda sia supportata, hai bisogno di determinare il driver appropriato per la scheda. I file /usr/src/conf/NOTES e /usr/src/sys/arch/conf/NOTES ti forniranno un elenco di driver per le interfacce di rete con alcune informazioni su chipset/schede supportate. Se hai dubbi su quale sia il driver corretto, leggi la pagina man del driver. La pagina man fornirà ulteriori informazioni sull’hardware supportato ed anche sui possibili problemi che potrebbero capitare.
Se sei in possesso di una scheda comune, la maggior parte delle volte non dovrai cercare molto per trovare un driver. I driver per le schede di reti comuni sono presenti nel kernel GENERIC, quindi la tua scheda dovrebbe presentarsi durante l’avvio, in questo modo:
dc0: <82c169 PNIC 10/100BaseTX> port 0xa000-0xa0ff mem 0xd3800000-0xd38
000ff irq 15 at device 11.0 on pci0
dc0: Ethernet address: 00:a0:cc:da:da:da
miibus0: <MII bus> on dc0
ukphy0: <Generic IEEE 802.3u media interface> on miibus0
ukphy0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, auto
dc1: <82c169 PNIC 10/100BaseTX> port 0x9800-0x98ff mem 0xd3000000-0xd30
000ff irq 11 at device 12.0 on pci0
dc1: Ethernet address: 00:a0:cc:da:da:db
miibus1: <MII bus> on dc1
ukphy1: <Generic IEEE 802.3u media interface> on miibus1
ukphy1: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, autoIn questo esempio, vediamo che nel sistema sono presenti due schede che usano il driver dc(4).
Se il driver per la tua NIC non è presente in GENERIC, dovrai caricare i driver appropriati per usare la tua NIC. Questo dovrà essere fatto in uno di questi due modi:
Il modo più semplice è caricare un modulo del kernel con kldload(8) o caricarlo automaticamente al momento del boot aggiungendo le linee appropriate a /boot/loader.conf. Non tutti i driver NIC sono disponibili come moduli; esempi notevoli di driver per i quali non esistono moduli sono schede ISA.
Alternativamente, puoi compilare staticamente il supporto per la tua scheda nel kernel. Controlla /usr/src/sys/conf/NOTES, /usr/src/sys/arch/conf/NOTES e la pagina di manuale del driver per sapere cosa aggiungere nel tuo file di configurazione del kernel. Per maggiori informazioni sul modo di ricompilare il kernel, per favore consulta il Configurazione del Kernel di FreeBSD. Se la tua scheda era riconosciuta al boot dal tuo kernel (GENERIC) non devi ricompilare un nuovo kernel.
Sfortunatamente, ci sono ancora molti venditori di hardware che non forniscono specifiche dei loro driver alla comunità open source perchè ritengono che tale informazione sia un segreto commerciale. Conseguentemente, gli sviluppatori di FreeBSD e di altri sistemi operativi hanno due scelte: sviluppare i driver con un lungo ed arduo processo di reverse engineering o usare i driver binari disponibili per le piattaforme Microsoft® Windows®. La maggior parte degli sviluppatori, inclusi quelli coinvolti in FreeBSD, ha preso la seconda strada.
Grazie al contributo di Bill Paul (wpaul), a partire da FreeBSD 5.3-RELEASE c’è supporto "nativo" per Network Driver Interface Specification (NDIS). Il NDISulator di FreeBSD (anche noto come Progetto Evil) prende un driver binario per Windows® e sostanzialmente crea un inganno fingendo di eseguirlo in Windows®. Poichè il driver ndis(4) sta usando un binario Windows®, è usabile solo su sistemi i386™ e amd64.
Il driver ndis(4) è designato per supportare principalmente device PCI, CardBus e PCMCIA, i device USB non sono ancora supportati. |
Per usare il NDISulator, hai bisogno sostanzialmente di tre cose:
Sorgenti del kernel
binari dei driver di Windows® XP (estensione .SYS)
file di configurazione dei driver per Windows® XP (estensione .INF)
Localizza i file per la tua carta specifica. Generalmente, posso essere trovati nel CD incluso o sui siti web dei venditori. Nei seguenti esempi, useremo W32DRIVER.SYS e W32DRIVER.INF.
Non puoi usare un driver Windows®/i386 con FreeBSD/amd64, devi trovare un driver Windows®/amd64 per farlo funzionare correttamente. |
Il prossimo passo è compilare il binario del driver in un modulo caricabile dal kernel. Per fare questo, come root, usa ndisgen(8):
# ndisgen /path/to/W32DRIVER.INF /path/to/W32DRIVER.SYSL’utility ndisgen(8) è interattiva e chiederà altre informazioni di cui necessita; produrrà un modulo del kernel nella presente directory che può essere caricato in questo modo:
# kldload ./W32DRIVER.koIn aggiunta al modulo del kernel generato, devi caricare i moduli ndis.ko e if_ndis.ko. Questo dovrebbe avvenire automaticamente quando uno carica un modulo che dipende da ndis(4). Se vuoi caricarli manualmente, usa il seguente comando:
# kldload ndis
# kldload if_ndisIl primo comando carica il wrapper del driver miniport NDIS, il secondo carica l’interfaccia di rete in questione.
Ora controlla dmesg(8) per vedere se c’era qualche errore durante il caricamento. Se tutto è andato bene, dovresti ottenere dell’output che somiglia a questo:
ndis0: <Wireless-G PCI Adapter> mem 0xf4100000-0xf4101fff irq 3 at device 8.0 on pci1
ndis0: NDIS API version: 5.0
ndis0: Ethernet address: 0a:b1:2c:d3:4e:f5
ndis0: 11b rates: 1Mbps 2Mbps 5.5Mbps 11Mbps
ndis0: 11g rates: 6Mbps 9Mbps 12Mbps 18Mbps 36Mbps 48Mbps 54MbpsD’ora in poi, puoi trattare il device ndis0 come ogni altra scheda di rete (ad esempio dc0).
Puoi configurare il sistema perché carichi il modulo NDIS al momento del boot nello stesso modo di ogni altro modulo. Per prima cosa, copia il modulo generato W32DRIVER.ko, nella directory /boot/modules. Quindi, aggiungi le seguenti linee a /boot/loader.conf:
W32DRIVER_load="YES"
Una volta che il driver giusto per la scheda di rete è stato caricato, la scheda ha bisogno di essere configurata. Come molte altre cose, la scheda di rete potrebbe essere già stata configurata al momento dell’installazione tramite sysinstall.
Per mostrare la configurazione delle interfacce di rete sul tuo sistema, immetti il seguente comando:
% ifconfig
dc0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 192.168.1.3 netmask 0xffffff00 broadcast 192.168.1.255
ether 00:a0:cc:da:da:da
media: Ethernet autoselect (100baseTX <full-duplex>)
status: active
dc1: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 10.0.0.1 netmask 0xffffff00 broadcast 10.0.0.255
ether 00:a0:cc:da:da:db
media: Ethernet 10baseT/UTP
status: no carrier
lp0: flags=8810<POINTOPOINT,SIMPLEX,MULTICAST> mtu 1500
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
inet 127.0.0.1 netmask 0xff000000
tun0: flags=8010<POINTOPOINT,MULTICAST> mtu 1500Vecchie versioni di FreeBSD potrebbero richiedere l’opzione |
In questo esempio, vengono mostrati i seguenti dispositivi:
dc0: La prima interfaccia Ethernet
dc1: La seconda interfaccia Ethernet
lp0: L’interfaccia della porta parallela
lo0: Il dispositivo di loopback
tun0: Il dispositivo tunnel usato da ppp
FreeBSD usa il nome del driver seguito dall’ordine nel quale la scheda è stata rilevata all’avvio del kernel per dare un nome alla scheda di rete. Ad esempio sis2 sarebbe la terza scheda di rete nel sistema che usa il driver sis(4).
In questo esempio, il dispositivo dc0 è attivo. Gli indicatori chiave sono:
UP significa che la scheda è pronta e configurata.
La scheda ha un indirizzo Internet (inet) (in questo caso 192.168.1.3).
Ha una maschera di sotto-rete valida (netmask; 0xffffff00 è lo stesso di 255.255.255.0).
Ha un indirizzo di broadcast valido (in questo caso, 192.168.1.255).
L’indirizzo MAC della scheda (ether) è 00:a0:cc:da:da:da.
La selezione del mezzo fisico è in modalità auto selezione (media: Ethernet autoselect (100baseTX <full-duplex>)). Vediamo che dc1 è stata configurata con un mezzo fisico 10baseT/UTP. Per ulteriori informazioni sui tipi di mezzi disponibili per un driver, fai riferimento alla sua pagina man.
Lo stato del collegamento (status) è active, ovvero è stata rilevata la portante. Per dc1, vediamo status: no carrier. Questo è normale quando un cavo Ethernet non è stato inserito nella scheda.
Se l’output di ifconfig(8) avesse mostrato qualcosa di simile a:
dc0: flags=8843<BROADCAST,SIMPLEX,MULTICAST> mtu 1500
ether 00:a0:cc:da:da:daciò avrebbe indicato che la scheda non era stata ben configurata.
Per configurare la tua scheda, avrai bisogno dei privilegi di root. La configurazione della scheda di rete può essere effettuata da riga di comando con ifconfig(8), ma avresti bisogno di farlo ad ogni riavvio del sistema. Il file /etc/rc.conf è il posto giusto dove scrivere la configurazione della scheda di rete.
Apri /etc/rc.conf con il tuo editor preferito. Avrai bisogno di aggiungere una riga per ogni scheda di rete presente nel sistema, ad esempio nel nostro caso, abbiamo aggiunto queste linee:
ifconfig_dc0="inet 192.168.1.3 netmask 255.255.255.0" ifconfig_dc1="inet 10.0.0.1 netmask 255.255.255.0 media 10baseT/UTP"
Dovrai sostituire dc0, dc1, e così via, con i dispositivi corretti per la tua scheda, e gli indirizzi con quelli appropriati. Dovresti leggere le pagine man del driver e di ifconfig(8) per maggiori dettagli sulle opzioni permesse ed anche la pagina man di rc.conf(5) per maggiori informazioni sulla sintassi di /etc/rc.conf.
Se hai configurato la rete durante l’installazione, alcune linee relative alle schede di rete potrebbero essere già presenti. Controlla due volte /etc/rc.conf prima di aggiungere ogni linea.
Avrai anche bisogno di modificare il file /etc/hosts per aggiungere i nomi e gli IP delle varie macchine della LAN, se non sono già lì. Per maggiori informazioni, fai riferimento a hosts(5) ed a /usr/shared/examples/etc/hosts.
Una volta che hai effettuato i cambiamenti necessari a /etc/rc.conf, dovresti riavviare la macchina. Ciò farà sì che i cambiamenti alle interfacce vengano applicati, e verificherà che il sistema si riavvii senza nessun errore di configurazione.
Una volta che il sistema è stato riavviato, dovresti testare le interfacce di rete.
Per verificare che una scheda Ethernet sia configurata correttamente, si devono provare due cose. Prima, effettuare un ping verso l’interfaccia stessa, e poi un ping verso un’altra macchina sulla LAN.
Prima proviamo l’interfaccia:
% ping -c5 192.168.1.3
PING 192.168.1.3 (192.168.1.3): 56 data bytes
64 bytes from 192.168.1.3: icmp_seq=0 ttl=64 time=0.082 ms
64 bytes from 192.168.1.3: icmp_seq=1 ttl=64 time=0.074 ms
64 bytes from 192.168.1.3: icmp_seq=2 ttl=64 time=0.076 ms
64 bytes from 192.168.1.3: icmp_seq=3 ttl=64 time=0.108 ms
64 bytes from 192.168.1.3: icmp_seq=4 ttl=64 time=0.076 ms
--- 192.168.1.3 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 0.074/0.083/0.108/0.013 msOra dobbiamo effettuare un ping verso un’altra macchina della LAN:
% ping -c5 192.168.1.2
PING 192.168.1.2 (192.168.1.2): 56 data bytes
64 bytes from 192.168.1.2: icmp_seq=0 ttl=64 time=0.726 ms
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.766 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.700 ms
64 bytes from 192.168.1.2: icmp_seq=3 ttl=64 time=0.747 ms
64 bytes from 192.168.1.2: icmp_seq=4 ttl=64 time=0.704 ms
--- 192.168.1.2 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 0.700/0.729/0.766/0.025 msPuoi usare il nome della macchina invece di 192.168.1.2 se hai sistemato il file /etc/hosts.
Risolvere i problemi delle varie configurazioni hardware e software è sempre una faticaccia, ma è una fatica che può essere diminuita controllando da subito le cose semplici. Avete collegato il cavo di rete? Avete configurato i servizi di rete? Avete configurato il firewall correttamente? La scheda di rete che state usando è supportata da FreeBSD? Controllate sempre le note sul vostro hardware prima di inviare un bug report. Aggiornate la vostra versione di FreeBSD all’ultima versione STABLE disponibile. Controllate gli archivi delle mailing list, o magari cercate su Internet.
Se la scheda funziona, ma le prestazioni sono scadenti, potrebbe esservi utile la lettura della pagina man tuning(7). Potreste anche verificare la vostra configurazione della rete, poichè una configurazione scorretta può essere la causa di connessioni lente.
Alcuni utenti riscontrano dei device timeouts, il che è normale per alcune schede. Se questi continuano, o se sono fastidiosi, potreste voler ricontrollare che non ci siano conflitti con altri dispositivi. Controllate due volte la connessione di rete. Forse dovreste procurarvi un’altra scheda.
Alcune volte, gli utenti notano alcuni errori watchdog timeout. La prima cosa da fare è controllare il cavo di rete. Alcune schede di rete richiedono uno slot PCI che supporti il Bus Mastering. Su alcune vecchie schede madri, ciò è permesso solo per uno slot PCI (tipicamente lo slot 0). Controllate la documentazione della scheda di rete e della scheda madre per determinare se possa essere quello il problema.
Messaggi No route to host vengono generati se il sistema non è in grado di effettuare il routing di un pacchetto verso una certa destinazione. Ciò può accadere se non è specificata una route di default, o se il cavo è scollegato. Controllate l’output di netstat -rn ed assicuratevi che ci sia una route valida per l’host che state cercando di raggiungere. Se non c’è, leggete il Networking Avanzato.
I messaggi d’errore ping: sendto: Permission denied sono spessi causati da un firewall mal configurato. Se ipfw è abilitato nel kernel ma non ci sono regole definite, allora la politica di default è di negare tutto il traffico, comprese le richieste di ping! Leggete il Firewall per maggiori informazioni.
Talvolta le prestazioni della scheda di rete sono scadenti, o sotto la media. In questi casi è preferibile cambiare la selezione del media da autoselect ad una selezione corretta. Anche se questo sistema funziona con la maggior parte dell’hardware, potrebbe non risolvere il problema per tutti. Ancora una volta, controllate tutte le impostazioni di rete, e leggete la pagina man tuning(7) .
Un uso piuttosto comune di FreeBSD è come hosting di siti virtuali, dove un solo server appare alla rete come molti server distinti. Ciò viene effettuato assegnando indirizzi di rete multipli ad una sola interfaccia.
Una data interfaccia di rete ha un solo indirizzo "reale", e può avere un numero qualsiasi di indirizzi "alias". Questi alias vengono normalmente aggiunti mettendo dei campi alias in /etc/rc.conf.
Un campo alias per l’interfaccia fxp0 appare così:
ifconfig_fxp0_alias0="inet xxx.xxx.xxx.xxx netmask xxx.xxx.xxx.xxx"
Nota che il campo alias deve iniziare con alias0 e aumentare in ordine, (ad esempio, _alias1, _alias2, e così via). Il processo di configurazione si fermerà al primo numero mancante.
Il calcolo delle maschere di sotto-rete degli alias è importante, ma, fortunatamente, è anche abbastanza semplice. Per una data interfaccia, deve esserci un indirizzo che rappresenta correttamente la maschera di sotto-rete. Ogni altro indirizzo che ricada in questa rete deve avere una maschera di sotto-rete con tutti 1 (espressi come 255.255.255.255 o 0xffffffff).
Ad esempio, considera il caso in cui l’interfaccia fxp0 sia connessa a due reti, la rete 10.1.1.0 con maschera di sotto-rete 255.255.255.0 e la rete 202.0.75.16 con maschera di sotto-rete 255.255.255.240. Vogliamo che il sistema sia visibile come 10.1.1.1 fino a 10.1.1.5 e come 202.0.75.17 fino a 202.0.75.20. Come notato sopra, solo il primo indirizzo in un dato range di sotto-rete (in questo caso, 10.0.1.1 e 202.0.75.17) dovrebbe avere una vera netmask; tutto il resto ( 10.1.1.2 fino a 10.1.1.5 e 202.0.75.18 fino a 202.0.75.20) dovrebbe essere configurato con una netmask di 255.255.255.255.
Le seguenti righe configurano il dispositivo correttamente per questo scopo:
ifconfig_fxp0="inet 10.1.1.1 netmask 255.255.255.0" ifconfig_fxp0_alias0="inet 10.1.1.2 netmask 255.255.255.255" ifconfig_fxp0_alias1="inet 10.1.1.3 netmask 255.255.255.255" ifconfig_fxp0_alias2="inet 10.1.1.4 netmask 255.255.255.255" ifconfig_fxp0_alias3="inet 10.1.1.5 netmask 255.255.255.255" ifconfig_fxp0_alias4="inet 202.0.75.17 netmask 255.255.255.240" ifconfig_fxp0_alias5="inet 202.0.75.18 netmask 255.255.255.255" ifconfig_fxp0_alias6="inet 202.0.75.19 netmask 255.255.255.255" ifconfig_fxp0_alias7="inet 202.0.75.20 netmask 255.255.255.255"
Ci sono molte directory nelle quali vengono tenute le informazioni di configurazione. Tra queste ci sono:
/etc | Informazioni generiche sulla configurazione del sistema; questi dati sono specifici del sistema. |
/etc/defaults | Versioni di default dei file di configurazione del sistema. |
/etc/mail | Configurazioni extra di sendmail(8), o file di configurazione di altri MTA. |
/etc/ppp | Configurazione ppp sia per i programmi a livello utente che a livello kernel. |
/etc/namedb | Posizione predefinita per i dati di named(8). Normalmente qui si trova named.conf insieme ai file di zona. |
/usr/local/etc | File di configurazione per le applicazioni installate. Può contenere sottodirectory. |
/usr/local/etc/rc.d | Script start/stop per i programmi installati. |
/var/db | File di dati specifici del sistema generati automaticamente, come il database dei package, il database di locate, e così via. |
/etc/resolv.conf detta il modo in cui il sistema di risoluzione dei nomi di FreeBSD accede al DNS (Internet Domain Name System).
I campi più comuni in resolv.conf sono:
| L’indirizzo IP di un name server al quale dovrà rivolgersi il sistema di risoluzione. I server vengono interrogati nell’ordine in cui sono elencati, fino a un massimo di tre. |
| Lista di ricerca per i nomi degli host. Normalmente questo viene determinato dal dominio dell’host locale. |
| Il nome del dominio locale. |
Un resolv.conf tipico:
search example.com nameserver 147.11.1.11 nameserver 147.11.100.30
Si dovrebbe usare solo una tra le due opzioni |
Se stai usando DHCP, dhclient(8) generalmente sovrascriverà resolv.conf con le informazioni ricevute dal server DHCP.
/etc/hosts è un semplice database testuale, reminiscenza della vecchia rete Internet. Esso lavora in congiunzione con DNS e NIS fornendo una mappatura da nome a indirizzo IP. Computer locali connessi ad una LAN possono essere messi in questo file per una gestione semplice dei nomi, invece di mettere su un server named(8). Inoltre, /etc/hosts può essere usato per fornire un registro locale dei nomi di Internet, riducendo la necessità di effettuare richieste esternamente per i nomi ad accesso frequente.
# $FreeBSD$ # # Host Database # Questo file dovrebbe contenere gli indirizzi e gli alias # per gli host locali che condividono questo file. # In presenza di DNS o NIS, questo file potrebbe non essere consultato affatto; # guarda /etc/nsswitch.conf per l'ordine di risoluzione. # # ::1 localhost localhost.my.domain myname.my.domain 127.0.0.1 localhost localhost.my.domain myname.my.domain # # Rete immaginaria. #10.0.0.2 myname.my.domain myname #10.0.0.3 myfriend.my.domain myfriend # # In accordo all'RFC 1918, puoi usare le seguenti classi di IP per reti private # che non verranno mai connesse ad Internet: # # 10.0.0.0 - 10.255.255.255 # 172.16.0.0 - 172.31.255.255 # 192.168.0.0 - 192.168.255.255 # # In caso volessi essere in grado di collegarti ad Internet, avrai bisogno # di veri numeri ufficiali assegnati. PER FAVORE PER FAVORE PER FAVORE # non tentare di inventarti i numeri della tua rete ma fattene assegnare # uno dal tuo provider (se ne hai uno) o dall'Internet Registry (ftp su # rs.internic.net, directory `/templates'). #
/etc/hosts accetta il semplicissimo formato:
[Indirizzo Internet ] [nome host ufficiale] [alias1] [alias2] ...
Ad esempio:
10.0.0.1 myRealHostname.example.com myRealHostname foobar1 foobar2
Consulta hosts(5) per maggiori informazioni.
syslog.conf è il file di configurazione per il programma syslogd(8). Indica quale tipo di messaggi syslog verranno scritti su ogni file di log.
# $FreeBSD$ # # Gli spazi SONO validi separatori dei campi in questo file. Ad ogni modo, # altri sistemi *nix-like insistono ancora nell'usare tab come separatori # di campo. Se condividi questo file tra più sistemi, potresti # voler usare solo dei tab come separatori. # Consulta la pagina man di syslog.conf(5). *.err;kern.debug;auth.notice;mail.crit /dev/console *.notice;kern.debug;lpr.info;mail.crit;news.err /var/log/messages security.* /var/log/security mail.info /var/log/maillog lpr.info /var/log/lpd-errs cron.* /var/log/cron *.err root *.notice;news.err root *.alert root *.emerg * # togli il commento a questo per loggare tutte le scritture su /dev/console # in /var/log/console.log #console.info /var/log/console.log # togli il commento a questo per abilitare il logging di tutti i messaggi di log # su /var/log/all.log #*.* /var/log/all.log # togli il commento a questo per abilitare il logging su un host remoto di nome # loghost #*.* @loghost # togli i commenti a questi se hai inn in funzione # news.crit /var/log/news/news.crit # news.err /var/log/news/news.err # news.notice /var/log/news/news.notice !startslip *.* /var/log/slip.log !ppp *.* /var/log/ppp.log
Consulta la pagina man di syslog.conf(5) per maggiori informazioni.
newsyslog.conf è il file di configurazione di newsyslog(8), un programma che normalmente viene eseguito da cron(8). newsyslog(8) determina quando i file di log richiedono un’archiviazione o un riordinamento. logfile viene rinominato in logfile.0, logfile.0 in logfile.1 e così via. Alternativamente, i file potranno essere archiviati in formato gzip(1), e quindi diventeranno: logfile.0.gz, logfile.1.gz, e così via.
newsyslog.conf indica quali file di log devono essere gestiti, quanti devono essere mantenuti, e quando devono essere toccati. I file di log possono essere riordinati e/o archiviati quando raggiungono una certa dimensione, o a una certa data/ora periodica.
# file di configurazione per newsyslog # $FreeBSD$ # # filename [owner:group] mode count size when [ZB] [/pid_file] [sig_num] /var/log/cron 600 3 100 * Z /var/log/amd.log 644 7 100 * Z /var/log/kerberos.log 644 7 100 * Z /var/log/lpd-errs 644 7 100 * Z /var/log/maillog 644 7 * @T00 Z /var/log/sendmail.st 644 10 * 168 B /var/log/messages 644 5 100 * Z /var/log/all.log 600 7 * @T00 Z /var/log/slip.log 600 3 100 * Z /var/log/ppp.log 600 3 100 * Z /var/log/security 600 10 100 * Z /var/log/wtmp 644 3 * @01T05 B /var/log/daily.log 640 7 * @T00 Z /var/log/weekly.log 640 5 1 $W6D0 Z /var/log/monthly.log 640 12 * $M1D0 Z /var/log/console.log 640 5 100 * Z
Consulta la pagina man di newsyslog(8) per maggiori informazioni.
sysctl.conf assomiglia molto a rc.conf. I valori vengono impostati nella forma variabile=valore. I valori specificati vengono impostati dopo che il sistema è entrato in modalità multiutente. Non tutte le variabili sono gestibili in questo modo.
Per disabilitare il log sulle uscite dei processi per segnale fatale ed impedire agli utenti di vedere che i processi sono avviati con altre utenze, puoi settare in sysctl.conf la riga seguente:
# Do not log fatal signal exits (e.g. sig 11) kern.logsigexit=0 # Prevent users from seeing information about processes that # are being run under another UID. security.bsd.see_other_uids=0
sysctl(8) è un’interfaccia che permette di effettuare cambiamenti ad un sistema FreeBSD già attivo. Questo include molte opzioni avanzate dello stack TCP/IP e del sistema di memoria virtuale che possono permettere di migliorare drammaticamente le prestazioni ad un sistemista che abbia esperienza. Più di cinquecento variabili di sistema possono essere lette e modificate usando sysctl(8).
In sostanza, sysctl(8) serve a due cose: a leggere e a modificare le impostazioni di sistema.
Per visualizzare tutte le variabili leggibili:
% sysctl -aPer leggere una particolare variabile, ad esempio, kern.maxproc:
% sysctl kern.maxproc
kern.maxproc: 1044Per impostare una particolare variabile, usa l’intuitiva sintassi variabile=valore:
# sysctl kern.maxfiles=5000
kern.maxfiles: 2088 -> 5000I valori validi per le variabili di sysctl sono generalmente o stringhe, o numeri, o valori booleani (un valore booleano può valere 1 per sì o 0 per no).
Se vuoi settare in modo automatico alcune variabile ad ogni avvio della macchina, usa il file /etc/sysctl.conf. Per maggiori informazioni guarda la pagina man di sysctl.conf(5) e la sysctl.conf.
In alcuni casi può essere desiderabile modificare i valori di sysctl(8) in sola lettura. Anche se questo talvolta è inevitabile, può essere fatto solo con un riavvio.
Ad esempio in alcuni modelli di laptop il dispositivo cardbus(4) non effettuerà il controllo sugli intervalli di memoria, e fallirà con errori che assomigliano a questi:
cbb0: Could not map register memory
device_probe_and_attach: cbb0 attach returned 12Casi come il precedente richiedono tipicamente la modifica di alcuni valori predefiniti di sysctl(8) che sono impostati come sola lettura. Per superare queste situazioni un utente può mettere degli "OID" di sysctl(8) nel proprio /boot/loader.conf.local. I valori predefiniti sono indicati nel file /boot/defaults/loader.conf.
Per risolvere i problemi menzionati qui sopra sarà necessario modificare hw.pci.allow_unsupported_io_range=1 nel file suddetto. Ora cardbus(4) funzionerà correttamente.
vfs.vmiodirenableLa variabile sysctl vfs.vmiodirenable può essere impostata a 0 (inattivo) o 1 (attivo); di default è 1. Questa variabile controlla il modo in cui le directory vengono messe nella cache dal sistema. La maggior parte delle directory sono piccole, e usano solo un singolo frammento (tipicamente 1 K) nel file system e meno (tipicamente 512 byte) nella cache. Con questa variabile impostata a 0, il buffer manterrà soltanto un numero fissato di directory nella cache anche se hai una quantità enorme di memoria. Attivando questa sysctl si permette al buffer di usare la VM Page Cache per immagazzinare le directory, rendendo disponibile tutta la memoria disponibile per il caching delle directory. In ogni caso, la minima quantità di memoria usata per memorizzare una directory sarà la dimensione della pagina fisica (in genere 4 K) invece di 512 byte. Noi consigliamo di attivare questa opzione se si hanno in esecuzione dei servizi che manipolano un grosso numero file. Servizi di questo tipo sono le cache web, i grandi sistemi di posta, e quelli di news. Attivare questa opzione in generale non ridurrà le prestazioni nonostante la memoria sprecata, ma dovresti sperimentare tu stesso per verificare.
vfs.write_behindLa variabile sysctl vfs.write_behind ha il valore predefinito di 1 (attivo). Essa dice al file system di effettuare le scritture sul media quando vengono raccolti cluster completi, il che accade tipicamente quando si scrivono grossi file sequenziali. L’idea è di evitare la saturazione del buffer cache con buffer "sporchi" quando le prestazioni dell’I/O non ne trarrebbero giovamento. Ad ogni modo, questo può causare uno stallo dei processi, ed in alcune circostanze potreste desiderare di disabilitarlo.
vfs.hirunningspaceLa variabile sysctl vfs.hirunningspace determina quanto grande deve essere la coda I/O in tutti i controller dei dischi nel sistema in un dato momento. Il valore predefinito in genere è sufficiente ma su macchine con molti dischi potreste voler aumentarlo a quattro o cinque megabyte. Notate che impostandolo ad un valore troppo alto (superando i limiti della cache) potreste avere delle performance peggiori. Non impostate un valore troppo alto arbitrariamente! Valori più alti aumentano la latenza nelle letture contemporanee.
Ci sono altre sysctl relative alla buffer-cache ed alle cache delle pagine VM. Non vi consigliamo di cambiare questi valori, il sistema di VM fa già un ottimo lavoro di messa a punto automatica.
vm.swap_idle_enabledLa variabile sysctl vm.swap_idle_enabled è utile in grossi sistemi multiutente dove si hanno molti utenti che entrano ed escono lasciando molti processi inattivi. Questi sistemi tendono a generare un grande pressione sulle riserve di memoria libera. Attivando questa caratteristica e manipolando l’isteresi di swap (in secondi di inattività) tramite vm.swap_idle_threshold1 e vm.swap_idle_threshold2 potete abbassare la priorità delle pagine di memoria associate con i processi inattivi più velocemente che con il normale algoritmo di paginazione. Ciò dà una mano al demone di paginazione. Non attivate questa opzione a meno che non ne abbiate bisogno, poichè il compromesso che state accettando è essenzialmente di pre-paginare la memoria in anticipo piuttosto che in ritardo, consumando dunque più swap e banda di trasmissione verso il disco. In un piccolo sistema questa opzione avrà un effetto ridotto ma in un grosso sistema che è già sottoposto a un moderato carico di paginazione questa opzione permette al sistema VM di spostare facilmente interi processi dentro e fuori la memoria.
hw.ata.wcFreeBSD 4.3 ha giocato un pò con l’idea di disattivare il caching IDE in scrittura. Questo ha ridotto la larghezza di banda in scrittura verso i dischi IDE ma è stato considerato necessario a causa di gravi problemi di consistenza dei dati introdotti dai venditori di dischi rigidi. Il problema è che il disco IDE rimane inattivo dopo che una scrittura è stata completata. Con il caching in scrittura attivo, i dischi IDE non scrivono soltanto i dati sui dischi in maniera disordinata, ma talvolta rimandano la scrittura indefinitamente sotto carichi di lavoro del disco pesanti. Un crash o un calo di tensione possono condurre a seri problemi di corruzione del file system. L’impostazione predefinita di FreeBSD fu cambiata in favore della sicurezza. Sfortunatamente, il risultato è stato una perdita di prestazioni talmente tremenda che abbiamo dovuto reinserire il caching in scrittura di default dopo quella release. Dovresti verificare il valore di default sul tuo sistema osservando la variabile sysctl hw.ata.wc. Se il caching IDE in scrittura è disattivato, potete attivarlo reimpostando la variabile del kernel a 1. Questo dovrebbe essere effettuato dal boot loader all’avvio. Tentare di effettuare questo cambiamento dopo che il kernel è stato avviato non avrà nessun effetto.
Per maggiori informazioni, guarda ata(4).
SCSI_DELAY (kern.cam.scsi_delay)La configurazione del kernel SCSI_DELAY può ridurre il tempo di avvio del sistema. I valori di default sono piuttosto alti e possono essere responsabili anche di 15 secondi di ritardo nel processo di avvio. Ridurre il valore a 5 secondi funziona in molti casi (specialmente con i dispositivi moderni). Nuove versioni di FreeBSD (5.0 e superiori) dovrebbero essere in grado di usare kern.cam.scsi_delay come un’opzione da boot. Quest’ultima e l’opzione di configurazione del kernel accettano valori in millisecondi , e non in secondi.
Il programma tunefs(8) può essere usato per mettere a punto con accuratezza un file system. Questo programma ha molte opzioni differenti, ma per ora noi ci preoccuperemo solo di attivare e disattivare i Soft Update, che verrà effettuato tramite:
# tunefs -n enable /filesystem
# tunefs -n disable /filesystemUn file system non potrà essere modificato con tunefs(8) mentre è montato. Un buon momento per attivare i Soft Update è prima che le partizioni siano montate, in modalità singolo utente.
I Soft Update migliorano drasticamente le prestazioni dei meta-dati, principalmente la creazione e la cancellazione di file, attraverso l’uso di una memoria cache. Consigliamo di attivare i Soft Update su tutti i file system. Ci sono due lati negativi relativi ai Soft Update dei quali dovresti essere a conoscenza: primo, i Soft Update garantiscono la consistenza del file system in caso di crash ma è più che probabile che passino molti secondi (anche un minuto!) prima che venga aggiornato fisicamente il disco. Se il sistema va in crash potresti perdere molto più lavoro in questo modo. Secondo, i Soft Update rallentano la liberazione dei blocchi liberi del file system. Se hai un file system (come il file system root) che è quasi pieno, la realizzazione di un grosso aggiornamento, come un make installworld, potrebbe essere causa di un superamento dei limiti di spazio del file system e di un fallimento dell’aggiornamento.
Ci sono due approcci tradizionalmente nella scrittura dei meta-dati del file system su disco. (Gli aggiornamenti dei meta-dati sono aggiornamenti ai dati che non sono contenuto, come gli inode o le directory.)
Storicamente, il comportamento predefinito era di scrivere gli aggiornamenti dei meta-dati in maniera sincrona. Se una directory veniva modificata, il sistema attendeva finchè il cambiamento venisse effettivamente scritto su disco. I buffer con i dati dei file (i contenuti dei file) venivano passati attraverso la cache e salvati su disco in seguito, in maniera asincrona. Il vantaggio di questa implementazione è che avviene in maniera sicura. Se si verifica un problema durante un aggiornamento, i meta-dati sono sempre in uno stato consistente. Un file viene creato completamente o non viene creato affatto. Se i blocchi dati di un file non sono riusciti ad uscire dalla cache e arrivare al disco prima del crash, fsck(8) è in grado di capirlo e riparare il file system impostando a zero la lunghezza del file. Inoltre, l’implementazione è chiara e semplice. Lo svantaggio è che i cambiamenti dei meta-dati sono lenti. Un rm -r, ad esempio, tocca tutti i file in una directory consecutivamente, ma ogni cambiamento della directory (la cancellazione del file) verrà scritto su disco in maniera sincrona. Questo include gli aggiornamenti alla directory stessa, alla tabella degli inode, e magari anche ai blocchi indiretti allocati dal file. Simili considerazioni si applicano nell’elenco di grosse gerarchie (tar -x).
Il secondo caso è l’aggiornamento asincrono dei meta-dati. Questo è il comportamento predefinito per Linux/ext2fs e mount -o async per *BSD/ufs. Anche tutti gli aggiornamenti dei meta-dati vengono semplicemente fatti passare attraverso la cache, cioè vengono mescolati con gli aggiornamenti dei dati contenuti nel file. Il vantaggio di questa implementazione è che non c’è bisogno di attendere che ogni aggiornamento dei meta-dati venga scritto su disco, dunque tutte le operazioni che causano enormi quantità di aggiornamenti dei meta-dati lavorano molto più velocemente che nel caso sincrono. Inoltre, l’implementazione è ancora semplice e chiara, dunque c’è un basso rischio che si annidino dei bug nel codice. Lo svantaggio è che non c’è nessuna garanzia di uno stato consistente del file system. Se si verifica un problema durante un’operazione che ha aggiornato grandi quantità di meta-dati (ad esempio un abbassamento di tensione, o qualcuno che preme il tasto reset), il file system verrà lasciato in uno stato imprevedibile. Non c’è opportunità di esaminare lo stato del file system quando il sistema viene riavviato; i blocchi dati di un file potrebbero essere già stati scritti sul disco mentre gli aggiornamenti della tabella degli inode o la directory associata non lo sono. È praticamente impossibile implementare un fsck che sia in grado di ripulire il caos risultante (perchè i dati necessari non sono disponibili sul disco). Se il file system è stato danneggiato più del riparabile, la sola scelta è di usare newfs(8) per ricrearlo e recuperarlo da un backup.
La soluzione comune di questo problema era implementare la registrazione delle regioni sporche, a cui spesso si fa riferimento come journaling, anche se questo termine non viene usato coerentemente e talvolta viene applicato ad altre forme di logging delle transazioni. Gli aggiornamenti dei meta-dati sono ancora scritti in maniera sincrona, ma solo in una piccola regione del disco. In seguito vengono spostati nella posizione appropriata. Poichè l’area di registrazione è una piccola regione contigua sul disco, non ci sono lunghe distanze da percorrere per le testine del disco, anche durante le operazioni pesanti, dunque queste operazioni sono più veloci degli aggiornamenti sincroni. Inoltre la complessità dell’implementazione è piuttosto limitata, dunque il rischio che si presentino dei bug è basso. Uno svantaggio è che tutti i meta-dati vengono scritti due volte (una volta nella regione di logging ed un’altra nella posizione appropriata) e quindi per un lavoro normale si può avere un "peggioramento" delle prestazioni. D’altro canto, in caso di crash, tutte le operazioni sui meta-dati in sospeso possono essere velocemente annullate o recuperate dall’area di registrazione quando il sistema è di nuovo attivo, e come risultato si ha un avvio veloce del file system.
Kirk McKusick, lo sviluppatore del Berkeley FFS, ha risolto questo problema con i Soft Update: tutti gli aggiornamenti dei meta-dati vengono tenuti in memoria e vengono scritti su disco in sequenza ordinata ("aggiornamenti ordinati dei meta-dati"). Ciò porta all’effetto che, in caso di operazioni pesanti sui meta-dati, gli ultimi aggiornamenti ad un elemento "recuperano" i precedenti se questi sono ancora in memoria e non sono già stati scritti su disco. Dunque tutte le operazioni, diciamo su una directory, vengono effettuate principalmente in memoria prima che l’aggiornamento sia scritto su disco (i blocchi dei dati vengono ordinati in relazione alla loro posizione, in modo che non vengano scritti su disco prima dei loro meta-dati). Se il sistema va in crash, ciò causa un implicito "riavvolgimento del log": tutte le operazioni che non hanno ancora trovato posto sul disco appariranno come mai effettuate. Viene mantenuto uno stato consistente del file system che sarà quello di 30 o 60 secondi prima. L’algoritmo usato garantisce anche che tutte le risorse in uso siano marcate come tali nelle appropriate tabelle di bit: blocchi e inode. Dopo un crash, il solo errore di allocazione è che vengono marcate come "usate" anche risorse che sono effettivamente "libere". fsck(8) riconosce questa situazione, e libera le risorse che non sono più in uso. Non c’è pericolo nell’ignorare lo stato di sporcizia del file system dopo un crash montandolo di forza con mount -f. Per poter liberare le risorse che potrebbero essere non usate, fsck(8) ha bisogno di essere avviato in seguito. Questa è l’idea di un fsck in background: all’avvio del sistema, viene registrata solo una immagine del file system. fsck può essere eseguito in seguito. Tutti i file system possono essere montati "sporchi", quindi il processo di avvio del sistema procede in modalità multiutente. In seguito, fsck viene avviato in background su tutti i file system dove è necessario, per liberare le risorse che potrebbero essere inutilizzate. (I file system che non usano i Soft Updates hanno ancora bisogno del solito fsck, comunque.)
Il vantaggio è che le operazioni sui meta-dati sono veloci quasi come gli aggiornamenti asincroni (cioè più veloci che con il logging, che deve scrivere i meta-dati due volte). Gli svantaggi sono nella complessità del codice (che implica un maggiore rischio di trovare bug in un’area molto sensibile, essendo legata alla perdita dei dati degli utenti), ed un consumo di memoria maggiore. Inoltre ci sono alcune idiosincrasie alle quali ci si deve abituare. Dopo un crash, lo stato del file system appare in qualche modo "vecchio". In situazioni dove l’approccio sincrono avrebbe causato la permanenza di alcuni file di lunghezza zero dopo un fsck, questi file non esistono affatto con un file system con Soft Update, perchè nè i meta-dati nè i contenuti dei file sono mai stati scritti su disco. Lo spazio su disco non viene rilasciato finchè gli aggiornamenti non sono stati scritti su disco, il che può avvenire qualche tempo dopo che è stato eseguito rm. Questo potrebbe causare problemi durante l’installazione di grandi quantità di dati su un file system che non avesse abbastanza spazio per contenere tutti i file due volte.
kern.maxfileskern.maxfiles può essere aumentato o abbassato a seconda dei requisiti del tuo sistema. Questa variabile indica il numero massimo di descrittori di file sul tuo sistema. Quando la tabella dei descrittori di file è piena, apparirà ripetutamente la scritta file: table is full nel buffer dei messaggi di sistema, che può essere visualizzato con il comando dmesg.
Ogni file, socket, o fifo aperta usa un descrittore di file. Un server di produzione di larga scala può richiedere facilmente molte migliaia di descrittori di file, in relazione al tipo e al numero di servizi in esecuzione insieme.
Nelle vecchie release di FreeBSD, il valore predefinito di kern.maxfile viene dettato dall’opzione maxusers nel file di configurazione del kernel. kern.maxfiles cresce proporzionalmente al valore di maxusers. Quando si compila un kernel personalizzato, è una buona idea impostare questa opzione di configurazione del kernel in base agli usi del proprio sistema. Da questo numero, dipendono molti dei limiti predefiniti del kernel. Anche se una macchina in produzione potrebbe non avere effettivamente 256 utenti connessi contemporaneamente, le risorse necessarie potrebbero essere simili a quelle di un server web su larga scala.
A partire da FreeBSD 4.5, kern.maxusers è automaticamente dimensionato sulla base della memoria disponibile nel sistema, e può essere determinato a run-time leggendo il valore del sysctl read-only kern.maxusers. Alcuni siti richiedono valori minori o maggiori di kern.maxusers e questo può essere impostato come un parametro modificabile dal loader; valori di 64, 128 o 256 non sono fuori dal comune. Non raccomandiamo di andare oltre i 256 a meno che non si necessiti di un numero esagerato di file descriptor; molti dei valori modificati nel loro default da kern.maxusers possono essere singolarmente sovrascritti a boot-time o a run-time in /boot/loader.conf (leggi la pagina di manuale loader.conf(5) o il file /boot/defaults/loader.conf per alcuni suggerimenti) o come descritto altrove in questo documento. Sistemi precedenti a FreeBSD 4.4 devono invece impostare questo valore attraverso l’opzione di config(8) maxusers.
Nelle release precedenti, il sistema setterà in modo automatico maxusers se lo imposti a 0. Quando usi quest’opzione, impostalo almeno a 4, specialmente se stai usando il sistema a finestre X o se compili software. Questo è dovuto al fatto che la tabella più importante settata da maxusers è quella relativa al numero massimo di processi, risultato di 20 + 16 * maxusers, e quindi se setti maxusers a 1, puoi avere solo 36 processi in modo simultaneo, inclusi i 18 o più di avvio del sistema e i 15 o più che verranno creati all’avvio del sistema a finestre X. Perfino una semplice attività come la lettura di una pagina man avvia fino a 9 processi per filtrare, decomprimere, e visualizzare la pagina. Settando maxusers a 64 avrai fino a 1044 processi simultanei, che dovrebbero essere sufficienti per quasi tutti gli utenti. Ad ogni modo, se vedi il temuto errore quando tenti di avviare un programma, o se stai usando un server con molti utenti simultanei (come ftp.FreeBSD.org), puoi sempre incrementare il numero e ricompilare.
|
kern.ipc.somaxconnLa variabile sysctl kern.ipc.somaxconn limita la dimensione della coda in ascolto per le connessioni TCP. Il valore predefinito è di 128, generalmente troppo basso per una gestione robusta di nuove connessioni in ambienti come i web server molto carichi. Per tali ambienti, è consigliato aumentare questo valore a 1024 o maggiore. Il demone di servizio può a sua volta limitare la dimensione della coda (e.g. sendmail(8), o Apache) ma spesso avrà una direttiva nel proprio file di configurazione per correggere la dimensione della coda. Grosse code di ascolto aiutano anche ad evitare attacchi di tipo Denial of Service ().
L’opzione di configurazione del kernel NMBCLUSTERS decide la quantità di Mbuf di rete disponibili al sistema. Un server molto trafficato con un numero basso di Mbuf ostacolerebbe le possibilità di FreeBSD. Ogni cluster rappresenta approssimativamente 2 K di memoria, dunque un valore di 1024 rappresenta 2 megabyte di memoria del kernel riservata per i buffer di rete. Può essere effettuato un semplice calcolo per capire quanti ne siano necessari. Se hai un web server che arriva al massimo a 1000 connessioni simultanee, ed ogni connessione consuma un buffer di 16 K in ricezione e un altro di 16 K in trasmissione, avrai bisogno approssimativamente di 32 MB di buffer di rete per coprire il web server. Una buona regola generale è di moltiplicare per 2, dunque 2x32 MB / 2 KB = 64 MB / 2 KB = 32768. Consigliamo valori compresi tra 4096 e 32768 per macchine con grandi quantità di memoria. In nessun caso dovreste specificare un valore alto arbitrario per questo parametro, poichè potrebbe portare ad un crash all’avvio. L’opzione -m di netstat(1) può essere usata per osservare l’uso della rete.
L’opzione del loader kern.ipc.nmbclusters può essere usata per impostare questi valori all’avvio. Solo versioni vecchie di FreeBSD richiedono l’uso dell’opzione NMBCLUSTERS come configurazione del kernel (config(8)).
Per server sotto carico che fanno un uso massiccio della chiamata di sistema sendfile(2), potrebbe essere necessario aumentare il numero di buffer sendfile(2) tramite l’opzione di configurazione del kernel NSFBUFS o impostando il suo valore in /boot/loader.conf (vedere loader(8) per maggiori dettagli). Un indicatore comune che questo parametro deve essere corretto è la comparsa di processi nello stato sfbufa. La variabile sysctl kern.ipc.nsfbufs è solo un riferimento read-only alla variabile configurata nel kernel. Questo parametro aumenta nominalmente con kern.maxusers, in ogni caso potrebbe essere necessario effettuare piccole correzioni per farli concordare.
Anche se un socket è stato segnalato come non-bloccante, richiamando sendfile(2) su di esso si potrebbe avere un blocco della chiamata sendfile(2) fino a quando non sono disponibili delle |
net.inet.ip.portrange.*La variabili sysctl net.inet.ip.portrange.* controllano i numeri di porta automaticamente assegnate a socket TCP ed UDP. Ci sono tre intervalli: uno basso, uno predefinito, ed uno alto. La maggior parte dei programmi usa l’intervallo predefinito che è controllato da net.inet.ip.portrange.first e net.inet.ip.portrange.last, che hanno valori predefiniti di 1024 e 5000. Questi intervalli sono usati per le connessioni in uscita, ed è possibile che il sistema esaurisca le porte in alcune circostanze. Ciò accade per lo più quando avete un web proxy molto carico. L’intervallo di porte non è un problema quando si usano server che abbiano per lo più connessioni in ingresso, come i normali web server, o un numero limitato di connessioni in uscita, come i relay di posta. Per situazioni nelle quali potreste terminare le porte, è consigliato aumentare leggermente net.inet.ip.portrange.last. Un valore di 10000, 20000 o 30000 può essere ragionevole. Dovreste anche considerare gli effetti relativi ad un firewall nel cambiare il range di porte. Alcuni firewall potrebbero bloccare grandi intervalli di porte (tipicamente le porte basse) ed aspettarsi che i sistemi usino porte più alte per le connessioni in uscita - per questa ragione si consiglia di non abbassare il valore di net.inet.ip.portrange.first.
Il limite del Prodotto del Ritardo di Banda TCP è simile a TCP/Vegas in NetBSD. Può essere abilitato impostando la variabile sysctl net.inet.tcp.inflight_enable ad 1. Il sistema tenterà di calcolare il prodotto del ritardo di banda per ogni connessione e limiterà l’ammontare di dati accodati per la trasmissione su rete al livello migliore per garantire il massimo throughput.
Questa funzionalità è utile quando si inviano dati su modem multipli, su Ethernet Gigabit, o su collegamenti WAN ad alta velocità (o qualsiasi altro collegamento con un alto prodotto a banda di ritardo), in particolar modo se state usando anche il window scaling o se avete configurato una finestra TCP molto ampia. Se abilitate questa opzione, dovreste anche assicurarvi di impostare a 0 net.inet.tcp.inflight_debug (per disabilitare il debugging), e per un uso di produzione può essere utile impostare net.inet.tcp.inflight_min ad almeno 6144. Notate comunque che impostando dei livelli minimi alti può in pratica disabilitare la limitazione di banda, su alcuni tipi di collegamento. La funzionalità di limitazione della banda riduce la quantità di dati creati in rotte intermedie e fa circolare le code di pacchetti così come riduce la quantità di dati creati nella coda di interfaccia dell’host locale. Con meno pacchetti accodati, le connessioni interattive, specialmente sopra modem lenti, opereranno con lenti Round Trip Times (tempi di andata e ritorno). Comunque, nota che questa feature ha effetto solo sulla trasmissione dati (uploading / lato server). Non ha effetto sulla ricezione (downloading).
Modificare net.inet.tcp.inflight.stab non è raccomandato. Questo parametro è di default a 20, rappresentando 2 pacchetti massimi aggiunti al ritardo del prodotto della banda della finestra. La finestra addizionale è richiesta per stabilizzare l’algoritmo e migliorare la risposta alle condizioni che cambiano ma può risultare in tempi lunghi sui ping sopra link lenti (anche se molto più lento di quello che otterresti senza l’algoritmo di inflight). In questi casi, puoi voler ridurre questo parametro a 15, 10 o 5; e puoi anche ridurre net.inet.tcp.inflight.min (per esempio, a 3500) per ottenere l’effetto desiderato. Ridurre questi parametri dovrebbe essere fatto solo come ultima spiaggia.
kern.maxvnodesUn vnode è la rappresentazione di un file o una directory. Aumentare il numero di vnodi disponibili sul sistema operativo aumenterà l’I/O di disco. Normalmente questo viene gestito dal sistema operativo e non deve essere cambiato. In pochi casi dove l’I/O di disco è un collo di bottiglia ed il sistema sta finendo i suoi vnodi, questo parametro sarà aumentato. L’aumento di RAM libera ed inattiva sarà tenuto in conto.
Per vedere il numero corrente di vnodi in uso:
# sysctl vfs.numvnodes
vfs.numvnodes: 91349Per vedere il numero massimo di vnodi:
# sysctl kern.maxvnodes
kern.maxvnodes: 100000Se l’uso del nodo corrente è vicino alla fine, aumentare kern.maxvnodes di un valore di 1.000 è probabilmente una buona idea. Tenete un occhio sul numero di vfs.numvnodes. Se scala al massimo, kern.maxvnodes dovrà essere incrementato ancora. Dovrebbe essere visibile con top(1) uno spostamento nell’uso della memoria. Molta memoria dovrebbe essere attiva.
Non importa con quanta cura pianifichi tutto, a volte un sistema non funziona come ti aspetti. Se ti trovi ad avere bisogno di maggiore spazio di swap, è abbastanza semplice aggiungerlo. Ci sono tre modi per aumentare lo spazio di swap: aggiungere un nuovo disco rigido, abilitare lo swap su NFS, e creare un file di swap su una partizione esistente.
Per informazioni su come criptare lo spazio di swap, quali opzioni esistono e perchè dovrebbe essere fatto, vedere la sezione swap-encrypting del Manuale.
Il modo migliore per aggiungere dello swap, ovviamente, è usare questa come scusa per aggiungere un altro disco rigido. Puoi sempre aggiungere un nuovo disco, dopo tutto. Se puoi fare così, vai a rileggere la discussione sullo spazio di swap nella Configurazione Iniziale del Manuale per alcuni suggerimenti su come organizzare al meglio lo spazio di swap.
Lo swap su NFS è consigliato solo se non hai un disco locale su cui realizzare lo swap. Lo swap via NFS è limitato dalla larghezza di banda disponibile sulla rete e aggiunge ulteriore lavoro per il server NFS.
Puoi creare un file delle dimensioni specifiche per usarlo come file di swap. In questo nostro esempio useremo un file di 64MB chiamato /usr/swap0. Puoi usare qualsiasi nome vuoi, ovviamente.
Accertati che il tuo file di configurazione del kernel includa il memory disk driver (md(4)). È di default nel kernel GENERIC.
device md # Memory "disks"
Crea un file di swap (/usr/swap0):
# dd if=/dev/zero of=/usr/swap0 bs=1024k count=64Imposta i permessi appropriati su (/usr/swap0):
# chmod 0600 /usr/swap0Riavvia la macchina o per abilitare il file di swap immediatamente scrivi:
# mdconfig -a -t vnode -f /usr/swap0 -u 0 && swapon /dev/md0È importante utilizzare le risorse hardware in maniera efficiente. Prima che ACPI fosse introdotto era difficile e per nulla flessibile per il sistema operativo gestire l’energia e le proprietà termiche del sistema. L’hardware era controllato dal BIOS e quindi l’utente aveva meno controllo e visibilità per il settaggio della gestione dell’energia. Una configurazione limitata era disponibile tramite Advanced Power Management (APM). La gestione dell’energia e delle risorse è uno dei concetti fondamentali di un moderno sistema operativo. Per esempio, puoi far sì che un sistema operativo faccia il monitoraggio dei limiti di sistema (e possibilmente ti avvisi) in caso la temperatura del sistema cresca in maniera incontrollata.
In questa sezione del Manuale di FreeBSD, ti forniremo informazioni esaustive circa ACPI. Alla fine saranno forniti maggiori riferimenti per ulteriori letture.
ACPI (Advanced Configuration and Power Interface) è uno standard scritto da un gruppo di venditori per fornire un’interfaccia standard per risorse hardware e gestione dell’energia (da qui il nome). È un elemento centrale nella configurazione diretta del sistema operativo e nella gestione dell’energia, ad esempio: fornisce più controllo e flessibilità al sistema operativo (OS). I sistemi moderni "stressano" i limiti delle interfacce correnti Plug and Play, prima della introduzione di ACPI. ACPI è il diretto successore di APM (Advanced Power Management).
La tecnologia Advanced Power Management (APM) controlla l’uso dell’energia di un sistema basandosi sulla sua attività. Il BIOS APM è fornito dal venditore del sistema ed è specifico alla piattaforma hardware. Un driver APM nell’OS media l’accesso all'Interfaccia Software APM che permette la gestione dei livelli di energia. APM dovrebbe essere usato per sistemi prodotti nel o prima dell’anno 2000.
Ci sono quattro problemi maggiori in APM. Primo, la gestione dell’energia è fatta dal BIOS (specifico del venditore) e l’OS non ne ha conoscenza. Un esempio di questo è quando l’utente imposta i valori di pausa per un disco nell’APM BIOS, che quando vengono ecceduti, il BIOS rallenta il disco, senza il consenso dell’OS. Secondo, la logica di APM è integrata nel BIOS, e opera al di fuori lo scopo dell’OS. Questo significa che gli utenti possono riparare i problemi nel loro BIOS APM facendo un flash di una nuova memoria nel ROM; il che è una procedura molto difficile con il pericolo potenziale di lasciare il sistema in uno stato irrecuperabile se fallisce. Terzo, APM è una tecnologia specifica del venditore il che significa che c’è un sacco di duplicazione degli sforzi e bachi trovati nel BIOS di un venditore che non possono essere risolti in altri. In ultima analisi, il BIOS APM non ha abbastanza spazio per implementare una politica sofisticata, o una che può adattarsi molto bene allo scopo della macchina.
Plug and Play BIOS (PNPBIOS) era inaffidabile in molte situazioni. PNPBIOS era una tecnologia a 16 bit, così il sistema operativo doveva usare l’emulazione a 16 bit per "interfacciarsi" con i metodi PNPBIOS.
Il driver APM di FreeBSD è documentato nella pagina di manuale apm(4).
Il driver acpi.ko è caricato di default all’avvio dal loader(8) e non dovrebbe essere compilato nel kernel. Il ragionamento dietro a questo è che è più facile lavorare coi moduli, ad esempio se si passa ad un altro acpi.ko senza fare un rebuild del kernel. Questo ha il vantaggio di rendere il testing più facile. Un altro motivo è che avviare ACPI dopo che un sistema è stato riavviato spesso non funziona bene. Se incontri dei problemi, puoi disabilitare completamente ACPI. Questo driver non dovrebbe e non può essere scaricato perchè il bus di sistema lo usa per diverse interazioni hardware. ACPI può essere disabilitato settando hint.acpi.0.disabled="1" in /boot/loader.conf o al prompt del loader(8).
ACPI ed APM non possono coesistere e dovrebbero essere usati separatamente. L’ultimo ad essere caricato terminerà se il driver nota che l’altro è già in funzione. |
ACPI può essere usato per mettere il sistema in modalità sleep con acpiconf(8), l’opzione -s ed un’opzione 1-5. La maggior parte degli utenti avranno bisogno solo di 1 o 3 (sospensione della RAM). L’opzione 5 farà un morbido shutdown che è la stessa azione di:
# halt -pSono disponibili altre opzioni via sysctl(8). Controlla la pagina man di acpi(4) e acpiconf(8) per maggiori informazioni.
ACPI è un modo fondamentalmente nuovo di utilizzare dispositivi, gestire le risorse elettriche, e fornire accesso standardizzato all’hardware gestito precedentemente dal BIOS. Si stanno facendo progressi per far funzionare ACPI su tutti i sistemi, ma continuano ad apparire bachi nel codice del Linguaggio Macchina ACPI (AML), incompletezza nel sottosistema kernel di FreeBSD, e bachi nell’interprete ACPI-CA di Intel®.
Questo documento è creato per aiutarti ad assistere i manutentori di ACPI di FreeBSD nell’identificare le cause primarie dei problemi che riscontri e debuggare e sviluppare una soluzione. Grazie per l’attenzione e speriamo di poter risolvere i problemi del tuo sistema.
Prima di sottomettere un problema, accertati di avere in esecuzione l’ultima versione del BIOS e, se disponibile, la versione del firmware del controller integrato. |
Per quelli di voi che vogliono sottomettere un problema subito, per favore inviate la seguente informazione a freebsd-acpi@FreeBSD.org:
Descrizione del comportamento affetto da bachi, inclusi il tipo di sistema ed il modello e tutto quello che fa sì che il baco appaia. Inoltre, per favore annotati il più accuratamente possibile quando il baco è iniziato ad apparire se è nuovo per il tuo sistema.
L’output del comando dmesg(8) dopo boot -v, incluso ogni messaggio di errore generato dal tuo sistema mentre investigavi questo baco.
L’output del comando dmesg(8) dopo boot -v con ACPI disabilitato, se disabitarlo ti aiuta a rimettere a posto il sistema.
L’output di sysctl hw.acpi. Anche questo è un buon modo di figurarti quali caratteristiche il tuo sistema offre.
URL dove il tuo ACPI Source Language (ASL) risiede. Non inviare la ASL direttamente alla lista dato che può essere molto grande. Generate una copia della vostra ASL eseguendo questo comando:
# acpidump -dt > name-system.asl(Sostituite name con la vostra login ed il modello/manifattura del sistema. Ad esempio njl-FooCoo6000.asl)
Molti degli sviluppatori seguono la mailing list su FreeBSD-CURRENT ma per favore sottomettete i vostri problemi a mailing list su ACPI in FreeBSD per essere sicuri che siano visti. Per favore siate pazienti, abbiamo tutti lavori full-time altrove. Se i vostri bachi non sono chiarissimi, vi chiederemo di sottomettere un PR attraverso send-pr(1). Quando si invia un PR, per favore includete le stesse informazioni sopracitate. Questo aiuterà a tracciare il problema e risolverlo. Non inviare un PR senza prima inviare una email a mailing list su ACPI in FreeBSD, dato che noi usiamo PR come promemoria di problemi esistenti, non come meccanismo di reporting. È probabile che i vostri problemi siano stati riportati da qualcun altro prima.
ACPI è presente su tutti i computer moderni che conformi all’architettura ia32(x86), ia64 (Itanium), e amd64 (AMD). L’intero standard ha molte caratteristiche che includono la gestione della performance della CPU, il controllo dei piani energetici, delle zone termiche, delle batterie del sistema, controller incorporati, ed enumerazione dei bus. Molti sistemi implementano meno dello standard completo. Per esempio, un sistema desktop di solito implementa le parti di enumerazione dei bus mentre un laptop potrebbe avere il raffreddamento ed anche il supporto alla gestione della batteria. I laptop hanno anche sospensioni e riavvii, con la loro complessità associata.
Un sistema ACPI-compliant ha molte componenti. Il BIOS ed i venditori di chipset forniscono varie tabelle fisse in memoria (ad esempio FADT) che specificano cose come la mappa APIC (usata per SMP), i registri di configurazione, e semplici valori di configurazione. Inoltre viene fornita una tabella di codici di byte (la Differentiated System Description Table DSDT) per specificare uno spazio dei nomi ad albero di dispositivi e metodi.
Il driver ACPI deve fare il parse delle tabelle fisse, implementare un interprete per il codice di byte, e modificare i device driver ed il kernel per accettare informazioni dal sottosistema ACPI. Per FreeBSD, Intel® ha fornito un interprete (ACPI-CA) che è condiviso fra Linux e NetBSD. Il path al codice sorgente ACPI-CA è src/sys/contrib/dev/acpica. Il codice che permette ad ACPI-CA di lavorare con FreeBSD è in src/sys/dev/acpica/Osd. Finalmente, i driver che implementano vari dispositivi ACPI si trovano in src/sys/dev/acpica.
Affincè ACPI funzioni correttamente tutte le parti devono funzionare correttamente. Ci sono alcuni problemi comuni, in ordine di frequenza di apparizione, ed alcuni possibili workaround o mezzi per aggiustarli.
In alcuni casi, ripartire dopo una operazione di sospensione, fa sì che il mouse non riparta. Un noto workaround è aggiungere hint.psm.0.flags="0x3000" al file /boot/loader.conf. Se questo non funziona allora per favore considera l’invio di un report del baco come descritto in precedenza.
ACPI ha tre stati di sospensione RAM (STR), S1-S3 ed un stato di sospensione disco (STD), chiamato S4. S5 è il "soft off" ed è il normale stato in cui il tuo sistema si trova quando è collegato ma non acceso. S4 può essere implementato in due modi separati. S4BIOS è una sospensione BIOS-assistita da disco. S4OS è implementato direttamente dal sistema operativo.
Inizia a controllare sysctl hw.acpi per le entry relative alla sospensione. Questi sono i risultati per un Thinkpad:
hw.acpi.supported_sleep_state: S3 S4 S5
hw.acpi.s4bios: 0Questo significa che possiamo usare acpiconf -s per testare S3, S4OS, S5. Se s4bios fosse stato uno (1), avremmo supporto a S4BIOS invece di S4OS.
Quando si testa la sospensione/riavvio, inizia con S1, se supportato. È più probabile che funzioni questo stato dato che non richiede molto supporto dal driver. Nessuno ha implementato S2, ma se tu lo hai, è simile a S1. La prossima cosa da provare è S3. Questo è lo stato più profondo STR e richiede molto supporto dal driver per reinizializzare il tuo hardware. Se hai problemi a riavviarlo, sentiti libero di segnalarlo via mail alla lista mailing list su ACPI in FreeBSD ma non aspettarti che il problema sia risolto dato che ci sono molti driver/hardware che hanno bisogno di test e di lavoro aggiuntivo.
Per aiutare ad isolare il problema, rimuovi quanti più driver possibile dal tuo kernel. Se funziona, puoi scoprire quale driver causa il problema caricando dei driver fino a che il problema si ripresenta. Tipicamente i driver binari come nvidia.ko, i driver di display di X11, e USB avranno la maggior parte dei problemi mentre interfacce Ethernet funzioneranno bene. Se puoi caricare/scaricare driver correttamente, puoi automatizzare questo piazzando i comandi appropriati in /etc/rc.suspend e /etc/rc.resume. C’è un esempio commentato su come caricare e scaricare un driver. Prova a impostare hw.acpi.reset_video a zero (0) se il tuo display è confuso dopo il riavvio. Prova a impostare valori più lunghi o corti per hw.acpi.sleep_delay per vedere se aiuta.
Un’altra cosa da provare è caricare una distribuzione Linux recente con supporto ACPI e testare il loro supporto sospensione/riavvio sullo stesso hardware. Se funziona su Linux, è probabile che sia un problema driver relativo a FreeBSD e restringere il campo di indagine su quale driver causi il problema può aiutare a risolvere il problema. Notate che i manutentori di ACPI non mantengono altri driver (ad esempio suono, ATA, etc.) così ogni lavoro fatto sull’identificazione del problema del driver dovrebbe alla fine essere risolto dalla lista mailing list su FreeBSD-CURRENT e inviato via mail al manutentore del driver. Se ti senti avventuroso, vai avanti e inizia a porre qualche printf(3) in un driver che dà problemi per tracciare in quale driver nella sua funzione di resume vada in palla.
Alla fine, cerca di disabilitare ACPI ed ad abilitare APM invece. Se la sospensione ed il riavvio funziona con APM, è meglio che tu continui con APM, specialmente su hardware vecchio (pre-2000). Ci vuole un pò di tempo per i venditori per ottenere un supporto corretto all’ACPI e l’hardware più vecchio è più probabile che abbia problemi BIOS con ACPI.
La maggior parte dei blocchisono causati da interrupt persi o da una tempesta di interrupt. I chipset hanno un sacco di problemi su come il BIOS configuri gli interrupt prima del boot, la correttezza delle tabelle ACPI (MADT) ed il routing del System Control Interrupt (SCI).
Le tempeste di interrupt possono essere distinte da interrupt persi controllando l’output di vmstat -i e guardando alla linea che riguarda acpi0. Se il contatore sta avanzando più di un paio di secondi per volta, hai una tempesta di interrupt. Se il sistema si blocca, cerca di di entrare in DDB (CTRL+ALT+ESC sulla console) e digita show interrupts.
Il modo migliore in caso di problemi di interrupt è provare a disabilitare il supporto APIC con hint.apic.0.disabled="1" in loader.conf.
I panici sono relativamente rari per ACPI e sono il primo problema ad essere corretto. Il primo passo da fare è riprodurre il panico (se possibile) ed ottenere un backtrace. Segui l’avvertimento per abilitare options DDB e imposta una console seriale (vedi la Accesso al Debugger DDB dalla Linea Seriale) o imposta una partizione di dump(8). Puoi ottenere un backtrace in DDB con tr. Se hai scritto a mano il backtrace, accertati di ottenere le ultime cinque (5) e le prime cinque (5) linee nella traccia.
Poi, prova ad isolare il problema facendo boot con ACPI disabilitato. Se funziona, puoi isolare il sottosistema ACPI usando vari valori di debug.acpi.disable. Leggi la pagina di manuale di acpi(4) per alcuni esempi.
Prima, cerca di impostare hw.acpi.disable_on_poweroff="0" in loader.conf(5). Questo fa sì che ACPI abbia disabilitato alcuni eventi durante il processo di shutdown. Alcuni sistemi hanno bisogno di impostare questo valore a 1 (il default) per la stessa ragione. Questo di solito aggiusta il problema di un sistema che si accende spontaneamente dopo una sospensione o uno spegnimento.
Se hai altri problemi con ACPI (lavorare con un docking station, dispositivi non trovati, ecc.), per favore invia via mail una descrizione anche alla mailing list; comunque, alcune di queste questioni possono essere correlate a parti del sottosistema ACPI così può volerci un pò prima che siano implementate. Per favore sii paziente e preparato a testare le patch che ti vengono inviate.
acpidump, e IASLIl più comune problema è il BIOS di venditori che forniscono bytecode incorretto (o addirittura con bachi). Questo si deduce usualmente da messaggi del kernel come questo:
ACPI-1287: *** Error: Method execution failed [\\_SB_.PCI0.LPC0.FIGD._STA] \\
(Node 0xc3f6d160), AE_NOT_FOUNDSpesso puoi risolvere questi problemi aggiornando il tuo BIOS all’ultima versione. La maggior parte dei messaggi di console non indica nulla di notevole, ma se hai altri problemi come lo stato della batteria non funzionante, questi sono un buon inizio per iniziare a cercare problemi in AML. Il bytecode, noto come AML, è compilato da un insieme di codici sorgenti chiamato ASL. L’AML, è trovato nella tabella nota come come DSDT. Per trovare una copia del tuo ASL usa acpidump(8). Dovresti usare entrambe le opzioni -t (mostra i contenuti della tabella fissa) e la -d (disassembla AML ad ASL). Vedi la sezione Fornire Informazione di Debug per un esempio della sintassi.
Il tuo primo controllo che puoi fare è ricompilare il tuo ASL per controllare errori. Possono essere ignorati i 'warning' ma gli errori sono bachi che impediranno all’ACPI di funzionare correttamente. Per ricompilare il tuo ASL, usa il comando seguente:
# iasl your.aslAlla lunga, il nostro obiettivo è avere ACPI che funzioni per tutti senza intervento. A questo punto, comunque stiamo ancora sviluppando workaround per errori comuni fatti dal venditore del BIOS. L’interprete Microsoft® (acpi.sys e acpiec.sys) non è strettamente conforme agli standard, e così molti venditori BIOS che testano solo ACPI sotto Windows® non aggiustano mai il loro ASL. Vogliamo continuare a identificare e documentare esattamente quali comportamenti non standard sono concessi dall’interprete Microsoft® e replicarlo cosicchè FreeBSD può funzionare senza forzare gli utenti ad usare ASL. Come workaround e per aiutarci ad identificare il comportamento puoi fissare la ASL manualmente. Se questo funziona per favore invia un diff(1) del vecchio e del nuovo ASL, cosicchè possiamo lavorare attorno al comportamento bacato di ACPI-CA e così rimettere a posto il necessario.
Qui c’è una lista di messaggi di errori comuni, le loro cause e come fissarli:
Alcuni AML assumono che il mondo consiste di varie versioni Windows®. Puoi far sì che FreeBSD simuli qualsiasi OS per vedere se questo risolve il problema che hai. Un modo facile per sovrascrivere questo è porre hw.acpi.osname="Windows 2001" in /boot/loader.conf o altre stringhe simili che trovi nella ASL.
Alcuni metodi non ritornano esplicitamente un valore come i requisiti standard. Mentre ACPI-CA non gestisce questo, FreeBSD ha un workaround che permette di ritornare i valori implicitamente. Puoi anche aggiungere espliciti Valori di Ritorno dove si richiede se sai quale valore dovrebbe essere ritornato. Per forzare iasl a compilare l’ASL usa il flag -f.
Dopo che personalizzi il tuo your.asl, potresti volerlo compilare, esegui:
# iasl your.aslPuoi aggiungere il flag -f per forzare la creazione dell’AML, anche se ci sono errori durante la compilazione. Ricorda che alcuni errori (ad esempio valori di Ritorno mancanti) sono automaticamente riaggiustati dall’interprete.
DSDT.aml è il nome del file di default del comando iasl. Puoi caricare questo invece della copia difettosa del tuo BIOS (che è ancora presente in memoria) editando il file /boot/loader.conf come segue:
acpi_dsdt_load="YES" acpi_dsdt_name="/boot/DSDT.aml"
Assicurati di copiare il tuo file DSDT.aml nella directory /boot.
Il driver ACPI ha una facility di debug molto utile. Permette di specificare un insieme di sottosistemi come anche un livello di verbosità. I sottosistemi che desideri debuggare sono specificati come "strati" e sono divisi in componenti ACPI-CA (ACPI_ALL_COMPONENTS) e supporto hardware ACPI (ACPI_ALL_DRIVERS). La verbosità dell’output di debug è specificata come "livello" e varia da ACPI_LV_ERROR (riporta solo gli errori) ad ACIP_LV_VERBOSE (tutto). Il "livello" è una bitmask che fa sì che molte opzioni possano essere impostate una alla volta, separate da spazi. In pratica, puoi usare una console seriale per loggare l’output se è così lungo da riempire il buffer di messaggi della console. Una lista completa degli strati individuali e dei livelli è disponibile nella pagina man acpi(4).
L’output di debug non è abilitato di default. Per abilitarlo, aggiungi options ACPI_DEBUG al tuo file di configurazione del kernel se ACPI è compilato nel kernel. Puoi aggiungere ACPI_DEBUG=1 al tuo /etc/make.conf per abilitarlo in modo globale. Se è un modulo, puoi ricompilare soltanto il tuo modulo acpi.ko come segue:
# cd /sys/modules/acpi/acpi
&& make clean &&
make ACPI_DEBUG=1Installa acpi.ko in /boot/kernel ed aggiungi il tuo livello desiderato e gli strati in loader.conf. Questo esempio abilita i messaggi per tutti i componenti ACPI-CA e tutti i driver hardware ACPI (CPU, LID, etc.). Produrrà solo messaggi di errore, i meno verbosi.
debug.acpi.layer="ACPI_ALL_COMPONENENTS ACPI_ALL_DRIVERS" debug.acpi.level="ACPI_LV_ERROR"
Se l’informazione che vuoi ottenere è prodotta da un evento specifico (ad esempio, una sospensione ed un riavvio), puoi tralasciare i cambiamenti di loader.conf ed invece usare sysctl per specificare lo strato ed il livello dopo il boot e preparare il tuo sistema per l’evento specifico. I sysctl sono nominati allo stesso modo dei parametri in loader.conf.
Maggiori informazioni su ACPI possono essere trovate nei seguenti posti:
Gli archivi della mailing list ACPI http://lists.freebsd.org/pipermail/freebsd-acpi/
I vecchi archivi della mailing list ACPI http://home.jp.FreeBSD.org/mail-list/acpi-jp/
Le pagine man di FreeBSD: acpi(4), acpi_thermal(4), acpidump(8), iasl(8), acpidb(8)
Le risorse di debugging di DSDT. (Usa Compaq come esempio ma è sempre utile.)
Il processo di accensione di un computer e caricamento del sistema operativo viene detto "processo di avviamento", o semplicemente "avvio". La procedura di avvio di FreeBSD fornisce un alto grado di flessibilità nel personalizzare quello che succede quando avvii il sistema, dandoti la possibilità di scegliere tra diversi sistemi operativi installati sullo stesso computer, o anche tra diverse versioni dello stesso sistema operativo o tra diversi kernel installati.
Questo capitolo fornisce i dettagli sulle opzioni di configurazione che puoi impostare per personalizzare il processo di avvio di FreeBSD. Ciò comprende tutto quello che avviene fino a quando il kernel viene lanciato, vengono controllate le periferiche, e viene avviato init(8). Se non sei sicuro di sapere quando tutto questo accada, si tratta del momento in cui il colore del testo a video cambia da bianco brillante a grigio.
Dopo aver letto questo capitolo, saprai:
Quali sono i componenti del sistema di avvio di FreeBSD, e come interagiscono.
Le opzioni che puoi impostare per i componenti durante l’avviamento di FreeBSD per controllare il processo di avvio.
Le basi dei device.hints(5).
Solo per x86 Questo capitolo descrive la procedura di avvio di FreeBSD su sistemi Intel x86. |
Accendere un computer e far partire il sistema operativo pone un dilemma interessante. Per definizione, il computer non sa fare nulla finché non viene avviato il sistema operativo. Questo include anche l’esecuzione dei programmi dal disco. Dunque se il computer non può eseguire un programma da disco senza il sistema operativo, ed i programmi del sistema operativo sono sul disco, come viene avviato il sistema operativo?
Questo è un problema analogo a quello descritto nel libro Le Avventure del Barone di Munchausen. Un personaggio era caduto in una botola, e ne era uscito tirandosi su da sé (in inglese "bootstrap"), riuscendo nell’intento solo con i propri sforzi. Nei primi giorni dei calcolatori al meccanismo usato per caricare il sistema operativo fu applicato il termine bootstrap, ed in seguito venne abbreviato in "booting" (in italiano "avvio").
Su sistemi con hardware x86 il BIOS (Basic Input/Output System) è il responsabile del caricamento del sistema operativo. Per fare ciò, il BIOS cerca nel disco rigido il Master Boot Record (MBR), che deve essere in una specifica posizione sul disco. Il BIOS ha abbastanza conoscenze per caricare ed eseguire l’MBR, ed assume che l’MBR possa portare avanti il resto dei compiti relativi al caricamento del sistema operativo, possibilmente con l’aiuto del BIOS.
Il codice all’interno del MBR è di solito riferito come boot manager, specialmente quando interagisce con l’utente. In questo caso la maggior parte del suo codice è nella prima traccia del disco o direttamente nel file system dell’OS. (Il boot manager qualche volta viene chiamato anche boot loader, ma gli utenti di FreeBSD usano questo termine per una successiva fase di avvio.) Boot manager popolari sono boot0 (a.k.a. Boot Easy, il boot manager standard di FreeBSD), Grub, GAG, e LILO. (Solo boot0 è all’interno del MBR.)
Se hai solo un sistema operativo installato sui tuoi dischi allora sarà sufficiente il MBR standard del PC. Questo MBR cerca la prima slice avviabile (a.k.a. attiva) sul disco, e quindi esegue il codice in quella slice per caricare il resto del sistema operativo. Il MBR installato da fdisk(8), di default, è come un MBR. È basato su /boot/mbr.
Se hai installato più sistemi operativi sui tuoi dischi allora puoi installare un boot manager diverso, che mostra una lista dei diversi sistemi operativi, e ti permette di scegliere quale avviare. Nella prossima sezione ne vengono presentati due.
Il resto del sistema di avvio di FreeBSD è diviso in tre stadi. Il primo stadio viene eseguito dall’MBR, che sa solo il necessario per mettere il computer in un certo stato ed eseguire il secondo stadio. Quest’ultimo può fare poco di più, prima di eseguire il terzo. Il terzo stadio esaurisce il compito di caricare il sistema operativo. Il lavoro è diviso in queste tre parti perché gli standard dei PC pongono dei limiti alla dimensione dei programmi che possono essere eseguiti nei primi due stadi. Concatenando i compiti si permette a FreeBSD di fornire un loader più flessibile.
A questo punto viene avviato il kernel ed esso comincia a verificare i dispositivi e ad inizializzarli. Una volta che la procedura di avvio del kernel è finita, il kernel passa il controllo al processo utente init(8), che si assicura che i dischi siano in uno stato usabile. Poi init(8) avvia la configurazione delle risorse a livello utente che monta i file system, imposta le schede di rete per comunicare via rete, ed in generale fa partire tutti i processi che generalmente sono in esecuzione su un sistema FreeBSD all’avvio.
Il codice nel MBR o nel boot manager è solitamente riferito alla fase zero del processo di boot. Questa sezione discute dei due boot manager menzionati in precedenza: boot0 e LILO.
Il Boot Manager boot0: Il MBR installato dall’installer di FreeBSD o da boot0cfg(8), di default, si basa su /boot/boot0. (Il programma boot0 è molto semplice, poichè il programma nel può essere al più di 446 byte a causa della tabella della slice e dell’identificatore 0x55AA alla fine del MBR.) Se hai installato boot0 e hai più di un sistema operativo sui tuoi dischi, allora vedrai una schermata simile alla seguente nella fase di avvio:
F1 DOS
F2 FreeBSD
F3 Linux
F4 ??
F5 Drive 1
Default: F2Altri sistemi operativi, in particolare Windows®, sono noti per l’abitudine di sovrascrivere l’MBR esistente con il proprio. Se accade questo, o se vuoi rimpiazzare l’MBR pre-esistente con quello di FreeBSD puoi usare il seguente comando:
# fdisk -B -b /boot/boot0 dispositivodove dispositivo è il dispositivo dal quale vuoi avviare, come ad0 per il primo disco IDE, ad2 per il primo disco ide sul secondo canale, da0 per il primo disco SCSI, e così via. Se vuoi una configurazione ad hoc dell’MBR, usa boot0cfg(8).
Il Boot Manager LILO: Per installare questo boot manager affinchè possa avviare anche FreeBSD, avvia Linux e aggiungi le seguenti cose nel tuo file di configurazione /etc/lilo.conf:
other=/dev/hdXY table=/dev/hdX loader=/boot/chain.b label=FreeBSD
Specifica la partizione primaria di FreeBSD e il disco usando le direttive di Linux, rimpiazzando X con la lettera del dispositivo di Linux e Y con il numero della partizione primaria di Linux. Se stai usando un dispositivo SCSI, devi modificare /dev/hd in qualcosa simile a /dev/sd. La linea loader=/boot/chain.b può essere omessa se hai entrambi i sistemi operativi sullo stesso disco. Esegui /sbin/lilo -v per apportare le modifiche al sistema; verificando il relativo messaggio a video.
Concettualmente il primo ed il secondo stadio sono parte dello stesso programma, sulla stessa area del disco. Per limitazioni di spazio sono stati divisi in due, ma li installerai sempre insieme. Sono copiati dal file /boot/boot dall’installer o da bsdlabel (vedi sotto).
Questi sono posizionati fuori dai file system, nella prima traccia della slice di boot, a partire dal primo settore. Questo è il posto dove boot0, o qualsiasi altro boot manager, si aspetta di trovare un programma da avviare per continuare il processo di boot. Il numero di settori usati è facilmente determinabile dalla dimensione di /boot/boot.
boot1 è molto semplice, poiché può essere lungo solo 512 byte, e conosce solo lo stretto necessario del bsdlabel di FreeBSD, il quale memorizza le informazioni sulle slice, per trovare ed eseguire boot2.
boot2 è leggermente più sofisticato, e conosce il file system di FreeBSD abbastanza da potervi trovare dei file, e può fornire una semplice interfaccia per scegliere quale kernel o loader eseguire.
Poiché il loader è molto più complesso, e fornisce una gradevole interfaccia di facile utilizzo alla configurazione di avvio, boot2 in genere lo esegue, ma in precedenza era incaricato di lanciare il kernel direttamente.
>> FreeBSD/i386 BOOT
Default: 0:ad(0,a)/boot/loader
boot:Se mai avrai bisogno di rimpiazzare il boot1 ed il boot2 installati, usa bsdlabel(8):
# bsdlabel -B discoslicedove discoslice sono il disco e la slice dal quale vuoi effettuare l’avvio, come ad esempio ad0s1 per la prima slice sul primo disco IDE.
Modalità Pericolosamente Dedicata Se nella sintassi del comando bsdlabel(8) usi solo il nome del disco, come ad0, creerai un disco pericolosamente dedicato, senza slice. Quasi sicuramente non è questo quello che vuoi fare, quindi controlla due volte il comando bsdlabel(8) prima di premere Invio. |
Il loader è l’ultimo stadio della procedura di avvio divisa in tre, e si trova sul file system, generalmente come /boot/loader.
Il loader deve essere inteso come un metodo user-friendly per la configurazione di avvio, tramite l’uso di un insieme di comandi integrati facili da usare, sostenuto da un potente interprete, con un insieme di comandi più complessi.
Durante l’inizializzazione, il loader controllerà la console e i dischi, e cercherà di capire da quale disco si stia avviando. Imposterà le variabili di conseguenza, ed avvierà un interprete al quale potranno essere passati i comandi dell’utente in maniera interattiva o attraverso uno script.
Poi il loader leggerà /boot/loader.rc, che di default legge i settaggi di /boot/defaults/loader.conf il quale imposta dei valori di default ragionevoli per le variabili e inoltre /boot/loader.rc legge /boot/loader.conf per i cambiamenti locali a quelle variabili. In base a queste variabili loader.rc carica i moduli ed il kernel prescelti.
Infine, di default, il loader attende per 10 secondi la pressione di un tasto, ed avvia il kernel se non viene interrotto. Se invece viene interrotto, viene presentato all’utente un prompt in grado di comprendere un semplice insieme di comandi, dal quale l’utente può impostare precisamente le variabili, scaricare dalla memoria tutti i moduli, o caricarli, ed infine avviare o ri-avviare.
Questi sono i comandi usati più comunemente. Per una discussione completa su tutti i comandi disponibili, guarda loader(8).
Procede all’avvio del kernel se non viene interrotto nell’intervallo di tempo specificato, in secondi. Mostra un conto alla rovescia, e l’intervallo predefinito è di 10 secondi.
Procede immediatamente all’avvio del kernel, con le opzioni date, se ce ne sono, e con il nome del kernel specificato, se fornito.
Va avanti con la stessa configurazione automatica di moduli basati sulle variabili come accade al boot. Questo ha senso solo se prima usi unload, e cambi delle variabili, in generale kernel.
Mostra un messaggio d’aiuto letto da /boot/loader.help. Se l’argomento dato è index, allora elenca tutti gli argomenti disponibili.
Processa il file specificato. Il file viene letto, e interpretato riga per riga. Un errore blocca il comando include immediatamente.
Carica il kernel, il modulo del kernel, o il file del tipo specificato, con il nome specificato. Ogni argomento dopo nomefile viene passato al file.
Mostra un elenco dei file nel percorso dato, o nella directory root, se non ne viene specificato uno. Se è specificato -l, verranno mostrate anche le dimensioni dei file.
Elenca tutti i dispositivi dai quali potrebbe essere possibile caricare moduli. Se viene specificata l’opzione -v, verranno stampati dettagli maggiori.
Mostra i moduli caricati. Se viene specificato -v, verranno stampati dettagli maggiori.
Mostra i file specificati, con una pausa ad ogni pagina visualizzata.
Riavvia immediatamente il sistema.
Imposta le variabili di ambiente del loader.
Rimuove tutti i moduli caricati.
Qui ci sono alcuni esempi pratici sull’uso del loader:
Per avviare semplicemente il vostro kernel abituale, ma in modalità singolo utente:
boot -sPer scaricare dalla memoria i moduli e il kernel usuali, e poi caricare solo il vecchio (o un altro) kernel:
unload
load kernel.oldPuoi usare kernel.GENERIC per riferirti al kernel generico che viene fornito nel disco d’installazione, o kernel.old per riferirti al kernel installato precedentemente (quando hai aggiornato o configurato il kernel, ad esempio).
Usa il comando seguente per caricare i tuoi soliti moduli con un altro kernel: |
Per caricare uno script di configurazione del kernel (uno script automatizzato che faccia le cose che faresti tu normalmente configurando il kernel all’avvio):
load -t userconfig_script /boot/kernel.confUna volta che il kernel è stato caricato dal loader (come di consueto) o da boot2 (scavalcando il loader), esso esamina i suoi flag di avvio, se ce ne sono, e aggiusta il suo comportamento come necessario.
Qui ci sono alcuni dei più comuni flag di avvio:
-adurante l’inizializzazione del kernel, chiede il dispositivo da montare come file system di root.
-Cavvia da CDROM.
-cesegue UserConfig, il programma di configurazione del kernel all’avvio
-savvia in modalità singolo utente
-vaumenta la verbosità durante l’avvio del kernel
Ci sono altri flag di avvio, leggi boot(8) per maggiori informazioni su di essi. |
Questa è una caratteristica di FreeBSD 5.0 e successive che non esiste nelle versioni precedenti. |
Durante l’avvio iniziale del sistema, il boot loader(8) leggerà il file device.hints(5). Questo file contiene informazioni di avvio per il kernel dette variabili, e talvolta indicate come "device hints", suggerimenti per i dispositivi. Questi "device hints" vengono usati dai driver per la configurazione delle varie periferiche.
I device hints possono essere specificati anche nel prompt del terzo stadio del boot loader. Le variabili possono essere aggiunte usando il comando set, rimosse con unset, e visualizzate con show. Inoltre, in questo modo, le variabili impostate nel file /boot/device.hints possono essere scavalcate. I device hint inseriti in questo modo non sono permanenti e verranno dimenticati al riavvio seguente.
Una volta che il sistema è stato avviato, può essere usato il comando kenv(1) per mostrare tutte le variabili.
La sintassi per il file /boot/device.hints è una variabile per riga, usando il solito cancelletto "#" per indicare i commenti. Le linee sono costruite come segue:
hint.driver.unit.keyword="valore"La sintassi nel terzo stadio del boot loader è:
set hint.driver.unit.keyword=valoredriver è il nome del driver per il dispositivo, unit è il numero di unità per quel driver, e keyword è la parola chiave per quell’hint. La parola chiave può essere:
at: specifica il bus sul quale è collegato il dispositivo.
port: specifica l’indirizzo iniziale di I/O che deve essere usato.
irq: specifica il numero di interrupt request che deve essere usato.
drq: specifica il numero del canale DMA.
maddr: specifica l’indirizzo di memoria fisico occupato dal dispositivo.
flags: imposta vari bit di flag per il dispositivo.
disabled: se impostato a "1" il dispositivo è disabilitato.
I driver possono accettare (o richiedere) più hints di quelli elencati qui, si raccomanda quindi di verificare la loro pagina di manuale. Per maggiori informazioni, consulta le pagine man device.hints(5), kenv(1), loader.conf(5), e loader(8).
Una volta che il kernel ha finito di avviarsi, trasferisce il controllo al processo utente init, che si trova in /sbin/init, o al programma specificato nella variabile init_path nel loader.
La sequenza di riavvio automatica assicura che i file system disponibili sul sistema siano consistenti. Se qualcuno non lo è, e fsck(8) non può risolvere le inconsistenze, init(8) abbandona il sistema in modalità singolo utente per permettere all’amministratore di sistema di occuparsi dei problemi direttamente.
Questa modalità può essere raggiunta attraverso la sequenza di riavvio automatica, o tramite l’avvio da parte dell’utente con l’opzione -s o impostando la variabile boot_single nel loader.
Si può arrivare ad essa anche richiamando shutdown(8) senza l’opzione per il riavvio (-r) o per l’arresto (-h), dalla modalità multi utente.
Se la console del sistema è settata come insecure in /etc/ttys, allora il sistema richiede la password di root prima di entrare in modalità singolo utente.
# name getty type status comments # # Se la console è settata come "insecure", allora init chiederà # la password di root per andare in modalità singolo utente . console none unknown off insecure
Avere una console |
Se init(8) ritiene che i tuoi file system siano in ordine, o quando l’utente ha terminato il lavoro in modalità singolo utente, il sistema entra in modalità multi utente, nella quale inizia la configurazione delle risorse del sistema.
Il sistema di configurazione delle risorse legge i valori predefiniti della configurazione da /etc/defaults/rc.conf, e i dettagli specifici del sistema da /etc/rc.conf, e poi procede al montaggio dei file system del sistema elencati in /etc/fstab, avvia i servizi di rete, avvia vari demoni di sistema, ed infine esegue gli script di avvio dei pacchetti installati localmente.
La pagina man di rc(8) è un buon riferimento per la configurazione delle risorse del sistema, poiché esamina gli script stessi.
Al momento di uno spegnimento controllato, tramite shutdown(8), init(8) cercherà di eseguire lo script /etc/rc.shutdown, e poi procederà ad inviare a tutti i processi il segnale TERM, e successivamente il segnale KILL a quelli che non sono terminati in tempo.
Per spegnere una macchina FreeBSD su architetture e sistemi che supportano la gestione dell’energia, usa semplicemente il comando shutdown -p now per disattivare immediatamente l’alimentazione. Per riavviare semplicemente un sistema FreeBSD, usa solo shutdown -r now. Avrai bisogno di essere root o un membro del gruppo operator per eseguire shutdown(8). Possono essere usati anche i comandi halt(8) e reboot(8), fai riferimento alle loro pagine di man ed a quella di shutdown(8) per maggiori informazioni.
La gestione dell’energia richiede il supporto acpi(4) nel kernel o caricato come modulo. |
Questo capitolo dà un’introduzione di base sui concetti dei sistemi di sicurezza, alcune buone regole di comportamento e alcuni argomenti avanzati per FreeBSD. Molti degli argomenti qua trattati possono essere applicati anche ai sistemi e alla sicurezza su Internet in generale. Internet non è più il luogo "amichevole" dove ognuno vuole essere il tuo gentile vicino. Mettere in sicurezza il tuo sistema è un imperativo per la protezione dei tuoi dati, della tua proprietà intelletuale, del tuo tempo e molto altro dalla mano di hacker e simili.
FreeBSD dà un insieme di utility e di meccanismi per assicurare l’integrità e la sicurezza del tuo sistema e della tua rete.
Dopo la lettura di questo capitolo, conoscerai:
Concetti di base dei sistemi di sicurezza, rispetto a FreeBSD.
Vari meccanismi di crittografia disponibili in FreeBSD, come DES e MD5.
Come configurare l’autenticazione OTP (password a singolo uso).
Come configurare i TCP Wrapper per l’uso con inetd.
Come configurare KerberosIV su FreeBSD.
Come configurare Kerberos5 su FreeBSD 5.0 o successivi.
Come configurare IPsec e creare una VPN tra macchine FreeBSD/Windows®.
Come configurare e usare OpenSSH, l’implementaizone SSH usata da FreeBSD.
Cosa sono le ACL del file system e come usarle.
Come usare l’utility Portaudit per monitorare i pacchetti software di terze parti installati dalla Ports Collection.
Come utilizzare le pubblicazioni sugli avvisi di sicurezza di FreeBSD.
Avere un’idea di cosa sia il Process Accounting e come abilitarlo su FreeBSD.
Prima di leggere questo capitolo dovresti:
Capire concetti base di FreeBSD e Internet.
Altri argomenti inerenti la sicurezza sono trattati in altre parti di questo libro. Ad esempio i meccanismy di MAC sono discussi in Controllo di Accesso Vincolato e la gestione dei firewall in Firewall.
La sicurezza è una funzione che inizia e finisce con l’amministratore di sistema. Nonostante ogni sistema multi-utente UNIX® BSD abbia della sicurezza insita, il lavoro di costruire e mantenere meccanismi di sicurezza aggiuntivi in modo da mantenere "onesti" gli utenti è probabilmente uno dei maggiori lavori di un amministratore di sistema. La macchine sono sicure solo quanto le si rende e le richieste di sicurezza si scontrano sempre con l’umana necessità per la comodità. I sistemi UNIX®, in generale, sono capaci di eseguire un gran numero di processi contemporanei e ognuno di questi processi opera come server - nel senso che entità esterne possono connettersi e parlarci. Mentre i mini e i mainframe di ieri diventano i desktop di oggi, mentre i computer diventano interconnessi e internet-connessi, la sicurezza diventa un problema sempre maggiore.
La sicurezza di un sistema riguarda anche il gestire varie forme di attacco, compresi attacchi che tentano di bloccare, o comunque rendere inusabile, il sistema, anche se non necessariamente cercano di compromettere l’account di root root ("rompere root"). I problemi di sicurezza possono essere suddivisi in svariate categorie:
Attacchi che limitano la disponibilità dei servizi ("Denial of service" o, in breve, DoS).
Compromissione degli account utente.
Compromissione di root tramite server accessibili.
Compromissione di root tramite gli account utente.
Crazione di backdoor (letteralmente "porte sul retro", ovvero accessi secondari personalizzati).
Un attacco DoS è un’azione che priva la macchina di risorse. Tipicamente un attacco DoS è un meccanismo a forza-bruta che tenta di bloccare e comunque rendere inusabile una macchina travolgendo di richieste i server che rende disponibili o direttamente lo stack di rete. Alcuni attacchi DoS tentano di trarre vantaggio da bug nello stack di rete per bloccare la macchina con un singolo pacchetto. Questo genere di attacchi può evitato solo mettendo a posto il bug direttamente nel kernel. Gli attacchi sui server possono spesso essere evitati specificando con attenzione dei limiti sul carico che i server stessi devono accettare in caso che il sistema lavori in condizioni avverse. Gli attacchi a forza-bruta generati da un’intera rete di attaccanti sono più difficili da gestire. Ad esempio un attacco con pacchetti in spoof (ovvero con il campo mittente falsato) è praticamente impossibile da fermare, a meno di staccare del tutto il sistema da Internet. Potrà anche non fermare la tua macchina, ma sicuramente può saturare la tua connessione Internet.
La compromissione di un account utente è ancora più comune di un attacco DoS. Molti sysadmin usano ancora i server standard telnetd, rlogind, rshd e ftpd sulle loro macchine. Questi programmi, normalmente, non usano connessioni crittate. Il risultato è che quando hai una base utenti di medie dimensioni, uno o più degli utenti connessi al tuo sistema da remoto (il modo più comune e conveniente per collegarsi a un sisetma) avrà una password compromessa da un’operaizone di sniffing. Gli amministratori di sistema attenti controllano i registri degli accessi remoto cercando indirizzi sospetti anche tra gli accessi permessi.
Bisogna sempre dare per scontato che una volta che un attaccante ha accesso ad un account utente, può rompere anche root. In realtà, comunque, in un sistema ben configurato e mantenuto, questo non è necessariamente vero. La distinzione è importante perché senza accesso a root l’attaccante in genere non può nascondere le proprie tracce e può, alla peggio, rovinare i file dell’utente o mandare la macchina in crash. La compromissione degli account utente è molto comune dato che gli utenti tendono a non prendere precauzioni tanto quanto gli amministratori di sistema.
Gli amministratori di sistema devono ricordare che su una macchina ci sono potenzialmente molti modi per rompere root. L’attaccante potrebbe conoscere la password di root, potrebbe trovare un bug in un programma server in esecuzione con diritti di root e sfruttarlo per entrare da remoto, oppure una volta ottenuto un account utente potrebbe fare lo stesso con un bug in un programma con suid root. Se un attaccante rompe root su una macchina, potrebbe non aver bisogno di installare una backdoor. Molti dei buchi per l’accesso come root trovati (e chiusi) fino ad oggi richiedono un considerevole lavoro da parte dell’attaccante per pulire le tracce lasciate, quindi molti attaccanti installano delle backdoor. Una backdoor dà all’attaccante un modo semplice per riottenere accesso root al sistema, ma danno anche un modo semplice per individuare l’intrusione, all’amministratore di sistema furbo. Rendere impossibile installare backdoor all’attaccante potrebbe in realtà diminuire la sicurezza del sistema, dato che comunque non chiuderà il buco che l’attaccante ha trovato la prima volta.
Le soluzioni di sicurezza devono sempre essere implementate con un approccio multi-strato a "cipolla" e possono essere categorizzate come segue:
Rendere sicuro root e gli account dello staff.
Rendere sicuri i server e i binari suid/sgid in esecuzione come root.
Rendere sicuri gli account utente.
Rendere sicuro il file delle password.
Rendere sicuro il nucleo del kernel, i device raw e il file system.
Individuazione rapida delle modifiche non appropriate fatte al sistema.
Paranoia.
La prossima sezione di questo capitolo coprirà questi punti in maggior dettaglio.
Comandi o Protocolli In questo documento useremo testo grassetto per riferirci ad applicazioni e testo |
Le sezioni seguenti descrivono i metodi per rendere sicuro il vostro sistema FreeBSD che sono stati menzionati nella sezione precedente di questo capitolo.
root e gli account dello staff.Innanzitutto, non preoccuparti di rendere sicuri gli account di staff se non hai reso sicuro l’account root. La maggior parte dei sistemi hanno una password assegnata per l’account root. La prima cosa che devi dare per assunta è che la password è sempre compromessa. Questo non significa che devi togliere la password; la password è quasi sempre necessaria per l’accesso dalla console della macchina. Quello che questo significa è che non dovresti render possibile l’uso di questa password tranne che da console e possibilmente neanche dal comando su(1). Per esempio, assicurati che le tue pty siano specificate come insecure nel file /etc/ttys in modo che accessi diretti root tramite telnet o rlogin non siano permessi. Se usi altri servizi di login come ad esempio sshd, fai in modo che accessi diretti come root siano vietati anche per questi. Puoi farlo modificando il file /etc/ssh/sshd_config e assicurandoti che PermitRootLogin sia impostato a NO. Tieni conto di tutti i modi di accesso - servizi come ad esempio FTP vengono spesso trascurati. Login root diretti dovrebbero essere permessi solo tramite la console di sistema.
Ovviamente, come sysadmin (amministratore di sistema) hai bisogno di accesso a root, quindi apriremo alcuni passaggi; ci assicureremo però che questi passaggi richiedano ulteriori verifiche di password per funzionare. Un modo per accedere a root è aggiungere gli appropriati account di staff al gruppo wheel (in /etc/group). I membri del gruppo wheel possono accedere a root tramite su. Non dovresti mai dare ai membri dello staff accesso nativo al gruppo wheel mettendoli in quel gruppo nel file /etc/passwd; dovresti metterli nel gruppo staff e quindi aggiungerli al gruppo wheel tramite il file /etc/group. Solo i membri dello staff che hanno effettivo bisogno di accesso a root dovrebbero essere nel gruppo wheel group. Altra possibilità, quando si utilizzi Kerberos come metodo di autenticazione, ` quella di utilizzare il file .k5login dell’account root in modo da permettere l’accesso a root tramite ksu(1) senza bisogno di mettere nessuno nel gruppo wheel. Questa potrebbe essere la soluzione migliore dato che il meccanismo wheel permette all’attaccante di diventare root se è riuscito ad ottenere accesso ad un account di staff. Benché il meccanismo wheel sia meglio di niente, non è necessariamente la soluzione più sicura.
Un metodo indiretto per rendere sicuri gli account di staff e quindi l’accesso a root è quello di eseguire l’operazione nota come "starring" delle password cifrate. password for the staff accounts: utilizzando il comando vipw(8) si può rimpiazzare ogni password cifrata con un singolo carattere “*” (asterisco, in inglese "star"). Questo comando aggiorna il file /etc/master.passwd e il database utenti/password in modo da disabilitare i login autenticati da password.
Un account di staff come il seguente:
foobar:R9DT/Fa1/LV9U:1000:1000::0:0:Foo Bar:/home/foobar:/usr/local/bin/tcsh
Andrebbe modificato così:
foobar:*:1000:1000::0:0:Foo Bar:/home/foobar:/usr/local/bin/tcsh
Questo previene i normali login dato che la password cifrata non sarà mai “*”. Fatto questo i membri dello staff dovranno utilizzare un diverso meccanismo di autenticazione come ad esempio kerberos(1) o ssh(1) utilizzando una coppia di chiavi pubblica/privata. Utilizzando Kerberos bisogna generalmente rendere sicure sia le macchine su cui viene eseguito il server Kerberos che la propria workstation. Utilizzando una coppia di chiavi bisogna in generale rendere sicura la macchina da cui ci si sta collegando (in genere la propria workstation); si può aggiungere un ulteriore strato di protezione proteggendo la coppia di chiavi con una password all’atto della creazione con ssh-keygen(1). Eseguire lo "starring" degli account dello staff garantisce che questi possano eseguire il login solo tramite i metodi di accesso sicuri che sono stati configutati. Quest forze l’intero staff all’uso di connessioni sicure e cifrate in tutte le loro sessioni, chiudendo un importante falla di sicurezza utilizzata da molti attaccanti: ascoltare il traffico di rete da un’altra macchina meno sicura.
I meccanismi di sicurezza più indiretti assumono anche che ci si colleghi da un server più restrittivo a uno che lo è di meno; per esempio se il tuo server primario ha in esecuzione una grande varietà di servizi, la tua workstation non dovrebbe averne in esecuzione nessuno. Per fare in modo che la tua workstation sia ragionevolmente sicura dovresti eseguire meno servizi possibile, o perfino nessuno del tutto, e dovresti utilizzare uno screen saver protetto da password. Ovviamente, avendo accesso fisico alla workstation un attaccante può rompere qualsiasi protezione che tu possa aver importato, ma bisogna sempre considerare che la magior parte degli attacchi avviene remotamente, tramite una rete, da parte di persone che non hanno accesso fisico alle tue workstation o ai tuoi server.
L’uso di sistemi come Kerberos permette di disabilitare o cambiare la pasword ad un account di staff in un solo posto ed avere effeto immediato su tutte le macchine in cui il membro dello staff ha un account. Nel caso l’account di un membro dello staff venga compromesso, la possibilità di poter cambiare la sua password su tutte le macchine non ` cosa di poco conto. Con password separate, cambiare una password su molte macchine può essere un bel problema. Con Kerberos puoi anche imporre restrizioni di cambio password: non solo un ticket Kerberos può essere fatto per scadere dopo un tempo predeterminato, ma il sistema Kerberos può richiedere all’utente di scegliere una nuova passsword dopo un certo periodo di tempo (per esempio, una volta al mese).
Il sysadmin prudente esegue soltanto i server che gli sono necessari, ná di più né di meno. Bisogna tenere conto del fatto che i server di terze parti sono generalmente i più affetti da bug. Per esempio, utilizzare una versione obsoleta di imapd o popper è equivalente a dare accesso root al mondo intero. Non eseguire mai un server senza controllarlo accuratamente. Molti server non hanno bisogno di essere eseguiti come root. Per esempio i demoni ntalk, comsat e finger possono essere eseguiti in speciali sandbox utente. Difficilmente una sandbox sarà una soluzione completa del problema, a meno di dedicarci parecchio tempo, ma resta valido l’approccio a cipolla alla sicurezza: se qualcuno riesce ad irrompere in un server eseguito in una sandbox, deve ancora riuscire ad evadere da quest’ultima. Più strati l’attaccante deve superare, minore la sua probabilità di successo. Storicamente sono state trovate falle di accesso a root in virtualmente ogni server mai eseguito come root, inclusi i server del sistema base. Se hai una macchina alla quale la gente accede solamente tramite sshd e mai tramite telnetd o rshd o rlogind, allora disattiva questi servizi!
FreeBSD attualmente esegue per default ntalkd, comsat e finger in una sandbox. Un altro programma candidato ad essere eseguito in una sandbox è named(8). /etc/defaults/rc.conf comprende le opzioni necessarie per eseguire named in una sandbox in forma comentata. A seconda se state installando un nuovo sistema o aggiornando un sistema esistente, gli speciali account utente utilizzati da queste sandbox potrebbero non essere presenti. Il sysadmin prudente dovrebbe cercar di utilizzare delle sandbox per i server ogniqualvolta possibile.
Esiste un certo numero di altri servizi che generalmente non vengono eseguiti in una sandbox: sendmail, popper, imapd, ftpd e altri. Ci sono software alternativi ad alcuni di questi ma installarli potrebbe richiedere più lavoro di quello che si intende dedicargli (il fattore convenienza colpisce ancora). Potresti dover eseguire questi servizi come root ed affidarti ad altri meccanismi per individuare le intrusioni che potrebbero essere fatte attraverso questi.
L’altra grande potenziale fonte di falle per l’accesso a root sono i binari suid-root e sgid installati nel sistema, come ad esempio rlogin, nelle directory /bin, /sbin, /usr/bin o /usr/sbin. Benché niente sia sicuro al 100%, i binari suid e sgid presenti nel sistema per default possono essere considerati ragionevolmente sicuri. In ogni caso, delle falle da root sono occasionalmente trovate anche in questi. Nel 1998 è stata trovata una falla da root in Xlib che rendeva vulnerabile xterm (che tipicamente è suid). It is better to be safe than sorry and the prudent sysadmin will restrict suid binaries, that only staff should run, to a special group that only staff can access, and get rid of (chmod 000) any suid binaries that nobody uses. A server with no display generally does not need an xterm binary. Sgid binaries can be almost as dangerous. If an intruder can break an sgid-kmem binary, the intruder might be able to read /dev/kmem and thus read the encrypted password file, potentially compromising any passworded account. Alternatively an intruder who breaks group kmem can monitor keystrokes sent through ptys, including ptys used by users who login through secure methods. An intruder that breaks the tty group can write to almost any user’s tty. If a user is running a terminal program or emulator with a keyboard-simulation feature, the intruder can potentially generate a data stream that causes the user’s terminal to echo a command, which is then run as that user.
Gli account utente sono generalmente i più difficili da rendere sicuri. Bench*eacute; tu possa imporre restrizioni d’accesso allo staff ed eseguire lo "starring" delle loro password, potresti non poter farlo con l’account di un generico utente. Se hai sufficiente controllo potesti farcela e rendere gli account utente sufficientemente sicuri, altrimenti dovrai essere più vigile nel controllo di questi account. L’uso di ssh e Kerberos per gli account utente è più problematico, a causa del maggiore supporto amministrativo e tecnico richiesto, ma è sempre un’ottima soluzione se confrontata all’uso di un file password cifrato.
L’unica strada sicura è quella di eseguire lo starring so più password possibile e utilizzare ssh o Kerberos per accedere a quegli account. Anche se il file di password cifrato (/etc/spwd.db) può essere letto solo da root, potrebbe essere possibile per un attaccante ottenere accesso in lettura a quel file anche senza aver ottenuto accesso in scrittura.
I tuoi script di sicurezza dovrebbero sempre verificare che il file password non venga modificato e in caso riportarlo ad un amministratore (cfr. la sezione Verifica dell’integrità dei file sottostante).
Quando un attaccante irrompe nell’account di root può fare qualsiasi cosa, ma alcune cose sono più comode di altre. Per esempio, la maggior parte dei kernel moderni comprende un device per l’ascolto dei pacchetti di rete. In FreeBSD questo device si chiama bpf. Un intrusore generalmente cercherà di ascoltare i pacchetti delle reti a cui la macchina compromessa è collegata. Non ò obbligatorio dare all’intrusore questa possibilità e d’altro canto la maggior parte dei sistemi non ha bisogno di avere il device bpf.
Anche nel caso di aver disattivato il device bpf, bisogna comunque preoccuparsi di /dev/mem e /dev/kmem; tra l’altro l’intrusore ha anche la possibilità di scrivere sui device disco raw o utilizzare il comando di caricamento moduli del kernel, kldload(8). Un intrusore intraprendente può utilizzare un proprio modulo del kernel per l’ascolto dei pacchetti e caricarlo su un kernel in esecuzione. Per evitare questi problemi bisogna eseguire il kernel ad un livello di sicurezza più alto, almeno al livello 1. Il livello di sicurezza può essere impostato con sysctl modificando la variabile kern.securelevel. Se il livello di sicurezza è impostato ad 1, l’accesso in scrittura ai device raw sarà negato e alcuni chflags speciali, come ad esempio schg, verranno verificati. Devi anche verificare che il flag schg sia impostato sui binari, cartelle e script utilizzati all’avvio prima dell’impostazione del livello di sicurezza. L’uso di un livello di sicurezza superiore potrebbe essere una misura eccesiva, dato che rende l aggiornamento del sistema molto più complesso. You may compromise and run the system at a higher secure level but not set the schg flag for every system file and directory under the sun. Another possibility is to simply mount / and /usr read-only. It should be noted that being too draconian in what you attempt to protect may prevent the all-important detection of an intrusion.
TODO:When it comes right down to it, you can only protect your core system configuration and control files so much before the convenience factor rears its ugly head. For example, using chflags to set the schg bit on most of the files in / and /usr is probably counterproductive, because while it may protect the files, it also closes a detection window. The last layer of your security onion is perhaps the most important - detection. The rest of your security is pretty much useless (or, worse, presents you with a false sense of security) if you cannot detect potential intrusions. Half the job of the onion is to slow down the attacker, rather than stop him, in order to be able to catch him in the act.
The best way to detect an intrusion is to look for modified, missing, or unexpected files. The best way to look for modified files is from another (often centralized) limited-access system. Writing your security scripts on the extra-secure limited-access system makes them mostly invisible to potential attackers, and this is important. In order to take maximum advantage you generally have to give the limited-access box significant access to the other machines in the business, usually either by doing a read-only NFS export of the other machines to the limited-access box, or by setting up ssh key-pairs to allow the limited-access box to ssh to the other machines. Except for its network traffic, NFS is the least visible method - allowing you to monitor the file systems on each client box virtually undetected. If your limited-access server is connected to the client boxes through a switch, the NFS method is often the better choice. If your limited-access server is connected to the client boxes through a hub, or through several layers of routing, the NFS method may be too insecure (network-wise) and using ssh may be the better choice even with the audit-trail tracks that ssh lays.
Once you have given a limited-access box at least read access to the client systems it is supposed to monitor, you must write scripts to do the actual monitoring. Given an NFS mount, you can write scripts out of simple system utilities such as find(1) and md5(1). It is best to physically md5 the client-box files at least once a day, and to test control files such as those found in /etc and /usr/local/etc even more often. When mismatches are found, relative to the base md5 information the limited-access machine knows is valid, it should scream at a sysadmin to go check it out. A good security script will also check for inappropriate suid binaries and for new or deleted files on system partitions such as / and /usr.
When using ssh rather than NFS, writing the security script is much more difficult. You essentially have to scp the scripts to the client box in order to run them, making them visible, and for safety you also need to scp the binaries (such as find) that those scripts use. The ssh client on the client box may already be compromised. All in all, using ssh may be necessary when running over insecure links, but it is also a lot harder to deal with.
A good security script will also check for changes to user and staff members access configuration files: .rhosts, .shosts, .ssh/authorized_keys and so forth, files that might fall outside the purview of the MD5 check.
If you have a huge amount of user disk space, it may take too long to run through every file on those partitions. In this case, setting mount flags to disallow suid binaries and devices on those partitions is a good idea. The nodev and nosuid options (see mount(8)) are what you want to look into. You should probably scan them anyway, at least once a week, since the object of this layer is to detect a break-in attempt, whether or not the attempt succeeds.
Process accounting (see accton(8)) is a relatively low-overhead feature of the operating system which might help as a post-break-in evaluation mechanism. It is especially useful in tracking down how an intruder has actually broken into a system, assuming the file is still intact after the break-in has occurred.
Finally, security scripts should process the log files, and the logs themselves should be generated in as secure a manner as possible - remote syslog can be very useful. An intruder will try to cover his tracks, and log files are critical to the sysadmin trying to track down the time and method of the initial break-in. One way to keep a permanent record of the log files is to run the system console to a serial port and collect the information to a secure machine monitoring the consoles.
Un po' di paranoia non fa mai male. Come regola, un sysadmin può aggiungere qualsiasi feature di sicurezza fintantoché non impattano la comodità e può aggiungerne altre che la impattano, ma solo dopo averci pensato bene. Even more importantly, a security administrator should mix it up a bit - if you use recommendations such as those given by this document verbatim, you give away your methodologies to the prospective attacker who also has access to this document.
Questa sezione parla degli attacchi Denial of Service, ovvero quelli atti ad interrompere i servizi in esecuzione su una macchina. Tipicamente un attacco DoS è un attacco a pacchetto; benché non si possa fare molto riguardo ad un attacco moderno che satura la vostra rete con pacchetti , si può cercare di limitare il danno assicurandosi che l’attacco non blocchi i vostri servizi, utilizzando le seguenti tecniche:
Limitare le fork dei server.
TODO:Limiting springboard attacks (ICMP response attacks, ping broadcast, etc.).
Sovraccaricare la Kernel Route Cache.
Un comune scenario è l’attacco di un server che fa fork e fargli creare così tanti processi figli da esaurire le risorse della macchina, come ad esempio la memoria, i file descriptor o altri e costringerlo quindi a fermarsi. inetd (cfr. inetd(8)) ha molte opzioni per limitare questo tipo di attacchi. Si deve notare che benché sia possibile evitare che la macchina si fermi, non è generalmente possibile evitare che i servizi vengano resi non disponibili dall’attacco. Leggete attentamente la pagina del manuale di inetd, con particolare attenzione alle opzioni -c, -C e -R. Un attacco con IP aggira l’opzione -C quindi è bene utilizzare una combinazione di opzioni. Alcuni server indipendenti hanno meccanismi interni per la limitazione delle fork.
Sendmail ha l’opzione -OMaxDaemonChildren che generalmente funziona molto meglio che cercare di utilizzare le funzioni di limitazione basate sul carico della macchina, a causa del ritardo di aggiornamento del valore di carico. Quando lanci sendmail dovresti specificare un parametro MaxDaemonChildren abbastanza alto da gestire il carico previsto , ma non così alto da non essere gestibile dal computer. È anche prudente eseguire Sendmail in modalità queued (-ODeliveryMode=queued) ed eseguire il demone (sendmail -bd) separatamente dalla gestione code (sendmail -q15m). Se vuoi che i messaggi vengano consegnati in tempo reale puoi utilizzare un intervallo molto più breve, come ad esempio -q1m, ma assicurati di utilizzare un valore MaxDaemonChildren adatto per quel Sendmail, in modo da prevenire problemi a catena.
Syslogd può essere attaccato direttamente ed è fortemente consigliato l’uso dell’opzione -s quando possibile, o al limite l’opzione -a.
You should also be fairly careful with connect-back services such as TCP Wrapper’s reverse-identd, which can be attacked directly. You generally do not want to use the reverse-ident feature of TCP Wrapper for this reason.
È un’ottima idea quella di proteggere i servizi interni dall’accesso esterno chiudendoli tramite regole del firewall ai bordi della vostra rete. L’idea è di prevenire gli attacchi a saturazione provenienti dall’esterno della vostra rete, non tanto di proteggere i servizi da attacchi di rete atti a compromettere root. Utilizza sempre un firewall , ovvero "blocca tutto tranne le porte A, B, C, D e M-Z"; puoi bloccare tutte le porte basse ad eccezione di specifici servizi quali named (se sei primario per una zona), ntalkd, sendmail e altri servizi accessibili da Internet. Se tu cercassi di configurare il firewall in maniera opposta (inclusivo o permissivo) c’è una buona probabilità che tu ti scordi di "chiudere" qualche servizio o che tu aggiunga un nuovo servizio interno e dimentichi di aggiornare il firewall. Puoi comunque lasciare aperte tutte le porte , permettendo un uso permissivo, senza però compromettere le porte . Nota anche che FreeBSD ti permette di controllare l’intervallo di porte utilizzate per il binding dinamico tramite vari sysctl net.inet.ip.portrange (sysctl -a | fgrep portrange), che possono semplificare la complessità di configurazione del tuo firewall.
Another common DoS attack is called a springboard attack - to attack a server in a manner that causes the server to generate responses which overloads the server, the local network, or some other machine. The most common attack of this nature is the ICMP ping broadcast attack. The attacker spoofs ping packets sent to your LAN’s broadcast address with the source IP address set to the actual machine they wish to attack. If your border routers are not configured to stomp on ping packets to broadcast addresses, your LAN winds up generating sufficient responses to the spoofed source address to saturate the victim, especially when the attacker uses the same trick on several dozen broadcast addresses over several dozen different networks at once. Broadcast attacks of over a hundred and twenty megabits have been measured. A second common springboard attack is against the ICMP error reporting system. By constructing packets that generate ICMP error responses, an attacker can saturate a server’s incoming network and cause the server to saturate its outgoing network with ICMP responses. This type of attack can also crash the server by running it out of memory, especially if the server cannot drain the ICMP responses it generates fast enough. Use the sysctl variable net.inet.icmp.icmplim to limit these attacks. The last major class of springboard attacks is related to certain internal inetd services such as the udp echo service. An attacker simply spoofs a UDP packet with the source address being server A’s echo port, and the destination address being server B’s echo port, where server A and B are both on your LAN. The two servers then bounce this one packet back and forth between each other. The attacker can overload both servers and their LANs simply by injecting a few packets in this manner. Similar problems exist with the internal chargen port. A competent sysadmin will turn off all of these inetd-internal test services.
Spoofed packet attacks may also be used to overload the kernel route cache. Refer to the net.inet.ip.rtexpire, rtminexpire, and rtmaxcache sysctl parameters. A spoofed packet attack that uses a random source IP will cause the kernel to generate a temporary cached route in the route table, viewable with netstat -rna | fgrep W3. These routes typically timeout in 1600 seconds or so. If the kernel detects that the cached route table has gotten too big it will dynamically reduce the rtexpire but will never decrease it to less than rtminexpire. There are two problems:
The kernel does not react quickly enough when a lightly loaded server is suddenly attacked.
The rtminexpire is not low enough for the kernel to survive a sustained attack.
If your servers are connected to the Internet via a T3 or better, it may be prudent to manually override both rtexpire and rtminexpire via sysctl(8). Never set either parameter to zero (unless you want to crash the machine). Setting both parameters to 2 seconds should be sufficient to protect the route table from attack.
There are a few issues with both Kerberos and ssh that need to be addressed if you intend to use them. Kerberos 5 is an excellent authentication protocol, but there are bugs in the kerberized telnet and rlogin applications that make them unsuitable for dealing with binary streams. Also, by default Kerberos does not encrypt a session unless you use the -x option. ssh encrypts everything by default.
Ssh works quite well in every respect except that it forwards encryption keys by default. What this means is that if you have a secure workstation holding keys that give you access to the rest of the system, and you ssh to an insecure machine, your keys are usable. The actual keys themselves are not exposed, but ssh installs a forwarding port for the duration of your login, and if an attacker has broken root on the insecure machine he can utilize that port to use your keys to gain access to any other machine that your keys unlock.
We recommend that you use ssh in combination with Kerberos whenever possible for staff logins. Ssh can be compiled with Kerberos support. This reduces your reliance on potentially exposed ssh keys while at the same time protecting passwords via Kerberos. Ssh keys should only be used for automated tasks from secure machines (something that Kerberos is unsuited to do). We also recommend that you either turn off key-forwarding in the ssh configuration, or that you make use of the from=IP/DOMAIN option that ssh allows in its authorized_keys file to make the key only usable to entities logging in from specific machines.
Ogni utente su un sistema UNIX® ha una password associata con il proprio account. È pvviamente necessario che queste password siano note solamente all’utente e al sistema operativo vero e proprio. Per poter mantenere segrete queste password, sono cifrate con quello che si chiama un "one-way hash", ovvero possono essere facilmente cifrate ma non decifrate. In altre parole, quel che poco fa abbiamo dato per ovvio non è neanche vero: il sistema operativo in sé non conosce realmente la password, conosce soltanto la forma cifrata della password. L’unico modo per ricavare la password in chiaro è una brutale ricerca nell’intero spazio delle password possibili.
Sfortunatamente l’unico modo sicuro di cifrare le password quando UNIX® è nato era di utilizzare DES (Data Encryption Standard). Questo non era un grosso problema per gli utenti residenti in USA, ma dato che il codice sorgente riguardante DES non poteva essere esportato al di fuori degli USA, FreeBSD ha dovuto cercare un modo per poter contemporaneamente essere in regola con la legge USA e mantenere la compatibilità con tutte le altre varianti UNIX® che ancora utilizzavano DES.
La soluzione è stata quella di suddividere le librerie di cifratura in modo tale che gli utenti USA potessero installare le librerie DES ed utilizzarlo ma gli utenti internazionali avessero comunque a disposizioni metodi crittografici che potessero essere esportati all’estero. Questo è il modo in cui FreeBSD adottò MD5 come metodo di cifratura di default. MD5 è considerato più sicuro di DES, quindi installare DES è una possibilità pensata principalmente per motivi di compatibilià.
Attualmente la libreria supporta gli algoritmi DES, MD5 e Blowfish. Per default FreeBSD utilizza MD5 per cifrare le password.
È piuttosto semplice identificare il tipo di cifratura utilizzato; ad esempio uno dei metodi è di leggere il file /etc/master.passwd. Le password cifrate con l’hash MD5 sono più lunghe e iniziano con i caratteri $1$. Le password che iniziano con $2a$ sono cifrate con Blowfish. Le password DES non hanno alcun carattere identificativo particolare, ma sono più corte e sono codificate in un alfabeto di 64 caratteri che non include il $, quindi una stringa relativamente corta che non inizia con un simbolo di dollaro è molto probabilmente una password DES.
Il formato utilizzato per le nuove password è deciso dal valore del campo passwd_format nel file /etc/login.conf, che può avere i valori di des, md5 oo blf. Fai riferimento alla pagina del manuale login.conf(5) per avere ulteriori informazioni sulle configurazioni di login.
Per default FreeBSD include il supporto per OPIE (One-time Passwords In Everything), configurato per utilizzare l’hash MD5.
Ci sono tre tipi di diverse password di cui parleremo in seguito. Le prime sono le normali pasword UNIX® o Kerberos, che verranno chiamate "password UNIX®". Il secondo tipo sono le password one-time generate dal programma OPIE opiekey(1) e accettate dal programma opiepasswd(1) e dal prompt di login, che chiameremo "password one-time". L’ultimo tipo di password è la password segreta che darai al programma opiekey (e qualche volte al programma opiepasswd) e che viene utilizzata per generare le password one-time, che chiameremo "password segreta" o più semplicemente "password".
La password segreta non ha niente a che vedere con la password UNIX®; possono essere uguali ma questo è sconsigliato. Le password segrete di OPIE non sono limitate a 8 caratteri come le vecchie password UNIX®, possono essere lunghe quanto ti pare. Sono abbastana diffuse password composte da frasi di sei o sette parole. Per la maggior parte, il sistema OPIE funziona in modo totalmente indipendente dal sistema di password UNIX®.
Oltre alla password, ci sono altre due informazioni utili a OPIE. Una è nota come "seme" o "chiave" e consiste di due lettere e cinque numeri. L’altra è nota come "numero di iterazioni" ed è un valore tra 1 e 100. OPIE crea la password one-time concatenando il seme e la password segreta ed applicandovi l’hash MD5 tante volte quanto specificate dal numero di iterazioni, trasformando poi il risultato in sei corte parole inglesi, che saranno la tua password one-time. Il sistema di autenticazione (principalmente PAM) mantiene traccia dell’ultima password one-time usata e autentica l’utente se l’hash della password fornita dall’utente è uguale alla password precedente. Dato che viene usato un hash, ovvero una funzione matematica a senso unico è impossibile generare password one-time future se viene catturata una password durante il suo utilizzo; il numero di iterazioni viene decrementato dopo un login avvenuto con successo per mantenere l’utente e il programma di login in sincrono. Quando il numero di iterazioni scende a 1, OPIE deve essere reinizializzato.
Nelle seguenti spiegazioni si farà riferimento a vari programmi: il programma opiekey richiede un numero di iterazioni, un seme e una password segreta e genera una password one-time o una lista di password one-time consecutive; il programma opiepasswd viene utilizzato per inizializzzare OPIE e per cambiare password, numeri di iterazioni, semi e password one-time; il programma opieinfo analizza i file di credenziali (/etc/opiekeys) e stampa il numero di iterazioni e il seme correnti dell’utente che lo richiama.
Traduzione in corso
Questo capitolo fornirà una spiegazione di cosa siano le jail in FreeBSD e di come usarle. Le jail, definite a volte come una miglioria dell'ambiente chroot, sono un strumento molto potente per amministratori di sistema, ma il loro uso può essere utile anche per utenti avanzati.
Dopo aver letto questo capitolo, saprai:
Cosa è una jail e a quale scopi può servire nelle installazioni di FreeBSD.
Come creare, avviare e fermare una jail.
Le basi per l’amministrazione delle jail, sia dall’interno che dall’esterno di una jail.
Altre fonti di informazioni utili a proposito delle jail sono:
La pagina man jail(8). Questo è un riferimento completo dell’utility jail - il tool di amministrazione che può essere usato in FreeBSD per avviare, fermare e controllare le jail in FreeBSD.
Le mailing list ed i loro archivi. Gli archivi della mailing list per le domande generiche su FreeBSD ed altre mailing list ospitate sul server delle liste di FreeBSD contengono già una varietà di materiale per le jail. Si dovrebbe sempre cercare negli archivi, o inviare una nuova domanda alla mailing list freebsd-questions.
Per facilitare una migliore comprensione delle parti di FreeBSD relative alle jail, i loro meandri ed il modo in cui interagiscono con il resto di FreeBSD, i seguenti termini saranno usati più avanti in questo capitolo:
Una chiamata di sistema di FreeBSD, che cambia la directory root di un processo e di tutti i suoi discendenti.
L’ambiente di un processo eseguito con "chroot". Sono incluse le risorse come la parte del file system visibile, ID di utenti e di gruppi che sono disponibili, interfacce di rete, altri meccanismi di IPC, ecc.
L’utility di amministrazione di sistema che permette di eseguire processi all’interno di una jail.
Il sistema di controllo di una jail. Il sistema host ha accesso a tutte le risorse hardware disponibili, e può controllare processi sia all’interno che al di fuori di una jail. Una delle differenze importanti di un sistema host rispetto a una jail è che le limitazioni applicate ai processi superuser dentro una jail non sono valide per i processi del sistema host.
Un processo, utente o altra entità, che abbia l’accesso alle risorse, limitato da una jail di FreeBSD.
Dato che l’amministrazione di sistema è un compito difficile e gravoso, sono stati sviluppati molti strumenti potenti per rendere la vita più semplice per l’amministratore. Questi strumenti forniscono aiuti di vario genere nel modo in cui i sistemi sono installati, configurati e quindi manutenuti. Parte dei compiti che un amministratore dovrebbe fare riguarda la corretta configurazione nell’ambito della sicurezza di un sistema, in modo tale da continuare a servire il suo vero intento, senza permettere violazioni di sistema.
Uno degli strumenti che possono essere usati per migliorare la sicurezza di FreeBSD sono le jail. Le jail furono introdotte con FreeBSD 4.X da Poul-Henning Kamp <phk@FreeBSD.org>, ma furono notevolmente migliorate in FreeBSD 5.X per renderle un sottosistema potente e flessibile. Il loro sviluppo continua per migliorare la loro utilità, le prestazioni e la sicurezza.
I sistemi operativi BSD-like hanno avuto il chroot(2) dai tempi di 4.2BSD. L’utility chroot(2) può essere usata per cambiare la directory root di un insieme di processi, creando un ambiente sicuro e separato dal resto del sistema. I processi creati nell’ambiente chroot non possono accedere a file o risorse fuori da questo. Per questa ragione, compromettere un servizio che viene eseguito in un ambiente chroot non dovrebbe permettere all’attaccante di compromettere l’intero sistema. L’utility chroot(2) è utile per compiti semplici, che non richiedono molta flessibilità o caratteristiche complesse e avanzate. Tuttavia, dall’inizio del concetto di chroot, sono stati trovati diversi modi per uscire da un ambiente chroot, e, benchè siano stati fixati nelle versioni moderne del kernel di FreeBSD, è diventato chiaro che chroot(2) non era la soluzione ideale per rendere sicuri i servizi. Un nuovo sottosistema doveva essere implementato.
Queste sono alcune delle ragioni principali per cui le jail sono state sviluppate.
Le jail migliorano il concetto dell’ambiente chroot(2) tradizionale, in molti modi. In un ambiente chroot(2) tradizionale, i processi sono limitati solo nella porzione di file system che possono accedere. Il resto delle risorse di sistema (come l’insieme di utenti di sistema, i processi in esecuzione, o il sotto-sistema di rete) sono condivise dai processi in chroot e dai processi del sistema host (quelli non inseriti in un ambiente chroot). Le jail espandono questo modello virtualizzando non solo l’accesso al file system, ma anche l’insieme di utenti, il sotto-sistema di rete del kernel di FreeBSD e alcune altre cose. Un più completo insieme di controlli disponibili per calibrare l’accesso ad un ambiente jail è descritto nella Messa a Punto ed Amministrazione.
Una jail è caratterizzata da quattro elementi:
Un sotto-ramo di una directory - il punto di partenza da cui si entra nella jail. Una volta all’interno della jail, ad un processo non è permesso di uscire da questo sotto-ramo. Le questioni tradizionali di sicurezza che colpiscono il design di chroot(2) originale non affliggono le jail di FreeBSD.
Un hostname - l’hostname che sarà usato all’interno della jail. Le jail sono principalmente usate per ospitare servizi di rete, quindi avere un nome host descrittivo per ogni jail può veramente aiutare l’amministratore di sistema.
Un indirizzo IP - questo sarà assegnato alla jail e non può essere cambiato in alcun modo durante l’arco di vita della jail. L’indirizzo IP di una jail è in genere un indirizzo alias di un’interfaccia di rete esistente, anche se questo non è strettamente necessario.
Un comando - il percorso di un eseguibile da avviare all’interno della jail. Questo è relativo alla directory root dell’ambiente della jail, e può variare molto, a seconda del tipo specifico di ambiente della jail.
Oltre a queste caratteristiche, le jail possono avere il loro insieme di utenti ed il loro utente root. Naturalmente, i poteri dell’utente root sono limitati all’interno dell’ambiente jail e, dal punto di vista del sistema host, l’utente root della jail non è il superuser. Inoltre, l’utente root di una jail non potrà eseguire operazioni critiche sul sistema al di fuori del suo ambiente jail(8). Altre informazioni sui poteri e sulle restrizioni dell’utente root saranno discusse nella Messa a Punto ed Amministrazione.
Alcuni amministratori dividono le jail nei seguenti due tipi: jail "complete", che sono simili ad un sistema FreeBSD reale, e jail "di servizio", dedicate ad un’unica applicazione o servizio, possibilmente in esecuzione con privilegi. Questa è solo una divisione concettuale ed il processo di creazione della jail non viene modificato da ciò. La pagina man jail(8) è abbastanza chiara a riguardo della procedura di creazione di una jail:
# setenv D /qui/c'e'/la/jail
# mkdir -p $D (1)
# cd /usr/src
# make world DESTDIR=$D (2)
# cd etc/ [7]
# make distribution DESTDIR=$D (3)
# mount_devfs devfs $D/dev (4)| 1 | Selezionare una directory per la jail è il miglior punto in cui iniziare. Questo sarà il punto in cui la jail risiederà fisicamente nel file system del sistema host. Una buona scelta può essere /usr/jail/nomejail, dove nomejail è il nome host che identifica la jail. Il file system /usr/ in genere ha abbastanza spazio vuoto per il file system delle jail, che per una jail "completa" è, in pratica, una replica di ogni file presente in una installazione base di FreeBSD |
| 2 | Questo comando popolerà la sotto-directory scelta come locazione fisica della jail con i binari necessari, le librerie, le pagine man e cosí via. Tutto è fatto nello stile tipico di FreeBSD - prima tutto viene creato/compilato, poi installato nel percorso di destinazione. |
| 3 | Il target distribution per make installa ogni file di configuazione richiesto. In parole povere, installa ogni file di /usr/src/etc/ nella directory /etc dell’ambiente jail: $D/etc/. |
| 4 | Non è richiesto di montare il file system devfs(8) all’interno della jail. D’altro lato, ogni applicazione o quasi ha bisogno di accedere ad almeno un dispositivo, a seconda dello scopo dell’applicazione stessa. È molto importante controllare l’accesso ai dispositivi dall’interno della jail, dato che con dei settaggi impropri un attaccante potrebbe compiere azioni dannose nella jail. Il controllo su devfs(8) è gestito attraverso le regole che sono descritte nelle pagine man di devfs(8) e devfs.conf(5). |
Una volta che una jail è installata, può essere avviata usando l’utility jail(8). L’utility jail(8) prende quattro argomenti obbligatori che sono descritti nella Cosa è una Jail. Possono essere specificati altri argomenti, ad esempio, per eseguire il programma nella jail con le credenziali di un utente specifico. L’argomento comando dipende dal tipo di jail; per un sistema virtuale, /etc/rc è una buona scelta, dato che replicherà la sequenza di avvio di un sistema FreeBSD reale. Per una jail di servizio, dipenderà dal servizio o dalla applicazione che sarà eseguita all’interno della jail.
Le jail spesso sono avviate al momento di boot e il meccanismo rc di FreeBSD fornisce un modo semplice per farlo.
Una lista delle jail che sono abilitate al boot dovrebbe essere aggiunta al file rc.conf(5):
jail_enable="YES" # NO per disabilitare l'avvio delle jail jail_list="www" # Lista dei nomi delle jail separati da spazi
Per ogni jail elencata in jail_list, dovrebbe essere aggiunto un gruppo di impostazioni di rc.conf(5), che descrive la jail:
jail_www_rootdir="/usr/jail/www" # directory root della jail jail_www_hostname="www.example.org" # nome-host della jail jail_www_ip="192.168.0.10" # indirizzo IP della jail jail_www_devfs_enable="YES" # dispositivi di mount devfs nella jail jail_www_devfs_ruleset="www_ruleset" # regole devfs da applicare alla jail
L’avvio di default delle jail configurate in rc.conf(5) eseguirà lo script della jail in /etc/rc, che assume che la jail sia un completo sistema virtuale. Per jail di servizio, il comando di default di avvio della jail dovrebbe essere cambiato, impostando l’opzione jailnomejailexec_start in modo appropriato.
Per una lista completa delle opzioni disponibili, per favore consulta la pagina man rc.conf(5). |
Lo script /etc/rc.d/jail può essere usato per avviare o fermare una jail a mano, se esiste una entry in rc.conf:
# /etc/rc.d/jail start www
# /etc/rc.d/jail stop wwwUn modo pulito per spegnere una jail(8) non è disponibile al momento. Questo perchè i comandi usati normalmente per fare uno shutdown pulito non possono essere usati all’interno della jail. Il modo migliore per spegnere una jail è eseguire il seguente comando all’interno della jail stessa o usando l’utility jexec(8) da fuori della jail:
# sh /etc/rc.shutdownMaggiori informazioni al riguardo possono essere trovate nella pagina man jail(8).
Ci sono molte opzioni che possono essere impostate per ogni jail, e molti modi di combinare un sistema FreeBSD con le jail, per produrre applicazioni di alto livello. Questa sezione presenta:
Alcune delle opzioni disponibili per impostare il comportamento e le restrizioni di sicurezza implementate da una installazione di una jail.
Alcune degli applicativi di alto livello per la gestione delle jail, che sono disponibili attraverso la Collezione dei Port di FreeBSD, e possono essere usate per implementare soluzioni complete basate sulle jail.
La messa a punto di una configurazione di una jail è principalmente fatta settando variabili sysctl(8). Esiste un sotto-ramo speciale di sysctl con tutte le opzioni del caso: la gerarchia security.jail.* delle opzioni del kernel di FreeBSD. Qui c’è una lista delle principali opzioni di sysctl relative alle jail, con il loro valori di default. I nomi dovrebbero essere auto esplicativi, ma per maggiori informazioni riguardo questi, per favore fai riferimento alle pagine man jail(8) e sysctl(8).
security.jail.set_hostname_allowed: 1
security.jail.socket_unixiproute_only: 1
security.jail.sysvipc_allowed: 0
security.jail.enforce_statfs: 2
security.jail.allow_raw_sockets: 0
security.jail.chflags_allowed: 0
security.jail.jailed: 0
Queste variabili possono essere usate dall’amministratore di sistema del sistema host per aggiungere o rimuovere alcune delle limitazioni imposte di default all’utente root. Nota che ci sono alcune limitazioni che non possono essere rimosse. L’utente root non ha il permesso di montare o smontare file system all’interno della jail(8). L’utente root all’interno della jail non può caricare o scaricare regole di devfs(8), impostare regole del firewall, o compiere molti altri compiti di amministrazione che richiedono modifiche in kernel, come impostare il securelevel del kernel.
Il sistema base di FreeBSD contiene un insieme di base di strumenti per vedere informazioni a proposito delle jail attive, e per attaccarsi ad una jail per eseguire compiti amministrativi. Il comando jail(8) e jexec(8) sono parte del sistema base di FreeBSD, e possono essere usati per eseguire i seguenti semplici compiti:
Stampa una lista di jail attive e i loro corrispondenti identificativi di jail (JID), indirizzo IP, nome host e percorso.
Attaccarsi ad una jail in esecuzione, dal suo sistema host, ed eseguire un comando o compiti amministrativi dall’interno della jail stessa. Questo è specialmente utile quando l’utente root vuole spegnere in modo pulito una jail. L’utility jexec(8) può anche essere usata per avviare una shell in una jail per fare dell’amministrazione; ad esempio:
# jexec 1 tcshFra le tante utility di terze parti per l’amministrazione delle jail, uno dei più completi ed utili è sysutils/jailutils. È un insieme di piccoli applicativi che contribuiscono alla gestione delle jail(8). Per favore fai riferimento alla corrispondente pagina web per maggiori informazioni.
Questa sezione è basata su un’idea di Simon L. B. Nielsen <simon@FreeBSD.org> (http://simon.nitro.dk/service-jails.html), e su un articolo scritto da by Ken Tom locals@gmail.com. Questa sezione illustra come configurare un sistema FreeBSD aggiungendo uno strato di sicurezza addizionale, usando le funzionalità delle jail(8). Inoltre questa sezione assume che la versione FreeBSD del sistema sia almeno la RELENG_6_0 e che siano state capite le informazioni fornite precedentemente nel capitolo.
Uno dei maggiori problemi delle jail è la gestione del loro processo di aggiornamento. Questo tende a essere un problema poichè ciascuna jail deve essere ricostruita da zero ogni volta che deve essere aggiornata. Di solito questo non è un problema per una jail singola, poichè il processo di aggiornamento è abbastanza semplice, ma se sono create tante jail può diventare un processo lungo e tedioso.
Questa configurazione richiede una esperienza avanzata con FreeBSD. Se i procedimenti seguenti risultano troppo complicati, si consiglia di dare un’occhiata a un sistema più intuitivo come sysutils/ezjail, che fornisce un modo semplice di amministrare le jail in FreeBSD e non è sofisticato come questa configurazione. |
Questa idea è stata presentata per risolvere il problema di condividere quanto più possibile tra le jail, in modo sicuro - usando mount_nullfs(8) in sola lettura, affinchè l’aggiornamento sia semplice, e per fare diventare più allettante mettere singoli servizi in jail individuali. Inoltre, si fornisce un modo per creare, aggiornare e rimuovere jail.
Esempi di servizi in questo contesto sono: un server HTTP, un server DNS, un server SMTP, e via dicendo. |
Gli scopi di configurazione descritti in questa sezione sono:
Comprendere la struttura jail. Questo implica di not dovere eseguire un installworld completo per ogni jail.
Semplificare l’aggiunta di una nuova jail o la rimozione di una esistente.
Semplificare l’aggiornamento o la modifica di una jail esistente.
Rende possibile l’esecuzione di un FreeBSD su misura.
Essere paranoici sulla sicurezza, riducendo quanto più possibile la possibilità di mettere a repentaglio il sistema.
Salvare spazio e inode, quanto più possibile.
Come già menzionato, questa configurazione si basa pesantemente nell’avere un unico template master che è in sola lettura (conosciuto come nullfs) montato in ogni jail e un dispositivo in lettura-scrittura per jail. Il dispositivo può essere un disco fisico separato, una partizione, o un dispositivo vnode md(4). In questo esempio, useremo un nullfs in lettura e scrittura.
Viene qui descritto il layout del file system:
Ogni jail sarà montata sotto la directory /home/j.
/home/j/mroot è il template per ogni jail e la partizione in sola lettura per tutte le jail.
Una directory vuota sarà creata per ogni jail sotto la directory /home/j.
Ogni jail avrà una directory /s, che sarà linkata alla porzione del sistema in lettura e scrittura.
Ogni jail ha il suo sistema in lettura e scrittura in /home/j/skel.
Ogni spazio di jail (la porzione in lettura e scrittura di ogni jail) sarà creato in /home/js.
Si assume che le jail siano posizionate sotto la partizione /home. Di sicuro, questo può essere modificato con qualcosa di diverso, ma questo cambiamento dovrà essere tenuto in considerazione negli esempi più avanti. |
Questa sezione descrive le fasi necessarie per creare il template di riferimento che sarà la parte in sola lettura utilizzate dalle jail.
È sempre una buona idea aggiornare FreeBSD al branch -RELEASE più recente. Per farlo, consulta il capitolo di riferimento dell’Handbook. Nel caso che l’aggiornamento non sia fattibile, sarà necessaria la procedura di buildworld per poter procedere. Inoltre, è richiesto il pacchetto sysutils/cpdup. Useremo l’utility portsnap(8) per scaricare la FreeBSD Ports Collection. Il Capitolo Portsnap dell’handbook è sempre una buona lettura per i nuovi arrivati.
Primo, creiamo la struttura della directory per il file system in sola lettura che conterrà i binari di FreeBSD per le nostre jail, quindi portiamoci nel ramo della directory dei sorgenti di FreeBSD e installiamo il file system in sola lettura per il template delle jail:
# mkdir /home/j /home/j/mroot
# cd /usr/src
# make installworld DESTDIR=/home/j/mrootQuindi, prepariamo la FreeBSD Ports Collection per le jail così come abbiamo fatto per l’alberatura dei sorgenti, richiesta per mergemaster:
# cd /home/j/mroot
# mkdir usr/ports
# portsnap -p /home/j/mroot/usr/ports fetch extract
# cpdup /usr/src /home/j/mroot/usr/srcCreiamo lo scheletro per la parte del sistema in lettura e scrittura:
# mkdir /home/j/skel /home/j/skel/home /home/j/skel/usr-X11R6 /home/j/skel/distfiles
# mv etc /home/j/skel
# mv usr/local /home/j/skel/usr-local
# mv tmp /home/j/skel
# mv var /home/j/skel
# mv root /home/j/skelUsiamo mergemaster per installare i file di configurazione mancanti. Quindi liberiamoci delle directory extra che mergemaster ha creato:
# mergemaster -t /home/j/skel/var/tmp/temproot -D /home/j/skel -i
# cd /home/j/skel
# rm -R bin boot lib libexec mnt proc rescue sbin sys usr devOra, linkiamo in modo simbolico il file system in lettura e scrittura nel file system di sola lettura. Assicuriamoci che i link simbolici siano creati nelle posizioni corrette in s/. La creazione di directory in posti sbagliati causerà un fallimento durante l’installazione.
# cd /home/j/mroot
# mkdir s
# ln -s s/etc etc
# ln -s s/home home
# ln -s s/root root
# ln -s ../s/usr-local usr/local
# ln -s ../s/usr-X11R6 usr/X11R6
# ln -s ../../s/distfiles usr/ports/distfiles
# ln -s s/tmp tmp
# ln -s s/var varCome ultima fase, creiamo un generico /home/j/skel/etc/make.conf con il seguente contenuto:
WRKDIRPREFIX?= /s/portbuild
Avendo settato WRKDIRPREFIX in questo modo sarà possibile compilare i port di FreeBSD all’interno di ogni jail. Ricordati che la directory dei port è parte del sistema in sola lettura. Il percorso ad doc di WRKDIRPREFIX permette di compilare nella porzione in lettura e scrittura di ogni jail.
Ora che abbiamo completato il template della jail, possiamo configurare le jail in /etc/rc.conf. Questo esempio mostra la creazione di 3 jail: "NS", "MAIL" e "WWW".
Inseriamo le seguenti righe nel file /etc/fstab, in modo tale che il template in sola lettura per le jail e lo spazio in lettura e scrittura sarà disponibile nella rispettive jail:
/home/j/mroot /home/j/ns nullfs ro 0 0 /home/j/mroot /home/j/mail nullfs ro 0 0 /home/j/mroot /home/j/www nullfs ro 0 0 /home/js/ns /home/j/ns/s nullfs rw 0 0 /home/js/mail /home/j/mail/s nullfs rw 0 0 /home/js/www /home/j/www/s nullfs rw 0 0
Le partizioni con uno 0 come numero di pass non sono verificate da fsck(8) durante il boot, e le partizioni con uno 0 come numero di dump non sono prese in considerazione da dump(8). Non si vuole che fsck verifichi i mount nullfs o che dump faccia un backup dei mount nullfs in sola lettura delle jail. Ecco perchè queste partizioni hanno "0 0" nelle ultime due colonne di ogni riga di fstab sopra mosrate. |
Configuriamo le jail in /etc/rc.conf:
jail_enable="YES" jail_set_hostname_allow="NO" jail_list="ns mail www" jail_ns_hostname="ns.example.org" jail_ns_ip="192.168.3.17" jail_ns_rootdir="/usr/home/j/ns" jail_ns_devfs_enable="YES" jail_mail_hostname="mail.example.org" jail_mail_ip="192.168.3.18" jail_mail_rootdir="/usr/home/j/mail" jail_mail_devfs_enable="YES" jail_www_hostname="www.example.org" jail_www_ip="62.123.43.14" jail_www_rootdir="/usr/home/j/www" jail_www_devfs_enable="YES"
La ragione del perchè la variabile |
Creiamo i punti di mount richiesti per il file system in sola lettura di ogni jail:
# mkdir /home/j/ns /home/j/mail /home/j/wwwInstalliamo il template in lettura e scrittura in ciascuna jail. Notare l’utilizzo di sysutils/cpdup, che assicura una corretta copia di ogni directory:
# mkdir /home/js
# cpdup /home/j/skel /home/js/ns
# cpdup /home/j/skel /home/js/mail
# cpdup /home/j/skel /home/js/wwwIn questa fase, le jail sono preparate per essere eseguite. Montiamo il file system richiesto per ogni jail, e quindi avviamole con lo script /etc/rc.d/jail:
# mount -a
# /etc/rc.d/jail startLe jail dovrebbero essere in esecuzione. Per verificare che siano state avviate correttamente, usiamo il comando jls(8). Il suo output dovrebbe essere simile al seguente:
# jls
JID IP Address Hostname Path
3 192.168.3.17 ns.example.org /home/j/ns
2 192.168.3.18 mail.example.org /home/j/mail
1 62.123.43.14 www.example.org /home/j/wwwA questo punto, dovrebbe essere possibile entrare in ciascuna jail, aggiungere nuovi utenti o configurare demoni. La colonna JID indica il numero identificativo di ciascuna jail in esecuzione. Usa il comando seguente per effettuare compiti amministrativi nella jail con JID 3:
# jexec 3 tcshIl tempo passa, e sarà necessario aggiornare il sistema a una nuova versione di FreeBSD, vuoi per questioni di sicurezza, o perchè sono state implementate nuove funzionalità che ritornano utili per le jail esistenti. Di seguito si fornisce un modo semplice per effettuare l’aggiornamento delle jail esistenti. Inoltre, questo metodo minimizza il tempo in cui le jail non sono in esecuzione, poichè le jail saranno disattivate solo per un breve periodo. Questa procedura fornisce un modo per ritornare indietro alle vecchie versioni nel caso qualcosa vada storto.
Il primo passo è aggiornare il sistema host nella maniera usuale. Quindi creiamo un template temporaneo in sola lettura in /home/j/mroot2.
# mkdir /home/j/mroot2
# cd /usr/src
# make installworld DESTDIR=/home/j/mroot2
# cd /home/j/mroot2
# cpdup /usr/src usr/src
# mkdir sIl processo di installworld crea alcune directory non necessarie, che possono essere rimosse:
# chflags -R 0 var
# rm -R etc var root usr/local tmpRicreiamo i link simbolici in lettura e scrittura per il file system di riferimento:
# ln -s s/etc etc
# ln -s s/root root
# ln -s s/home home
# ln -s ../s/usr-local usr/local
# ln -s ../s/usr-X11R6 usr/X11R6
# ln -s s/tmp tmp
# ln -s s/var varÈ questo il momento per fermare le jail:
# /etc/rc.d/jail stopSmontiamo il file system originale:
# umount /home/j/ns/s
# umount /home/j/ns
# umount /home/j/mail/s
# umount /home/j/mail
# umount /home/j/www/s
# umount /home/j/wwwI sistemi in lettura e scrittura sono attaccati al sistema in sola lettura (/s) e devono essere smontati. |
Muovi il file system in sola lettura e rimpiazzalo con quello nuovo. Il vecchio file system in sola lettura servirà da backup in caso qualcosa dovesse andare storto. La convenzione dei nomi qui utilizzata corrisponde a quella utilizzata quando fu creato il file system in sola lettura. Muovi la FreeBSD Ports Collection originale nel nuovo file system per risparmiare spazio e inode:
# cd /home/j
# mv mroot mroot.20060601
# mv mroot2 mroot
# mv mroot.20060601/usr/ports mroot/usrA questo punto il nuovo template in sola lettura è pronto, quindi ci rimare di rimontare il file system e avviare le jail:
# mount -a
# /etc/rc.d/jail startUsa jls(8) per verificare che le jail sono state avviate correttamente. Non dimenticare di eseguire mergemaster in ciascuna jail. I file di configurazione dovranno essere aggiornati così come gli script rc.d.
FreeBSD 6.2-RELEASE e i successivi includono supporto per audit di eventi relativi alla sicurezza. L’audit degli eventi permette di tener traccia attraverso i log in modo affidabile, preciso e configurabile di una varietà di eventi rilevanti per la sicurezza del sistema, inclusi i login, i cambiamenti della configurazione e l’accesso ai file ed alla rete. Questi dati loggati possono essere molto preziosi per il monitoraggio di sistemi in produzione, ricerca di intrusioni ed analisi post mortem. FreeBSD implementa le API di BSM di Sun™ e i suoi formati di file, ed è interoperabile sia con le implementazioni di audit di Sun™ Solaris™ che con quelle di Apple® Mac OS® X.
Questo capitolo si focalizza sull’installazione e la configurazione dell’Auditing degli Eventi. Spiega politiche di auditing e fornisce come esempio una configurazione di audit.
Dopo aver letto questo capitolo, saprai:
Cosa è l’Auditing di Eventi e come funziona.
Come configurare l’Auditing di Eventi su FreeBSD per utenti e processi.
Come rivedere la traccia di audit usando la riduzione dell’audit e i tool per studiarla.
Prima di leggere questo capitolo, dovresti:
Comprendere le basi di UNIX® e FreeBSD (Basi di UNIX).
Essere familiare con le basi di configurazione e compilazione del kernel (Configurazione del Kernel di FreeBSD).
Avere una certa familiarità con la sicurezza e come si applica a FreeBSD (Sicurezza).
La funzione di audit in FreeBSD 6.X è sperimentale e la messa in produzione dovrebbe avvenire solo dopo aver ben ponderato i rischi connessi al software sperimentale. Le limitazioni note includono che non tutti gli eventi relativi alla sicurezza al momento posso essere tracciati con l’audit, e che alcuni meccanismi di login, come display manager basati su X11 e demoni di terze parti, non sono correttamente configurabili per tracciare sotto audit le sessioni di login degli utenti. La funzione di audit di sicurezza può generare log molto dettagliati dell’attività di sistema: su un sistema carico, i file di traccia possono essere molto grandi quando sono configurati in dettaglio, oltre i gigabytes per settimana. Gli amministratori dovrebbero tenere in conto le richieste di spazio associate alla configurazione dell’audit di grandi dimensioni. Ad esempio, potrebbe essere desiderabile dedicare un intero file system alle directory sotto /var/audit in modo che gli altri file system non siano toccati se il file system di audit si riempie completamente. |
Prima di leggere questo capitolo, dobbiamo chiarire alcuni termini relativi all’audit:
event: Un event tracciabile da audit è ogni evento che può essere tenuto sotto osservazione dal sottosistema di audit. Esempi di eventi rilevanti per la sicurezza includono la creazione di un file, lo stabilire una connessione di rete, o il loggarsi di un utente. Gli event sono o "attribuibili", ovvero possono essere riferiti ad un utente autenticato, o "non attribuibili" se non possono esserlo. Esempi di eventi non attribuibili sono tutti gli eventi che occorrono prima dell’autenticazione nel processo di login, come tentativi di login con password errata.
class: Le class di eventi sono insiemi di eventi correlati fra loro, e sono usati nelle espressioni di selezione. Class di eventi usate spesso includono " la creazione di file" (fc), "esecuzione" (ex) e "login_logout" (lo).
record: Un record è una voce nel log di audit che descrive un evento di sicurezza. I record contengono il tipo di evento, informazione sul soggetto che ha causato l’evento, informazione sulla data e sull’ora dell’evento, informazione su ogni oggetto o argomento, ed una condizione di successo o fallimento.
trail: Una traccia di audit, o file di log, consiste in una serie di record di eventi che descrivono eventi di sicurezza. Tipicamente le tracce sono in qualche modo in ordine cronologico rispetto all’istante in cui l’evento si è realizzato. Solo processi autorizzati hanno il permesso di tracciare record nella traccia di audit.
selection expression: Una espressione di selezione è una stringa che contiene una lista di prefissi e nomi di classi di eventi usati per catalogare eventi.
preselection: Il processo attraverso il quale il sistema identifica quali eventi sono di interesse per l’amministratore al fine di evitare di generare record di audit per eventi che non siano di interesse. La configurazione della preselezione usa una serie di espressioni di selezioni per identificare quali classi di eventi siano da tracciare per quale utente, come anche impostazioni globali che si applicano sia a processi autenticati che nono autenticati.
reduction: Il processo attraverso il quale i record di un audit esistente sono selezionati per il salvataggio, la stampa, l’analisi. Ovvero, il processo attraverso il quale record di audit non desiderati siano rimossi dalla traccia di audit. Usando la riduzione, gli amministratori sono in grado di implementare politiche per il salvataggio di dati di audit. Per esempio, tracce di audit dettagliate possono essere tenute per un mese, dopodichè le tracce possono essere ridotte al fine di preservare solo le informazioni di login.
Il supporto in user space per l’Audit degli Eventi è installato come parte del sistema operativo FreeBSD. In FreeBSD 7.0 e successivi, il supporto kernel all’Audit degli eventi è compilato di default. In FreeBSD 6.X, il supporto all’Audit degli eventi deve essere compilato esplicitamente nel kernel aggiungendo le seguenti righe al file di configurazione del kernel:
options AUDIT
Ricompila e reinstalla il kernel attraverso il normale processo spiegato in Configurazione del Kernel di FreeBSD.
Una volta che il kernel è stato compilato ed installato con l’audit abilitato, ed il sistema è stato rebootato, abilita il demone audit aggiungendo la seguente riga in rc.conf(5):
auditd_enable="YES"
Il supporto all’audit a questo punto deve essere avviato al reboot, o manualmente avviando il demone:
/etc/rc.d/auditd start
Tutti i file di configurazione per l’audit di sicurezza si trovano in /etc/security. I seguenti file devono essere presenti prima dell’avvio del demone audit:
audit_class - Contiene le definizioni delle classi di audit.
audit_control - Controlla aspetti del sottosistema dell’audit, come le classi audit di default, il minimo spazio su disco da lasciare al log di audit, la massima dimensione della traccia di audit, etc.
audit_event - Nomi testuali e descrizioni degli eventi di audit di sistema, cosí come una lista di quali classi contengano quali eventi.
audit_user - Requisiti specifici dell’audit per l’utente, combinati con i default globali al login.
audit_warn - Uno script customizzabile usato da auditd per generare messaggi di warning in situazioni eccezionali, come ad esempio quando sta finendo lo spazio per i record o quando le tracce dell’audit sono ruotate.
I file di configurazione dell’audit dovrebbero essere editati e manotenuti con attenzione, dato che errori nella configurazione possono risultare in un tracciamento improprio degli eventi. |
Le espressioni per la selezione sono usate in un certo numero di posti nella configurazione dell’audit per determinare quali eventi dovrebbero essere sotto audit. Le espressioni contengono una serie di classi di eventi, ognuna con un prefisso che indica se i record che sono indicati debbano essere accettati o ignorati, ed opzionalmente ad indicare se i record che vengono individuati siano da tracciare ad un successo o ad un fallimento. Le espressioni di selezione sono valutate da sinistra a destra, e due espressioni sono combinate aggiungendo una all’altra.
La seguente lista contiene le classi di eventi di default presenti in audit_class:
all - all - Indica tutte le classi di eventi.
ad - administrative - Le azioni amministrative eseguite su un sistema nel suo complesso.
ap - application - Azioni definite dall’applicazione.
cl - file close - Chiamate audit alla system call close.
ex - exec - Fa l’audit delle esecuzioni di un programma. L’audit degli argomenti della command line e delle variabili di ambiente è controllato da audit_control(5) usando i parametri argv e envv nelle impostazioni della policy.
fa - file attribute access - Fa l’audit dell’accesso ad attributi di accesso come stat(1), pathconf(2) ed eventi simili.
fc - file create - Fa l’audit di eventi che hanno come risultato la creazione di un file.
fd - file delete - Fa l’audit di eventi in cui avvenga una cancellazione di file.
fm - file attribute modify - Fa l’audit di eventi in cui avvenga una modifica degli attributi dei file, come chown(8), chflags(1), flock(2), etc.
fr - file read - Fa l’audit di eventi nei quali dei dati siano letti, file siano aperti in lettura, etc.
fw - file write - Fa l’audit di eventi in cui dati siano scritti, file siano scritti o modificati, etc.
io - ioctl - Fa l’audit dell’uso della system call ioctl(2).
ip - ipc - Fa l’audit di varie forme di Inter-Process Communication, incluse pipe POSIX e operazioni IPC System V.
lo - login_logout - Fa l’audit di eventi di login(1) e logout(1) che occorrano nel sistema.
na - non attributable - Fa l’audit di eventi non attribuibili.
no - invalid class - Indica nessun evento di audit.
nt - network - Fa l’audit di eventi relativi ad azioni di rete, come connect(2) e accept(2).
ot - other - Fa l’audit di eventi miscellanei.
pc - process - Fa l’audit di operazioni dei processi, come exec(3) e exit(3).
Queste classi di eventi audit possono essere personalizzate modificando i file di configurazione audit_class e audit_event.
Ogni classe di audit nella lista è combinata con un prefisso che indica se le operazione di successo o andate in fallimento siano intercettate, e se la entry sta aggiungendo o togliendo delle regole di intercettazione per la classe ed il tipo.
(none) Fa l’audit di istanze dell’evento sia di successo che fallite.
+ Fa l’audit di eventi di successo in questa classe.
- fa l’audit di eventi falliti in questa classe.
^ Non fa l’audit di eventi nè di successo nè falliti in questa classe.
^+ Non fa l’audit di eventi di successo in questa classe.
^- Non fa l’audit di eventi falliti in questa classe.
Il seguente esempio di selezione indica eventi di login/logout sia di successo che non, ma solo eventi di successo di esecuzione:
lo,+ex
Nella maggior parte dei casi, gli amministratori dovranno solo modificare due file quando configurano il sistema audit: audit_control ed audit_user. Il primo controlla le proprietà e le politiche di tutto il sistema, il secondo può essere usato per fare del fine tuning iper il singolo utente.
Il file audit_control specifica un certo numero di valori di default per il sottosistema audit. Leggendo i contenuti di questo file, notiamo le seguenti righe:
dir:/var/audit flags:lo minfree:20 naflags:lo policy:cnt filesz:0
L’opzione dir viene usata per impostare una o più directory dove i file di log dell’audit vengono salvati. Se appare più di una directory, saranno usati in ordine uno dopo l’altro, dopo che uno si riempie. È comune configurare audit cosicchè i log siano tenuti in un filesystem dedicato, per prevenire interferenze fra il sottosistema audit ed altri sottosistemi se il filesystem si riempie.
Il campo flags imposta la maschera di preselzione per gli eventi attribuibili per tutto il sistema. Nell’esempio sopra, i login ed i logout di successo e quelli falliti sono tenuti sotto audit per tutto il sistema.
L’opzione minfree definisce la minima percentuale di spazio libero per i file system dove vengono conservate le tracce dell’audit. Quando questo limite viene superato, sarà generato un warning. L’esempio sopra imposta il minimo spazio libero al venti per cento.
L’opzione naflags specifica le classi di audit da tenere sotto audit per gli eventi non attribuibili, come il processo di login ed i demoni di sistema.
L’opzione policy specifica una lista separata da virgole di flag per le politiche che controllano vari aspetti del comportamento dell’audit. Il flag di default cnt indica che il sistema dovrebbe continuare a funzionare nonostante un errore dell’audit (questa flag è altamente consigliato). Un altro flag usato di comune è argv, che fa sì che gli argomenti di command line della sistema call execve(2) siano tenuti sotto audit come parte dell’esecuzione del comando.
L’opzione filesz specifica la massima dimensione in bytes da tenere per le tracce di audit, prima di terminarli automaticamente e routarli. Il default, 0, disabilita la rotazione dei file di log. Se la dimensione è diversa di zero ma minore del minimo, 512k, sarà ignorata ed un messaggio di log sarà generato.
Il file audit_user permette all’amministratore di specificare ulteriori requisiti dell’audit per utenti specifici. Ogni linea configura l’audit per un utente attraverso due campi: il primo campo è alwaysaudit, che specifica un insieme di eventi che dovrebbero sempre essere tenuti sotto audit per l’utente, ed il secondo è il campo neveraudit, che specifica un insieme di eventi che non dovrebbero mai essere tenuti sotto audit per l’utente.
Il seguente esempio di file audit_user fa l’audit di eventi di login/logout e delle esecuzioni di successo per l’utente root, e fa l’audit della creazione e dell’esecuzione di successo per l’utente www. Se usato con il file di esempio audit_control sopra riportato, l’entry lo per root è ridondante, e gli eventi di login/logout sarano tenuti sotto audit anche per l’utente www.
root:lo,+ex:no www:fc,+ex:no
Le tracce di audit sono conservate nel formato binario BSM, così devono essere usati degli strumenti appositi per modificare o convertirli a testo. Il comando praudit(1) converte file di traccia a semplice formato testo; il comando auditreduce può essere usato per ridurre file di traccia per analisi, archiviazione o stampa. auditreduce(1) supporta una varietà di parametri di selezione, incluso il tipo di evento, la classe dell’evento, l’utente, la data o l’ora dell’evento, ed il percorso del file o l’oggetto su cui si opera.
Per esempio, l’utility praudit farà il dump dell’intero contenuto di uno specifico file di log di audit in semplice formato testuale:
# praudit /var/audit/AUDITFILEDove AUDITFILE è il nome del file di log di cui fare il dump.
Le tracce di audit consistono in una serie di record di audit composti da token, che praudit scrive sequenzialmente uno per linea. Ogni token è per un tipo specifico, come header che tiene un header di un record audit, o path che tiene un percorso di file da una ricerca del nome. Il seguente è un esempio di un evento execve:
header,133,10,execve(2),0,Mon Sep 25 15:58:03 2006, + 384 msec exec arg,finger,doug path,/usr/bin/finger attribute,555,root,wheel,90,24918,104944 subject,robert,root,wheel,root,wheel,38439,38032,42086,128.232.9.100 return,success,0 trailer,133
Questo audit rappresenta una chiamata di successo a execve, in cui il comando finger doug è stato eseguito. Il token degli argomenti contiene la riga di comando presentata dalla shell al kernel. Il token path contiene il percorso dell’eseguibile usato dal kernel. Il token attribute descrive il binario, ed in particolare include i permessi del file che possono essere usato per determinare se l’applicazione era setuid. Il token subject descrive il processo in oggetto e conserva in sequenza l’id utente dell’audit, l’id effettivo dell’utente, il group id, lo user id reale ed il group id reale, il process id, l’id della sessione, l’id della porta e l’indirizzo di login. Nota che l’audit user id ed il real user id sono diversi: l’utente robert è diventato root prima di eseguire questo comando, ma questo viene tenuto sotto audit usando lo user id originale. Infine, il token return indica l’esecuzione andata a buon fine, ed il trailer chiude il record.
In FreeBSD 6.3 e successive, praudit supporta anche il formato di output XML, che può essere selezionato usando l’argomento -x.
Dato che i log dell’audit possono essere molto grandi, un amministratore probabilmente vorrà selezionarne solo un sottoinsieme utile, ad esempio i record associati con un utente specifico:
# auditreduce -u trhodes /var/audit/AUDITFILE | prauditQuesto selezionerà tutti i record di audit per l’utente trhodes conservati nel file AUDITFILE.
I membri del gruppo audit hanno il permesso di leggere tracce di audit in /var/audit; di default questo gruppo e' vuoto, così solo root può leggere le tracce di audit. Utenti possono essere aggiunti al gruppo audit per delegare diritti di lettura sull’audit. Dato che l’abilità di tracciare contenuti del log di audit fornisce significative informazioni sul comportamento di utenti e processi, si raccomanda che la delega di lettura sia fatta con cautela.
Le pipe di audit sono degli pseudo-device clonanti nel file system dei device che permettono alle applicazioni di intercettare lo stream dei record di audit in tempo reale. Questo è di primario interesse per i creatori di applicativi di intrusion detection e di monitoraggio di sistemi. In ogni caso, per l’amministratore il device della pipe dell’audit è un modo conveniente per permettere il monitaraggio dal vivo senza incontrare problemi con i permessi della traccia audit o la rotazione dei log che interrompono lo stream degli eventi. Per tracciare lo stream degli eventi dell’audit, usa la seguente linea di comando:
# praudit /dev/auditpipeDi default, i nodi di device delle pipe dell’audit sono accessibili solo dall’utente root. Per renderlo accessibile ai membri del gruppo audit, aggiungi una regola devfs al file devfs.rules:
add path 'auditpipe*' mode 0440 group audit
Leggi devfs.rules(5) per altre informazioni su come configurare il filesystem devfs.
È facile produrre cicli di feedback di eventi audit, in cui il semplice osservare ogni evento di audit risulta nella creazione di più eventi di audit. Per esempio, se tutto il traffico di rete viene tenuto sotto audit, e praudit(1) viene eseguito da una sessione SSH, un flusso continuo di notevoli dimensioni di eventi audit sarà generato, dato che ogni evento scritto genererà un altro evento. È consigliabile eseguire |
Le tracce di audit sono scritte solo dal kernel, e gestite solo dal demone dell’audit, auditd. Gli amministratori non dovrebbero cercare di usare newsyslog.conf(5) o altri tool per ruotare direttamente i log di audit. Invece, il tool di gestione audit può essere usato per interrompere l’audit, riconfigurare il sistema di audit, ed eseguire la rotazione dei log. Il seguente comando fa sì che il demone audit crei un nuovo log di audit e segnali al kernel di usare il nuovo log. I vecchio log sarà terminato e rinominato, ed a questo punto potrà essere manipolato dall’amministratore.
# audit -nSe il demone auditd non sta girando al momento, questo comando fallirà e sarà prodotto un messaggio di errore. |
Aggiungendo la seguente linea a /etc/crontab forzerà la rotazione ogni dodici ore da parte di cron(8):
0 */12 * * * root /usr/sbin/audit -n
Il cambiamento prenderà effetto dopo che hai salvato il nuovo /etc/crontab.
La rotazione automatica della traccia dell’audit basata sulla dimensione del file è possibile attraverso l’opzione filesz in audit_control(5), ed è descritta nella sezione sui file di configurazione di questo capitolo.
Man mano che i file di traccia dell’audit diventano di grandi dimensioni, è spesso desiderabile comprimerli o in qualche modo archiviarli dopo che sono stati chiusi dal demone audit. Lo script audit_warn può essere usato per eseguire operazioni personalizzate per una varietà di eventi relativi all’audit, incluse la chiusura pulita delle tracce di audit quando sono ruotate. Ad esempio, il seguente comando può essere aggiunto allo script audit_warn per comprimere le tracce di audit alla chiusura:
#
# Compress audit trail files on close.
#
if [ "$1" = closefile ]; then
gzip -9 $2
fiAltre attività di archiviazione possono includere copiare i file di traccia su di un server centralizzato, cancellare file di traccia vecchi, o ridurre la traccia di audit per rimuovere i record non voluti. Lo script sarà eseguito solo quando i file di traccia sono chiusi in maniera pulita, così non sarà eseguito su tracce lasciate non terminate a seguito di uno shutdown improprio.
Questo articolo tratta l’utilizzo dei dischi attraverso la struttura GEOM implementata in FreeBSD. Questo include le più importanti utility di controllo RAID che utilizzano la suddetta struttura per la loro configurazione. Questo capitolo non si soffermerà in discussioni approfondite su come la struttura GEOM utilizza o controlla gli I/O, il suo sottosistema di funzionamento o il codice. Queste informazioni sono fornite dalla manpage geom(4) e nei suoi vari riferimenti SEE ALSO. Questo capitolo non è nemmeno la guida definitiva alla configurazione del RAID Soltanto i dischiRAID classificati come "supportati da GEOM" saranno discussi.
Dopo la lettura di questo capitolo saprai:
Quale genere di supportoRAID è disponibile attraverso GEOM.
Come usare le utilities di base per configurare, manutenere, e manipolare i vari livelli di RAID.
Come creare dei mirror, degli stripe, criptare e connettere dischi remoti attraverso l’utilizzo di GEOM.
Come sbrogliare problematiche relative ai dischi connessi attraverso GEOM.
Prima di procedere alla lettura di questo capitolo dovresti:
Sapere la meccanica di utilizzo dei dischi da parte di FreeBSD. (Archiviazione dei Dati).
Sapere come configurare e installare un kernel personalizzato sotto FreeBSD (Configurazione del Kernel di FreeBSD).
GEOM permette l’accesso e il controllo alle classi - Master Boot Records, BSD labels, ecc - attraverso l’uso di forniture o di di files speciali in /dev. Mediante il supporto di vari software di configurazioneRAID , GEOM fornisce un accesso "trasparente" al sistema operativo e alle utilità di sistema.
Lo striping è un metodo utilizzato per unire gli hard disks in un singolo volume. In molti casi, questo si ottiene attraverso dei controllers hardware. Il sottosistema GEOM fornisce il supporto software per il RAID0, conosciuto anche come disk striping.
In un sistema RAID0, i dati sono tagliati in blocchi che vengono "spalmati" su tutti i dischi della catena RAID. Invece di aspettare che il sistema scriva un blocco di 256kb su un disco, il RAID0 può scrivere blocchi di 64k ciascuno su quattro differenti dischi, offrendo performances I/O migliori. Queste performances possono essere ulteriormente migliorate utilizzando più controllers per dischi.
In ogni "stripe" RAID0 ogni disco deve essere della stessa grandezza degli altri, dal momento che le chiamate I/O sono inframezzate per leggere e scrivere su più dischi in parallelo.
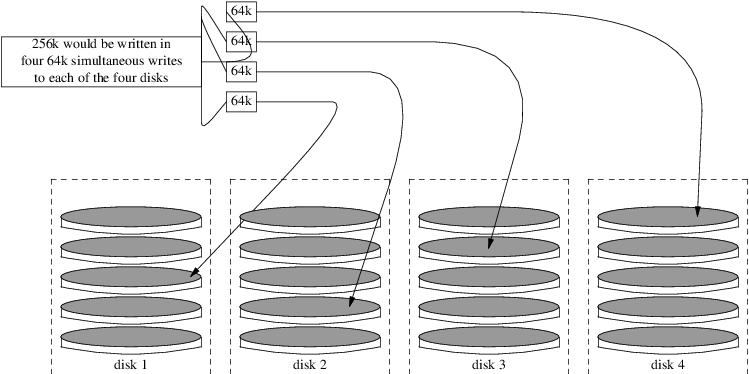
Procedure: Creazione di uno stripe di dischi ATA non formattati
Caricare il modulo geom_stripe:
# kldload geom_stripe.koAssicurati che esiste una appropriato mount point. Se il volume in questione diventerà una partizione di root, allora usa temporaneamente un mount point diverso,ad esempio /mnt:
# mkdir /mntDetermina i nomi dei devices per i dischi che verranno configurati in stripe e creali. Ad esempio per configurare in modalità stripe 2 dischi ATA /dev/ad2 e /dev/ad3 non ancora partizionati potresti usare il seguente comando.
# gstripe label -v st0 /dev/ad2 /dev/ad3Se questo volume sarà utilizzato come dispositivo di root da cui effettuare il boot, allora prima di creare il filesystem devi utilizzare il seguente comando:
# fdisk -vBI /dev/stripe/st0Crea una tabella delle partizioni sul nuovo volume con in seguente comando:
# bsdlabel -wB /dev/stripe/st0Questa procedura dovrebbe aver creato altri due device in /dev/stripe in aggiunta a st0. Nella fattispecie st0a e st0c. Ora bisogna creare un filesystem nel device st0a utilizzando il comando newfs come segue:
# newfs -U /dev/stripe/st0aDopo che per qualche secondo vedrete parecchi numeri scorrere sullo schermo, la procedura sarà completa. Il volume è stato creato ed è pronto per essere montato.
Per montare manualmente il dispositivo stripe appena creato usa il seguente comando:
# mount /dev/stripe/st0a /mntPer montare il filesystem stripe automaticamente all’avvio del sistema, inserisci le informazioni del volume nel file /etc/fstab:
# echo "/dev/stripe/st0a /mnt ufs rw 2 2" \
>> /etc/fstabIl modulo geom deve essere caricato contestualmente all’avvio del sistema; questo lo si ottiene semplicemente inserendo la seguente linea nel file /boot/loader.conf:
# echo 'geom_stripe_load="YES"' >> /boot/loader.confIl mirroring è una tecnologia utilizzata da molte aziende e utenti casalinghi per il salvataggio dei dati senza interruzioni. La presenza di un "mirror" significa semplicemente che il disco B replica il disco A;oppure che i dischi C e D replicano i dischi A e B. Indipendentemente dalla configurazione del disco, l’aspetto importante è che le informazioni presenti su un disco o una partizione sono letteralmente "replicati". Successivamente queste informazioni possono essere facilmente ripristinate,salvate senza che si verifichino disservizi o interruzioni nel loro accesso e, addirittura, conservate fisicamente in cassaforte.
Per cominciare assicurati che il sistema disponga di due dischi di identica capacità. Questo esercizio si riferisce a dischi SCSIad accesso diretto (da(4)),
Comincia installando FreeBSD sul primo disco creando solamente due partizioni. Una dovrebbe essere una partizione di swap, pari al doppio della RAM presente nel sistema e il resto dello spazio dedicato al filesystem di root (/). È possibile creare partizioni separate per gli altri mount points, aumentando parecchio la difficoltà di realizzazione del progetto; questo è dovuto alla necessità di alterare manualmente i settaggi di bsdlabel(8) e fdisk(8).
Riavvia e aspetta che il sistema sia completamente attivo. Non appena il boot è completato effettua il login come root.
Crea il device /dev/mirror/gm e fai un link dello stesso a /dev/da1:
# gmirror label -vnb round-robin gm0 /dev/da1Il sistema dovrebbe rispondere con:
Metadata value stored on /dev/da1.
Done.Avvia GEOM,questa procedura caricherà nel kernel il modulo /boot/kernel/geom_mirror.ko
# gmirror loadQuesto comando dovrebbe ora avere creato i nodi di device gm0, gm0s1, gm0s1a e gm0s1c nella directory /dev/mirror. |
Crea una label generica e un codice di boot nel device gm0 appena creato utilizzando il comando fdisk:
# fdisk -vBI /dev/mirror/gm0Ora crea una label di informazioni generica con bsdlabel:
# bsdlabel -wB /dev/mirror/gm0s1Se sono presenti più slices e partizioni, i flags dei due comandi precedenti richiederanno delle modifiche. Queste modifiche devono combaciare con la grandezza delle slices e delle partizioni dell’altro disco. |
Utilizza l’utility newfs(8) per creare un filesystem di default sul nodo di device gm0s1a:
# newfs -U /dev/mirror/gm0s1aQuesto dovrebbe causare la visualizzazione di un bel pò di numeri e informazioni varie da parte del sistema. È corretto. Esamina bene lo schermo per vedere se ci sono messaggi di errore e monta il device in /mnt:
# mount /dev/mirror/gm0s1a /mntOra sposta tutti i dati presenti sul tuo disco di boot nel nuovo filesystem. Questo esempio usa i comandi dump(8) e restore(8) comunque anche dd(1) dovrebbe funzionare nel contesto che stiamo trattando. Evita di utilizzare tar(1) dal momento che non copia il codice di boot. In caso contrario il fallimento è garantito.
# dump -L -0 -f- / |(cd /mnt && restore -r -v -f-)Questo deve essere fatto per ciascun filesystem. Disponi semplicemente il filesystem appropriato nella posizione corretta quando digiti il suddetto comando.
Ora edita il file /mnt/etc/fstab "replicato" e rimuovi,o commenta (#) la riga relativa al file di swap. Per utilizzare il nuovo disco cambia le altre informazioni di filesystem. Dai un' occhiata al seguente esempio:
# Device Mountpoint FStype Options Dump Pass# #/dev/da0s2b none swap sw 0 0 /dev/mirror/gm0s1a / ufs rw 1 1
Ora crea un file boot.conf in entrambe le partizioni di root; quella corrente e quella nuova. Questo file aiuterà il BIOS di sistema ad effettuare il boot dal drive corretto.
# echo "1:da(1,a)/boot/loader" > /boot.config# echo "1:da(1,a)/boot/loader" > /mnt/boot.configLo abbiamo inserito in entrambe le partizioni di root per assicurarci un boot corretto. Se per qualche ragione il sistema non potesse leggere la nuova partizione di root, è disponibile una procedura di recupero. |
Adesso aggiungi la seguente linea al nuovo file /boot/loader.conf:
# echo 'geom_mirror_load="YES"' >> /mnt/boot/loader.confQuesto indicherà a loader(8) come caricare il modulo geom_mirror.ko durante l’inizializzazione del sistema.
Riavvia il sistema:
# shutdown -r nowSe tutto è andato liscio il sistema dovrebbe aver effettuato il boot di device gm0s1a e il prompt di login dovrebbe essere in attesa. Se qualcosa è andato storto fai riferimento alla sezione successiva "risoluzione dei problemi". Ora aggiungi al disco da0 al device gm0:
# gmirror configure -a gm0
# gmirror insert gm0 /dev/da0Il flag -a dice a gmirror(8) di usare la sincronizzazione automatica; ovvero mirrorare automaticamente le scritture sul disco. La manpage descrive come ricostruire o rimpiazzare i dischi, utilizzando data al posto di gm0.
Se al boot il sistema mostra un prompt simile a questo:
ffs_mountroot: can't find rootvp Root mount failed: 6 mountroot>
Riavvia la macchina utilizzando il tasto di reset o il pulsante di accensione. Arrivato al menu del boot, scegli l’opzione sei (6). Questo forzerà il sistema al prompt di loader(8). Carica manualmente il modulo del kernel:
OK? load geom_mirror.ko
OK? bootSe funziona significa che per qualche ragione il modulo non era stato caricato correttamente. Inserisci:
options GEOM_MIRROR
nel file di configurazione del kernek,ricompilalo e reinstallalo. Questo dovrebbe risolvere il problema.
Qualunque siano i dischi che hai, ci sono sempre dei problemi potenziali:
Potrebbero essere troppo piccoli.
Potrebbero essere troppo lenti.
Potrebbero essere troppo inaffidabili.
Un modo in cui alcuni utenti salvaguardano sè stessi contro questi problemi è attraverso l’uso di dischi multipli, e talvolta ridondanti.
In aggiunta a supportare diverse schede e controller per sistemi RAID hardware, il sistema FreeBSD base include il gestore di volumi Vinum, un driver di dispositivo a blocchi che implementa dischi virtuali.
Vinum fornisce più flessibilità, prestazioni, e affidabilità rispetto all’archiviazione su disco tradizionale e implementa i modelli RAID-0, RAID-1, e RAID-5 sia singolarmente che in combinazione.
Questo capitolo fornisce una panoramica sui potenziali problemi dell’archiviazione su disco tradizionale e un’introduzione al gestore di volumi Vinum.
Vinum è un Volume Manager, ovvero un driver virtuale di disco che si occupa dei tre problemi indicati nella sinossi. Diamo un’occhiata in dettaglio a questi problemi, per i quali sono state proposte e implementate varie soluzioni.
I dischi stanno diventando sempre più grandi, ma questo è vero anche per le necessità di spazio per i dati. Spesso sentirai il bisogno di avere un file system più grande dei dischi che possiedi. Effettivamente questo problema non è così grave come lo era dieci anni fa, ma è sempre presente. Alcuni sistemi risolvono la questione creando un dispositivo astratto che ripartisce i suoi dati su vari dischi.
I moderni sistemi hanno frequentemente la necessità di accedere ai dati in modo concorrente. Ad esempio, un grande server FTP o HTTP può avere migliaia di sessioni concorrenti e molteplici connessioni da 100 Mbit/s verso il mondo esterno, ben oltre il transfer rate (velocità di trasferimento) che la maggior parte dei dischi può sostenere.
I dischi odierni possono trasferire sequenzialmente dati fino a 70 MB/s, ma questo valore ha poca importanza in un ambiente dove molti processi indipendenti accedono al disco, in quanto raggiungerebbero solo una frazione di quella velocità. In questi casi è più interessante vedere il problema dal punto di vista del sottosistema dischi: il parametro importante è il carico che il trasferimento pone sul sottosistema, in altre parole il tempo per cui il trasferimento occupa i dischi necessari per lo stesso.
In ogni trasferimento da disco il drive deve prima posizionare le testine, poi aspettare che il primo settore passi sotto la testina di lettura e solo dopo può effettuare il trasferimento. Queste azioni possono essere considerate atomiche: non ha alcun senso interromperle.
Considera un tipico trasferimento di circa 10 kB: l’attuale generazione di dischi ad alte prestazioni può posizionare le testine in circa 3,5 ms. I dischi più veloci ruotano a 15.000 rpm, quindi la latenza media rotazionale (mezzo giro) è di 2 ms. A 70 MB/s, il trasferimento in sé occupa circa 150 μs, quasi nulla in confronto al tempo di posizionamento. In questo caso il transfer rate effettivo può scendere fino a poco oltre 1 MB/s e questo è chiaramente molto dipendente dalla dimensione del trasferimento.
La tradizionale e ovvia soluzione a questo collo di bottiglia è "più assi": invece di usare un grande disco si usano molti piccoli dischi con la stessa dimensione totale. Ogni disco è capace di posizionarsi e trasferire dati indipendentemente quindi la velocità effettiva aumenta di un fattore vicino al numero di dischi usati.
L’esatto fattore di miglioramento è, ovviamente, più piccolo del numero di dischi: benché ogni disco sia capace di trasferire in parallelo non c’è modo di assicurare che le richieste siano distribuite uniformemente tra tutti i dischi. Inevitabilmente il carico su uno dei dischi è più alto che sugli altri.
L’uniformità della distribuzione del carico sui dischi è fortemente dipendente dal modo in cui i dati sono condivisi tra i dischi stessi. Nella seguente discussione è conveniente pensare allo spazio di immagazzinamento come se fosse diviso in un gran numero di settori identificati da un indirizzo numerico, come pagine in un libro. Il metodo più ovvio è di dividere il disco virtuale in gruppi di settori consecutivi della dimensione dei dischi fisici e immagazzinarli in questa maniera, come strappare un grosso libro in piccole sezioni. Questo metodo è chiamato concatenazione e ha il vantaggio di non avere particolari richieste sulla dimensione degli specifici dischi. Funziona bene quando l’accesso al disco virtuale è ben ripartito tra tutto il suo spazio di indirizzamento. Quando l’accesso è concentrato in una piccola area il miglioramento è meno marcato. La Organizzazione Concatenata illustra la sequenza in cui le unità di immagazzinamento sono allocate nell’organizzazione concatenata.
Un metodo alternativo è dividere lo spazio di indirizzamento in più piccole componenti di egual dimensione e immagazzinarle sequenzialmente su differenti dispositivi. Per esempio i primi 256 settori potrebbero essere immagazzinati sul primo disco, i seguenti 256 settori sul disco seguente e così via. Dopo aver immagazzinato i dati sull’ultimo disco il processo si ripete finché i dischi non sono pieni. Questo mappamento è chiamato striping (letteralmente "a bande") o RAID-0. Lo striping richiede qualche sforzo aggiuntivo per localizzare i dati e può causare carico di I/O aggiuntivo quando il trasferimento è distribuito tra vari dischi, ma aiuta il carico a essere ben distribuito tra i vari dischi. La Organizzazione in Striping illustra la sequenza in cui i blocchi di dati sono allocati nell’organizzazione in striping.
L’ultimo problema dei dischi attuali è che sono inaffidabili. Benché la loro affidabilità sia aumentata tremendamente durante gli ultimi anni sono tuttora il componente di un server che ha la maggior probabilità di rompersi. Quando succede i risultati possono essere catastrofici: rimpiazzare un disco rotto e riempirlo dei dati originari può richiedere giorni.
Il metodo tradizionale per affrontare questo problema si chiama mirroring (letteralmente "specchiatura") e consiste nel tenere due copie dei dati su hardware fisici differenti. Con l’avvento dei livelli RAID questa tecnica è stata chiamata RAID di livello 1 o RAID-1. Ogni scrittura su disco scrive in entrambe le locazioni; una lettura può essere soddisfatta da entrambi quindi se un disco si rompe i dati sono sempre disponibili sull’altro disco.
Il mirroring ha due problemi:
Il prezzo. Richiede il doppio dello spazio di immagazzinamento delle soluzioni non ridondanti.
L’impatto sulle prestazioni. La scrittura deve essere compiuta su entrambi i dischi quindi la banda occupata raddoppia. Le letture non soffrono di problemi sulle prestazioni: possono perfino essere più veloci.
Una soluzione alternativa è la parità, implementata nel RAID di livello 2, 3, 4 e 5. Di questi, il RAID-5 è il più interessante. La sua implementazione in Vinum è una variante dell’organizzazione in striping che dedica un blocco di ogni banda alla parità degli altri blocchi. Per come è implementato in Vinum, ogni blocco RAID-5 è simile a un blocco in striping, con la differenza che implementa il RAID-5 includendo un blocco di parità per ogni banda. Come richiesto dal RAID-5 la locazione di questi blocchi di parità cambia da ogni banda alla successiva. I numeri nei blocchi dati indicano il numero dei blocchi relativi.
Comparandolo al mirroring, il RAID-5 ha il vantaggio di richiedere molto meno spazio di immagazzinamento. La velocità di lettura è simile all’organizzazione in striping, ma in scrittura l’accesso è significativamente più lento, circa il 25% della performance di lettura. Se uno dei dischi si rompe l’aggregato continua a lavorare con performance peggiorate: la lettura da uno dei dischi rimanenti continua normalmente, ma la lettura dal disco rotto è ricalcolata dai corrispondenti blocchi dei dischi rimanenti.
Per risolvere questi problemi Vinum implementa una categoria di oggetti a quattro livelli:
L’oggetto più visibile è il disco virtuale, chiamato volume. I volumi hanno essenzialmente le stesse proprietà di un disco UNIX®, benché ci sia qualche differenza minore. Non hanno limiti di dimensione.
I volumi sono composti da plex, ognuno dei quali rappresenta il completo spazio di indirizzamento del volume. È quindi questo il livello della gerarchia che gestisce la ridondanza dei dati. Pensa ai plex come a singoli dischi collegati tra loro in mirroring, ognuno contenente gli stessi dati.
Dato che Vinum vive all’interno del framework UNIX® di immagazzinamento dei dati sarebbe possibile utilizzare le partizioni UNIX® come blocchi basilari per costruire i plex multidisco, ma questo approccio sarebbe in effetti troppo poco flessibile: i dischi UNIX® possono avere solo un limitato numero di partizioni; al contrario Vinum suddivide le singole partizioni UNIX® (drive, ovvero dischi) in aree contigue chiamate subdisks (sottodischi), che sono a loro volta utilizzati come elementi per costruire i plex.
I sottodischi risiedono su drive Vinum, che attualmente sono partizioni UNIX®. I drive Vinum possono contenere qualsiasi quantità di sottodischi. Con l’eccezione di una piccola area all’inizio del drive, che è usata per immagazzinare informazioni sulla configurazione e sullo stato, l’intero drive è disponibile per l’immagazzinamento dei dati.
La sezione seguente descrive come gli oggetti sopra discussi possano dare le funzionalità richieste.
I plex possono contenere molteplici sottodischi distribuiti tra tutti i drive presenti nella configurazione di Vinum, questo permette alla dimensione dei plex, e quindi anche dei volumi, di non essere limitata dalla dimensione dei singoli dischi.
Vinum implementa il mirroring collegando più plex allo stesso volume, ogni plex contiene la rappresentazione di tutti i dati del volume. Un volume può contenere da uno ad otto plex.
Nonostante un plex rappresenti i dati di un volume per intero, è possibile che parti di questa rappresentazione vengano a mancare o per scelta (non definendo dei sottodischi per alcune parti del plex) o per accidente (come risultato della rottura del disco che le conteneva). Finché almeno un plex contiene i dati di tutto lo spazio d’indirizzamento del volume, il volume stesso è completamente funzionale.
Vinum implementa sia la concatenazione che lo striping al livello di plex:
Un plex concatenato usa lo spazio di indirizzamento di ogni sottodisco a turno.
Un plex in striping suddivide i dati tra ogni sottodisco. I sottodischi devono tutti avere la stessa dimensione e devono essere presenti almeno due sottodischi perché esista differenza da un plex concatenato.
La versione di Vinum distribuita con FreeBSD 12.0 implementa due tipi di plex:
I plex concatenati, che sono i più flessibili: possono contenere qualsiasi numero di sottodischi e questi possono avere qualsiasi dimensione. Il plex può essere esteso aggiungendo sottodischi. Richiede meno tempo di CPU di un plex in striping, benché la differenza in carico di CPU non sia misurabile. D’altro canto sono più suscettibili agli hot spot (letteralmente "zona calda"): ovvero situazioni in cui un disco è molto attivo mentre gli altri sono fermi.
Il più grande vantaggio dei plex in striping (RAID-0) è la loro capacità di ridurre gli hot spot: scegliendo una dimensione di striping ottimale (circa 256 kB) si può ridistribuire il carico sui drive. Gli svantaggi di questo approccio sono codice più complesso e restrizioni sui sottodischi: devono essere tutti della stessa dimensione, inoltre estendere il plex aggiungendo sottodischi è così complicato che attualmente Vinum non lo implementa. Vinum aggiunge anche un’ulteriore restrizione elementare: un plex in striping deve contenere almeno due sottodischi, dato che sarebbe altrimenti indistinguibile da un plex concatenato.
La Organizzazione dei Plex Vinum riassume vantaggi e svantaggi di ogni tipo di organizzazione dei plex.
| Tipo di plex | Sottodischi minimi | Sottodischi aggiungibili | Dimensioni forzatamente uguali | Applicazione |
|---|---|---|---|---|
concatenato | 1 | sì | no | Immagazzinamento di grandi moli di dati con la massima flessibilità e prestazioni moderate |
striping | 2 | no | sì | Alte prestazioni in casi di accessi altamente concorrenti |
Vinum mantiene un database della configurazione che descrive gli oggetti del sistema conosciuti. Inizialmente l’utente crea il database della configurazione da uno o più file di configurazione, con l’aiuto del programma vinum(8). Vinum immagazzina una copia del database di configurazione in ogni slice del disco (che Vinum chiama device, ovvero "dispositivo") sotto il suo controllo. Questo database è aggiornato a ogni cambio di stato in modo che un riavvio possa recuperare accuratamente lo stato di ogni oggetto Vinum.
Il file di configurazione descrive singoli oggetti Vinum. La definizione di un semplice volume potrebbe essere:
drive a device /dev/da3h
volume myvol
plex org concat
sd length 512m drive aQuesto file descrive quattro oggetti Vinum:
La linea drive descrive la partizione del disco (drive) e la sua locazione relativa all’hardware sottostante. Gli viene assegnato il nome simbolico a. Questa separazione dei nomi simbolici dai nomi di dispositivo permette di muovere i dischi da una locazione ad un’altra senza confusione.
La linea volume descrive un volume. L’unico attributo richiesto è il nome, in questo caso myvol.
La linea plex definisce un plex. L’unico parametro richiesto è il tipo di organizzazione, in questo caso concat. Non è necessario un nome: il sistema genera un nome automaticamente a partire dal nome del volume, aggiungendo un suffisso .px, dove x indica il numero del plex nel volume. Il plex verrà quindi chiamato myvol.p0.
La linea sd descrive un sottodisco. Le specifiche minime sono il nome del drive su cui immagazzinarlo e la lunghezza del sottodisco. Come per i plex non è necessario un nome: il sistema assegna automaticamente nomi derivati dal nome del plex, aggiungendo il suffisso .sx, dove x indica il numero del sottodisco nel plex, quindi Vinum darà a questo sottodisco il nome di myvol.p0.s0.
Dopo aver elaborato questo file, vinum(8) produce il seguente output:
# vinum -> create config1
Configuration summary
Drives: 1 (4 configured)
Volumes: 1 (4 configured)
Plexes: 1 (8 configured)
Subdisks: 1 (16 configured)
D a State: up Device /dev/da3h Avail: 2061/2573 MB (80%)
V myvol State: up Plexes: 1 Size: 512 MB
P myvol.p0 C State: up Subdisks: 1 Size: 512 MB
S myvol.p0.s0 State: up PO: 0 B Size: 512 MBQuesto output mostra il formato di elenco breve di vinum(8), che è rappresentato graficamente nella Un Semplice Volume Vinum.
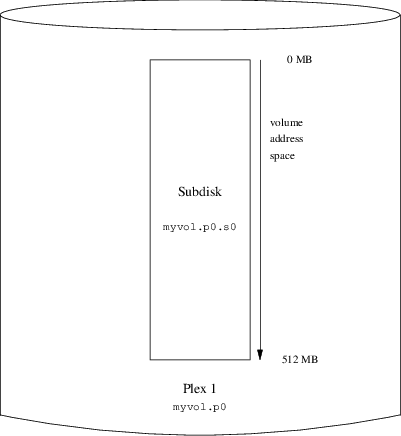
Questa figura e quelle che seguono rappresentano un volume contenente dei plex che a loro volta contengono dei sottodischi. In questo semplice esempio il volume contiene un plex e il plex contiene un sottodisco.
Questo particolare volume non ha specifici vantaggi su una convenzionale partizione di disco. Contiene un singolo plex, quindi non è ridondante. Il plex contiene un solo sottodisco, quindi non c’è differenza nell’immagazzinamento dei dati. Le sezioni seguenti mostrano vari metodi di configurazione più interessanti.
Il mirroring può aumentare, in un volume, la resistenza alle rotture. Quando si definisce un volume in mirroring è importante assicurarsi che i sottodischi di ogni plex siano su dischi differenti, in modo che la rottura di un drive non blocchi entrambi i plex. La seguente configurazione mostra un volume in mirroring:
drive b device /dev/da4h
volume mirror
plex org concat
sd length 512m drive a
plex org concat
sd length 512m drive bIn questo esempio non è necessario specificare nuovamente la definizione del drive a, dato che Vinum mantiene traccia di tutti gli oggetti nel suo database di configurazione. Dopo aver elaborato questa definizione, la configurazione appare così:
Drives: 2 (4 configured)
Volumes: 2 (4 configured)
Plexes: 3 (8 configured)
Subdisks: 3 (16 configured)
D a State: up Device /dev/da3h Avail: 1549/2573 MB (60%)
D b State: up Device /dev/da4h Avail: 2061/2573 MB (80%)
V myvol State: up Plexes: 1 Size: 512 MB
V mirror State: up Plexes: 2 Size: 512 MB
P myvol.p0 C State: up Subdisks: 1 Size: 512 MB
P mirror.p0 C State: up Subdisks: 1 Size: 512 MB
P mirror.p1 C State: initializing Subdisks: 1 Size: 512 MB
S myvol.p0.s0 State: up PO: 0 B Size: 512 MB
S mirror.p0.s0 State: up PO: 0 B Size: 512 MB
S mirror.p1.s0 State: empty PO: 0 B Size: 512 MBUn Volume Vinum in Mirroring mostra la struttura graficamente.
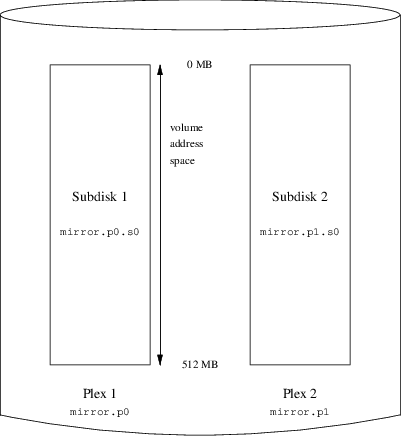
In questo esempio ogni plex contiene l’intero spazio di indirizzamento di 512 MB. Come nel precedente esempio ogni plex contiene un solo sottodisco.
Il volume in mirroring dell’esempio precedente è più resistente alle rotture di un volume non in mirroring, ma le sue prestazioni sono inferiori: ogni scrittura sul volume richiede una scrittura su ognuno dei drive, utilizzando quindi una maggior frazione della banda passante totale dei dischi. Considerazioni sulle prestazioni portano ad un differente approccio: al posto del mirroring, i dati vengono posti sul maggior numero di dischi possibile utilizzando lo striping. La seguente configurazione mostra un volume con un plex in striping su quattro dischi:
drive c device /dev/da5h
drive d device /dev/da6h
volume stripe
plex org striped 512k
sd length 128m drive a
sd length 128m drive b
sd length 128m drive c
sd length 128m drive dCome prima non è necessario definire i drive che Vinum già conosce. Dopo aver elaborato queste definizioni la configurazione appare così:
Drives: 4 (4 configured)
Volumes: 3 (4 configured)
Plexes: 4 (8 configured)
Subdisks: 7 (16 configured)
D a State: up Device /dev/da3h Avail: 1421/2573 MB (55%)
D b State: up Device /dev/da4h Avail: 1933/2573 MB (75%)
D c State: up Device /dev/da5h Avail: 2445/2573 MB (95%)
D d State: up Device /dev/da6h Avail: 2445/2573 MB (95%)
V myvol State: up Plexes: 1 Size: 512 MB
V mirror State: up Plexes: 2 Size: 512 MB
V striped State: up Plexes: 1 Size: 512 MB
P myvol.p0 C State: up Subdisks: 1 Size: 512 MB
P mirror.p0 C State: up Subdisks: 1 Size: 512 MB
P mirror.p1 C State: initializing Subdisks: 1 Size: 512 MB
P striped.p1 State: up Subdisks: 1 Size: 512 MB
S myvol.p0.s0 State: up PO: 0 B Size: 512 MB
S mirror.p0.s0 State: up PO: 0 B Size: 512 MB
S mirror.p1.s0 State: empty PO: 0 B Size: 512 MB
S striped.p0.s0 State: up PO: 0 B Size: 128 MB
S striped.p0.s1 State: up PO: 512 kB Size: 128 MB
S striped.p0.s2 State: up PO: 1024 kB Size: 128 MB
S striped.p0.s3 State: up PO: 1536 kB Size: 128 MB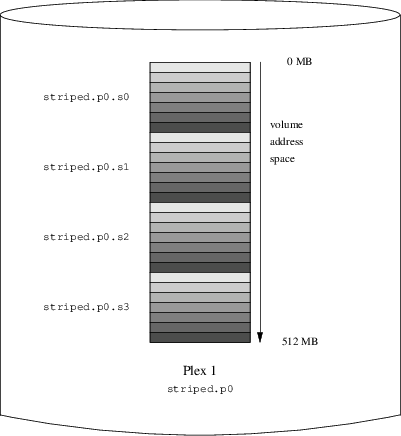
Questo volume è rappresentato nella Un Volume Vinum in Striping. L’intensità del colore delle strisce indica la posizione all’interno dello spazio di indirizzamento del plex: le più chiare all’inizio, le più scure alla fine.
Con hardware a sufficenza è possibile creare volumi con miglioramenti sia nella resistenza alle rotture che nelle prestazioni, comparati alle normali partizioni UNIX®. Una tipica configurazione potrebbe essere:
volume raid10
plex org striped 512k
sd length 102480k drive a
sd length 102480k drive b
sd length 102480k drive c
sd length 102480k drive d
sd length 102480k drive e
plex org striped 512k
sd length 102480k drive c
sd length 102480k drive d
sd length 102480k drive e
sd length 102480k drive a
sd length 102480k drive bI sottodischi del secondo plex sono spostati di due posti rispetto a quelli del primo plex: questo aumenta le probabilità che le scritture non utilizzino lo stesso sottodisco anche nel caso in cui un trasferimento utilizzi entrambi i drive.
La Un Volume Vinum in Mirroring e Striping rappresenta la struttura di questo volume.
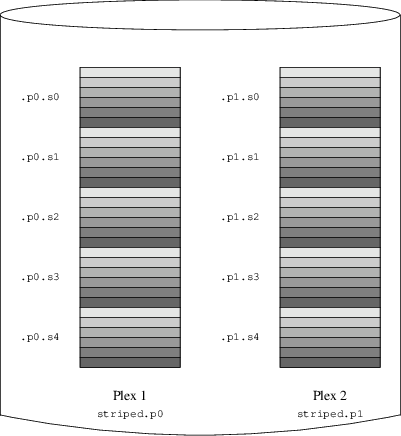
Come descritto sopra, Vinum assegna nomi di default a plex e sottodischi, benché questi possano essere cambiati. Cambiare il nome di default non è raccomandato: l’esperienza con il VERITAS volume manager, che permette la nomenclatura arbitraria degli oggetti, ha mostrato che questa flessibilità non porta vantaggi significativi e può causare confusione.
I nomi possono contenere ogni carattere non blank (i caratteri di spazio, tabulazione, cambio riga) ma è consigliato limitarsi a lettere, cifre e il carattere di underscore. I nomi di volumi, plex e sottodischi possono essere lunghi fino a 64 caratteri, i nomi di drive invece hanno un massimo di 32 caratteri.
I nomi assegnati agli oggetti Vinum sono nella gerarchia /dev/vinum. La configurazione di Vinum mostrata sopra creerebbe i seguenti dispositivi:
I dispositivi di controllo /dev/vinum/control e /dev/vinum/controld, utilizzati rispettivamente da vinum(8) e dal demone Vinum.
Voci di dispositivi a blocchi e a caratteri per ogni volume. Questi sono i principali dispositivi utilizzati da Vinum. I dispositivi a blocchi hanno il nome dei relativi volumi, quelli a caratteri, seguendo la tradizione BSD, hanno una lettera r all’inizio del nome. Quindi la configurazione vista sopra genererebbe i dispositivi a blocchi /dev/vinum/myvol, /dev/vinum/mirror, /dev/vinum/striped, /dev/vinum/raid5 e /dev/vinum/raid10, e i dispositivi a caratteri /dev/vinum/rmyvol, /dev/vinum/rmirror, /dev/vinum/rstriped, /dev/vinum/rraid5 e /dev/vinum/rraid10. In questo c’è un ovvio problema: è possibile avere due volumi chiamati r e rr che avrebbero un conflitto nel creare il nodo /dev/vinum/rr: sarebbe il dispositivo a caratteri per il volume r o il dispositivo a blocchi per il volume rr? Attualmente Vinum non si interessa di questo conflitto: il volume definito per primo prende il nome.
Una directory /dev/vinum/drive con voci per ogni disco. Queste voci sono in effetti dei collegamenti simbolici ai rispettivi nodi di disco.
Una directory /dev/vinum/volume con voci per ogni volume. Contiene sottodirectory per ogni plex, che a loro volta contengono sottodirectory per ogni sottodisco.
Le directory /dev/vinum/plex, /dev/vinum/sd e /dev/vinum/rsd contengono i dispositivi a blocchi per ogni plex, dispositivo a blocchi e dispositivo a caratteri per ogni sottodisco rispettivamente.
Ad esempio, considera il seguente file di configurazione:
drive drive1 device /dev/sd1h
drive drive2 device /dev/sd2h
drive drive3 device /dev/sd3h
drive drive4 device /dev/sd4h
volume s64 setupstate
plex org striped 64k
sd length 100m drive drive1
sd length 100m drive drive2
sd length 100m drive drive3
sd length 100m drive drive4Dopo aver elaborato questo file, vinum(8) crea la seguente struttura in /dev/vinum:
brwx------ 1 root wheel 25, 0x40000001 Apr 13 16:46 Control
brwx------ 1 root wheel 25, 0x40000002 Apr 13 16:46 control
brwx------ 1 root wheel 25, 0x40000000 Apr 13 16:46 controld
drwxr-xr-x 2 root wheel 512 Apr 13 16:46 drive
drwxr-xr-x 2 root wheel 512 Apr 13 16:46 plex
crwxr-xr-- 1 root wheel 91, 2 Apr 13 16:46 rs64
drwxr-xr-x 2 root wheel 512 Apr 13 16:46 rsd
drwxr-xr-x 2 root wheel 512 Apr 13 16:46 rvol
brwxr-xr-- 1 root wheel 25, 2 Apr 13 16:46 s64
drwxr-xr-x 2 root wheel 512 Apr 13 16:46 sd
drwxr-xr-x 3 root wheel 512 Apr 13 16:46 vol
/dev/vinum/drive:
total 0
lrwxr-xr-x 1 root wheel 9 Apr 13 16:46 drive1 -> /dev/sd1h
lrwxr-xr-x 1 root wheel 9 Apr 13 16:46 drive2 -> /dev/sd2h
lrwxr-xr-x 1 root wheel 9 Apr 13 16:46 drive3 -> /dev/sd3h
lrwxr-xr-x 1 root wheel 9 Apr 13 16:46 drive4 -> /dev/sd4h
/dev/vinum/plex:
total 0
brwxr-xr-- 1 root wheel 25, 0x10000002 Apr 13 16:46 s64.p0
/dev/vinum/rsd:
total 0
crwxr-xr-- 1 root wheel 91, 0x20000002 Apr 13 16:46 s64.p0.s0
crwxr-xr-- 1 root wheel 91, 0x20100002 Apr 13 16:46 s64.p0.s1
crwxr-xr-- 1 root wheel 91, 0x20200002 Apr 13 16:46 s64.p0.s2
crwxr-xr-- 1 root wheel 91, 0x20300002 Apr 13 16:46 s64.p0.s3
/dev/vinum/rvol:
total 0
crwxr-xr-- 1 root wheel 91, 2 Apr 13 16:46 s64
/dev/vinum/sd:
total 0
brwxr-xr-- 1 root wheel 25, 0x20000002 Apr 13 16:46 s64.p0.s0
brwxr-xr-- 1 root wheel 25, 0x20100002 Apr 13 16:46 s64.p0.s1
brwxr-xr-- 1 root wheel 25, 0x20200002 Apr 13 16:46 s64.p0.s2
brwxr-xr-- 1 root wheel 25, 0x20300002 Apr 13 16:46 s64.p0.s3
/dev/vinum/vol:
total 1
brwxr-xr-- 1 root wheel 25, 2 Apr 13 16:46 s64
drwxr-xr-x 3 root wheel 512 Apr 13 16:46 s64.plex
/dev/vinum/vol/s64.plex:
total 1
brwxr-xr-- 1 root wheel 25, 0x10000002 Apr 13 16:46 s64.p0
drwxr-xr-x 2 root wheel 512 Apr 13 16:46 s64.p0.sd
/dev/vinum/vol/s64.plex/s64.p0.sd:
total 0
brwxr-xr-- 1 root wheel 25, 0x20000002 Apr 13 16:46 s64.p0.s0
brwxr-xr-- 1 root wheel 25, 0x20100002 Apr 13 16:46 s64.p0.s1
brwxr-xr-- 1 root wheel 25, 0x20200002 Apr 13 16:46 s64.p0.s2
brwxr-xr-- 1 root wheel 25, 0x20300002 Apr 13 16:46 s64.p0.s3Benché sia raccomandato non allocare nomi specifici a plex e sottodischi, i drive di Vinum devono avere un nome. Questo permette di spostare un disco in una differente locazione e continuare a riconoscerlo automaticamente. I nomi di drive possono essere lunghi fino a 32 caratteri.
I volumi appaiono al sistema identici ai dischi, con un’eccezione. Differentemente dai dischi UNIX®, Vinum non partiziona i volumi, che quindi non contengono una tabella delle partizioni. Questo ha reso necessario modificare alcuni programmi di utilità del disco, tra cui newfs(8), che precedentemente cercava di interpretare l’ultima lettera di un volume Vinum come un identificatore di partizione. Ad esempio un disco potrebbe avere un nome come /dev/ad0a o /dev/da2h. Questi nomi rappresentano la prima partizione (a) del primo (0) disco IDE (ad) e l’ottava partizione (h) del terzo (2) disco SCSI (da), rispettivamente. Al contrario un volume Vinum potrebbe essere chiamato /dev/vinum/concat, un nome che non ha alcuna relazione con nomi di partizione.
Normalmente newfs(8) interpreta il nome del disco e si lamenta se non riesce a comprenderlo. Per esempio:
# newfs /dev/vinum/concat
newfs: /dev/vinum/concat: can't figure out file system partitionQueste informazioni sono valide solo per versioni di FreeBSD precedenti alla 5.0: |
Per poter creare un file system su questo volume usa newfs(8) con l’opzione -v:
# newfs -v /dev/vinum/concatIl kernel GENERIC non contiene Vinum. È possibile creare un kernel speciale che lo contenga, ma questo non è raccomandato: il metodo standard per lanciare Vinum è come modulo del kernel (kld). Non è neanche necessario usare kldload(8) per Vinum: quando lanci vinum(8) il programma controlla se il modulo è stato caricato e, in caso non sia caricato, lo carica automaticamente.
Vinum immagazzina le informazioni sulla configurazione dei dischi essenzialmente nella stessa forma dei file di configurazione. Quando legge il database di configurazione Vinum riconosce un numero di parole chiave che non sono permesse nei file di configurazione, ad esempio un file di configurazione del disco potrebbe contenere il seguente testo:
volume myvol state up volume bigraid state down plex name myvol.p0 state up org concat vol myvol plex name myvol.p1 state up org concat vol myvol plex name myvol.p2 state init org striped 512b vol myvol plex name bigraid.p0 state initializing org raid5 512b vol bigraid sd name myvol.p0.s0 drive a plex myvol.p0 state up len 1048576b driveoffset 265b plexoffset 0b sd name myvol.p0.s1 drive b plex myvol.p0 state up len 1048576b driveoffset 265b plexoffset 1048576b sd name myvol.p1.s0 drive c plex myvol.p1 state up len 1048576b driveoffset 265b plexoffset 0b sd name myvol.p1.s1 drive d plex myvol.p1 state up len 1048576b driveoffset 265b plexoffset 1048576b sd name myvol.p2.s0 drive a plex myvol.p2 state init len 524288b driveoffset 1048841b plexoffset 0b sd name myvol.p2.s1 drive b plex myvol.p2 state init len 524288b driveoffset 1048841b plexoffset 524288b sd name myvol.p2.s2 drive c plex myvol.p2 state init len 524288b driveoffset 1048841b plexoffset 1048576b sd name myvol.p2.s3 drive d plex myvol.p2 state init len 524288b driveoffset 1048841b plexoffset 1572864b sd name bigraid.p0.s0 drive a plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 0b sd name bigraid.p0.s1 drive b plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 4194304b sd name bigraid.p0.s2 drive c plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 8388608b sd name bigraid.p0.s3 drive d plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 12582912b sd name bigraid.p0.s4 drive e plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 16777216b
Le ovvie differenze sono qua la presenza di informazioni esplicite sulle locazioni e sulla nomenclatura (entrambe permesse, ma scoraggiate, all’utente) e le informazioni sugli stati (che non sono disponibili all’utente). Vinum non immagazzina informazioni sui drive tra le informazioni della configurazione: trova i drive scandendo le partizioni dei dischi configurati alla ricerca di un’etichetta Vinum. Questo permette a Vinum di identificare i drive correttamente anche se gli è stato assegnato un differente codice identificativo di drive UNIX®.
Per poter lanciare Vinum automaticamente all’avvio del sistema assicuratevi che le seguenti linee siano nel vostro /etc/rc.conf:
start_vinum="YES" # set to YES to start vinum
Se non hai un file /etc/rc.conf, creane uno con questo contenuto. Questo ordinerà al sistema di caricare il Vinum kld all’avvio, inizializzando ogni oggetto menzionato nella configurazione. Questo viene fatto prima del mount dei file system quindi è possibile fare automaticamente fsck(8) e mount dei file system su volumi Vinum.
Quando esegui Vinum con il comando vinum start Vinum legge il database di configurazione da uno dei drive Vinum. In circostanze normali ogni drive contiene una copia identica del database di configurazione quindi non conta da quale disco viene letto. Dopo un crash, tuttavia, Vinum deve determinare quale drive è stato aggiornato più recentemente e leggere la configurazione da questo drive. Quindi aggiorna la configurazione, se necessario, sui drive progressivamente più vecchi.
Per una macchina con filesystem completamente in mirroring con Vinum è desiderabile mettere in mirroring anche il filesystem di root; fare questo è meno semplice che non per un filesystem arbitrario, dato che:
Il filesystem root deve essere disponibile nella parte iniziale del processo di boot, quindi l’infrastruttura di Vinum deve essere già disponibile in quel momento.
Il volume contenente il filesystem root contiene anche il sistema di avvio e il kernel, che devono essere letti usando le funzioni native del sistema (ovvero il BIOS, sui PC) che spesso non conoscono i dettagli di Vinum.
Nelle sezioni seguenti, il termine "volume root" è usato generalmente per descrivere il volume Vinum che contiene il filesystem root. È probabilmente una buona idea usare il nome "root" per questo volume, ma non è necessario. Tutti gli esempi nelle prossime sezioni usano questo nome.
Ci sono varie misure da prendere per fare in modo che questo accada:
Vinum deve essere disponibile nel kernel già all’avvio, quindi il metodo per lanciare Vinum automaticamente descritto in Avvio Automatico non può essere utilizzato e il parametro start_vinum in realtà non va impostato in questo tipo di configurazione. La prima possibilità è di compilare Vinum staticamente dentro al kernel, in modo che sia sempre disponibile, ma questo non è normalmente desiderabile. Un’altra opportunità à di fare in modo che /boot/loader (Stadio Tre) carichi il modulo kernel di Vinum prima di lanciare il kernel. Questo può essere fatto utilizzando la riga:
vinum_load="YES"
nel file /boot/loader.conf.
Vinum deve essere inizializzato subito in modo da poter fornire il volume per il filesystem root. Per default la porzione kernel di Vinum non cerca dischi che contengano informazioni sui volumi Vinum fino a quando un amministratore (o uno degli script di partenza) non esegue un comando di vinum start.
I seguenti paragrafi spiegano i passi necessari per FreeBSD 5.X e superiori. L’impostazione richiesta da FreeBSD 4.X è diversa ed è descritta dopo, in Differenze per FreeBSD 4.X. |
Inserendo la linea:
vinum.autostart="YES"
dentro a /boot/loader.conf, Vinum viene istruito, alla partenza del kernel, di controllare automaticamente tutti i dischi alla ricerca di informazioni sui volumi Vinum.
Da notare il fatto che non è necessario istruire il kernel sulla locazione del filesystem root. /boot/loader cerca il nome del device di root in /etc/fstab e passa l’informazione al kernel. Quando è necessario montare il filesystem root, il kernel, tramite il nome di device fornitogli, capisce a quale driver deve chiedere la conversione di tale nome in ID interno di device (numero maggiore/minore).
Dato che il codice di avvio di FreeBSD è attualmente di soli 7.5 KB ed è già appesantito dalla lettura di file (come /boot/loader) da un filesystem UFS, è semplicemente impossibile insegnargli anche a leggere le strutture interne di Vinum in modo da fargli leggere i dati della configurazione di Vinum per ricavarne gli elementi del volume di boot stesso. Sono quindi necessari alcuni trucchi per dare al codice di avvio l’illusione di una partizione "a" standard contenente il filesystem di root.
Perché questo sia anche solo possibile, il volume di root deve rispondere ai seguenti requisiti:
Il volume di root non deve essere in striping o in RAID-5.
Il volume di root non deve contenere la concatenazione di più di un sottodisco per ogni plex.
Da notare che è desiderabile e possibile avere plex multipli, contenente ognuno una replica del filesystem root. Il processo di avvio, però, usa solo una di queste repliche per trovare i file necessario all’avvio, fino a quando il kernel monta il filesystem di root stesso. Ogni singolo sottodisco in questi plex avrà quindi bisogno di una propria partizione "a" illusoria, affinché la periferica relativa possa essere avviabile. Non è strettamente necessario che ognuna di queste finte partizioni "a" sia locato con lo stesso spiazzamento all’interno della propria periferica, rispetto alle periferiche contenenti gli altri plex del volume. È comunque probabilmente una buona idea creare i volumi Vinum in modo che le periferiche in mirror siano simmetriche, per evitare confusione.
Per poter configurare queste partizioni "a", in ogni periferica contenente parte del volume di root, bisogna fare le seguenti cose:
La locazione (spiazzamento dall’inizio della periferica) e la dimensione del sottodisco che è parte del volume di root deve essere esaminato, usando il comando:
# vinum l -rv rootDa notare che gli spiazzamenti e le dimensioni in Vinum sono misurati in byte. Devono essere divisi per 512 per ottenere il numero di blocchi necessari nel comando disklabel.
Esegui il comando:
# disklabel -e devnameper ogni periferica che partecipa al volume di root. devname deve essere o il nome della slice (ad esempio ad0s1) o il nome del disco (ad esempio da0) per dischi senza tabella delle slice (ovvero i nomi che si usano anche con fdisk).
Se c’è già una partizione "a" sulla periferica (presumibilmente contenente un filesystem root precedente all’uso di Vinum), dovrebbe essere rinominata in altro modo, in modo da restare accessibile (non si sa mai), ma non essere usata più per default per avviare il sistema. Da notare che le partizioni attive (ad esempio un filesystem root attualmente montato) non possono essere rinominati, quindi questo deve essere eseguito o avviando da un disco "Fixit" o (in caso di mirror) in un processo a due passi dove il disco non di avvio viene modificato per primo.
Infine, lo spiazzamento della partizione Vinum sulla periferica va aggiunto allo spiazzamento del rispettivo sottodisco di root rispetto alla periferica stessa. Il risultato sarà il valore di "offset" (spiazzamento) per la nuova partizione "a". Il valore "size" (dimensione) per questa partizione può essere copiato pari pari dal calcolo fatto sopra. Il valore "fstype" deve essere 4.2BSD. I valori "fsize", "bsize" e "cpg" devono preferibilmente essere scelti per corrispondere al vero e proprio filesystem, anche se in questo contesto non sono molto importanti.
In questo modo una nuova partizione "a" sarà creata ricoprendo le partizioni Vinum su questa periferica. Da notare che disklabel permetterà questa ricopertura solo se la partizione Vinum è stata appropriatamente marcata usando un "fstype" pari a "vinum" fstype.
È tutto! Ora una falsa partizione "a" esiste su ogni periferica che abbia una replica del volume di root. È altamente raccomandabile verificare nuovamente i risultati, usando un comando come:
# fsck -n /dev/devnameaBisogna ricordarsi che tutte le informazioni contenute nei file di controllo devono essere relative al filesystem di root nel volume Vinum che, quando si imposta un nuovo volume di root Vinum, potrebbe non coincidere con quello del filesystem root attualmente attivo. In particolare bisogna stare attenti ai file /etc/fstab e /boot/loader.conf.
Al seguente riavvio il sistema dovrebbe ricavare le informazioni di controllo appropriate dal filesystem di root Vinum e agire di consequenza. Alla fine del processo di inizializzazione del kernel, dopo che tutte le periferiche sono state annunciate, l’avvertimento principale che conferma il successo dell’avvio è un messaggio simile a questo:
Mounting root from ufs:/dev/vinum/rootDopo aver creato il volume di root Vinum, vinum l -rv root dovrebbe produrre qualcosa di simile a:
...
Subdisk root.p0.s0:
Size: 125829120 bytes (120 MB)
State: up
Plex root.p0 at offset 0 (0 B)
Drive disk0 (/dev/da0h) at offset 135680 (132 kB)
Subdisk root.p1.s0:
Size: 125829120 bytes (120 MB)
State: up
Plex root.p1 at offset 0 (0 B)
Drive disk1 (/dev/da1h) at offset 135680 (132 kB)I valori su cui fare caso sono il 135680 dello spiazzamento (relativo alla partizione /dev/da0h). Questo si traduce in 265 blocchi da 512 byte nei termini di disklabel. /dev/da1h, contenente la seconda replica del volume di root, ha una configurazione simmetrica.
La disklabel per queste periferiche dovrebbe essere simile a questa:
...
8 partitions:
# size offset fstype [fsize bsize bps/cpg]
a: 245760 281 4.2BSD 2048 16384 0 # (Cyl. 0*- 15*)
c: 71771688 0 unused 0 0 # (Cyl. 0 - 4467*)
h: 71771672 16 vinum # (Cyl. 0*- 4467*)Si può notare che il parametro "size" per la finta partizione "a" corrisponde al valore di cui abbiamo parlato prima, mentre il parametro "offset" è la somma dello spiazzamento all’interno della partizione Vinum "h" e lo spiazzamento all’interno della periferica (o slice). Questa è una tipica configurazione necessaria per evitare il problema descritto in Non si Carica Niente, l’Avvio va in Panico. Si può anche notare che l’intera partizione "a" è completamente contenuta dalla partizione "h", che contiene tutti i dati Vinum per questa periferica.
Notate che in questo esempio l’intera periferica è dedicata a Vinum e non c’è spazio per partizioni pre-Vinum, dato che questo disco è stato configurato da nuovo per il solo scopo di far parte di una configurazione Vinum.
Se qualcosa va storto, serve un modo per tornare in una situazione di normalità. Segue una lista di alcuni tipici problemi, completi di soluzione.
Se per qualsiasi ragione in sistema non prosegue nell’avvio, si può interrompere il processo di avvio premendo il tasto spazio all’avviso dei 10 secondi. Le variabili di avvio potranno quindi essere esaminate usando il comando show e manipolate con set e unset.
Se l’unico problema è che il modulo kernel di Vinum non è ancora presente nella lista dei moduli da caricare automaticamente, un semplice load vinum aiuterà.
Quando pronti, il processo di avvio può continuare con un boot -as. Le opzioni -as comunicano al kernel di montare il filesystem di root (-a) e di interrompere il processo di avvio in modalità singolo utente (-s), quando il filesystem di root è montato a sola lettura. In questo modo benché uno solo dei plex do un volume multi-plex sia stato montato, non si rischia inconsistenza dei dati tra i vari plex.
Alla richiesta di un filesystem di root da montare, ogni periferica che contenga un filesystem di root valido può essere usata. Se /etc/fstab è stato impostato correttamente, il default dovrebbe essere ufs:/dev/vinum/root o simile. Una tipica alternativa potrebbe essere ufs:da0d, una ipotetica partizione contenente un filesystem root pre-Vinum. Bisogna fare attenzione quando si sceglie una delle partizioni "a" alias di un sottodisco della periferica root di Vinum, perché in una configurazione in mirror questo monterebbe solo un pezzo della root in mirror. Se questo filesystem deve poi essere montato in lettura/scrittura è necessario rimuovere gli altri plex del volume root di Vinum dato che conterrebbero comunque dati non consistenti.
Se /boot/loader non si carica, ma l’avvio primario si carica comunque (si capisce dal singolo trattino nella colonna di sinistra dello schermo subito dopo l’inizio dell’avvio), si può tentare di fermare l’avvio primario in questo punto, premendo il tasto spazio. Questo fermerà l’avvio nella seconda fase, vedi Stadio Uno. Qua si può fare un tentativo di caricare una differente partizione, ad esempio la partizione contenente il precedente filesystem di root "a", prima di sostituirlo come sopra indicato.
Questa situazione accade quando l’installazione di Vinum ha distrutto il codice di avvio. Sfortunatamente Vinum lascia solo 4 KB liberi all’inizio della sua partizione prima di scrivere il proprio header. Purtroppo le due fasi dell’avvio e la disklabel compresa tra le due attualmente occupa 8 KB, quindi se la partizione Vinum è creata con spiazzamento 0 in una slice o disco che dovrebbe essere avviabile, la configurazione di Vinum distruggerà il codice di avvio.
Similmente, se la situazione sopra descritta è stata risolta avviando da un disco di "Fixit", e il codice di avvio re-installato usando disklabel -B come descritto in Stadio Uno, il codice di avvio distruggerà l’header di Vinum, che non saprà più trovare i propri dischi. Benché nessun dato, di configurazione o contenuto, sia distrutto da questo processo, che risulta quindi recuperabile reinserendo la stessa configurazione di Vinum, la situazione è in realtà di difficile risoluzione: sarebbe necessario spostare l’intera partizione Vinum di almeno 4 KB, in modo da lasciare abbastanza spazio sia per il codice di avvio che per l’header Vinum.
In FreeBSD 4.X alcune funzioni interne necessarie a Vinum per poter trovare automaticamente tutti i dischi non sono presenti e il codice che ricava l’ID interno della periferica di root non è abbastanza intelligente da gestire automaticamente nomi come /dev/vinum/root, quindi le cose vengono fatte in modo un po' diverso.
Bisogna dire esplicitamente a Vinum quali dischi controllare, usando una riga di /boot/loader.conf come la seguente:
vinum.drives="/dev/da0 /dev/da1"
È importante indicare tutti i drive che possono contenere dati Vinum. Non è un problema indicare drive di troppo, non è neanche necessario aggiungere esplicitamente ogni slice e/o partizione, dato che Vinum cercherà header Vinum in tutte le slice e partizioni dei drive nominati.
Dato che le procedure utilizzate per interpretare il nome del filesystem di root e derivarne l’ID di periferica (numeri maggiore e minore) sono adatte per gestire solo nomi "classici" di periferica come /dev/ad0s1a, non riescono a capire nomi di volumi root come /dev/vinum/root. Per questo motivo Vinum ha bisogno di pre-impostare durante la propria inzializzazione il parametro kernel interno che contiene l’ID della periferica di root. Questo viene fatto indicando il nome del volume di root nella variabile di avvio vinum.root. La riga di /boot/loader.conf adatta per fare questo è simile alla seguente:
vinum.root="root"
Quando l’inizializzazione del kernel cerca di trovare la periferica root da montare controlla se qualche modulo del kernel ha già pre-inizializzato il parametro kernel apposito; se questo è il caso e la periferica che dice di essere la periferica di root ha il numero maggiore e minore corrispondenti al driver come trovato dal nome della periferica di root passata (ovvero "vinum", nel nostro caso), userà l’ID di periferica pre-allocato, anziché cercar di trovarne uno da solo. In tal modo durante l’usuale avvio automatico può continuare a montare il volume di root Vinum per il filesystem di root.
Bisogna comunque notare che anche quando boot -a richiede di inserire manualmente il nome della periferica di root tale nome non può essere intepretato nel caso sia un nome riferito a un volume Vinum. Se è inserito un nome di periferica non riferito a una periferica Vinum, la non corrispondenza col numero maggiore pre-allocato del parametro di root e del driver ricavato dal nome farà sì che la procedura utilizzi il normale interprete, quindi una stringa come ufs:da0d funzionerà come previsto. Da notare che se questo fallisce non si può più provare una stringa come ufs:vinum/root, dato che non verrebbe interpretata; l’unica via di uscita è riavviare e ripartire da zero. (Alla richiesta di "askroot", la parte iniziale /dev/ può sempre essere omessa.)
FreeBSD è un progetto di larga diffusione con utenti e collaboratori in ogni parte del mondo. Questo capitolo affronta quegli aspetti tipici di FreeBSD relativi all’internazionalizzazione e localizzazione del sistema che permettono agli utenti non di lingua inglese di operare in maniera più confortevole. Ci sono molti aspetti da considerare dell’implementazione I18N sia a livello utente che di sistema, perciò, ove necessario, si rinvierà il lettore a fonti di informazione più specifiche.
Dopo aver letto questo capitolo, saprai:
Come i vari linguaggi e nazioni sono codificati nei moderni sistemi operativi.
Come impostare la localizzazione per la tua shell di login.
Come configurare la tua console per una lingua che non sia l’inglese.
Come usare concretamente X Window System con differenti lingue.
Dove reperire ulteriori informazioni su come scrivere applicazioni I18N compatibili.
Prima di leggere questo capitolo, dovresti:
Sapere come installare applicazioni aggiuntive di terze parti (Installazione delle Applicazioni. Port e Package).
Gli sviluppatori hanno abbreviato la parola "internationalization" in I18N, contando il numero di lettere che costituiscono la parola "internationalization", escludendo la prima e l’ultima. Lo stesso è stato fatto per l’acronimo L10N, che deriva appunto da "localization". Combinando insieme i metodi, i protocolli e le applicazioni che rispettano gli standard I18N/L10N si permette agli utenti di utilizzare una qualsiasi lingua di propria scelta.
Le applicazioni I18N sono realizzate mediante appositi kit, disponibili tramite specifiche librerie. Questo permette agli sviluppatori di scrivere in un normale file di testo i menù e i messaggi da visualizzare nel programma e di tradurlo poi nelle varie lingue. Si raccomandano vivamente i programmatori di seguire questa convenzione.
Vista la sua importanza, I18N non è specifico del sistema FreeBSD ed è una convenzione. Siete invitati ad aiutare il progetto FreeBSD per sostenere questa convenzione.
Le impostazioni per la localizzazione o nazionalizzazione sono basate su tre termini principali: Codice Lingua, Codice Nazione e Codifica. I nomi che contraddistinguono una localizzazione sono formati utilizzando questi termini nel modo seguente:
CodiceLingua_CodiceNazione.Codifica
Al fine di localizzare un sistema FreeBSD (o qualsiasi altro sistema UNIX® che gestisca I18N) in una specifica lingua, l’utente deve innanzitutto conoscere i codici della nazione e della lingua desiderati (i codici delle nazioni segnalano alle applicazioni quali convenzioni adottare all’interno di un dato linguaggio). Inoltre, i browser web, i server SMTP/POP, i server web, ecc. possono operare in base ad essi. I seguenti sono esempi di codici lingua/nazione:
| Codice Lingua/Nazione | Descrizione |
|---|---|
en_US | inglese - Stati Uniti d’America |
ru_RU | russo - Russia |
zh_TW | cinese tradizionale - Taiwan |
Alcune lingue utilizzano codifiche non ASCII, cioè caratteri a 8 bit, estesi o multibyte, vedere multibyte(3) per maggiori dettagli. Le applicazioni più vecchie, non riconoscendoli, li interpretano come caratteri di controllo. Quelle più recenti invece riconoscono di solito i caratteri a 8 bit. A seconda dell’implementazione, è possibile che gli utenti debbano ricompilare un’applicazione con il supporto ai caratteri estesi o multibyte, o debbano configurare l’applicazione in modo corretto. Per essere in grado di immettere e di elaborare caratteri estesi o multibyte, la FreeBSD Ports Collection fornisce vari programmi in differenti linguaggi. Si faccia riferimento alla relativa documentazione I18N del port di FreeBSD.
Precisamente, l’utente deve consultare la documentazione propria dell’applicazione per conoscere come configurarla correttamente o come passare i giusti valori al configuratore/Makefile/compilatore.
Alcune cose da tener presente sono:
Gli insiemi di caratteri rappresentabili dal tipo char del linguaggio C, specifici della lingua (vedere multibyte(3)), cioè ISO8859-1, ISO8859-15, KOI8-R, CP437.
Codifiche estese o multibyte, cioè EUC, Big5.
Puoi consultare l’elenco corrente degli insiemi di caratteri nel Registro IANA.
FreeBSD usa le codifiche per la localizzazione compatibili con X11. |
Nel sistema dei port e dei pacchetti precompilati di FreeBSD, le applicazioni I18N sono facilmente riconoscibili, perché il loro nome include la sigla I18N. Tuttavia, non sempre queste potrebbero supportare la lingua desiderata.
Di solito è sufficiente esportare il valore del nome del locale posto nella variabile LANG all’interno della shell di login. Questo può essere fatto utilizzando il file dell’utente ~/.login_conf oppure il file di configurazione della shell di login dell’utente (~/.profile, ~/.bashrc, ~/.cshrc). Non c’è bisogno di impostare le altre variabili del locale, come LC_CTYPE, LC_CTIME. Per maggiori informazioni si faccia riferimento alla documentazione di FreeBSD specifica per la data lingua.
Puoi settare le due variabili d’ambiente seguenti nei tuoi file di configurazione:
LANG per le funzioni appartenenti alla famiglia POSIX®, setlocale(3)
MM_CHARSET per l’insieme dei caratteri che dovranno usare le applicazioni che supportano lo standard MIME
Ciò va fatto per la configurazione della shell dell’utente, di un’applicazione specifica e per quella di X11.
Ci sono due metodi per impostare il locale, entrambi descritti qui di seguito. Il primo (raccomandato) consiste nell’impostare le variabili d’ambiente in una classe di login, mentre il secondo consiste nell’aggiungere i valori delle variabili d’ambiente al file d’avvio della shell di sistema.
Questo metodo fa sì che le variabili d’ambiente necessarie per il nome del locale e per gli insiemi dei caratteri MIME vengano inizializzate una volta sola per ogni possibile shell di sistema invece di aggiungere specifici assegnamenti per ogni file d’avvio di shell. Il Setup a Livello Utente può essere fatto dall’utente stesso e il Setup a Livello Amministratore richiede i privilegi del superuser.
Ecco un breve esempio di un file .login_conf posto nella directory home di un utente che ha entrambe le variabili impostate alla codifica Latin-1:
me:\ :charset=ISO-8859-1:\ :lang=de_DE.ISO8859-1:
Ecco invece un esempio di un file .login_conf che imposta le variabili per il cinese tradizionale con codifica BIG-5. Si noti che sono state impostate molte variabili perchè alcuni programmi non rispettano come dovrebbero le variabili di localizzazione per il cinese, giapponese e il coreano.
#Gli utenti che non vogliono usare l'unità monetaria o i formati temporali
#di Taiwan possono modificare manualmente ogni variabile
me:\
:lang=zh_TW.Big5:\
:setenv=LC_ALL=zh_TW.Big:\
:setenv=LC_COLLATE=zh_TW.Big5:\
:setenv=LC_CTYPE=zh_TW.Big5:\
:setenv=LC_MESSAGES=zh_TW.Big5:\
:setenv=LC_MONETARY=zh_TW.Big5:\
:setenv=LC_NUMERIC=zh_TW.Big5:\
:setenv=LC_TIME=zh_TW.Big5:\
:charset=big5:\
:xmodifiers="@im=gcin": #Set gcin as the XIM Input ServerVedere il paragrafo Setup a Livello Amministratore e login.conf(5) per maggiori dettagli.
Controlla che la classe di login dell’utente in /etc/login.conf selezioni la lingua corretta. Assicurati che queste impostazioni appaiano in /etc/login.conf:
nome_lingua:titolo_account:\ :charset=MIME_charset:\ :lang=nome_locale:\ :tc=default:
Ritornando quindi all’esempio di prima che utilizzava Latin-1, si dovrebbe avere una cosa simile a questa:
tedesco:Account Utenti Tedeschi:\ :charset=ISO-8859-1:\ :lang=de_DE.ISO8859-1:\ :tc=default:
Dopo aver modificato le Classi di Login degli utenti esegui il comando seguente:
# cap_mkdb /etc/login.confper creare una nuova configurazione in /etc/login.conf visibile al sistema.
Usa vipw per aggiungere nuovi utenti, e crea qualcosa di simile a quanto segue:
utente:password:1111:11:lingua:0:0:Nome Utente:/home/user:/bin/sh
Usa adduser per aggiungere nuovi utenti, in questo modo:
Imposta defaultclass = lingua in /etc/adduser.conf. Tieni presente che in questo modo dovrai inserire una classe default per tutti gli utenti di altre lingue.
In alternativa si può specificare la lingua desiderata ogni volta che appare il prompt
Enter login class: default []:durante l’esecuzione di adduser(8)
Un’altra alternativa è utilizzare il comando nel modo seguente per ogni utente di una diversa lingua che si desidera aggiungere:
# adduser -class linguaSe utilizzi il comando pw(8) per aggiungere nuovi utenti, invocalo in questo modo:
# pw useradd nome_utente -L linguaQuesto metodo è sconsigliato perché richiede una inizializzazione diversa per ogni possibile shell. Usa invece il Metodo delle Classi di Login. |
Per aggiungere il nome del locale e l’insieme dei caratteri per lo standard MIME, bisogna semplicemente settare le due variabili d’ambiente mostrate di seguito nei file d’avvio della shell /etc/profile e/o /etc/csh.login. Nell’esempio che segue viene utilizzata la lingua tedesca:
In /etc/profile:
LANG=de_DE.ISO8859-1; export LANG MM_CHARSET=ISO8859-1; export MM_CHARSET
Oppure in /etc/csh.login:
setenv LANG de_DE.ISO8859-1 setenv MM_CHARSET ISO8859-1
Lo stesso risultato si ottiene aggiungendo i precedenti comandi al file /usr/shared/skel/dot.profile (per i comandi usati in /etc/profile), oppure al file /usr/shared/skel/dot.login (per quelli in /etc/csh.login).
Per l’ambiente X11:
Nel file $HOME/.xinitrc:
LANG=de_DE.ISO8859-1; export LANG
Oppure:
setenv LANG de_DE.ISO8859-1
a seconda della shell utilizzata (vedi sopra).
Per tutti gli insiemi di caratteri che sono rappresentabili con il tipo char in C, imposta i font della console adatti alla lingua prescelta in /etc/rc.conf:
font8x16=nome_font font8x14=nome_font font8x8=nome_font
nome_font è il nome di uno dei file di font presenti nella directory /usr/shared/syscons/fonts, privato del suffisso .fnt.
Assicurati anche di impostare la giusta mappatura della tastiera e del video per il proprio set di caratteri usando sysinstall (/stand/sysinstall nelle versioni di FreeBSD precedenti alla 5.2). Una volta all’interno di sysinstall, seleziona , quindi . In alternativa, aggiungi le seguenti righe in /etc/rc.conf:
scrnmap=nome_screenmap keymap=nome_keymap keychange="numero_tasto_funzione sequenza"
nome_screenmap viene preso dalla directory /usr/shared/syscons/scrnmaps, privato del suffisso .scm. Una screenmap assieme ad una corrispondente mappa dei font è solitamente necessaria nel caso la scheda grafica non gestisca i font via software, ma li abbia codificati internamente; la screenmap serve appunto a rimappare tali font interni nel font prescelto.
Se hai abilitato il demone moused inserendo la seguente riga in /etc/rc.conf:
moused_enable="YES"
allora leggi quanto riportato nel prossimo paragrafo sul cursore del mouse.
Di default il cursore del mouse del driver syscons(4) occupa l’intervallo da 0xd0 a 0xd3 nel set di caratteri in uso. Se la tua lingua utilizza tali caratteri, devi spostare l’intervallo occupato dal cursore. Per far questo con FreeBSD, inserisci la seguente riga in /etc/rc.conf:
mousechar_start=3
nome_keymap deve invece corrispondere a uno dei file presenti nella directory /usr/shared/syscons/keymaps, privato del suffisso .kbd. Se sei indeciso su quale keymap scegliere, puoi usare il comando kbdmap(1) per testare le varie mappature senza dover riavviare il sistema.
La variabile keychange è di solito richiesta per programmare i tasti funzione in relazione al tipo di terminale in uso, poiché le sequenze generate da un tasto funzione non possono essere definite in una mappa di tasti.
Assicurati inoltre di impostare il corretto tipo di terminale in /etc/ttys per tutte le voci del tipo ttyv*. Attualmente, le corrispondenze predefinite sono:
| Insieme di Caratteri | Tipo di Terminale |
|---|---|
ISO8859-1 o ISO8859-15 |
|
ISO8859-2 |
|
ISO8859-7 |
|
KOI8-R |
|
KOI8-U |
|
CP437 (di default per VGA) |
|
US-ASCII |
|
Per i linguaggi che usano caratteri estesi o multibyte, è bene servirsi del corretto port di FreeBSD nella directory /usr/ports/linguaggio. Poichè alcuni port che si presentano come console sono riconosciuti dal sistema come terminali seriali virtuali (vtty), devi riservare abbastanza vtty sia per X11 che per la console pseudo-seriale. Ecco una lista parziale di applicazioni con cui si possono utilizzare altri linguaggi in console:
| Linguaggio | Ubicazione |
|---|---|
cinese tradizionale (BIG-5) | |
giapponese | |
coreano |
Sebbene X11 non faccia parte del progetto FreeBSD, vengono qui fornite alcune informazioni per gli utenti di FreeBSD. Per maggiori dettagli, si faccia riferimento al sito web Xorg o a quello del Server X11 utilizzato.
Nel file ~/.Xresources, puoi mettere a punto le impostazioni per I18N specifiche di un’applicazione (ad esempio, i font, i menu, ecc.).
Installa il server Xorg (x11-servers/xorg-server) o XFree86™ (x11-servers/XFree86-4-Server), quindi installa i font TrueType® propri della lingua prescelta. L’impostazione del corretto locale dovrebbe permetterti di visualizzare tale lingua nei vari menu, ecc.
Alcuni set di caratteri del tipo char del C sono solitamente codificati a livello hardware all’interno delle stampanti stesse. Gli insiemi di caratteri estesi o multibyte richiedono invece una speciale configurazione e si raccomanda l’utilizzo di apsfilter. Puoi anche convertire documenti nei formati PostScript® o PDF utilizzando convertitori specifici per una data lingua.
Il file system di FreeBSD FFS (Fast File System) è completamente a 8-bit, perciò può essere utilizzato con qualsiasi insieme di caratteri del tipo char del C (vedere multibyte(3)), ma non vi è un nome particolare di un insieme di caratteri memorizzato nel file system; cioè, il file system è a 8 bit senza alcuna codifica interna e ignora un’eventuale codifica. Ufficialmente, FFS non supporta ancora alcuna forma degli insiemi di caratteri estesi o multibyte. Tuttavia, esistono per alcuni di questi delle patch indipendenti per il FFS che abilitano tale supporto. Sono solo soluzioni temporanee, non portabili ed si è deciso di non includerle nell’albero dei sorgenti. Si faccia riferimento ai rispettivi siti web della lingua desiderata per ulteriori informazioni e per i file di patch.
Il supporto per il file system di MS-DOS® in FreeBSD offre la possibilità di configurare la modalità di conversione tra gli insiemi di caratteri MS-DOS®, Unicode e quelli scelti per il file system di FreeBSD. Consultare mount_msdosfs(8) per i dettagli.
Molti dei port di FreeBSD includono il supporto I18N. Alcuni di essi sono contrassegnati dal suffisso -I18N nel loro nome. Questi e molti altri programmi hanno il supporto per I18N già incluso e non necessitano perciò di speciali considerazioni.
Tuttavia, alcune applicazioni come ad esempio MySQL richiedono che venga specificato nel Makefile l’insieme dei caratteri che si utilizzeranno. Questa operazione viene fatta o modificando direttamente il suddetto file oppure passando un opportuno valore al programma configure nella directory dei sorgenti.
Per maggiori informazioni sulla codifica KOI8-R, si veda la fonte di riferimento per il KOI8-R (Russian Net Character Set).
Metti le seguenti righe nel tuo file ~/.login_conf:
me:My Account:\ :charset=KOI8-R:\ :lang=ru_RU.KOI8-R:
Si veda quanto esposto precedentemente in questo capitolo per degli esempi di impostazione del locale.
Aggiungi la riga seguente al tuo file /etc/rc.conf:
mousechar_start=3
Utilizza inoltre le seguenti impostazioni nel file /etc/rc.conf:
keymap="ru.utf-8" scrnmap="utf-82cp866" font8x16="cp866b-8x16" font8x14="cp866-8x14" font8x8="cp866-8x8"
Per ogni voce ttyv* nel file /etc/ttys, usa cons25r come tipo di terminale.
Si veda quanto esposto in precedenza in questo capitolo per degli esempi su come impostare la console.
Dal momento che la maggior parte delle stampanti con caratteri russi hanno a livello hardware la codifica codepage CP866, è necessario utilizzare uno speciale filtro di conversione da KOI8-R a CP866. Tale filtro viene installato di default come /usr/libexec/lpr/ru/koi2alt. La voce per una stampante russa dovrebbe apparire perciò così in /etc/printcap:
lp|Russian local line printer:\ :sh:of=/usr/libexec/lpr/ru/koi2alt:\ :lp=/dev/lpt0:sd=/var/spool/output/lpd:lf=/var/log/lpd-errs:
Si veda printcap(5) per una spiegazione dettagliata del significato dei vari campi.
La seguente voce d’esempio di fstab(5) abilita il supporto per i nomi di file in russo su file system MS-DOS®:
/dev/ad0s2 /dos/c msdos rw,-W=koi2dos,-L=ru_RU.KOI8-R 0 0
L’opzione -L seleziona il nome locale usato, e -W imposta la tabella di conversione dei caratteri. Per usare l’opzione -W, assicurati di montare /usr prima della partizione MS-DOS® perché le tabelle di conversione sono posizionate in /usr/libdata/msdosfs. Per maggiori informazioni, guarda la pagina man di mount_msdosfs(8).
Segui innanzitutto la configurazione del locale in console come descritto in precedenza.
Se usi Xorg, installa il package x11-fonts/xorg-fonts-cyrillic.
Controlla la sezione "Files" nel tuo file /etc/X11/xorg.conf. Le seguenti righe devono essere aggiunte prima di qualsiasi altra voce FontPath:
FontPath "/usr/X11R6/lib/X11/fonts/cyrillic/misc" FontPath "/usr/X11R6/lib/X11/fonts/cyrillic/75dpi" FontPath "/usr/X11R6/lib/X11/fonts/cyrillic/100dpi"
Se utilizzi una modalità video ad alta risoluzione, scambia le righe 75 dpi e 100 dpi.
Cerca nei port per altri font cirillici. |
Per attivare la tastiera russa, aggiungi alla sezione "Keyboard" del tuo file xorg.conf queste cose:
Option "XkbLayout" "us,ru" Option "XkbOptions" "grp:toggle"
Verifica inoltre che la riga XkbDisable sia commentata.
Per grp:caps_toggle il cambio RUS/LAT si usa Right Alt, per grp:ctrl_shift_toggle si usa Ctrl+Shift. La vecchia funzione di CapsLock à ancora disponibile via Shift+CapsLock (solamente in modalità LAT). Per grp:toggle il cambio RUS/LAT si usa Right Alt. grp:caps_toggle non funziona in Xorg per ragioni sconosciute.
Se hai i tasti "Windows®" sulla tua tastiera, e noti che alcuni tasti non alfabetici sono mappati non correttamente in modalità RUS, aggiungi in xorg.conf la seguente riga:
Option "XkbVariant" ",winkeys"
La tastiera russa XKB potrebbe non lavorare con applicazioni non localizzate. |
Di base le applicazioni localizzate dovrebbe chiamare la funzione Guarda KOI8-R per X Window per maggiori istruzioni sulle applicazioni di X11 localizzate. |
Il FreeBSD-Taiwan Project fornisce un Chinese HOWTO per FreeBSD all’indirizzo http://freebsd.sinica.edu.tw/~statue/freebsd/zh-tut/ per l’utilizzo di gran parte delle applicazioni in cinese. L’attuale autore del FreeBSD Chinese HOWTO è Shen Chuan-Hsing statue@freebsd.sinica.edu.tw.
Chuan-Hsing Shen statue@freebsd.sinica.edu.tw ha creato la Chinese FreeBSD Collection (CFC) utilizzando zh-l10n-tut del FreeBSD-Taiwan Project. I pacchetti e i file di script sono disponibili all’url ftp://freebsd.csie.nctu.edu.tw/pub/taiwan/CFC/.
Slaven Rezic eserte@cs.tu-berlin.de ha scritto un tutorial su come utilizzare le lettere con l'umlaut su una macchina FreeBSD. Il tutorial è scritto in tedesco e disponibile all’indirizzo http://user.cs.tu-berlin.de/~eserte/FreeBSD/doc/umlaute/umlaute.html.
Per il giapponese, vedere l’url http://www.jp.FreeBSD.org/, per il coreano, l’url http://www.kr.FreeBSD.org/.
Alcuni volontari hanno tradotto parte della documentazione di FreeBSD in altre lingue. Questo materiale è raggiungibile seguendo i link segnalati sul sito ufficiale di FreeBSD oppure sotto la directory /usr/shared/doc.
FreeBSD è uno dei maggiori sistemi operativi schierati verso alte performance dei servizi di rete. I capitoli di questa parte trattano:
Comunicazioni Seriali
PPP e PPP over Ethernet
Posta Elettronica
Esecuzione di Servizi di Rete
Firewall
Altri Argomenti di Networking Avanzato
Questi capitoli sono studiati per essere letti quando si ha bisogno di un’informazione. Non devi leggerli in un ordine particolare, né devi leggerli tutti prima di poter usare FreeBSD in rete.
UNIX® ha sempre avuto un supporto per le comunicazioni seriali. In effetti, le prime vere macchine UNIX® si appoggiavano a linee seriali per l’input e l’output da e verso l’utente. Le cose sono cambiate molto dai giorni in cui un "terminale" consisteva in una stampante da 10 caratteri al secondo o in una tastiera. Questo capitolo coprirà alcuni dei modi nei quali FreeBSD usa le comunicazioni seriali.
Dopo aver letto questo capitolo, saprai:
Come connettere terminali al tuo sistema FreeBSD.
Come usare un modem per collegarti telefonicamente ad una macchina remota.
Come permettere a utenti remoti di effettuare login sul tuo sistema via modem.
Come avviare il tuo sistema da una console seriale.
Prima di leggere questo capitolo, dovresti:
Sapere come configurare ed installare un nuovo kernel (Configurazione del Kernel di FreeBSD).
Comprendere i permessi ed i processi UNIX® (Basi di UNIX).
Avere accesso al manuale tecnico per l’hardware seriale (modem o scheda multiporta) che vuoi usare con FreeBSD.
Bits per Second (Bit per Secondo) - la frequenza alla quale vengono trasmessi i dati
Data Terminal Equipment (Attrezzatura per il Terminale Dati) - ad esempio, il tuo computer
Data Communications Equipment (Attrezzatura per le Comunicazioni Dati) - il tuo modem
Standard EIA per le comunicazioni tra hardware seriale
Nel parlare della velocità di comunicazione, questa sezione non usa il termine "baud". Il baud si riferisce al numero di transizioni degli stati elettrici che possono essere effettuati in un periodo di tempo, mentre i "bps" (bit per secondo) sono il termine corretto da usare (o almeno non sembra irritare troppo i perfezionisti).
Per collegare un modem o un terminale alla tua macchina FreeBSD, avrai bisogno di una porta seriale sul tuo computer e del cavo appropriato per il tuo dispositivo seriale. Se sei già pratico con l’hardware ed i cavi necessari, puoi saltare tranquillamente questa sezione.
Ci sono parecchi tipi diversi di cavi seriali. I due tipi più comuni per i nostri scopi sono i cavi null-modem ed i cavi standard ("dritti") RS-232. La documentazione per il tuo hardware dovrebbe descrivere il tipo di cavi necessari.
Un cavo null-modem porta segnali dritti, come il "Segnale di Massa", e segnali incrociati. Per esempio, il pin di "Trasmissione Dati" su un capo è il pin di "Ricezione Dati" sull’altro capo.
Puoi costruirti un cavo null-modem da usare con i terminali (es., se vuoi una migliore qualità). Questa tabella mostra i segnali dell’RS-232C e i numeri dei pin su un connettore DB-25. Nota che lo standard richiede il segnale dritto sul pin 1 chiamato Massa di Protezione, anche se questo è spesso omesso. Alcuni terminali funzionano usando solo i pin 2, 3 e 7, mentre altri richiedono configurazioni diverse come mostrate negli esempi qui sotto.
| Segnale | Pin # | Pin # | Segnale | |
|---|---|---|---|---|
SG | 7 | si connette a | 7 | SG |
TD | 2 | si connette a | 3 | RD |
RD | 3 | si connette a | 2 | TD |
RTS | 4 | si connette a | 5 | CTS |
CTS | 5 | si connette a | 4 | RTS |
DTR | 20 | si connette a | 6 | DSR |
DTR | 20 | si connesso a | 8 | DCD |
DSR | 6 | si connette a | 20 | DTR |
DCD | 8 | si connette a | 20 | DTR |
Ecco altri due comuni schemi.
| Segnale | Pin # | Pin # | Segnale | |
|---|---|---|---|---|
RD | 2 | si connette a | 3 | TD |
TD | 3 | si connette a | 2 | RD |
DTR | 4 | si connette a | 6 | DSR |
DTR | 4 | si connette a | 1 | DCD |
SG | 5 | si connette a | 5 | SG |
DSR | 6 | si connette a | 4 | DTR |
DCD | 1 | si connette a | 4 | DTR |
RTS | 7 | si connette a | 8 | CTS |
CTS | 8 | si connette a | 7 | RTS |
| Segnale | Pin # | Pin # | Segnale | |
|---|---|---|---|---|
RD | 2 | si connette a | 2 | TD |
TD | 3 | si connette a | 3 | RD |
DTR | 4 | si connette a | 6 | DSR |
DTR | 4 | si connette a | 8 | DCD |
SG | 5 | si connette a | 7 | SG |
DSR | 6 | si connette a | 20 | DTR |
DCD | 1 | si connette a | 20 | DTR |
RTS | 7 | si connette a | 5 | CTS |
CTS | 8 | si connette a | 4 | RTS |
Quando un pin di un capo si connette a una coppia di pin dell’altro capo, questo è solitamente fatto ponendo un cavetto tra la coppia di pin nel loro connettore e collegando questi con un altro cavo al singolo pin dell’altro capo. |
Queste sembrano essere le implementazioni più popolari. In altre varianti (spiegate nel libro RS-232 Made Easy) SG è connesso a SG, TD a RD, RTS e CTS a DCD, DTR a DSR, e vice-versa.
Un cavo seriale standard ha tutti i segnali RS-232C diritti. Cioè, il pin di "Trasmissione Dati" su un capo del cavo va nel pin di "Trasmissione Dati" sull’altro capo. Questo è il tipo di cavo da usare per collegare un modem al tuo sistema FreeBSD, ed è anche appropriato per alcuni terminali.
Le porte seriali sono i dispositivi attraverso i quali vengono trasferiti i dati tra il computer FreeBSD ed il terminale. Questa sezione descrive il tipo di porte che esistono e come vengono indicate in FreeBSD.
Esistono parecchi tipi di porte seriali. Prima di comprare o costruire un cavo, avrai bisogno di assicurarti che sia adatto alle porte sul terminale e sul sistema FreeBSD.
La maggior parte dei terminali avrà porte DB-25. I personal computer, compresi i PC con FreeBSD, avranno porte DB-25 o DB-9. Se hai una scheda seriale multiporta nel tuo PC, potresti avere porte RJ-12 o RJ-45.
Guarda la documentazione fornita con l’hardware per le specifiche del tipo di porta usata. Spesso basta anche un’ispezione visiva della porta.
In FreeBSD, si accede ad ogni porta seriale attraverso una voce nella directory /dev. Ci sono due differenti tipi di voci:
Le porte di ingresso vengono dette /dev/ttydN dove N è il numero di porta, cominciando da zero. Generalmente, puoi usare la porta di ingresso per i terminali. Le porte di ingresso richiedono che la linea fornisca un segnale detto data carrier detect (DCD) per funzionare correttamente.
Le porte di uscita vengono dette /dev/cuadN. In genere non si usano porte di uscita per i terminali, ma solo per i modem. Puoi usare la porta di uscita se il cavo seriale o il terminale non supportano il segnale di carrier detect.
Le porte di uscita sono chiamate /dev/cuaaN in FreeBSD 5.X e precedenti. |
Se hai connesso un terminale sulla prima porta seriale (COM1 in MS-DOS®), allora userai /dev/ttyd0 per riferirti al terminale. Se il terminale è sulla seconda porta seriale (anche nota come COM2), usa /dev/ttyd1, e così via.
FreeBSD supporta quattro porte seriali di default. Nel mondo MS-DOS®, queste sono note come COM1, COM2, COM3, e COM4. FreeBSD attualmente supporta schede d’interfaccia seriale multiporta "stupide", come le BocaBoard 1008 e 2016, così come le schede multiporta intelligenti come quelle fatte dalla Digiboard e dalla Stallion Technologies. Ad ogni modo, il kernel di default usa solo le porte COM standard.
Per vedere se il tuo kernel riconosce una delle tue porte seriali, guarda i messaggi mentre il kernel viene avviato, o usa il comando /sbin/dmesg per far scorrere di nuovo i messaggi di avvio del kernel. In particolare, cerca dei messaggi che inizino con i caratteri sio.
Per vedere solo i messaggi che hanno la parola |
Ad esempio, su un sistema con quattro porte seriali, questi sono i messaggi dati dall’avvio del kernel specifici delle porte seriali:
sio0 at 0x3f8-0x3ff irq 4 on isa
sio0: type 16550A
sio1 at 0x2f8-0x2ff irq 3 on isa
sio1: type 16550A
sio2 at 0x3e8-0x3ef irq 5 on isa
sio2: type 16550A
sio3 at 0x2e8-0x2ef irq 9 on isa
sio3: type 16550ASe il tuo kernel non riconosce tutte le tue porte seriali, probabilmente devi configurare il kernel sistemando il file /boot/device.hints. Inoltre puoi commentare o rimuovere completamente le righe dei dispositivi che non hai.
Su FreeBSD 4.X devi editare il tuo file di configurazione del kernel. Per informazioni dettagliate sulla configurazione del kernel, guarda Configurazione del Kernel di FreeBSD. Le righe dei dispositivi interessati dovrebbero essere simili a queste:
device sio0 at isa? port IO_COM1 irq 4 device sio1 at isa? port IO_COM2 irq 3 device sio2 at isa? port IO_COM3 irq 5 device sio3 at isa? port IO_COM4 irq 9
Guarda la pagina man di sio(4) per informazioni aggiuntive sulla configurazione delle porte seriali e delle schede multiporta. Stai attento se stai usando un file di configurazione già usato per una versione differente di FreeBSD, poiché i flag dei dispositivi e la sintassi sono cambiati tra una versione e l’altra.
|
Alla maggior parte dei dispositivi nel kernel si accede attraverso "file speciali di dispositivo", che si trovano nella directory /dev. Ai dispositivi sio si accede attraverso i /dev/ttydN (ingresso) e /dev/cuadN (uscita). FreeBSD fornisce anche dei dispositivi di inizializzazione (/dev/ttydN.init e /dev/cuadN.init su FreeBSD 6.X, /dev/ttyidN e /dev/cuaidN su FreeBSD 5.X e precedenti) e dispositivi di blocco (/dev/ttydN.lock e /dev/cuadN.lock su FreeBSD 6.X, /dev/ttyldN e /dev/cualdN su FreeBSD 5.X e precedenti). I dispositivi di inizializzazione vengono usati per inizializzare i parametri delle porte di comunicazione ogni volta che una porta viene aperta, come crtscts per i modem che usano le segnalazioni RTS/CTS per il controllo di flusso. I dispositivi di blocco vengono usati per fissare i flag sulle porte ed evitare che altri utenti o programmi cambino certi parametri; guarda le pagine man di termios(4), sio(4), e stty(1) per maggiori informazioni sulle impostazioni dei terminali, sui dispositivi di blocco ed inizializzazione, e sull’impostazione delle opzioni del terminale, rispettivamente.
FreeBSD 5.0 include il file system devfs(5) che crea automaticamente nodi per i dispositivi necessari. Se stai usando una versione di FreeBSD con il |
Uno script di shell di nome MAKEDEV nella directory /dev gestisce i file di dispositivo. Per usare MAKEDEV nella creazione del file di dispositivo per COM1 (porta 0), fai cd su /dev e dai il comando MAKEDEV ttyd0. Allo stesso modo, per creare il file di dispositivo per COM2 (porta 1), usa MAKEDEV ttyd1.
MAKEDEV non crea solo i file speciali /dev/ttydN, ma anche i nodi /dev/cuaaN, /dev/cuaiaN, /dev/cualaN, /dev/ttyldN, e /dev/ttyidN.
Dopo aver creato i nuovi file di dispositivo, fa attenzione nel controllare i permessi sui file (specialmente sui file /dev/cua*) per assicurarti che solo gli utenti che dovrebbero effettivamente avere accesso a questi dispositivi possano leggerli e scriverli - magari non vorrai permettere al tuo utente medio di usare il tuo modem per chiamare verso l’esterno. I permessi predefiniti su /dev/cua* dovrebbero essere adatti:
crw-rw---- 1 uucp dialer 28, 129 Feb 15 14:38 /dev/cuaa1
crw-rw---- 1 uucp dialer 28, 161 Feb 15 14:38 /dev/cuaia1
crw-rw---- 1 uucp dialer 28, 193 Feb 15 14:38 /dev/cuala1Questi permessi permettono all’utente uucp e agli utenti nel gruppo dialer di usare i dispositivi di uscita.
Il dispositivo ttydN (o cuadN) è il normale dispositivo che si apre per le proprie applicazioni. Quando un processo apre il dispositivo, avrà un insieme di impostazioni di I/O predefinite per il terminale. Puoi visualizzare queste impostazioni con il comando:
# stty -a -f /dev/ttyd1Quando cambi le impostazioni per questo dispositivo, queste rimangono efficaci finché il dispositivo non viene chiuso. Quando viene riaperto, ritorna all’insieme di default. Per effettuare dei cambiamenti all’insieme predefinito, modifica le impostazioni per il dispositivo di "stato iniziale". Ad esempio, per attivare di default modalità CLOCAL, comunicazione a 8 bit, e controllo di flusso XON/XOFF per ttyd5, scrivi:
# stty -f /dev/ttyd5.init clocal cs8 ixon ixoffLe inizializzazioni di sistema per i dispositivi seriali sono controllate in /etc/rc.d/serial. Questo file influisce sui valori predefiniti dei dispositivi seriali.
Su FreeBSD 4.X, l’inizializzazione globale dei dispositivi seriali è controllata in /etc/rc.serial. |
Per evitare cambiamenti da parte di qualche applicazione, modifica il dispositivo di "blocco dello stato". Ad esempio, per bloccare la velocità di ttyd5 a 57600 bps, scrivi:
# stty -f /dev/ttyd5.lock 57600Ora, un applicazione che apra ttyd5 e cerchi di cambiare la velocità della porta resterà bloccata a 57600 bps.
Naturalmente, dovresti rendere i dispositivi di stato iniziale e stato di blocco scrivibili solo da root.
I terminali forniscono un sistema di accesso conveniente ed a basso costo al tuo sistema FreeBSD quando non sei davanti alla console del computer o connesso ad una rete. Questa sezione descrive l’uso dei terminali con FreeBSD.
I sistemi UNIX® originali non avevano console. Invece, la gente effettuava il login ed avviava programmi attraverso terminali connessi alle porte seriali del computer. Ciò era abbastanza simile all’uso di modem e programmi terminale per collegarsi telefonicamente ad un sistema remoto e lavorare da riga di comando.
I PC di oggi hanno console capaci di grafica di alta qualità, ma l’abilità di stabilire una sessione di login su una porta seriale esiste ancora in quasi ogni sistema operativo in stile UNIX® di oggi; FreeBSD non fa eccezione. Usando un terminale attaccato ad una porta seriale inutilizzata, puoi effettuare il login ed eseguire qualsiasi programma testuale che potresti lanciare normalmente dalla console o da una finestra xterm in X Window.
Un utente aziendale può connettere molti terminali ad un sistema FreeBSD e porli sulle scrivanie dei propri impiegati. Un utente casalingo può usare qualcosa come un vecchio PC IBM o un Macintosh® come terminale connesso a un computer più potente che faccia girare FreeBSD. Puoi anche trasformare quello che sarebbe un computer singolo utente in un potente sistema per utenti multipli.
Per FreeBSD, esistono tre tipi di terminali:
Le sottosezioni rimanenti descrivono ognuno di questi tipi.
Questi terminali sono oggetti hardware specializzati che permettono di connettere dei computer tramite linee seriali. Essi vengono detti "stupidi" poiché hanno solo la potenza di calcolo necessaria per mostrare, inviare, e ricevere testo. Non potete eseguire nessun programma su di essi. È il computer al quale vi collegate che ha la potenza per eseguire editor di testo, compilatori, email, giochi, e così via.
Ci sono centinaia di tipi di terminali di questo tipo, venduti da molti produttori, incluso il VT-100 della Digital Equipment Corporation e il WY-75 della Wyse. Quasi tutti funzioneranno con FreeBSD. Alcuni terminali di alto livello possono anche mostrare della grafica, ma solo alcuni pacchetti software possono avvalersi di queste caratteristiche.
I terminali stupidi sono popolari negli ambienti di lavoro nei quali i lavoratori non hanno bisogno di accedere ad applicazioni grafiche come quelle fornite dal sistema X Window.
Se un terminale stupido ha appena le capacità per mostrare, inviare, e ricevere testo, allora di certo un qualunque personal computer può funzionare come un terminale stupido. Tutto ciò di cui hai bisogno è il cavo appropriato ed un qualche programma per l'emulazione di terminale sul tuo computer.
Una simile configurazione è comune in molte case. Ad esempio, se il tuo coniuge sta lavorando alla console del sistema FreeBSD, tu puoi fare del lavoro testuale allo stesso momento da un PC meno potente connesso come terminale al sistema FreeBSD.
I terminali X sono i terminali più sofisticati tra quelli disponibili. Invece di collegarsi alla porta seriale, in genere ci si collega ad essi tramite un rete come Ethernet. Invece di essere relegati alle applicazioni testuali, essi possono mostrare applicazioni X.
Introduciamo i terminali X solo per una questione di completezza. Ad ogni modo, questo capitolo non affronta in modo completo l’installazione, la configurazione, o l’uso dei terminali X.
Questa sezione descrive quello che hai bisogno di configurare sul tuo sistema FreeBSD per abilitare una sessione di login via terminale. Si assume che tu abbia già configurato il kernel con il supporto per la porta seriale alla quale è connesso il terminale - e che questo sia già connesso.
Dovresti ricordare dal La Procedura di Avvio che il processo init è responsabile del controllo di tutti i processi e dell’inizializzazione del sistema all’avvio. Uno dei compiti svolti da init è la lettura del file /etc/ttys e l’avvio di un processo getty sui terminali disponibili. Il processo getty è responsabile della lettura di un nome di login e dell’avvio del programma login.
Dunque, per configurare i terminali per il tuo sistema FreeBSD devono essere effettuati come root i seguenti passi:
Aggiungi una linea a /etc/ttys relativa al file in /dev per la porta seriale, se non è già presente.
Specifica che /usr/libexec/getty deve essere eseguito sulla porta, e specifica il tipo appropriato di getty dal file /etc/gettytab.
Specifica il tipo di terminale predefinito.
Imposta la porta su "on".
Specifica se la porta deve essere "sicura".
Forza init alla rilettura del file /etc/ttys.
Come passo opzionale, potresti desiderare di creare un tipo di getty personale da usare nel secondo passo aggiungendo una linea in /etc/gettytab. Questo capitolo non spiega come fare ciò; sei incoraggiato a leggere le pagine man di gettytab(5) e getty(8) per maggiori informazioni.
Il file /etc/ttys elenca tutte le porte del tuo sistema FreeBSD dalle quali vuoi permettere un login. Ad esempio, la prima console virtuale ttyv0 è elencata in questo file. Si può accedere al sistema dalla console grazie a questa voce. Questo file contiene anche delle voci per altre console virtuali, porte seriali, e pseudo-tty. Per un terminale connesso fisicamente, basta copiare l’elenco delle porte seriali in /dev senza la parte /dev (ad esempio, /dev/ttyv0 verrà scritta come ttyv0).
Un’installazione predefinita di FreeBSD include un file /etc/ttys con supporto per le prime quattro porte seriali: da ttyd0 a ttyd3. Se vuoi collegare un terminale a una di queste porte, non hai bisogno di aggiungere un’altra voce.
Supponiamo che si vogliano collegare due terminali ad un sistema: un Wyse-50 ed un vecchio PC IBM 286 con Procomm come programma di emulazione di terminale VT-100. Colleghiamo il Wyse alla seconda porta seriale ed il 286 alla sesta (una porta su scheda seriale multiporta). Le voci corrispondenti nel file /etc/ttys apparirebbero così:
ttyd1 "/usr/libexec/getty std.38400" wy50 on insecure ttyd5 "/usr/libexec/getty std.19200" vt100 on insecure
Il primo campo in genere specifica il nome del file speciale per il terminale, come si trova in /dev.
Il secondo campo è il comando da eseguire per questa linea, generalmente getty(8). getty inizializza ed apre la linea, imposta la velocità, richiede all’utente un nome di login e poi esegue il programma login(1).Il programma getty accetta un parametro (opzionale) da riga di comando, il tipo di getty. Un tipo di getty configura le caratteristiche della linea del terminale, come la frequenza di bit per secondo e la parità. Il programma getty legge questa caratteristiche dal file /etc/gettytab.Il file /etc/gettytab contiene molte voci per le linee di terminale sia vecchie che nuove. In quasi tutti i casi, le voci che cominciano per std funzioneranno con i terminali connessi fisicamente. Queste voci ignorano la parità. C’è una voce std per ogni frequenza di bps da 110 a 115200. Naturalmente, puoi aggiungere le tue voci a questo file. La pagina man di gettytab(5) fornisce maggiori informazioni.Nell’impostare il tipo di getty nel file /etc/ttys, assicurati che le impostazioni di comunicazione sul terminale corrispondano.Nel nostro esempio, il Wyse-50 non usa parità e si connette a 38400 bps. Il PC 286 non usa parità e si connette a 19200 bps.
Il terzo campo è il tipo di terminale generalmente collegato alla linea tty. Per le porte dial-up, viene usato tipicamente unknown o dialup poiché gli utenti possono collegarsi con praticamente qualunque tipo di terminale o programma. Per i terminali connessi direttamente, il tipo di terminale non cambia, quindi puoi mettere un vero tipo di terminale preso dal file database di termcap(5) in questo campo.Per il nostro esempio, il Wyse-50 usa il tipo per il vero terminale mentre il PC 286 con Procomm in esecuzione verrà impostato per emulare un VT-100.
Il quarto campo specifica se la porta deve essere abilitata. Scrivere on qui farà sì che il processo init avvii il programma nel secondo campo, getty. Se metti off in questo campo, non ci sarà nessun getty, e dunque nessun login sulla porta.
Il campo finale è usato per specificare se la porta è sicura. Segnare una porta come sicura significa confidare nel fatto che non ci sia rischio nel permettere all’account di root (o ad un altro con user ID uguale a 0) di effettuare il login da quella porta. Porte insicure non permettono il login a root. Su una porta insicura, gli utenti devono effettuare un login con accesso non privilegiato, e poi usare su(1) o un meccanismo simile per ottenere privilegi superiori.È fortemente consigliato l’uso di "insecure" anche per i terminali che si trovano dietro porte chiuse a chiave. È abbastanza semplice effettuare il login e usare su se si ha bisogno di privilegi da superutente.
init a Rileggere /etc/ttysDopo aver effettuato i cambiamenti necessari al file /etc/ttys si deve mandare un segnale SIGHUP (hangup) al processo init affinché sia costretto a rileggere il suo file di configurazione. Ad esempio:
# kill -HUP 1
|
Se tutto è stato impostato correttamente, tutti i cavi sono collegati, ed i terminali sono accesi, allora un processo getty dovrebbe essere in esecuzione su ogni terminale e a questo punto dovresti vedere dei prompt per il login sui tuoi terminali.
Anche con la più meticolosa attenzione ai dettagli, qualcosa potrebbe comunque andare storto nell’impostazione di un terminale. Questa è una lista dei sintomi e di alcuni suggerimenti per risolverli.
Assicurati che il terminale sia connesso e acceso. Se è un personal computer che funziona da terminale, assicurati che il programma di emulazione di terminale sia attivo sulla porta seriale giusta.
Assicurati che il cavo sia ben connesso sia al terminale che al computer FreeBSD. Assicurati che sia il giusto tipo di cavo.
Assicurati che il terminale e FreeBSD siano concordi sul valore di bps e sulle impostazioni di parità. Se hai un terminale con un display video, assicurati che il contrasto e la luminosità siano giusti. Se è un terminale di stampa, assicurati che ci siano carta e inchiostro sufficienti.
Assicurati che il processo getty sia attivo per quel terminale. Ad esempio, per avere una lista dei processi getty con ps, scrivi:
# ps -axww | grep gettydovresti vedere una voce per il terminale. Ad esempio, la schermata seguente mostra che getty è in esecuzione sulla seconda porta seriale ttyd1 e sta usando la voce std.38400 in /etc/gettytab:
22189 d1 Is+ 0:00.03 /usr/libexec/getty std.38400 ttyd1Se non c’è nessun processo getty in esecuzione, assicurati di aver abilitato la porta in /etc/ttys. Ricordati anche di eseguire kill -HUP 1 dopo aver modificato il file ttys.
Se il processo getty è attivo ma il terminale non mostra ancora un prompt di login, o se mostra un prompt ma non ti permette di digitare nulla, il tuo terminale o il tuo cavo potrebbero non supportare la transazione hardware. Prova a cambiare il valore in /etc/ttys da std.38400 a 3wire.38400 (e ricordati di dare un kill -HUP 1 dopo aver modificato /etc/ttys). La voce 3wire è simile a std, ma ignora l’handshake hardware. Potresti aver bisogno di ridurre i baud o di abilitare un controllo di flusso software usando 3wire per evitare dei buffer overflow.
Assicurati che il terminale e FreeBSD siano concordi sui bps e sulle impostazioni di parità. Verifica i processi getty per assicurarti che sia in funzione il tipo corretto di getty. Se non è così, modifica /etc/ttys ed esegui kill -HUP 1.
La configurazione del sistema FreeBSD per il servizio di ricezione chiamate è molto simile alla connessione di terminali tranne per il fatto che si ha a che fare con dei modem invece che con dei terminali.
I modem esterni sembrerebbero migliori per chiamare, poiché i modem esterni spesso possono essere configurati in maniera semipermanente tramite dei parametri immagazzinati in RAM non volatile e generalmente forniscono degli indicatori luminosi che mostrano lo stato degli importanti segnali RS-232. Le lucine lampeggianti impressionano gli ospiti, ma sono anche molto utili per vedere se un modem sta funzionando in maniera appropriata.
I modem interni in genere mancano della RAM non-volatile, quindi la loro configurazione può essere limitata solo impostando i DIP switch. Se il tuo modem interno ha delle luci indicatrici di segnale, probabilmente è difficile vederle quando il case del sistema è al suo posto.
Se stai usando un modem esterno, allora avrai bisogno del cavo appropriato. Un cavo seriale standard RS-232C dovrebbe essere sufficiente, posto che tutti i normali segnali siano connessi:
| Acronimi | Nomi |
|---|---|
RD | Ricezione Dati |
TD | Trasmissione Dati |
DTR | Terminale di Dati Disponibile |
DSR | Pronto alla Trasmissione |
DCD | Data Carrier Detect (scopre il Segnale di Linea di Ricezione di RS-232) |
SG | Segnale di Massa |
RTS | Richiesta alla Trasmissione |
CTS | Disponibile all’Invio |
FreeBSD necessita dei segnali RTS e CTS per il controllo di flusso a velocità superiori a 2400 bps, del segnale CD per identificare quando c’è stata una risposta alla chiamata o quando una linea è stata scollegata, e del segnale DTR per dare il reset al modem dopo che una sessione è terminata. Alcuni cavi sono connessi senza alcuni dei segnali necessari, dunque se hai dei problemi, come una sessione di login che non scompare quando la linea è sconnessa, potresti avere un problema col cavo.
Come altri sistemi operativi UNIX®, FreeBSD usa i segnali hardware per scoprire quando una chiamata è stata accettata o quando una linea è stata scollegata e per scollegare e resettare il modem dopo una chiamata. FreeBSD evita di mandare comandi al modem o di leggere i valori riportati dal modem. Se hai familiarità con la connessione dei modem a BBS di PC, questo potrebbe sembrarti scomodo.
FreeBSD supporta interfacce di comunicazione EIA RS-232C (CCITT V.24) basate su NS8250, NS16450, NS16550, e NS16550A. I dispositivi 8250 e 16450 hanno buffer di un singolo carattere. Il dispositivo 16550 fornisce un buffer di 16 caratteri, che permette prestazioni del sistema migliori. (Dei bug nel normale 16550 impediscono l’uso del buffer di 16 caratteri, quindi usate 16550A se possibile). A causa del buffer a singolo carattere questi dispositivi richiedono un lavoro maggiore da parte del sistema operativo rispetto ai dispositivi a 16 caratteri di buffer, le schede d’interfaccia seriale basate su 16550A sono preferibili. Se il sistema ha molte porte seriali attive o dovrà sopportare un grosso carico, le schede basate su 16550A sono migliori per comunicazioni a basso tasso d’errore.
Come con i terminali, init lancia un processo getty per ogni porta seriale configurata per connessioni in ingresso. Ad esempio, se un modem è connesso a /dev/ttyd0, il comando ps ax mostrerà questo:
4850 ?? I 0:00.09 /usr/libexec/getty V19200 ttyd0Quando un utente chiama la linea del modem e questo si collega, il modem riporterà la linea CD (Carrier Detect). Il kernel nota che la portante è stata rilevata e completa l’apertura della porta con getty. getty invia un prompt login: alla velocità iniziale di linea specificata. getty aspetta per verificare che vengano ricevuti caratteri legittimi, e, in una tipica configurazione, se trova dei caratteri strani (probabilmente perché la velocità del modem è differente da quella di getty), getty cerca di calibrare la velocità di linea fino a ricevere dei caratteri ragionevoli.
Dopo che l’utente ha inserito il suo nome di login, getty esegue /usr/bin/login, che completa il login richiedendo la password per l’utente ed avviandone la shell.
Ci sono tre file di configurazione di sistema nella directory /etc che avrai probabilmente bisogno di modificare per permettere chiamate in ingresso sul tuo sistema FreeBSD. Il primo, /etc/gettytab, contiene le informazioni di configurazione per il demone /usr/libexec/getty. Il secondo, /etc/ttys contiene le informazioni che dicono a /sbin/init quali dispositivi tty devono avere processi getty in esecuzione. Infine, si possono mettere comandi di inizializzazione nello script /etc/rc.d/serial.
Ci sono due scuole di pensiero riguardo i modem su UNIX®. Un gruppo preferisce configurare i propri modem in maniera che qualunque sia la velocità con la quale un utente remoto si collega, l’interfaccia locale RS-232 computer-modem funzioni ad una velocità fissa. Il beneficio di questa configurazione è che l’utente remoto vede sempre un prompt di login immediato. Il lato negativo è che il sistema non sa quale sia la vera velocità di trasmissione dati di un utente, quindi programmi a tutto schermo come Emacs non modificheranno i loro metodi di rappresentazione dello schermo per ottimizzare la risposta su connessioni lente.
L’altra scuola di pensiero configura le proprie interfacce RS-232 verso il modem per variare la propria velocità rispetto a quella di connessione dell’utente remoto. Ad esempio, le connessioni V.32bis (14.4 Kbps) faranno sì che il modem faccia funzionare la propria interfaccia RS-232 a 19.2 Kbps, mentre le connessioni a 2400 bps faranno sì che funzioni a 2400 bps. Poiché getty non comprende nessun valore restituito dal modem riguardo la velocità di connessione, getty darà un messaggio login: ad una velocità iniziale fissata e aspetterà i caratteri in risposta. Se l’utente vede caratteri strani, si assume che sappia che dovrà premere Invio finché non vedrà un prompt riconoscibile. Se le frequenze di trasmissione non concordano, getty vedrà tutto ciò che l’utente preme come "spazzatura", cercherà di passare alla velocità seguente e invierà il prompt login: di nuovo. Questa procedura potrebbe continuare ad nauseam, ma normalmente ci vogliono solo una o due pressioni sui tasti prima che l’utente veda un buon prompt. Ovviamente, questa sequenza di login non è pulita come la precedente a "velocità fissata", ma un utente su una connessione a bassa velocità dovrebbe ricevere una risposta interattiva migliore da programmi a tutto schermo.
Questa sezione cercherà di fornire informazioni di configurazione bilanciate, ma è indirizzata verso l’approccio di avere la frequenza di trasmissione del modem che segue la velocità della connessione.
/etc/gettytab è un file di configurazione sul modello di termcap(5) per getty(8). Si prega di vedere la pagina man di gettytab(5) per le informazioni complete sul formato del file e la lista delle sue possibilità.
Se stai fissando la frequenza di comunicazione del modem ad una velocità particolare, probabilmente non avrai bisogno di effettuare nessun cambiamento a /etc/gettytab.
C’è bisogno di impostare una voce in /etc/gettytab per dare a getty le informazioni sulla velocità che si vuole usare per il modem. Se si possiede un modem a 2400 bps, probabilmente è possibile usare la voce D2400 già esistente.
#
# Terminali chiamanti veloci, a rotazione 2400/1200/300
# (può impostarsi in tutti i modi)
#
D2400|d2400|Fast-Dial-2400:\
:nx=D1200:tc=2400-baud:
3|D1200|Fast-Dial-1200:\
:nx=D300:tc=1200-baud:
5|D300|Fast-Dial-300:\
:nx=D2400:tc=300-baud:Se si possiede un modem con velocità maggiore, probabilmente sarà necessario aggiungere una voce in /etc/gettytab; qui c’è un esempio per modem a 14.4 Kbps modem con una velocità massima d’interfaccia di 19.2 Kbps:
#
# Aggiunte per un modem V.32bis
#
um|V300|High Speed Modem at 300,8-bit:\
:nx=V19200:tc=std.300:
un|V1200|High Speed Modem at 1200,8-bit:\
:nx=V300:tc=std.1200:
uo|V2400|High Speed Modem at 2400,8-bit:\
:nx=V1200:tc=std.2400:
up|V9600|High Speed Modem at 9600,8-bit:\
:nx=V2400:tc=std.9600:
uq|V19200|High Speed Modem at 19200,8-bit:\
:nx=V9600:tc=std.19200:Questo risulterà in una connessione a 8-bit, senza parità.
L’esempio precedente avvia la comunicazione a 19.2 Kbps (per una connessione V.32bis), poi cicla tra 9600 bps (per V.32), 2400 bps, 1200 bps, 300 bps, e poi ancora a 19.2 Kbps. Il ciclo sulle frequenze di comunicazione è implementato con nx= ("next table"). Ogni linea usa una voce tc= ("table continuation") per continuare a leggere le impostazioni "standard" per una frequenza particolare.
Se hai un modem a 28.8 Kbps e/o vuoi avvantaggiarti della compressione su un modem a 14.4 Kbps, hai bisogno di usare una frequenza di comunicazione più alta di 19.2 Kbps. Qui c’è un esempio di voce per gettytab che imposta la velocità a 57.6 Kbps:
#
# Aggiunte per modem V.32bis o V.34 Modem
# Impostazione a 57.6 Kbps
#
vm|VH300|Very High Speed Modem at 300,8-bit:\
:nx=VH57600:tc=std.300:
vn|VH1200|Very High Speed Modem at 1200,8-bit:\
:nx=VH300:tc=std.1200:
vo|VH2400|Very High Speed Modem at 2400,8-bit:\
:nx=VH1200:tc=std.2400:
vp|VH9600|Very High Speed Modem at 9600,8-bit:\
:nx=VH2400:tc=std.9600:
vq|VH57600|Very High Speed Modem at 57600,8-bit:\
:nx=VH9600:tc=std.57600:Se hai una CPU lenta o un carico di sistema pesante e non hai porte seriale 16550A, potresti ricevere errori `sio`"silo" a 57.6 Kbps.
La configurazione del file /etc/ttys è stata affrontata nella Aggiunta di Voci per Altri Terminali a /etc/ttys. La configurazione dei modem è simile ma dobbiamo passare un argomento differente a getty e specificare un tipo di terminale differente. Il formato generale per la configurazione sia a velocità fissata che per quella concordata è:
ttyd0 "/usr/libexec/getty xxx" dialup on
Il primo elemento nella linea precedente è il file di dispositivo per questa voce - ttyd0 significa che /dev/ttyd0 è il file che verrà tenuto d’occhio da getty. Il secondo elemento, "/usr/libexec/getty xxx" (xxx verrà rimpiazzato dalla capacità iniziale di gettytab) è il processo che init eseguirà sul dispositivo. Il terzo elemento, dialup, è il tipo predefinito di terminale. Il quarto parametro, on, indica a init che quella linea è operativa. Potrebbe esserci un quinto parametro, secure, ma dovrebbe essere usato solo per i terminali che siano fisicamente sicuri (come la console di sistema).
Il tipo di terminale predefinito (dialup nell’esempio precedente) potrebbe dipendere dalle preferenze locali. dialup è il terminale tradizionale predefinito sulle linee di ingresso in maniera che gli utenti possano personalizzare i loro script di login per notare quando il terminale è dialup e modificare automaticamente il loro tipo di terminale. Ad ogni modo, l’autore ritiene più semplice specificare vt102 come tipo di terminale predefinito, poiché l’utente può usare semplicemente un’emulazione VT102 sul suo sistema remoto.
Dopo aver effettuato i cambiamenti a /etc/ttys, puoi inviare un segnale HUP a init per fargli rileggere il file. Puoi usare il comando
# kill -HUP 1per inviare il segnale. Se questa è la prima volta che cambi le impostazioni del sistema, puoi aspettare finché il modem non sia configurato in maniera appropriata e connesso, prima di inviare il segnale a init.
Per una configurazione a velocità fissa, la voce in ttys ha bisogno di una voce che gestisca la velocità fissa anche per getty. Per un modem la cui velocità sulla porta sia bloccata a 19.2 Kbps, la voce in ttys potrebbe essere così:
ttyd0 "/usr/libexec/getty std.19200" dialup on
Se il tuo modem è bloccato su una frequenza di trasmissione differente, sostituisci il valore appropriato per std.velocità al posto di std.19200. Assicurati di usare un tipo valido elencato in /etc/gettytab.
In una configurazione a velocità concordata, la voce in ttys deve fare riferimento alla voce iniziale "auto-baud" (sic) in /etc/gettytab. Ad esempio, se hai aggiunto la riga suggerita precedentemente per un modem con velocità variabile che inizi a 19.2 Kbps (la riga in gettytab contenente il punto d’avvio V19200), la riga in ttys potrebbe essere questa:
ttyd0 "/usr/libexec/getty V19200" dialup on
I modem ad alta velocità, come i V.32, i V.32bis, e i V.34, necessitano di un controllo di flusso hardware (RTS/CTS). Puoi aggiungere dei comandi stty al file /etc/rc.d/serial per impostare i flag di controllo di flusso nel kernel FreeBSD per le porte del modem.
Ad esempio per impostare il flag termios``crtscts sui dispositivi di inizializzazione di ingresso e uscita della porta seriale numero 1 (COM2), si possono aggiungere le seguenti linee a /etc/rc.d/serial:
# Configurazione iniziale della porta seriale stty -f /dev/ttyd1.init crtscts stty -f /dev/cuad1.init crtscts
Se hai uno di quei modem i cui parametri possono essere impostati in maniera permanente in RAM non volatile, avrai bisogno di usare un programma terminale (come Telix su MS-DOS® o tip sotto FreeBSD) per impostare i parametri. Collegati al modem usando le stesse velocità iniziali e di comunicazione che userebbe getty e configura la RAM non volatile secondo queste necessità:
CD attivo per la connessione
DTR attivo per l’operazione; l’assenza del DTR porta allo scollegamento della linea e al reset del modem
CTS controllo di flusso dei dati trasmessi
Disabilita il controllo di flusso XON/XOFF
RTS controllo di flusso dei dati ricevuti
Modalità silenziosa (nessun codice di risposta)
Nessun echo dei comandi
Leggi la documentazione del tuo modem per capire quali comandi e/o impostazioni per i DIP switch sia necessario fornirgli.
Ad esempio, per impostare i parametri precedenti su un U.S. Robotics® Sportster® 14.400 esterno, si potrebbero dare questi comandi al modem:
ATZ AT&C1&D2&H1&I0&R2&W
Potresti anche sfruttare questa opportunità per raffinare le impostazioni del modem, ad esempio per decidere se dovrà usare V.42bis e/o la compressione MNP5.
Il modem esterno U.S. Robotics® Sportster® 14.400 ha anche dei DIP switch che devono essere impostati; per altri modem, forse potrai usare queste impostazioni come esempio:
Switch 1: SU - DTR Normale
Switch 2: N/D (Codici di Risposta Verbali/Codici di Risposta Numerici
Switch 3: SU - Sopprime i Codici di Risposta
Switch 4: GIÙ - Nessun echo, comandi offline
Switch 5: SU - Auto risposta
Switch 6: SU - Carrier Detect Normale
Switch 7: SU - Carica i valori predefiniti dall’NVRAM
Switch 8: N/D (Modalità intelligente/modalità stupida)
I codici di risposta dovrebbero essere disabilitati/soppressi per i modem chiamanti per evitare i problemi che possono capitare se getty dà incidentalmente un prompt login: ad un modem che si trova in modalità di comando ed il modem restituisce l’eco del comando o un codice di risposta. Questa sequenza può portare ad una lunga, stupida conversazione tra getty ed il modem.
Per una configurazione a velocità fissa, avrai bisogno di configurare il modem affinché mantenga una frequenza dati da modem a computer indipendente dalla frequenza di comunicazione. Su un modem esterno U.S. Robotics® Sportster® 14.400 questi comandi bloccheranno la velocità dati tra modem e computer alla velocità con la quale i comandi sono stati inviati:
ATZ AT&B1&W
Per una configurazione a velocità concordata, sarà necessario configurare il modem affinché modifichi la frequenza dei dati della porta seriale relativamente alla velocità di arrivo. Su un modem esterno U.S. Robotics® Sportster® 14.400, questi comandi causeranno il blocco della frequenza di trasmissione dati con correzione d’errore del modem sulla velocità con il quale è stato inviato il comando, ma permetteranno variazioni della velocità della porta seriale per le connessioni senza correzione d’errore:
ATZ AT&B2&W
La maggior parte dei modem ad alta velocità fornisce comandi per verificare i parametri funzionali usati dal modem in maniera più o meno comprensibile. Sui modem esterni U.S. Robotics® Sportster® 14.400, il comando ATI5 mostra le impostazioni che sono immagazzinate nella RAM non volatile. Per vedere i veri parametri operativi del modem (così come vengono influenzati dai DIP switch del modem), usa i comandi ATZ e ATI4.
Se hai modem di marche differenti, verifica il manuale del tuo modem per vedere come sia possibile un ulteriore controllo sui parametri di configurazione del modem.
Questi sono un po' di passi che è possibile seguire per verificare il funzionamento del modem sul tuo sistema.
Collega il modem al sistema FreeBSD, avvia il sistema, e, se il tuo modem ha luci di indicazione dello stato, guarda se la luce DTR del modem si accende quando appare il prompt login: sulla console del sistema - se si accende, dovrebbe significare che FreeBSD ha avviato un processo getty sulla porta di comunicazione appropriata e sta aspettando una chiamata dal modem.
Se l’indicatore DTR non lampeggia, effettua il login sul sistema FreeBSD dalla console e dai il comando ps ax per verificare se FreeBSD sta cercando di eseguire un processo getty sulla porta corretta. Dovresti vedere linee come queste tra i processi mostrati:
114 ?? I 0:00.10 /usr/libexec/getty V19200 ttyd0
115 ?? I 0:00.10 /usr/libexec/getty V19200 ttyd1Se vedi qualcosa di diverso, come questo:
114 d0 I 0:00.10 /usr/libexec/getty V19200 ttyd0ed il modem non ha ancora accettato chiamate, ciò significa che getty ha completato l’apertura della porta di comunicazione. Questo potrebbe indicare un problema nei cavi o un modem mal configurato, poiché getty non dovrebbe completare l’apertura della porta fino al rilevamento del segnale CD (carrier detect).
Se non vedi nessun processo getty in attesa sulla porta ttydN scelta, ricontrolla le voci in /etc/ttys per vedere se ci sono errori lì. Inoltre, controlla il file di log /var/log/messages per vedere se ci sono messaggi di init o getty riguardo i loro problemi. Se ci sono messaggi, ri-ricontrolla i file di configurazione /etc/ttys e /etc/gettytab, ed anche i file speciali di dispositivo /dev/ttydN, cercando ogni errore, voce mancante, o file di dispositivo mancante.
Cerca di collegarti dall’esterno al sistema; assicurati di usare 8 bit, nessuna parità, e 1 bit di stop sul sistema remoto. Se non ottieni un prompt, o vengono visualizzati caratteri strani, prova a premere Invio circa una volta per secondo. Se dopo un po' ancora non vedi un prompt login:, prova inviare un'`INTERRUZIONE`. Se stai usando un modem ad alta velocità per effettuare la chiamata, prova a richiamare dopo aver bloccato la velocità dell’interfaccia del modem (tramite AT&B1 su un U.S. Robotics® Sportster®, ad esempio).
Se ancora non ottieni alcun prompt login:, verifica /etc/gettytab ancora e ricontrolla che:
La capacità iniziale specificata in /etc/ttys per quella linea corrisponda a quella in /etc/gettytab
Ogni campo nx= corrisponda ad un valore in gettytab
Ogni campo tc= corrisponda a un altro nome di capacità in gettytab
Se chiami ma il modem su FreeBSD non risponde, assicurati che il modem sia configurato per rispondere alla chiamata quando viene fornito un segnale DTR. Se il modem sembra essere configurato correttamente, verifica che la linea DTR sia attiva controllando gli indicatori luminosi del modem (se ne ha).
Se hai già controllato tutto quanto più volte ed ancora non funziona, fai una pausa e riprova in seguito. Se ancora non funziona puoi provare a inviare un messaggio di posta elettronica alla mailing list per le domande generiche su FreeBSD descrivendo il tuo modem ed il tuo problema, e i bravi ragazzi della lista cercheranno di darti una mano.
I seguenti sono consigli per far sì che la tua macchina sia in grado di connettersi tramite modem ad un altro computer. Questo è appropriato per stabilire una sessione terminale con un host remoto.
Questo è utile per collegarsi ad una BBS.
Questo tipo di connessione può essere estremamente utile per ottenere un file da Internet se hai problemi con il PPP. Se hai bisogno di usare l’FTP ed il PPP non funziona, usa la sessione terminale per eseguire l’FTP. Poi usa zmodem per trasferire il file sulla tua macchina.
Effettivamente, la pagina man di tip è un po' datata. C’è un compositore Hayes generico già integrato. Usa semplicemente at=hayes nel tuo /etc/remote file.
Il driver Hayes non è abbastanza intelligente da riconoscere alcune delle caratteristiche avanzate dei nuovi modem-messaggi come BUSY, NO DIALTONE, o CONNECT 115200 lo confonderanno e basta. Dovrai disattivare questi messaggi quando usate tip (usando ATX0&W).
Inoltre, il timeout di composizione per tip è di 60 secondi. Il tuo modem dovrebbe usare qualcosa di meno, altrimenti tip penserà che ci sia un problema di comunicazione. Prova ATS7=45&W.
Come viene fornito, Modifica la linea |
Inserisci quella che viene definita una voce "diretta" nel file /etc/remote. Ad esempio, se il tuo modem è collegato alla prima porta seriale, /dev/cuad0, allora inserisci la riga seguente:
cuad0:dv=/dev/cuad0:br#19200:pa=none
Usa la frequenza di bps più alta supportata dal tuo modem per il valore di br. Poi, digita tip cuad0 e verrai connesso al tuo modem.
O usa cu come root con il seguente comando:
# cu -llinea -s velocitàlinea è la porta seriale (es. /dev/cuad0) e velocità è la velocità (es. 57600). Quando hai finito di inserire i comandi AT premi ~. per uscire.
@ per il Valore pn Non Funziona!Il simbolo @ come valore del numero telefonico dice a tip di andare a cercare un numero telefonico in /etc/phones. Ma il segno @ è anche un carattere speciale nei file come /etc/remote. Devi farne l’escape con un backslash:
pn=\@
Metti una cosiddetta voce "generica" in /etc/remote. Ad Esempio:
tip115200|Chiama un qualunque numero a 115200 bps:\
:dv=/dev/cuad0:br#115200:at=hayes:pa=none:du:
tip57600|Chiama un qualunque numero a 57600 bps:\
:dv=/dev/cuad0:br#57600:at=hayes:pa=none:du:Poi puoi fare una cosa simile:
# tip -115200 5551234Se preferisci cu a tip, usa una voce generica per cu:
cu115200|Usa cu per chiamare un numero qualsiasi a 115200bps:\
:dv=/dev/cuad1:br#57600:at=hayes:pa=none:du:e digita:
# cu 5551234 -s 115200Metti una voce per tip1200 o cu1200, ma vai avanti e inserisci una qualunque frequenza di bps appropriata per il valore di br. tip pensa che un buon valore predefinito sia 1200 bps, motivo per cui cerca una voce per tip1200. Non sei obbligato a usare 1200 bps, comunque.
Invece di aspettare fino ad essere connesso e poi digitare CONNECT <host> ogni volta, usa la funzionalità cm di tip. Ad esempio, queste voci in /etc/remote:
pain|pain.deep13.com|La macchina di Forrester:\
:cm=CONNECT pain\n:tc=deep13:
muffin|muffin.deep13.com|La macchina di Frank:\
:cm=CONNECT muffin\n:tc=deep13:
deep13:Server di terminali del Gizmonics Institute:\
:dv=/dev/cuad2:br#38400:at=hayes:du:pa=none:pn=5551234:ti permetteranno di digitare tip pain o tip muffin per collegarti agli host pain o muffin, e tip deep13 per il server di terminali.
Questo è spesso un problema quando una università ha molte linee di modem e molte migliaia di studenti cercano di usarle.
Inserisci una voce per la tua università in /etc/remote e usa @ per il campo pn:
big-university:\
:pn=\@:tc=dialout
dialout:\
:dv=/dev/cuad3:br#9600:at=courier:du:pa=none:Poi, elenca i numeri di telefono dell’università in /etc/phones:
big-university 5551111 big-university 5551112 big-university 5551113 big-university 5551114
tip proverà ognuno di questi secondo l’ordine, poi smetterà. Se vuoi continuare a riprovare, esegui tip in un ciclo while.
Ctrl+P è il carattere predefinito per "forzare", usato per dire a tip che il prossimo carattere è un dato letterale. Puoi impostare il carattere per forzare a qualsiasi altro carattere con il comando di escape ~s, che significa "imposta una variabile".
Digita ~sforce=singolo-carattere seguito da un ritorno a capo. singolo-carattere è un qualsiasi carattere singolo. Se non date nessun singolo-carattere, allora il carattere per forzare sarà il carattere nullo, che è possibile ottenere premendo Ctrl+2 o Ctrl+Spazio. Un valore abbastanza buono per il singolo-carattere è Shift+Ctrl+6, che è usato solo da alcuni server di terminali.
Potete far sì che il carattere per forzare sia un qualsiasi carattere vogliate specificando la riga seguente nel file $HOME/.tiprc:
force=<singolo-carattere>
Devi aver premuto Ctrl+A, il "raise character", di tip progettato specificamente per le persone con il tasto caps-lock rotto. Usa ~s come mostrato prima per impostare la variabile raisechar a qualcosa di ragionevole. In pratica, puoi impostarla allo stesso valore del carattere per forzare, se pensi di non usare mai queste due caratteristiche.
Qui c’è un file .tiprc di esempio per gli utenti Emacs che hanno bisogno di premere Ctrl+2 e Ctrl+A molto spesso:
force=^^ raisechar=^^
Il carattere ^^ è Shift+Ctrl+6.
tip?Se stai parlando ad altri sistemi UNIX®, puoi mandare e ricevere file con ~p (put) e ~t (take). Questi comandi eseguono cat ed echo sul sistema remoto per accettare e inviare file. La sintassi è:
~p file-locale [ file-remoto ]
~t file-remoto [ file-locale ]
non c’è controllo d’errore, quindi probabilmente dovresti usare un altro protocollo, come zmodem.
FreeBSD ha la capacità di avviare un sistema con soltanto un terminale stupido su porta seriale come console. Una configurazione simile dovrebbe essere utile per due tipi di persone: amministratori di sistema che desiderano installare FreeBSD su macchine che non hanno tastiera o monitor connesso, e sviluppatori che vogliono effettuare il debug del kernel o dei driver.
Come descritto nel La Procedura di Avvio, FreeBSD implementa un avviamento composto da tre stadi. I primi due stadi sono nel blocco di avvio che viene immagazzinato all’inizio della slice di FreeBSD sul disco d’avvio. Il blocco di avvio poi carica ed avvia il loader (/boot/loader) come terzo stadio.
Per poter impostare la console seriale devi configurare il codice del blocco di avvio, il codice del loader ed il kernel.
Questa sezione presuppone che stai usando una configurazione di default e vuoi solamente una veloce panoramica su come abilitare una console seriale.
Connetti il cavo seriale alla COM1 e al terminale.
Per vedere tutti i messaggi di boot sulla console seriale, dai il comando seguente mentre sei loggato come superuser:
# echo 'console="comconsole"' >> /boot/loader.confModifica il file /etc/ttys e cambia off in on e dialup in vt100 per l’entry ttyd0. Altrimenti non verrà chiesta la password per connettersi via console seriale, con il risultato di creare un potenziale buco di sicurezza.
Riavvia il sistema per vedere se i cambiamenti funzionano.
Se si necessita di una diversa configurazione, esiste una spiegazione maggiormente dettagliata nella sezione Configurazione della Console Seriale.
Preparazione di un cavo seriale.
Avrai bisogno di un cavo null-modem o di un cavo seriale standard ed un adattatore null-modem. Guarda Cavi e Porte per una discussione sui cavi seriali.
Scollegamento della tastiera.
La maggior parte dei sistemi PC verifica la presenza di una tastiera durante il Power-On Self-Test (POST) e dà un errore se la tastiera non viene rilevata. Alcune macchine si lamentano parecchio per la mancanza della tastiera e non proseguono l’avvio finché non viene collegata.
Se il tuo computer si lamenta per questo errore, ma si avvia lo stesso, allora non devi fare nulla di speciale. (Alcune macchine con BIOS Phoenix semplicemente dicono Keyboard failed e continuano ad avviarsi normalmente).
Se il tuo computer rifiuta di avviarsi senza la tastiera allora dovrai configurare il BIOS affinché ignori questo errore (se possibile). Consulta il manuale della tua scheda madre per maggiori dettagli su come fare ciò.
Imposta la tastiera su "Non installata" nel setup del BIOS. Sarai ancora in grado di usare la tastiera. Tutto quel che fa è dire al BIOS di non verificare la presenza di una tastiera all’accensione. Il tuo BIOS non dovrebbe segnalare che la tastiera non è collegata. Puoi lasciare la tastiera collegata anche con questa opzione impostata a "Non installata" e la tastiera funzionerà lo stesso. |
Se il tuo sistema ha un mouse PS/2®, le possibilità di dover scollegare il mouse allo stesso modo della tastiera sono alte. Questo perché i mouse PS/2® condividono dell’hardware con la tastiera e lasciando il mouse collegato potresti ingannare la verifica della tastiera facendogli credere che sia ancora presente. Si dice che il sistema Gateway 2000 Pentium 90 MHz con BIOS AMI funzioni così. In generale, questo non è un problema perché il mouse non è comunque particolarmente utile senza la tastiera. |
Collegamento di un terminale stupido alla COM1 (sio0).
Se non possiedi un terminale stupido, puoi usare un vecchio PC/XT con un programma per modem, o la porta seriale di un altra macchina UNIX®. Se non hai una COM1 (sio0), trovane una. Attualmente, non c’è altro modo di scegliere una porta diversa dalla COM1 per i blocco di avvio senza doverlo ricompilare. Se stai già usando la COM1 per un altro dispositivo, dovrai rimuoverlo temporaneamente ed installare un nuovo blocco di avvio ed un nuovo kernel una volta che FreeBSD sia funzionante. (Si assume che la COM1 sia sempre disponibile su un server di file/calcolo/terminali; se davvero hai bisogno della COM1 per qualcos’altro (e non puoi passare quel qualcosa alla COM2 (sio1)), allora probabilmente non dovresti nemmeno avere a che fare con tutto questo in primo luogo).
Assicurati che il file di configurazione del tuo kernel abbia i parametri appropriati impostati per la COM1 (sio0).
I parametri rilevanti sono:
0x10Abilita il supporto alla console per questa unità. Gli altri parametri di console sono ignorati se non è fissato questo. Attualmente, al massimo un’unità può avere il supporto alla console; verrà preferita la prima (secondo l’ordine nel file di configurazione) con questo parametro. Questa opzione non renderà la porta seriale la console. Imposta il parametro seguente o usa l’opzione -h descritta più in basso, insieme a questa impostazione.
0x20Forza questa unità ad essere la console (a meno che sia presente un’altra console con priorità più alta), trascurando l’opzione -h discussa precedentemente. Il parametro 0x20 deve essere usato insieme al 0x10.
0x40Riserva questa unità (insieme a 0x10) e rende l’unità indisponibile per l’accesso normale. Non dovresti impostare questo parametro sull’unità della porta seriale che desideri usare come console seriale. L’unico uso di questo parametro è per designare l’unità per il debug remoto del kernel. Guarda il Developer’s Handbook per maggiori informazioni sul debugging remoto.
In FreeBSD 4.0 o successivo, la semantica del parametro |
Esempio:
device sio0 at isa? port IO_COM1 flags 0x10 irq 4
Guarda la pagina man sio(4) per maggiori dettagli.
Se i parametri non sono stati impostati, sarà necessario eseguire UserConfig (su una console differente) o ricompilare il kernel.
Creazione di boot.config nella directory radice della partizione a nel disco di avvio.
Questo file istruirà il codice del blocco di avvio su come vuoi avviare il sistema. Per poter attivare la console seriale, avrai bisogno di una o più delle seguenti opzioni-se vuoi opzioni multiple, includile tutte sulla stessa linea:
-hPassa dalla console interna a quella seriale. Puoi usarla per cambiare i dispositivi console. Ad esempio, se avvii dalla console interna (video), puoi usare -h per dirigere il loader ed il kernel in modo che usino la porta seriale come dispositivo per la console. Alternativamente, se avvii da porta seriale, puoi usare l’opzione -h per dire al loader ed al kernel di usare lo schermo come console.
-DPassa da una configurazione singola a una duplice. Nella configurazione singola la console sarà o quella interna (il display video) o la porta seriale, a seconda dello stato dell’opzione -h già descritta. Nella configurazione duplice, sia il display video che la porta seriale diventeranno la console allo stesso momento, senza curarsi dello stato dell’opzione -h. Ad ogni modo, nota che questa configurazione duplice ha effetto solo durante l’esecuzione del blocco di avvio. Una volta che il loader ha assunto il controllo, la console specificata da -h diventa l’unica.
-PFa sì che il blocco di avvio verifichi la presenza della tastiera. Se non ne viene rilevata nessuna, le opzioni -D e -h vengono impostate automaticamente.
A causa delle costrizioni relative allo spazio nelle versioni attuali del blocco di avvio, l’opzione |
Usa l’opzione -P per selezionare la console automaticamente, o l’opzione -h per attivare la console seriale.
Puoi includere altre opzioni come descritte in boot(8).
Le opzioni, eccetto -P, verranno passate al loader (/boot/loader). Il loader determinerà quale tra il video interno o la console seriale debba diventare la console esaminando lo stato dell’opzione -h. Ciò significa che se specifichi l’opzione -D ma non la -h in /boot.config, puoi usare la porta seriale come console soltanto durante l’esecuzione del blocco di avvio; il loader userà il video interno come console.
Avviamento della macchina.
Quando avvii la tua macchina FreeBSD, il blocco di avvio scriverà il contenuto di /boot.config sulla console. Ad esempio:
/boot.config: -P
Keyboard: noLa seconda linea appare solo se metti l’opzione -P in /boot.config ed indichi la presenza/assenza della tastiera. Questo messaggio va alla console seriale o a quella interna, o a entrambe, a seconda dell’opzione in /boot.config.
| Opzioni | I messaggi vanno a |
|---|---|
nessuna | console interna |
| console seriale |
| console seriale ed interna |
| console seriale ed interna |
| console interna |
| console seriale |
Dopo i messaggi precedenti, ci sarà una piccola pausa prima che il blocco di avvio continui nel caricamento del loader e prima che ulteriori messaggi vengano scritti sulla console. In circostanze normali, non hai necessità di interrompere il blocco di avvio, ma potresti volerlo fare per verificare che tutto sia impostato correttamente.
Premi un tasto qualsiasi, differente da Invio, alla console per interrompere il processo di avvio. Il blocco di avvio aspetterà ulteriori azioni. Dovresti vedere qualcosa del genere:
>> FreeBSD/i386 BOOT
Default: 0:ad(0,a)/boot/loader
boot:Verifica se il messaggio precedente appare sulla console seriale o su quella interna o su entrambe, secondo le opzioni poste in /boot.config. Se il messaggio appare nella console corretta, premi Invio per continuare il processo di avvio.
Se vuoi la console seriale ma non riesci a vedere il prompt sul terminale seriale, qualcosa è sbagliato nelle tue impostazioni. Nel frattempo, scrivi -h e premi Invio (se possibile) per dire al blocco di avvio (e al loader e al kernel) di scegliere la porta seriale per la console. Una volta che il sistema è attivo, torna indietro e verifica cosa è andato storto.
Dopo che il loader è stato caricato e ti trovi nel terzo stadio del processo di avvio puoi ancora passare dalla console interna alla console seriale impostando le variabili d’ambiente appropriate nel loader. Guarda la Cambiamento della Console dal Loader.
Qui c’è il sommario delle varie impostazioni discusse in questa sezione e la console eventualmente selezionata.
device sio0 at isa? port IO_COM1 flags 0x10 irq 4
| Opzioni in /boot.config | Console durante i blocco di avvio | Console durante il loader | Console nel kernel |
|---|---|---|---|
niente | interna | interna | interna |
| seriale | seriale | seriale |
| seriale ed interna | interna | interna |
| seriale ed interna | seriale | seriale |
| interna | interna | interna |
| seriale ed interna | seriale | seriale |
device sio0 at isa? port IO_COM1 flags 0x30 irq 4
| Opzioni in /boot.config | Console durante i blocco di avvio | Console durante il loader | Console nel kernel |
|---|---|---|---|
niente | interna | interna | seriale |
| seriale | seriale | seriale |
| seriale ed interna | interna | seriale |
| seriale ed interna | seriale | seriale |
| interna | interna | seriale |
| seriale ed interna | seriale | seriale |
Di default, le impostazioni della porta seriale sono: 9600 baud, 8 bit, nessuna parità, ed 1 bit di stop. Se desideri cambiare la velocità, avrai bisogno di ricompilare almeno il blocco di avvio. Aggiungi la linea seguente a /etc/make.conf e compila il nuovo blocco di avvio:
BOOT_COMCONSOLE_SPEED=19200
Guarda Utilizzo di una Porta Seriale Differente da sio0 per la Console per istruzioni dettagliate su come costruire e installare nuovi blocchi di avvio.
Se la console seriale è configurata in qualche altra maniera invece di essere selezionata all’avvio con -h, o se la console seriale usata dal kernel è differente da quella usata dal blocco di avvio, allora dovrai aggiungere anche le opzioni seguenti al file di configurazione del kernel e compilare un nuovo kernel:
options CONSPEED=19200
Usare una porta seriale differente da sio0 come console richiede un po' di ricompilazione. Se vuoi usare un’altra porta seriale per qualche motivo, ricompila il blocco di avvio, il loader ed il kernel come segue.
Ottieni i sorgenti del kernel. (Guarda il Lo Stato dell’Arte)
Modifica /etc/make.conf e imposta BOOT_COMCONSOLE_PORT all’indirizzo della porta che vuoi usare (0x3F8, 0x2F8, 0x3E8 o 0x2E8). Solo i dispositivi da sio0 a sio3 (COM1 a COM4) possono essere usati; le schede seriali multiporta non funzioneranno. Non sono necessarie impostazioni per gli interrupt.
Crea un file di configurazione del kernel personalizzato e aggiungi i flag appropriati per la porta seriale che intendi usare. Ad esempio, se vuoi fare di sio1 (COM2) la console:
device sio1 at isa? port IO_COM2 flags 0x10 irq 3
o
device sio1 at isa? port IO_COM2 flags 0x30 irq 3
I flag di console per le altre porte seriali non dovrebbero essere impostati.
Ricompila ed installa il blocco di avvio ed il loader:
# cd /sys/boot
# make clean
# make
# make installRicompila ed installa il kernel.
Scrivi il blocco di avvio sul disco di avvio con disklabel(8) ed avvia con il nuovo kernel.
Se desideri entrare nel debugger del kernel dalla console seriale (utile per diagnostiche remote, ma anche molto pericoloso se generi un BREAK spurio sulla porta seriale!) allora dovrai compilare il tuo kernel con le opzioni seguenti:
options BREAK_TO_DEBUGGER options DDB
Anche se questo non è necessario, potresti desiderare un prompt di login sulla linea seriale, ora che puoi vedere i messaggi di avvio e puoi accedere a sessioni di debug del kernel attraverso la console seriale. Qui è spiegato come fare.
Apri il file /etc/ttys con un editor e trova queste linee:
ttyd0 "/usr/libexec/getty std.9600" unknown off secure ttyd1 "/usr/libexec/getty std.9600" unknown off secure ttyd2 "/usr/libexec/getty std.9600" unknown off secure ttyd3 "/usr/libexec/getty std.9600" unknown off secure
I dispositivi da ttyd0 a ttyd3 corrispondono a COM1 fino a COM4. Cambia off a on per la porta desiderata. Se hai cambiato la velocità della porta seriale, dovrai cambiare std.9600 affinché corrisponda all’impostazione corrente, ad es. std.19200.
Potresti anche desiderare cambiare il tipo di terminale da unknown al tipo effettivo del tuo terminale seriale.
Dopo avere modificato il file, devi dare un kill -HUP 1 affinché i cambiamenti abbiano effetto.
Le sezioni precedenti hanno descritto come impostare la console seriale lavorando sul blocco di avvio. Questa sezione mostra come specificare a console inserendo alcuni comandi ed alcune variabili di ambiente nel loader. Quando il loader verrà invocato al terzo stadio del processo di avvio, dopo il blocco di avvio, le impostazioni nel loader prenderanno il posto di quelle nel blocco di avvio.
Puoi facilmente specificare al loader ed al kernel di usare la console seriale scrivendo una sola riga in /boot/loader.rc:
set console="comconsole"
Ciò sarà efficace in ogni caso, qualunque siano le impostazioni nel blocco di avvio discusse nella sezione precedente.
Sarebbe meglio mettere la linea precedente come prima linea di /boot/loader.rc in modo da vedere i messaggi sulla console seriale il prima possibile.
Altrimenti, puoi specificare la console interna come:
set console="vidconsole"
Se non imposti la variabile di ambiente console del loader, quest’ultimo, e conseguentemente anche il kernel, useranno una console qualunque indicata dall’opzione -h nel blocco di avvio.
Nelle versioni 3.2 o successive, è possibile specificare la console in /boot/loader.conf.local o /boot/loader.conf, piuttosto che in /boot/loader.rc. Con questo metodo il tuo /boot/loader.rc dovrebbe apparire così:
include /boot/loader.4th start
Poi, crea /boot/loader.conf.local ed aggiungi lì la linea seguente.
console=comconsole
o
console=vidconsole
Guarda loader.conf(5) per maggiori informazioni.
Al momento il loader non ha un’opzione equivalente alla |
Sarà necessario ricompilare il loader per usare una porta seriale differente da sio0 per la console seriale. Segui la procedura descritta nella Utilizzo di una Porta Seriale Differente da sio0 per la Console.
L’idea di tutto questo è di permettere alla gente di mettere su server dedicati che non abbiano bisogno di hardware grafico o di tastiere. Sfortunatamente, mentre la maggior parte dei sistemi ti permetteranno di avviare senza tastiera, ce ne sono alcuni che non ti permetteranno di partire senza un adattatore grafico. Le macchine con BIOS AMI possono essere configurate per partire senza adattatori grafici cambiando semplicemente il valore di "graphics adapter" nella configurazione CMOS a "Not installed".
Ad ogni modo, molte macchine non supportano questa opzione e si rifiuteranno di avviarsi se non si ha hardware grafico nel sistema. Con queste macchine, avrai bisogno di lasciare un qualche tipo di scheda grafica attaccata, (anche una scheda monocromatica di recupero) sebbene non avrai necessità di collegare un monitor. Potresti anche tentare di installare un BIOS AMI.
La "Posta Elettronica", meglio conosciuta come email, è una delle forme di comunicazione maggiormente utilizzate tutt’oggi. Questo capitolo fornisce un’introduzione di base per eseguire un server di posta su FreeBSD, come pure un’introduzione per inviare e ricevere la posta elettronica usando FreeBSD comunque, questo non è un riferimento completo e infatti molte considerazioni importanti sono omesse. Per coprire questo argomento in modo più completo, si rimanda il lettore alla moltitudine di eccellenti libri elencati nell’Bibliografia.
Dopo aver letto questo capitolo, saprai:
Quali componenti software vengono coinvolti nell’invio e nella ricezione della posta elettronica.
Dove sono collocati in FreeBSD i file di configurazione fondamentali di sendmail.
Le differenze tra casella di posta remota e locale.
Come impedire agli spammer di usare illegalmente il tuo server di posta come un relay.
Come installare e configurare un mail transfer agent alternativo sul tuo sistema, sostituendo sendmail.
Come risolvere i problemi più frequenti legati al server di posta.
Come usare SMTP con UCCP.
Come configurare il sistema solo per inviare la posta.
Come usare la posta con una connessione dialup.
Come configurare l’Autenticazione SMTP per aumentare la sicurezza.
Come installare e usare un Mail User Agent (MUA), come mutt per inviare e ricevere la posta.
Come scaricare la tua posta da un server remoto POP o IMAP.
Come applicare in modo automatico filtri e regole sulla posta in entrata.
Prima di leggere questo capitolo, dovresti:
Aver configurato correttamente la tua connessione di rete (Networking Avanzato).
Aver configurato correttamente le informazioni DNS relative alla tua macchina server di posta (Servizi di Rete).
Sapere come installare software aggiuntivo di terze parti (Installazione delle Applicazioni. Port e Package).
Ci sono cinque parti principali impegnate in uno scambio di email. Queste sono: il programma client, quello server, il DNS, una casella di posta remota o locale, e naturalmente la macchina server di posta.
Questo include programmi a riga di comando quali mutt, pine, elm, e mail, e programmi con un’interfaccia grafica (GUI) quali balsa, xfmail per citarne alcuni, e qualcosa di più "raffinato" simile a un browser WWW. Questi programmi semplicemente fanno passare le transazioni email alla "macchina server di posta" locale, chiamando uno dei programmi server disponibili o inoltrando queste transazioni via TCP.
FreeBSD incorpora di default sendmail, ma supporta anche altri programmi server di posta elettronica, alcuni dei quali sono:
exim;
postfix;
qmail.
Di solito il programma server svolge due funzioni-si occupa di ricevere la posta in arrivo e di consegnare quella in partenza. Questo programma non permette di prelevare la posta usando protocolli come POP o IMAP, ne tanto meno di "collegarsi" alle caselle di posta locali mbox o di tipo Maildir. Per far questo hai bisogno di un altro demone.
Vecchie versioni di sendmail contengono alcuni seri problemi di sicurezza che possono dare la possibilità ad un attaccante di guadagnarsi un accesso locale e/o remote sulla tua macchina. Assicurati di eseguire una versione aggiornata per evitare questi problemi. In alternativa, installa un altro MTA dalla FreeBSD Ports Collection. |
Il DNS (Domain Name System) e il suo demone named giocano un ruolo fondamentale nella consegna della posta. Per consegnare la posta dal tuo host a un altro, il programma server cercherà l’host remoto nel DNS per determinare la macchina server che riceverà la posta per il destinatario. Lo stesso processo avviene quando un host remoto invia dei messaggi di posta alla tua macchina server di posta.
Il DNS è responsabile della corrispondenza tra nomi host ed indirizzi IP, e memorizza anche informazioni specifiche per la consegna della posta, informazioni conosciute come record MX. Il record MX (Mail eXchanger) specifica quale/i host dovranno ricevere la posta per un particolare dominio. Se non hai un record MX per il tuo nome host o per il tuo dominio, la posta sarà consegnata direttamente al tuo host a condizione di avere un record A che mappa il tuo nome host al tuo indirizzo IP.
Puoi vedere i record MX per un dominio usando il comando host(1), come mostrato nel seguente esempio:
% host -t mx FreeBSD.org
FreeBSD.org mail is handled (pri=10) by mx1.FreeBSD.orgLa ricezione della posta per il tuo dominio viene gestita dalla macchina server di posta. Questa raccoglierà la posta indirizzata al tuo dominio e la salverà nel formato mbox (metodo per la memorizzazione della posta di default) o Maildir, a seconda delle tua configurazione. Una volta memorizzata, la posta può essere sia letta in modo locale usando applicazioni come mail(1) o mutt, sia prelevata in modo remoto usando protocolli come POP e IMAP. Ciò significa che se vuoi solo leggere la posta localmente, non hai bisogno di installare un server POP o IMAP.
Per accedere a caselle di posta in modo remoto, devi avere l’accesso a un server POP o IMAP. Questi protocolli permettono agli utenti di collegarsi con facilità alle loro caselle di posta da locazioni remote. Benchè sia POP che IMAP permettono agli utenti di accedere alle caselle di posta in modo remoto, IMAP offre alcuni vantaggi, alcuni dei quali sono:
IMAP può memorizzare e prelevare i messaggi di posta su un server remoto.
IMAP supporta aggiornamenti simultanei.
IMAP può essere estremamente utile con connessioni lente poichè permette agli utenti di prelevare la struttura dei messaggi senza scaricarli completamente; può inoltre realizzare compiti come la ricerca su un server al fine di minimizzare il trasferimento dei dati tra client e server.
Per installare un server POP o IMAP, devi seguire i seguenti passi:
Scegli un server IMAP o POP che meglio soddisfa le tue necessità. I seguenti server POP e IMAP sono ben noti e si prestano come degli ottimi esempi:
qpopper;
teapop;
imap-uw;
courier-imap;
Installa il demone POP o IMAP di tua scelta dalla collezione dei port.
Se necessario, modifica il file /etc/inetd.conf per avviare il server POP o IMAP.
Nota che sia POP che IMAP trasmettono informazioni, inclusi il nome utente e la password in chiaro. Ciò significa che se vuoi mettere al sicuro la trasmissione di informazioni su questi protocolli, potresti considerare di effettuare tunnel di sessioni con ssh(1). La creazione di tunnel di sessioni è descritta nella SSH Tunneling. |
Si può accedere localmente alla casella di posta utilizzando un MUA sul server nel quale risiede la casella di posta. Questo può essere fatto usando applicazioni come mutt o mail(1).
sendmail(8) è il Mail Transfer Agent (MTA) di default su FreeBSD. Il compito di sendmail è di accettare posta dai Mail User Agent (MUA), e consegnarla al server di posta appropriato come definito nel suo file di configurazione. Inoltre sendmail può accettare connessioni via rete e consegnare i messaggi a caselle di posta locali o ad un altro programma.
sendmail utilizza i seguenti file di configurazione:
| File | Funzione |
|---|---|
/etc/mail/access | File database di accesso di sendmail |
/etc/mail/aliases | Alias delle caselle di posta |
/etc/mail/local-host-names | Lista di host per i quali sendmail accetta posta |
/etc/mail/mailer.conf | File di configurazione del programma di posta |
/etc/mail/mailertable | Tabella di consegna del programma di posta |
/etc/mail/sendmail.cf | File di configurazione principale di sendmail |
/etc/mail/virtusertable | Tabelle degli utenti e dei domini virtuali |
Il database di accesso definisce quali host o indirizzi IP hanno accesso al server di posta locale e quale tipo di accesso hanno. Gli host possono essere catalogati come OK, REJECT, RELAY o possono semplicemente essere passati alla procedura di gestione degli errori di sendmail con un preciso errore. Gli host che sono definiti OK, che è il valore di default, possono spedire posta a questo host sempre che la destinazione finale della posta sia la macchina locale. Gli host che sono definiti REJECT vengono rifiutati per qualsiasi connessione di posta. Gli host che hanno l’opzione RELAY per i loro nomi host possono utilizzare questo server per spedire posta verso qualsiasi destinazione.
cyberspammer.com 550 Non accettiamo posta dagli spammer FREE.STEALTH.MAILER@ 550 Non accettiamo posta dagli spammer altra.sorgente.di.spam REJECT okay.cyberspammer.com OK 128.32 RELAY
In questo esempio abbiamo cinque elementi. Gli host mittenti che corrispondono a quelli posti sul lato sinistro della tabella sono condizionati dall’azione posta sul lato destro della tabella. I primi due esempi passano un codice di errore alla procedura di sendmail che gestisce gli errori. Il messaggio viene restituito all’host remoto quando viene trovata una corrispondenza sul lato sinistro della tabella. Il terzo esempio rifiuta la posta da un host specifico su Internet, altra.sorgente.di.spam. Il quarto esempio accetta connessioni di posta da un host, okay.cyberspammer.com, che è più preciso rispetto a cyberspammer.com della prima linea. Le corrispondenze più precise sovrascrivono quelle meno precise. L’ultimo esempio permette il relay della posta elettronica agli host che hanno un indirizzo IP che inizia con 128.32. Questi host possono spedire messaggi destinati ad altri server di posta attraverso questo server.
Quando modifichi questo file, devi eseguire make in /etc/mail/ per aggiornare il database.
Il database degli alias contiene una lista di caselle di posta virtuali che sono espanse in altri utenti, file, programmi o in altri alias. Seguono alcuni esempi che possono essere usati in /etc/mail/aliases:
root: utentelocale ftp-bugs: joe,eric,paul bit.bucket: /dev/null procmail: "|/usr/local/bin/procmail"
Il formato del file è semplice: il nome della casella di posta che si trova a sinistra dei due punti viene espanso negli elementi posti a destra dei due punti. Il primo esempio semplicemente espande la casella di posta root nella casella di posta utentelocale, che è di nuovo ricercata nel database degli alias. Se non viene trovata, allora il messaggio viene consegnato all’utente locale utentelocale. L’esempio successivo mostra una mailing list. La posta indirizzata alla casella di posta ftp-bugs viene espansa nelle tre caselle di posta locali joe, eric, e paul. Nota che una casella di posta remota può essere specificata come user@example.com. Il terzo esempio mostra come scrivere la posta su un file, in questo caso /dev/null. L’ultimo esempio mostra come mandare la posta a un programma, in questo caso il messaggio di posta diventa lo standard input di /usr/local/bin/procmail tramite una pipe UNIX®.
Quando modifichi questo file, devi eseguire make in /etc/mail/ per aggiornare il database.
Questo file è una lista di nomi host che sendmail(8) accetta come se fossero l’host locale. Metti i domini o gli host per i quali sendmail deve ricevere posta. Per esempio, se questo server di posta dovesse essere in grado di accettare posta per il dominio example.com e per l’host mail.example.com, il suo local-host-names potrebbe assomigliare a questo:
example.com mail.example.com
Quando modifichi questo file, devi riavviare sendmail(8) per attivare i cambiamenti.
Il file di configurazione principale di sendmail, sendmail.cf controlla l’intero comportamento di sendmail, inclusa ogni cosa, dalla rielaborazione degli indirizzi e-mail alla stampa del messaggio di rifiuto per i server di posta remoti. Naturalmente, avendo svariati compiti, questo file di configurazione è alquanto complesso e i suoi dettagli vanno oltre lo scopo di questa sezione. Fortunatamente, questo file necessita raramente di essere modificato per server di posta standard.
Il file di configurazione principale di sendmail può essere costruito a partire da macro m4(1) che definiscono le caratteristiche e il comportamento di sendmail. Guarda /usr/src/contrib/sendmail/cf/README per ulteriori dettagli.
Quando modifichi questo file, devi riavviare sendmail(8) per attivare i cambiamenti.
Il file virtusertable mappa indirizzi di posta relativi a domini e caselle di posta virtuali in caselle di posta reali. Queste caselle di posta possono essere locali, remote, alias definiti in /etc/mail/aliases o file.
root@example.com root postmaster@example.com postmaster@noc.example.net @example.com joe
Nell’esempio precedente, abbiamo una mappatura per il dominio example.com. Questo file viene processato dall’alto verso il basso fermandosi alla prima corrispondenza trovata. Il primo elemento mappa root@example.com nella casella di posta locale root. Il secondo elemento mappa postmaster@example.com nella casella di posta postmaster sull’host noc.example.net. Infine, se non sono state trovate corrispondenze per example.com fino a questo punto, verrà verificata l’ultima mappatura, che corrisponde a tutti gli altri messaggi di posta indirizzati a qualche utente di example.com. Questo verrà mappato nella casella di posta locale joe.
Come già menzionato, l’MTA (Mail Transfer Agent, agente di trasferimento della posta elettronica) installato di default su FreeBSD è sendmail. Di conseguenza sendmail è responsabile della tua posta in partenza e di quella in arrivo.
Comunque, per vari motivi, alcuni amministratori necessitano di cambiare l’MTA dei loro sistemi. Questi motivi spaziano dal voler semplicemente provare un altro MTA all’aver bisogno di una caratteristica o di un pacchetto specifico ritrovabile in un altro MTA. Fortunatamente, per qualsiasi motivo, FreeBSD semplifica il processo di sostituzione.
Hai un’ampia scelta di MTA utilizzabili. Un buon punto di partenza è la FreeBSD Ports Collection dove puoi trovarne molti. Naturalmente sei libero di usare qualunque MTA proveniente da qualche sito, a condizione che tu riesca ad eseguirlo sotto FreeBSD.
Inizia installando il tuo nuovo MTA. Una volta installato devi valutare se realmente soddisfa le tue necessità, inoltre devi avere la possibilità di configurare il tuo nuovo programma prima che subentri a sendmail. Valutato questo, devi essere sicuro che durante l’installazione del nuovo programma non ci siano stati tentativi di sovrascrivere binari di sistema come /usr/bin/sendmail. Altrimenti, il tuo nuovo programma di posta è stato essenzialmente messo in attività prima che tu l’abbia configurato.
Per cortesia fai riferimento alla documentazione dell’MTA che hai scelto per informazioni su come configurarlo.
La procedura usata per avviare sendmail cambia significativamente tra la 4.5-RELEASE e la 4.6-RELEASE. Di conseguenza, la procedura usata per disabilitarlo è leggermente differente a seconda della versione di FreeBSD utilizzata.
Se disabiliti il servizio di consegna della posta di sendmail in questo modo, è importante che questo venga rimpiazzato con un altro sistema di consegna della posta. Se non lo farai, le funzioni di sistema come periodic(8) saranno incapaci di inviare i loro risultati tramite e-mail come normalmente prevedono di fare. Molte parti del tuo sistema potrebbero presupporre di avere un sistema funzionante compatibile con sendmail. Se le applicazioni continuano a usare i binari di sendmail per tentare di spedire e-mail dopo che tu l’hai disabilitato, la posta potrebbe finire in una coda inattiva di sendmail, senza che venga mai consegnata. |
Metti:
sendmail_enable="NO"
in /etc/rc.conf. In questo modo si disabiliterà il servizio di ricezione della posta di sendmail, ma se /etc/mail/mailer.conf (vedi sotto) non viene modificato, sendmail verrà ancora usato per spedire e-mail.
Per disabilitare completamente sendmail, incluso il servizio della posta in uscita, devi mettere
sendmail_enable="NONE"
in /etc/rc.conf.
Se vuoi solamente disabilitare il servizio di ricezione della posta di sendmail, devi mettere
sendmail_enable="NO"
in /etc/rc.conf. Comunque, se la ricezione della posta è disabilitata, la consegna locale funzionerà ancora. Maggiori informazioni sulle opzioni di avvio di sendmail sono disponibili nella pagina man di rc.sendmail(8).
Per disabilitare completamente sendmail, servizi di posta in ingresso e in uscita inclusi, devi usare
sendmail_enable="NO" sendmail_submit_enable="NO" sendmail_outbound_enable="NO" sendmail_msp_queue_enable="NO"
in /etc/rc.conf.
Se vuoi solamente disabilitare il servizio di ricezione della posta di sendmail, devi mettere
sendmail_enable="NO"
in /etc/rc.conf. Molte informazioni sulle opzioni di avvio di sendmail sono disponibili nella pagina man di rc.sendmail(8).
Hai due possibili metodi per eseguire il tuo nuovo MTA all’avvio, a seconda della versione di FreeBSD utilizzata.
Posiziona uno script in /usr/local/etc/rc.d/ con estensione .sh ed eseguibile da root. Lo script deve accettare i parametri start e stop. Nella fase di avvio di FreeBSD gli script di sistema eseguiranno il comando
/usr/local/etc/rc.d/supermailer.sh start
che puoi anche usare per avviare manualmente il server. Nella fase di chiusura di FreeBSD, gli script di sistema useranno l’opzione stop, eseguendo il comando
/usr/local/etc/rc.d/supermailer.sh stop
che puoi anche usare per arrestare manualmente il server mentre il sistema è in funzione.
Con le versioni recenti di FreeBSD, puoi usare il metodo precedente oppure puoi mettere
mta_start_script="nomefile"
in /etc/rc.conf, dove nomefile è il nome dello script che vuoi eseguire all’avvio per avviare il tuo MTA.
sendmail è così onnipresente come programma standard su sistemi UNIX® che alcuni programmi lo suppongono già installato e configurato. Per questa ragione, molti degli altri MTA forniscono la loro compatibile implementazione dell’interfaccia a riga di comando di sendmail; questo agevola il loro utilizzo come sostituti "drop-in" di sendmail.
Quindi, se usi un altro programma di posta, dovrai assicurarti che i programmi che tentano di eseguire i binari standard di sendmail come /usr/bin/sendmail in realtà eseguano il programma di posta da te scelto. Fortunatamente, FreeBSD fornisce un meccanismo chiamato mailwrapper(8) che fa questo lavoro per te.
Quando sendmail è operativo, dovresti vedere in /etc/mail/mailer.conf qualcosa di simile a questo:
sendmail /usr/libexec/sendmail/sendmail send-mail /usr/libexec/sendmail/sendmail mailq /usr/libexec/sendmail/sendmail newaliases /usr/libexec/sendmail/sendmail hoststat /usr/libexec/sendmail/sendmail purgestat /usr/libexec/sendmail/sendmail
Questo significa che quando uno di questi comandi (come sendmail stesso) viene eseguito, in realtà il sistema invoca una copia di mailwrapper di nome sendmail, la quale esamina mailer.conf ed esegue /usr/libexec/sendmail/sendmail. Questo meccanismo facilita la sostituzione dei binari che sono realmente eseguiti quando vengono invocate queste funzioni di default di sendmail.
Quindi se vuoi che /usr/local/supermailer/bin/sendmail-compat sia eseguito al posto di sendmail, devi modificare /etc/mail/mailer.conf in questo modo:
sendmail /usr/local/supermailer/bin/sendmail-compat send-mail /usr/local/supermailer/bin/sendmail-compat mailq /usr/local/supermailer/bin/mailq-compat newaliases /usr/local/supermailer/bin/newaliases-compat hoststat /usr/local/supermailer/bin/hoststat-compat purgestat /usr/local/supermailer/bin/purgestat-compat
Una volta che hai configurato ogni cosa a tuo piacimento, devi terminare i processi di sendmail di cui non hai più bisogno e avviare i processi appartenenti al tuo nuovo programma, oppure puoi semplicemente riavviare il sistema. Riavviando il sistema avrai la possibilità di verificare se il sistema sia stato configurato correttamente per eseguire il tuo nuovo MTA in modo automatico all’avvio.
Probabilmente ti accorgerai che l’host è effettivamente in un dominio differente; per esempio, se sei in foo.bar.edu e desideri raggiungere un host chiamato mumble appartenente al dominio bar.edu, dovrai riferirti a questo tramite un nome di dominio completo, mumble.bar.edu, invece del solo mumble.
Tradizionalmente, questo era permesso dai resolver BIND di BSD. Tuttavia la versione corrente di BIND equipaggiata con FreeBSD non prevede più l’abbreviazione di default per nomi di dominio non completi all’infuori del dominio in cui sei. Quindi l’host mumble sarà giudicato come mumble.foo.bar.edu, oppure sarà ricercato per il dominio radice.
Questo differisce dal comportamento precedente, dove la ricerca continuava attraverso mumble.bar.edu, e mumble.edu. Dai un’occhiata all’RFC 1535 per i motivi per cui questa sia considerata una cattiva pratica, o persino un buco di sicurezza.
Come buona soluzione al problema, puoi mettere la linea:
search foo.bar.edu bar.edu
al posto della precedente:
domain foo.bar.edu
nel tuo /etc/resolv.conf. Comunque, assicurati che l’ordine di ricerca non oltrepassi il "confine tra amministrazione locale e pubblica", come definito nell’RFC 1535.
La risposta è contenuta nelle FAQ di sendmail come segue:
Ottengo messaggi di errore, come questo: 553 MX list for domain.net points back to relay.domain.net 554 <user@domain.net>... Local configuration error Come posso risolvere questo problema? Hai chiesto che la posta per il dominio (es., domain.net) sia inoltrata a un host specifico (in questo caso, relay.domain.net) attraverso l'uso di un record MXrecord MX, ma la macchina di inoltro non si riconosce appartenente a domain.net. Aggiungi domain.net in /etc/mail/local-host-names [chiamato /etc/sendmail.cw nelle versioni precedenti alla 8.10] (se stai usando FEATURE(use_cw_file)) oppure aggiungi Cw domain.net in /etc/mail/sendmail.cf.
Le FAQ di sendmail possono essere trovate su http://www.sendmail.org/faq/ ed è raccomandato leggerle se vuoi "perfezionare" la tua configurazione di posta.
Vuoi collegare ad Internet una macchina FreeBSD posta sulla tua LAN. La macchina FreeBSD sarà un gateway di posta per la LAN. La connessione PPP non è molto indicata per questo scopo.
Esistono almeno due modi per far questo. Un modo è usare UUCP.
L’altro è trovare un server Internet a tempo pieno che fornisca un servizio MX secondario per il tuo dominio. Per esempio, se il dominio della tua società è example.com e il tuo fornitore di servizi Internet ha attivato example.net per fornire il servizio MX secondario al tuo dominio, allora:
example.com. MX 10 example.com.
MX 20 example.net.Solo un host deve essere specificato come ultimo ricevente (aggiungi Cw example.com in /etc/mail/sendmail.cf su example.com).
Quando sendmail tenterà di consegnare la posta proverà a connettersi alla tua connessione modem (example.com). Molto probabilmente finirà in time out poiché non sei online. In modo automatico sendmail consegnerà la posta al server MX secondario, ad esempio il tuo provider Internet (example.net). Il server MX secondario tenterà periodicamente di collegarsi al tuo host per consegnare la posta all’host MX primario (example.com).
Come script di login potresti usare qualcosa di simile a questo:
#!/bin/sh # Mettimi in /usr/local/bin/pppmyisp ( sleep 60 ; /usr/sbin/sendmail -q ) & /usr/sbin/ppp -direct pppmyisp
Se hai intenzione di creare uno script di login separato per un utente potresti usare sendmail -qRexample.com nello script precedente. Questo forzerà a processare immediatamente tutta la posta per example.com situata nella tua coda.
Segue un’ulteriore sottigliezza della situazione:
Messaggio rubato dalla mailing list degli Internet Service Provider che usano FreeBSD.
> forniamo l'MX secondario per un cliente. Il cliente si connette > automaticamente ai nostri servizi molte volte al giorno per ottenere la > posta per il suo MX primario (non chiamiamo il suo server quando arriva > posta per il suo dominio). Il nostro sendmail processa la posta in coda > ogni 30 minuti. Attualmente il cliente sta 30 minuti online per assicurarsi > che tutta la posta vada all'MX primario. > > Esiste un comando che permetta di configurare sendmail in modo tale da > spedire tutta la posta in quel momento? Naturalmente l'utente non ha > privilegi di root sulla nostra macchina. Nella sezione privacy flags di sendmail.cf, c'è una definizione Opgoaway,restrictqrun Rimuovi restrictqrun per permettere a utenti non root di avviare l'elaborazione della coda. Inoltre potresti risistemare gli MX. Noi siamo l'MX primario per i nostri clienti come questo, e abbiamo definito: # Se siamo il miglior MX per un host, prova direttamente invece di generare # errori di configurazione locale. OwTrue In questo modo un server remoto consegnerà direttamente a te, senza tentare di connettersi al cliente. Dopodiché tu spedisci al tuo cliente. Funziona solamente con gli host, quindi hai bisogno che il tuo cliente chiami la sua macchina di posta customer.com così come nomehost.customer.com nel DNS. Basta mettere un record A nel DNS per customer.com.
Con l’installazione di default di FreeBSD, sendmail viene configurato in modo tale da permettere di spedire posta solamente dall’host sul quale è in esecuzione. Per esempio, se c’è installato un server POP, allora gli utenti saranno in grado di controllare la posta da scuola, dal lavoro, o da altre postazioni remote ma tuttavia non potranno inviare messaggi di posta all’esterno da postazioni esterne. Tipicamente, pochi istanti dopo il tentativo, verrà spedita una email da MAILER-DAEMON con il messaggio di errore 5.7 Relaying Denied.
Esistono diversi modi per aggirare questo problema. La soluzione più semplice è mettere il proprio indirizzo assegnato dall’ISP nel file che contiene i domini a cui viene permesso di effettuare il relay, /etc/mail/relay-domains. Un modo veloce per far questo può essere:
# echo "your.isp.example.com" > /etc/mail/relay-domainsDopo aver creato o modificato questo file devi riavviare sendmail. Questa soluzione è ideale se sei un amministratore del server e non desideri spedire posta localmente, o se vorresti usare un client/sistema punta e clicca su un’altra macchina o perfino su un altro ISP. Inoltre è molto utile se hai solo uno o due account di posta configurati. Se ci sono molti indirizzi da aggiungere, puoi semplicemente aprire questo file con il tuo editor di testo preferito e aggiungere i domini, uno per riga:
your.isp.example.com other.isp.example.net users-isp.example.org www.example.org
Ora l’invio della posta tramite il tuo sistema, da parte di qualche host in lista (a condizione che l’utente abbia un account sul tuo sistema), avrà successo. Questo è un buon metodo per permettere agli utenti di spedire posta dal tuo sistema in modo remoto senza dare la possibilità a qualcuno di spedire SPAM tramite il tuo sistema.
La seguente sezione tratta argomenti più complicati come l’organizzazione e la configurazione della posta per tutto il tuo dominio.
Dalla macchina FreeBSD, dovresti essere in grado di spedire posta a host esterni a condizione di aver sistemato /etc/resolv.conf o di avere in esecuzione un proprio server dei nomi. Se vuoi che la posta per il tuo host sia consegnata all’MTA (es., sendmail) in esecuzione sul tuo host FreeBSD, esistono due metodi per farlo:
Eseguire un proprio server dei nomi e avere un proprio dominio. Per esempio, FreeBSD.org
Ricevere la posta direttamente sul tuo host. Questo viene fatto consegnando la posta direttamente al nome DNS corrente della tua macchina. Per esempio, example.FreeBSD.org.
Indipendentemente dal metodo scelto, affinché la posta possa essere consegnata direttamente al tuo host, devi avere un indirizzo IP statico permanente (non un indirizzo dinamico, come avviene nella maggior parte delle configurazioni dial-up di PPP). Se sei dietro a un firewall, devi abilitare il traffico SMTP in entrata. Se vuoi ricevere la posta direttamente sul tuo host, devi verificare una di queste due cose:
Assicurati che il record MX (con il numero più basso) relativo al tuo host nel tuo DNS punti all’indirizzo IP del tuo host.
Assicurati che non ci siano record MX nel tuo DNS per il tuo host.
Entrambi questi due metodi ti permettono di ricevere posta direttamente sul tuo host.
Prova questi comandi:
# hostname
example.FreeBSD.org
# host example.FreeBSD.org
example.FreeBSD.org has address 204.216.27.XXSe ottieni un risultato simile, l’invio diretto a yourlogin@example.FreeBSD.org dovrebbe funzionare senza problemi (assumendo che sendmail sia correttamente in esecuzione su example.FreeBSD.org).
Se invece vedi qualcosa di simile a questo:
# host example.FreeBSD.org
example.FreeBSD.org has address 204.216.27.XX
example.FreeBSD.org mail is handled (pri=10) by hub.FreeBSD.orgTutta la posta spedita al tuo host (example.FreeBSD.org) finirà per essere raccolta su hub sotto lo stesso nome utente invece di essere spedita direttamente al tuo host.
L’informazione precedente viene gestita dal tuo server DNS. Il record DNS che riporta l’informazione di instradamento della posta è l’elemento Mail eXchange. Se non esistono record MX, la posta sarà consegnata direttamente all’host attraverso il suo indirizzo IP.
L’elemento MX per freefall.FreeBSD.org in passato assomigliava a questo:
freefall MX 30 mail.crl.net freefall MX 40 agora.rdrop.com freefall MX 10 freefall.FreeBSD.org freefall MX 20 who.cdrom.com
Come puoi vedere, freefall aveva molti elementi MX. Il numero MX più basso è l’host che, se disponibile, riceve direttamente la posta; se per qualche ragione questo non è accessibile, gli altri (qualche volta chiamati "MX di backup") accettano i messaggi temporaneamente, e li passano all’host attivo con numero inferiore, fino all’host con il numero più basso.
I server MX alternativi dovrebbero avere connessioni Internet indipendenti dalla propria al fine di risultare più utili. Il tuo ISP o un tuo amico non dovrebbero avere problemi a darti questo servizio.
Per organizzare un server di posta hai bisogno che la posta inviata alle stazioni di lavoro sia ricevuta direttamente sul server di posta. Sostanzialmente, hai bisogno di "richiedere" che la posta per i nomi host del tuo dominio (in questo caso *.FreeBSD.org) sia deviata al server di posta in modo tale che i tuoi utenti possono raccogliere la loro posta sul server di posta principale.
Per rendere la vita più facile, dovrebbe esistere su entrambe le macchine un account utente con lo stesso nome utente. Usa adduser(8) per farlo.
La macchina server di posta che utilizzerai deve essere designata come la macchina che scambia la posta per tutte le postazioni sulla rete. Questo viene realizzato attraverso la configurazione del DNS in modo simile a quanto segue:
example.FreeBSD.org A 204.216.27.XX ; Stazione di lavoro
MX 10 hub.FreeBSD.org ; Server di postaIn questo modo la posta per la stazione di lavoro sarà reindirizzata al server di posta senza preoccuparsi dove punti il record A. La posta viene inviata all’host MX.
Non puoi effettuare queste modifiche da solo a meno che non hai in esecuzione un tuo server DNS. Se non puoi eseguire un server DNS, consulta il tuo ISP o chiunque ti fornisca il servizio DNS.
Se stai facendo dell’hosting di posta elettronica virtuale, le seguenti informazioni ti torneranno utili. In questo esempio, assumiamo che hai un cliente con un proprio dominio, in questo caso customer1.org, e vuoi che tutta la posta per customer1.org sia spedita alla tua macchina server di posta mail.myhost.com. L’elemento nel tuo DNS dovrebbe assomigliare a questo:
customer1.org MX 10 mail.myhost.com
Non hai bisogno di un record A per customer1.org se vuoi solamente gestire la posta per tale dominio
Sii consapevole che un ping su |
L’ultima cosa che devi fare è indicare a sendmail, posto sulla tua macchina server, per quali domini e/o host deve accettare posta. Esistono differenti modi per farlo. I seguenti due funzionano entrambi:
Se usi FEATURE(use_cw_file) aggiungi gli host al tuo file /etc/mail/local-host-names. Se usi una versione di sendmail precedente alla 8.10, il file da usare è /etc/sendmail.cw.
Se usi la versione di sendmail 8.10 o superiore aggiungi la riga Cwyour.host.com al tuo /etc/sendmail.cf o /etc/mail/sendmail.cf.
La configurazione di sendmail di default su FreeBSD è designata per siti che si collegano direttamente a Internet. I siti che vogliono scambiarsi lo loro posta tramite UUCP devono installare un altro file di configurazione di sendmail.
Editare a mano il file /etc/mail/sendmail.cf è materia da esperti. La versione 8 di sendmail genera file di configurazione tramite la preelaborazione di m4(1), dove l’attuale configurazione avviene su un livello di astrazione più alto. I file di configurazione di m4(1) possono essere trovati sotto /usr/shared/sendmail/cf. Il file README nella directory cf può servire come introduzione di base alla configurazione di m4(1).
Il miglior modo per supportare la consegna UUCP è usare la caratteristica mailertable. Questa crea un database che sendmail può usare per prendere le decisioni di instradamento.
Prima di tutto, devi creare il tuo file .mc. La directory /usr/shared/sendmail/cf/cf contiene alcuni esempi. Assumendo che tu abbia chiamato il tuo file foo.mc, tutto quello che devi fare per convertirlo in un valido sendmail.cf è:
# cd /etc/mail
# make foo.cf
# cp foo.cf /etc/mail/sendmail.cfUn tipico file .mc potrebbe assomigliare a questo:
VERSIONID(`Il tuo numero di versione') OSTYPE(bsd4.4) FEATURE(accept_unresolvable_domains) FEATURE(nocanonify) FEATURE(mailertable, `hash -o /etc/mail/mailertable') define(`UUCP_RELAY', il.tuo.relay.uucp) define(`UUCP_MAX_SIZE', 200000) define(`confDONT_PROBE_INTERFACES') MAILER(local) MAILER(smtp) MAILER(uucp) Cw il.tuo.nome.host.alias Cw iltuonodouucp.UUCP
Le righe contenenti le caratteristiche accept_unresolvable_domains, nocanonify, and confDONT_PROBE_INTERFACES impediscono l’uso del DNS durante la consegna della posta. La clausola UUCP_RELAY è necessaria per supportare la consegna UUCP. Metti semplicemente un nome host di Internet che è in grado di gestire indirizzi di pseudo-domini .UUCP; molto probabilmente, metterai il relay del tuo ISP.
Una volta fatto questo, hai bisogno del file /etc/mail/mailertable. Se hai solo un collegamento per l’esterno che viene usato per tutta la tua posta, la seguente riga sarà sufficiente:
# # makemap hash /etc/mail/mailertable.db < /etc/mail/mailertable . uucp-dom:il.tuo.relay.uucp
Un esempio più complesso potrebbe essere simile a questo:
# # makemap hash /etc/mail/mailertable.db < /etc/mail/mailertable # horus.interface-business.de uucp-dom:horus .interface-business.de uucp-dom:if-bus interface-business.de uucp-dom:if-bus .heep.sax.de smtp8:%1 horus.UUCP uucp-dom:horus if-bus.UUCP uucp-dom:if-bus . uucp-dom:
Le prime tre righe gestiscono dei casi speciali dove la posta indirizzata a quel dominio non dovrebbe essere spedita tramite l’instradamento di default, ma piuttosto tramite alcuni UUCP di confine al fine di "accorciare" il percorso di consegna. La quarta riga gestisce la posta per il dominio Ethernet locale la quale può essere consegnata usando SMTP. Infine, gli UUCP di confine sono menzionati con la notazione a pseudo-dominio .UUCP, per permettere a un uucp-diconfine !destinatario di sovrascrivere le regole di default. L’ultima riga è sempre un singolo punto, a cui corrisponde ogni altra cosa e che rappresenta la consegna UUCP tramite l’UUCP di confine che viene usato come il tuo gateway di posta universale verso il mondo. Tutti i nomi dei nodi dietro alla parola uucp-dom: devono essere validi UUCP di confine, come puoi verificare usando il comando uuname.
Si ricorda che questo file deve essere convertito in un file database DBM prima di essere usato. La riga di comando che realizza ciò è messa come un commento in cima al file mailertable. Devi sempre eseguire quel comando ogni volta che modifichi il file mailertable.
Ultimo suggerimento: se non sei sicuro che alcuni instradamenti di posta potrebbero funzionare, ricordati l’opzione -bt di sendmail. Questa avvia sendmail in modalità test indirizzo; digita semplicemente 3,0, seguito dall’indirizzo su cui vuoi verificare l’instradamento della posta. L’ultima riga ti informa quale agente di posta interno è stato utilizzato, quale host di destinazione questo agente contatterà, e l’indirizzo (molto probabilmente tradotto). Lascia questa modalità digitando Ctrl+D.
% sendmail -bt
ADDRESS TEST MODE (ruleset 3 NOT automatically invoked)
Enter <ruleset> <address>
> 3,0 foo@example.com
canonify input: foo @ example . com
...
parse returns: $# uucp-dom $@ your.uucp.relay $: foo < @ example . com . >
> ^DEsistono molti casi in cui vorresti avere la possibilità di inviare la posta attraverso un relay. Alcuni esempi sono:
Il tuo computer è una macchina desktop, tuttavia vorresti essere in grado di usare programmi come send-pr(1). Per fare ciò, dovresti usare il relay di posta del tuo ISP.
Il computer è un server che non gestisce localmente la posta, ma demanda la gestione di tutta la posta ad un relay inoltrandola in modo opportuno.
La maggior parte degli MTA sono in grado di soddisfare questa particolare richiesta. Sfortunatamente, configurare in modo opportuno un MTA standard affinchè permetta solo l’inoltro della posta può essere un compito molto oneroso. Usare applicazioni come sendmail e postfix per questo fine risulta spesso troppo eccessivo.
Inoltre, alcuni servizi di accesso a Internet prevedono nel contratto l’impossibilità da parte del cliente di usare un "server di posta".
Il modo più facile per colmare questa necessità è installare il port mail/ssmtp. Esegui i seguenti comandi come root:
# cd /usr/ports/mail/ssmtp
# make install replace cleanUna volta installato, il port mail/ssmtp può essere configurato con quattro righe nel file /usr/local/etc/ssmtp/ssmtp.conf:
root=il_tuo_indirizzo_di_posta_reale mailhub=mail.esempio.com rewriteDomain=esempio.com hostname=_HOSTNAME_
Assicurati di usare il tuo indirizzo di posta per la variabile root. Inserisci il server di posta di inoltro del tuo ISP al posto di mail.esempio.com (alcuni ISP lo chiamano come il "server di posta in uscita" o il "server SMTP").
Assicurati di disabilitare sendmail, incluso il servizio di posta in uscita. Guarda la Disabilitazione di sendmail per maggiori dettagli.
Il port mail/ssmtp ha altre opzioni disponibili. Guarda il file di configurazione di esempio /usr/local/etc/ssmtp e la pagina man di ssmtp per alcuni esempi e maggiori informazioni.
Configurando ssmtp in questo modo permetterai ai programmi sul tuo computer che necessitano di spedire posta di funzionare correttamente, senza violare le politiche del tuo ISP e senza permettere che il tuo computer sia utilizzato per l’inoltro di spam.
Se hai un indirizzo IP statico, non hai bisogno di adattare nulla alla configurazione di default. Imposta come nome host il nome Internet che ti è stato assegnato e sendmail farà il resto.
Se hai un indirizzo IP assegnato in modo dinamico e usi una connessione PPP dialup per Internet, allora probabilmente avrai una casella di posta sul server di posta del tuo ISP. Assumiamo che il dominio del tuo ISP sia example.net, che il tuo nome utente sia user, che hai chiamato la tua macchina bsd.home, e che il tuo ISP ti ha detto che puoi usare relay.example.net come relay per la posta.
Per ricevere la posta dalla tua casella, devi installare un agente di ricupero. L’utility fetchmail è una buona scelta poichè supporta diversi tipi di protocolli. Questo programma è disponibile come package o dalla collezione dei port (mail/fetchmail). Di solito, il tuo ISP fornirà POP. Se stai usando PPP a livello utente, puoi prelevare automaticamente la tua posta quando viene stabilita una connessione a Internet mettendo la seguente riga in /etc/ppp/ppp.linkup:
MYADDR: !bg su user -c fetchmail
Se stai usando sendmail (come mostrato sotto) per consegnare posta ad account non locali, probabilmente vorrai che sendmail processi la tua coda di posta non appena viene stabilita una connessione ad Internet. Per far questo, metti il seguente comando dopo il comando fetchmail in /etc/ppp/ppp.linkup.
!bg su user -c "sendmail -q"
Assumiamo che tu abbia un account per user su bsd.home. Nella directory home di user su bsd.home, crea il file .fetchmailrc così composto:
poll example.net protocol pop3 fetchall pass MySecret
Questo file non dovrebbe essere leggibile da nessuno ad eccezione di user poichè contiene la password MySecret.
Per spedire la posta con il corretto header from:, devi indicare a sendmail di usare user@example.net piuttosto che user@bsd.home. Inoltre vorrai indicare a sendmail di spedire tutta la posta tramite relay.example.net, permettendo una veloce trasmissione della posta.
Il seguente file .mc dovrebbe essere sufficiente:
VERSIONID(`bsd.home.mc version 1.0') OSTYPE(bsd4.4)dnl FEATURE(nouucp)dnl MAILER(local)dnl MAILER(smtp)dnl Cwlocalhost Cwbsd.home MASQUERADE_AS(`example.net')dnl FEATURE(allmasquerade)dnl FEATURE(masquerade_envelope)dnl FEATURE(nocanonify)dnl FEATURE(nodns)dnl define(`SMART_HOST', `relay.example.net') Dmbsd.home define(`confDOMAIN_NAME',`bsd.home')dnl define(`confDELIVERY_MODE',`deferred')dnl
Fai riferimento alla precedente sezione per i dettagli su come trasformare questo file .mc nel file sendmail.cf. Inoltre, non dimenticarti di riavviare sendmail dopo aver aggiornato il file sendmail.cf.
Avere un’Autenticazione SMTP operativa sul tuo server di posta porta numerosi benefici. L’Autenticazione SMTP aggiunge un ulteriore strato di sicurezza a sendmail, e ha il vantaggio di dare agli utenti mobili che cambiano host la possibilità di usare lo stesso server di posta senza avere la necessità di riconfigurare ogni volta i settaggi dei loro programmi client di posta.
Installa dai port security/cyrus-sasl2. Puoi trovare questo port in security/cyrus-sasl2. Il port security/cyrus-sasl2 ha diverse opzioni di compilazione. Per il metodo di autenticazione SMTP che useremo, assicurati che l’opzione LOGIN non sia disabilitata.
Dopo aver installato security/cyrus-sasl2, edita /usr/local/lib/sasl2/Sendmail.conf (o crealo se non esiste) e aggiungi la seguente riga:
pwcheck_method: saslauthd
Quindi, installa security/cyrus-sasl2-saslauthd, edita /etc/rc.conf aggiungendo la riga seguente:
saslauthd_enable="YES"
ed infine avvia il demone saslauthd:
# /usr/local/etc/rc.d/saslauthd startQuesto demone serve come mediatore con sendmail per autenticare gli utenti tramite il proprio database passwd di FreeBSD. Questo procedimento evita di creare un nuovo set di nomi utenti e password per ogni utente che necessita di usare l’autenticazione SMTP, mantenendo la password di login uguale alla password di posta.
Ora aggiungi le seguenti righe in /etc/make.conf:
SENDMAIL_CFLAGS=-I/usr/local/include/sasl -DSASL SENDMAIL_LDFLAGS=-L/usr/local/lib SENDMAIL_LDADD=-lsasl2
Queste righe daranno, in fase di compilazione di sendmail, le giuste opzioni di configurazione per linkare a cyrus-sasl2. Assicurati che cyrus-sasl2 sia installato prima di ricompilare sendmail.
Ricompila sendmail eseguendo i seguenti comandi:
# cd /usr/src/lib/libsmutil
# make cleandir && make obj && make
# cd /usr/src/lib/libsm
# make cleandir && make obj && make
# cd /usr/src/usr.sbin/sendmail
# make cleandir && make obj && make && make installSe /usr/src non ha subito enormi cambiamenti e se le librerie condivise di cui si ha bisogno sono disponibili, la compilazione di sendmail non dovrebbe avere problemi.
Dopo aver compilato e reinstallato sendmail, edita il tuo file /etc/mail/freebsd.mc (o qualunque altro file che usi come file .mc. Molti amministratori preferiscono usare, per unicità, l’output di hostname(1) come nome del file .mc). Aggiungi le seguenti righe:
dnl set SASL options TRUST_AUTH_MECH(`GSSAPI DIGEST-MD5 CRAM-MD5 LOGIN')dnl define(`confAUTH_MECHANISMS', `GSSAPI DIGEST-MD5 CRAM-MD5 LOGIN')dnl
Queste opzioni configurano i vari metodi che sendmail ha a disposizione per autenticare gli utenti. Se vuoi usare un metodo diverso da pwcheck, guarda la documentazione inclusa nel package.
Per finire, esegui make(1) in /etc/mail. Questo eseguirà il tuo nuovo file .mc e creerà un file .cf di nome freebsd.cf (o con il nome che hai usato per il file .mc). Quindi esegui il comando make install restart, che copierà il file in sendmail.cf, e riavvierà correttamente sendmail. Per maggiori informazioni su questa procedura, dovresti prendere come riferimento /etc/mail/Makefile.
Se tutto è andato per il verso giusto, dovresti essere in grado di inviare un messaggio di prova dopo aver inserito le informazioni di login nel programma client di posta. Per ulteriori indagini, setta il LogLevel di sendmail a 13 e guarda il file /var/log/maillog per eventuali errori.
Per ulteriori informazioni, guarda la pagina riguardante l’autenticazione SMTP di sendmail.
Un Mail User Agent (MUA) è un’applicazione che viene usata per inviare e ricevere la posta elettronica. Man mano che la posta "evolve" e diventa più complessa, gli MUA diventano sempre più potenti nel modo in cui essi interagiscono con la posta elettronica; ciò fornisce agli utenti maggiori funzionalità e flessibilità. FreeBSD supporta svariati mail user agent, che possono essere facilmente installati usando la FreeBSD Ports Collection. Gli utenti possono scegliere tra client di posta con un’interfaccia grafica come evolution o balsa, client basati sulla console come mutt, pine e mail, oppure interfacce web utilizzate da alcune grandi organizzazioni.
mail(1) è il Mail User Agent (MUA) di default su FreeBSD. Si tratta di un MUA basato sulla console che offre tutte le funzionalità di base richieste per inviare e ricevere messaggi di posta testuali, anche se è limitato nelle capacità di gestione degli allegati, e può solo supportare caselle di posta locali.
Sebbene mail non supporta in modo nativo interazioni con server POP o IMAP, queste caselle di posta possono essere scaricate nel file mbox locale usando un’applicazione come fetchmail, che verrà discussa più tardi in questo capitolo (Usare fetchmail).
Al fine di inviare o ricevere la posta, invoca semplicemente il comando mail come nel seguente esempio:
% mailI contenuti delle caselle di posta degli utenti in /var/mail sono letti automaticamente dall’utility mail. Se la casella di posta è vuota, l’utility esce con un messaggio che indica che non è stato trovato nessun messaggio di posta. Una volta che la casella di posta è stata letta, viene avviata l’interfaccia dell’applicazione, e vengono visualizzati una lista di messaggi. I messaggi sono numerati in modo automatico, come nel seguente esempio:
Mail version 8.1 6/6/93. Type ? for help.
"/var/mail/marcs": 3 messages 3 new
>N 1 root@localhost Mon Mar 8 14:05 14/510 "test"
N 2 root@localhost Mon Mar 8 14:05 14/509 "user account"
N 3 root@localhost Mon Mar 8 14:05 14/509 "sample"I messaggi possono ora essere letti usando il comando t di mail, seguito dal numero del messaggio che si vuole visualizzare. In questo esempio, leggeremo il primo messaggio di posta:
& t 1
Message 1:
From root@localhost Mon Mar 8 14:05:52 2004
X-Original-To: marcs@localhost
Delivered-To: marcs@localhost
To: marcs@localhost
Subject: test
Date: Mon, 8 Mar 2004 14:05:52 +0200 (SAST)
From: root@localhost (Charlie Root)
Questo è un messaggio di prova, per favore rispondi se lo ricevi.Come puoi vedere nell’esempio precedente, il tasto t visualizza il messaggio completo di tutte le sue intestazioni (header). Per visualizzare ancora la lista dei messaggi, puoi usare il tasto h.
Se il messaggio di posta richiede una replica, puoi usare mail per rispondere, usando il tasto R o r di mail. Il tasto R dice a mail di rispondere solamente al mittente del messaggio, mentre r replica non solo al mittente, ma anche agli altri eventuali destinatari del messaggio originario. Puoi anche impartire quei comandi con un suffisso relativo al numero di messaggio per il quale intendi rispondere. Fatto ciò, inserisci la tua risposta, segnalando la fine del messaggio con un singolo punto (.) su una nuova linea. Ecco un esempio:
& R 1
To: root@localhost
Subject: Re: test
Thank you, I did get your email.
.
EOTPer inviare un nuovo messaggio, puoi usare il tasto m, seguito dall’indirizzo di posta elettronica del destinatario. Puoi specificare più destinatari separando ogni indirizzo da una virgola (,). Quindi si inserisce il soggetto del messaggio (il subject), seguito dal contenuto del messaggio stesso. La fine del messaggio deve essere specificata da un singolo punto (.) su una nuova linea.
& mail root@localhost
Subject: Ho imparato ad usare mail
Ora posso inviare e ricevere posta usando mail ... :)
.
EOTAnche se in mail, il comando ? può essere usato per invocare l’help in linea, la pagina man mail(1) dovrebbe essere consultata per ottenere maggiori informazioni.
Come menzionato in precedenza, il comando mail(1) non è stato originariamente progettato per gestire gli allegati, e quindi il supporto per essi è proprio misero. Nuovi MUA come mutt gestiscono gli allegati in un modo più intelligente. Tuttavia se desideri comunque usare il comando |
mutt è un Mail User Agent leggero ma molto potente, con caratteristiche eccellenti, alcune delle quali sono:
Abilità nella gestione di thread di messaggi;
Supporto PGP per la firma digitale e per criptare i messaggi di posta;
Supporto al MIME;
Supporto del formato Maildir;
Altamente personalizzabile.
Tutte queste caratteristiche fanno di mutt uno dei maggiori user agent avanzati oggi disponibili. Guarda http://www.mutt.org per maggiori informazioni su mutt.
La versione stabile di mutt può essere installata usando il port mail/mutt, mentre la versione corrente di sviluppo può essere installata tramite il port mail/mutt-devel. Una volta che il port è stato installato, mutt può essere avviato usando il seguente comando:
% muttmutt in modo automatico legge il contenuto della casella di posta dell’utente in /var/mail/ e ne visualizza il contenuto. Se non ci sono messaggi nella casella di posta dell’utente, allora mutt si mette in attesa di comandi da parte dell’utente. L’esempio qui sotto mostra mutt che visualizza una lista di messaggi:
Per leggere un messaggio, selezionalo usando i tasti cursore, e premi il tasto Invio. Segue un esempio di come mutt visualizza un messaggio:
Come con il comando mail(1), mutt permette agli utenti di rispondere al solo mittente del messaggio come pure a tutti i suoi destinatari. Per rispondere solo al mittente del messaggio, usa il tasto r. Per inviare una risposta di gruppo, che invierà la risposta sia al mittente originario sia a tutti i destinatari del messaggio, usa il tasto g.
mutt si serve del comando vi(1) come editor per la creazione o risposta dei messaggi di posta elettronica. Il tipo di editor può essere personalizzato dall’utente creando o editando il proprio file di configurazione .muttrc nella propria directory home e settando in modo opportuno la variabile |
Per comporre un nuovo messaggio, premi il tasto m. Dopo aver digitato un valido soggetto, mutt avvierà vi(1) con il quale comporre il corpo del messaggio. Fatto ciò, salvando e uscendo da vi, mutt visualizzarà una schermata riassuntiva del messaggio che sta per essere consegnato. Per inviare il messaggio, premi il tasto y. Segue un esempio di una schermata riassuntiva di un messaggio:
mutt contiene un ottimo help in linea, che può essere accessibile nella maggior parte dei menù digitando il tasto ?. Inoltre, in alcuni casi, nella parte superiore delle finestra vengono elencati i tasti funzioni principali.
pine è rivolto agli utenti novizi, tuttavia include alcune caratteristiche avanzate.
Il software pine ha avuto svariate vulnerabilità remote scoperte in passato, che permettevano ad attaccanti remoti di eseguire del codice arbitrario come se fossero degli utenti locali del sistema, tramite l’invio di un messaggio di posta preparato ad doc. Tutti questi noti problemi sono stati rattoppati, ma il codice di pine è stato scritto in un modo insicuro e il Servizio di Sicurezza di FreeBSD crede che probabilmente esistono altre vulnerabilità non ancora scoperte o divulgate. Installa pine a tuo rischio e pericolo. |
L’attuale versione di pine può essere installata usando il port mail/pine4. Una volta che il port è stato installato, pine può essere avviato con il comando seguente:
% pineLa prima volta che pine viene avviato viene visualizza una pagina di presentazione con una breve introduzione, e un sollecito del team di sviluppo di pine ad inviare un messaggio anonimo che permette di constatare quanti sono gli utenti che usano la loro applicazione. Per inviare questo messaggio anonimo, premi Invio, oppure premi il tasto E per uscire dalla presentazione senza inviare il messaggio anonimo. Ecco un esempio della pagina di presentazione:
All’utente viene quindi presentato il menù principale, che può essere facilmente esplorato con i tasti cursore. Questo menù principale fornisce le scorciatoie per comporre nuovi messaggi di posta, per esplorare le directory di posta e perfino per amministrare l’agenda degli indirizzi. Sotto al menù principale, sono mostrati i tasti funzione utili per realizzare azioni specifiche, attinenti all’attuale contesto d’uso.
La directory di default aperta da pine è inbox. Per visualizzare l’indice dei messaggi, premi il tasto I, o seleziona l’opzione come da esempio:
L’indice dei messaggi mostra i messaggi nella directory corrente, e può essere esplorato con i tasti cursore. I messaggi selezionati possono essere letti premendo il tasto Invio.
Nello screenshot seguente, viene visualizzato un semplice messaggio in pine. I tasti funzione sono visualizzati come riferimento nella parte superiore della finestra. Un esempio di uno di questi tasti funzioni è il tasto r, che dice al MUA di rispondere al messaggio attualmente visualizzato.
In pine la risposta ad un messaggio viene realizzata con l’editor pico, che è installato di default con pine. L’utility pico permette una semplice esplorazione del messaggio ed è più permissivo con i nuovi utenti rispetto a vi(1) o mail(1). Una volta completata la risposta, il messaggio può essere inviato con Ctrl+X. L’applicazione pine chiederà una conferma.
pine può essere personalizzato usando l’opzione del menù principale. Consulta http://www.washington.edu/pine/ per maggiori informazioni.
fetchmail è un client IMAP e POP super attrezzato che da la possibilità agli utenti di scaricare automaticamente la posta da server remoti IMAP e POP e di salvarla nelle proprie caselle di posta locali; in questo modo la posta è più accessibile. fetchmail può essere installato usando il port mail/fetchmail, e offre diverse caratteristiche, alcune delle quali sono:
Supporto dei protocolli POP3, APOP, KPOP, IMAP, ETRN e ODMR.
Capacità di inoltrare la posta usando SMTP, permettendo di filtrare, inoltrare, e usare la funzionalità alias come di consueto.
Può essere eseguito in modalità demone per verificare in modo periodico la presenza di nuovi messaggi.
Può recuperare più caselle di posta e inoltrare i relativi messaggi a diversi utenti locali, a seconda della sua configurazione.
Benchè la spiegazione di tutte le caratteristiche di fetchmail vada oltre lo scopo di questo documento, verranno presentate alcune funzionalità di base. fetchmail richiede un file di configurazione .fetchmailrc, al fine di poter essere avviato in modo corretto. Questo file include informazioni sui server come pure le credenziali per il login. Data la natura sensibile del contenuto di questo file, è consigliabile renderlo accessibile in sola lettura dal proprietario, usando il seguente comando:
% chmod 600 .fetchmailrcLa seguente configurazione di .fetchmailrc serve come esempio per scaricare una singola casella di posta usando POP. Essa indica a fetchmail di connettersi a example.com usando come nome utente joesoap e come password XXX. Questo esempio assume che l’utente joesoap è anche un utente del sistema locale.
poll example.com protocol pop3 username "joesoap" password "XXX"
Il prossimo esempio si connette a più server POP e IMAP e redirige i vari messaggi a diversi nomi utenti locali quando necessario:
poll example.com proto pop3: user "joesoap", with password "XXX", is "jsoap" here; user "andrea", with password "XXXX"; poll example2.net proto imap: user "john", with password "XXXXX", is "myth" here;
L’utility fetchmail può essere eseguita in modalità demone con l’opzione -d, seguita da un intervallo (in secondi) in base al quale fetchmail sonderà i server elencati nel file .fetchmailrc. Il seguente esempio indica a fetchmail di sondare i server ogni 600 secondi:
% fetchmail -d 600Maggiori informazioni su fetchmail possono essere trovate all’indirizzo http://fetchmail.berlios.de/.
L’utility procmail è un’applicazione molto potente usata per filtrare la posta in ingresso. Permette agli utenti di definire delle "regole" che sono confrontate con la posta in ingresso per realizzare funzioni specifiche o per inoltrare la posta ad una casella di posta alternativa e/o ad altri indirizzi di posta. procmail può essere installato usando il port mail/procmail. Una volta installato, può essere integrato direttamente nella maggior parte degli MTA; consulta la documentazione del tuo MTA per maggiori informazioni. Altrimenti, procmail può essere integrato aggiungendo la seguente linea nel file .forward nella home directory dell’utente, potendo così utilizzare le funzionalità di procmail:
"|exec /usr/local/bin/procmail || exit 75"
La seguente sezione mostra alcune regole base di procmail, così come una breve descrizione di ciò che fanno. Queste ed eventualmente altre regole, devono essere inserite nel file .procmailrc, posto nella home directory dell’utente.
La maggior parte di queste regole possono essere trovate anche nella pagina man di procmailex(5).
Per inoltrare la posta inviata da user@example.com all’indirizzo di posta goodmail@example2.com:
:0 * ^From.*user@example.com ! goodmail@example2.com
Per inoltrare tutti i messaggi di posta con dimensioni inferiori a 1000 bytes verso l’indirizzo di posta esterno goodmail@example2.com:
:0 * < 1000 ! goodmail@example2.com
Per inoltrare tutta la posta inviata a alternate@example.com in una casella di posta chiamata alternate:
:0 * ^TOalternate@example.com alternate
Per inviare tutti messaggi di posta con soggetto "Spam" in /dev/null:
:0 ^Subject:.*Spam /dev/null
Ecco una ricetta utile che analizza i messaggi di posta in ingresso delle liste di FreeBSD.org e li posiziona in base alla lista in una opportuna casella di posta:
:0
* ^Sender:.owner-freebsd-\/[^@]+@FreeBSD.ORG
{
LISTNAME=${MATCH}
:0
* LISTNAME??^\/[^@]+
FreeBSD-${MATCH}
}Questo capitolo coprirà alcuni dei servizi di rete usati più di frequente sui sistemi UNIX®. Fra gli argomenti toccati, ci saranno l’installazione, la configurazione, il test ed la manutenzione di molti tipi diversi di servizi di rete. Per vostro beneficio in tutto il capitolo saranno inclusi file di configurazione di esempio.
Dopo aver letto questo capitolo, sarai in grado di:
Gestire il demone inetd.
Installare un file system di rete.
Installare un server NIS per condividere account utenti.
Installare impostazioni automatiche di rete usando DHCP.
Installare un server di risoluzione dei nomi.
Installare il server HTTP Apache.
Installare un File Transfer Protocol (FTP) Server.
Installare un file server e server di stampa per client Windows® usando Samba.
Sincronizzare la data e l’ora ed installare un time server, col protocollo NTP.
Prima di leggere questo capitolo, dovresti:
Comprendere le basi dell’organizzazione degli scripts /etc/rc.
Avere familiarità con la terminologia di rete di base.
Sapere come installare software aggiuntivo di terze parti (Installazione delle Applicazioni. Port e Package).
inetd(8) viene talvolta definito l'"Internet Super-Server" perchè gestisce le connessioni verso molti servizi. Quando una connessione viene ricevuta da inetd, questo determina per quale programma la connessione sia destinata, esegue quel particolare processo e affida a lui la socket (il programma è invocato con la socket del servizio come descrittore di standard input, output ed error). Eseguire inetd per server dal carico non troppo alto può ridurre il carico complessivo di sistema, rispetto all’esecuzione individuale di ogni demone in modalità stand-alone.
Principalmente, inetd è usato per lanciare altri demoni, ma molti protocolli triviali sono gestiti direttamente, come ad esempio i protocolli chargen, auth, e daytime.
Questa sezione coprirà le basi della configurazione di inetd attraverso le opzioni da linea di comando ed il suo file di configurazione, /etc/inetd.conf.
inetd viene inizializzato attraverso il sistema rc(8). L’opzione inetd_enable è impostata a NO di default, ma può essere attivata da sysinstall durante l’installazione, a seconda della configurazione scelta dall’utente. Inserendo:
inetd_enable="YES"
o
inetd_enable="NO"
in /etc/rc.conf si abiliterà o meno la partenza di inetd al boot. Il comando:
# /etc/rc.d/inetd rcvarpuò essere utilizzato per mostrare le impostazioni attive al momento.
Inoltre, diverse opzioni di linea di comando possono essere passate a inetd attraverso l’opzione inetd_flags.
Come molti server di rete, inetd ha un numero di opzioni che possono essergli passate per modificare il suo comportamento. La lista di tutte le opzioni è:
inetd synopsis:
inetd [-d] [-l] [-w] [-W] [-c maximum] [-C rate] [-a address | hostname] [-p filename] [-R rate] [configuration file]
Si possono passare opzioni ad inetd usando l’opzione inetd_flags in /etc/rc.conf. Di default, inetd_flags è impostato a -wW -C 60, il che attiva il TCP wrapping per i servizi di inetd, ed impedisce ad ogni singolo indirizzo IP di richiedere qualsiasi servizio piùdi 60 volte al minuto.
Gli utenti novizi possono notare con piacere che questi parametri di solito non devono essere modificati, anche se bisogna menzionare il fatto che le opzioni di limitazione delle connessioni sono utili solo se ci si accorge di ricevere un numero eccessivo di connessioni. L’intera lista delle opzioni di inetd(8) può essere trovata nel manuale di inetd(8).
Specifica il numero massimo di invocazioni simultanee per ogni servizio; il default è illimitato. Può essere sovrascritto per ogni servizio dal parametro max-child.
Specifica un numero massimo di volte in cui un servizio può essere invocato da un singolo indirizzo IP in un minuto; il default è illimitato. Può essere sovrascritto per ogni servizio con il parametro max-connections-per-ip-per-minute.
Specifica il numero massimo di volte che un servizio può essere invocato in un minuto; il default è 256. L’impostazione 0 permette un numero illimitato di invocazioni.
Specifica il numero massimo di volte che un servizio può essere invocato per ogni periodo di tempo; il default è illimitato. Può essere sovrascritto per ogni singolo servizio con il parametro max-child-per-ip.
La configurazione di inetd è fatta attraverso il file /etc/inetd.conf.
Quando viene apportata una modifica a /etc/inetd.conf, si può forzare inetd a rileggere il suo file di configurazione eseguendo il comando:
# /etc/rc.d/inetd reloadOgni linea del file di configurazione specifica un singolo demone. I commenti nel file sono preceduti da un "#". Il formato di ogni riga del file /etc/inetd.conf è il seguente:
nome del servizio
tipo della socket
protocollo
{wait|nowait}[/max-child[/max-connections-per-ip-per-minute]]
utente[:gruppo][/classe-di-login]
programma-server
argomenti-del-programma-serverUn esempio di linea per il demone ftpd(8) usando l’IPv4:
ftp stream tcp nowait root /usr/libexec/ftpd ftpd -l
È il nome del servizio per il demone. Deve corrispondere ad un servizio elencato in /etc/services. Questo determina su quale porta inetd deve restare in ascolto. Se viene creato un nuovo servizio, deve essere messo prima in /etc/services.
Una a scelta fra stream, dgram, raw, o seqpacket. stream deve essere usata per demoni basati sulla connessione, tipo TCP, mentre dgram è usato per demoni che usano il protocollo di trasporto UDP.
Uno dei seguenti:
| Protocollo | Spiegazione |
|---|---|
tcp, tcp4 | TCP IPv4 |
udp, udp4 | UDP IPv4 |
tcp6 | TCP IPv6 |
udp6 | UDP IPv6 |
tcp46 | Entrambi TCP IPv4 e v6 |
udp46 | Entrambi UDP IPv4 e v6 |
wait|nowait indica se il demone invocato da inetd è in grado di gestire la sua socket o meno. Il tipo di socket dgram deve usare l’opzione wait, mentre i demoni con socket stream, che sono in genere multi-thread, devono usare nowait. wait in genere fornisce socket multiple ad un singolo demone, mentre nowait lancia un demone figlio per ogni nuova socket.
Il massimo numero di demoni figli che inetd può lanciare si imposta attraverso l’opzione max-child. Se è richiesto un limite di dieci istanze per un particolare demone, un /10 dovrebbe essere inserito dopo l’opzione nowait. Specificando /0 si lascia un numero illimitato di figli.
Oltre all’opzione max-child, possono essere attivate due altre opzioni che limitano il massimo numero di connessioni da un singolo ip verso un particolare demone. max-connections-per-ip-per-minute limita il numero di connessioni da un particolare indirizzo IP per minuto, ad esempio un valore di dieci limiterebbe ogni singolo indirizzo IP a connettersi verso un certo servizio a dieci connessioni al minuto. max-child-per-ip limita il numero di figli che possono essere avviati su richiesta di un singolo indirizzo IP in ogni momento. Queste opzioni sono utili per prevenire eccessivo consumo delle risorse intenzionale o non intenzionale e attacchi Denial of Service (DoS) ad una macchina.
In questo campo, wait o nowait sono obbligatorie. max-child e max-connections-per-ip-per-minute e max-child-per-ip sono opzionali.
Un demone tipo-stream multi-thread senza i limiti max-child o max-connections-per-ip-per-minute dovrebbe essere semplicemente: nowait.
Lo stesso demone con un limite massimo di dieci demoni dovrebbe avere: nowait/10.
In aggiunta, la stessa impostazione con un limite di venti connessioni per IP al minuto ed un limite massimo di dieci demoni figli avrebbe: nowait/10/20.
Queste opzioni sono tutte utilizzate di default nelle impostazioni del demone fingerd(8) come si vede di seguito:
finger stream tcp nowait/3/10 nobody /usr/libexec/fingerd fingerd -s
Alla fine, un esempio di questo campo con 100 figli in tutto, con un massimo di 5 per singolo indirizzo IP sarebbe: nowait/100/0/5.
Questo è lo username sotto il quale un particolare demone dovrebbe girare. Di frequente, i demoni girano come utente root. Per motivi di sicurezza, è normale trovare alcuni server che girano con l’utente daemon, o il meno privilegiato utente nobody.
Il percorso assoluto del demone che deve essere eseguito quando è ricevuta una connessione . Se il demone è un servizio offerto da inetd internamente, bisogna usare internal.
Questa opzione funziona in congiunzione con server-program specificando gli argomenti, cominciando con argv[0], passati al demone al momento dell’invocazione. Se mydaemon -d è la linea di comando, mydaemon -d sarà il valore dell’opzione server-program-arguments. Ancora, se un demone è un servizio interno, usa internal.
A seconda delle scelte fatte all’installazione, molti servizi di inetd potrebbero essere attivi di default. Se non c’è necessità apparente per un particolare demone, considera di disabilitarlo. Usa un "#" a capo della riga del demone in questione in /etc/inetd.conf, e quindi ricarica la configurazione di inetd. Alcuni demoni, come fingerd, potrebbero non essere assolutamente desiderati, poichè forniscono all’attaccante informazioni che gli potrebbero risultare utili.
Alcuni demoni non sono stati creati coll’obiettivo della sicurezza ed hanno timeout lunghi, o non esistenti. Questo permette ad un attaccante di inviare lentamente connessioni ad un particolare demone, saturando in questo modo le risorse disponibile. Può essere una buona idea impostare le limitazioni max-connections-per-ip-per-minute e max-child o max-child-per-ip su certi demoni se scopri di avere troppe connessioni.
Di default, il TCP wrapping è attivo. Consulta la pagina del manuale di hosts_access(5) per impostare delle restrizioni TCP su certi demoni invocati da inetd.
daytime, time, echo, discard, chargen, e auth sono tutti servizi interni di inetd.
Il servizio auth fornisce servizi di rete di identificazione ed è configurabile fino ad un certo punto, mentre gli altri possono solo essere accesi o spenti.
Consulta la paigna di manuale di inetd(8) per dettagli più approfonditi.
Fra i molti differenti file system che FreeBSD supporta c’è il Network File System, conosciuto anche come NFS. NFS permette ad un sistema di condividere directory e file con altri sistemi in rete. Usando NFS, utenti e programmi possono accedere a file su sistemi remoti quasi come se fossero files locali.
Alcuni dei più notevoli benefici che NFS ci fornisce sono:
Workstation locali usano meno spazio su disco perchè i dati usati in locale possono essere conservati su una singola macchina e restano accessibili agli altri sulla rete.
Non c’è bisogno per gli utenti di avere home directory separate su ogni macchina in rete. Le home directory possono essere poste sul server NFS e rese disponibili attraverso la rete.
Device di storage come floppy disk, drive CDROM, e drive Zip® possono essere usati da altre macchine sulla rete. Questo può ridurre il numero di device di storage rimuovibili sulla rete.
NFS consiste di almeno due parti: un server ed uno o più client. Il client accede da remoto ai dati conservati sulla macchina server. Affinchè questo funzioni, alcuni processi devono essere configurati e devono essere attivi.
Il server deve avere attivi i seguenti demoni:
| Demone | Descrizione |
|---|---|
nfsd | Il demone NFS che serve richieste da client NFS. |
mountd | Il demone di mount NFS che serve le richieste che nfsd(8) gli passa. |
rpcbind | Questo demone permette ai client NFS di scoprire quali porte il server NFS sta usando. |
Il client può anche eseguire un demone, noto come nfsiod. Il demone nfsiod serve le richieste dal server NFS. E' opzionale, aiuta a migliorare le prestazioni ma non è indispensabile per operazioni corrette. Consultare la pagina di manuale di nfsiod(8) per più informazioni.
La configurazione di NFS è un processo relativamente semplice. I processi che devono essere attivi possono essere tutti avviati al boot della macchina con poche modifiche al tuo file /etc/rc.conf.
Sul server NFS assicurati che le seguenti opzioni sono configurati nel file /etc/rc.conf:
rpcbind_enable="YES" nfs_server_enable="YES" mountd_flags="-r"
mountd viene eseguito automaticamente in caso il server NFS sia abilitato.
Sul client, accertati che questa riga sia attiva nel file /etc/rc.conf:
nfs_client_enable="YES"
Il file /etc/exports specifica quali file system NFS dovrebbe esportare (talora chiamate anche "share"). Ogni linea di /etc/exports specifica un file system che deve essere esportato e quali macchine hanno accesso a quel file system. Assieme alle macchine che hanno accesso a quel file system, possono esserci specificate anche opzioni. Ci sono molte opzioni di questo tipo che possono essere usate in questo file ma solo poche saranno menzionate qui. Puoi facilmente scoprire le altre opzioni leggendo la pagina di manuale di exports(5).
Queste sono alcune linee di esempio del file /etc/exports:
I seguenti esempi danno un’idea di come esportare file system, anche se le impostazioni possono essere diverse a seconda del tuo ambiente e della tua configurazione di rete. Ad esempio, per esportare la directory /cdrom a tre macchine di esempio che hanno lo stesso nome di dominio del server (da qui la mancanza di nome dominio per ognuno) o hanno delle linee nel vostro file /etc/hosts. L’opzione -ro rende il file system esportato read-only. Con questo flag, il sistema remoto non sarà in grado di scrivere alcun cambiamento sul file system esportato.
/cdrom -ro host1 host2 host3
La seguente linea esporta la directory /home a tre host identificati da indirizzo IP. E' una impostazione utile in caso tu abbia una rete privata senza un DNS server configurato. Opzionalmente il file /etc/hosts può essere configurato per hostname interni. Per favore rileggi hosts(5) per più informazioni. Il flag -alldirs permette alle sottodirectory di fungere da mount point. In altre parole, non monterà le sottodirectory ma permetterà ai client di montare solo le directory che necessita o di cui ha bisogno.
/home -alldirs 10.0.0.2 10.0.0.3 10.0.0.4
La linea seguente esporta /a cosicchè due client da diversi domini possono accedere al file system. L’opzione -maproot=root permette all’utente root sul sistema remoto di scrivere dati sul file system esportato come utente root. Se il flag -maproot=root non è specificato, anche se l’utente ha accesso come root sul file system remoto, non sarà in grado di modificare files sul file system esportato.
/a -maproot=root host.example.com box.example.org
Affinchè un client abbia accesso ad un file system, questo deve avere permessi adeguati. Assicurati che il client sia elencato nel file /etc/exports.
In /etc/exports, ogni linea rappresenta le informazioni per un file system esportato ad un host. Un host remoto può essere specificato solo una volta per file system, e può avere solo una entry di default. Ad esempio, supponi che /usr sia un singolo file system. Il seguente /etc/exports sarebbe invalido:
# Invalid when /usr is one file system /usr/src client /usr/ports client
Un file system, /usr, ha due linee che specificano exports verso lo stesso host, client. Il formato corretto per questa situazione è:
/usr/src /usr/ports client
Le proprietà di un file system esportato ad un dato host devono essere tutte su una riga. Linee senza un cliente specificato sono trattate come un singolo host. Questo limita il modo di esportare file system, ma per la maggior parte delle persone non è un problema.
Il seguente è un esempio di valida lista di esportazione, dove /usr e /exports /usr and /exports sono file system locali:
# Export src and ports to client01 and client02, but only # client01 has root privileges on it /usr/src /usr/ports -maproot=root client01 /usr/src /usr/ports client02 # The client machines have root and can mount anywhere # on /exports. Anyone in the world can mount /exports/obj read-only /exports -alldirs -maproot=root client01 client02 /exports/obj -ro
Il demone mountd deve essere forzato a rileggere il file /etc/exports ogni volta che lo modifichi, cosicchè i cambiamenti abbiano effetto. Questo può essere ottenuto inviando un segnale HUP al processo mountd:
# kill -HUP `cat /var/run/mountd.pid`o invocando lo script mountd rc(8) con i parametri appropriati:
# /etc/rc.d/mountd onereloadSei invitato a far riferimento a Configurazione Iniziale per maggiori informazioni sugli script rc.
Alternativamente, un reboot farà sì che FreeBSD imposti tutto correttamente. Non è necessario tuttavia effettuare un reboot. L’esecuzione del seguente comando da utente root dovrebbe avviare tutto.
Sul server NFS:
# rpcbind
# nfsd -u -t -n 4
# mountd -rSul client NFS:
# nfsiod -n 4Ora dovrebbe essere tutto pronto per montare un file system remoto. In questi esempi il nome del server sarà server e quello del client sarà client. Se vuoi solo temporaneamente montare un file system remoto o anche testare la configurazione, basta che esegui un comando come questo come utente root sul client:
# mount server:/home
/mntQuesto monterà la directory /home del server sopra /mnt sul client. Se tutto è impostato correttamente dovresti essere in grado di entrare nella directory /mnt sul client e vedere tutti i file che sono sul server.
Se vuoi montare automaticamente un file system remoto ogni volta che il computer fa boot, aggiungi il file system al file /etc/fstab. Questo è un esempio:
server:/home /mnt nfs rw 0 0
La pagina di manuale di fstab(5) elenca tutte le possibili opzioni.
Alcune applicazioni (es. mutt) richiedono il lock dei file per operare in modo corretto. In caso di NFS, può essere utilizzato rpc.lockd per il lock dei file. Per abilitarlo, aggiungi la seguente riga al file /etc/rc.conf sia sul client che sul server (assumendo che il client e server NFS siano già configurati):
rpc_lockd_enable="YES" rpc_statd_enable="YES"
Avvia l’applicazione con:
# /etc/rc.d/nfslocking startSe non è richiesto un lock reale tra il server e il client NFS, è possibile dire al client NFS di fare un lock locale passando l’opzione -L a mount_nfs(8). Ulteriori dettagli possono essere trovati nella pagina man di mount_nfs(8).
NFS ha molti usi pratici. Alcuni dei più usati sono elencati di seguito:
Fa sì che alcune macchine condividano un CDROM o un altro media fra di loro. Questo è un metodo più economico e spesso più convieniente di installare software su molte macchine.
Su grandi reti, potrebbe essere più conveniente configurare un server NFS centrale in cui conservare tutte le home directory degi utenti. Queste home directory possono essere esportate sulla rete cosicchè gli utenti abbiano sempre la stessa directory, indipendentemente dalla workstation dalla quale effettuino il login.
Molte macchine potrebbero avere una directory comune /usr/ports/distfiles. In questo modo, quando hai bisogno di installare un port su molte macchine, puoi velocemente accedere al sorgente senza scaricarlo su ogni macchina.
amd(8) (il demone di mount automatico) monta automaticamente un file system remoto ogni volta che un file o una directory in quel file system viene acceduto. I file system che sono inattivi per un certo periodo di tempo possono anche essere smontati automaticamente da amd. L’uso di amd fornisce una semplice alternativa a mount permanenti, dato che i mount permanenti sono di solito elencati in /etc/fstab.
amd opera connettendosi ad un server NFS sulle directory /host e /net. Quando si accede ad un file all’interno di una di queste directory, amd fa una ricerca del mount remoto corrispondente e lo monta automaticamente. /net è usato per montare un file system esportato da un indirizzo IP, mentre /host è usato per montare un export da un hostname remoto.
Un accesso ad un file in /host/foobar/usr dovrebbe comunicare a amd di cercare di montare l’export /usr sull’host foobar.
Puoi osservare i mount disponibili di un host remoto con il comando showmount. Ad esempio, per vedere i mounts di un host chiamato foobar, puoi usare:
% showmount -e foobar
Exports list on foobar:
/usr 10.10.10.0
/a 10.10.10.0
% cd /host/foobar/usrCome si vede nell’esempio, il comando showmount mostra /usr come un export. Quando si cambia directory in /host/foobar/usr, amd cerca di risolvere foobar e automaticamente monta l’export desiderato.
amd può essere avviato dagli scripts di startup inserendo le seguenti linee in /etc/rc.conf:
amd_enable="YES"
Inoltre, altri flags personalizzati possono essere ad amd con le opzioni amd_flags. Di default, amd_flags è impostato a:
amd_flags="-a /.amd_mnt -l syslog /host /etc/amd.map /net /etc/amd.map"
Il file /etc/amd.map definisce le opzioni di default con le quali gli export sono montati. Il file /etc/amd.conf definisce alcune delle più avanzate caratteristiche di amd.
Consulta le pagine di manuale di amd(8) e amd.conf(8) per maggiori informazioni.
Alcuni adapter Ethernet per sistemi PC hanno limitazioni che possono portare a seri problemi seri di rete, in particolare con NFS. Questa difficoltà non è specifica a FreeBSD, ma i sistemi FreeBSD ne sono affetti.
I problemi avvengono quasi sempre quando sistemi PC (FreeBSD) sono connessi in rete con workstation ad alta performance, tipo quelli di Silicon Graphics, Inc., e Sun Microsystems, Inc. Il mount NFS funziona, ed alcune operazioni possono avere successo, ma d’improvviso sembra che il server non dia più risposte al client, anche se le richieste da e verso altri sistemi continuano ad essere processate. Questo avviene sul sistema client, sia che il client sia il sistema FreeBSD sia che sia la workstation. Su molti sistemi, non c’è modo di effettuare lo shutdown del client in modo pulito una volta che questo problema si sia manifestato. L’unica soluzione è spesso quella di resettare il client, poichè la situazione NFS non può essere risolta.
Anche se la soluzione "corretta" è usare un adapter Ethernet dalle migliori prestazioni e capacità , c’è un semplice workaround che permetterà operazioni soddisfacenti. Se il sistem FreeBSD è il server, includi le opzioni -w=1024 al mount dal client. Se il sistema FreeBSD è il client, allora monta il file system NFS con l’opzione -r=1024. Queste opzioni possono essere specificate usando il quarto campo della linea di fstab sul client per mount automatici, o usa il parametro -o del comando mount(8) per mount manuali.
Bisognerebbe notare che c’è un problema diverso, a volte confuso con questo, quando il server NFS ed il client sono su reti diverse. Se è questo il caso, accertatevi che i vostri router indirizzino correttamente l’informazione necessaria su UDP, o non andrai da nessuna parte, indipendentemente da cosa tu stia cercando di fare.
Nei seguenti esempi, fastws è il nome host (interfaccia) di una workstation ad alte prestazioni, e freebox è il nome host (interfaccia) di un sistema FreeBSD con un adapter Ethernet a basse prestazioni. Inoltre, /sharedfs sarà il file system esportato (vedi exports(5)), e /project sarà il mount point sul client per il file system montato. In tutti i casi, nota che le opzioni hard o soft e bg possono essere utili nella tua applicazione.
Esempi dal sistema FreeBSD (freebox) come client da /etc/fstab su freebox:
fastws:/sharedfs /project nfs rw,-r=1024 0 0
Come comando manuale di mount da freebox:
# mount -t nfs -o -r=1024 fastws:/sharedfs /projectEsempi dal sistema FreeBSD come server in /etc/fstab su fastws:
freebox:/sharedfs /project nfs rw,-w=1024 0 0
Come comando di mount manuale su fastws:
# mount -t nfs -o -w=1024 freebox:/sharedfs /projectPraticamente ogni Ethernet adapter a 16-bit permetterà operazioni senza le succitate restrizioni sulla dimensione di lettura e scrittura.
Per chiunque è interessato, ecco cosa succede quando occorre il problema, il che spiega anche perchè sia non riparabile. NFS tipicamente lavora con una dimensione di "block" di 8 K (anche se può creare frammenti di dimensione minore). Dal momento che la massima dimensione dei pacchetti Ethernet è attorno a 1500 bytes, il "block" NFS sarà diviso in molti pacchetti Ethernet anche se è pur sempre una singola unità per il codice di più alto livello e deve essere ricevuto, assemblato e riconosciuto come una unità . La workstation ad alta performance può inviare pacchetti che comprendono le unità NFS una dietro l’altra, l’una vicino all’altra come permette lo standard.i Sulla scheda a minore capacità , gli ultimi pacchetti sovrascrivono i precedenti pacchetti della stessa unità prima che possano essere trasferiti all’host e l’unità nella sua interezza non può essere ricostruita o riconosciuta. Come risultato, la workstation andrà in timeout e cercherà ancora di ripetere l’operazione, ma cercherà con la stessa unità da 8 K, ed il processo sarà ripetuto ancora, all’infinito.
Mantenendo la dimensione dell’unità al di sotto della limitazione dei pacchetti Ethernet, ci assicuriamo che ogni completo pacchetto Ethernet ricevuto possa essere ricono sciuto individualmente, evitando così la situazione deadlock.
Sovrascritture possono anche capitare quando una workstation ad alte prestazioni riversi dati verso un sistema PC, ma con la scheda di rete migliore, sovrascritture di questo tipo non sono garantite su "unità " NFS. Quando una sovrascrittura avviene, le unità affette saranno ritrasmesse, e c’è una buona probabilità che saranno ricevute, assemblate, e riconosciute.
NIS, che sta per Network Information Services, fu sviluppato da Sun Microsystems per centralizzare l’amministrazione di sistemi UNIX® (in origine SunOS™). Ora in sostanza è diventato uno standard di settore; tutti i sistemi UNIX® like (Solaris™, HP-UX, AIX®, Linux, NetBSD, OpenBSD, FreeBSD, etc) supportano NIS.
NIS in precedenza era noto come Yellow Pages, ma per una questione di marchi, Sun ha cambiato il nome. Il vecchio termine (e yp) è ancora si incontra ancora spesso.
E' un sistema client/server basato su RPC che permette ad un gruppo di macchine in un dominio NIS di condividere un insieme comune di file di configurazione. Questo permette ad un amministratore di sistema di installare sistemi client NIS con il minimo di dati di configurazione e di aggiungere, rimuovere o modificare dati di configurazione da una singola macchina.
E' simile al sistema di domini di Windows NT®; anche se le implementazioni interne dei due sistemi sono del tutto diverse, le funzionalità base possono essere paragonate.
Ci sono parecchi termini e molti importanti processi utente che incontrerai quando cercherai di implementare NIS su FreeBSD, sia che cerchi di creare un server NIS sia che cerchi di installare un client NIS:
| Termine | Descrizione |
|---|---|
Nome dominio NIS | Un server NIS master e tutti i suoi client (inclusi i suoi server slave) hanno un nome dominio NIS. Analogamente al nome dominio di Windows NT®, il nome dominio NIS non ha nulla a che fare con il DNS. |
rpcbind | Deve essere in esecuzione al fine di abilitare RPC (Remote Procedure Call, un protocollo di rete usato da NIS). Se rpcbind non è attivo, sarà impossibile portare in esecuzione un server NIS o fungere da client NIS |
ypbind | Esegue il "bind" di un client NIS al suo server. Prenderà il nome dominio NIS dal sistema, e, usando RPC, si connetterà al server. ypbind è il fulcro di una comunicazione client-server in ambiente NIS; se ypbind muore su un client, questo non sarà in grado di accedere il server NIS. |
ypserv | Dovrebbe essere in esecuzione solo sui server NIS;è il processo NIS vero e proprio. Se ypserv(8) muore, il server non sarà più in grado di rispondere a richieste NIS (si spera ci sia un server slave per sostituirlo). Ci sono alcune implementazioni di NIS (ma non quello di FreeBSD) che non cerca di ricollegarsi ad un altro server se il server che stava usando muore. Spesso, l’unica cosa che aiuta in questo caso è riavviare il processo server (o anche l’intero server o il processo ypbind sul client). |
rpc.yppasswdd | Un altro processo che dovrebbe essere in esecuzione solo sui server master NIS; è un demone che permette a client NIS di cambiare le proprie password NIS. Se questo demone non è attivo, gli utenti dovranno loggarsi al server master NIS e cambiare le proprie password da lì. |
Ci sono tre tipi di host in ambiente NIS: master server, slave server e client. I server fungono da magazzino centralizzato per le informazioni sulla configurazione degli host. I server master mantengono la copia "ufficiale" di queste informazioni, mentre i server slave effettuano il mirror di queste informazioni per ridondanza. I client si affidano al server per ottenere queste informazioni.
Le informazioni in molti file possono essere condivise in questo modo. I file master.passwd ,group e hosts sono in genere condivisi in questo modo via NIS. Qualora un processo su un client necessiti di informazioni che normalmente sarebbero trovate in questi file in locale, fa una query al server NIS a cui è legato.
Un server master NIS. Questo server, analogamente a primary domain controller Windows NT® , mantiene i file usati da tutti i client NIS. Il file passwd, il file group, e vari altri file usati da client NIS vivono sul server master.
E' possibile per una macchina agire da master server NIS per più di un dominio NIS. Comunque, questo caso non sarà coperto in questa introduzione, che presuppone un ambiente NIS relativamente piccolo. |
NIS slave server. Analogamente a backup domain controller Windows NT®, i server slave NIS mantengono copie dei file di dati del server master NIS. I server slave NIS garantiscono la ridondanza che viene richiesta in ambienti importanti. Inoltre aiutano a bilanciare il carico del server master: i client NIS si legano sempre al NIS server che risponde per primo alla loro richiesta, compresi i server slave.
NIS client. I client NIS, come la maggior parte delle workstation Windows NT® , si autenticano nei confronti del NIS server (o del domain controller Windows NT® nel caso di workstation Windows NT®) per effettuare il login.
Questa sezione riguarderà l’installazione di un ambiente di esempio NIS.
Supponiamo che tu sia l’amministratore di un piccolo laboratorio universitario. Questo laboratorio, che consiste di 15 macchine FreeBSD, al momento non ha un sistema centralizzato di amministrazione; ogni macchina ha il suo /etc/passwd e /etc/master.passwd. Questi file sono tenuti sincronizzati fra di loro attraverso intervento manuale; al momento, quando aggiungi un utente al laboratorio, devi eseguire adduser su tutte e 15 le macchine. Chiaramente, questa situazione è provvisoria, così hai deciso di convertire il laboratorio a NIS, usando due delle macchine come server.
Così la configurazione del laboratorio adesso sembra questa:
| Nome della macchina | Indirizzo IP | Ruolo della macchina |
|---|---|---|
|
| NIS master |
|
| NIS slave |
|
| Workstation della facoltà |
|
| Macchina client |
|
| Altre macchine client |
Se stai installando uno schema NIS per la prima volta, è una buona idea riflettere su come affrontarlo. Indipendemente dalla dimensione della rete, ci sono alcune decisioni che devono essere prese.
Questo può non essere il "nome dominio" a cui sei abituato. Per la precisione viene chiamato "nome dominio NIS". Quando un client fa il broadcast della sua richiesta per informazioni, include il nome del dominio NIS di cui fa parte. In questo modo molti server su una rete possono distinguere a quale server la richiesta è riferita. Considerate il nome dominio NIS come il nome per un gruppo di host che sono collegati per qualche motivo.
Alcune organizzazioni scelgono di usare il loro nome dominio Internet come nome dominio NIS. Questo non è raccomandabile in quanto può causare confusione quando si cerchi di debuggare problemi di rete. Il nome dominio NIS dovrebbe essere unico all’interno della tua rete ed è utile che sia descrittivo del gruppo di macchine che rappresenta. Per esempio, il dipartimento di Arte della Acme Inc. può essere nel dominio "acme-art". Per questo esempio, si presume tu abbia scelto il nome test-domain.
Comunque, alcuni sistemi operativi (principalmente SunOS™) usano il loro nome dominio NIS come loro nome dominio Internet. Se una o più macchine sulla tua rete hanno questa restrizione, tu devi usare il nome dominio Internet come il tuo nome dominio NIS.
Ci sono molte cose da tener in mente quando si sceglie quale macchina usare come server NIS. Una delle caratteristiche più sfortunate di NIS è il livello di dipendenza che i client hanno verso il server. Se un client non riesce a contattare il server per il suo dominio NIS, molto spesso la macchina risulta inutilizzabile. La mancanza di informazioni utente e di gruppo fa sì che molti sistemi si blocchino. Tenendo questo in mente dovresti accertati di scegliere una macchina che non sia soggetta a reboot frequenti o una che non sia usata per sviluppo. Il server NIS dovrebbe essere in teoria una macchina stand alone il cui unico scopo di esistenza è essere un server NIS. Se hai una rete non pesantemente trafficata, è accettabile installare il server NIS su una macchina che esegue altri servizi, basta ricordarsi che se il server NIS diventa irrangiungibile, tutti i tuoi client NIS ne saranno affetti in modo negativo.
Le copie canoniche di tutte le informazioni NIS sono conservate su una singola macchina chiamata il server master NIS. I database usati per conservare le informazioni sono chiamate mappe NIS. In FreeBSD, queste mappe sono conservate in /var/yp/[nome-dominio] dove [nome-dominio] è il nome del dominio NIS che si server. Un singolo server NIS può supportare molti domini al tempo stesso, di conseguenza è possibile avere molte directory di questo tipo, una per ogni dominio supportato. Ogni dominio avrà il suo insieme indipendente di mappe.
I server NIS master e slave gestiscono tutte le richieste NIS col demone ypserv. ypserv è responsabile per la ricezione delle richieste in entrata dai client NIS, traducendo il dominio richiesto e il nome mappa ad un percorso verso il file di database e trasmettendo i dati indietro al client.
Installare un server master NIS può essere relativamente semplice, a seconda delle tue necessità . FreeBSD presenta un supporto nativo per NIS. Tutto quello che devi fare è aggiungere le seguenti linee a /etc/rc.conf, e FreeBSD farà il resto.
nisdomainname="test-domain"
Questa linea imposterà il nome domino NIS a test-domain al momento della configurazione di rete (ad esempio dopo il reboot).
nis_server_enable="YES"
Questa linea dirà a FreeBSD di avviare i processi NIS server la prossima volta che la rete è riavviata.
nis_yppasswdd_enable="YES"
Questo avvierà il demone rpc.yppasswd che, come accennato prima, permetterà agli utenti di cambiare la loro password NIS dalle macchine client.
A seconda delle tue impostazioni NIS, potresti aver bisogno di aggiungere altre linee. Leggi la sezione sui NIS server che sono anche NIS client , di seguito, per dettagli. |
Ora, tutto quello che devi fare è eseguire il comando /etc/netstart come super-utente. Questo imposterà il sistema, usando i valori che hai specificato in /etc/rc.conf.
Le mappe NIS sono file di database, che sono conservati nella directory /var/yp. Sono generati da file di configurazione nella directory /etc del NIS master, con una eccezione: il file /etc/master.passwd. C’è un buon motivo per questo, infatti normalmente non vuoi che siano propagate le password a root e ad altri account amministrativi a tutti gli altri server nel dominio NIS. Così prima di inizializzare le mappe NIS, dovresti:
# cp /etc/master.passwd /var/yp/master.passwd
# cd /var/yp
# vi master.passwdDovresti rimuovere tutte le linee che riguardano account di sistema (bin, tty, kmem, games, etc.), così come altri account che non vuoi siano propagate ai client NIS (per esempio root ed ogni altro account con UID 0 (super-utente)).
Accertati che il file /var/yp/master.passwd non sia nè leggibile dal gruppo nè dal resto del mondo (modo 600)! Usa il comando |
Quando hai finito, è il momento di inizializzare le mappe NIS! FreeBSD include uno script chiamato ypinit che lo fa per te (leggi la sua pagina di manuale per dettagli). Nota che questo script è disponibile sulla maggior parte dei sistemi operativi UNIX® ma non su tutti. Su Digital Unix/Compaq Tru64 UNIX è chiamato ypsetup. Poichè stiamo generando mappe per un NIS master, passeremo l’opzione -m al comando ypinit. Per generare le mappe NIS, supponendo che tu abbia già eseguito i passi di cui sopra, esegui:
ellington# ypinit -m test-domain
Server Type: MASTER Domain: test-domain
Creating an YP server will require that you answer a few questions.
Questions will all be asked at the beginning of the procedure.
Do you want this procedure to quit on non-fatal errors? [y/n: n]
n
Ok, please remember to go back and redo manually whatever fails.
If you don't, something might not work.
At this point, we have to construct a list of this domains YP servers.
rod.darktech.org is already known as master server.
Please continue to add any slave servers, one per line. When you are
done with the list, type a <control D>.
master server : ellington
next host to add: coltrane
next host to add: ^D
The current list of NIS servers looks like this:
ellington
coltrane
Is this correct? [y/n: y] y
[..output from map generation..]
NIS Map update completed.
ellington has been setup as an YP master server without any errors.ypinit dovrebbe aver creato /var/yp/Makefile da /var/yp/Makefile.dist. Quando creato, questo file assume che tu stia operando su un ambiente NIS a server singolo con solo macchine FreeBSD. Dal momento che test-domain ha anche un server slave, devi editare /var/yp/Makefile:
ellington# vi /var/yp/MakefileDovresti commentare la linea che dice
NOPUSH = "True"
(se non è già commentata).
Impostare un server NIS slave è anche più semplice che impostare il master. Loggati al server slave ed edita il file /etc/rc.conf esattamente come hai fatto col server master. L’unica differenza è che ora dobbiamo usare l’opzione -s quando eseguiamo ypinit. L’opzione -s richiede che il nome del server NIS sia passato, così la nostra linea di comando assomiglia alla seguente:
coltrane# ypinit -s ellington
test-domain
Server Type: SLAVE Domain: test-domain Master: ellington
Creating an YP server will require that you answer a few questions.
Questions will all be asked at the beginning of the procedure.
Do you want this procedure to quit on non-fatal errors? [y/n: n]
n
Ok, please remember to go back and redo manually whatever fails.
If you don't, something might not work.
There will be no further questions. The remainder of the procedure
should take a few minutes, to copy the databases from ellington.
Transferring netgroup...
ypxfr: Exiting: Map successfully transferred
Transferring netgroup.byuser...
ypxfr: Exiting: Map successfully transferred
Transferring netgroup.byhost...
ypxfr: Exiting: Map successfully transferred
Transferring master.passwd.byuid...
ypxfr: Exiting: Map successfully transferred
Transferring passwd.byuid...
ypxfr: Exiting: Map successfully transferred
Transferring passwd.byname...
ypxfr: Exiting: Map successfully transferred
Transferring group.bygid...
ypxfr: Exiting: Map successfully transferred
Transferring group.byname...
ypxfr: Exiting: Map successfully transferred
Transferring services.byname...
ypxfr: Exiting: Map successfully transferred
Transferring rpc.bynumber...
ypxfr: Exiting: Map successfully transferred
Transferring rpc.byname...
ypxfr: Exiting: Map successfully transferred
Transferring protocols.byname...
ypxfr: Exiting: Map successfully transferred
Transferring master.passwd.byname...
ypxfr: Exiting: Map successfully transferred
Transferring networks.byname...
ypxfr: Exiting: Map successfully transferred
Transferring networks.byaddr...
ypxfr: Exiting: Map successfully transferred
Transferring netid.byname...
ypxfr: Exiting: Map successfully transferred
Transferring hosts.byaddr...
ypxfr: Exiting: Map successfully transferred
Transferring protocols.bynumber...
ypxfr: Exiting: Map successfully transferred
Transferring ypservers...
ypxfr: Exiting: Map successfully transferred
Transferring hosts.byname...
ypxfr: Exiting: Map successfully transferred
coltrane has been setup as an YP slave server without any errors.
Don't forget to update map ypservers on ellington.Ora dovresti avere una directory chiamata /var/yp/test-domain. Copie delle mappe NIS del master server dovrebbero risiedere in questa directory. Dovresti accertarti che siano aggiornate. La seguente linea di /etc/crontab sul tuo server slave dovrebbe far ciò:
20 * * * * root /usr/libexec/ypxfr passwd.byname 21 * * * * root /usr/libexec/ypxfr passwd.byuid
Queste due linee forzano lo slave a sincronizzare le sue mappe con le mappe del server master. Anche se queste entry non sono obbligatorie, dal momento che il server master cerca di assicurarsi che tutte le modifiche alle sue mappe NIS siano comunicate ad i suoi slave e perchè le informazioni sulle password sono vitali per i sistemi che dipendono dal server, è una buona idea forzare gli aggiornamenti. Questo è ancora più importante su reti trafficate dove gli aggiornamenti delle mappe potrebbero non essere completi.
Adesso, esegui il comando /etc/netstart anche sullo slave, per avviare il server NIS.
Un client NIS stabilisce quello che è chiamato un binding ad un particolare NIS server usando il demone ypbind. ypbind controlla il dominio di default del sistema (impostato dal comando domainname), ed inizia a fare broadcast di richieste RPC sulla rete locale. Queste richieste specificano il nome del dominio per il quale ypbind sta cercando di stabilire un binding. Se un server è stato configurato a servire il dominio richiesto, risponderà a ypbind, che registrerà l’indirizzo del server. Se ci sono molti server disponibili (ad esempio un master e molti slave), ypbind userà l’indirizzo del primo che risponde. Da quel momento in poi, il sistema client dirigerà tutte le sue richieste NIS a quel server. ypbind occasionalmente farà un "ping" del server per accertarsi che sia su ed attivo. Se non riceve una risposta di uno dei suoi ping in un tempo accettabile, ypbind segnerà il dominio come non connesso e inizierà di nuovo a fare broadcasting nella speranza di localizzare un altro server.
Impostare una macchina FreeBSD perchè sia un client NIS è abbastanza semplice.
Edita il file /etc/rc.conf e aggiungi le seguenti linee per impostare il nome dominio NIS ed avviare ypbind all’avvio della rete:
nisdomainname="test-domain" nis_client_enable="YES"
Per importare tutte le possibili linee di password dal server NIS, rimuovi tutti gli account utente dal tuo /etc/master.passwd ed usa vipw per aggiungere la seguente linea alla fine del file:
+:::::::::
Questa linea permetterà a chiunque con un valido account nella mappa delle password del server NIS di loggarsi sul client. Ci sono molti modi per configurare il tuo client NIS cambiando questa linea. Leggi la sezione sui netgroups di seguito per maggiori informazioni. Per letture più dettagliate vedere il libro della O’Reilly |
Dovresti tenere almeno un account locale (non importato via NIS) nel tuo file /etc/master.passwd e questo account dovrebbe essere anche un membro del gruppo |
Per impostare tutte le possibili linee dei gruppi dal server NIS, aggiungi questa linea al tuo file /etc/group:
+:*::
Dopo aver completato questi passi, dovresti essere in grado di eseguire ypcat passwd e vedere la mappa delle password del NIS server.
In generale, ogni utente remoto può eseguire una RPC a ypserv(8) ed ottenere i contenuti delle tue mappe NIS, ammesso che l’utente remoto conosca il tuo nome dominio. Per prevenire tali transazioni non autorizzate, ypserv(8) supporta una caratteristica chiamata "securenets" che può essere usata per restringere l’accesso ad un dato insieme di host. All’avvio ypserv(8) cercherà di caricare le informazioni delle securenets da un file chiamato /var/yp/securenets.
Questo percorso varia a secondo del percorso specificato con l’opzione |
# allow connections from local host -- mandatory 127.0.0.1 255.255.255.255 # allow connections from any host # on the 192.168.128.0 network 192.168.128.0 255.255.255.0 # allow connections from any host # between 10.0.0.0 to 10.0.15.255 # this includes the machines in the testlab 10.0.0.0 255.255.240.0
Se ypserv(8) riceve una richiesta da un indirizzo che coincide con una di queste regole, processerà la richiesta normalmente. Se l’indirizzo non coincide la richiesta sarà ignorata ed un messaggio di warning sarà loggato. Se il file /var/yp/securenets non esiste, ypserv permetterà connessioni da ogni host.
Il programma ypserv ha anche supporto per il pacchetto di Wietse Venema TCP Wrapper. Questo permette all’amministratore di usare i file di configurazione di TCP Wrapper per controlli sull’accesso al posto di /var/yp/securenets.
Pur essendo entrambi questi meccanismi di accesso di controllo abbastanza sicuri, questi, come il test di porta privilegiata, sono vulnerabili agli attacchi "IP spoofing". Tutto il traffico relativo a NIS dovrebbe essere bloccato al firewall. I server che usano /var/yp/securenets possono non riuscire a servire client NIS legittimi che abbiano implementazioni TCP/IP obsolete. Alcune di queste implementazioni impostano a zero tutti i bit degli host quando fanno broadcast e/o non riescono a osservare la maschera di sotto-rete quando calcolano l’indirizzo broadcast. Mentre alcuni di questi problemi possono essere corretti cambiando la configurazione del client, altri problemi possono causare il ritiro dei client in questione o l’abbandono di /var/yp/securenets. Usando /var/yp/securenets su un server con una tale obsoleta implementazione del TCP/IP è sicuramente una cattiva idea e causerà alla perdita della funzionalità NIS per gran parte della tua rete. L’uso del pacchetto TCP Wrapper aumenta la latenza del tuo server NIS. Il ritardo addizionale può essere lungo a sufficienza tanto da causare dei timeout in programmi client, specialmente su reti trafficate o con server NIS lenti. Se uno o più client soffre di questi sintomi, dovresti convertire il sistema dei client in questione a server NIS slave e forzarli a non fare il binding a loro stessi. |
Nel nostro laboratorio c’è una macchina basie che si suppone sia una workstation solo della facoltà . Non vogliamo togliere questa macchina dal dominio NIS, tuttavia il file passwd sul server NIS master contiene account che sono sia della facoltà sia degli studenti. Cosa possiamo fare?
C’è un modo di impedire a specifici utenti di loggarsi ad una macchina, anche se sono presenti nel database NIS. Per farlo, tutto quello che devi fare è aggiungere -username alla fine del file /etc/master.passwd sulla macchina client, dove username è lo username dell’utente di cui vuoi impedire l’accesso. E' meglio fare questo con vipw dato che vipw farà un controllo di correttezza dei tuoi cambiamenti a /etc/master.passwd, e ricostruirà automaticamente il database delle password quando hai finito di editarlo. Ad esempio, se vogliamo impedire l’accesso all’utente bill verso l’host basie faremmo:
basie# vipw
[aggiungi -bill alla fine del file, poi esci]
vipw: rebuilding the database...
vipw: done
basie# cat /etc/master.passwd
root:[password]:0:0::0:0:The super-user:/root:/bin/csh
toor:[password]:0:0::0:0:The other super-user:/root:/bin/sh
daemon:*:1:1::0:0:Owner of many system processes:/root:/sbin/nologin
operator:*:2:5::0:0:System &:/:/sbin/nologin
bin:*:3:7::0:0:Binaries Commands and Source,,,:/:/sbin/nologin
tty:*:4:65533::0:0:Tty Sandbox:/:/sbin/nologin
kmem:*:5:65533::0:0:KMem Sandbox:/:/sbin/nologin
games:*:7:13::0:0:Games pseudo-user:/usr/games:/sbin/nologin
news:*:8:8::0:0:News Subsystem:/:/sbin/nologin
man:*:9:9::0:0:Mister Man Pages:/usr/shared/man:/sbin/nologin
bind:*:53:53::0:0:Bind Sandbox:/:/sbin/nologin
uucp:*:66:66::0:0:UUCP
pseudo-user:/var/spool/uucppublic:/usr/libexec/uucp/uucico
xten:*:67:67::0:0:X-10 daemon:/usr/local/xten:/sbin/nologin
pop:*:68:6::0:0:Post Office Owner:/nonexistent:/sbin/nologin
nobody:*:65534:65534::0:0:Unprivileged user:/nonexistent:/sbin/nologin
+:::::::::
-bill
basie#Il metodo mostrato nella sezione precedente funziona ragionevolmente bene se hai bisogno di regole speciali per un numero molto piccolo di utenti e/o macchine. Su reti più grandi, certamente ti dimenticherai di impedire l’accesso di certi utenti a macchine dal ruolo critico, oppure potresti perfino finire a modificare ogni macchina separatamente, in questo modo perdendo il beneficio centrale di NIS: l’amministrazione centralizzata.
La soluzione degli sviluppatori NIS a questo problema è chiamata netgroups. Il loro scopo e la loro semantica possono essere paragonate ai normali gruppi utenti usati dal file system UNIX®. L’unica differenza è la mancanza di un ID numerico e l’abilità di definire un netgroup che includa sia gruppi utenti che altri netgroup.
I netgroup furono sviluppati per gestire grandi reti complesse con centinaia di utenti e macchine. Da un lato questa è una Buona Cosa se sei obbligato a gestire una simile situazione. Dall’altro, questa complessità rende praticamente impossibile spiegare i netgroup con esempi relativamente semplici. L’esempio usato nel resto di questa sezione dimostra questo problema.
Assumiamo che la favorevole introduzione di NIS nei tuoi laboratori catturi l’interesse dei tuoi superiori. Il tuo prossimo compito è di estendere il tuo dominio NIS per coprire alcune altre macchine del campo. Le due tabelle contengono i nomi dei nuovi utenti e delle nuove macchine, con una breve descrizione.
| User Name(s) | Description |
|---|---|
| Impiegato normale del dipartimento IT |
| Il nuovo apprendista del dipartimento IT |
| Impiegato ordinario |
| Gli interni correnti |
| Machine Name(s) | Description |
|---|---|
| Il tuoi server più importanti. Solo gli impiegati IT hanno il permesso di loggarsi in queste macchine. |
| Server meno importanti. Tutti i membri del dipartimento IT hanno il permesso di loggarsi a queste macchine. |
| Workstation normali. Solo veri impiegati hanno permesso di accedere a queste macchine. |
| Una macchina molto vecchia senza alcun dato critico. Anche gli interni hanno permesso di usare questa macchina. |
Se provi ad implementare queste restrizioni bloccando separatamente ogni utente, dovresti aggiungere una linea -user ad ogni passwd per ogni utente che non ha il permesso di loggarsi in quel sistema. Se ti dimentichi anche solo di una linea, potresti essere nei pasticci. Può essere ragionevole fare ciò correttamente durante l’installazione iniziale, comunque certamente ti dimenticherai alla fine di aggiungere le linee per i nuovi utenti durante le operazioni giornaliere. Dopo tutto, Murphy era un ottimista.
Gestire questa situazione con i netgroup offre molti vantaggi. Non c’è bisogno di gestire separatamente ogni utente; basta assegnare un utente ad uno o più netgroup e permettere o impedire il login a tutti i membri del netgroup. Se aggiungi una nuova macchina, dovrai solo definire restrizioni di login per i netgroup. Se un nuovo utente viene aggiunto, dovrai solo aggiungere l’utente ad uno o più netgroup. Questi cambiamenti sono indipendenti l’uno dall’altro: non più "per ogni combinazione di utenti e macchine fai …"Se la tua installazione NIS è pianificata con attenzione, dovrai solo modificare esattamente un file centrale di configurazione per garantire o negare l’accesso alle macchine.
Il primo passo è l’inizializzazione della mappa NIS netgroup. ypinit(8) di FreeBSD non crea questa mappa di default, ma la sua implementazione NIS la supporterà una volta che è stata creata. Per aggiungere una linea alla mappa, semplicemente usa il comando
ellington# vi /var/yp/netgroupe poi inizia ad aggiungere contenuti. Per i nostri esempi abbiamo bisogno di almeno quattro netgroup: impiegati IT, apprendisti IT, impiegati normali ed interni.
IT_EMP (,alpha,test-domain) (,beta,test-domain)
IT_APP (,charlie,test-domain) (,delta,test-domain)
USERS (,echo,test-domain) (,foxtrott,test-domain) \
(,golf,test-domain)
INTERNS (,able,test-domain) (,baker,test-domain)IT_EMP, IT_APP etc. sono i nomi dei netgroup. Ogni gruppo fra parentesi tonde aggiunge uno o più account utente. I tre campi dentro il gruppo sono:
Il nome degli host dove le seguenti caratteristiche sono valide. Se non specifichi un nome host, la linea è valida per tutti gli host. Se specifichi un nome host, entrerai nel regno dell’oscurità , dell’orrore e della confusione assoluta.
Il nome dell’account che appartiene a questo netgroup.
Il dominio NIS per l’account. Puoi importare account da altri domini NIS nel tuo netgroup se sei uno di quei ragazzi sfortunati con più di un dominio NIS.
Ognuno di questi campi può contenere wildcards. Leggi netgroup(5) per dettagli.
Nomi netgroup più lunghi di 8 caratteri non dovrebbero essere usati, specialmente se hai macchine che eseguono altri sistemi operativi all’interno del tuo dominio NIS. I nomi sono case sensitive; usare le lettere maiuscole per il tuo netgroup è un modo semplice per distinguere fra utenti, macchine e nomi di netgroup. Alcuni client NIS (non FreeBSD) non possono gestire netgroup con un numero troppo grande di linee. Ad esempio, alcune vecchie versioni di SunOS™ iniziano ad avere problemi se un netgroup contiene più di 15 linee. Puoi superare questo limite creando molti sotto-netgroup con 15 o meno utenti ed un vero netgroup che consiste dei sotto-netgroup: BIGGRP1 (,joe1,domain) (,joe2,domain) (,joe3,domain) [...] BIGGRP2 (,joe16,domain) (,joe17,domain) [...] BIGGRP3 (,joe31,domain) (,joe32,domain) BIGGROUP BIGGRP1 BIGGRP2 BIGGRP3 Puoi ripetere questo processo se hai bisogno di più di 225 utenti all’interno di un singolo netgroup. |
Attivare e distribuire la tua nuova mappa NIS è facile:
ellington# cd /var/yp
ellington# makeQuesto genererà le tre mappe NIS netgroup, netgroup.byhost e netgroup.byuser. Usa ypcat(1) per controllare che le tue nuove mappe NIS siano disponibili:
ellington% ypcat -k
netgroup
ellington% ypcat -k netgroup.byhost
ellington% ypcat -k
netgroup.byuserL’output del tuo primo comando dovrebbe assomigliare a /var/yp/netgroup. Il secondo comando non produrrà output se non hai specificato netgroup specifici agli host. Il terzo comando può essere usato per ottenere una lista dei netgroup di un utente.
L’installazione del client è abbastanza semplice. Per configurare il server war, devi solo eseguire vipw(8) e sostituire la linea
+:::::::::
con
+@IT_EMP:::::::::
Ora, solo i dati per l’utente definito nel netgroup IT_EMP sono importati nel database delle password di war e solo questi utenti hanno permesso di accesso.
Sfortunatamente, questa limitazione si applica anche alla funzione della shell ~ ed a tutte le routine che convertono fra nomi utenti e user ID numerici. In altre parole,cd ~user ` non funzionerà , `ls -l mostrerà gli ID numerici invece dello username e find . -user joe -print darà l’errore No such user. Per riparare questo, dovrai importare tutte le linee dell’utente senza permettere a loro di loggarsi sui tuoi server.
Questo può essere ottenuto aggiungendo un’altra linea a /etc/master.passwd. Questo dovrebbe contenere:
+:::::::::/sbin/nologin, dal significato "Importa tutte le entry ma imposta la shell di login a /sbin/nologin nelle linee importate". Puoi sostituire ogni campo nella linea passwd piazzando un valore di default nel tuo /etc/master.passwd.
Accertati che la linea |
Dopo questo cambiamento, dovrai solo cambiare una mappa NIS se un nuovo impiegato si unisce al dipartimento IT. Puoi usare un simile approccio per i server meno importanti sostituendo +::::::::: nella tua versione locale di /etc/master.passwd con qualcosa del tipo:
+@IT_EMP::::::::: +@IT_APP::::::::: +:::::::::/sbin/nologin
Le linee corrispondenti per le workstation normali potrebbero essere:
+@IT_EMP::::::::: +@USERS::::::::: +:::::::::/sbin/nologin
E tutto sarebbe a posto fino a che non c’è un cambiamento di policy dopo poche settimane: il dipartimento IT inizia ad assumere interni. Gli interni IT hanno permesso di usare le normali workstation ed i server meno importanti; e gli apprendisti IT hanno permesso di loggarsi ai server principali. Aggiungi un nuovo netgroup IT_INTERN, aggiungi i nuovi interni IT a questo nuovo netgroup IT_INTERN, e inizia a cambiare la configurazione su ogni nuova macchina… Come il vecchio adagio dice:"Errori nella pianificazione centralizzata porta a caos globale".
L’abilità NIS di creare netgroup da altri netgroup può essere usata per prevenire situazioni come queste. Una possibilità è la creazione di netgroup basati sul ruolo. Per esempio, potresti creare un netgroup chiamato BIGSRV per definire le restrizioni di login per i server importanti, un altro netgroup chiamato SMALLSRV per i server meno importanti ed un terzo netgroup chiamato USERBOX per le workstation normali. Ognuna di questi netgroup contiene i netgroup che hanno permesso di accesso a queste macchine. Le nuove linee della tua mappa NIS dovrebbero assomigliare a questa:
BIGSRV IT_EMP IT_APP SMALLSRV IT_EMP IT_APP ITINTERN USERBOX IT_EMP ITINTERN USERS
Questo metodo di definire restrizioni di login funziona ragionevolmente bene se puoi definire gruppi di macchine con restrizioni identiche. Sfortunatamente questa è l’eccezione, non la regola. La maggior parte del tempo, avrai necessità di definire restrizioni di login macchina per macchina.
Definizioni di netgroup specifiche per ogni macchina sono l’altra possibilità per gestire il cambiamento di policy delineato sopra. In questo scenario il /etc/master.passwd di ogni macchina deve contenere due linee che iniziano con "+". La prima di queste aggiunge un netgroup con l’account che ha il permesso di loggarsi alla macchina, il secondo aggiunge tutti gli altri account con /sbin/nologin come shell. E' buona norma usare la versione "MAIUSCOLA" del nome macchina come nome del netgroup. In altre parole, le linee dovrebbero assomigliare a questa:
+@BOXNAME::::::::: +:::::::::/sbin/nologin
Una volta che hai completato questo task per tutte le macchine, non dovrai mai più modificare la versione locale di /etc/master.passwd. Tutti gli ulteriori cambiamenti possono essere gestiti modificando la mappa NIS. Di seguito un esempio di una possibile mappa netgroup per questo scenario con altri vantaggi addizionali:
# Define groups of users first IT_EMP (,alpha,test-domain) (,beta,test-domain) IT_APP (,charlie,test-domain) (,delta,test-domain) DEPT1 (,echo,test-domain) (,foxtrott,test-domain) DEPT2 (,golf,test-domain) (,hotel,test-domain) DEPT3 (,india,test-domain) (,juliet,test-domain) ITINTERN (,kilo,test-domain) (,lima,test-domain) D_INTERNS (,able,test-domain) (,baker,test-domain) # # Now, define some groups based on roles USERS DEPT1 DEPT2 DEPT3 BIGSRV IT_EMP IT_APP SMALLSRV IT_EMP IT_APP ITINTERN USERBOX IT_EMP ITINTERN USERS # # And a groups for a special tasks # Allow echo and golf to access our anti-virus-machine SECURITY IT_EMP (,echo,test-domain) (,golf,test-domain) # # machine-based netgroups # Our main servers WAR BIGSRV FAMINE BIGSRV # User india needs access to this server POLLUTION BIGSRV (,india,test-domain) # # This one is really important and needs more access restrictions DEATH IT_EMP # # The anti-virus-machine mentioned above ONE SECURITY # # Restrict a machine to a single user TWO (,hotel,test-domain) # [...more groups to follow]
Se stai usando qualche tipo di database per gestire i tuoi account utente, dovresti essere in grado di creare la prima parte della mappa con i tuoi tool di report del database. In questo modo, i nuovi utenti avranno accesso automaticamente alle macchine.
Un ultima nota di avvertimento: può non essere sempre consigliabile usare netgroup basati sulle macchine. Se stai per mettere in produzione qualche dozzina o perfino qualche centinaia di macchine identiche per laboratori studente, dovresti usare netgroup basati sul ruolo invece che netgroup basati sulla macchina, per tenere la dimensione della mappa NIS al di sotto di un limite ragionevole.
Ci sono ancora un paio di cose che dovrai cambiare ora che operi in ambiente NIS.
Ogni volta che devi aggiungere un utente al laboratorio devi aggiungerlo solo al server master NIS e devi ricordarti di ricostruire le mappe NIS. Se ti dimentichi di farlo il nuovo utente non sarà in grado di loggarsi in alcuna macchina eccetto che sul server NIS master. Per esempio, se abbiamo bisogno di aggiungere un nuovo utente jsmith al laboratorio, faremmo:
# pw useradd jsmith
# cd /var/yp
# make test-domainPuoi anche eseguire adduser jsmith invece di pw useradd jsmith.
Tieni gli account amministrativi fuori dalle mappe NIS. Normalmente non vuoi che gli account amministrativ e le password si propaghino a macchine che avranno utenti che non dovrebbero avere accesso a quegli account.
Tieni al sicuro il NIS master e slave, e minimizza il tempo in cui sono giù. Se qualcuno hackera o semplicemente spegne queste macchine riesce a privare molte persone della possibilità di loggarsi al laboratorio.
Questa è la principale debolezza di ogni sistema centralizzato di amministrazione. Se non proteggi il tuo server NIS, avrai un mucchio di utenti arrabbiati!
ypserv di FreeBSD supporta fino ad un certo punto client NIS v1. L’implementazione di NIS di FreeBSD usa solo il protocollo NIS v2, comunque altre implementazioni includono supporto per il protocollo v1 per compatibilità all’indietro coi vecchi sistemi. Il demone ypbind fornito con questi sistemi proverà a stabilire un binding con un server NIS v1 anche se potrebbero non averne mai bisogno (e possono continuare a fare broadcast in ricerca di uno anche dopo che hanno ricevuto risposta da un server v2). Nota che mentre il supporto per i client normali viene garantito, questa versione di ypserv non gestisce richieste di trasferimento di mappe v1; di conseguenza, non può essere usato come master o slave in congiunzione con server NIS più vecchi che supportano solo il protocollo v1. Fortunatamente, probabilmente non ci sono server del genere in uso oggi.
Bisogna prestare molta attenzione quando si esegue ypserv in un dominio multi-server dove le macchine server sono anche client NIS. E' generalmente una buona idea forzare i server ad effettuare il binding a sè stessi piuttosto che permettere loro di effettuare il broadcast delle richieste binding e potenzialmente possono fare il bind una all’altra. Possono risultare strani errori quando un server va giù e gli altri sono dipendenti da lui. Alla fine, tutti i client andranno in timeout e cercheranno di effettuare il bind ad altri server, ma il ritardo di questa operazione può essere considerevole e l’uscita di errore è ancora presente dato che i server possono fare il binding fra di loro di nuovo.
Puoi forzare un host a fare il binding ad un server in particolare usando ypbind con l’opzione -S. Se non vuoi fare questa azione a mano ogni volta che fai il reboot del tuo server NIS, puoi aggiungere queste linee al tuo /etc/rc.conf:
nis_client_enable="YES" # run client stuff as well nis_client_flags="-S NIS domain,server"
Consulta ypbind(8) per ulteriori informazioni.
Uno dei problemi più comuni in cui la gente incappa quando tenta di implementare NIS è la compatibilità del formato delle password. Se il tuo server NIS usa password criptate con DES, supporterà solo client che usano anche loro DES. Ad esempio, se hai client NIS Solaris™ nella rete, dovrai quasi certamente usare password criptate con DES.
Per controllare quale formato il tuo server e client usano, dai un’occhiata a /etc/login.conf. Se l’host è configurato per usare password criptate DES, la classe default conterrà una linea simile a questa:
default:\ :passwd_format=des:\ :copyright=/etc/COPYRIGHT:\ [Further entries elided]
Altri valori possibili per l’opzione passwd_format includono blf e md5 (per password criptate con Blowfish e con MD5, rispettivamente).
Se hai fatto modifiche a /etc/login.conf, dovrai anche ricostruire il database delle possibilità di login, il che si ottiene eseguendo il seguente comando come root:
# cap_mkdb /etc/login.confIl formato delle password che sono già in /etc/master.passwd non sarà aggiornato finchè un utente cambia la sua password per la prima volta dopo che il database delle possibilità di login è ricostruito. |
Dopodichè per assicurarti che le password siano criptate con il formato che hai scelto, dovresti anche controllare che crypt_default in /etc/auth.conf dia precedenza al formato delle password scelto. Per farlo, inserisci il formato che hai scelto per primo nella lista. Ad esempio, quando usi password criptate DES, la linea dovrebbe essere:
crypt_default = des blf md5
Seguendo i passi sopra citati su ognuno dei FreeBSD basati su NIS server e client, puoi star sicuro che tutti siano d’accordo su quale formato delle password sia usato all’interno della rete. Se hai problemi nell’identificazione su un client NIS, questo è un buon punto di partenza per cercare possibili problemi. Ricordati: se vuoi mettere in produzione un server NIS per una rete eterogenea, dovrai probabilmente usare DES su tutti i sistemi poichè questo è il minimo standard comune.
DHCP, il Protocollo di Configurazione Host Dinamico, descrive i passi attraverso i quali un sistema si può connettere ad una rete ed ottenere l’informazione necessaria per comunicare attraverso quella rete. Le versioni di FreeBSD prima della 6.0 usano l’implementazione DHCP client (dhclient(8)) dell’ISC (Internet Software Consortium). Le ultime versioni usano il dhclient di OpenBSD preso da OpenBSD 3.7. Tutte le informazioni specifiche all’implementazione di dhclient in questa sede sono riferite all’uso dei client DHCP sia di ISC che di OpenBSD. Il server DHCP è quello incluso nella distribuzione ISC.
Questa sezione descrive sia il lato client del sistema DHCP di ISC e di OpenBSD che il lato server del sistema DHCP ISC. Il programma client, dhclient, è già integrato con FreeBSD, e la parte server è disponibile nel port net/isc-dhcp3-server. Le pagine di manuale dhclient(8), dhcp-options(5), e dhclient.conf(5), oltre ai riferimenti elencati oltre, sono risorse utili.
Quando dhclient, il client DHCP, viene eseguito sulla macchina client, inizia a fare broadcasting di richieste per informazioni di configurazione. Di default queste richieste sono sulla porta UDP 68. Il server risponde sulla porta UDP 67, dando al client un indirizzo IP ed altre informazioni rilevanti di rete come la netmask, il router ed il DNS server. Tutte queste informazioni arrivano sotto forma di un "rilascio" DHCP e sono valide sono per un certo periodo di tempo (configurato dall’amministratore del server DHCP). In questo modo, gli indirizzi IP bloccati da client che non sono più connessi alla rete possono essere riutilizzati automaticamente.
I client DHCP possono ottenere molti tipi di informazione dal server. Una lista esauriente può essere trovata in dhcp-options(5).
FreeBSD integra completamente il client DHCP ISC o OpenBSD, dhclient (a seconda della versione di FreeBSD utilizzata). Viene fornito supporto al client DHCP sia con l’installazione sia con il sistema base, rendendo inutile il bisogno di una conoscenza dettagliata della configurazione di rete su ogni rete che abbia un server DHCP. dhclient è stato incluso in tutte le distribuzioni FreeBSD a partire dalla 3.2.
DHCP è supportato da sysinstall. Quando configuri una interfaccia di rete con sysinstall, la seconda domanda che ti pone è: " Vuoi provare a configurare l’interfaccia via DHCP?". Una risposta affermativa eseguirà dhclient, e, se ha successo, riempirà le informazioni di configurazione della rete in automatico.
Ci sono due cose che devi fare per far sì che il tuo sistema usi il DHCP all’avvio:
Accertati che il device bpf sia compilato nel tuo kernel. Per fare ciò, aggiungi device bpf al tuo file di configurazione del kernel, e ricompilalo. Per maggiori informazioni su come ricompilare i kernel, vedi Configurazione del Kernel di FreeBSD.
Il device bpf è già parte del kernel GENERIC che è fornito con FreeBSD, così se non hai un kernel custom, non dovresti aver bisogno di crearne uno al fine di far funzionare il DHCP.
Quelli di voi che sono particolarmente attenti alla sicurezza, dovrebbero sapere che il device bpf è anche il device che permette agli sniffer di pacchetti di funzionare correttamente (anche se devono sempre essere eseguiti come |
Edita il tuo /etc/rc.conf per includere la seguente linea:
ifconfig_fxp0="DHCP"
Accertati di sostituire |
Se stai usando una locazione diversa per dhclient, o se desideri passare flags addizionali a dhclient includi anche le linee seguenti (editandole come necessario):
dhcp_program="/sbin/dhclient" dhcp_flags=""
Il server DHCP, dhcpd, è incluso come parte del port net/isc-dhcp3-server nella collezione dei ports. Questo port contiene il server DHCP ISC e la documentazione.
/etc/dhclient.conf
dhclient richiede un file di configurazione, /etc/dhclient.conf. Tipicamente il file contiene solo commenti, essendo i default ragionevolmente corretti. Questo file di configurazione è descritto dalla pagina di manuale dhclient.conf(5).
/sbin/dhclient
dhclient è linkato staticamente e risiede in /sbin. Le pagine di manuale di dhclient(8) danno maggiori informazioni su dhclient.
/sbin/dhclient-script
dhclient-script è lo script di configurazione del client DHCP specifico di FreeBSD. Viene descritto in dhclient-script(8) ma non dovrebbe aver bisogno di nessuna modifica utente per funzionare correttamente.
/var/db/dhclient.leases
Il client DHCP mantiene un database di validi rilasci in questo file, che viene scritto come un log. dhclient.leases(5) ne dàuna descrizione leggermente più estesa.
Il protocollo DHCP è descritto in maniera estesa in RFC 2131. Informazioni aggiuntive sono presenti a questo URL: http://www.dhcp.org/.
Questa sezione fornisce informazioni su come configurare un sistema FreeBSD che funzioni come un server DHCP usando l’implementazione del server DHCP dell’ISC (Internet Software Consortium).
Il server non viene fornito come parte di FreeBSD, così dovrai installare il port net/isc-dhcp3-server per fornire questo servizio. Vedi Installazione delle Applicazioni. Port e Package per più informazioni su come usare la Collezione dei Port.
Per configurare il tuo sistema FreeBSD come un server DHCP, assicurati che il device bpf(4) sia compilato nel kernel. Per farlo, aggiungi device bpf al file di configurazione del kernel, e ricompilalo. Per maggiori informazioni su come compilare un kernel, vedi Configurazione del Kernel di FreeBSD.
Il device bpf è già parte del kernel GENERIC che viene fornito con FreeBSD, così non hai bisogno di creare un kernel custom per far funzionare il DHCP.
Quelli di voi che sono particolarmente attenti alla sicurezza, dovrebbero notare che bpf è anche il device che permette agli sniffer di pacchetti di funzionare correttamente (anche se tali programmi hanno bisogno di accesso privilegiato). bpf _è _ richiesto per il funzionamento del DHCP, ma se siete molto attenti alla sicurezza, probabilmente non dovreste includere bpf nel vostro kernel semplicemente perchè vi aspettate di usare il DHCP in qualche momento. |
La prossima cosa che devi fare è editare il file dhcpd.conf che è stato installato dal port net/isc-dhcp3-server. Di default, questo sarà /usr/local/etc/dhcpd.conf.sample e dovresti copiare questo file in /usr/local/etc/dhcpd.conf prima di procedere con i cambiamenti.
dhcpd.conf è composto di dichiarazioni riguardanti sottoreti ed host, e forse lo si spiega meglio con un esempio:
option domain-name "example.com";(1)
option domain-name-servers 192.168.4.100;(2)
option subnet-mask 255.255.255.0;(3)
default-lease-time 3600;(4)
max-lease-time 86400;(5)
ddns-update-style none;(6)
subnet 192.168.4.0 netmask 255.255.255.0 {
range 192.168.4.129 192.168.4.254;(7)
option routers 192.168.4.1;(8)
}
host mailhost {
hardware ethernet 02:03:04:05:06:07;(9)
fixed-address mailhost.example.com;(10)
}| 1 | Questa opzione specifica il dominio che verrà servito ai client come il dominio di default di ricerca. Si veda resolv.conf(5) per più informazioni. |
| 2 | Questa opzione specifica una lista di server DNS separata da virgole, che i client dovrebbero usare. |
| 3 | La netmask che sarà fornita ai client. |
| 4 | Un client potrebbe richiedere una lunghezza di tempo specifica per la quale il rilascio sarà valido. Altrimenti il server assegnerà un tempo di rilascio con questa durata (in secondi). |
| 5 | Questa è la lunghezza massima di tempo per la quale un server effettuerà un rilascio. Se un client dovesse richiedere un rilascio più lungo, sarà effettuato un rilascio, anche se sarà valido solo per max-lease-time secondi. |
| 6 | Questa opzione specifica se il server DHCP dovrà cercare di modificare il DNS quando un rilascio è accettato o liberato. Nella implementazione ISC questa opzione è richiesta. |
| 7 | Questo identifica quale indirizzo IP dovrà essere usato nel pool riservato per l’allocazione ad i client. Gli indirizzi IP fra, ed inclusi, quelli dichiarati sono assegnabili agli utenti. |
| 8 | Dichiara il default gateway che sarà assegnato ad i client. |
| 9 | L’indirizzo hardware MAC di un host (cosicchè il server DHCP possa riconoscere un host quando fa una richiesta). |
| 10 | Specifica che all’host dovrebbe sempre essere fornito lo stesso indirizzo IP. Nota che usare un hostname è corretto in questo caso, dato che il DHCP server risolverà l’hostname stesso prima di restituire l’informazione sul rilascio. |
Una volta che hai finito di scrivere il tuo dhcpd.conf, puoi abilitare il server DHCP in /etc/rc.conf, aggiungendo:
dhcpd_enable="YES" dhcpd_ifaces="dc0"
Sostituisci il nome dell’interfaccia dc0 con l’interfaccia (o le interfacce, separate da spazi) su cui il tuo server DHCP dovrebbe stare in ascolto per le richieste DHCP dei client.
Quindi, puoi procedere ad avviare il server con il seguente comando:
# /usr/local/etc/rc.d/isc-dhcpd.sh startSe hai bisogno di fare altri cambiamenti alla configurazione del server in futuro, è importante notare che l’invio di un segnale SIGHUP a dhcpd_non_ fa sì che il file di configurazione sia ricaricato, come avviene con la maggior parte dei demoni. Dovrai inviare un segnale SIGTERM per fermare il processo, e poi riavviarlo usando il comando sopracitato.
/usr/local/sbin/dhcpd
dhcpd è linkato staticamente e risiede in /usr/local/sbin. La pagina di manuale di dhcpd(8) installata con il port dà più informazioni su dhcpd.
/usr/local/etc/dhcpd.conf
dhcpd richiede un file di configurazione, /usr/local/etc/dhcpd.conf, prima che possa iniziare a fornire il servizio ai client. Questo file deve contenere tutte le informazioni che devono essere fornite ai client che sono serviti, oltre alle informazioni riguardanti le operazioni del server. Questo file di configurazione è descritto dalla pagina di manuale dhcpd.conf(5) installata dal port.
/var/db/dhcpd.leases
Il server DHCP mantiene un database dei rilasci che ha effettuato in questo file, che viene scritto come un log. La pagina di manuale dhcpd.leases(5), installata dal port ne dà una descrizione leggermente pi` lunga.
/usr/local/sbin/dhcrelay
dhcrelay è usata in ambienti avanzati dove un server DHCP reinvia le richieste da un client ad un altro server DHCP su una rete separata. Se hai bisogno di questa funzionalità, installa il port net/isc-dhcp3-relay. La pagina di manuale dhcrelay(8) fornita col port contiene più dettagli.
FreeBSD utilizza, di default, una versione di BIND (Berkeley Internet Name Domain), che è la più completa implementazione del protocollo DNS. DNS è il protocollo attraverso il quale nomi sono mappati ad indirizzi IP, e viceversa. Per esempio, una query per www.FreeBSD.org ` riceverà una replica con l’indirizzo IP del web server del The FreeBSD Project, mentre una query per `ftp.FreeBSD.org ritornerà l’indirizzo IP della corrispondente macchina FTP. Allo stesso modo, può avvenire l’opposto. Una query per un indirizzo IP può risolvere il suo nome host. Non è necessario avere in esecuzione un name server per fare DNS lookups su un sistema.
FreeBSD al momento viene distribuito con software DNSBIND9 di default. La nostra installazione fornisce caratteristiche di sicurezza migliorate, un nuovo layout del file system e configurazione chroot(8) automatica.
DNS è coordinato su Internet attraverso un sistema alquanto complesso di name server autoritativi, ed altri name server di più piccola scala che ospitano e gestiscono cache di informazioni individuali sui domini.
Al momento corrente, BIND è mantenuto dall’Internet Software Consortium http://www.isc.org/.
Per comprendere questo documento, alcuni termini relativi al DNS devono essere capiti.
| Termine | Definizione |
|---|---|
Forward DNS | La mappa da hostname ad indirizzi IP. |
Origine | Si riferisce al dominio coperto in un particolare file di zona. |
named, BIND, name server | Nomi comuni per il pacchetto name server BIND all’interno di FreeBSD. |
Risolutore | Un processo di sistema attraverso il quale una macchina fa query su un name server per informazioni di zona. |
DNS inverso | L’opposto del forward DNS; mappare indirizzi IP su nomi host. |
Zona root | L’inizio della gerarchia della zona Internet. Tutte le zone cadono sotto la zona root, analogamente a come tutti i file nel file system cadono sotto la directory root. |
Zona | Un dominio individuale, sottodominio, o porzione del DNS amministrato dalla stessa autorità |
Esempi di zone:
. è la zona root
org. è una zona Top Level Domain (TLD) sotto la zona root
example.org. è una zona sotto la zona `org.`TLD
1.168.192.in-addr.arpa è una zona che referenzia tutti gli indirizzi IP che cadono sotto lo spazio IP`192.168.1.*`.
Come si può vedere, la parte più specifica di un nome host appare a sinistra. Per esempio example.org. è più specifico di org., come org. è più specifico della zona root. La disposizione di ogni parte di un nome host è analoga ad un file system: la directory /dev cade all’interno della root, e così via.
Attualmente vengono usati due tipi di name server: un name server autoritativo, ed un name server cache.
Un name server autoritativo è necessario quando:
uno vuole servire informazioni DNS a tutto il mondo, rispondendo in maniera autoritativa alle query.
un dominio, tipo example.org, è registrato e gli indirizzi IP devono essere assegnati ad hostname sotto questo.
un blocco di indirizzi IP richiede entry di DNS inverso (da IP ad hostname).
un name server di backup, chiamato uno slave, deve rispondere alle query.
Un name server cache è necessario quando:
un server locale DNS può tenere in cache e rispondere più velocemente rispetto ad effettuare query ad un name server all’esterno.
una riduzione nel traffico complessivo di rete è desiderato (è stato calcolato che il traffico DNS conta più del 5% sul traffico totale di Internet).
Quando uno fa una query per risolvere www.FreeBSD.org, il risolutore di solito fa una query al name server dell’ISP a cui si è connessi, ed ottiene una risposta. Con un server DNS locale, che fa cache, la query deve essere effettuata una volta sola dal server DNS che fa cache. Ogni query aggiuntiva non dovrà cercare all’esterno della rete locale, dato che l’informazione è tenuta in cache localmente.
In FreeBSD, il demone BIND è chiamato named per ovvie ragioni.
| File | Descrizione |
|---|---|
Il demone BIND. | |
Programma di controllo del name server. | |
/etc/namedb | Directory dove risiedono le informazioni di zona di BIND. |
/etc/namedb/named.conf | File di configurazione del demone. |
A seconda di come certe zone sono configurate sul server, i file relativi a quelle zone possono essere trovate nelle sottodirectory master, slave, or dynamic della directory /etc/namedb. Questi file contengono le informazioni DNS che saranno distribuite dal name server in risposta alle query.
Dato che BIND è installato di default, configurarlo è relativamente semplice.
La configurazione di default di named è quella di un name server basilare, eseguito in ambiente chroot(8). Per avviare il server una volta con questa configurazione, usa il seguente comando:
# /etc/rc.d/named forcestartPer assicurarsi che il demone named sia avviato alla partenza, metti la seguente riga in /etc/rc.conf:
named_enable="YES"
Ci sono ovviamente molte opzioni di configurazione per /etc/namedb/named.conf che sono al di là dello scopo di questo documento. Comunque, se siete interessati nelle opzioni di avvio per named su FreeBSD, dai un’occhiata ai flags named_ in /etc/defaults/rc.conf e consulta la pagina di manuale rc.conf(5). Anche la sezione Configurazione Iniziale è una buona base di partenza.
I file di configurazione per named al corrente risiedono nella directory /etc/named e necessiteranno di modifiche prima dell’uso, a meno che non si voglia un semplice resolver. Qui è dove la maggior pare della configurazione viene effettuata.
make-localhostPer configurare una zona master per il localhost visita la directory /etc/namedb ed esegui il seguente comando:
# sh make-localhostSe tutto è andato bene, un nuovo file dovrebbe esistere nella sottodirectory master. I nomi dei file dovrebbero essere localhost.rev per il local domain name e localhost-v6.rev per le configurazioni IPv6. Come il file di configurazione di default, l’informazione richiesta sarà presente nel file named.conf.
// $FreeBSD$
//
// Refer to the named.conf(5) and named(8) man pages, and the documentation
// in /usr/shared/doc/bind9 for more details.
//
// If you are going to set up an authoritative server, make sure you
// understand the hairy details of how DNS works. Even with
// simple mistakes, you can break connectivity for affected parties,
// or cause huge amounts of useless Internet traffic.
options {
directory "/etc/namedb";
pid-file "/var/run/named/pid";
dump-file "/var/dump/named_dump.db";
statistics-file "/var/stats/named.stats";
// If named is being used only as a local resolver, this is a safe default.
// For named to be accessible to the network, comment this option, specify
// the proper IP address, or delete this option.
listen-on { 127.0.0.1; };
// If you have IPv6 enabled on this system, uncomment this option for
// use as a local resolver. To give access to the network, specify
// an IPv6 address, or the keyword "any".
// listen-on-v6 { ::1; };
// In addition to the "forwarders" clause, you can force your name
// server to never initiate queries of its own, but always ask its
// forwarders only, by enabling the following line:
//
// forward only;
// If you've got a DNS server around at your upstream provider, enter
// its IP address here, and enable the line below. This will make you
// benefit from its cache, thus reduce overall DNS traffic in the Internet.
/*
forwarders {
127.0.0.1;
};
*/Proprio come dicono i commenti, per beneficiare di una cache di un server superiore, può essere abilitato forwarders. Sotto circostanze normali, un name server farà query ricorsive attraverso Internet cercando certi name server fino a chè non trova la risposta che sta cercando. Averlo abilitato farà sì che sarà fatta prima una query verso il name server superiore (o il name server fornito), avvantaggiandosi della sua cache. Se il name server superiore è un name server molto trafficato e veloce, può valere la pena di abilitarlo.
|
/*
* If there is a firewall between you and nameservers you want
* to talk to, you might need to uncomment the query-source
* directive below. Previous versions of BIND always asked
* questions using port 53, but BIND versions 8 and later
* use a pseudo-random unprivileged UDP port by default.
*/
// query-source address * port 53;
};
// If you enable a local name server, don't forget to enter 127.0.0.1
// first in your /etc/resolv.conf so this server will be queried.
// Also, make sure to enable it in /etc/rc.conf.
zone "." {
type hint;
file "named.root";
};
zone "0.0.127.IN-ADDR.ARPA" {
type master;
file "master/localhost.rev";
};
// RFC 3152
zone "1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.IP6.ARPA" {
type master;
file "master/localhost-v6.rev";
};
// NB: Do not use the IP addresses below, they are faked, and only
// serve demonstration/documentation purposes!
//
// Example slave zone config entries. It can be convenient to become
// a slave at least for the zone your own domain is in. Ask
// your network administrator for the IP address of the responsible
// primary.
//
// Never forget to include the reverse lookup (IN-ADDR.ARPA) zone!
// (This is named after the first bytes of the IP address, in reverse
// order, with ".IN-ADDR.ARPA" appended.)
//
// Before starting to set up a primary zone, make sure you fully
// understand how DNS and BIND works. There are sometimes
// non-obvious pitfalls. Setting up a slave zone is simpler.
//
// NB: Don't blindly enable the examples below. :-) Use actual names
// and addresses instead.
/* An example master zone
zone "example.net" {
type master;
file "master/example.net";
};
*/
/* An example dynamic zone
key "exampleorgkey" {
algorithm hmac-md5;
secret "sf87HJqjkqh8ac87a02lla==";
};
zone "example.org" {
type master;
allow-update {
key "exampleorgkey";
};
file "dynamic/example.org";
};
*/
/* Examples of forward and reverse slave zones
zone "example.com" {
type slave;
file "slave/example.com";
masters {
192.168.1.1;
};
};
zone "1.168.192.in-addr.arpa" {
type slave;
file "slave/1.168.192.in-addr.arpa";
masters {
192.168.1.1;
};
};
*/In named.conf, ci sono esempi di linee slave per zone di forward ed inverse.
Per ogni nuova zona servita, una nuova linea di zona deve essere aggiunta a named.conf.
Per esempio, la più semplice entry per example.org può assomigliare a:
zone "example.org" {
type master;
file "master/example.org";
};La zona è una master, come indicato dall’entry type, e conserva le informazioni di zona su /etc/namedb/master/example.org indicata dalla entry file.
zone "example.org" {
type slave;
file "slave/example.org";
};Nel caso slave, l’informazione di zona è trasferita dal name server master per quella zona particolare, e salvata nel file specificato. Se e quando il master muore o è irraggiungibile, il name server slave avrà le informazioni di zona trasferite e sarà in grado di servirlo.
Un esempio di file di zona master per example.org (che esiste all’interno di /etc/namedb/master/example.org) è la seguente:
$TTL 3600 ; 1 hour
example.org. IN SOA ns1.example.org. admin.example.org. (
2006051501 ; Serial
10800 ; Refresh
3600 ; Retry
604800 ; Expire
86400 ; Minimum TTL
)
; DNS Servers
IN NS ns1.example.org.
IN NS ns2.example.org.
; MX Records
IN MX 10 mx.example.org.
IN MX 20 mail.example.org.
IN A 192.168.1.1
; Machine Names
localhost IN A 127.0.0.1
ns1 IN A 192.168.1.2
ns2 IN A 192.168.1.3
mx IN A 192.168.1.4
mail IN A 192.168.1.5
; Aliases
www IN CNAME @Nota che ogni hostname che finisce in un "." è un nome esatto, mentre ogni entità senza un "." è referenziato all’origine. Per esempio www è trasformato in www.origin. Nel nostro file di zone fittizio, la nostra origine è example.org, così www si trasformerebbe in www.example.org.
Il formato di un file di zona è il seguente:
recordname IN recordtype value
I record DNS usati più di frequente:
inizio di una zona di autorità
un name server autoritativo
un indirizzo host
il nome canonico per un alias
mail exchanger
un puntatore a nome di dominio (usato nel DNS inverso)
example.org. IN SOA ns1.example.org. admin.example.org. (
2006051501 ; Serial
10800 ; Refresh after 3 hours
3600 ; Retry after 1 hour
604800 ; Expire after 1 week
86400 ) ; Minimum TTL of 1
dayexample.org.il nome di dominio, inoltre è l’origine per questo file di zona.
ns1.example.org.il name server primario/autoritativo per questa zona.
admin.example.org.la persona responsabile per questa zona, un indirizzo email con "@" sostituito. (admin@example.org diventa admin.example.org)
2006051501il numero di serie del file. Questo deve essere aumentato ogni volta che il file di zona è modificato. Al giorno d’oggi molti amministratori preferiscono un formato yyyymmddrr per il numero di serie. 2006051501 significherebbe modificato l’ultima volta il 05/15/2006, l’ultimo 01 essendo la prima volta che il file di zona è stato modificato in questo giorno. Il numero di serie è importante dato che avverte name server slave per una zona quando questa ` modificata.
IN NS ns1.example.org.
Questa è una linea NS. Ogni name server che replicherà in maniera autoritativa la zona deve avere una di queste linee. Il @ come visto potrebbe essere stato ` example.org.` Il @ si traduce nell’origine.
localhost IN A 127.0.0.1 ns1 IN A 192.168.1.2 ns2 IN A 192.168.1.3 mx IN A 192.168.1.4 mail IN A 192.168.1.5
Il record A indica un nome macchina. Come visto sopra, ns1.example.org risolverebbe in 192.168.1.2.
IN A 192.168.1.1
Questa linea assegna l’indirizzo IP 192.168.1.1 alla corrente origine, in questo caso example.org.
www IN CNAME @
Il record nome canonico è usato per dare alias ad una macchina. Nell’esempio, www è tramutato in alias nella macchina "master" che corrisponde al domain name example.org ` (`192.168.1.1). CNAME possono essere usati per fornire alias ad hostname o distribuire in round robin un hostname fra molte macchine.
IN MX 10 mail.example.org.
Il record MX ` usato per specificare quali mail server sono responsabili per gestire mail entranti per la zona. `mail.example.org ` è l’hostname del mail server, e 10 è la priorità di quel mail server.
Uno può avere molti mail server, con priorità di 10, 20 e così via. Un mail server che cerca di consegnare una mail a example.org proverà prima l’MX con la più alta priorità (il record con il numero di priorita' minimo) poi il secondo, etc., fino a chè la mail non sia consegnata correttamente.
Per file di zona in-addr.arpa (DNS inverso), lo stesso formato è usato, eccetto con linee PTR al posto di A o CNAME.
$TTL 3600
1.168.192.in-addr.arpa. IN SOA ns1.example.org. admin.example.org. (
2006051501 ; Serial
10800 ; Refresh
3600 ; Retry
604800 ; Expire
3600 ) ; Minimum
IN NS ns1.example.org.
IN NS ns2.example.org.
1 IN PTR example.org.
2 IN PTR ns1.example.org.
3 IN PTR ns2.example.org.
4 IN PTR mx.example.org.
5 IN PTR mail.example.org.Questo file da la corretta mappa da indirizzi IP ad hostname per il nostro dominio fittizio.
Un name server caching è un name server che non è autoritativo per nessuna zona. Fa semplicemente query, e ne memorizza le risposte per uso successivo. Per impostarne uno, configura il name server come al solito, omettendo ogni inclusione di zona.
Anche se BIND è la più comune implementazione del DNS, c’è sempre la questione della sicurezza. Talvolta vengono trovati possibili e sfruttabili buchi di sicurezza.
Mentre FreeBSD tiene named automaticamente in un ambiente chroot(8), ci sono molti altri meccanismi di sicurezza che potrebbero essere sfruttati per attacchi al servizio DNS.
È una buona idea leggere gli avvisi sulla sicurezza di CERT e sottoscrivere le mailing list sugli avvisi di sicurezza su FreeBSD per stare aggiornato con le questioni correnti di sicurezza di Internet e FreeBSD.
Se sorge un problema, tenere i sorgenti aggiornati e fare una compilazione al volo di named non farebbe male. |
Pagine di manuale di BIND/named: rndc(8) named(8) named.conf(8)
FreeBSD è usato per far girare alcuni dei siti web più trafficati al mondo. La maggioranza dei web server su Internet usano attualmene Apache HTTP Server. Il pacchetto software di Apache dovrebbe essere incluso nel tuo media di installazione di FreeBSD. Se non hai installato Apache quando hai installato FreeBSD per la prima volta, lo puoi installare dal port www/apache13 o www/apache22.
Una volta che Apache è stato installato con successo, deve essere configurato.
Questa sezione copre la versione 1.3.X di Apache HTTP Server dato che è la versione più usata per FreeBSD. Apache 2.X introduce molte nuove tecnologie ma queste non saranno discusse in questa sede. Per maggiori informazioni su Apache 2.X, per favore consulta httpd://httpd.apache.org/. |
Il principale file di configurazione di Apache HTTP Server è installato in /usr/local/etc/apache/httpd.conf su FreeBSD. Questo file è un tipico file di testo di configurazione di UNIX® con linee di commento che cominciano col carattere #. Una descrizione comprensiva di tutte le possibili opzioni di configurazione è al di fuori dello scopo di questo libro, così solo le direttive usate più di frequente saranno descritte di seguito.
ServerRoot "/usr/local"Questo specifica la gerachia di directory di default per l’installazione di Apache. I binari sono conservati nelle sottodirectory bin e sbin sotto la server root, ed i file di configurazione sono conservati sotto etc/apache.
ServerAdmin you@your.addressL’indirizzo email al quale i problemi riguardanti il server dovrebbero essere inviati. Questo indirizzo appare su alcune pagine generate dal server, come alcuni documenti di errore.
ServerName www.example.comServerName ti permette di impostare un nome host che viene inviato ai client per il tuo server, se questo è differente da quello per il quale l’host è configurato (ad esempio usi `www ` invece del vero nome host).
DocumentRoot "/usr/local/www/data"DocumentRoot: La directory dalla quale servirai documenti. Di default tutte le richieste sono girate a questa directory, ma link simbolici ed alias possono essere usati per puntare ad altre locazioni.
È sempre una buona idea fare copie di backup del tuo file di configurazione di Apache prima di modificarlo. Una volta che sei soddisfatto dalla tua configurazione iniziale sei pronto per iniziare ad eseguire Apache.
Apache non viene eseguito dal super server inetd a differenza di molti altri server di rete. È configurato per girare standalone per migliori performance per gestire le richieste HTTP in entrata dai client web browser. Un wrapper shell script è incluso per rendere il più semplice possibile lo start, lo stop ed il restart del server. Per avviare Apache per la prima volta, esegui:
# /usr/local/sbin/apachectl startPuoi fermare il server in ogni istante digitando:
# /usr/local/sbin/apachectl stopDopo aver fatto modifiche al file di configurazione per una qualsiasi ragione, avrai bisogno di riavviare il server:
# /usr/local/sbin/apachectl restartPer riavviare Apache senza mandare in abort le connessioni correnti, esegui.
# /usr/local/sbin/apachectl gracefulInformazioni addizionali sono disponibili sulla pagina di manuale di apachectl(8).
Per eseguire Apache all’avvio del sistema, aggiungi la seguente linea ad /etc/rc.conf:
apache_enable="YES"
o per Apache 2.2:
apache22_enable="YES"
Se volessi fornire opzioni addizionali di linea di comando al programma Apache`httpd` avviato al boot di sistema, puoi specificarle con una linea addizionale in rc.conf:
apache_flags=""
Ora che il web server è in esecuzione puoi navigare il tuo sito web puntando il tuo web browser ad http://localhost/. La pagina di default che viene mostrata è /usr/local/www/data/index.html.
Apache supporta due tipi diversi di Virtual Hosting. Il primo metodo è Virtual Hosting basato sul nome. Il Virtual Hosting basato sul nome usa gli header HTTP/1.1 per scoprire l’hostname. Questo permette a molti domini diversi di condividere lo stesso indirizzo IP.
Per fare sì che Apache usi Virtual Hosting basato sui nomi aggiungi una entry come la seguente al tuo file httpd.conf:
NameVirtualHost *
Se il tuo webserver era nominato www.domain.tld e tu avessi voluto installare un dominio virtuale per `www.someotherdomain.tld ` avresti dovuto aggiungere le seguenti entry a httpd.conf:
<VirtualHost *>
ServerName www.domain.tld
DocumentRoot /www/domain.tld
</VirtualHost>
<VirtualHost *>
ServerName www.someotherdomain.tld
DocumentRoot /www/someotherdomain.tld
</VirtualHost>Sostituisci gli indirizzi con gli indirizzi che vuoi usare ed i percorsi dei documenti con quelli che usi.
Per maggiori informazioni sull’impostazione dei virtual host, per favore consulta la documentazione ufficiale a http://httpd.apache.org/docs/vhosts/.
Ci sono molti diversi moduli Apache disponibili per aggiungere funzionalità al server base. La Collezione Port di FreeBSD fornisce un modo semplice di installare Apache assieme ad alcuni dei più popolari moduli aggiuntivi.
Il modulo mod_ssl usa la libreria OpenSSL per fornire una forte crittografia attraverso i protocolli Secure Sockets Layer (SSL v2/v3) e Transport Layer Security (TLS v1). Questo modulo fornisce tutto il necessario per richiedere un certificato firmato da un’autorità fidata che emette certificati, cosicchè puoi eseguire un web server sicuro su FreeBSD.
Se non hai ancora installato Apache, una versione di Apache 1.3.X che includa mod_ssl può essere installata con il port www/apache13-modssl. Il supporto ad SSL è anche disponibile per Apache 2.X nel port www/apache22, dove viene abilitato di default.
Negli ultimi anni, molte aziende si sono rivolte a Internet per migliorare i loro ricavi e aumentare la loro esposizione. Questo ha anche aumentato il bisogno di contenuti interattivi web. Mentre alcune società come Microsoft® hanno introdotto soluzioni nei loro prodotti proprietari, la comunità open source ha risposto all’appello. Due opzioni per contenuti web dinamici includono mod_perl & mod_php.
Il progetto di integrazione Apache/Perl mette assieme la grande potenza del linguaggio di programmazione Perl e l’Apache HTTP Server. Con il modulo mod_perl è possibile scrivere moduli Apache interamente in Perl. In aggiunta l’interprete persistente integrato nel server evita l’overhead di avviare un interprete esterno e la penalizzazione del tempo di caricamento Perl.
mod_perl è disponibile in alcuni modi diversi. Per usare mod_perl ricorda che mod_perl 1.0 funziona solo con Apache 1.3 e mod_perl 2.0 funziona solo con Apache 2.X. mod_perl 1.0 è disponibile in www/mod_perl ed una versione compilata staticamente è disponibile in www/apache13-modperl. mod_perl 2.0 è disponibile in www/mod_perl2.
PHP, anche noto come "Hypertext Prepocessor" è un linguaggio di scripting di scopo generale che è particolarmente adatto per lo sviluppo Web. Adatto ad essere usato all’interno dell’HTML, la sua sintassi deriva dal C, Java™, e Perl con l’intenzione di permettere agli sviluppatori web di scrivere pagine web generate dinamicamente in modo veloce.
Per integrare supporto a PHP5 per il web server Apache, inizia con l’installare il port lang/php5.
Se il port lang/php5 viene installato per la prima volta, le OPTIONS disponibili saranno mostrate automaticamente. Se non viene mostrato un menu, ad esempio perché il port lang/php5 è stato installato qualche volta in passato, è sempre possibile rivedere il menu a dialogo con le opzioni eseguendo:
# make confignella directory dei port.
Nel menu a dialogo delle opzioni, flagga l’opzione APACHE per compilare mod_php5 come modulo caricabile per il web server Apache.
Molti siti stanno ancora usando PHP4 per varie ragioni (ad esempio questioni di compatibilità o applicativi web già costruiti). Se si necessita del modulo mod_php4 invece che di mod_php5, siete pregati di usare il port lang/php4. Il port lang/php4 supporta molte delle configurazioni e delle opzioni di build-time del port lang/php5. |
Questo installerà e configurerà i moduli richiesti per supportare applicazioni web dinamiche PHP. Controlla che le seguenti linee siano state aggiunte al file /usr/local/etc/apache/httpd.conf:
LoadModule php5_module libexec/apache/libphp5.so
AddModule mod_php5.c
<IfModule mod_php5.c>
DirectoryIndex index.php index.html
</IfModule>
<IfModule mod_php5.c>
AddType application/x-httpd-php .php
AddType application/x-httpd-php-source .phps
</IfModule>Una volta completato, una semplice chiamata al comando apachectl per un tranquillo restart è richiesto per caricare il modulo PHP:
# apachectl gracefulPer upgrade futuri di PHP, il comando make config non sarà richiesto; le OPTIONS selezionate sono salvate automaticamente dal sistema dei Ports di FreeBSD.
Il supporto a PHP in FreeBSD è estremamente modulare così l’installazione base è molto limitata. È molto facile aggiungere supporto usando il port lang/php5-extensions. Questo port fornisce un interfaccia a menu per l’installazione di estensioni a PHP. Alternativamente le singole estensioni possono essere installate usando il port appropriato.
Ad esempio, per aggiungere supporto al database MySQL a PHP5, semplicemente installa databases/php5-mysql.
Dopo aver installato un’estensione, il server Apache deve essere riavviato per caricare i cambiamenti della nuova configurazione:
# apachectl gracefulIl File Transfer Protocol (FTP) fornisce agli utenti un semplice modo di trasferire file da e verso un server FTP. FreeBSD include software per server FTP nel sistema base. Questo rende l’installazione e l’ammininistrazione di un server FTP molto semplice.
Il più importante passo di configurazione è decidere a quali account saraà permesso accedere al server FTP. Un sistema normale FreeBSD ha un certo numero di account di sistema usati per vari demoni, ma agli utenti estranei non dovrebbe essere permesso di loggarsi con questi account. Il file /etc/ftpusers è una lista di utenti a cui è negato l’accesso FTP. Di default include gli account di sistema sopra citati ma è possibile aggiungere utenti specifici che non dovrebbero avere accesso FTP.
Può essere che tu voglia restringere l’accesso ad alcuni utenti senza impedir loro di usare completamente FTP. Ciò può essere ottenuto con il file /etc/ftpchroot. Questo file elenca utenti e gruppi soggetti a restrizioni di accesso FTP. La pagina di manuale ftpchroot(5) ha tutti i dettagli così non sarà descritta qui.
Se tu volessi abilitare accesso anonimo FTP al tuo server, devi creare un utente chiamato ftp sul tuo sistema FreeBSD. Gli utenti allora potranno loggarsi al tuo server FTP con uno username di ftp o anonymous e con una password qualsiasi (di norma dovrebbe essere usato un indirizzo email dell’utente come password). Il server FTP chiamerà chroot(2) quando un utente anonimo si logga, per restringere l’accesso solo alla home directory di ftp.
Ci sono due file di testo che specificano messaggi di benvenuto per i client FTP. Il contenuto del file /etc/ftpwelcome sarà mostrato agli utenti prima che raggiungano il prompt del login. Dopo un login di successo, il contenuto del file /etc/ftpmotd sarà mostrato. Nota che il percorso di questo file è relativo all’ambiente di login, così saraà mostrato il file ~ftp/etc/ftpmotd.
Una volta che il server FTP è stato configurato correttamente, deve essere abilitato in /etc/inetd.conf. Tutto ciò che viene richiesto è rimuovere il simbolo di commento "#" dall’inizio della linea relativa a ftpd:
ftp stream tcp nowait root /usr/libexec/ftpd ftpd -l
Come spiegato in Ricaricare il file di configurazione di inetd, la configurazione di inetd deve essere ricaricata dopo che che questo file di configurazione è stato cambiato.
Ora puoi loggarti al tuo server FTP digitando:
% ftp localhostIl demone ftpd usa syslog(3) per loggare i mesaggi. Di default il demone dei log di sistema girerà i messaggi relativi a FTP nel file /var/log/xferlog. La posizione del log FTP può essere modificata cambiando la seguente linea in /etc/syslog.conf:
ftp.info /var/log/xferlog
Presta attenzione ai problemi potenziali correlati all’esecuzione di un server FTP anonimo. In particolare, dovresti pensarci due volte prima di permettere agli utenti anonimi di fare upload di file. Potresti scoprire che il tuo sito FTP è diventato un forum per il commercio di software commerciale senza licenza o anche peggio. Se hai veramente bisogno di permettere upload FTP anonimi, allora dovresti impostare i permessi in modo che questi file non possano essere letti da altri utenti fino a che non siano stati revisionati.
Samba è un popolare pacchetto software open source che fornisce servizi di file e stampa per client Microsoft® Windows®. Tali client possono connettersi ed usare un file system FreeBSD come se fosse un disco locale, o stampanti FreeBSD come se fossero stampanti locali.
Il pacchetto software Samba dovrebbe essere incluso nel tuo media di installazione FreeBSD. Se non hai installato Samba quando hai installato per la prima volta FreeBSD, puoi sempre installarlo dal port o pacchetto net/samba3.
Un file di configurazione di Samba di default è installato in /usr/local/shared/examples/smb.conf.default. Questo file deve essere copiato in /usr/local/etc/smb.conf e personalizzato prima che Samba possa essere usato.
Il file smb.conf contiene informazione di configurazione runtime per Samba, come le definizioni delle stampanti e "share di file system" che vorresti condividere con Windows® client. Il pacchetto Samba include un tool basato sul web chiamato swat che fornisce un modo semplice di configurare il file smb.conf.
Il Samba Web Administration Tool (SWAT) viene eseguito come demone da inetd. Quindi, dovresti togliere i commenti alla seguente linea in /etc/inetd.conf prima che swat possa essere usato per configurare Samba:
swat stream tcp nowait/400 root /usr/local/sbin/swat swat
Come spiegato in Ricaricare il file di configurazione di inetd, la configurazione di inetd deve essere ricaricata dopo che questo file di configurazione è stato cambiato.
Una volta che swat è stato abilitato in inetd.conf, puoi usare un browser per connetterti a http://localhost:901. Dovrai prima loggarti con l’account di sistema root.
Una volta che ti sei loggato con successo alla pagina principale di configurazione di Samba, puoi navigare la documentazione di sistema, o iniziare cliccando sul tab Globals. La sezione Globals corrisponde alle variabili che sono impostate nella sezione [global] di /usr/local/etc/smb.conf.
Sia che tu stia usando swat o che tu stia editando direttamente /usr/local/etc/smb.conf, le prime direttive che tu puoi incontrare quando configuri Samba sono:
workgroupNome dominio NT o nome Workgroup per i computer che accedono a questo server.
netbios nameQuesto imposta il nome NetBIOS attraverso il quale un Samba è conosciuto. Di default è lo stesso della prima parte del nome host DNS.
server stringQuesto imposta la stringa che sarà mostrata con il comando net view e con alcuni altri strumenti di rete che cercano di mostrare testo descrittivo sul server.
Due delle più importanti impostazioni in /usr/local/etc/smb.conf sono i modelli di sicurezza usati, ed il formato delle password di backend per utenti client. Le seguenti direttive controllano queste opzioni:
securityLe due più comuni opzioni in questo caso sono security = share e security = user. Se i tuoi client usano nomi utente che sono gli stessi dei nomi utenti sulla tua macchina FreeBSD, allora vorrai sicurezza di tipo user. Questa è la policy di sicurezza di default e richiede ai client prima di loggarsi prima che possano accedere a risorse condivise.
Nel modello di sicurezza di tipo share, i client non hanno bisogno di loggarsi al server con una valida coppia username e password prima che provino a connettersi a risorse condivise. Questo è il modello di sicurezza di default per versioni precedenti di Samba.
passdb backendSamba ha molti modelli diversi di backend di autenticazione. Puoi autenticare i client con LDAP, NIS+, un database SQL, o un file di password modificato. Il metodo di autenticazione di default è smbpasswd, e questo sarà l’unico coperto qui.
Assumendo che il backend usato sia quello di default, smbpasswd, il file /usr/local/private/smbpasswd deve essere creato per permettere a Samba di autenticare i client. Se tu volessi dare ai tuoi account UNIX® accesso da client Windows®, usa il seguente comando:
# smbpasswd -a usernamePer favore consulta l' Official Samba HOWTO HOWTO Ufficiale di Samba per informazioni addizionali sulle opzioni di configurazione. Con le basi delineate qui, dovresti avere tutto ciò di cui hai bisogno per avviare Samba.
Il port net/samba3 aggiunge un nuovo script di avvio, che può essere usato per controllare Samba. Per abilitare questo script, in modo tale da essere usato per esempio per avviare fermare o far ripartire Samba, aggiungi la riga seguente al file /etc/rc.conf:
samba_enable="YES"
Oppure, per un controllo più accurato:
nmbd_enable="YES"
smbd_enable="YES"
In questo modo Samba viene avviato automaticamente ad ogni avvio del sistema. |
Per avviare Samba digita:
# /usr/local/etc/rc.d/samba start
Starting SAMBA: removing stale tdbs :
Starting nmbd.
Starting smbd.Fai riferimento alla Usare rc con FreeBSD per ulteriori informazioni sull’uso degli script rc.
Samba attualmente consiste di tre demoni separati. Dovresti osservare che entrambi nmbd e smbd siano avviati dallo script samba. Se hai abilitato servizi di risoluzione di nomi winbind in smb.conf, allora osserverai che anche il demone winbindd è avviato.
Puoi anche fermare Samba in ogni istante digitando:
# /usr/local/etc/rc.d/samba stopSamba è una suite complessa di software con funzionalità che permette una larga integrazione con reti Microsoft® Windows®. Per maggiori informazioni sulle funzionalità al di là dell’installazione di base descritta qui per favore consulta http://www.samba.org.
Al passare del tempo, il clock di un computer tende a perdere la sincronizzazione. Il Network Time Protocol (NTP) fornisce un modo per assicurarti che il tuo clock sia accurato.
Molti servizi Internet si basano sul fatto che il clock del computer sia accurato, o comunque traggono notevole beneficio da questo fatto. Per esempio, un web server può ricevere richieste di inviare un file se questo è stato modificato da una certa data. In un ambiente locale di rete, è essenziale che i computer che condividono i file dallo stesso file server abbiano clock sincronizzati cosicchè i timestamp dei file siano consistenti. Anche servizi come cron(8) si basano su un clock di sistema accurato per eseguire comandi al momento specificato.
FreeBSD è dotato del server ntpd(8) NTP che può essere usato per interrogare altri server NTP per impostare il clock sulla tua macchina o fornire servizi di time ad altri.
Per sincronizzare il tuo clock, avrai bisogno di scegliere uno o più server NTP da usare. Il tuo amministratore di rete o ISP potrebbe aver impostato un server NTP, a questo scopo - controlla la loro documentazione per vedere se questo è il caso. C’è una lista online di server NTP pubblicamente accessibili che tu puoi usare per trovare un server NTP vicino a te. Accertati di essere al corrente della politica di ogni server che scegli, e chiedi il permesso se necessario.
Scegliere molti server NTP non connessi fra loro è una buona idea in caso uno dei server che stai usando diventa irraggiungibile o il suo clock è inaffidabile. ntpd(8) usa le risposte che riceve da altri server in modo intelligente; favorirà server inaffidabili meno di quelli affidabili.
Se desideri solo sincronizzare il tuo clock al momento del boot della macchina, puoi usare ntpdate(8). Questo può essere appropriato per alcune macchine desktop che sono rebootate di frequente e richiedono sincronizzazione non frequente, ma le altre macchine dovrebbero eseguire ntpd(8).
Usare ntpdate(8) al momento del boot è una buona idea per le macchine che eseguono ntpdate(8). Il programma ntpd(8) cambia il clock gradualmente, mentre ntpdate(8) imposta il clock, indipentemente da quanto grande sia la differenza fra l’impostazione di clock corrente di una macchina e l’ora corretta.
Per abilitare ntpdate(8) al momento del boot, aggiungi ntpdate_enable="YES" a /etc/rc.conf. Avrai anche bisogno di specificare tutti i server con i quali ti desideri sincronizzare ed ogni flags passato a ntpdate(8) in ntpdate_flags.
NTP è configurato dal file /etc/ntp.conf nel formato descritto da ntp.conf(5). Questo è un semplice esempio:
server ntplocal.example.com prefer server timeserver.example.org server ntp2a.example.net driftfile /var/db/ntp.drift
L’opzione server specifica quali server siano da usare, con un server elencato su ogni linea. Se un server è specificato con l’argomento prefer, come con ntplocal.example.com, quel server saraà preferito rispetto ad altri. Una risposta da un server preferito sarà scartata se differisce in modo significativo dalle risposte di altri server, altrimenti sarà usata senza nessuna considerazione delle altre risposte. L’argomento prefer è normalmente usato per server NTP che sono noti per essere molto accurati, come quelli con hardware a monitoraggio speciale del tempo.
L’opzione driftfile specifica quale file sia usato per conservare la frequenza di scostamento dal clock di sistema. Il programma ntpd(8) usa questo dato per compensare automaticamente le imprecisioni naturali del clock, permettendo di mantenere una impostazione ragionevolmente corretta anche se gli è impedito di accedere a tutte le sorgenti di sincronizzazione tempo esterne per un certo periodo di tempo.
L’opzione driftfile specifica quale file sia usato per conservare informazioni sulle risposte precedenti dai server NTP che usi. Questo file contiene informazioni interne per NTP. Non dovrebbe essere modificato da altri processi.
Di default, il tuo server NTP sarà accessibile a tutti gli host su Internet. L’opzione restrict in /etc/ntp.conf ti permette di controllare quali macchine possano accedere al tuo server.
Se vuoi negare a tutte le macchine accesso al tuo server NTP, aggiungi la seguente linea a /etc/ntp.conf:
restrict default ignore
Inoltre questo settaggio vieta l’accesso al tuo server dai server elencati nella tua configurazione locale. Se hai bisogno di sincronizzare il tuo server NTP con un server NTP esterno devi permettere il server che vuoi usare. Guada la pagina man ntp.conf(5) per ulteriori dettagli. |
Se vuoi permettere solo alle macchine della tua rete di sincronizzare il loro clock con il tuo server, ma assicurarti che non gli sia permesso configurare il server o che non sianousate come punto di riferimento per sincronizzarsi, aggiungi
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
invece, dove`192.168.1.0` è un indirizzo IP sulla tua rete e 255.255.255.0 è la netmask della tua rete.
/etc/ntp.conf può contenere molte opzioni restrict. Per maggiori dettagli, consulta la sezione Access Control Support di ntp.conf(5).
Per assicurarsi che il server NTP sia avviato al momento del boot, aggiungi la linea ntpd_enable="YES" a /etc/rc.conf. Se desideri passare flag addizionali a ntpd(8), edita il parametro ntpd_flags in /etc/rc.conf.
Per avviare il server senza riavviare la tua macchina, esegui ntpd accertandoti di specificare ogni parametro addizionale in ntpd_flags presente in /etc/rc.conf. Per esempio:
# ntpd -p /var/run/ntpd.pidIl programma ntpd(8) non necessita di una connessione permanente ad Internet per funzionnare correttamente. Comunque, se hai una connessione temporanea che è configurata per effettuare una chiamata su richiesta, è una buona idea evitare che il traffico NTP causi la chiamata o mantenga la connessione attiva. Se stai usando PPP utente, puoi usare le direttive filter in /etc/ppp/ppp.conf. Per esempio:
set filter dial 0 deny udp src eq 123 # Prevent NTP traffic from initiating dial out set filter dial 1 permit 0 0 set filter alive 0 deny udp src eq 123 # Prevent incoming NTP traffic from keeping the connection open set filter alive 1 deny udp dst eq 123 # Prevent outgoing NTP traffic from keeping the connection open set filter alive 2 permit 0/0 0/0
Pre maggiori dettagli consulta la sezione PACKET FILTERING in ppp(8) e gli esempi in /usr/shared/examples/ppp/.
Alcuni provider di accesso ad Internet bloccano le porte dal numero basso, impedendo ad NTP di funzionare dato che le repliche non raggiungono mai la tua macchina. |
FreeBSD è disponibile in confezioni (i CD di FreeBSD, del software aggiuntivo, e la documentazione cartacea) presso svariati rivenditori:
CompUSA
WWW: http://www.compusa.com/
Frys Electronics
WWW: http://www.frys.com/
I set di CD e DVD di FreeBSD sono disponibili presso molti rivenditori on-line:
BSD Mall by Daemon News
PO Box 161
Nauvoo, IL 62354
Stati Uniti d’America
Telefono: +1 866 273-6255
Fax: +1 217 453-9956
Email: <sales@bsdmall.com>
WWW: http://www.bsdmall.com/freebsd1.html
BSD-Systems
Email: <info@bsd-systems.co.uk>
WWW: http://www.bsd-systems.co.uk
FreeBSD Mall, Inc.
3623 Sanford Street
Concord, CA 94520-1405
Stati Uniti d’America
Telefono: +1 925 674-0783
Fax: +1 925 674-0821
Email: <info@freebsdmall.com>
WWW: http://www.freebsdmall.com/
Hinner EDV
St. Augustinus-Str. 10
D-81825 München
Germania
Telefono: (089) 428 419
WWW: http://www.hinner.de/linux/freebsd.html
Ikarios
22-24 rue Voltaire
92000 Nanterre
Francia
WWW: http://ikarios.com/form/#freebsd
JMC Software
Irlanda
Telefono: 353 1 6291282
WWW: http://www.thelinuxmall.com
Linux CD Mall
Private Bag MBE N348
Auckland 1030
Nuova Zelanda
Telefono: +64 21 866529
WWW: http://www.linuxcdmall.co.nz/
The Linux Emporium
Hilliard House, Lester Way
Wallingford
OX10 9TA
Regno Unito
Telefono: +44 1491 837010
Fax: +44 1491 837016
WWW: http://www.linuxemporium.co.uk/products/freebsd/
Linux+ DVD Magazine
Lewartowskiego 6
Warsaw
00-190
Polonia
Telefono: +48 22 860 18 18
Email: <editors@lpmagazine.org>
WWW: http://www.lpmagazine.org/
Linux System Labs Australia
21 Ray Drive
Balwyn North
VIC - 3104
Australia
Telefono: +61 3 9857 5918
Fax: +61 3 9857 8974
WWW: http://www.lsl.com.au
LinuxCenter.Ru
Galernaya Street, 55
Saint-Petersburg
190000
Russia
Telefono: +7-812-3125208
Email: <info@linuxcenter.ru>
WWW: http://linuxcenter.ru/freebsd
Se sei un rivenditore e vuoi vendere i CDROM di FreeBSD, contatta uno dei distributori seguenti:
Cylogistics
809B Cuesta Dr., #2149
Mountain View, CA 94040
Stati Uniti d’America
Telefono: +1 650 694-4949
Fax: +1 650 694-4953
Email: <sales@cylogistics.com>
WWW: http://www.cylogistics.com/
Ingram Micro
1600 E. St. Andrew Place
Santa Ana, CA 92705-4926
Stati Uniti d’America
Telefono: 1 (800) 456-8000
WWW: http://www.ingrammicro.com/
Kudzu, LLC
7375 Washington Ave. S.
Edina, MN 55439
Stati Uniti d’America
Telefono: +1 952 947-0822
Fax: +1 952 947-0876
Email: <sales@kudzuenterprises.com>
LinuxCenter.Ru
Galernaya Street, 55
Saint-Petersburg
190000
Russia
Phone: +7-812-3125208
Email: <info@linuxcenter.ru>
WWW: http://linuxcenter.ru/freebsd
Navarre Corp
7400 49th Ave South
New Hope, MN 55428
Stati Uniti d’America
Telefono: +1 763 535-8333
Fax: +1 763 535-0341
WWW: http://www.navarre.com/
I sorgenti ufficiali di FreeBSD sono disponibili via FTP anonimo da una serie di siti mirror sparsi in tutto il mondo. Il sito ftp://ftp.FreeBSD.org/pub/FreeBSD/ è ben gestito e permette un gran numero di connessioni, ma ti conviene probabilmente trovare un sito mirror a te "più vicino" (soprattutto se decidi di configurare una sorta di sito mirror).
Il database dei siti mirror di FreeBSD è più preciso della lista contenuta in questo manuale, poichè ottiene le informazioni direttamente dal DNS anziché affidarsi a una lista statica di host.
Inoltre, FreeBSD è disponibile via FTP anonimo dai seguenti siti mirror. Se decidi di procurarti FreeBSD via FTP anonimo, usa per favore un sito a te vicino. I siti mirror elencati come "Siti Mirror Primari" hanno tipicamente l’intero archivio di FreeBSD (tutte le versioni oggi disponibili per ognuna delle architetture) ma probabilmente scaricherai più velocemente da un sito che è nel tuo stato o regione. I siti di ogni stato contengono le versioni più recenti per le architetture più popolari ma potrebbero non contenere l’intero archivio di FreeBSD. Tutti i siti permettono l’accesso tramite FTP anonimo e alcuni permettono l’accesso anche con altri metodi. I metodi di accesso disponibili per ogni sito sono elencati fra parentesi dopo il nome dell’host.
Central Servers, Primary Mirror Sites, Armenia, Australia, Austria, Brazil, Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hong Kong, Ireland, Japan, Korea, Latvia, Lithuania, Netherlands, New Zealand, Norway, Poland, Russia, Saudi Arabia, Slovenia, South Africa, Spain, Sweden, Switzerland, Taiwan, Ukraine, United Kingdom, United States of America.
(aggiornato al UTC)
Central Servers
ftp://ftp.FreeBSD.org/pub/FreeBSD/ (ftp / ftpv6 / http://ftp.FreeBSD.org/pub/FreeBSD/ / http://ftp.FreeBSD.org/pub/FreeBSD/)
Primary Mirror Sites
In case of problems, please contact the hostmaster <mirror-admin@FreeBSD.org> for this domain.
ftp://ftp4.FreeBSD.org/pub/FreeBSD/ (ftp / ftpv6 / http://ftp4.FreeBSD.org/pub/FreeBSD/ / http://ftp4.FreeBSD.org/pub/FreeBSD/)
ftp://ftp10.FreeBSD.org/pub/FreeBSD/ (ftp / ftpv6 / http://ftp10.FreeBSD.org/pub/FreeBSD/ / http://ftp10.FreeBSD.org/pub/FreeBSD/)
ftp://ftp14.FreeBSD.org/pub/FreeBSD/ (ftp / http://ftp14.FreeBSD.org/pub/FreeBSD/)
Armenia
In case of problems, please contact the hostmaster <hostmaster@am.FreeBSD.org> for this domain.
Australia
In case of problems, please contact the hostmaster <hostmaster@au.FreeBSD.org> for this domain.
Austria
In case of problems, please contact the hostmaster <hostmaster@at.FreeBSD.org> for this domain.
Brazil
In case of problems, please contact the hostmaster <hostmaster@br.FreeBSD.org> for this domain.
Czech Republic
In case of problems, please contact the hostmaster <hostmaster@cz.FreeBSD.org> for this domain.
Denmark
In case of problems, please contact the hostmaster <staff@dotsrc.org> for this domain.
Estonia
In case of problems, please contact the hostmaster <hostmaster@ee.FreeBSD.org> for this domain.
Finland
In case of problems, please contact the hostmaster <hostmaster@fi.FreeBSD.org> for this domain.
France
In case of problems, please contact the hostmaster <hostmaster@fr.FreeBSD.org> for this domain.
ftp://ftp1.fr.FreeBSD.org/pub/FreeBSD/ (ftp / http://ftp1.fr.FreeBSD.org/pub/FreeBSD/ / rsync)
ftp://ftp6.fr.FreeBSD.org/pub/FreeBSD/ (ftp / rsync)
Germany
In case of problems, please contact the hostmaster <de-bsd-hubs@de.FreeBSD.org> for this domain.
ftp://ftp1.de.FreeBSD.org/freebsd/ (ftp / http://www1.de.FreeBSD.org/freebsd/ / rsync://rsync3.de.FreeBSD.org/freebsd/)
ftp://ftp2.de.FreeBSD.org/pub/FreeBSD/ (ftp / http://ftp2.de.FreeBSD.org/pub/FreeBSD/ / rsync)
ftp://ftp4.de.FreeBSD.org/FreeBSD/ (ftp / http://ftp4.de.FreeBSD.org/pub/FreeBSD/)
ftp://ftp7.de.FreeBSD.org/pub/FreeBSD/ (ftp / http://ftp7.de.FreeBSD.org/pub/FreeBSD/)
Greece
In case of problems, please contact the hostmaster <hostmaster@gr.FreeBSD.org> for this domain.
Hong Kong
Ireland
In case of problems, please contact the hostmaster <hostmaster@ie.FreeBSD.org> for this domain.
ftp://ftp3.ie.FreeBSD.org/pub/FreeBSD/ (ftp / rsync)
Japan
In case of problems, please contact the hostmaster <hostmaster@jp.FreeBSD.org> for this domain.
Korea
In case of problems, please contact the hostmaster <hostmaster@kr.FreeBSD.org> for this domain.
Latvia
In case of problems, please contact the hostmaster <hostmaster@lv.FreeBSD.org> for this domain.
Lithuania
In case of problems, please contact the hostmaster <hostmaster@lt.FreeBSD.org> for this domain.
Netherlands
In case of problems, please contact the hostmaster <hostmaster@nl.FreeBSD.org> for this domain.
New Zealand
Norway
In case of problems, please contact the hostmaster <hostmaster@no.FreeBSD.org> for this domain.
ftp://ftp.no.FreeBSD.org/pub/FreeBSD/ (ftp / rsync)
Poland
In case of problems, please contact the hostmaster <hostmaster@pl.FreeBSD.org> for this domain.
ftp2.pl.FreeBSD.org
Russia
In case of problems, please contact the hostmaster <hostmaster@ru.FreeBSD.org> for this domain.
Saudi Arabia
In case of problems, please contact the hostmaster <ftpadmin@isu.net.sa> for this domain.
Slovenia
In case of problems, please contact the hostmaster <hostmaster@si.FreeBSD.org> for this domain.
South Africa
In case of problems, please contact the hostmaster <hostmaster@za.FreeBSD.org> for this domain.
{mirrors-south-africa-ftp} (ftp)
Spain
In case of problems, please contact the hostmaster <hostmaster@es.FreeBSD.org> for this domain.
Sweden
In case of problems, please contact the hostmaster <hostmaster@se.FreeBSD.org> for this domain.
ftp://ftp2.se.FreeBSD.org/pub/FreeBSD/ (ftp / rsync://ftp2.se.FreeBSD.org/)
ftp://ftp4.se.FreeBSD.org/pub/FreeBSD/ (ftp / ftp://ftp4.se.FreeBSD.org/pub/FreeBSD/ / http://ftp4.se.FreeBSD.org/pub/FreeBSD/ / http://ftp4.se.FreeBSD.org/pub/FreeBSD/ / rsync://ftp4.se.FreeBSD.org/pub/FreeBSD/ / rsync://ftp4.se.FreeBSD.org/pub/FreeBSD/)
ftp://ftp6.se.FreeBSD.org/pub/FreeBSD/ (ftp / http://ftp6.se.FreeBSD.org/pub/FreeBSD/)
Switzerland
In case of problems, please contact the hostmaster <hostmaster@ch.FreeBSD.org> for this domain.
Taiwan
In case of problems, please contact the hostmaster <hostmaster@tw.FreeBSD.org> for this domain.
ftp://ftp.ch.FreeBSD.org/pub/FreeBSD/ (ftp / ftp://ftp.tw.FreeBSD.org/pub/FreeBSD/ / rsync / rsyncv6)
ftp://ftp2.tw.FreeBSD.org/pub/FreeBSD/ (ftp / ftp://ftp2.tw.FreeBSD.org/pub/FreeBSD/ / http://ftp2.tw.FreeBSD.org/pub/FreeBSD/ / http://ftp2.tw.FreeBSD.org/pub/FreeBSD/ / rsync / rsyncv6)
ftp://ftp6.tw.FreeBSD.org/pub/FreeBSD/ (ftp / http://ftp6.tw.FreeBSD.org/ / rsync)
ftp://ftp11.tw.FreeBSD.org/pub/FreeBSD/ (ftp / http://ftp11.tw.FreeBSD.org/FreeBSD/)
Ukraine
ftp://ftp.ua.FreeBSD.org/pub/FreeBSD/ (ftp / http://ftp.ua.FreeBSD.org/pub/FreeBSD/)
ftp://ftp6.ua.FreeBSD.org/pub/FreeBSD/ (ftp / http://ftp6.ua.FreeBSD.org/pub/FreeBSD / rsync://ftp6.ua.FreeBSD.org/FreeBSD/)
United Kingdom
In case of problems, please contact the hostmaster <hostmaster@uk.FreeBSD.org> for this domain.
ftp://ftp2.uk.FreeBSD.org/pub/FreeBSD/ (ftp / rsync://ftp2.uk.FreeBSD.org/ftp.freebsd.org/pub/FreeBSD/)
United States of America
In case of problems, please contact the hostmaster <hostmaster@us.FreeBSD.org> for this domain.
ftp://ftp4.us.FreeBSD.org/pub/FreeBSD/ (ftp / ftpv6 / http://ftp4.us.FreeBSD.org/pub/FreeBSD/ / http://ftp4.us.FreeBSD.org/pub/FreeBSD/)
ftp://ftp13.us.FreeBSD.org/pub/FreeBSD/ (ftp / http://ftp13.us.FreeBSD.org/pub/FreeBSD/ / rsync)
ftp://ftp14.us.FreeBSD.org/pub/FreeBSD/ (ftp / http://ftp14.us.FreeBSD.org/pub/FreeBSD/)
Il CVS Anonimo (anche conosciuto come anoncvs) è una caratteristica del programma di utilità CVS contenuto in FreeBSD che serve per sincronizzarsi con un deposito CVS remoto (in gergo repository CVS). Tra le altre cose, permette agli utenti di FreeBSD di realizzare, senza avere particolari permessi, operazioni CVS in sola lettura su uno dei server anoncvs ufficiali del progetto FreeBSD. Per utilizzarlo è sufficiente impostare la variabile di ambiente CVSROOT facendola puntare al server anoncvs appropriato, immettere la password "anoncvs" con il comando cvs login, e poi usare il comando cvs(1) per accederci come se fosse un deposito locale.
Il comando |
Benché si possa dire che i servizi CVSup e anoncvs realizzino sostanzialmente le stesse funzioni, ci sono vari particolari che possono influenzare la scelta di un metodo di sincronizzazione piuttosto dell’altro. Per dirla in breve, CVSup è più efficiente nell’uso delle risorse di rete ed è il più avanzato tecnicamente tra i due, ma tutto questo ha un prezzo. Per usare CVSup, bisogna installare e configurare un client speciale prima di poter scaricare qualcosa, e si può scaricare solo blocchi piuttosto grossi che CVSup chiama collezioni.
Anoncvs, al contrario, può essere usato per esaminare qualunque cosa a partire da un singolo file fino a uno specifico programma (come ls o grep) specificando il nome del modulo CVS. Ovviamente, anoncvs è adatto solo per operazioni di sola lettura sul deposito CVS, quindi se hai intenzione di supportare lo sviluppo locale in uno dei depositi condivisi del progetto FreeBSD allora CVSup è in realtà l’unica opzione.
La configurazione di cvs(1) per usare un deposito CVS Anonimo è semplicemente una questione di impostare la variabile di ambiente CVSROOT affinché punti a uno dei server anoncvs del progetto FreeBSD. Al momento della stesura di questo testo sono disponibili i seguenti server:
Austria: :pserver:anoncvs@anoncvs.at.FreeBSD.org:/home/ncvs (Usa cvs login ed inserisci qualunque password quando richiesta.)
Francia: :pserver:anoncvs@anoncvs.fr.FreeBSD.org:/home/ncvs (pserver (password "anoncvs"), ssh (nessuna password))
Germania: :pserver:anoncvs@anoncvs.de.FreeBSD.org:/home/ncvs (Usa cvs login ed inserisci la password "anoncvs" quando richiesta.)
Germania: :pserver:anoncvs@anoncvs2.de.FreeBSD.org:/home/ncvs (rsh, pserver, ssh, ssh/2022)
Giappone: :pserver:anoncvs@anoncvs.jp.FreeBSD.org:/home/ncvs (Usa cvs login ed inserisci la password "anoncvs" quando richiesta.)
USA: freebsdanoncvs@anoncvs.FreeBSD.org:/home/ncvs (solo ssh - nessuna password)
SSH HostKey: 1024 a1:e7:46:de:fb:56:ef:05:bc:73:aa:91:09:da:f7:f4 root@sanmateo.ecn.purdue.edu SSH2 HostKey: 1024 52:02:38:1a:2f:a8:71:d3:f5:83:93:8d:aa:00:6f:65 ssh_host_dsa_key.pub
USA: anoncvs@anoncvs1.FreeBSD.org:/home/ncvs (solo ssh - nessuna password)
SSH HostKey: 1024 8b:c4:6f:9a:7e:65:8a:eb:50:50:29:7c:a1:47:03:bc root@ender.liquidneon.com SSH2 HostKey: 2048 4d:59:19:7b:ea:9b:76:0b:ca:ee:da:26:e2:3a:83:b8 ssh_host_dsa_key.pub
Dato che CVS permette di estrarre (nel suo gergo: "check out") qualsiasi versione dei sorgenti di FreeBSD che sia mai esistita (o, in alcuni casi, che esisterà), è bene familiarizzare con il parametro revisione (-r) di cvs(1) e sapere quali valori può assumere nel deposito del progetto FreeBSD.
Ci sono due tipi di tag, i tag di revisione e i tag di ramo. Un tag di revisione fa riferimento ad una revisione specifica. Il suo significato rimane lo stesso di giorno in giorno. Un tag di ramo, d’altro canto, si riferisce sempre all’ultima revisione relativa a una specifica linea di sviluppo. Dato che un tag di ramo non si riferisce ad una revisione specifica, esso potrebbe avere un significato diverso da un giorno con l’altro.
La Tag CVS contiene i tag di revisione che possono essere interessanti per gli utenti. Tuttavia, nessuno di questi tag è valido per la collezione dei port poichè questa non ha revisioni multiple.
Quando specifichi un tag di ramo, normalmente ricevi l’ultima versione dei file relativa a quella linea di sviluppo. Se vuoi ricevere una versione precedente, puoi farlo specificando la data con il parametro -D date. Si rimanda alla pagina man di cvs(1) per ulteriori dettagli.
Benché sia consigliata un’attenta lettura della pagina man di cvs(1) prima di fare qualsiasi cosa, seguono alcuni veloci esempi che spiegano in modo essenziale l’uso del CVS Anonimo:
% setenv CVSROOT :pserver:anoncvs@anoncvs.jp.FreeBSD.org:/home/ncvs
% cvs login
Alla richiesta, inserire la password «anoncvs».
% cvs co ls% cvs -d freebsdanoncvs@anoncvs.FreeBSD.org:/home/ncvs co src
The authenticity of host 'anoncvs.freebsd.org (128.46.156.46)' can't be established.
DSA key fingerprint is 52:02:38:1a:2f:a8:71:d3:f5:83:93:8d:aa:00:6f:65.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'anoncvs.freebsd.org' (DSA) to the list of known hosts.% setenv CVSROOT :pserver:anoncvs@anoncvs.jp.FreeBSD.org:/home/ncvs
% cvs login
Alla richiesta, inserire la password «anoncvs».
% cvs co -rRELENG_6 ls% setenv CVSROOT :pserver:anoncvs@anoncvs.jp.FreeBSD.org:/home/ncvs
% cvs login
Alla richiesta, inserire la password «anoncvs».
% cvs rdiff -u -rRELENG_5_3_0_RELEASE -rRELENG_5_4_0_RELEASE ls% setenv CVSROOT :pserver:anoncvs@anoncvs.jp.FreeBSD.org:/home/ncvs
% cvs login
Alla richiesta, inserire la password «anoncvs».
% cvs co modules
% more modules/modulesLe seguenti risorse addizionali possono essere utili nell’apprendimento del CVS:
CVS Tutorial dal Cal Poly.
CVS Home, la comunità di sviluppo e supporto del CVS.
CVSWeb è l’interfaccia web di CVS relativa al progetto FreeBSD.
CTM è un metodo per mantenere sincronizzati un albero di directory remoto e uno centralizzato. È stato sviluppato per l’albero dei sorgenti di FreeBSD, anche se con il passare del tempo, altre persone lo hanno trovano utile per altri scopi. A tutt’oggi esiste pochissima documentazione sul processo della creazione delle delta, quindi contattate la mailing list ctm-users-desc per avere più informazioni e nel caso voleste usare CTM per altri scopi.
CTM fornisce una copia locale dell’albero dei sorgenti di FreeBSD. Ci sono molte "varietà" di alberi disponibili. Che tu voglia seguire l’intero albero CVS o solo uno dei rami, CTM può fornirti i dati che ti servono. Se sei uno sviluppatore attivo di FreeBSD, ma hai una connettività TCP/IP di bassa qualità o non esistente, o semplicemente desideri ricevere le modifiche in modo automatico, CTM fa al caso tuo. Riceverai fino a tre delta giornaliere per i rami più attivi. Tuttavia, puoi considerare che li puoi avere attraverso l’invio automatico di email. Le dimensioni degli aggiornamenti sono sempre più piccole possibile. Questi sono in genere meno di 5K, con occasionali (uno su dieci) aggiornamenti da 10-50K e qualcuno più grande (100K o più) di tanto in tanto.
Devi anche essere cosciente delle varie insidie relativi all’uso di sorgenti in via di sviluppo e non provenienti da release pronte. Questo è vero in particolare per i sorgenti "current" (correnti). È raccomandata la lettura di Restare in "current" con FreeBSD.
Ti servono due cose: il programma CTM, e le delta iniziali da dargli in pasto (per arrivare ai livelli della "current").
Il programma CTM fa parte di FreeBSD fin dalla release della versione 2.0 e, se hai una copia dei sorgenti disponibile, risiede in /usr/src/usr.sbin/ctm.
Le "delta" da dare in pasto a CTM si possono avere in due modi: tramite FTP o email. Se puoi utilizzare FTP via Internet allora i seguenti siti supportano l’accesso a CTM:
vedi anche la sezione mirror.
Entra via FTP nella directory giusta e, da lì, inizia col trasferire il file README.
Se invece desideri ricevere le delta per email:
Iscriviti ad una delle liste di distribuzione di CTM. ctm-cvs-cur-desc supporta l’interno albero CVS. ctm-src-cur-desc supporta il ramo di sviluppo current. mailing list di distribuzione CTM del ramo src 4-STABLE supporta il ramo della release 4.X, ecc. (Se non sai come iscriverti a una lista, clicca sul nome della lista o raggiungi la pagina https://lists.freebsd.org e clicca sulla lista a cui ti vuoi iscrivere. La pagina della lista dovrebbe contenere tutte le informazioni necessarie per l’iscrizione.)
Quando inizierai a ricevere gli aggiornamenti CTM via email, puoi usare il programma ctm_rmail per scompattarli e per applicarli. In realtà, se vuoi avere un processo completamente automatizzato, puoi usare il programma ctm_rmail direttamente in un elemento di /etc/aliases. Esamina la pagina man di ctm_rmail per maggiori dettagli.
Indipendentemente dal metodo che utilizzi per ricevere le delta di CTM, dovresti iscriverti alla mailing list ctm-announce-desc. In futuro, questo sarà l’unico posto dove saranno postati gli annunci riguardanti il funzionamento del sistema CTM. Clicca sul nome della lista e segui le istruzioni per iscriverti. |
Prima che tu possa servirti delle delta di CTM, hai bisogno di un punto di partenza dal quale successivamente costruire le delta.
Innanzitutto dovresti determinare ciò che hai. Si può iniziare da un directory "vuota". Devi usare una delta iniziale "Empty" per iniziare il tuo albero CTM. Qualche volta può succedere che una di queste delta "iniziali" sia distribuita su un CD per tua convenienza, ma comunque, questo generalmente non avviene.
Poichè gli alberi sono molte decine di megabyte, puoi iniziare da qualcosa che hai a portata di mano. Se hai un CD di una release, puoi copiare o estrarre i sorgenti da lì. Questo salverà un significativo trasferimento di dati.
Puoi riconoscere queste delta "iniziali" dalla lettera X preceduta da un numero (per esempio src-cur.3210XEmpty.gz). Il nome che segue la lettera X corrisponde all’origine del tuo "seme" iniziale. Empty è una directory vuota. Di solito una transizione base a partire da Empty è prodotta ogni 100 delta. Strada facendo, queste avranno grandi dimensioni! Le dimensioni comuni per le delta XEmpty vanno dai 70 a 80 Megabyte di dati compressi con gzip.
Una volta che ti sei procurato una delta base come punto di partenza, avrai bisogno anche di tutte le delta successive aventi un numero maggiore.
Per applicare le delta, fai come segue:
# cd /where/ever/you/want/the/stuff
# ctm -v -v /where/you/store/your/deltas/src-xxx.*CTM decifra le delta compresse tramite il comando gzip, quindi non hai bisogno di decomprimerle con gunzip, e ciò salva spazio su disco.
Tranne in alcune circostanze, CTM non toccherà il tuo albero. Per verificare una delta puoi usare l’opzione -c e di fatto CTM non toccherà il tuo albero; verificherà soltanto l’integrità della delta e se questa può essere applicata in modo pulito al tuo albero attuale.
Ci sono altre opzioni di CTM, guarda la pagina man o ispeziona i sorgenti per maggiori dettagli.
Questo è davvero tutto ciò che devi sapere. Ogni volta che ottieni una delta, esegui CTM per aggiornare i tuoi sorgenti.
È meglio non rimuovere le delta che richiedono grandi tempi di scaricamento. Nel caso succeda qualche disgrazia non dovrai riscaricarle. Anche se hai solo dischetti floppy, considera l’uso di fdwrite per crearne una copia.
Allo stesso modo di uno sviluppatore potresti voler sperimentare delle modifiche nell’albero dei sorgenti. CTM supporta le modifiche locali in modo limitato: prima di verificare la presenza di un file foo, esso cerca foo.ctm. Se questo file esiste, CTM opererà su di esso piuttosto che su foo.
Questo comportamento offre un semplice modo per mantenere le modifiche locali: copia semplicemente il file che desideri modificare in un file con lo stesso nome e suffisso .ctm. Quindi puoi liberamente hackerare il codice, e CTM manterrà aggiornato il file .ctm.
Puoi determinare la lista delle modifiche che CTM apporterà ai tuoi sorgenti usando l’opzione -l di CTM.
Questo è utile se vuoi mantenere dei log delle modifiche, prima o dopo aver modificato in qualche modo i file, o solo perchè ti senti un pò paranoico.
Qualche volta potresti voler creare dei backup di tutti i file che saranno modificati da un aggiornamento di CTM.
Specificando l’opzione -B backup-file, CTM effettuerà il backup di tutti i file che saranno modificati da una certa delta CTM nel file backup-file.
Qualche volta potresti volere restringere la portata di un certo aggiornamento CTM, o potresti essere interessato ad estrarre solo pochi file da una serie di delta.
Puoi controllare la lista dei file sui quali CTM opererà specificando un’espressione regolare usando le opzioni -e e -x.
Per esempio, per estrarre una copia aggiornata del file lib/libc/Makefile dalla tua collezione di delta CTM, esegui i comandi seguenti:
# cd /dove/vuoi/estrarre/
# ctm -e '^lib/libc/Makefile' ~ctm/src-xxx.*Per ogni file specificato in una delta CTM, le opzioni -e e -x sono applicate nello stesso ordine in cui compaiono sulla riga di comando. Il file è processato da CTM solo se risulta idoneo a tutte le opzioni -e e -x ad esso applicate.
I più importanti:
Usare qualche tipo di autenticazione nel sistema CTM, in modo tale da permette l’identificazione di aggiornamenti CTM contraffatti.
Ripulire le opzioni di CTM, che confondono e sono tutt’altro che intuitive.
Esiste una serie di delta per la collezione dei ports, ma è ancora di poco interesse.
CTM/FreeBSD è disponibile via FTP anonimo dai siti mirror seguenti. Se decidi di procurarti CTM via FTP anonimo, per favore usa un sito a te vicino.
In caso di problemi, contatta la mailing list ctm-users-desc.
Se non trovi un mirror a te vicino o se il mirror è incompleto, prova ad usare qualche motore di ricerca come alltheweb.
CVSup è un pacchetto di software per distribuire ed aggiornare alberi di sorgenti da un deposito centrale CVS posto su un server remoto. I sorgenti di FreeBSD sono mantenuti in un deposito CVS su una macchina centrale di sviluppo situata in California. Con CVSup, gli utenti di FreeBSD possono facilmente mantenere aggiornati i loro alberi di sorgenti.
CVSup usa il cosiddetto modello ad estrazione per aggiornare. In questo modello, è compito del client chiedere al server gli aggiornamenti. Il server attente passivamente le richieste di aggiornamento dai suoi client. In questo modo tutti gli aggiornamenti sono incitati dal client. Il server non invia mai degli aggiornamenti che non sono stati richiesti. Gli utenti devono eseguire il client CVSup manualmente per ottenere un aggiornamento, oppure possono usare cron per eseguire automaticamente queste operazioni secondo stabilite regole.
Il termine CVSup, scritto in quel modo, si riferisce all’intero pacchetto di software. I suoi componenti principali sono il client cvsup che viene eseguito su ogni macchina degli utenti, e il server cvsupd che viene eseguito su ogni sito mirror di FreeBSD.
Leggendo la documentazione di FreeBSD e le mailling list, potresti notare dei riferimenti a sup. Sup è il predecessore di CVSup, e serviva per un simile scopo. CVSup sostanzialmente è usato allo stesso modo di sup e, di fatto, i suoi file di configurazione sono compatibili con sup. Sup non viene più utilizzato nel progetto FreeBSD, poichè CVSup è più veloce e più flessibile.
Il modo più semplice per installare CVSup è usare il package precompilato net/cvsup della collezione dei package di FreeBSD. Se preferisci costruire CVSup partendo dal sorgente, allora puoi usare il port net/cvsup. Ma sei avvisato: il port net/cvsup dipende dal sistema Modula-3, che richiede una consistente quantità di tempo e di spazio su disco per scaricarlo e costruirlo.
Se hai intenzione di usare CVSup su una macchina sulla quale non sarà installato XFree86™ o Xorg, come su un server, assicurati di usare il port che non include la GUI di CVSup, ossia net/cvsup-without-gui. |
Il funzionamento di CVSup è controllato da un file di configurazione chiamato supfile. Esistono alcuni esempi di supfile nella directory /usr/shared/examples/cvsup/.
Le informazioni contenute in un supfile rispondono alle seguenti questioni relative a CVSup:
Nelle seguenti sezioni, costruiremo un tipico supfile per rispondere a turno ad ognuna di queste questioni. Incominciamo però col descrivere la struttura globale di un supfile.
Un supfile è un file di testo. I commenti iniziano con un # e si estendono fino alle fine della riga. Le righe bianche e le righe che contengono solo commenti sono ignorate.
Ogni altra riga descrive un insieme di file che l’utente vuole ricevere. Una riga inizia con il nome di una "collezione", un nome di un gruppo logico di file definiti dal server. Il nome della collezione indica al server i file che vuoi ricevere. Dopo il nome della collezione seguono zero o più campi, separati da spazi bianchi. Questi campi rispondono alle questioni citate in precedenza. Ci sono due tipi di campi: campo opzione e campo valore. Un campo opzione consiste di una parola chiave a se stante, es. delete o compress. Anche un campo valore inizia con una parola chiave, ma questa è seguita dal simbolo =, senza spazi bianchi intermedi, e da un seconda parola. Ad esempio, release=cvs è un campo valore.
Un supfile tipicamente specifica più di un’unica collezione da ricevere. Un modo di strutturare un supfile è specificare esplicitamente tutti i campi rilevanti per ogni collezione. Tuttavia, ciò tende a creare supfile troppo lunghi, e ciò è scomodo poichè in un supfile la maggior parte dei campi sono gli stessi per tutte le collezioni. CVSup fornisce un meccanismo per aggirare questi problemi. Le linee che iniziano con il nome speciale di pseudo-collezione *default possono essere usate per inizializzare opzioni e valori che saranno utilizzati come default per le successive collezioni definite nel supfile. Un valore di default può essere sovrascritto da una singola collezione, specificando un valore diverso per la collezione stessa. Inoltre i valori di default possono essere modificati in mezzo al supfile tramite linee *default aggiuntive.
Con queste conoscenze, possiamo ora procedere alla costruzione di un supfile per ricevere ed aggiornare l’albero dei sorgenti della FreeBSD-CURRENT.
I file disponibili via CVSup sono organizzati in gruppi chiamati "collezioni". Le collezioni che sono disponibili sono descritte nella prossima sezione. In questo esempio, desideriamo ricevere per intero l’albero corrente dei sorgenti del sistema FreeBSD. C’è un’unica e vasta collezione src-all che ci permette di ricevere tutto ciò. Come prima fase nella costruzione del nostro supfile, dobbiamo semplicemente elencare le collezioni, una per riga (in questo caso, c’è un’unica riga):
src-all
Con CVSup, hai la possibilità di ricevere qualsiasi versione dei sorgenti che sia mai esistita. Questo è possibile poichè il server cvsupd lavora direttamente sul deposito CVS, che contiene tutte le versioni. Puoi specificare la versione che vuoi usando i campi valori tag= e date=.
Stai molto attento a specificare i campi |
Il campo tag= richiama un tag simbolico nel deposito. Ci sono due tipi di tag, i tag di revisione e i tag di ramo. Un tag di revisione fa riferimento ad una revisione specifica. Il suo significato rimane lo stesso di giorno in giorno. Un tag di ramo, d’altro canto, si riferisce sempre all’ultima revisione relativa ad una specifica linea di sviluppo. Dato che un tag di ramo non si riferisce ad una revisione specifica, esso potrebbe avere un significato diverso da un giorno con l’altro.
La Tag CVS contiene tag di ramo che potrebbero interessare gli utenti. Quando si specifica un tag in un file di configurazione di CVSup, esso dovrebbe essere preceduto da tag= (RELENG_4 diviene tag=RELENG_4). Tieni presente che per la collezione dei port è rilevante solo tag=..
Sii molto attento a digitare il nome del tag nel modo esatto. CVSup non è in grado di riconoscere tag errati. Se digiti in modo sbagliato un tag, CVSup si comporterà come se tu avessi specificato un tag valido che non riguarda nessun file. In questo caso i tuoi sorgenti saranno eliminati. |
Quando specifichi un tag di ramo, normalmente ricevi le ultime versioni dei file di quella linea di sviluppo. Se vuoi ricevere versioni precedenti, puoi specificare una data con il campo valore date=. La pagina man di cvsup(1) spiega come farlo.
Nel nostro esempio, desideriamo ricevere FreeBSD-CURRENT. Aggiungiamo questa riga all’inizio del nostro supfile:
*default tag=.
C’è un importante caso speciale che entra in gioco se non specifichi ne un campo tag= ne un campo date=. In questo caso, ricevi i file RCS attuali direttamente dal deposito CVS del server, invece di ricevere una versione particolare. Gli sviluppatori in genere preferiscono questa modalità di funzionamento. Mantenendo una copia del deposito stesso sui loro sistemi, essi sono in grado di navigare attraverso la storia delle revisioni e di esaminare le versioni precedenti dei file. Comunque questo vantaggio è realizzabile al costo di un ingente quantità di spazio su disco.
Il campo host= indica a cvsup da dove prelevare i suoi aggiornamenti. Va bene uno qualunque dei siti mirror di CVSup, anche se dovresti provare a selezionarne uno che sia a te vicino nel ciberspazio. In questo esempio useremo un sito di distribuzione di FreeBSD fittizio, cvsup99.FreeBSD.org:
*default host=cvsup99.FreeBSD.org
Devi cambiare l’host in uno che esiste realmente prima di eseguire CVSup. Il settaggio dell’host può essere sovrascritto su riga di comando eseguendo cvsup con l’opzione -h hostname.
Dove li vuoi mettere sulla tua macchina?
Il campo prefix= indica a cvsup dove mettere i file che riceve. In questo esempio, metteremo i file sorgenti direttamente nel nostro albero dei sorgenti, /usr/src. La directory src è già implicita nelle collezioni che vogliamo ricevere, quindi la corretta specifica è questa:
*default prefix=/usr
Dove cvsup dovrebbe mantenere i suoi file di stato?
Il client di CVSup mantiene certi file di stato in ciò che è chiamata directory "base". Questi file aiutano CVSup a lavorare in modo più efficace, mantenendo traccia di quali aggiornamenti sono stati già ricevuti. Useremo la directory base standard, /var/db:
*default base=/var/db
Se la tua directory base non esiste, potrebbe essere una buona idea crearla subito. Il client cvsup interrompe l’esecuzione se la tua directory base non esiste.
Settaggi vari di supfile:
C’è un altro settaggio che normalmente deve essere presente in un supfile:
*default release=cvs delete use-rel-suffix compress
release=cvs indica che il server dovrebbe prendere le sue informazioni dal deposito CVS principale di FreeBSD. In genere questa è la normalità, ma esistono altre possibilità che vanno oltre lo scopo di questa sezione.
delete dà a CVSup il permesso di cancellare file. Dovresti sempre specificare questa opzione, in modo che CVSup possa mantenere il tuo albero dei sorgenti del tutto aggiornato. CVSup è attento nel cancellare solamente quei file dei quali è responsabile. Altri file extra verranno lasciati intatti.
use-rel-suffix è … arcano. Se vuoi realmente saperne di più, guarda la pagina man di cvsup(1). Altrimenti, specificala senza preoccupartene troppo.
compress abilita l’uso di una compressione stile gzip sul canale di comunicazione. Se hai una connessione T1 o più veloce, non dovresti usare la compressione. Diversamente, può essere veramente d’aiuto.
Ricapitolazione di tutti settaggi:
Il supfile completo per il nostro esempio è il seguente:
*default tag=. *default host=cvsup99.FreeBSD.org *default prefix=/usr *default base=/var/db *default release=cvs delete use-rel-suffix compress src-all
Come menzionato in precedenza, CVSup usa un modello ad estrazione. Sostanzialmente, questo significa che ti connetti al server CVSup, lui dice, "Ecco ciò che puoi scaricare …", ed il tuo client risponde "OK, prenderò questo, questo, questo e questo." Nella configurazione di default, il client CVSup prenderà ogni file associato alla collezione e al tag che hai specificato nel file di configurazione. Tuttavia, questo non è sempre ciò che vuoi, specialmente se stai sincronizzando gli alberi doc, ports, o www - molte persone non sono in grado di leggere quattro o cinque lingue, e quindi esse non hanno bisogno di scaricare i file di certe lingue. Se stai sincronizzando con CVSup la collezione dei port, puoi specificare collezioni individuali (es., ports-astrology, ports-biology, ecc. invece di specificare semplicemente ports-all). Tuttavia, poichè gli alberi doc e www non hanno collezioni per specifiche lingue, devi usare una delle molte abili caratteristiche di CVSup: il file refuse.
Il file refuse sostanzialmente indica a CVSup che non dovrebbe prendere ogni singolo file da una collezione; in altre parole, esso dice al client di rifiutare certi file dal server. Il file refuse può essere trovato (o, se non ne hai ancora uno, dovrebbe essere messo) in base/sup/. base è definita nel tuo supfile; la nostra base è /var/db, e quindi di default il file refuse è /var/db/sup/refuse.
Il file refuse ha veramente un formato molto semplice; esso contiene semplicemente i nomi dei file o delle directory che non desideri scaricare. Per esempio, se non parli altre lingue oltre all’inglese e al tedesco, e non hai la necessità di leggere la traduzione in tedesco della documentazione, puoi mettere le seguenti righe nel tuo file refuse:
doc/bn_*
doc/da_*
doc/de_*
doc/el_*
doc/es_*
doc/fr_*
doc/it_*
doc/ja_*
doc/nl_*
doc/no_*
doc/pl_*
doc/pt_*
doc/ru_*
doc/sr_*
doc/tr_*
doc/zh_*e così via per altre lingue (puoi ottenere la lista completa esplorando il deposito CVS di FreeBSD).
Con questa utile funzionalità, quegli utenti che hanno una connessione lenta o pagano ogni minuto di connessione Internet potranno risparmiare tempo prezioso poichè non dovranno più scaricare file che non usano mai. Per maggiori dettagli sul file refuse e su altre utili caratteristiche di CVSup, guarda la sua pagina man.
Sei ora pronto per provare un aggiornamento. La riga di comando per farlo è molto semplice:
# cvsup supfiledove supfile è naturalmente il nome del supfile che hai creato. Assumendo che stai lavorando sotto X11, cvsup visualizzarà una GUI con alcuni bottoni adibiti ad operazioni usuali. Premi il bottone go, e stai a guardare l’esecuzione.
Poichè in questo esempio stai aggiornando il tuo albero dei sorgenti /usr/src, avrai bisogno di eseguire il programma come root affinchè cvsup abbia i permessi necessari per aggiornare i tuoi file. Avendo appena creato il tuo file di configurazione, e non avendo mai usato questo programma prima ad ora, tutto ciò potrebbe renderti un pò nervoso. Esiste un semplice modo per provare la sincronizzazione senza toccare i tuoi preziosi file. Crea una directory vuota in qualche posto, e richiamala come argomento sulla riga di comando:
# mkdir /var/tmp/dest
# cvsup supfile /var/tmp/destLa directory che hai specificato sarà usata come directory di destinazione per tutti gli aggiornamenti dei file. CVSup esaminerà i tuoi file usuali in /usr/src, ma non modificherà o cencellerà alcuno di essi. Gli aggiornamenti dei file finiranno invece in /var/tmp/dest/usr/src. Inoltre CVSup lascerà intatta la sua directory base contenente gli stati dei file quando viene eseguito in questo modo. Le nuove versioni di questi file saranno scritte nella directory specificata. A condizione che tu abbia l’accesso di lettura in /usr/src, non hai bisogno di essere root per realizzare questo tipo di giro di prova.
Se non stai utilizzando X11 o se non ti piacciono le GUI, dovresti aggiungere un paio di opzioni alla riga di comando quando esegui cvsup:
# cvsup -g -L 2 supfileL’opzione -g indica a CVSup di non usare la sua GUI. Ciò è automatico se non stai utilizzando X11, ma se lo stai facendo allora la devi specificare.
L’opzione -L 2 indica a CVSup di visualizzare i dettagli di tutti gli aggiornamenti dei file che avvengono. Esistono tre livelli di verbosità, da -L 0 a -L 2. Il default è 0, che significa silenzio totale eccetto per i messaggi di errore.
Ci sono molte altre opzione disponibili. Per una breve lista di esse, digita cvsup -H. Per una descrizione più dettagliata, guarda la relativa pagina man.
Le collezioni di file disponibili via CVSup sono organizzate gerarchicamente. Ci sono poche collezioni grandi, le quali sono divise in piccole sotto-collezioni. Ricevere una grande collezione è equivalente a ricevere ogni sua sotto-collezione. Le relazioni gerarchiche tra le collezioni riflettono l’uso dell’identazione nella lista qui sotto.
Le collezioni maggiormente usate sono src-all, e ports-all. Le altre collezioni sono usate solo da piccoli gruppi di persone per scopi speciali, e alcuni siti mirror potrebbero non contenerle tutte.
cvs-all release=cvsIl deposito CVS maestro di FreeBSD, incluso il codice di crittografia.
distrib release=cvsFile relativi alla distribuzione e al mirroring di FreeBSD.
doc-all release=cvsSorgenti del Manuale di FreeBSD e altra documentazione. Questa collezione non include i file per il sito web di FreeBSD.
ports-all release=cvsLa FreeBSD Ports Collection.
Se non vuoi aggiornare per intero |
Se hai intenzione di creare localmente una copia di ports/INDEX, devi includere |
ports-accessibility release=cvsSoftware per aiutare gli utenti disabili.
ports-arabic release=cvsSupporto per la lingua araba.
ports-archivers release=cvsApplicazioni per l’archiviazione.
ports-astro release=cvsApplicazioni riguardanti l’astronomia.
ports-audio release=cvsApplicazioni di supporto all’audio.
ports-base release=cvsL’infrastruttura della costruzione della collezione dei port - vari file posti nelle sottodirectory Mk/ e Tools/ della directory /usr/ports.
Per favore vedi l'importante avvertimento qui sopra: dovresti sempre aggiornare questa sotto-collezione ogni volta che aggiorni qualche pezzo della FreeBSD Ports Collection! |
ports-benchmarks release=cvsBenchmark (applicazioni per valutare le prestazioni del computer).
ports-biology release=cvsBiologia.
ports-cad release=cvsApplicazioni per la grafica computerizzata.
ports-chinese release=cvsSupporto alla lingua cinese.
ports-comms release=cvsSoftware per la comunicazione.
ports-converters release=cvsConvertitori di codici di caratteri.
ports-databases release=cvsDatabase.
ports-deskutils release=cvsCose che erano utilizzate sulla scrivania prima che i computer furono inventati.
ports-devel release=cvsUtility per il development.
ports-dns release=cvsSoftware relativo al DNS.
ports-editors release=cvsEditor.
ports-emulators release=cvsEmulatori per altri sistemi operativi.
ports-finance release=cvsApplicazioni finanziarie, di gestione delle spese e simili.
ports-ftp release=cvsServer e client FTP.
ports-games release=cvsGiochi.
ports-german release=cvsSupporto alla lingua tedesca.
ports-graphics release=cvsUtilità per la grafica.
ports-hebrew release=cvsSupporto per la lingua ebraica.
ports-hungarian release=cvsSupporto alla lingua ungherese.
ports-irc release=cvsUtilità IRC (Internet Relay Chat).
ports-japanese release=cvsSupporto alla lingua giapponese.
ports-java release=cvsUtility Java™.
ports-korean release=cvsSupporto alla lingua coreana.
ports-lang release=cvsLinguaggi di programmazione.
ports-mail release=cvsSoftware di posta.
ports-math release=cvsSoftware per la computazione numerica.
ports-mbone release=cvsApplicazioni MBone.
ports-misc release=cvsUtility varie.
ports-multimedia release=cvsSoftware multimediale.
ports-net release=cvsSoftware di rete.
ports-net-im release=cvsSoftware per messaggeria istantanea.
ports-net-mgmt release=cvsSoftware di gestione del network.
ports-net-p2p release=cvsRete peer to peer.
ports-news release=cvsSoftware per USENET.
ports-palm release=cvsSoftware di supporto per i vari Palm™.
ports-polish release=cvsSupporto alla lingua polacca.
ports-portuguese release=cvsSupporto alla lingua portoghese.
ports-print release=cvsSoftware per la stampa.
ports-russian release=cvsSupporto alla lingua russa.
ports-science release=cvsScienzia.
ports-security release=cvsUtility per la sicurezza.
ports-shells release=cvsShell a riga di comando.
ports-sysutils release=cvsUtility di sistema.
ports-textproc release=cvsUtility per la manipolazione del testo (non include utility per la pubblicazione computerizzata).
ports-ukrainian release=cvsSupporto per la lingua ucraina.
ports-vietnamese release=cvsSupporto alla lingua vietnamite.
ports-www release=cvsSoftware relativo al World Wide Web.
ports-x11 release=cvsPort per il supporto al sistema a finestre X.
ports-x11-clocks release=cvsOrologi per X11.
ports-x11-fm release=cvsGestori di file per X11.
ports-x11-fonts release=cvsFont per X11 e relative utility.
ports-x11-toolkits release=cvsCassette degli attrezzi per X11.
ports-x11-servers release=cvsServer X11.
ports-x11-themes release=cvsTemi per X11.
ports-x11-wm release=cvsGestori di finestre per X11.
projects-all release=cvsSorgenti per i progetti di FreeBSD.
src-all release=cvsI sorgenti correnti di FreeBSD, incluso il codice di crittografia.
src-base release=cvsVari file posti in /usr/src.
src-bin release=cvsUtility per l’utente in ambiente mono-utente (/usr/src/bin).
src-contrib release=cvsUtility e librerie al di fuori del progetto FreeBSD, sostanzialmente utilizzati senza modifiche (/usr/src/contrib).
src-crypto release=cvsUtility e librerie per la crittografia al di fuori del progetto FreeBSD, sostanzialmente utilizzati senza modifiche (/usr/src/crypto).
src-eBones release=cvsKerberos e DES (/usr/src/eBones). Non usati nell’attuale release di FreeBSD.
src-etc release=cvsFile di configurazione del sistema (/usr/src/etc).
src-games release=cvsGiochi (/usr/src/games).
src-gnu release=cvsUtility protette dalla licenza pubblica di GNU (/usr/src/gnu).
src-include release=cvsFile header (/usr/src/include).
src-kerberos5 release=cvsPacchetto di sicurezza Kerberos5 (/usr/src/kerberos5).
src-kerberosIV release=cvsPacchetto di sicurezza KerberosIV (/usr/src/kerberosIV).
src-lib release=cvsLibrerie (/usr/src/lib).
src-libexec release=cvsProgrammi di sistema normalmente eseguiti da altri programmi (/usr/src/libexec).
src-release release=cvsFile richiesti per produrre una release di FreeBSD (/usr/src/release).
src-sbin release=cvsUtility di sistema per la modalità mono-utente (/usr/src/sbin).
src-secure release=cvsLibrerie e comandi per la crittografia (/usr/src/secure).
src-share release=cvsFile che possono essere condivisi tra sistemi multipli (/usr/src/share).
src-sys release=cvsIl kernel (/usr/src/sys).
src-sys-crypto release=cvsCodice di crittografia del kernel (/usr/src/sys/crypto).
src-tools release=cvsVari strumenti per il mantenimento di FreeBSD (/usr/src/tools).
src-usrbin release=cvsUtility per l’utente (/usr/src/usr.bin).
src-usrsbin release=cvsUtility di sistema (/usr/src/usr.sbin).
www release=cvsI sorgenti per il sito web di FreeBSD.
distrib release=selfI file di configurazione del server CVSup. Usati dai siti mirror CVSup.
gnats release=currentIl database GNATS per tener traccia dei bug.
mail-archive release=currentArchivio delle mailing list di FreeBSD.
www release=currentI file pre-processati del sito web di FreeBSD (non i file sorgenti). Usati dai siti mirror WWW.
Per le FAQ ed altre informazioni di CVSup vedere la pagina home di CVSup.
La maggior parte delle discussioni su CVSup inerenti a FreeBSD si svolgono sulla mailing list di discussioni tecniche su FreeBSD. In questa mailling list inoltre sono anche annunciate nuove versioni del software, come pure sulla mailing list di annunci su FreeBSD.
Questioni e resoconti di bug dovrebbero essere indirizzati all’autore del programma cvsup-bugs@polstra.com.
I server CVSup per FreeBSD si trovano ai seguenti siti:
Portsnap è un sistema per distribuire in modo sicuro l’albero dei port di FreeBSD. Circa ogni ora, viene generata una "snapshot" dell’albero dei port, che viene impacchettata e firmata criptograficamente. I file risultanti sono quindi distribuiti via HTTP.
Come CVSup, Portsnap usa un modello di aggiornamento a rchiesta: gli alberi dei port impacchettati e firmati sono messi sul server web che attende in modo passivo le richieste dei client. Gli utenti devono eseguire portsnap(8) manualmente o schedulare il job con cron(8) per scaricare periodicamente gli aggiornamenti in modo automatico.
Per ragioni tecniche, Portsnap non aggiorna direttamente il "reale" albero dei port in /usr/ports/; invece, lavora con una copia compressa dell’albero dei port memorizzata di default in /var/db/portsnap/. Questa copia compressa viene quindi usata per aggiornare l’albero dei port effettivo.
Se Portsnap è installato dalla collezione dei port di FreeBSD, la locazione di default per la sua snapshot compressa è /usr/local/portsnap/ invece di /var/db/portsnap/. |
Su FreeBSD 6.0 e versioni più recenti, Portsnap è contenuto nel sistema base. Su versioni di FreeBSD più datate, può essere installato usando il port sysutils/portsnap.
Il funzionamento di Portsnap è controllato dal file di configurazione /etc/portsnap.conf. Per la maggior parte degli utenti, la configurazione di default sarà sufficiente; per maggiori dettagli, consultare la pagina man portsnap.conf(5).
Se Portsnap è installato dalla collezione dei port di FreeBSD, userà il file di configurazione posto in /usr/local/etc/portsnap.conf invece di /etc/portsnap.conf. Questo file di configurazione non viene creato quando viene installato il port, ma viene dato un file di configurazione di base; per copiarlo nella giusta posizione, esegui il comando seguente: |
La prima volta che portsnap(8) viene eseguito, ha bisogno di scaricare una snapshot compressa dell’intero albero dei port in /var/db/portsnap/ (o /usr/local/portsnap/ se Portsnap è stato installato dalla collezione dei port). Dall’inizio del 2006 la sua dimensione è di circa 41 MB.
# portsnap fetchUna volta che la snapshot compressa è stata scaricata, una copia dell’albero dei port può estratta in /usr/ports/. Questo è necessario perfino se l’albero dei port è già stato creato in quella directory (es., usando CVSup), poichè stabilisce un punto di inizio dal qualche portsnap può determinare quale parte dell’albero dei port necessita di essere aggiornata.
# portsnap extractNell’installazione di default la directory /usr/ports non viene creata. Se usi FreeBSD 6.0-RELEASE, la directory dovrebbe essere creata prima di usare |
Dopo che una prima snapshot compressa dell’albero dei port è stata scaricata ed estratta in /usr/ports/, l’aggiornamento dell’albero dei port consiste in due passi: scaricando gli aggiornamenti della snapshot compressa, e usare questi per aggiornare l’albero dei port effettivo. Questi due passi possono essere specificati a portsnap con un comando singolo.
# portsnap fetch updateAlcune versioni vecchie di |
Al fine di evitare problemi di "affollamenti istantanei" accedendo ai server di Portsnap, portsnap fetch non funziona da un job cron(8). Esiste invece un comando apposito portsnap cron, che attende una durata random fino a 3600 secondi prima di scaricare gli aggiornamenti.
Inoltre, è fortemente racomandato che portsnap update non sia eseguito da un job cron, poichè è soggetto a causare problemi se viene avviato allo stesso tempo di compilazione o installazione di un port. Ad ogni modo, è possibile aggiornare i file INDEX dei port, e può essere fatto passando il flag -I a portsnap. (Ovviamente, se portsnap -I update viene eseguito da cron, sarà necessario eseguire successivamnte portsnap update senza la flag -I al fine di aggiornare il resto dell’albero.)
Aggiungendo la riga seguente in /etc/crontab, portsnap aggiornerà la snapshot compressa e i file INDEX in /usr/ports/, e manderà una email se qualche port installato non è aggiornato:
0 3 * * * root portsnap -I cron update pkg_version -vIL=
Se l’ora di sistema non è settata all’ora locale, sostituisci |
Alcune versioni datate di |
Quando ricevi o aggiorni dei sorgenti usando cvs o CVSup, devi specificare un tag di revisione. Un tag di revisione si riferisce sia ad una particolare linea di sviluppo di FreeBSD, sia ad un specifico periodo di tempo. I primi tipi sono chiamati "tag di ramo", mentre i secondi "tag di release".
Tutti, con l’eccezione di HEAD (che è sempre un valido tag), sono relativi all’albero src/. Gli alberi ports/, doc/, e www/ non sono ramificati.
Nome simbolico per la linea di sviluppo corrente, FreeBSD-CURRENT. È anche il tag di default se nessun tag di revisione è specificato.
In CVSup, questo tag è rappresentato dal simbolo ..
In CVS, questo è il settaggio di default se nessun tag di revisione è stato specificato. In genere non è una buona idea aggiornare i sorgenti a CURRENT su una macchina STABLE, a meno che sai cosa stai facendo. |
La linea di sviluppo per FreeBSD-6.X, anche conosciuta come FreeBSD 6-STABLE.
Il ramo di release per FreeBSD-6.1, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-6.0, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
La linea di sviluppo per FreeBSD-5.X, anche conosciuta come FreeBSD-STABLE.
Il ramo di release per FreeBSD-5.5, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-5.4, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-5.3, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-5.2 e FreeBSD-5.2.1, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-5.1, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-5.0, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
La linea di sviluppo per FreeBSD-4.X, anche conosciuta come FreeBSD 4-STABLE.
Il ramo di release per FreeBSD-4.11, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-4.10, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-4.9, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-4.8, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-4.7, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-4.6 e FreeBSD-4.6.2, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-4.5, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-4.4, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
Il ramo di release per FreeBSD-4.3, usato solo per aggiornamenti relativi alla sicurezza e per altri fix cruciali.
La line di sviluppo per FreeBSD-3.X, anche conosciuta come 3.X-STABLE.
La linea di sviluppo per FreeBSD-2.2.X, anche conosciuta come 2.2-STABLE. Questo ramo è per la maggior parte obsoleto.
Questi tag si riferiscono a un preciso istante di tempo quando una versione di FreeBSD è stata rilasciata. Il processo di release engineering è documentato in dettaglio dai documenti Release Engineering Information e Release Process. L’albero src usa nomi di tag che iniziano con RELENG_. Gli alberi ports e doc usano tag il cui nome inizia con RELEASE. Infine, l’albero www non viene taggato con alcun nome particolare per le release.
FreeBSD 6.1
FreeBSD 6.0
FreeBSD 5.5
FreeBSD 5.4
FreeBSD 4.11
FreeBSD 5.3
FreeBSD 4.10
FreeBSD 5.2.1
FreeBSD 5.2
FreeBSD 4.9
FreeBSD 5.1
FreeBSD 4.8
FreeBSD 5.0
FreeBSD 4.7
FreeBSD 4.6.2
FreeBSD 4.6.1
FreeBSD 4.6
FreeBSD 4.5
FreeBSD 4.4
FreeBSD 4.3
FreeBSD 4.2
FreeBSD 4.1.1
FreeBSD 4.1
FreeBSD 4.0
FreeBSD-3.5
FreeBSD-3.4
FreeBSD-3.3
FreeBSD-3.2
FreeBSD-3.1
FreeBSD-3.0
FreeBSD-2.2.8
FreeBSD-2.2.7
FreeBSD-2.2.6
FreeBSD-2.2.5
FreeBSD-2.2.2
FreeBSD-2.2.1
FreeBSD-2.2.0
I server AFS per FreeBSD sono in esecuzione nei seguenti siti:
Il percorso dei file è: /afs/stacken.kth.se/ftp/pub/FreeBSD/
stacken.kth.se # Stacken Computer Club, KTH, Svezia 130.237.234.43 #hot.stacken.kth.se 130.237.237.230 #fishburger.stacken.kth.se 130.237.234.3 #milko.stacken.kth.se
Il maintainer ftp@stacken.kth.se
I seguenti siti rendono disponibile FreeBSD tramite il protocollo rsync. L’utility rsync lavora nello stesso modo del comando rcp(1), ma ha più opzioni e usa il protocollo rsync per aggiornamenti remoti il quale trasferisce solo le differenze tra i due set di file, e di conseguenza accelera fortemente la sincronizzazione su rete. Questo è molto utile se hai un sito mirror del server FTP di FreeBSD, o del deposito CVS. La suite rsync è disponibile per molti sistemi operativi e, su FreeBSD, puoi usare il port net/rsync o il rispettivo package.
rsync://ftp.cz.FreeBSD.org/
Collezioni disponibili:
ftp: Un mirror parziale del server FTP di FreeBSD.
FreeBSD: Un mirror completo del server FTP di FreeBSD.
rsync://grappa.unix-ag.uni-kl.de/
Collezioni disponibili:
freebsd-cvs: Il completo deposito CVS di FreeBSD.
Questa macchina fa da mirror anche per il deposito CVS dei progetti NetBSD e OpenBSD, tra gli altri.
rsync://ftp.nl.FreeBSD.org/
Collezioni disponibili:
vol/4/freebsd-core: Un completo mirror del server FTP di FreeBSD.
rsync://rsync.mirror.ac.uk/
Collezioni disponibili:
ftp.FreeBSD.org: Un completo mirror del server FTP di FreeBSD.
rsync://ftp-master.FreeBSD.org/
Questo server può essere usato solo dai siti mirror primari di FreeBSD.
Collezioni disponibili:
FreeBSD: L’archivio master del server FTP di FreeBSD.
acl: La lista master delle ACL di FreeBSD.
rsync://ftp13.FreeBSD.org/
Collezioni disponibili:
FreeBSD: Un completo mirror del server FTP di FreeBSD.
Sebbene le pagine man forniscano la documentazione di riferimento definitiva per le singole parti del sistema operativo FreeBSD, sono famose per non illustrare come mettere insieme i pezzi per far andare uniformemente l’intero sistema operativo. Per questo, non esiste sostituto a un buon libro sull’amministrazione di un sistema UNIX® e a un buon manuale per gli utenti.
Libri & Riviste internazionali:
Using FreeBSD (in Cinese), pubblicato da Drmaster, 1997. ISBN 9-578-39435-7.
FreeBSD Unleashed (traduzione cinese semplificata), pubblicato da China Machine Press. ISBN 7-111-10201-0.
FreeBSD From Scratch First Edition (in cinese semplificato), pubblicato da China Machine Press. ISBN 7-111-07482-3.
FreeBSD From Scratch Second Edition (in cinese semplificato), pubblicato da China Machine Press. ISBN 7-111-10286-X.
FreeBSD Handbook Second Edition (traduzione cinese semplificata), pubblicato da Posts & Telecom Press. ISBN 7-115-10541-3.
FreeBSD 3.x Internet (in cinese semplificato), pubblicato da Tsinghua University Press. ISBN 7-900625-66-6.
FreeBSD & Windows (in cinese semplificato), pubblicato da China Railway Publishing House. ISBN 7-113-03845-X
FreeBSD Internet Services HOWTO (in cinese semplificato), pubblicato da China Railway Publishing House. ISBN 7-113-03423-3
FreeBSD for PC 98’ers (in giapponese), pubblicato da SHUWA System Co, LTD. ISBN 4-87966-468-5 C3055 P2900E.
FreeBSD (in giapponese), pubblicato da CUTT. ISBN 4-906391-22-2 C3055 P2400E.
Complete Introduction to FreeBSD (in giapponese), pubblicato da Shoeisha Co., Ltd. ISBN 4-88135-473-6 P3600E.
Personal UNIX Starter Kit FreeBSD (in giapponese), pubblicato da ASCII. ISBN 4-7561-1733-3 P3000E.
FreeBSD Handbook (traduzione giapponese), pubblicato da ASCII. ISBN 4-7561-1580-2 P3800E.
FreeBSD mit Methode (in tedesco), pubblicato da Computer und Literatur Verlag/Vertrieb Hanser, 1998. ISBN 3-932311-31-0.
FreeBSD 4 - Installieren, Konfigurieren, Administrieren (in tedesco), pubblicato da Computer und Literatur Verlag, 2001. ISBN 3-932311-88-4.
FreeBSD 5 - Installieren, Konfigurieren, Administrieren (in tedesco), pubblicato da Computer und Literatur Verlag, 2003. ISBN 3-936546-06-1.
FreeBSD de Luxe (in tedesco), pubblicato da Verlag Modere Industrie, 2003. ISBN 3-8266-1343-0.
FreeBSD Install and Utilization Manual (in giapponese), pubblicato da Mainichi Communications Inc., 1998. ISBN 4-8399-0112-0.
Onno W Purbo, Dodi Maryanto, Syahrial Hubbany, Widjil Widodo Building Internet Server with FreeBSD (in indonesiano), pubblicato da Elex Media Komputindo.
Absolute BSD: The Ultimate Guide to FreeBSD (traduzione cinese), pubblicato da GrandTech Press, 2003. ISBN 986-7944-92-5.
The FreeBSD 6.0 Book (in cinese), pubblicato da Drmaster, 2006. ISBN 9-575-27878-X.
Libri & Riviste in lingua inglese:
Absolute BSD: The Ultimate Guide to FreeBSD, pubblicato da No Starch Press, 2002. ISBN 1886411743.
The Complete FreeBSD, pubblicato da O’Reilly, 2003. ISBN 0596005164.
The FreeBSD Corporate Networker’s Guide, pubblicato da Addison-Wesley, 2000. ISBN 0201704811.
FreeBSD: An Open-Source Operating System for Your Personal Computer, pubblicato da The Bit Tree Press, 2001. ISBN 0971204500.
Teach Yourself FreeBSD in 24 Hours, pubblicato da Sams, 2002. ISBN 0672324245.
FreeBSD 6 Unleashed, pubblicato da Sams, 2006. ISBN: 0672328755
FreeBSD: The Complete Reference, pubblicato da McGrawHill, 2003. ISBN 0072224096.
Computer Systems Research Group, UC Berkeley. 4.4BSD User’s Reference Manual. O’Reilly & Associates, Inc., 1994. ISBN 1-56592-075-9
Computer Systems Research Group, UC Berkeley. 4.4BSD User’s Supplementary Documents. O’Reilly & Associates, Inc., 1994. ISBN 1-56592-076-7
UNIX in a Nutshell. O’Reilly & Associates, Inc., 1990. ISBN 093717520X
Mui, Linda. What You Need To Know When You Can’t Find Your UNIX System Administrator. O’Reilly & Associates, Inc., 1995. ISBN 1-56592-104-6
Ohio State University ha scritto un Corso Introduttivo a UNIX che è disponibile online in formato HTML e PostScript.
Una traduzione in italiano di questo documento è disponibile come parte del FreeBSD Italian Documentation Project.
Jpman Project, Japan FreeBSD Users Group. FreeBSD User’s Reference Manual (traduzione giapponese). Mainichi Communications Inc., 1998. ISBN 4-8399-0088-4 P3800E.
Edinburgh University ha scritto una Guida Online per i nuovi arrivati nell’ambiente UNIX.
Albitz, Paul e Liu, Cricket. DNS and BIND, 4a Ed. O’Reilly & Associates, Inc., 2001. ISBN 1-59600-158-4
Computer Systems Research Group, UC Berkeley. 4.4BSD System Manager’s Manual. O’Reilly & Associates, Inc., 1994. ISBN 1-56592-080-5
Costales, Brian, et al. Sendmail, 2a Ed. O’Reilly & Associates, Inc., 1997. ISBN 1-56592-222-0
Frisch, Æleen. Essential System Administration, 2a Ed. O’Reilly & Associates, Inc., 1995. ISBN 1-56592-127-5
Hunt, Craig. TCP/IP Network Administration, 2a Ed. O’Reilly & Associates, Inc., 1997. ISBN 1-56592-322-7
Nemeth, Evi. UNIX System Administration Handbook. 3a Ed. Prentice Hall, 2000. ISBN 0-13-020601-6
Stern, Hal Managing NFS and NIS O’Reilly & Associates, Inc., 1991. ISBN 0-937175-75-7
Jpman Project, Japan FreeBSD Users Group. FreeBSD System Administrator’s Manual (traduzione giapponese). Mainichi Communications Inc., 1998. ISBN 4-8399-0109-0 P3300E.
Dreyfus, Emmanuel. Cahiers de l’Admin: BSD 2nd Ed. (in French), Eyrolles, 2004. ISBN 2-212-11463-X
Asente, Paul, Converse, Diana, e Swick, Ralph. X Window System Toolkit. Digital Press, 1998. ISBN 1-55558-178-1
Computer Systems Research Group, UC Berkeley. 4.4BSD Programmer’s Reference Manual. O’Reilly & Associates, Inc., 1994. ISBN 1-56592-078-3
Computer Systems Research Group, UC Berkeley. 4.4BSD Programmer’s Supplementary Documents. O’Reilly & Associates, Inc., 1994. ISBN 1-56592-079-1
Harbison, Samuel P. e Steele, Guy L. Jr. C: A Reference Manual. 4a ed. Prentice Hall, 1995. ISBN 0-13-326224-3
Kernighan, Brian e Dennis M. Ritchie. The C Programming Language. 2nd Ed. PTR Prentice Hall, 1988. ISBN 0-13-110362-8
Lehey, Greg. Porting UNIX Software. O’Reilly & Associates, Inc., 1995. ISBN 1-56592-126-7
Plauger, P. J. The Standard C Library. Prentice Hall, 1992. ISBN 0-13-131509-9
Spinellis, Diomidis. Code Reading: The Open Source Perspective. Addison-Wesley, 2003. ISBN 0-201-79940-5
Spinellis, Diomidis. Code Quality: The Open Source Perspective. Addison-Wesley, 2006. ISBN 0-321-16607-8
Stevens, W. Richard and Stephen A. Rago. Advanced Programming in the UNIX Environment. 2nd Ed. Reading, Mass. : Addison-Wesley, 2005. ISBN 0-201-43307-9
Stevens, W. Richard. UNIX Network Programming. 2a Ed, PTR Prentice Hall, 1998. ISBN 0-13-490012-X
Wells, Bill. "Writing Serial Drivers for UNIX". Dr. Dobb’s Journal. 19(15), Dicembre 1994. pp68-71, 97-99.
Andleigh, Prabhat K. UNIX System Architecture. Prentice-Hall, Inc., 1990. ISBN 0-13-949843-5
Jolitz, William. "Porting UNIX to the 386". Dr. Dobb’s Journal. Gennaio 1991-Luglio 1992.
Leffler, Samuel J., Marshall Kirk McKusick, Michael J Karels e John Quarterman The Design and Implementation of the 4.3BSD UNIX Operating System. Reading, Mass. : Addison-Wesley, 1989. ISBN 0-201-06196-1
Leffler, Samuel J., Marshall Kirk McKusick, The Design and Implementation of the 4.3BSD UNIX Operating System: Answer Book. Reading, Mass. : Addison-Wesley, 1991. ISBN 0-201-54629-9
McKusick, Marshall Kirk, Keith Bostic, Michael J Karels, e John Quarterman. The Design and Implementation of the 4.4BSD Operating System. Reading, Mass. : Addison-Wesley, 1996. ISBN 0-201-54979-4
Marshall Kirk McKusick, George V. Neville-Neil The Design and Implementation of the FreeBSD Operating System. Boston, Mass. : Addison-Wesley, 2004. ISBN 0-201-70245-2
Stevens, W. Richard. TCP/IP Illustrated, Volume 1: The Protocols. Reading, Mass. : Addison-Wesley, 1996. ISBN 0-201-63346-9
Schimmel, Curt. Unix Systems for Modern Architectures. Reading, Mass. : Addison-Wesley, 1994. ISBN 0-201-63338-8
Stevens, W. Richard. TCP/IP Illustrated, Volume 3: TCP for Transactions, HTTP, NNTP and the UNIX Domain Protocols. Reading, Mass. : Addison-Wesley, 1996. ISBN 0-201-63495-3
Vahalia, Uresh. UNIX Internals — The New Frontiers. Prentice Hall, 1996. ISBN 0-13-101908-2
Wright, Gary R. and W. Richard Stevens. TCP/IP Illustrated, Volume 2: The Implementation. Reading, Mass. : Addison-Wesley, 1995. ISBN 0-201-63354-X
Cheswick, William R. e Steven M. Bellovin. Firewalls and Internet Security: Repelling the Wily Hacker. Reading, Mass. : Addison-Wesley, 1995. ISBN 0-201-63357-4
Garfinkel, Simson e Gene Spafford. Practical UNIX & Internet Security. 2a Ed. O’Reilly & Associates, Inc., 1996. ISBN 1-56592-148-8
Garfinkel, Simson. PGP Pretty Good Privacy O’Reilly & Associates, Inc., 1995. ISBN 1-56592-098-8
Anderson, Don e Tom Shanley. Pentium Processor System Architecture. 2a Ed. Reading, Mass. : Addison-Wesley, 1995. ISBN 0-201-40992-5
Ferraro, Richard F. Programmer’s Guide to the EGA, VGA, and Super VGA Cards. 3a ed. Reading, Mass. : Addison-Wesley, 1995. ISBN 0-201-62490-7
Intel Corporation pubblica la documentazione sulle sue CPU, chipsets e standards sul suo sito web per gli sviluppatori, solitamente come files PDF.
Shanley, Tom. 80486 System Architecture. 3a ed. Reading, Mass. : Addison-Wesley, 1995. ISBN 0-201-40994-1
Shanley, Tom. ISA System Architecture. 3a ed. Reading, Mass. : Addison-Wesley, 1995. ISBN 0-201-40996-8
Shanley, Tom. PCI System Architecture. 4a ed. Reading, Mass. : Addison-Wesley, 1999. ISBN 0-201-30974-2
Van Gilluwe, Frank. The Undocumented PC, 2a Ed. Reading, Mass: Addison-Wesley Pub. Co., 1996. ISBN 0-201-47950-8
Messmer, Hans-Peter. The Indispensable PC Hardware Book, 4a Ed. Reading, Mass: Addison-Wesley Pub. Co., 2002. ISBN 0-201-59616-4
Lion, John Lion’s Commentary on UNIX, 6th Ed. With Source Code. ITP Media Group, 1996. ISBN 1573980137
Raymond, Eric S. The New Hacker’s Dictionary, 3rd edition. MIT Press, 1996. ISBN 0-262-68092-0. Conosciuto anche come il Jargon File
Salus, Peter H. A quarter century of UNIX. Addison-Wesley Publishing Company, Inc., 1994. ISBN 0-201-54777-5
Simon Garfinkel, Daniel Weise, Steven Strassmann. The UNIX-HATERS Handbook. IDG Books Worldwide, Inc., 1994. ISBN 1-56884-203-1. Fuori stampa, ma disponibile online.
Don Libes, Sandy Ressler Life with UNIX - edizione speciale. Prentice-Hall, Inc., 1989. ISBN 0-13-536657-7
The BSD family tree. http://www.FreeBSD.org/cgi/cvsweb.cgi/src/shared/misc/bsd-family-tree o /usr/shared/misc/bsd-family-tree su una macchina FreeBSD.
The BSD Release Announcements collection. 1997. http://www.de.FreeBSD.org/de/ftp/releases/
Networked Computer Science Technical Reports Library. http://www.ncstrl.org/
Old BSD releases from the Computer Systems Research group (CSRG). http://www.mckusick.com/csrg/: Il set di 4 CD comprende tutte le versioni di BSD dalla 1BSD alla 4.4BSD e 4.4BSD-Lite2 (ma non la 2.11BSD, sfortunatamente). Inoltre, l’ultimo disco contiene i sorgenti finali più i file SCCS.
Il rapido sviluppo di FreeBSD rende la carta stampata un mezzo non pratico per poterne seguire l’evoluzione. Le risorse in rete sono il migliore, se non l’unico, modo per tenersi informati sulle novità di questo sistema. Dal momento che FreeBSD è il prodotto del lavoro di volontari, la comunità degli utenti generalmente si presta anche ad una funzione di "supporto tecnico" di varia natura, con l’email e le news USENET come il mezzo più efficace per entrare in contatto con queste comunità.
I più frequentati punti di ritrovo della comunità FreeBSD sono esposti di seguito. Se aveste conoscenza di altre risorse non menzionate in questa sede, vi preghiamo di darne informazione a mailing list sul progetto di documentazione di FreeBSD cosicchè possano essere incluse.
Anche se molti sviluppatori di FreeBSD leggono USENET, non può esservi garanzia di ottenere risposta alle proprie domande in tempi brevi (e in generale non può esservi garanzia di ottenere alcuna risposta) semplicemente scrivendo ad uno dei mail-group di comp.unix.bsd.freebsd.*. Indirizzando i propri messaggi alla mailing list appropriata si raggiungerà una audience più concentrata ed informata, permettendo risposte più precise (o quanto meno più sollecite).
Gli argomenti delle varie liste sono elencati all’inizio del documento. Si prega di leggere gli argomenti prima di unirsi o scrivere ad una lista. La maggior parte dei sottoscrittori di liste ricevono ogni giorno svariate centinaia di messaggi, e mantenendo argomenti e regole di comportamento cerchiamo di tenere alto il rapporto segnale/rumore della lista. Venir meno a queste regole vorrebbe dire il fallimento della mailing list come mezzo efficace di comunicazione per il progetto.
Se vuoi verificare la tua abilità nel spedire alle liste di FreeBSD, manda un messaggio testuale a mailing list di prova di FreeBSD. Per favore non mandare messaggi di prova a altre liste. |
Se hai alcuni dubbi su quale lista postare una questione, leggi Come ottenere i migliori risultati dalla mailing list FreeBSD-questions.
Prima di postare su qualsiasi lista, per favore impara a come usare al meglio le mailing list, ad esempio come evitare discussioni che vengono richieste di frequente, leggendo il documento (FAQ) Le Questioni Maggiormente Richieste sulle Mailing List.
Vengono tenuti archivi per tutte le mailing list, e questi possono essere esplorati usando il FreeBSD World Wide Web server. L’archivio esplorabile per parole chiave costituisce un mezzo eccellente per trovare risposte a domande poste di frequente e dovrebbe essere consultato prima di spedire una domanda.
Liste generiche: Le seguenti sono liste generiche a cui tutti sono invitati (e incoraggiati) a partecipare:
| Lista | Argomento |
|---|---|
Cambiamenti apportati all’albero dei sorgenti di FreeBSD | |
Evangelismo FreeBSD | |
Eventi importanti e annunci di progetti | |
Discussioni sull’architettura ed il design | |
Discussioni incentrate sul mantenimento del database dei report dei problemi di FreeBSD e progetti correlati | |
Report sui bug | |
Argomenti non-tecnici di interesse della comunità FreeBSD | |
Discussioni sull’utilizzo di FreeBSD.current; | |
Argomenti di interesse degli Internet Service Providers che usano FreeBSD | |
Opportunità di lavoro e consulenza relative a FreeBSD | |
Le decisioni sulla politica da adottare del core degli sviluppatori FreeBSD. Toni pacati e sola lettura | |
Domande degli utenti e assistenza tecnica | |
Notifiche sulla sicurezza | |
Discussioni sull’uso di FreeBSD.stable; | |
Dove spedire i tuoi messaggi di test, lasciando in pace le altre liste |
Liste tecniche: le seguenti liste sono a carattere tecnico. Dovreste leggere attentamente gli argomenti elencati di seguito prima di unirvi o spedirvi mail, poichè ci sono strette linee di condotta per il loro uso ed il loro contenuto.
| Lista | Argomento |
|---|---|
Sviluppo di ACPI e della gestione dell’energia | |
Il porting di AFS su FreeBSD | |
Sviluppare drivers per Adaptec® AIC 7xxx | |
Il porting di FreeBSD su Alpha | |
Il porting di FreeBSD sui sistemi AMD64 | |
Discussioni sui port relativi ad Apache | |
Il porting di FreeBSD su processori ARM® | |
Usare reti ATM con FreeBSD | |
Il progetto di audit del codice sorgente | |
Il design e lo sviluppo del sistema di aggiornamento dei binari | |
Usare la tecnologia Bluetooth® su FreeBSD | |
Usare FreeBSD in cluster | |
Il mantenimento di CVSweb | |
Discussioni sull’uso e lo sviluppo di database sotto FreeBSD | |
Creare documenti su FreeBSD | |
Scrivere driver di dispositivi per FreeBSD | |
Utenti FreeBSD di Eclipse IDE, strumenti, applicazioni client e port. | |
Come usare FreeBSD in applicazioni embedded | |
L’emulazione di altri sistemi operativi come Linux/MS-DOS®/Windows® | |
Supporto per il software relativo a FreeBSD che non è più supportato dal progetto FreeBSD. | |
Discussioni tecniche sui FreeBSD FireWire® (iLink, IEEE 1394) | |
I file system | |
Discussioni e implementazioni riguardanti GEOM | |
Il porting di GNOME e delle applicazioni GNOME | |
Discussioni tecniche generiche | |
Discussioni tecniche generiche sull’hardware e FreeBSD | |
L’internazionalizzazione di FreeBSD | |
FreeBSD sulla piattaforma IA-32 (Intel® x86) | |
Il porting di FreeBSD ai futuri sistemi Intel® IA64 | |
Discussioni tecniche sul redesign del codice del firewall | |
Sviluppatori ISDN | |
Discussioni sul metodo jail(8) | |
Sviluppatori Java™ e persone coinvolte nel port delle JDK™ sotto FreeBSD | |
Il porting di KDE e delle applicazioni KDE | |
Il porting di LFS sotto FreeBSD | |
Il sistema di installazione e di gestione dei pacchetti di seconda generazione | |
Il porting di FreeBSD su MIPS® | |
Discussioni sui portatili | |
Il porting di Mozilla sotto FreeBSD | |
Applicazioni multimediali | |
Discussioni tecniche sull’architettura bus | |
Discussione sul networking e codice sorgente TCP/IP | |
Il porting di OpenOffice.org e StarOffice™ su FreeBSD | |
Questioni relative alla calibrazione delle prestazioni per installazioni a ad alta performance o carico elevato | |
Mantenimento di un numero di port relativi a perl | |
Discussioni sul sistema di firewall packet filter | |
Riguardo al porting di FreeBSD su architetture non Intel® | |
Discussione sulla collezione dei port | |
Discussione sui bug/PR relativi ai port | |
Il porting di FreeBSD su PowerPC® | |
Discussioni tecniche di FreeBSD su piattaforme server HP ProLiant | |
Discussioni riguardo Python su FreeBSD. | |
Discussione su certificati di qualità, solitamente sotto una release | |
Discussione sul sistema rc.d e relativo sviluppo | |
Sviluppo di estensioni realtime su FreeBSD | |
Il sottosistema SCSI | |
Questioni relative alla sicurezza di FreeBSD | |
L’uso di FreeBSD in applicazioni embedded (obsoleto; usare al suo posto freebsd-embedded) | |
Discussioni di design per sistemi a multiprocessore [a]simmetrico | |
Il porting di FreeBSD su architetture SPARC® | |
La coerenza di FreeBSD agli standards C99 e POSIX® | |
Il porting di FreeBSD su sistemi T1 UltraSPARC® | |
Test di stabilità e performance di FreeBSD | |
Threading in FreeBSD | |
Supporto per il token-ring in FreeBSD | |
Supporto USB in FreeBSD | |
Discussioni sull’infrastruttura VuXML | |
Mantenimento e supporto di X11 su FreeBSD |
Liste limitate: Le seguenti liste sono adatte ad un audience più specializzata (ed esigente) e probabilmente non sono di interesse del pubblico generico. È inoltre buona norma frequentare le liste tecniche prima di unirsi ad una di queste liste così da comprendere l’etichetta di comunicazione richiesta.
| Lista | Argomento |
|---|---|
Per coloro che gestiscono mirrors (supporto infrastrutturale) | |
Coordinamento dei gruppi utenti | |
Coordinamento dei venditori pre-release | |
Coloro che mantengono il sito www.FreeBSD.org |
Liste digest: Tutte le liste sopracitate sono anche consultabili come digest. Una volta iscritto a una lista, puoi cambiare le tue opzioni digest nella sezione delle opzioni del tuo account.
Liste CVS: Le liste seguenti sono per le persone interessate a vedere i messaggi di log delle modifiche alle varie aree dell’albero dei sorgenti. Sono liste a Sola Lettura e non si dovrebbero inviare messaggi ad esse.
| Lista | Area dei sorgenti | Descrizione dell’area |
|---|---|---|
/usr/(CVSROOT|doc|ports|projects|src) | Tutte le modifiche in ogni parte dell’albero (unione di tutte le altre liste di commit CVS) | |
/usr/(doc|www) | Tutte le modifiche all’albero doc e www | |
/usr/ports | Tutte le modifiche all’albero ports | |
/usr/projects | Tutte le modifiche all’albero projects | |
/usr/src | Tutte le modifiche all’albero src |
Per iscriverti ad una lista, clicca sul nome della lista qui sopra o vai su https://lists.freebsd.org e clicca sulla lista a cui sei interessato. La pagina delle liste dovrebbe contenere tutte le informazioni necessarie all’iscrizione.
Per mandare un messaggio ad una lista basta inviare una mail a listname@FreeBSD.org. Sarà poi redisribuita a tutti i membri della lista.
Per disiscriverti da una lista, clicca sull’URL che trovi in fondo a ogni email ricevuta dalla lista. È anche possibile inviare un’email a listname-unsubscribe@FreeBSD.org per disiscriverti.
A costo di ripeterci, vorremmo che i membri della lista tecnica tenessero la discussione su un tono tecnico. Se sei solo interessato ad annunci importanti, allora è preferibile che ti iscrivi alla mailing list di annunci su FreeBSD, creata apposta per traffico non frequente.
Tutte le mailing list FreeBSD hanno alcune regole base che tutti gli utenti devono seguire. La mancata aderenza a queste regole comporterà due (2) avvisi scritti dal PostMaster FreeBSD postmaster@FreeBSD.org, dopo dei quali, ad una terza trasgressione, il membro sarà espulso da tutte le mailing list di FreeBSD e gli sarà impedita qualsiasi futura iscrizione. Siamo mortificati del fatto che queste regole e misure siano necessarie, ma al giorno d’oggi Internet è diventato, a quanto pare, un’ambiente alquanto disordinato, e molti paiono scordarsi di quanto siano fragili alcuni suoi meccanismi.
Regole della strada:
L’argomento di ogni messaaggio dovrebbe aderire all’argomento della lista a cui è inviato, ad esempio se la lista è a carattere tecnico, i vostri messaggi dovrebbero contenere discussioni tecniche. Chiacchiericci continui ed irrilevanti vanno a discapito del valore della lista per tutti i suoi membri e non saranno tollerati. Per discussioni libere senza restrizioni sull’argomento, la mailing list di chiacchiere su FreeBSD è liberamente fruibile e dovrebbe essere usata per questo.
Non bisognerebbe scrivere a più di due mailing list, ed anche a due solo e soltanto se un motivo reale e concreto esiste. Per molte liste, esiste già un grande traffico di messaggi che si sovrappongono ed eccetto per i mix più esoterici (ad esempio "-stable & -scsi"), non c’è alcun motivo di scrivere a più di una lista alla volta. Se un messaggio è inviato in modo tale che molte mailing list appaiono nella linea Cc, allora la linea Cc dovrebbe essere suddivisa prima di inviare nuovi messaggi. Voi siete del tutto responsabili per i vostri messaggi inviati in modo errato, non importa di chi sia la causa.
Attacchi personali ed insulti (nel contesto di una discussione) non sono permessi, e questa regola comprende membri e sviluppatori. Gravi violazioni della netiquette, come citare o inviare messaggi altrui quando il permesso a farlo non c’era e non sarebbe giunto sono altamente disapprovate ma non sanzionate direttamente. Comunque, ci sono pochissimi casi in cui questi messaggi sarebbero pertinenti all’argomento della lista, quindi tali comportamenti probabilmente otterrebbero un avviso (o un espulsione) del Postmaster, solo per quel motivo.
Pubblicità di prodotti non-FreeBSD è altamente proibita e comportertà un’espulsione immediata se è chiaro che il trasgressore sta inviando pubblicità spam.
Argomenti delle singole liste:
Sviluppo di ACPI e della gestione dell’energia
Andrew File System
Questa è la lista per le discussioni sul porting e l’uso dell' AFS da CMU/Transarc.
Eventi importanti/pietre miliari
Questa è la mailing list per le persone interessate soltanto in annunci occasionali di eventi significativi riguardanti FreeBSD. Contiene annunci riguardo snapshots e altre release. Contiene annunci su nuove potenzialità di FreeBSD. Può contenere richieste di volontari etc. È una mailing list dal poco traffico, strettamente regolata.
Discussione sull’architettura e la progettazione
Questa lista è per la discussione dell’architettura FreeBSD. I messaggi saranno mantenuti strettamente tecnici di natura. Esempi di possibili argomenti:
Come modificare il processo di build per avere molti build personalizzati in funzione allo stesso tempo.
Cosa deve essere modificato nel VFS per far funzionare i layers Heimann.
Come modificare l’interfaccia dei device driver per poter usare gli stessi driver senza problemi su molti buses e architetture.
Come scrivere un driver di rete.
Progetto di audit del sorgente
Questa è la mailing list per il progetto di audit del codice FreeBSD. Anche se in origine era intesa per cambiamenti relativi alla sicurezza, le sue caratteristiche sono state estese per includere ogni cambiamento al codice.
Questa lista è piena di discussioni di patch, e probabilmente di non grandissimo interesse per l’utente medio FreeBSD. Discussioni sulla sicurezza non relative ad una particolare modifica del codice si tengono in FreeBSD-security. Nel frattempo tutti gli svilupatori sono incoraggiati a spedire le proprie patch a questa lista per correzioni, specialmente se toccano parte del sistema dove un bug può influenzare negativamente l’integrità del sistema.
Aggiornamento dei binari FreeBSD
Questa lista esiste per fornire un terreno di discussione per il sistema di aggiornamento dei binari, o binup. Sono consentite questioni di design, dettagli di implementazione, patch, report di bug, report di status, richieste di feature, log delle modifiche, e tutto ciò che riguardi binup.
Bluetooth® su FreeBSD
Questo è il forum dove si riuniscono gli utenti Bluetooth® di FreeBSD. Sono consentite aromentazioni su problemi di progettazione, dettagli implementativi, patch, report di bug, lo stato attuale, nuove caratteristiche, e altro materiale relativo a Bluetooth®.
Coordinamento dello sforzo di gestione dei Problem Report
Lo scopo di questa lista è di servire come forum di coordinamento e discussione per il Bugmeister, i suoi Bugbuster, e ogni altra parte che abbia un genuino interesse nel database PR. Questa lista non è per la discussione di bug specifici, patch, o PR.
Report di bug
Questa è la lista per i report dei bug di FreeBSD. Quando possibile, i bug dovrebbero essere indicati usando il comando send-pr(1) o tramite la sua interfaccia WEB.
Argomenti non tecnici relativi alla comunità FreeBSD
Questa lista contiene ciò che resta dalle altre liste riguardo ad informazioni non tecniche, sociali. Include discussioni sul fatto che Jordan sembri o meno un toon ferret, se scrivere o meno in maiuscolo, chi sta bevendo troppo caffè, dove spillano la migliore birra, chi spilla birra in cantina, e così via. Annunci occasionali di eventi importanti (party a venire, celebrazioni di matrimoni, nascite, nuovi lavori etc.) possono essere fatti alle liste non tecniche, ma i suddetti argomenti dovrebbero essere diretti a questa lista.
Il core team di FreeBSD
Questa è una lista interna ad uso dei membri core. Messaggi possono esservi spediti quando una seria questione relativa a FreeBSD richiede un arbitrato da un alto scrutinio.
Discussioni sull’uso di FreeBSD.current;
Questa è la mailing list di discussione di FreeBSD.current;. Contiene avvertimenti su nuove features in arrivo in -CURRENT che toccheranno gli utenti, ed istruzioni su passi che devono restare -CURRENT. Chiunque usi "CURRENT" deve sottoscrivere questa lista. È una mailing list tecnica per la quale ci si attende materiale strettamente tecnico.
Progetto CVSweb di FreeBSD
Discussioni tecniche sull’uso, sviluppo e mantenimento di FreeBSD-CVSweb
Progetto di documentazione
Questa mailing list è per la discussione di argomenti e progetti riguardanti la creazione della documentazione FreeBSD. I membri di questa mailing list sono noti in genere come "The FreeBSD Documentation Project". È una lista aperta, sentitevi liberi di unirla e contribuirvi.
Scrivere driver di dispositivi per FreeBSD
Questo è un forum per discussioni tecniche relative ai driver di dispositivi su FreeBSD. È sostanzialmente un posto per gli sviluppatori di driver di dispositivi su questioni su come scrivere driver di dispositivi usando le API del kernel di FreeBSD.
Utenti FreeBSD di Eclipse IDE, strumenti, applicazioni client e port.
L’intenzione di questa lista è di fornire un supporto reciproco per tutto ciò che concerne la scelta, l’installazione, l’uso, lo sviluppo e il mantenimento di Eclipse IDE, gli strumenti, le applicazioni client sulla piattaforma FreeBSD e l’assistenza al porting di Eclipse IDE nonchè i plugin per l’ambiente di FreeBSD.
L’intenzione è anche quella di facilitare lo scambio di informazioni tra la comunità di Eclipse e la comunità di FreeBSD per un reciproco beneficio.
Benchè questa lista si focalizzi principalmente sulle necessità degli utenti di Eclipse essa fornisce anche un forum per quelli ai quali piace sviluppare applicaizoni specifiche per FreeBSD usando il framework Eclipse.
Come usare FreeBSD in applicazioni embedded.
In questa lista sono affrontati argomenti relativi all’uso di FreeBSD in sistemi embedded. Essendo questa una mailing list tecnica ci si aspetta contenuti tecnici. Per l’intento di questa lista definiamo i sistemi embedded come quei calcolatori che non sono desktop e che in genere sono utilizzati per un singolo fine al contrario dell’usuale concezione dei sistemi calcolatori. Esempi includono, senza limitazione alcuna, tutti i tipi di telefonini, strumenti di networking come i router, gli switch, i PBX, strumenti di misurazione remota, PDA, sistemi di punti vendita, e altri ancora.
Emulazione di altri sistemi come Linux/MS-DOS®/Windows®
Questo è un forum per discussioni tecniche relative all’esecuzione su FreeBSD di programmi scritti per altri sistemi operativi.
Supporto per il software relativo a FreeBSD che non è più supportato dal progetto FreeBSD.
Questa lista è rivolta a coloro che sono interessati a fornire o usufruire del supporto per software relativo a FreeBSD per il quale il progetto FreeBSD non fornisce più un supporto ufficiale (es. avvisi di sicurezza e patch).
FireWire® (iLink, IEEE 1394)
Questa è la mailing list per la discussione del design e l’implementazione di un sottosistema FireWire® (anche noto come IEEE 1394 o iLink) per FreeBSD. Argomenti rilevanti includono nello specifico gli standards, i bus devices, i loro protocolli, insiemi di adapter boards/cards/chips, e l’architettura e implementazione del codice per il loro pieno supporto.
File system
Discussioni riguardanti i file system FreeBSD. Questa è una lista dalle caratteristiche tecniche per la quale ci si attende contenuto strettamente tecnico.
GEOM
Discussioni riguardanti GEOM e relative implementazioni. Questa è una mailing list tecnica per la quale ci si attente contenuto strettamente tecnico.
GNOME
Discussioni riguardanti The Gnome Desktop Environment per sistemi FreeBSD. Questa è una mailing list tecnica per la quale ci si attende materiale strettamente tecnico.
Firewall IP
Questo è il forum di discussione riguardante il redesign del codice IP firewall di FreeBSD. Questa è una mailing list tecnica per la quale ci si attende materiale strettamente tecnico.
Il porting di FreeBSD su IA64
Questa è una mailing list tecnica per individui impegnati attivamente nel porting di FreeBSD alla piattaforma IA-64 dall’Intel®, nel sollevare problemi e nel proporre soluzioni. Individui interessati nel seguire le discussioni tecniche sono comunque benvenuti.
Sistema di comunicazione ISDN
Questa è la mailing list per le persone che discutono lo sviluppo del supporto ISDN per FreeBSD.
Sviluppo Java™
Questa è la mailing list per le persone impegnate nello sviluppo di applicazioni Java™ significative per FreeBSD ed il porting ed il mantenimento delle JDK™.
Cercasi e offresi opportunità di lavoro
Questo è un forum dove inviare avvisi di impiego e curriculum vitae relativi specificatamente a FreeBSD, ad esempio se stai cercando un impiego relativo a FreeBSD o hai un posto di lavoro da pubblicizzare che coinvolge FreeBSD allora questo è il posto giusto. Questa non è una mailing list sui problemi di occupazione in generale visto che forum appropriati esistono già da altre parti.
Nota che questa lista, come le altre mailing list di FreeBSD.org, è distribuita in tutto il mondo. Di conseguenza, devi essere chiaro sul luogo e sulle possibiltà di telelavoro o assistenza nel cambiare abitazione, se disponibili.
Le email dovrebbero usare solo formati aperti - preferibilmente testo semplice, ma molti lettori accettano anche Portable Document Format (PDF), HTML, e alcuni altri. Formati chiusi come Microsoft® Word (.doc) saranno respinti dal server delle mailing list.
KDE
Discussioni concernenti KDE su sistemi FreeBSD. È una mailing list a carattere tecnico per la quale ci si attende materiale strettamente tecnico.
Discussioni tecniche
Questo è un forum per discussioni tecniche relative a FreeBSD. Questa è la mailing list tecnica principale. È per individui che lavorano attivamente a FreeBSD per sollevare problemi o discutere soluzioni alternative. Individui interessati nel seguire le discussioni tecniche sono comunque benvenuti. È una mailing list tecnica per la quale ci si attende contenuto strettamente tecnico.
Discussione generale sull’hardware e FreeBSD
Discussione generica sui vari tipi di hardware che FreeBSD supporta, vari problemi e suggerimenti riguardo a cosa convenga acquistare e cosa evitare.
Siti mirror
Annunci e discussioni per persone che mantengono siti mirror FreeBSD.
Questioni riguardanti gli Internet Service Provider
Questa mailing list è per la discussione di argomenti riguardanti gli Internet Service Provider (ISP) che usano FreeBSD. È una mailing list tecnica per a quale ci si attende materiale strettamente tecnico.
OpenOffice.org
Questione concernenti il porting ed il mantenimento di OpenOffice.org e StarOffice™.
Discussioni riguardo la calibrazione o la velocizzazione di FreeBSD
Questa mailing list esiste per procurare ad hackers, amministratori di sistema, e/o parti interessate un luogo dove discutere argomenti legati alla performance di FreeBSD. Argomenti accettabili includono installazioni di FreeBSD ad alto carico, con problemi di performance o che stanno spingendo ai limiti delle sue possibilità FreeBSD. Le parti interessate che sono disposte a lavorare per un miglioramento delle prestazioni di FreeBSD sono altamente incoraggiate a sottoscrivere questa lista. Questa è una lista estremamente tecnica, idealmente adatta per utenti FreeBSD esperti, hackers o amministratori intenzionati a mantenere FreeBSD veloce, robusto e scalabile. Questa lista non è una lista domanda-e-risposta che sostituisce l’uso della documentazione, quanto piuttosto un luogo dove apportare i propri contributi o porre domande che non hanno avuto risposta altrove riguardo a tematiche di prestazione.
Discussioni sul sistema di firewall packet filter
Discussioni concernenti il sistema di firewall packet filter (pf) su FreeBSD. Saranno ben accolte sia discussioni tecniche che questioni generiche. Inoltre su questa lista si discute anche del framework ALTQ Qos.
Il porting sulle piattaforme non Intel®
Questione concernenti FreeBSD fra le varie piattaforme, discussioni generiche e proposte per ports ad architetture non Intel®. È una maliling list tecnica per la quale ci si attende materiale strettamente tecnico.
Le decisioni della politica del Core Team
Questa è una mailing list a scarso traffico, di sola lettura, per le decisioni politiche del Core Team.
Discussioni sui "port"
Discussioni riguardanti la collezione dei "port" di FreeBSD (/usr/ports), l’infrastruttura dei port, e sforzi generali per la coordinazione dei port. È una mailing list a carattere tecnico per la quale ci si attende materiale strettamente tecnico.
Discussione dei bug dei "port"
Discussioni concernenti report di problemi sulla "collezione dei port" di FreeBSD (/usr/ports), proposte di nuovi port, o modifiche ai port. È una mailing list a carattere tecnico per la quale ci si attende materiale strettamente tecnico.
Discussioni tecniche di FreeBSD su piattaforme server HP ProLiant
Questa mailing list è usata per discussioni tecniche sull’uso di FreeBSD su server HP ProLiant, includendo discussioni su driver ProLiant, software di gestione, strumenti di configurazione, ed aggiornamenti del BIOS. Come tale, questo è il posto adatto per discutere circa hpasmd, hpasmcli, e hpacucli.
Python su FreeBSD
Questa è una lista di discussioni relative al miglioramento del supporto di Python su FreeBSD. Questa è una mailing list tecnica. È per coloro che lavorano sul porting di Python, sui suoi moduli di terze parti e sul materiale di Zopein FreeBSD. Inoltre sono benvenute persone interessate alle discussioni tecniche.
Domande degli utenti
Questa è una mailing list per domande riguardanti FreeBSD. Non dovreste porre domande del tipo "how to" alle liste tecniche a meno che stiate considerando le questioni come molto tecniche.
Sottosistema SCSI
Questa è la mailing list per le persone impegnate nel sottosistema SCSI di FreeBSD. È una mailing list tecnica per la quale ci si attende materiale strettamente tecnico.
Questioni di sicurezza
Argomenti relativi alla sicurezza dei sistemi FreeBSD (DES, Kerberos, buchi di sicurezza noti e fixes, etc.). Questa è una mailing list tecnica per la quale ci si attende materiale strettamente tecnico. Notate che questa non è una lista domanda e risposta, ma che i contributi (SIA domande SIA risposte) alle FAQ sono benvenute.
Notifiche riguardanti la sicurezza
Notifiche riguardanti problemi di sicurezza di FreeBSD e fix. Non è una lista di discussione. La relativa lista di discussione è FreeBSD-security.
Utilizzo di FreeBSD in applicazioni embedded
Questa lista discute argomenti relativi ad installazioni di FreeBSD su macchine dalle risorse estremamente limitate e sistemi embedded.
Questa lista è stata resa obsoleta da freebsd-embedded. |
Discussioni riguardo l’uso di FreeBSD.stable;
Questa è la mailing list degli utenti di FreeBSD.stable;. Include avvertimenti su nuove caratteristiche in arrivo nella -STABLE che toccheranno gli utenti, e istruzioni sui passi da compiere per tenere aggiornata la -STABLE. Chiunque usi la "STABLE" dovrebbe sottoscrivere questa lista. È una lista di carattere tecnico per la quale ci si attende materiale strettamente tecnico.
Rispetto degli standards C99 & POSIX
Questo è un forum di discussioni tecniche relative al rispetto degli standards C99 e POSIX da parte di FreeBSD.
Discussioni per il supporto USB in FreeBSD
Questa è la mailing list per discussioni tecniche relative al supporto USB in FreeBSD.
Lista di coordinamento dei gruppi utenti
Questa è la mailing list per i coordinatori di ogni Gruppo Utenti locale, in cui discutere questioni fra di loro e un membro designato del Core Team. Questa mailing list dovrebbe essere limitata a discussioni su meeting e coordinamento di progetti che riguardano molti Gruppi Utenti.
I venditori
Discussioni di coordinamento fra il FreeBSD Project e venditori di software e hardware per FreeBSD.
Le mailing list di FreeBSD sono filtrate in molti modi per evitare la distribuzione di spam, virus, e altre email non volute. Le azioni di filtraggio descritte in questa sezione non includono tutte quelle usate per proteggere le mailing list.
Solo certi tipi di allegati sono ammessi sulle mailing list. Tutti gli allegati con un tipo di contenuto MIME non presente nella lista seguente saranno eliminati prima che l’email sia distribuita sulla mailing list.
application/octet-stream
application/pdf
application/pgp-signature
application/x-pkcs7-signature
message/rfc822
multipart/alternative
multipart/related
multipart/signed
text/html
text/plain
text/x-diff
text/x-patch
Alcune mailing list potrebbero ammettere allegati di altri tipi di contenuto MIME, ma la lista qui sopra dovrebbe essere corretta per la maggior parte delle mailing list. |
Se un’email contiene sia una versione HTML che una versione testo, quella HTML verrà rimossa. Se un’email contiene solo una versione HTML, sarà convertita in semplice testo.
Oltre ai due newsgroup specificamente designati per FreeBSD, ve ne sono molti altri in cui FreeBSD è discusso o che sono comunque rilevanti per gli utenti FreeBSD. Sono disponibili degli archivi interrogabili attraverso parole chiave su questi newsgroup per gentile concessione di Warren Toomey wkt@cs.adfa.edu.au.
de.comp.os.unix.bsd (Tedesco)
fr.comp.os.bsd (Francese)
it.comp.os.freebsd (Italiano)
tw.bbs.comp.386bsd (Cinese Tradizionale)
Central Servers, Armenia, Australia, Austria, Czech Republic, Denmark, Finland, France, Germany, Hong Kong, Ireland, Japan, Latvia, Lithuania, Netherlands, Norway, Russia, Slovenia, South Africa, Spain, Sweden, Switzerland, Taiwan, United Kingdom, United States of America.
(as of UTC)
Central Servers
Armenia
http://www.at.FreeBSD.org/ (IPv6)
Australia
Austria
http://www.at.FreeBSD.org/ (IPv6)
Czech Republic
http://www.cz.FreeBSD.org/ (IPv6)
Denmark
http://www.dk.FreeBSD.org/ (IPv6)
Finland
France
Germany
Hong Kong
Ireland
Japan
Latvia
Lithuania
Netherlands
Norway
Russia
http://www.ru.FreeBSD.org/ (IPv6)
Slovenia
South Africa
Spain
Sweden
Switzerland
http://www.ch.FreeBSD.org/ (IPv6)
http://www2.ch.FreeBSD.org/ (IPv6)
Taiwan
United Kingdom
United States of America
http://www5.us.FreeBSD.org/ (IPv6)
I seguenti Gruppi Utenti forniscono indirizzi email per i propri membri. Gli amministratori di lista si riservano il diritto di revocare l’indirizzo assegnato se in alcun modo se ne fa cattivo uso.
| Dominio | Offerta | Gruppo utente | Amministratore |
|---|---|---|---|
ukug.uk.FreeBSD.org | Solo forwarding | Lee Johnston lee@uk.FreeBSD.org |
I seguenti Gruppi utenti forniscono account di shell a persone che supportano attivamente il progetto FreeBSD. Gli amministratori elencati si riservano il diritto di cancellare l’account se viene in alcun modo usato male.
| Host | Accesso | Offerta | Amministratore |
|---|---|---|---|
dogma.freebsd-uk.eu.org | Telnet/FTP/SSH | Email, spazio Web, FTP anonimo | Lee Johnston lee@uk.FreeBSD.org |
Nel caso tu debba verificare una firma o inviare un messaggio cifrato a una delle cariche ufficiali o a uno degli sviluppatori, qui puoi trovare per tua comodità una serie di chiavi. Un portachiavi completo degli utenti FreeBSD.org è disponibile per il download da pgpkeyring.txt.
<security-officer@FreeBSD.org>pub rsa4096/D9AD2A18057474CB 2022-12-11 [C] [expires: 2026-01-24]
Key fingerprint = 0BE3 3275 D74C 953C 79F8 1107 D9AD 2A18 0574 74CB
uid FreeBSD Security Officer <security-officer@freebsd.org>
sub rsa4096/6E58DE901F001AEF 2022-12-11 [S] [expires: 2026-01-15]
sub rsa4096/46DB26D62F6039B7 2022-12-11 [E] [expires: 2026-01-15]-----BEGIN PGP PUBLIC KEY BLOCK----- mQINBGOVdeUBEADHF5VGg1iPbACB+7lomX6aDytUf0k2k2Yc/Kp6lfYv7JKU+1nr TcNF7Gt1YkajPSeWRKNZw/X94g4w5TEOHbJ6QQWx9g+N7RjEq75actQ/r2N5zY4S ujfFTepbvgR55mLTxlxGKFBmNrfNbpHRyh4GwFRgPlxf5Jy9SB+0m54yFS4QlSd0 pIzO0CLkjHUFy/8S93oSK2zUkgok5gLWruBXom+8VC3OtBElkWswPkE1pKZvMQCv VyM+7BS+MCFXSdZczDZZoEzpQJGhUYFsdg0KqlLv6z1rP+HsgUYKTkRpcrumDQV0 MMuCE4ECU6nFDDTnbR8Wn3LF5oTt0GtwS0nWf+nZ1SFTDURcSPR4Lp/PKjuDAkOS P8BaruCNx1ItHSwcnXw0gS4+h8FjtWNZpsawtzjjgApcl+m9KP6dkBcbN+i1DHm6 NG6YQVtVWyN8aOKmoC/FEm1CWh1bv+ri9XOkF2EqT/ktbjbT1hFoFGBkS9/35y1G 3KKyWtwKcyF4OXcArl6sQwGgiYnZEG3sUMaGrwQovRtMf7le3cAYsMkXyiAnEufa deuabYLD8qp9L/eNo+9aZmhJqQg4EQb+ePH7bGPNDZ+M5oGUwReX857FoWaPhs4L dAKQ1YwASxdKKh8wnaamjIeZSGP5TCjurH7pADAIaB3/D+ZNl2a7od+C1wARAQAB tDdGcmVlQlNEIFNlY3VyaXR5IE9mZmljZXIgPHNlY3VyaXR5LW9mZmljZXJAZnJl ZWJzZC5vcmc+iQJSBBMBCgA8AhsBBAsJCAcEFQoJCAUWAgMBAAIeBQIXgBYhBAvj MnXXTJU8efgRB9mtKhgFdHTLBQJjlXeQBQkF3u+rAAoJENmtKhgFdHTLOVoQALS3 cj7rqYkHiV4zDYrgPEp9O1kAyGI8VdfGAMkDVTqr+wP4v/o7LIUrgwZl5qxesVFB VknFr0Wp5g9h0iAjasoI5sDd6tH2SmumhBHXFVdftzDQhrugxH6fWRhHs0SaFYCk Qt5nFbcpUfWgtQ35XTbsL8iENdYpjKXsSFQrJneGSwxIjWYTFn6ps/AI3gwR8+Bn OffEFdYugJ049O6Vu6YBFJHrnMO7NbF4v95dVYuLtpMIaXWM+V9KITmhaBzFz5fM Q7UOzcLlbxOYKNIWcp8QQk429mayKW5VUeUExUD1ZzBHn+P6ZG7QTMDu/RmBqiHo ewCMVz4n9uXT5BiOngE4CvS0WQwHzK+k9MLpG2u/Bo9+LT0Ceh9Ou1rfU5+0tRwl GyOFFjf3INS7I7gkcAwxQ7dzDItN/UQPZpg8y9mABU2x4enz0AvTnb61d/1dnTEr tdNgU433he0ZnD1HurZCjBEWC656wv6iMdWcD8gjhMbmEpPmjvXcYlTO6zhEygSM DiwdQCWK2W4++YJerA6ULBi3niNWBpofOFH8XylV56ruhjtHCo7+/3carcMoPOJv lVZ1zCKxLro3TRBT15JTFBGqblRyTopFK3PuxW//GTnZOtpQEOV6yL4RAXcWeC1d 1hb5k/YxUmRF6XsDNEH4b08T8ZO8dV3dAV43Wh1oiQEzBBABCAAdFiEEuyjUCzYO 7pNq7RVv5fe8y6O93fgFAmObXVYACgkQ5fe8y6O93fiBlwf/W8y1XXJIx1ZA3n6u f7aS70rbP9KFPr4U0dixwKE/gbtIQ9ckeNXrDDWz0v0NCz4qS+33IPiJg1WcY3vR W90e7QgAueCo5TdZPImPbCs42vadpa5byMXS4Pw+xyT+d/yp2oLKYbj3En4bg1GM w71DezIjvV+e01UR++u1t9yZ8LOWM5Kumz1zyQLZDZ8qIKt1bBfpa+E0cEqtNQWu iGhQE3AHI8eWV+jBkg5y2zHRIevbWb1UPsj43lgkFtAGHk9rrM8Rmgr4AXr531iD srBwauKZ/MElcF3MINuLH+gkPPaFHw/YIpLRLaZXZVsw3Xi1RNXI2n2ea29dvs/C Lcf1vYkCMwQQAQgAHRYhBPwOh4rlr+eIAo1jVdOXkvSep+XCBQJjm14FAAoJENOX kvSep+XC0DcP/1ZB7k9p1T+9QbbZZE1PJiHby3815ccH3XKexbNmmakHIn3L6Cet F891Kqt9ssbhFRMNtyZ/k/8y8Hv5bKxVep5/HMyK+8aqfDFN0WMrqZh0/CiR6DJh gnAmPNw/hAVHMHaYGII9kCrFfPFJ02FKoc81g9F08odb7TV+UlvRjkErhRxF+dGS wQoO0RCbf0Z1cs7nd0Vb2z4IJh4XMxBjWc/uQ2Q9dH/0uRzwpAnR4YX+MG5YrX7Z zBvDyR0r76iQwRSDKgioNgkr6R3rq1NZGdaj+8b0LzdOqtzKJ/eupDe3+H67e/EN qymtreGjrubpiU9bKvYArisUqhE5KtguryvR6Qz9bj87nPg33DT3WWGVrwFRxBox dbWzjQFv0wug8m4GAwVF7fPR5/eW7IHw8zvgn0vSPcZz7MZ4e6Y5jN4kA5/xWJYZ Sps54qQWB+FA30unIXN68KqdIzONIbtaY3W4/JjJUCm4T+wEjKaH+wJX8w1DMjlg mkTmGh/UrTyC1vXbPgk9Sy3cRTICR1T9z7W8UlmTtnKrUklrjlFR7SXzrEXzLGOX Fm+NEHpHNXqzcm6c3QfzY/yQ9HSAQ/t7SUQ9caRePbDz3/msyPxtGFor9roQv6VN wRXCyRgkH4Y5tPhJAQ8G/FxX+VXFb93QL0lfelb23/BBu6cUwW63SRn5iHUEExYI AB0WIQQeB2Johg/5/ikUnJwDU9SVF1S13AUCZISO3wAKCRADU9SVF1S13NnqAP95 LA1Om9XSAKl76VtV+L3JPDdAwIdbNa0OsRT4Wm7U3wD/YoFrdHXVHHQFKwYeUUhj XZcxnZLe9Ixo0/JP+RVFVw65Ag0EY5V2yQEQAOqjzPpMUCGu8eElXnAd2PruC6hi +lc/yC90KqizxIuW6qLQBaAkTCWq7suYpDqoygn7YM3rL50S285WAECAXrcst/cV Aqr0UH/e6p4iJCUIiXcfjd/wq20RnN/+VuvLhjpCFLY5czfVS31D7Uh9MbC+zUTz 8nVTiNCsAao0qSdfJDIzB4nSO+9xIsme/dLsI5QlU5PdxOBV6HdEhCUXOoratJCb KAOlLxtPwyMKxmv4oZ7Mqlt10peKjhpBb97qcIzJhHxujQZD0OmzIA6xoQ2eSCGd xCEDsZ09kr3Esw1AwKnQ51xmWpFWNFk6627M1bo8+hzOz81CrTZhYrgE+1JXv6V1 L2A9lMsimdE1BHNycDS+dBOpIB9qxXCwAab4ykfvNxox/ZPDUrTy7v7mDI5uDNTN CYYsKCj1UidycOKzSziB9Oa2uvmMJ5XstgNBf7Z8Cky1dtVd4ol6bU9L5nos9tbY eSXFi4bmcWB7AJiVCMq6N+LBbUKWGLglB4TU1qhttpqv31X9V6ges5gARY/RuRTK sVyhwsn7SDcqmNKRy0im2AYakwEp7hT07ulahOSLxjP+5hCf+nSJlwbxJ8ozwjjb zeN2yLlJSI00klkIFBNUDt3wzFRW/n6qlf+/lepgzekfNrYMtfPB8AT07Z2A3U4x lgiV346dZymbY/EjABEBAAGJBHIEGAEKACYWIQQL4zJ110yVPHn4EQfZrSoYBXR0 ywUCY5V2yQIbAgUJAgIpAAJACRDZrSoYBXR0y8F0IAQZAQoAHRYhBLYVJ36BCH33 XIGDO25Y3pAfABrvBQJjlXbJAAoJEG5Y3pAfABrvuBsQAOlQFPXhx6whO4yw5Ziz IS02YHhSVMVYKS2T9jPIKi1qxnEiEw9eKH0bW0Oj0TEhZPyM2NJID7DRWK5r8+Ks Mu8jwm1fUmIrefAx6fCVfCWRECT1MlbL3jhh6AcX/nK2e3Bn8vgExhzczO3JlvD6 wPCc0FkpiY7yDB9ihu1+gbE5Hg6dvftttRXDrbEdAifbNp9KYxDigxdlOb0S14hj CBysLWH5Su/khcIlkeuqZcI8TmDldnUb2OqTCVpFhaNwsPSrHBzmb0s2sXo4FL03 pLsOdwhi31W6kjk4KvW5FKrOpoEwUMKVNMf50DHdvonUoUHRSIc/cV5NqUWHwvc0 T5031qk0CCRRa/+/iij/p2RG7c1mx7ZECj+jZfmvjSqT+WHJ1BFlNJMWyK4fdVRZ WyCaoAecdbukwzDwUCUqHJFIWeFtbut7SOPxcwg7sbnKNApAKdi491dvH75s/U/O wRYO/2P+ymHlqtyix2jq0ReSVYcQPXswQ8i2ifX41F+xTSl4RWCBBeXB1Nxk3+Hs V4Jnnp1zAJZ0KlKW/oJxbNFdI1TImkpr2p8ioFf+aiePLvDkgeaG8vABgjoihPXW HVAMR8Z+GvBY/A6OdexpibkTvC/zDr0/Exs4lsylZKDwvvFbctcpHVXBeCBQLX5v fLrsTkaCLWF/SV9OdMykvYKU7ZAP+gKEwhp+HPFuOHZbOBhqFUdkfeCkdzX/QGdz Tuz349roRhgz2vRfN7MtbtuzA6NWWhEWt5DcUgX/Y5I3Q4Z2bt3JiXQ6WJMgMMOX Ar+XxtxyRRykc1HV3DQ/cq8OWYubNnIbgebPNIFr2OIWKsR9yDaucZzpmLfzaMZU Au5hWmU9fIw5SIKGnQABBnNMhilfD+CkETp6baTvjTK4rpaobjJdeCTrsWgfXRNC 8x3hDvcrjPD70MylOGVQdx8GYChWJnCKXsLTGX7KwdfxkjclTyzWvdcCemp0eLha mLGb9y1dtWdNIDcVCvZJy0lipHVUdFYYxb4iLZJANL631tlPM6AA8sO1/L4mqEGn AIHVrUQd+2QkSiOl9mKlpgaR/fJz683BR5Qen9ywX0JPtBupqPW3t9VbO/uNxUql HCeAhPi9NLOpujpYLfgW5QAfS3u0nkp5nrbkCoQUua2q0Oj7J0mFmtWtcE1c9+TH mFJVb8j2G9yQw3ADe3Qp9ALazP5nVDVri8NZBhHK1/KuBmRYZtcyfqXUnKoiiWAl m5rHaRiztW7e3wqm2oJu/RkEAagybutEuBWh2Ej2+gDxjEKKtIKGu54lif4kqTww jKTcN1ekGihwwgCMUkBSBeNXk1ClkzLFHwESJCcFwdEgpVYQTKFsu0emYISyco3I pUajGzfUiQRyBBgBCgAmAhsCFiEEC+MydddMlTx5+BEH2a0qGAV0dMsFAmWFy28F CQPyfaYCQMF0IAQZAQoAHRYhBLYVJ36BCH33XIGDO25Y3pAfABrvBQJjlXbJAAoJ EG5Y3pAfABrvuBsQAOlQFPXhx6whO4yw5ZizIS02YHhSVMVYKS2T9jPIKi1qxnEi Ew9eKH0bW0Oj0TEhZPyM2NJID7DRWK5r8+KsMu8jwm1fUmIrefAx6fCVfCWRECT1 MlbL3jhh6AcX/nK2e3Bn8vgExhzczO3JlvD6wPCc0FkpiY7yDB9ihu1+gbE5Hg6d vftttRXDrbEdAifbNp9KYxDigxdlOb0S14hjCBysLWH5Su/khcIlkeuqZcI8TmDl dnUb2OqTCVpFhaNwsPSrHBzmb0s2sXo4FL03pLsOdwhi31W6kjk4KvW5FKrOpoEw UMKVNMf50DHdvonUoUHRSIc/cV5NqUWHwvc0T5031qk0CCRRa/+/iij/p2RG7c1m x7ZECj+jZfmvjSqT+WHJ1BFlNJMWyK4fdVRZWyCaoAecdbukwzDwUCUqHJFIWeFt but7SOPxcwg7sbnKNApAKdi491dvH75s/U/OwRYO/2P+ymHlqtyix2jq0ReSVYcQ PXswQ8i2ifX41F+xTSl4RWCBBeXB1Nxk3+HsV4Jnnp1zAJZ0KlKW/oJxbNFdI1TI mkpr2p8ioFf+aiePLvDkgeaG8vABgjoihPXWHVAMR8Z+GvBY/A6OdexpibkTvC/z Dr0/Exs4lsylZKDwvvFbctcpHVXBeCBQLX5vfLrsTkaCLWF/SV9OdMykvYKUCRDZ rSoYBXR0yyOqEACitDvbkbfjaton6izr4T8QU2yvhJHkf4B6KeVDbKY1J4784OxX p2bJgPeF53SYBe8gm3YHjp8ULh4A/19U4hswyE8ymcm5nIs8OLyBdxkuBZJGEnzx H3woiyYqWH7991kzhEjUkuMgKLuTI1HiO0oLMuPQNhUHOnWafSVPC0XO/tIL12Om oUuc7ligY9Z9AceFjTZOuHamixHAAc6hpxdIW+yhC/qTpc2VK0niWeuQfq3453iR Tf9MnR5Beztl3ZYRWcx7UiFuKGwZwBibNnNmUs6GyQcJ5UTa1oeJcLqHi0Lf/r0j Xo3wgJq7EZjjVyU+GI2ZVoDOaS6c4/OvLm62XoeSlnn/dQxUcjUki+x8lb69IxSF 1xAgsC/oNtFZYd5rHdlnqIBUYK0lLtSCXBkzVeivSiQa0hL5on8LDu1nw2bXyW61 yt/YxVb4FanMxAqdYVBhOfU0RaPNifH01rbb4TwC9bTZN1LQ1KI/Swb/SruUE0Ry T28fhYRtsReS2PnUODghJSFDJbwFbBZf6RKI16q1xqKRRvxIWPm+lMOi1NLOKR9P +OKy9HmChMw0UJUcVl1cJ2xtRl3wi5t6AA6HoNv/TrLeYVgMR9wYmKlpvjTQ5jTd rbHD1XP5jGsp8QsJMGja1m/7cryReCpcVxvImeReaOdgz+zDmQqq3O5zuIkEcgQY AQoAJgIbAhYhBAvjMnXXTJU8efgRB9mtKhgFdHTLBQJnhEEJBQkF0/JAAkDBdCAE GQEKAB0WIQS2FSd+gQh991yBgztuWN6QHwAa7wUCY5V2yQAKCRBuWN6QHwAa77gb EADpUBT14cesITuMsOWYsyEtNmB4UlTFWCktk/YzyCotasZxIhMPXih9G1tDo9Ex IWT8jNjSSA+w0Viua/PirDLvI8JtX1JiK3nwMenwlXwlkRAk9TJWy944YegHF/5y tntwZ/L4BMYc3MztyZbw+sDwnNBZKYmO8gwfYobtfoGxOR4Onb37bbUVw62xHQIn 2zafSmMQ4oMXZTm9EteIYwgcrC1h+Urv5IXCJZHrqmXCPE5g5XZ1G9jqkwlaRYWj cLD0qxwc5m9LNrF6OBS9N6S7DncIYt9VupI5OCr1uRSqzqaBMFDClTTH+dAx3b6J 1KFB0UiHP3FeTalFh8L3NE+dN9apNAgkUWv/v4oo/6dkRu3NZse2RAo/o2X5r40q k/lhydQRZTSTFsiuH3VUWVsgmqAHnHW7pMMw8FAlKhyRSFnhbW7re0jj8XMIO7G5 yjQKQCnYuPdXbx++bP1PzsEWDv9j/sph5arcosdo6tEXklWHED17MEPIton1+NRf sU0peEVggQXlwdTcZN/h7FeCZ56dcwCWdCpSlv6CcWzRXSNUyJpKa9qfIqBX/mon jy7w5IHmhvLwAYI6IoT11h1QDEfGfhrwWPwOjnXsaYm5E7wv8w69PxMbOJbMpWSg 8L7xW3LXKR1VwXggUC1+b3y67E5Ggi1hf0lfTnTMpL2ClAkQ2a0qGAV0dMsNxRAA suW1aLh+hgydW+iH6DmdQRMESsB1kE02kO1462TAQaziIAvNoxw5h48xvyEnrDA8 d+9IDMyxdrLmAbndUlSveMa9+EPiGHwr6VTyFL8nA5F7DcFi4mjEyGKe18JcaAlY UtvHgWH6EjiX2iSXpsrJFEhtfFNolZ5sp9LFI6hOBihSJxZK4sbMR7Q6IkDuAVpT FLiejBRlsXpFvTGL6040CtxbL5cqkVMYP38rFMTuc3pGGJA4wb5EC1dGjUi6XjbY H7kuCAFyXqV9eQQP61x7K9W8qnXW+weCIMKfSX7AcCtH1jXBAM6lqpPrh6amc+/r bg2eNA7DmgJnEY4apIcDB/b4khRMga2ozeGWWyIvOaVvR2R7ALQ+Rgut85cM+4+V l2PHmOzW/yYdHVb5REQItFR5COb/mGUqYhkCtiV3nXo/K0uOQKu5SBbNzLuNvuwd n+Eimxjl18VnrGG7sjtUa0MLmtr62GiEVrhrDqa/biHp8LdWkAQjLZ4aTRh2XZig gaVFZHmkw3ILPyKKM21UXdM0YRk3TGVK8ODQy58ebPS4v9yYT9gUA9UDkDYeGcF2 qjoDPVNvcG6H8jCSsPRl1KZwtqqITCOSAIAPI4Nu97kO6nbOyQpYlwjd1MhvVXnP 66mHSvmqaxbNGX1mF9B/yERkBkooNZrKuJSvBTC2J1q5Ag0EY5V3BwEQAMpFVczZ o9ZPNsgW791UW5o6wnrnd1nIO+S4rc37q2TEz8KGHCuxo5NwffZ2t6Ln04BI54pb apg17b7a0hPka37HFkL28n4VyMdx0CsAm3QEfUsdK6xwKV2SucYeVcrV1upcN4Pd XD7su1I7/A4CWXFJG047zJ0Z89lJZiQEiAq7ghvEoinC0sm+0a6ao/ocqCgWCKM1 yCPOyzJXleRrv29SRnYziMR+q2U0x9xg9Xl6GMwUmFwbJc9nORVvLH7fbU6/du8E goAYrglFOFZG/TSolSGWRSMiavz0JSD/i+rEN4aIT4WfBe+L9Wy1AmrNxiAO+zKm zHQu3JSxDncr+y+hcd+W0gqw10FoI9jWLcL7kR+6a0iOjuJSXSopq2l3DafiPxtC Fmr4CGQhzBHM6e4/v/NNd3F0XpVbJ6RQph7lkfvfz8q2lvUlHhezJ0p1xXmhff9C HjdVMhmAmz5+imBAXk2mottNfKb0pFEen1xY3K/UPA4g+oPsSj495MsvIg9eIMCc C3/z0SEUMWH/styyJzPqfpyfGwZeTcIj9vg2o+RnGvmcLVYA/EGToPk905kv/cK7 3oy8bZyOB0zMg7T9PaWgLUO0sqjqo0Mw3knFySg3oRXlcilPQvfPdX0JvwLpc9DW lr1+1GkCXJ08lWugJc96CJQupKRb1IbC0oUXABEBAAGJAjwEGAEKACYWIQQL4zJ1 10yVPHn4EQfZrSoYBXR0ywUCY5V3BwIbDAUJAgIpAAAKCRDZrSoYBXR0ywwtD/wI DmEcHdFlyFRTomUBjbeK2uzcZIhkkgL58lc63UPle5iJ2FBvmYS+0rQS53sVEscc n5KfkOwTryKllvWbl0IzuiqfawxALcfWpfZJHzTMSnDHfgXvOOyFMQruqRDAHAr7 PNC0CnbT0sEF2ZFzad8M9fLqtkXUx4mgECNGJ4CVqg75KY8uUzv/BmRwEf587FT5 /iAIed5MjFB2VFDX9GABcvTTbHxCZIxnxl3cs15SxT0lAofZ2ueU6kWYWZSXFeaE M/4ymPJws2mmV0AkbJghLXCn9Mx3nX6NTZZ9Harbru+RzW3/Hg3DZd0J9vko8Paf P0l1NWtgyX74CqvTgjzTxXTnqrRXzcczK7fhcC2u4i0prPtXXcyyi7SwpoLikaZC LFFhUmOx+mS5TjtgFyFZBNxnO7iAwkzfcTcC9sPoWaFmiQf6q5EIYzG+WQpncj80 mxl3HWOP6oFj/hZJRYseKeMkvJzLTo87rFdM6CsMrLwETR6e+aWM0btPFil1rXVA CNOjsy0bxTV8OJEfyxnYmyjvnBvB0kdiaVEDdVhxgSqzLAX4mgXa49/V6M/uzMr+ n3/A1Jdk4V6fVm8S5cFIXxoUat3cB4xGaT9OWD3o1NPr6eS9Vo0EsJlRl81SG68f S+Qtk2fX27T68YG4Aa3zMfZxUsVuFLtTuQbRC+fJpIkCPAQYAQoAJgIbDBYhBAvj MnXXTJU8efgRB9mtKhgFdHTLBQJlhcuqBQkD8n1oAAoJENmtKhgFdHTLoO0QAJsT E9fkleb7YzPEuP9GJ3jx8PGdWm7n+8UNdr24kS6gOXVUfPZrWa5So21hcIwZb4PZ DqHSVSQnRciKhSnG7gplYPNGZ4+FWbLr/mBRYarjkVFLUuCPexSIjxV1KSGJnWs9 YTVAKZAz75GpCML6jD6biCOQCQ86wqOdWvZIZR8YvurrxR64ABB0rjbsaG8cNOUX 1cwAfdLwthf64dS+2m3lqNGDHkP5eNL0RIxC5gXYEp0lvmlMH3ZuO5WrfH73PTDg 89bxXeuhrFmSEwf4xWm603oi8/2qQvR9/7jb0o+t71NQuWrWIFONZWWgZBUGso+u yT3XgY4YqKGR3z2QzKHYnJ6M7SvSYpqS7RtcxcCXF0HGNfES8cAgtKVpFtbtSwXX p8O8oLyjmVIO/NjUpbLOGdFIsarsezLFV9f2fqZ63J34hyUSg8LrYVV1fA5DJUpe bbX4hLpdk0MMtgG43BwKIGlJTpL5RkQ/uQU3YW2kairy7o+1imDD0TRzQxtdjVOI 5vnlTNcfJZIIfLx4drABA12OvpX3dfPV62R+8BAlJFT430CG6AISJIBqJRFvuikm nZGUvEHmOUs/FLbbaXTPkKc7tR2WIwljRvMV+Qk84cWcX6YchMslMuiDM1mtlQZi g34WHGSE+zCWnXAslIHlSwox7qfdO0Kz2XncSbIAiQI8BBgBCgAmAhsMFiEEC+My dddMlTx5+BEH2a0qGAV0dMsFAmeEQS4FCQXT8gIACgkQ2a0qGAV0dMsm1Q//V09x OutSbWU44KRurdnGKsk56DFlqXtjGYJqDPrODpX3M8IDf2MuTIN2yfPMv984bAbO A9RL7EaGVlQUW9QWPURMsZKEFQljhfxRJO9JoGDYI7uRDnSEi6WjVvgUk5OiIh0K EI4jEcaLCzveIEcswrVDSAn+7nGvewP8Rrx7qMUNvLAltxiMyfGXneavRs3sfusz db9LTTY8lCU0xrslaXrrvfCkaRbskFi3S31I+1ZB/ewuAhHqfc13eRBjPwQOanJF epAzP4GF41fVQN9GtssATCD+dV6OFhYjfWJbOIcPv277wCvGIFucM9XRjbkCIYFQ E5W+1O/act3Obj1sB90C+cVOgCng37YqfObYLF19RE4+a7NUAh/GxHj+8TxUyvvr aWWyfNqTMDjHMShNDjG0qSzFX7vfyUpmfAfz+6ad78aks9LMf+86iGkvBhXFs7cz Vv4PWWYV1+WShNU2Y9yMaH3zpWUaREdB07HKbLva4Y1icqWVx+z6xs3PvsqbTei/ moXiZk7ohpbBm0htJlki22ARYrGXSK6w5RQtCZoBW0DEj5JNBjkK6XbAW3VFuAA1 J5wLS2z0eIR5adP+/SxQUbTq+ZFiOGdBP1g/783e7zEdyA0YfA2KU9OdLzupUix/ x+JYcxmrZXndSMObd0IiWOhwXlgarbJJMReOORg= =cYaK -----END PGP PUBLIC KEY BLOCK-----
<core-secretary@FreeBSD.org>pub rsa4096/4D632518C3546B05 2024-02-17 [SC] [expires: 2028-02-08]
Key fingerprint = 1A23 6A92 528D 00DD 7965 76FE 4D63 2518 C354 6B05
uid FreeBSD Core Team Secretary <core-secretary@FreeBSD.org>
sub rsa4096/CABFDE12CA516ED2 2024-02-17 [E] [expires: 2028-02-08]-----BEGIN PGP PUBLIC KEY BLOCK----- mQINBGXQ1o8BEAC+Rcg8cmVxuP17Vu+q5KgCx/XiulQuqKXAqqBlYCH2jqk6DINP yFrREGBhzd/qNmlAYEahQ4Zgl0bUZNTrZVDyzicOvPP0jH+KSTQwRs7NOawEdlVO cyHrwDCPEqf5ZzD4NhfTriEOw+j0pEH/onitUGvoQRtx15xWyaJQxDEBMTYMLewE 86D1bltwnTNczE3UZb7oQLJXkAX5hcLtou70XJGgZITvJkK+kp/xot2eFjnqRz/u WeXnKhYAmC07EKwZ1uw047eHKwMMRBYqzApLwoQtfE430Kxf2q8de64x8zDbi6YM 1J4r8OAxOtHVyfJ0j7Q23DEZz0VVb4b1Tx5OG2Re/KSNvqI0awJO4TcRmOR88OyY dzyXgnX6Sa7GVQY1FXvn7vtFuDAt7egZOzeomSHL9bdX07LTQ4UtM88EV9wm3q4q smoatV9jsvPQ1zxCU3aQD/5eWTJH2/kz1LIuBL/Qi5XQpJn91lBtUWJrCgkHWPGu f//rnnXmsG7DAChW+yZ7cFO8lfNa8sFhPqSxCYphWmJTrvadyQtDngB8JakWdnmK pfGS6y5lel+181vw38ZZKt04AKM+nDY8051lBM7Q9Q6kTLI33UZeImndx5xYukVD kV6aQ31HYfEark15c7iEz+OAcwFnM2ntXMt7kKGd40CqzusiPcQkPqPbAQARAQAB tDhGcmVlQlNEIENvcmUgVGVhbSBTZWNyZXRhcnkgPGNvcmUtc2VjcmV0YXJ5QEZy ZWVCU0Qub3JnPokCVwQTAQoAQQIbAwgLCQ0IDAcLAwUVCgkICwUWAwIBAAIeBQIX gBYhBBojapJSjQDdeWV2/k1jJRjDVGsFBQJnp8PiBQkHeofTAAoJEE1jJRjDVGsF GMIQALhj+mNpH8OmTFeihQ6t9P8un3llz6Wmqe/Q+ULWeqJvV/uC1J5T9fnoGhwF MgECuguXYJtoYQ16KXnsSOs1tcqMOK9GtEtFJTGe2DtfLiBednwUvu9j3HmTlwLN M+7rqkiC0HCg2qSjcMjxbVbA5BSgNkgfyTSO2YdjfaZ+ceiHwo/qa5xWE6i2dMR1 PLGMMHTeELdtdSH6VR9/3h0qt3qzwdMBRCVAQHbim7CqwjUH9jg+IOySXl81jNoB xuVZR3pKshyY4Oxo1dK+W86Uiff/+c4jCAxokGWIR7C4MkZZWUQqV7920gkZFC/5 qzpT1A1/sFUg8HfFTr0vCoPSVFWn2+Tto3vr78DICVaAf02aYAFlyKK18BMCoHkS hDDO+/JQZmvHOIgEYK+T2WN1c9gm9IDJzGZuH0X2C/vkREnJKkccJfB4pXuN10wt fqyP9fn8h6+/t+sv3qNLm4d8fkmLXofulG3WB4i/F+Hip2rjPvvBCF7zl4xy6cJ2 xVY5HUOBTqmIwVhYwUpXaqNoWa/qJBLTuot3z7ciKmKX6Lq+Dze5dzhrPNl/CalC HBf3miHRK3TZbYLooG3bcEWgxU2BnBi3vl5NpCoUOKkPYRlALXi2TyHmPxO7oT4e mIzS6BgnXOqO+AXvbKKfayuSePdBqkNMK/SMC4Dylkf6Xj25iQIzBBABCgAdFiEE EBpxaxYrAOVb7eoFrbv4YQo3ibcFAmbu7x4ACgkQrbv4YQo3ibcr5A//TIcbD/EW YJz0zrUQdc9xG3UNfU6uHmQzAuUy5ginevyqv0TSso5qvSkOHvdxbi41rfMiB2RJ V3q0n0PSvHFld89fOTZUMZXaPvozCiBYWScrt+KA/2pq3K8mUumHS+IFtpHLL2Tu +gI8XCHUFxO9HUThM/rFlIyEdzoctgmqQ7IG4uZG+o2J3w09llhDAUe0vraJK1On p9yFACnRrhqvl41JeUWcv9MH9JcwHUqtUo9WLTCIb+hkByTOyRfHBYpYw//bdXdf 6rkCwKVWpyMDbk61zq2VsS1kqbP9IH/A8CsBnA6mg+zPq2i7HIFw8Swj4OGJcIvG a9ubUYJRjDhX/vBpNrtncANZ88FQmA+Maq0vu0LS5IIGyIKkvd1fKIsyvBDDa9kE nfCW0XMkJA0Gf+kxdB+elXQHBwKO2sr5BiKnJT5lJq3Yu9fxxGBnf93yiN4E9bmF gG7cZxpyb1Bp76TJhLcANyybOTjCtiNRrgqeaSx9/6hSPfPigGXIne0H2lmJO6oq jUrsYmFiWvU9sc7AcPVw/eHG8FgW35TuwKX71z8w994iaahUPNcSVyXOUD+QNROv HhGUXrc81t613rivh22N0NZpNubVatq43KV7+/bnPyWBIi1Awh3vIFsNNSQSrYxF lUuQaAHQXTeZMZ/7npE4t86seMt0T7BGn765Ag0EZdDWjwEQAL3VwFifpnRCYzQ4 VZ1dAjp8w542iRprqeA+C3tvNbk2OvKpN3DIc49l2bgNZ/VI7/T58lEKrFsgLK4w AWtv18OV7xuh0AuOblmq5MvcPrUelkPj5HA7M6Ng/rAubuHfwdP/IjIrzzY6+XDh fP9N5KIv9VRJYT23BbvLPeit4J4tQEB/NpxL3L6zI75qq4R3T/EkHP6Y9Buup9Lr isJlcxkSK+CyORCgTpEz6fWsXiTDgS7cTaQ969XCygBpj4wRQzwkBdokxo1wsiFt 4zLt07/PrPYjeHltTDkrF9XDNhLNJ5GliHnd01oHg1j5/n+9Osvh1maoFwuBxXTN nTZ2P+7RKLBaVQVSkUa5KJbXoM3v7bMbXM5aLs2XjglrAzrZOV+Y7zOu5UYQdpXd 7x8XAEtEozRJzt7dosQIhKx9h4LlltFFulDUpf5VCvcUEoAzMbiX0aju9n5Rwsql DHatU9Mm3W8OdFXj1foIXZD+VX2Jp9DgxPLoAJ0CWhPXJ8f+WFSJZCjWoPJEJKWY 0EOxiXyAuvAyniAZAC/eKZkfGckXmu7edRgYbRTTwPmZ/axa/k9aHsHLwmbxuZo/ xxQXzqU70EleHZ31A3mOqsC1epjN6dn4AFKgvVesP/K/fbvSsfsfiABS2A/68ne4 zJG73Tnk4L6J79vrXc2iMJbmdg3ZABEBAAGJAjwEGAEKACYCGwwWIQQaI2qSUo0A 3Xlldv5NYyUYw1RrBQUCZ6fEFQUJB3qIBgAKCRBNYyUYw1RrBQd9EACMVckxzy4w aUGlERguJ+kslS8MkMjNqnfDPLRDVxbUxNvbbhw7/u9blM65DCGCeNLc2n4oiu5C E3I095AKmvq/0dOa81mEEdZkC1CVc64bXWbEyz5AtSHUpgdxRso6C+YopndSiz1T WcIagQRXfWaw3FBWPooA87gmibmSmCegCtqx+uyc5QxX2eFI8mRK7vlfnGpYKHs0 D1/yUSGQOwoNRJ5FYm+ynfDE3FzHEQL7lv1vpv1k3xNKfBziMMg4IMEBKNHV4VKN qJpa8UCodeTGSWQdNnCeCWPsxz5oQjCcVH9Z3e8sMpWLHhRcBZzSwXUOws2GbRMH xHwrfrpHJcrBhe64pgfGOvZLUJ9BDs+8egTHsqRFacipbtTR+hhVhuJEHDaQQWuM 8IRHj9HIuTAczET8JTDHTMIoo8DZdOtiW/YgqCDwYghkI77d12oNQqYoeJ2HiqbK cGzwCpsR0A+p/iOAxJG13tsxqZV8TQ8iTokWG6ACtZ7sfeWEhxqMbUKUMgogZn0I 3n1kV+tUZC6BQrIYI7TiKg95wLZsIydeoIsQoNZwvyKAXfVmQ62YjIX8njZwN+07 8/ipUPJxCYa8zL8BZyDmoFJqa3y9z+11+vtiZ9t+aTwGvjpHDwyeCJco7go9cU3m GRFZYciqIoG4n3tl8Pob15vFlVqk47rRqg== =8TzT -----END PGP PUBLIC KEY BLOCK-----
<portmgr-secretary@FreeBSD.org>pub ed25519/E3C401F60D709D59 2023-03-06 [SC] [expires: 2027-03-05]
Key fingerprint = BED4 A1D3 6555 B681 2E9F ABDA E3C4 01F6 0D70 9D59
uid FreeBSD Ports Management Team Secretary <portmgr-secretary@FreeBSD.org>
sub cv25519/2C92B55E27A641C3 2023-03-06 [E] [expires: 2027-03-05]-----BEGIN PGP PUBLIC KEY BLOCK----- mDMEZAXJvxYJKwYBBAHaRw8BAQdASFAC20WL3R1T6uNyGMZbfJCxDkcP4C5vi3Op tcZ2fbq0R0ZyZWVCU0QgUG9ydHMgTWFuYWdlbWVudCBUZWFtIFNlY3JldGFyeSA8 cG9ydG1nci1zZWNyZXRhcnlARnJlZUJTRC5vcmc+iJYEExYKAD4WIQS+1KHTZVW2 gS6fq9rjxAH2DXCdWQUCZAXJvwIbAwUJB4TOAAULCQgHAwUVCgkICwUWAwIBAAIe BQIXgAAKCRDjxAH2DXCdWYN1AP43TjyfZtZ3DLYT++g0+SuPsoO/3yWVybA+UmFL zb8MngEA+LLNUfvEwCuXS/soh+ww5bpfmi3UUmeGiQEAXug3iA+JATMEEAEKAB0W IQT7N0XIbxXo7ayBMvzYKU7Du8TX1QUCZAXLkwAKCRDYKU7Du8TX1XHMB/9R1MX4 6zMgpKqPPt76GOI+eGEdBK6bY8aJZjQGdqTh9f6VtXVoTGIG7cvhc9X8tDBoB0PT 2KZWheF51AV1+NHU4HwLAQ1BMebrFvWSfkw4xg4fBGwDhz9/GN85No+Js772V5ey 8lRiL6meRVWxMlLyWcxGd8JjcC5yX/iAUQ3SBGCLqW7unWjjg7CTd+AMBwcqPGrv ax8q6eFVguJcHJAjMnKf6HAy4cpK3s+uMoUBCGnszSN12B3ysKfyC4pNO/pix5tA Q5v8aRqTeFPh5zmNhWo0KGPzplTPqRQSHDl7GDQC8Ru3MhzFkeWzHsexjZVwS6W2 DPcYpuuAsA0XOZIZiQIzBBABCgAdFiEEEBpxaxYrAOVb7eoFrbv4YQo3ibcFAmQF 0u0ACgkQrbv4YQo3ibccwg/9F2Xuic3nhKxRbB3mJeDo6SYQETa/Gh1qQ34+8zlt 8UMazOx67gnYQfy+pXjro6eQ2up0a4eUYezcNOudqAQD21nRz3HA6EQVNcE/TzEA xl5CJntTaLOt7S+EDXFW5BuQIvhhoMGgm8+WNVgA0EJ7tfL0OcYBSvr19fqwChEn 9c14cSk6mgHSsleP5NvskYN053pxHwy0LTSb8YBBv52th37t/CRFC1363rS5q+D7 JixFopd1O5pKpA5ipvE4gGgRjPtwjx0SjjepwK/3fuhEJQQyKzTIKlMfu2Dj/iR2 Li1Sfccau5LQXOj9fUITU3u1YG7yrm8VGzT7ao4d+KRwgMLjd2pLqiGIbbJwGBiP FRmtilWQoeIlmSlFX4obAA517DOK0pW1mH8+eEn4EJd3SekT3yzFyKTASv0J48Z8 3F928xg+eZvHxVC0t1J+J5IG0gt3EEncuWKIPQGR7PiQbti6R3FQVTz6WfMWOebP Qi0E9F/Aqakr6Vj2sKGrDq+ebpaF5G8Yw1YrUl2IDiPzkCegp3ZbI0wh11Xvzhi8 LXPQGK4jBQas4G8cegfitzmtdGRHYrbMv0R9I4mvaL+WlOuD2AvyVG28lguqVhnN AZP+ohdquYyX2CNCVvbKWAtXo6Ur0vWG8BL8m6defAtEkIwVBALaOHQOSI3aNUz4 lwy4OARkBcm/EgorBgEEAZdVAQUBAQdAsefmSfxEOdOr02+K/6noYCuJ1FeAWVz6 jFYQ+9w6jggDAQgHiH4EGBYKACYWIQS+1KHTZVW2gS6fq9rjxAH2DXCdWQUCZAXJ vwIbDAUJB4TOAAAKCRDjxAH2DXCdWRl4AP9h5ot212BK29S6ZcMBhHvmtF5PG1oD c7LnZycSRmbFiwEAndCMpAGOhDW8iVgDd0wLQq/ZMPe+xccfG1b3zFH2EgE= =iiAT -----END PGP PUBLIC KEY BLOCK-----
<doceng-secretary@FreeBSD.org>pub rsa2048/E1C03580AEB45E58 2019-10-31 [SC] [expires: 2022-10-30]
Key fingerprint = F24D 7B32 B864 625E 5541 A0E4 E1C0 3580 AEB4 5E58
uid FreeBSD Doceng Team Secretary <doceng-secretary@freebsd.org>
sub rsa2048/9EA8D713509472FC 2019-10-31 [E] [expires: 2022-10-30]-----BEGIN PGP PUBLIC KEY BLOCK----- mQENBF27FFcBCADeoSsIgyQUY8vREwkTikwFFlNg31MVy5s/Nq1cNK1PRfRMnprS yfB62KqbYuz16bmQKaA9zHN4FGfiTvR6tl66LVHm1s/5HPiLv8sP14GsruLro9zN v72dO7a9i68bMw+jarPOnu9dGiDFEI0dACOkdCGEYKEUapQeNpmWRrQ46BeXyFwF JcNx76bJJUkwk6fWC0W63D762e6lCEX6ndoaPjjLBnFvtx13heNGUc8RukBwe2mA U5pSGHj47J05bdWiRSwZaXa8PcW+20zTWaP755w7zWe4h60GANY7OsT9nuOqsioJ QonxTrJuZweKRV8fNQ1EfDws3HZr7/7iXvO3ABEBAAG0PEZyZWVCU0QgRG9jZW5n IFRlYW0gU2VjcmV0YXJ5IDxkb2Nlbmctc2VjcmV0YXJ5QGZyZWVic2Qub3JnPokB VAQTAQoAPhYhBPJNezK4ZGJeVUGg5OHANYCutF5YBQJduxRXAhsDBQkFo5qABQsJ CAcDBRUKCQgLBRYDAgEAAh4BAheAAAoJEOHANYCutF5YB2IIALw+EPYmOz9qlqIn oTFmk/5MrcdzC5iLEfxubbF6TopDWsWPiOh5mAuvfEmROSGf6ctvdYe9UtQV3VNY KeeyskeFrIBOFo2KG/dFqKPAWef6IfhbW3HWDWo5uOBg01jHzQ/pB1n6SMKiXfsM idL9wN+UQKxF3Y7S/bVrZTV0isRUolO9+8kQeSYT/NMojVM0H2fWrTP/TaNEW4fY JBDAl5hsktzdl8sdbNqdC0GiX3xb4GvgVzGGQELagsxjfuXk6PfOyn6Wx2d+yRcI FrKojmhihBp5VGFQkntBIXQkaW0xhW+WBGxwXdaAl0drQlZ3W+edgdOl705x73kf Uw3Fh2a5AQ0EXbsUVwEIANEPAsltM4vFj2pi5xEuHEcZIrIX/ZJhoaBtZkqvkB+H 4pu3/eQHK5hg0Dw12ugffPMz8mi57iGNI9TXd8ZYMJxAdvEZSDHCKZTX9G+FcxWa /AzKNiG25uSISzz7rMB/lV1gofCdGtpHFRFTiNxFcoacugTdlYDiscgJZMJSg/hC GXBdEKXR5WRAgAGandcL8llCToOt1lZEOkd5vJM861w6evgDhAZ2HGhRuG8/NDxG r4UtlnYGUCFof/Q4oPNbDJzmZXF+8OQyTNcEpVD3leEOWG1Uv5XWS2XKVHcHZZ++ ISo/B5Q6Oi3SJFCVV9f+g09YF+PgfP/mVMBgif2fT20AEQEAAYkBPAQYAQoAJhYh BPJNezK4ZGJeVUGg5OHANYCutF5YBQJduxRXAhsMBQkFo5qAAAoJEOHANYCutF5Y kecIAMTh2VHQqjXHTszQMsy3NjiTVVITI3z+pzY0u2EYmLytXQ2pZMzLHMcklmub 5po0X4EvL6bZiJcLMI2mSrOs0Gp8P3hyMI40IkqoLMp7VA2LFlPgIJ7K5W4oVwf8 khY6lw7qg2l69APm/MM3xAyiL4p6MU8tpvWg5AncZ6lxyy27rxVflzEtCrKQuG/a oVaOlMjH3uxvOK6IIxlhvWD0nKs/e2h2HIAZ+ILE6ytS5ZEg2GXuigoQZdEnv71L xyvE9JANwGZLkDxnS5pgN2ikfkQYlFpJEkrNTQleCOHIIIp8vgJngEaP51xOIbQM CiG/y3cmKQ/ZfH7BBvlZVtZKQsI= =MQKT -----END PGP PUBLIC KEY BLOCK-----
Ultima modifica: 11 dicembre 2021 da Sergio Carlavilla Delgado