
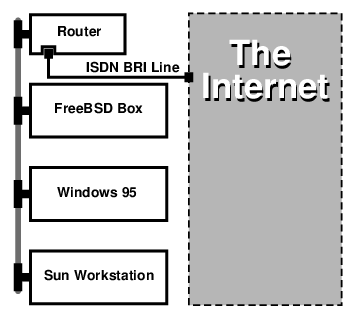
% netstat -r
Routing tables
Destination Gateway Flags Refs Use Netif Expire
default outside-gw UGSc 37 418 ppp0
localhost localhost UH 0 181 lo0
test0 0:e0:b5:36:cf:4f UHLW 5 63288 ed0 77
10.20.30.255 link#1 UHLW 1 2421
example.com link#1 UC 0 0
host1 0:e0:a8:37:8:1e UHLW 3 4601 lo0
host2 0:e0:a8:37:8:1e UHLW 0 5 lo0 =>
host2.example.com link#1 UC 0 0
224 link#1 UC 0 0第20章 高度なネットワーク
This translation may be out of date. To help with the translations please access the FreeBSD translations instance.
目次
20.1. この章では
この章では UNIX® システム上で良く利用されるネットワークサービスについて説明します。 FreeBSD が利用するすべてのネットワークサービスをどのように定義し、 設定し、テストし、そして保守するのかを扱います。さらに、 本章を通してあなたの役に立つ設定例が載っています。
この章を読めば以下のことが分かります。
ゲートウェイと経路の基本
FreeBSD をブリッジとして動作させる方法
ネットワークファイルシステム (NFS) の設定方法
ディスクレスマシンのネットワークブートの設定方法
ユーザアカウントを共有するためのネットワークインフォメーションサーバ (NIS) の設定方法
DHCP を用いて自動的にネットワーク設定を行う方法
ドメインネームサーバ (DNS) の設定方法
NTP プロトコルを用いて日時を同期してタイムサーバを設定する方法
ネットワークアドレス変換 (NAT) の設定方法
inetdデーモンの管理方法PLIP 経由で二台のコンピュータを接続する方法
FreeBSD で IPv6 を設定する方法
この章を読む前に、以下のことを行っておくべきです。
/etc/rc スクリプトの基本を理解していること
基礎的なネットワーク用語に精通していること
20.2. ゲートウェイと経路
あるマシンがネットワーク上で他のマシンをみつけることができるようにするには、 あるマシンから他のマシンへどのようにたどり着くかを記述する適切な仕組みが必要です。 この仕組みをルーティングと呼びます。 "経路" (route) は "送信先" (destination) と "ゲートウェイ" の 2 つのアドレスの組で定義します。この組合せは、この 送信先 へたどり着こうとする場合は、その ゲートウェイ を通じて通信することを示しています。 送信先には個々のホスト、サブネット、"デフォルト" の 3 つの型があります。 "デフォルトルート" は他のどの経路も適用できない場合に使われます。 デフォルトルートについてはのちほどもう少し詳しく述べます。 また、ゲートウェイには、個々のホスト、インタフェース ("リンク" とも呼ばれます)、 イーサネットハードウェアアドレス (MAC アドレス) の 3 つの型があります。
20.2.1. 例
以下に示す netstat の例を使って、ルーティングのさまざまな状態を説明します。
最初の 2 行はデフォルトルート (次節で扱います) と、 localhost への経路を示しています。
localhost に割り当てるインタフェース (Netif 欄) としてこのルーティングテーブルが指定しているのは lo0 で、これはループバックデバイスともいいます。 これは結局のところ出たところに戻るだけなので、 この送信先あてのトラフィックは、LAN に送られずに、すべて内部的に処理されます。
次の行では 0:e0: から始まるアドレスに注目しましょう。 これはイーサネットハードウェアアドレスで、MAC アドレスともいいます。 FreeBSD はローカルなイーサネット上の任意のホスト (この例では test0) を自動的に認識し、 イーサネットインタフェース ed0 にそのホストへの直接の経路をつけ加えます。 この種の経路には、タイムアウト時間 (Expire 欄) も結びつけられており、 指定された時間内にホストからの応答がないことを判断するのに用いられます。 その場合、そのホストへの経路情報は自動的に削除されます。 これらのホストは RIP (Routing Information Protocol) という、 最短パス判定に基づいてローカルなホストへの経路を決定する仕組みを利用して認識されます。
さらに FreeBSD ではローカルサブネットへの経路情報も加えることができます (10.20.30.255 は 10.20.30 というサブネットに対するブロードキャストアドレスで、 example.com はこのサブネットに結びつけられているドメイン名)。 link#1 という名称は、 このマシンの一つ目のイーサネットカードのことをさします。 これらについては、 何も追加インタフェースが指定されていないことがわかります。
これら 2 つのグループ (ローカルネットワークホストとローカルサブネット) は、両方とも routed というデーモンによって自動的に経路が設定されます。 routed を動かさなければ、静的に定義した (つまり明示的に設定した) 経路のみが存在することになります。
host1 の行は私たちのホストのことで、 イーサネットアドレスで示されています。送信側のホストの場合、 FreeBSDはイーサネットインタフェースへ送るのではなく、 ループバックインタフェース (lo0) を使います。
2 つある host2 の行は、 ifconfig(8) のエイリアスを使ったときにどのようになるかを示す例です (このようなことをする理由については Ethernet の節を参照してください)。 lo0 の後にある ⇒ は、 インタフェースが (このアドレスがローカルなホストを参照しているので) ループバックを使っているというだけでなく、 エイリアスになっていることも示しています。 このような経路はエイリアスに対応しているホストにのみ現れます。 ローカルネットワーク上の他のすべてのホストでは、 それぞれの経路に対して単にlink#1 となります。
最後の行 (送信先サブネット 224) はマルチキャストで扱うものですが、これは他の節で説明します。
最後に Flags (フラグ) 欄にそれぞれの経路のさまざまな属性が表示されます。 以下にフラグの一部と、それが何を意味しているかを示します。
U | Up: この経路はアクティブです。 |
H | Host: 経路の送信先が単一のホストです。 |
G | Gateway: この送信先へ送られると、 どこへ送ればよいかを明らかにして、 そのリモートシステムへ送られます。 |
S | Static: この経路はシステムによって自動的に生成されたのではなく、 手動で作成されました。 |
C | Clone: マシンに接続したときにこの経路に基づく新しい経路が作られます。 この型の経路は通常はローカルネットワークで使われます。 |
W | WasCloned: ローカルエリアネットワーク (LAN) の (Clone) 経路に基づいて自動的に生成された経路であることを示します。 |
L | Link: イーサネットハードウェアへの参照を含む経路です。 |
20.2.2. デフォルトルート
ローカルシステムからリモートホストにコネクションを張る必要がある場合、 既知の経路が存在するかどうかを確認するためにルーティングテーブルをチェックします。 到達するための経路を知っているサブネットの内部にリモートホストがある場合 (Cloned routes)、 システムはそのインタフェースから接続できるかどうか確認します。
知っているパスがすべて駄目だった場合でも、 システムには最後の手段として "デフォルト" ルートがあります。このルートはゲートウェイルート (普通はシステムに 1 つしかありません) の特別なものです。そして、 フラグ欄には必ず c が表示されています。このゲートウェイは、LAN 内のホストにとって、どのマシンでも外部へ (PPP リンク、DSL、ケーブルモデム、T1、 またはその他のネットワークインタフェースのいずれかを経由して) 直接接続するために設定されるものです。
外部に対するゲートウェイとして機能するマシンでデフォルトルートを設定する場合、 デフォルトルートはインターネットサービスプロバイダ (ISP) のサイトのゲートウェイマシンになるでしょう。
それではデフォルトルートの一例を見てみましょう。 一般的な構成を示します。

ホスト Local1 とホスト Local2 はあなたのサイト内にあります。Local1 はダイアルアップ PPP 接続経由で ISP に接続されています。 この PPP サーバコンピュータは、その ISP のインターネットへの接続点に向けた外部インタフェースを備えた他のゲートウェイコンピュータへ LAN を通じて接続しています。
あなたのマシンのデフォルトルートはそれぞれ次のようになります。
| ホスト | デフォルトゲートウェイ | インタフェース |
|---|---|---|
Local2 | Local1 | Ethernet |
Local1 | T1-GW | PPP |
"なぜ (あるいは、どうやって) デフォルトゲートウェイを、Local1 が接続されている ISP のサーバではなく、T1-GW に設定するのか" という質問がよくあります。
PPP 接続で、あなたのサイト側の PPP インタフェースは、 ISP のローカルネットワーク上のアドレスを用いているため、 ISP のローカルネットワーク上のすべてのマシンへの経路は 自動的に生成されています。 つまりあなたのマシンは、どのようにして T1-GW に到達するかという経路を既に知っていることになりますから、 ISP サーバにトラフィックを送るのに、 中間的な段階を踏む必要はありません。
一般的にローカルネットワークでは X.X.X.1 というアドレスをゲートウェイアドレスとして使います。ですから (同じ例を用います)、あなたの class-C のアドレス空間が 10.20.30 で ISP が 10.9.9 を用いている場合、 デフォルトルートは次のようになります。
| ホスト | デフォルトルート |
|---|---|
Local2 (10.20.30.2) | Local1 (10.20.30.1) |
Local1 (10.20.30.1, 10.9.9.30) | T1-GW (10.9.9.1) |
デフォルトルートは /etc/rc.conf ファイルで簡単に定義できます。この例では、 Local2 マシンで /etc/rc.conf に次の行を追加しています。
defaultrouter="10.20.30.1"
route(8) コマンドを使ってコマンドラインから直接実行することもできます。
# route add default 10.20.30.1経路情報を手動で操作する方法について詳しいことは route(8) のマニュアルページをご覧ください。
20.2.3. デュアルホームホスト
ここで扱うべき種類の設定がもう一つあります。 それは 2 つの異なるネットワークにまたがるホストです。 技術的にはゲートウェイとして機能するマシン (上の例では PPP コネクションを用いています) はすべてデュアルホームホストです。 しかし実際にはこの言葉は、2 つの LAN 上のサイトであるマシンを指す言葉としてのみ使われます。
2 枚のイーサネットカードを持つマシンが、 別のサブネット上にそれぞれアドレスを持っている場合があります。 あるいは、イーサネットカードが 1 枚しかないマシンで、 ifconfig(8) のエイリアスを使っているかもしれません。 物理的に分かれている 2 つのイーサネットのネットワークが使われているならば前者が用いられます。 後者は、物理的には 1 つのネットワークセグメントで、 論理的には 2 つのサブネットに分かれている場合に用いられます。
どちらにしても、 このマシンがお互いのサブネットへのゲートウェイ (inbound route) として定義されていることが分かるように、 おのおののサブネットでルーティングテーブルを設定します。このマシンが 2 つのサブネットの間のルータとして動作するという構成は、 パケットのフィルタリングを実装する必要がある場合や、 一方向または双方向のファイアウォールを利用したセキュリティを構築する場合によく用いられます。
このマシンが二つのインタフェース間で実際にパケットを受け渡すようにしたい場合は、 FreeBSD でこの機能を有効にしないといけません。 くわしい手順については次の節をご覧ください。
20.2.4. ルータの構築
ネットワークルータは単にあるインタフェースから別のインタフェースへパケットを転送するシステムです。 インターネット標準およびすぐれた技術的な慣習から、 FreeBSD プロジェクトは FreeBSD においてこの機能をデフォルトでは有効にしていません。 rc.conf(5) 内で次の変数を YES に変更することでこの機能を有効にできます。
gateway_enable=YES # Set to YES if this host will be a gateway
このオプションは sysctl(8) 変数の net.inet.ip.forwarding を 1 に設定します。 一時的にルーティングを停止する必要があるときには、 この変数を一時的に 0 に設定しなおせます。
次に、トラフィックの宛先を決めるために、 そのルータには経路情報が必要になります。 ネットワークが十分簡素なら、静的経路が利用できます。 また、FreeBSD は BSD の標準ルーティングデーモンである routed(8) を備えています。これは RIP (バージョン 1 および 2) および IRDP を扱えます。 BGP バージョン 4、OSPF バージョン2、 その他洗練されたルーティングプロトコルは net/zebra package を用いれば対応できます。 また、より複雑なネットワークルーティングソリューションには、 GateD® のような商用製品も利用可能です。
このように FreeBSD を設定したとしても、 ルータに対するインターネット標準要求を完全に満たすわけではありません。 しかし、通常利用に関しては十分といえます。
20.2.5. 静的な経路の設定
20.2.5.1. 手動による経路の設定
以下のようなネットワークが存在すると仮定します。
INTERNET
| (10.0.0.1/24) Default Router to Internet
|
|Interface xl0
|10.0.0.10/24
+------+
| | RouterA
| | (FreeBSD gateway)
+------+
| Interface xl1
| 192.168.1.1/24
|
+--------------------------------+
Internal Net 1 | 192.168.1.2/24
|
+------+
| | RouterB
| |
+------+
| 192.168.2.1/24
|
Internal Net 2このシナリオでは、FreeBSD マシンの RouterA がインターネットに向けられたルータとして動作します。 ルータは外側のネットワークへ接続できるように 10.0.0.1 へ向けたデフォルトルートを保持しています。 RouterB はすでに適切に設定されており、 どこへ向かう必要があるか、 行き着く方法を知っていると仮定します (この例では、図のように簡単です。 192.168.1.1 をゲートウェイとして RouterB にデフォルトルートを追加するだけです)。
RouterA のルーティングテーブルを確認すると、 以下のような出力を得ます。
% netstat -nr
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
default 10.0.0.1 UGS 0 49378 xl0
127.0.0.1 127.0.0.1 UH 0 6 lo0
10.0.0/24 link#1 UC 0 0 xl0
192.168.1/24 link#2 UC 0 0 xl1現在のルーティングテーブルでは、RouterA はまだ Internal Net 2 には到達できないでしょう。 192.168.2.0/24 の経路を保持していないからです。 解決するための一つの方法は、経路を手動で追加することです。 以下のコマンドで RouterA のルーティングテーブルに 192.168.1.2 を送り先として、Internal Net 2 ネットワークを追加します。
# route add -net 192.168.2.0/24 192.168.1.2これにより、RouterA は、 192.168.2.0/24 ネットワーク上のホストに到達出来ます。
20.2.5.2. 永続的な設定
上記の例は、 起動しているシステム上に静的な経路を設定する方法としては完全です。 しかしながら、FreeBSD マシンを再起動した際にルーティング情報が残らないという問題が一つあります。 静的な経路を追加するには、/etc/rc.conf ファイルにルートを追加してください。
# Add Internal Net 2 as a static route static_routes="internalnet2" route_internalnet2="-net 192.168.2.0/24 192.168.1.2"
static_routes の設定変数は、 スペースによって分離される文字列のリストです。 それぞれの文字列は経路名として参照されます。 上記の例では static_routes は一つの文字列のみを持ちます。 その文字列は internalnet2 です。その後、 route_internalnet2 という設定変数を追加し、 route(8) コマンドに与えるすべての設定パラメータを指定しています。 前節の例では、以下のコマンド
# route add -net 192.168.2.0/24 192.168.1.2を用いたので、 "-net 192.168.2.0/24 192.168.1.2" が必要になります。
上記のように static_routes は一つ以上の文字列を持つことが出来るので、 多数の静的な経路を作ることができます。 以下の行は 192.168.0.0/24 および 192.168.1.0/24 ネットワークを、 仮想ルータ上に静的な経路として追加する例です。
static_routes="net1 net2" route_net1="-net 192.168.0.0/24 192.168.0.1" route_net2="-net 192.168.1.0/24 192.168.1.1"
20.2.6. ルーティングの伝搬
外部との経路をどのように定義したらよいかはすでに説明しました。 しかし外部から私たちのマシンをどのようにして見つけるのかについては説明していません。
ある特定のアドレス空間 (この例では class-C のサブネット) におけるすべてのトラフィックが、 到着したパケットを内部で転送するネットワーク上の特定のホストに送られるようにルーティングテーブルを設定することができるのは分かっています。
あなたのサイトにアドレス空間を割り当てる場合、 あなたのサブネットへのすべてのトラフィックがすべて PPP リンクを通じてサイトに送ってくるようにサービスプロバイダはルーティングテーブルを設定します。 しかし、国境の向こう側のサイトはどのようにしてあなたの ISP へ送ることを知るのでしょうか?
割り当てられているすべてのアドレス空間の経路を維持する (分散している DNS 情報とよく似た) システムがあり、 そのインターネットバックボーンへの接続点を定義しています。 "バックボーン" とは国を越え、 世界中のインターネットのトラフィックを運ぶ主要な信用できる幹線のことです。 どのバックボーンマシンも、 あるネットワークから特定のバックボーンのマシンへ向かうトラフィックと、 そのバックボーンのマシンからあなたのネットワークに届くサービスプロバイダまでのチェーンのマスタテーブルのコピーを持っています。
あなたのサイトが接続 (プロバイダからみて内側にあることになります) したということを、 プロバイダからバックボーンサイトへ通知することはプロバイダの仕事です。 これが経路の伝搬です。
20.2.7. トラブルシューティング
経路の伝搬に問題が生じて、 いくつかのサイトが接続をおこなうことができなくなることがあります。 ルーティングがどこでおかしくなっているかを明らかにするのに最も有効なコマンドはおそらく traceroute(8) コマンドでしょう。 このコマンドは、あなたがリモートマシンに対して接続をおこなうことができない (たとえば ping(8) に失敗するような) 場合も、同じように有効です。
traceroute(8) コマンドは、 接続を試みているリモートホストを引数にして実行します。 試みている経路が経由するゲートウェイホストを表示し、 最終的には目的のホストにたどり着くか、 コネクションの欠如によって終ってしまうかのどちらかになります。
より詳しい情報は、traceroute(8) のマニュアルページをみてください。
20.2.8. マルチキャストルーティング
FreeBSD はマルチキャストアプリケーションとマルチキャストルーティングの両方にネイティブ対応しています。 マルチキャストアプリケーションを動かすのに FreeBSD で特別な設定をする必要は一切ありません。 アプリケーションは普通はそのままで動くでしょう。 マルチキャストルーティングに対応するには、 下のオプションを追加してカーネルをコンパイルする必要があります。
options MROUTING
さらに、/etc/mrouted.conf を編集してルーティングデーモン mrouted(8) を設定し、トンネルと DVMRP を設置する必要があります。 マルチキャスト設定についての詳細は mrouted(8) のマニュアルページを参照してください。
20.3. 無線ネットワーク
20.3.1. はじめに
常にネットワークケーブルをつないでいるという面倒なことをせずに、 コンピュータを使用できることは、とても有用でしょう。 FreeBSD は無線のクライアントとして、 さらに "アクセスポイント" としても使えます。
20.3.2. 無線の動作モード
802.11 無線デバイスの設定には、BSS と IBSS の二つの方法があります。
20.3.2.1. BSS モード
BSS モードは一般的に使われているモードです。 BSS モードはインフラストラクチャモードとも呼ばれています。 このモードでは、 多くの無線アクセスポイントが 1 つの有線ネットワークに接続されます。 それぞれのワイヤレスネットワークは固有の名称を持っています。 その名称はネットワークの SSID と呼ばれます。
無線クライアントはこれらの無線アクセスポイントに接続します。 IEEE 802.11 標準は無線ネットワークが接続するのに使用するプロトコルを規定しています。 SSID が設定されているときは、 無線クライアントを特定のネットワークに結びつけることができます。 SSID を明示的に指定しないことにより、 無線クライアントを任意のネットワークに接続することもできます。
20.3.2.2. IBSS モード
アドホックモードとも呼ばれる IBSS モードは、 一対一通信のために設計された通信方式です。 実際には二種類のアドホックモードがあります。 一つは IBSS モードで、アドホックモード、または IEEE アドホックモードとも呼ばれます。 このモードは IEEE 802.11 標準に規定されています。 もう一つはデモアドホックモードもしくは Lucent アドホックモード (そして時々、紛らわしいことに、アドホックモード) と呼ばれるモードです。 このモードは古く、802.11 が標準化する以前のアドホックモードで、 これは古い設備でのみ使用されるべきでしょう。 ここでは、どちらのアドホックモードについてもこれ以上言及しません。
20.3.3. インフラストラクチャーモード
20.3.3.1. アクセスポイント
アクセスポイントは一つ以上の無線クライアントが、 そのデバイスをセントラルハブとして利用できるようにする無線ネットワークデバイスです。 アクセスポイントを使用している間、 すべてのクライアントはアクセスポイントを介して通信します。 家屋や職場、または公園などの空間を無線ネットワークで完全にカバーするために、 複数のアクセスポイントがよく使われます。
アクセスポイントは一般的に複数のネットワーク接続 (無線カードと、 その他のネットワークに接続するための一つ以上の有線イーサネットアダプタ) を持っています。
アクセスポイントは、出来合いのものを購入することもできますし、 FreeBSD と対応している無線カードを組み合わせて、 自分で構築することもできます。 いくつものメーカが、 さまざまな機能をもった無線アクセスポイントおよび無線カードを製造しています。
20.3.3.2. FreeBSD のアクセスポイントの構築
要件
FreeBSD で無線アクセスポイントを設定するためには、 互換性のある無線カードが必要です。 現状では Prism チップセットのカードのみに対応しています。 また FreeBSD に対応している有線ネットワークカードも必要になるでしょう (これを見つけるのは難しくないでしょう。 FreeBSD は多くの異なるデバイスに対応しているからです) 。 この手引きでは、 無線デバイスと有線ネットワークカードに接続しているネットワーク間のトラフィックを bridge(4) したいと仮定します。
FreeBSD がアクセスポイントを実装するのに使用する hostap 機能はファームウェアの特定のバージョンで一番よく性能を発揮します。 Prism 2 カードは、 1.3.4 以降のバージョンのファームウェアで使用すべきです。 Prism 2.5 および Prism 3 カードでは、バージョン 1.4.9 のバージョンのファームウェアで使用すべきです。 それより古いバージョンのファームウェアは、 正常に動くかもしれませんし、動かないかもしれません。 現時点では、カードのファームウェアを更新する唯一の方法は、 カードの製造元から入手できる Windows® 用ファームウェアアップデートユーティリティを使うものです。
設定
はじめにシステムが無線カードを認識していることを確認してください。
# ifconfig -a
wi0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet6 fe80::202:2dff:fe2d:c938%wi0 prefixlen 64 scopeid 0x7
inet 0.0.0.0 netmask 0xff000000 broadcast 255.255.255.255
ether 00:09:2d:2d:c9:50
media: IEEE 802.11 Wireless Ethernet autoselect (DS/2Mbps)
status: no carrier
ssid ""
stationname "FreeBSD Wireless node"
channel 10 authmode OPEN powersavemode OFF powersavesleep 100
wepmode OFF weptxkey 1細かいことは気にせず、 無線カードがインストールされていることを示す何かが表示されていることを確かめてください。 PC カードを使用していて、無線インタフェースを認識できない場合、 詳しい情報を得るために pccardc(8) と pccardd(8) のマニュアルページを調べてみてください。
次に、アクセスポイント用に FreeBSD のブリッジ機能を担う部分を有効にするために、 モジュールを読み込む必要があるでしょう。 bridge(4) モジュールを読み込むには、 次のコマンドをそのまま実行します。
# kldload bridgeモジュールを読み込む時には、何もエラーはでないはずです。 もしもエラーがでたら、カーネルに bridge(4) のコードを入れてコンパイルする必要があるかもしれません。 ハンドブックのブリッジの節が、 この課題を成し遂げる手助けをになるかもしれません。
ブリッジ部分が準備できたので、 どのインタフェース間をブリッジするのかを FreeBSD カーネルに指定する必要があります。 これは、sysctl(8) を使って行います。
# sysctl net.link.ether.bridge=1
# sysctl net.link.ether.bridge_cfg="wi0,xl0"
# sysctl net.inet.ip.forwarding=1FreeBSD 5.2-RELEASE 以降では、次のように指定しなければなりません。
# sysctl net.link.ether.bridge.enable=1
# sysctl net.link.ether.bridge.config="wi0,xl0"
# sysctl net.inet.ip.forwarding=1さて、無線カードを設定するときです。 次のコマンドはカードをアクセスポイントとして設定します。
# ifconfig wi0 ssid my_net channel 11 media DS/11Mbps mediaopt hostap up stationname "FreeBSD AP"この ifconfig(8) コマンド行は wi0 インタフェースを up 状態にし、SSID を my_net に設定し、 ステーション名を FreeBSD AP に設定します。 media DS/11Mbps オプションはカードを 11Mbps モードに設定し、また mediaopt を実際に有効にするのに必要です。 mediaopt hostap オプションはインタフェースをアクセスポイントモードにします。 channel 11 オプションは使用するチャネルを 802.11b に設定します。 各規制地域 (regulatory domain) で有効なチャネル番号は wicontrol(8) マニュアルページに載っています。
さて、 これで完全に機能するアクセスポイントが立ち上がり、動作しています。 より詳しい情報については、wicontrol(8), ifconfig(8) および wi(4) のマニュアルを読むとよいでしょう。
また、下記の暗号化に関する節を読むこともおすすめします。
ステータス情報
一度アクセスポイントが設定されて稼働すると、 管理者はアクセスポイントを利用しているクライアントを見たいと思うでしょう。 いつでも管理者は以下のコマンドを実行できます。
# wicontrol -l
1 station:
00:09:b7:7b:9d:16 asid=04c0, flags=3<ASSOC,AUTH>, caps=1<ESS>, rates=f<1M,2M,5.5M,11M>, sig=38/15これは一つの局が、 表示されているパラメータで接続していることを示します。 表示された信号は、 相対的な強さを表示しているだけのものとして扱われるべきです。 dBm やその他の単位への変換結果は、 異なるファームウェアバージョン間で異なります。
20.3.3.3. クライアント
無線クライアントはアクセスポイント、 または他のクライアントに直接アクセスするシステムです。
典型的には、 無線クライアントが有しているネットワークデバイスは、 無線ネットワークカード 1 枚だけです。
無線クライアントを設定するにはいくつか方法があります。 それぞれは異なる無線モードに依存していますが、 一般的には BSS (アクセスポイントを必要とするインフラストラクチャーモード) か、 IBSS (アドホック、またはピアツーピアモード) のどちらかです。 ここでは、アクセスポイントと通信をするのに、 両者のうちで最も広まっている BSS モードを使用します。
無線 FreeBSD クライアントの設定
設定をはじめる前に、 あなたが接続しようとする無線ネットワークについていくつか知っておかなければなりません。 この例では、my_net という名前で暗号化は無効になっているネットワークに接続しようとしています。
この例では暗号化を行っていないのですが、 これは危険な状況です。次の節で、暗号化を有効にする方法と、 なぜそれが重要で、 暗号技術によっては完全にはあなたを保護することができないのはなぜか、 ということを学ぶでしょう。 |
カードが FreeBSD に認識されていることを確認してください。
# ifconfig -a
wi0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet6 fe80::202:2dff:fe2d:c938%wi0 prefixlen 64 scopeid 0x7
inet 0.0.0.0 netmask 0xff000000 broadcast 255.255.255.255
ether 00:09:2d:2d:c9:50
media: IEEE 802.11 Wireless Ethernet autoselect (DS/2Mbps)
status: no carrier
ssid ""
stationname "FreeBSD Wireless node"
channel 10 authmode OPEN powersavemode OFF powersavesleep 100
wepmode OFF weptxkey 1それでは、このカードをネットワークに合わせて設定しましょう。
# ifconfig wi0 inet 192.168.0.20 netmask 255.255.255.0 ssid my_net192.168.0.20 と 255.255.255.0 を有線ネットワークで有効な IP アドレスとネットマスクに置き換えてください。 アクセスポイントは無線ネットワークと有線ネットワークの間でデータをブリッジしているため、 ネットワーク上の他のデバイスには、このデバイスが、他と同様に、 有線ネットワーク上にあるかのように見えることに注意してください。
これを終えると、 あなたは標準的な有線接続を使用しているかのように、 有線ネットワーク上のホストに ping を送ることができるでしょう。
無線接続に関する問題がある場合は、 アクセスポイントに接続されていることを確認してください。
# ifconfig wi0いくらか情報が表示されるはずです。 その中に以下の表示があるはずです。
status: associatedもし associated と表示されなければ、 アクセスポイントの範囲外かもしれないし、 暗号化が有効になっているかもしれないし、 または設定の問題を抱えているのかもしれません。
20.3.3.4. 暗号化
無線ネットワークを暗号化することが重要なのは、 十分保護された領域にネットワークを留める能力がもはやないからです。 無線データはその周辺全体にわたって放送されるので、 それを読みたいと思う人はだれでも読むことができます。 そこで暗号化が役に立ちます。 電波に載せて送られるデータを暗号化することによって、 興味を抱いた者が空中からデータを取得することをずっと難しくします。
クライアントとアクセスポイント間のデータを暗号化するもっとも一般的な方法には、 WEP と ipsec(4) の二種類があります。
WEP
WEP は Wired Equivalency Protocol (訳注: 直訳すると、有線等価プロトコル) の略語です。WEP は無線ネットワークを有線ネットワークと同程度に安全で確実なものにしようとする試みです。 残念ながら、これはすでに破られており、 破るのはそれほど苦労しません。 これは、機密データを暗号化するという場合に、 これに頼るものではないということも意味します。
なにも無いよりはましなので、 次のコマンドを使って、あなたの新しい FreeBSD アクセスポイント上で WEP を有効にしてください。
# ifconfig wi0 inet up ssid my_net wepmode on wepkey 0x1234567890 media DS/11Mbps mediaopt hostapクライアントについては次のコマンドで WEP を有効にできます。
# ifconfig wi0 inet 192.168.0.20 netmask 255.255.255.0 ssid my_net wepmode on wepkey 0x12345678900x1234567890 をより特異なキーに変更すべきであることに注意してください。
20.3.3.5. ツール
無線ネットワークをデバッグしたり設定するのに使うツールがわずかばかりあります。 ここでその一部と、それらが何をしているか説明します。
bsd-airtools パッケージ
bsd-airtools パッケージは、 WEP キークラッキング、 アクセスポイント検知などの無線通信を監査するツールを含む完備されたツール集です。
bsd-airtools ユーティリティは net/bsd-airtools port からインストールできます。 ports のインストールに関する情報はこのハンドブックの アプリケーションのインストール - packages と ports を参照してください。
dstumbler プログラムは、 アクセスポイントの発見および S/N 比のグラフ化をできるようにするパッケージツールです。 アクセスポイントを立ち上げて動かすのに苦労しているなら、 dstumbler はうまく行く手助けになるかもしれません。
無線ネットワークの安全性をテストするのに、 "dweputils" (dwepcrack, dwepdump および dwepkeygen) を使用することで、 WEP があなたの無線安全性への要求に対する正しい解決策かどうか判断するのを助けられるかもしれません。
wicontrol, ancontrol および raycontrol ユーティリティ
これらは、無線ネットワーク上で無線カードがどのように動作するかを制御するツールです。 上記の例では、無線カードが wi0 インタフェースであるので、wicontrol(8) を使用することに決めました。 もし Cisco の無線デバイスを持っている場合は、それは an0 として動作するでしょうから、 ancontrol(8) を使うことになるでしょう。
ifconfig コマンド
ifconfig(8) は wicontrol(8) と同じオプションの多くを処理できますが、 いくつかのオプションを欠いています。 コマンドライン引数とオプションについて ifconfig(8) を参照してください。
20.3.3.6. 対応しているカード
アクセスポイント
現在のところ (アクセスポイントとして) BSS モードに対応した唯一のカードは Prism 2, 2.5 または 3 チップセットを利用したデバイスです。 wi(4) に完全な一覧があります。
20.4. Bluetooth
20.4.1. はじめに
Bluetooth は免許のいらない 2.4 GHz の帯域を利用して、 10 m 程度のパーソナルネットワークを作る無線技術です。 ネットワークはたいていの場合、その場その場で、携帯電話や PDA やノートパソコンなどの携帯デバイスから形成されます。 Wi-Fi などの他の有名な無線技術とは違い、 Bluetooth はより高いレベルのサービスを提供します。 たとえば、FTP のようなファイルサーバ、ファイルのプッシュ、 音声伝送、シリアル線のエミュレーションなどのサービスです。
FreeBSD 内での Bluetooth スタックは Netgraph フレームワーク (netgraph(4) 参照) を使って実現されています。 ng_ubt(4) ドライバは、 多種多様な Bluetooth USB ドングルに対応しています。 Broadcom BCM2033 チップを搭載した Bluetooth デバイスは ubtbcmfw(4) および ng_ubt(4) ドライバによって対応されています。 3Com Bluetooth PC カード 3CRWB60-A は ng_bt3c(4) ドライバによって対応されています。 シリアルおよび UART を搭載した Bluetooth デバイスは sio(4), ng_h4(4) および hcseriald(8) ドライバによって対応されています。 この節では USB Bluetooth ドングルの使用法について説明します。 Bluetooth に対応しているのは FreeBSD 5.0 以降のシステムです。
5.0, 5.1 Release ではカーネルモジュールは利用可能ですが、 種々のユーティリティとマニュアルは標準でコンパイルされていません。 |
20.4.2. デバイスの挿入
デフォルトでは Bluetooth デバイスドライバはカーネルモジュールとして利用できます。 デバイスを接続する前に、 カーネルにドライバを読み込む必要があります。
# kldload ng_ubtBluetooth デバイスがシステム起動時に存在している場合、 /boot/loader.conf からモジュールを読み込んでください。
ng_ubt_load="YES"
USB ドングルを挿してください。コンソールに (または syslog に) 下記のような表示が現れるでしょう。
ubt0: vendor 0x0a12 product 0x0001, rev 1.10/5.25, addr 2
ubt0: Interface 0 endpoints: interrupt=0x81, bulk-in=0x82, bulk-out=0x2
ubt0: Interface 1 (alt.config 5) endpoints: isoc-in=0x83, isoc-out=0x3,
wMaxPacketSize=49, nframes=6, buffer size=294/usr/shared/examples/netgraph/bluetooth/rc.bluetooth を /etc/rc.bluetooth のようなどこか便利な場所にコピーしてください。 このスクリプトは Bluetooth スタックを開始および終了させるのに使われます。 デバイスを抜く前にスタックを終了するのはよい考えですが、 (たいていの場合) しなくても致命的ではありません。 スタックを開始するときに、下記のような出力がされます。
# /etc/rc.bluetooth start ubt0
BD_ADDR: 00:02:72:00:d4:1a
Features: 0xff 0xff 0xf 00 00 00 00 00
<3-Slot> <5-Slot> <Encryption> <Slot offset>
<Timing accuracy> <Switch> <Hold mode> <Sniff mode>
<Park mode> <RSSI> <Channel quality> <SCO link>
<HV2 packets> <HV3 packets> <u-law log> <A-law log> <CVSD>
<Paging scheme> <Power control> <Transparent SCO data>
Max. ACL packet size: 192 bytes
Number of ACL packets: 8
Max. SCO packet size: 64 bytes
Number of SCO packets: 820.4.3. ホストコントローラインタフェース (HCI)
ホストコントローラインタフェース (HCI) は、 ベースバンドコントローラおよびリンクマネージャへのコマンドインタフェースを提供し、 ハードウェアステータスおよびコントロールレジスタへアクセスします。 このインタフェースは Bluetooth ベースバンド機能へアクセスする画一的な方法を提供します。 ホストの HCI 層は Bluetooth ハードウェア上の HCI ファームウェアと、 データとコマンドをやり取りします。 ホストコントローラトランスポート層 (つまり物理的なバス) のドライバは、 両方の HCI 層に相互に情報を交換する能力を与えます。
一つの Bluetooth デバイスにつき、hci タイプの Netgraph ノードが一つ作成されます。 HCI ノードは通常 Bluetooth デバイスドライバノード (下流) と L2CAP ノード (上流) に接続されます。 すべての HCI 動作はデバイスドライバノード上ではなく、 HCI ノード上で行われなくてはいけません。 HCI ノードのデフォルト名は "devicehci" です。 詳細については ng_hci(4) マニュアルを参照してください。
最も一般的なタスクの一つに、無線通信的に近傍にある Bluetooth デバイスの発見があります。 この動作は inquiry (問い合わせ) と呼ばれています。 Inquiry や他の HCI に関連した動作は hccontrol(8) ユーティリティによってなされます。 下記の例は、どの Bluetooth デバイスが通信圏内にあるかを知る方法を示しています。 デバイスのリストが表示されるには数秒かかります。 リモートデバイスは discoverable (発見可能な) モードにある場合にのみ inquiry に返答するということに注意してください。
% hccontrol -n ubt0hci inquiry
Inquiry result, num_responses=1
Inquiry result #0
BD_ADDR: 00:80:37:29:19:a4
Page Scan Rep. Mode: 0x1
Page Scan Period Mode: 00
Page Scan Mode: 00
Class: 52:02:04
Clock offset: 0x78ef
Inquiry complete. Status: No error [00]BD_ADDR は Bluetooth デバイスに固有のアドレスです。 これはネットワークカードの MAC アドレスに似ています。 このアドレスはデバイスとの通信を続けるのに必要となります。 BD_ADDR に人間が判読しやすい名前を割り当てることもできます。 /etc/bluetooth/hosts ファイルには、 既知の Bluetooth ホストに関する情報が含まれています。 次の例はリモートデバイスに割り当てられている、 人間が判読しやすい名前を得る方法を示しています。
% hccontrol -n ubt0hci remote_name_request 00:80:37:29:19:a4
BD_ADDR: 00:80:37:29:19:a4
Name: Pav's T39リモートの Bluetooth デバイス上で inquiry を実行すると、 あなたのコンピュータは "your.host.name (ubt0)" と認識されます。 ローカルデバイスに割り当てられた名前はいつでも変更できます。
Bluetooth システムは一対一接続 (二つの Bluetooth ユニットだけが関係します) または一対多接続を提供します。 一対多接続では、接続はいくつかの Bluetooth デバイス間で共有されます。 次の例は、ローカルデバイスに対するアクティブなベースバンド接続のリストを得る方法を示しています。
% hccontrol -n ubt0hci read_connection_list
Remote BD_ADDR Handle Type Mode Role Encrypt Pending Queue State
00:80:37:29:19:a4 41 ACL 0 MAST NONE 0 0 OPENconnection handle はベースバンド接続の終了が必要とされるときに便利です。 もっとも、通常はこれを手動で行う必要はありません。 Bluetooth スタックはアクティブでないベースバンド接続を自動的に終了します。
# hccontrol -n ubt0hci disconnect 41
Connection handle: 41
Reason: Connection terminated by local host [0x16]利用可能な HCI コマンドの完全な一覧を得るには、 hccontrol help を参照してください。 HCI コマンドのほとんどはスーパユーザ権限を必要としません。
20.4.4. ロジカルリンクコントロールおよびアダプテーションプロトコル (L2CAP)
ロジカルリンクコントロールおよびアダプテーションプロトコル (L2CAP) は、プロトコル多重化ケーパビリティおよび分割・再編成動作を備えた、 上位層プロトコルへのコネクション指向およびコネクションレスデータサービスを提供します。 L2CAP は上位層プロトコルおよびアプリケーションが 64 KB までの長さの L2CAP データパケットを送受信することを可能にします。
L2CAP は チャネル の概念に基づいています。 チャネルはベースバンド接続の上位に位置する論理的な接続です。 それぞれのチャネルは多対一の方法で一つのプロトコルに結びつけられます。 複数のチャネルを同じプロトコルに結びつけることは可能ですが、 一つのチャネルを複数のプロトコルに結びつけることはできません。 チャネル上で受け取られたそれぞれの L2CAP パケットは、 適切なより上位のプロトコルに渡されます。 複数のチャネルは同じベースバンド接続を共有できます。
一つの Bluetooth デバイスに対して、l2cap タイプの Netgraph ノードが一つ作成されます。 L2CAP ノードは通常 Bluetooth HCI ノード (下流) と Bluetooth ソケットノード (上流) に接続されます。 L2CAP ノードのデフォルト名は "devicel2cap" です。 詳細については ng_l2cap(4) マニュアルを参照してください。
便利なコマンドに、他のデバイスに ping を送ることができる l2ping(8) があります。Bluetooth 実装によっては、 送られたデータすべては返さないことがあります。 したがって次の例で 0 バイト は正常です。
# l2ping -a 00:80:37:29:19:a4
0 bytes from 0:80:37:29:19:a4 seq_no=0 time=48.633 ms result=0
0 bytes from 0:80:37:29:19:a4 seq_no=1 time=37.551 ms result=0
0 bytes from 0:80:37:29:19:a4 seq_no=2 time=28.324 ms result=0
0 bytes from 0:80:37:29:19:a4 seq_no=3 time=46.150 ms result=0l2control(8) ユーティリティは L2CAP ノード上でさまざまな操作を行うのに使われます。 この例は、ローカルデバイスに対する論理的な接続 (チャネル) およびベースバンド接続の一覧を得る方法を示しています。
% l2control -a 00:02:72:00:d4:1a read_channel_list
L2CAP channels:
Remote BD_ADDR SCID/ DCID PSM IMTU/ OMTU State
00:07:e0:00:0b:ca 66/ 64 3 132/ 672 OPEN
% l2control -a 00:02:72:00:d4:1a read_connection_list
L2CAP connections:
Remote BD_ADDR Handle Flags Pending State
00:07:e0:00:0b:ca 41 O 0 OPEN別の診断ツールが btsockstat(1) です。 これは netstat(1) と同様の作業を、Bluetooth ネットワークに関するデータ構造についての行います。 下記の例は上の l2control(8) と同じ論理的な接続を示します。
% btsockstat
Active L2CAP sockets
PCB Recv-Q Send-Q Local address/PSM Foreign address CID State
c2afe900 0 0 00:02:72:00:d4:1a/3 00:07:e0:00:0b:ca 66 OPEN
Active RFCOMM sessions
L2PCB PCB Flag MTU Out-Q DLCs State
c2afe900 c2b53380 1 127 0 Yes OPEN
Active RFCOMM sockets
PCB Recv-Q Send-Q Local address Foreign address Chan DLCI State
c2e8bc80 0 250 00:02:72:00:d4:1a 00:07:e0:00:0b:ca 3 6 OPEN20.4.5. RFCOMM プロトコル
RFCOMM プロトコルは L2CAP プロトコルを介してシリアルポートのエミュレーションを提供します。 このプロトコルは ETSI (訳注: 欧州電気通信標準化機構) 標準 TS 07.10 に基づいています。 RFCOMM プロトコルは、単純な伝送プロトコルに RS-232 (EIATIA-232-E) シリアルポートの 9 本の結線をエミュレートする項目を加えたものです。 RFCOMM プロトコルは、二つの Bluetooth デバイス間で、最大 60 までの同時接続 (RFCOMM チャネル) に対応しています。
RFCOMM の目的から、完全な通信経路は、異なるデバイス上 (通信の端点) で動作している二つのアプリケーションと、 その間の通信セグメントを含んでいます。RFCOMM は、それが動いているデバイスのシリアルポートを利用するアプリケーションをカバーするためのものです。 通信セグメントはあるデバイスから他のデバイスへの Bluetooth リンクです (直接接続)。
RFCOMM は直接接続している場合のデバイス間の接続、 またはネットワークの場合のデバイスとモデムの間の接続にだけ関係があります。 RFCOMM は、一方が Bluetooth 無線技術で通信し、 もう一方で有線インタフェースを提供するモジュールのような、 他の構成にも対応できます。
FreeBSD では RFCOMM プロトコルは Bluetooth ソケット層に実装されています。
20.4.6. デバイスのペアリング
デフォルトでは Bluetooth 通信は認証されておらず、 すべてのデバイスが他のすべてのデバイスと通信できます。 Bluetooth デバイス (たとえば携帯電話) は特定のサービス (たとえばダイアルアップサービス) を提供するために、 認証を要求することも選択できます。 Bluetooth 認証は通常 PIN コード で行われます。 PIN コードは最長 16 文字のアスキー文字列です。 ユーザは両デバイスで同じ PIN コードを入力することを要求されます。 一度 PIN コードを入力すると、 両デバイスは リンクキー を作成します。 その後、リンクキーはそのデバイス自身または、 不揮発性記憶デバイス内に格納できます。 次の機会には、両デバイスは前に作成されたリンクキーを使用するでしょう。 このような手続きをペアリング (pairing) と呼びます。いずれかのデバイス上でリンクキーが失われたときには、 ペアリングをやり直さなければならないことに注意してください。
hcsecd(8) デーモンが Bluetooth 認証要求のすべてを扱う責任を負っています。 デフォルトの設定ファイルは /etc/bluetooth/hcsecd.conf です。 PIN コードが "1234" に設定された携帯電話に関する例は以下の通りです。
device {
bdaddr 00:80:37:29:19:a4;
name "Pav's T39";
key nokey;
pin "1234";
}PIN コードには (長さを除いて) 制限はありません。 いくつかのデバイス (たとえば Bluetooth ヘッドフォン) には固定的な PIN コードが組み込まれているかもしれません。 -d オプションは hcsecd(8) デーモンがフォアグラウンドで動作するように強制するため、 何が起きているのか確認しやすくなります。 リモートデバイスがペアリングを受け取るように設定して、 リモートデバイスへの Bluetooth 接続を開始してください。 リモートデバイスはペアリングが受け入れらた、と応答して PIN コードを要求するでしょう。 hcsecd.conf 内にあるのと同じ PIN コードを入力してください。 これであなたの PC とリモートデバイスがペアとなりました。 また、リモートデバイスからペアリングを開始することもできます。 以下は hcsecd の出力例です。
hcsecd[16484]: Got Link_Key_Request event from 'ubt0hci', remote bdaddr 0:80:37:29:19:a4 hcsecd[16484]: Found matching entry, remote bdaddr 0:80:37:29:19:a4, name 'Pav's T39', link key doesn't exist hcsecd[16484]: Sending Link_Key_Negative_Reply to 'ubt0hci' for remote bdaddr 0:80:37:29:19:a4 hcsecd[16484]: Got PIN_Code_Request event from 'ubt0hci', remote bdaddr 0:80:37:29:19:a4 hcsecd[16484]: Found matching entry, remote bdaddr 0:80:37:29:19:a4, name 'Pav's T39', PIN code exists hcsecd[16484]: Sending PIN_Code_Reply to 'ubt0hci' for remote bdaddr 0:80:37:29:19:a4
20.4.7. サービスディスカバリプロトコル (SDP)
サービスディスカバリプロトコル (SDP) は、 クライアントアプリケーションが、 サーバアプリケーションが提供するサービスの存在とその属性を発見する手段を提供します。 サービスの属性には提示されているサービスのタイプまたはクラス、 および、サービスを利用するのに必要な仕組みまたはプロトコルの情報が含まれます。
SDP には SDP サーバと SDP クライアント間の通信が含まれます。 SDP サーバは、サーバに関連づけられたサービスの特性について記述しているサービスレコードの一覧を維持しています。 各サービスレコードにはそれぞれ 1 つのサービスの情報が書かれています。 クライアントは SDP リクエストを出すことによって、 SDP サーバが維持しているサービスレコードから情報を検索できます。 クライアントまたはクライアントに関連づけられたアプリケーションがサービスを利用することにしたら、 サービスを利用するためには、 サービスプロバイダへの接続を別途開かなければなりません。 SDP はサービスとそれらの属性を発見するための仕組みを提供しますが、 そのサービスを利用するための仕組みは提供しません。
通常 SDP クライアントは希望するサービスの特性に基づいてサービスを検索します。 しかしながら、サービスに関する事前の情報なしに、 どのタイプのサービスが SDP サーバのサービスレコードに記述されているか知ることが望ましいことがあります。 この、提供されている任意のサービスを閲覧する手順を、 ブラウジング (browsing) と呼びます。
現在のところ Bluetooth SDP サーバおよびクライアントは、 ここ からダウンロードできる第三者パッケージ sdp-1.5 で実装されています。 sdptool はコマンドラインの SDP クライアントです。 次の例は SDP ブラウズの問い合わせ方法を示しています。
# sdptool browse 00:80:37:29:19:a4
Browsing 00:80:37:29:19:A4 ...
Service Name: Dial-up Networking
Protocol Descriptor List:
"L2CAP" (0x0100)
"RFCOMM" (0x0003)
Channel: 1
Service Name: Fax
Protocol Descriptor List:
"L2CAP" (0x0100)
"RFCOMM" (0x0003)
Channel: 2
Service Name: Voice gateway
Service Class ID List:
"Headset Audio Gateway" (0x1112)
"Generic Audio" (0x1203)
Protocol Descriptor List:
"L2CAP" (0x0100)
"RFCOMM" (0x0003)
Channel: 3等々。 それぞれのサービスは属性の一覧 (たとえば RFCOMM チャネル) を持っていることに注意してください。サービスによっては、 属性のリストの一部についてメモをとっておく必要があるかもしれません。 Bluetooth 実装のいくつかは、サービスブラウジングに対応しておらず、 空の一覧を返してくるかもしれません。この場合、 特定のサービスを検索をすることは可能です。下記の例は OBEX オブジェクトプッシュ (OPUSH) サービスを検索する方法です。
# sdptool search --bdaddr 00:07:e0:00:0b:ca OPUSHFreeBSD 上における Bluetooth クライアントへのサービス提供は sdpd サーバが行います。
# sdpdsdptool は、ローカル SDP サーバにサービスを登録するのにも用いられます。 下記の例は PPP (LAN) サービスを備えたネットワークアクセスを登録する方法を示しています。 一部のサービスでは属性 (たとえば RFCOMM チャネル) を要求することに注意してください。
# sdptool add --channel=7 LANローカル SDP サーバに登録されたサービスの一覧は SDP ブラウザの問い合わせを "特別な" BD_ADDR に送ることで得られます。
# sdptool browse ff:ff:ff:00:00:0020.4.8. ダイアルアップネットワーク (DUN) および PPP (LAN) を用いたネットワークアクセスプロファイル
ダイアルアップネットワーク (DUN) プロファイルはほとんどの場合、 モデムや携帯電話とともに使用されます。 このプロファイルが対象とする場面は以下のものです。
コンピュータから携帯電話またはモデムを、 ダイアルアップインターネットアクセスサーバへの接続、 または他のダイアルアップサービスを利用するための無線モデムとして使うこと
データ呼び出しを受けるための、 コンピュータによる携帯電話またはモデムの使用
PPP (LAN) によるネットワークアクセスプロファイルは、 次の状況で利用できます。
単一の Bluetooth デバイスへの LAN アクセス
マルチ Bluetooth デバイスへの LAN アクセス
(シリアルケーブルエミュレーション上の PPP ネットワーク接続を使用した) PC から PC への接続
FreeBSD ではどちらのプロファイルも ppp(8) と rfcomm_pppd(8) (RFCOMM Bluetooth 接続を PPP が制御可能なように変換するラッパ) で実装されています。 いずれかのプロファイルが使用可能となる前に、 /etc/ppp/ppp.conf 内に新しい PPP ラベルが作成されていなければなりません。 例については、 rfcomm_pppd(8) のマニュアルページを参照してください。
次の例では、DUN RFCOMM チャネル上で BD_ADDR が 00:80:37:29:19:a4 のリモートデバイスへの RFCOMM 接続を開くのに rfcomm_pppd(8) が使われます。実際の RFCOMM チャネル番号は SDP を介してリモートデバイスから得ます。 手動で RFCOMM チャネルを指定することもでき、その場合 rfcomm_pppd(8) は SDP 問い合わせを実行しません。 リモートデバイス上の RFCOMM チャネルを見つけるには、 sdptool を使ってください。
# rfcomm_pppd -a 00:80:37:29:19:a4 -c -C dun -l rfcomm-dialupPPP (LAN) サービスでネットワークアクセスを提供するためには、 sdpd サーバが動いていなければなりません。 これはローカル SDP サーバに LAN サービスを登録するのにも必要です。 LAN サービスは RFCOMM チャネル属性を必要とすることに注意してください。 /etc/ppp/ppp.conf ファイル内に LAN クライアントの新しいエントリを作成しなければなりません。 例については rfcomm_pppd(8) のマニュアルページを参照してください。 最後に、RFCOMM PPP サーバが実行され、 ローカル SDP サーバに登録されているのと同じ RFCOMM チャネルで待ち受けていなければなりません。 次の例は RFCOMM PPP サーバを起動する方法を示しています。
# rfcomm_pppd -s -C 7 -l rfcomm-server20.4.9. OBEX プッシュ (OPUSH) プロファイル
OBEX はモバイルデバイス間で広く使われている単純なファイル転送プロトコルです。 これは主に赤外線通信で利用されており、ノートパソコンや PDA 間の汎用的なファイル転送、および PIM アプリケーションを搭載した携帯電話その他のデバイス間で名刺やカレンダーエントリを転送するのに用いられます。
OBEX サーバおよびクライアントは、 ここ からダウンロードできる obexapp-1.0 という第三者のパッケージとして実装されています。 このパッケージは openobex ライブラリ (上記の obexapp に含まれます) および devel/glib12 port を必要とします。 なお、obexapp はルート権限を必要としません。
OBEX クライアントは OBEX サーバとの間でオブジェクトを渡したり (プッシュ) および受け取ったり (プル) するのに使用されます。 オブジェクトは、たとえば名刺や予定などになります。 OBEX クライアントは RFCOMM チャネル番号を SDP によってリモートデバイスから得ることができます。 これは RFCOMM チャネル番号の代わりにサービス名を指定することによって行うことができます。 対応しているサービス名は IrMC, FTRN および OPUSH です。 RFCOMM チャネルを番号で指定することもできます。 下記は、デバイス情報オブジェクトを携帯電話から受け取り、 新しいオブジェクト (名刺) が携帯電話に渡される場合の OBEX セッションの例です。
% obexapp -a 00:80:37:29:19:a4 -C IrMC
obex> get
get: remote file> telecom/devinfo.txt
get: local file> devinfo-t39.txt
Success, response: OK, Success (0x20)
obex> put
put: local file> new.vcf
put: remote file> new.vcf
Success, response: OK, Success (0x20)
obex> di
Success, response: OK, Success (0x20)OBEX プッシュサービスを提供するためには、 sdpd サーバが実行されていなければなりません。 また OPUSH サービスをローカル SDP サーバに登録することも必要です。 なお、OPUSH サービスには RFCOMM チャネル属性が必要です。 渡されるオブジェクトをすべて格納するルートフォルダを作成しなければいけません。 ルートフォルダのデフォルトパスは /var/spool/obex です。 最後に OBEX サーバが実行され、 ローカル SDP サーバに登録されているのと同じ RFCOMM チャネルで待ち受けていなければなりません。 下記の例は OBEX サーバの起動方法を示します。
# obexapp -s -C 1020.4.10. シリアルポート (SP) プロファイル
シリアルポート (SP) プロファイルは Bluetooth デバイスが RS232 (または同様の) シリアルケーブルエミュレーションを行えるようにします。 このプロファイルが対象とする場面は、 レガシーアプリケーションが、仮想シリアルポート抽象を介して Bluetooth をケーブルの代替品として使うところです。
rfcomm_sppd(1) ユーティリティはシリアルポートプロファイルを実装します。 Pseudo tty が仮想シリアルポート抽象概念として用いられます。 下記の例はリモートデバイスのシリアルポートサービスへ接続する方法を示します。 なお、RFCOMM チャネルを指定する必要はありません。- rfcomm_sppd(1) は SDP を介してリモートデバイスからその情報を得ることができます。 これを上書きしたい場合にはコマンドラインで RFCOMM チャネルを指定してください。
# rfcomm_sppd -a 00:07:E0:00:0B:CA -t /dev/ttyp6
rfcomm_sppd[94692]: Starting on /dev/ttyp6...接続された pseudo tty はシリアルポートとして利用することができます。
# cu -l ttyp620.4.11. トラブルシューティング
20.4.11.1. リモートデバイスが接続できません
古い Bluetooth デバイスのなかにはロールスイッチング (role switching) に対応していないものがあります。 デフォルトでは FreeBSD が新しい接続を受け付けるときに、 ロールスイッチを実行してマスタになろうとします。 これに対応していないデバイスは接続できないでしょう。 なお、ロールスイッチングは新しい接続が確立されるときに実行されるので、 ロールスイッチングに対応しているかどうかリモートデバイスに問い合わせることはできません。 ローカル側でロールスイッチングを無効にする HCI オプションがあります。
# hccontrol -n ubt0hci write_node_role_switch 020.4.11.2. 何かがうまくいっていないみたいです。 何が実際に起こっているか確認できますか?
できます。 ここ からダウンロードできる第三者パッケージ hcidump-1.5 を使ってください。 hcidump ユーティリティは tcpdump(1) と似ています。 これはターミナル上の Bluetooth パケットの内容の表示および Bluetooth パケットをファイルにダンプするのに使えます。
20.5. ブリッジ
20.5.1. はじめに
IP サブネットを作成して、 それらのセグメントをルータを使って接続することなしに、 (Ethernet セグメントのような) 一つの物理ネットワークを二つのネットワークセグメントに分割することはとても有効な場合があります。 この方法で二つのネットワークを繋ぐデバイスは "ブリッジ" と呼ばれます。 二つのネットワークインタフェースカードを持つ FreeBSD システムは、ブリッジとして動作することができます。
ブリッジは、各ネットワークインタフェイスに繋がるデバイスの MAC 層のアドレス (Ethernet アドレス) を記憶することにより動作します。 ブリッジはトラフィックの送信元と受信先が異なったネットワーク上にある場合にのみトラフィックを転送します。
多くの点で、ブリッジはポート数の少ない Ethernet スイッチのようなものといえます。
20.5.2. ブリッジがふさわしい状況
今日ブリッジが活躍する場面は大きく分けて二つあります。
20.5.2.1. トラフィックの激しいセグメント
ひとつは、 物理ネットワークセグメントがトラフィック過剰になっているが、 なんらかの理由によりネットワークをサブネットに分け、 ルータで接続することができない場合です。
編集部門と製作部門がおなじサブネットに同居している新聞社を例に考えてみましょう。 編集部門のユーザはファイルサーバとして全員サーバ A を利用し、 製作部門のユーザはサーバ B を利用します。 すべてのユーザを接続するのには Ethernet が使われており、 高負荷となったネットワークは遅くなってしまいます。
もし編集部門のユーザを一つのネットワークセグメントに分離することができ、 製作部門のユーザも同様にできるのなら、 二つのネットワークセグメントをブリッジで繋ぐことができます。 ブリッジの "反対" 側へ向かうネットワークトラフィックだけが転送され、 各ネットワークセグメントの混雑は緩和されます。
20.5.2.2. パケットフィルタ/帯域制御用ファイアウォール
もうひとつはネットワークアドレス変換 (NAT) を使わずにファイアウォール機能を利用したい場合です。
ここでは DSL もしくは ISDN で ISP に接続している小さな会社を例にとってみましょう。 この会社は ISP からグローバル IP アドレスを 13 個割り当てられており、ネットワーク上には 10 台の PC が存在します。 このような状況では、サブネット化にまつわる問題から、 ルータを用いたファイアウォールを利用することは困難です。
ブリッジを用いたファイアウォールなら、 IP アドレスの問題を気にすること無く、 DSL/ISDN ルータの下流側に置くように設定できます。
20.5.3. ブリッジを設定する
20.5.3.1. ネットワークインタフェースカードの選択
ブリッジを利用するには少なくとも 2 枚のネットワークカードが必要です。 残念なことに FreeBSD 4.0 ではすべてのネットワークインタフェースカードがブリッジ機能に対応しているわけではありません。 カードに対応しているかどうかについては bridge(4) を参照してください。
以下に進む前に、 二枚のネットワークカードをインストールしてテストしてください。
20.5.3.2. カーネルコンフィグレーションの変更
カーネルでブリッジ機能を有効にするには
options BRIDGE
という行をカーネルコンフィグレーションファイルに追加して カーネルを再構築してください。
20.5.3.3. ファイアウォール対応
ファイアウォールとしてブリッジを利用しようとしている場合には IPFIREWALL オプションも指定する必要があります。 ブリッジをファイアウォールとして設定する際の一般的な情報に関しては、 ファイアウォールの章 を参照してください。
IP 以外のパケット (ARP など) がブリッジを通過するようにするためには、 ファイアウォール用オプションを設定しなければなりません。 このオプションは IPFIREWALL_DEFAULT_TO_ACCEPT です。この変更により、 デフォルトではファイアウォールがすべてのパケットを受け入れるようになることに注意してください。 この設定を行う前に、 この変更が自分のルールセットにどのような影響をおよぼすかを把握しておかなければなりません。
20.5.3.4. 帯域制御機能
ブリッジで帯域制御機能を利用したい場合、 カーネルコンフィグレーションで DUMMYNET オプションを加える必要があります。 詳しい情報に関しては dummynet(4) を参照してください。
20.5.4. ブリッジを有効にする
ブリッジを有効にするには、 /etc/sysctl.conf に以下の行を加えてください。
net.link.ether.bridge=1
指定したインタフェースでブリッジを可能にするには以下を加えてください。
net.link.ether.bridge_cfg=if1,if2
(if1 および if2 は二つのネットワークインタフェースの名前に置き換えてください)。 ブリッジを経由したパケットを ipfw(8) でフィルタしたい場合には、 以下の行も付け加える必要があります
net.link.ether.bridge_ipfw=1
FreeBSD 5.2-RELEASE 以降では、かわりに以下の行を使用してください。
net.link.ether.bridge.enable=1 net.link.ether.bridge.config=if1,if2 net.link.ether.bridge.ipfw=1
20.6. NFS
FreeBSD がサポートしている多くのファイルシステムの中には、 NFS とも呼ばれているネットワークファイルシステムがあります。 NFS はあるマシンから他のマシンへと、 ネットワークを通じてディレクトリとファイルを共有することを可能にします。 NFS を使うことで、 ユーザやプログラムはリモートシステムのファイルを、 それがローカルファイルであるかのようにアクセスすることができます。
NFS が提供可能な最も特筆すべき利点いくつかは以下のものです。
一般的に使われるデータを単一のマシンに納めることができ、 ユーザはネットワークを通じてデータにアクセスできるため、 ローカルワークステーションが使用するディスク容量が減ります。
ネットワーク上のすべてのマシンに、 ユーザが別々にホームディレクトリを持つ必要がありません。 NFS サーバ上にホームディレクトリが設定されれば、 ネットワークのどこからでもアクセス可能です。
フロッピーディスクや CDROM ドライブ、 ZIP ドライブなどのストレージデバイスを、 ネットワーク上の他のマシンで利用することができます。 ネットワーク全体のリムーバブルドライブの数を減らせるかもしれません。
20.6.1. NFS はどのように動作するのか
NFS は最低二つの主要な部分、 サーバと一つ以上のクライアントからなります。 クライアントはサーバマシン上に格納されたデータにリモートからアクセスします。 これが適切に機能するには、 いくつかのプロセスが設定されて実行されていなければなりません。
FreeBSD 5.X では |
サーバは以下のデーモンを動作させなければなりません。
| デーモン | 説明 |
|---|---|
nfsd | NFS クライアントからのリクエストを処理する NFS デーモン |
mountd | nfsd(8) から渡されたリクエストを実際に実行する NFS マウントデーモン |
portmap | NFS サーバの利用しているポートを NFS クライアントから取得できるようにするためのポートマッパデーモン |
クライアント側では nfsiod というデーモンも実行できます。 nfsiod デーモンは NFS サーバからのリクエストを処理します。 これは任意であり、性能を改善しますが、 通常の正しい動作には必要としません。詳細については nfsiod(8) マニュアルページを参照してください。
20.6.2. NFS の設定
NFS の設定は比較的素直な工程です。 動かさなければならないプロセスは /etc/rc.conf ファイルを少し変更すれば起動時に実行させられます。
NFS サーバでは /etc/rc.conf ファイルの中で、 以下のオプションが設定されていることを確かめてください。
portmap_enable="YES" nfs_server_enable="YES" mountd_flags="-r"
mountd は NFS サーバが有効になっていれば、 自動的に実行されます。
クライアント側では /etc/rc.conf 内に以下の設定があることを確認してください。
nfs_client_enable="YES"
/etc/exports ファイルは NFS サーバがどのファイルシステムをエクスポート (ときどき "共有" と呼ばれます) するのかを指定します。 /etc/exports ファイル中の各行は、 エクスポートするファイルシステム、 およびそのファイルシステムにアクセスできるマシンを指定します。 ファイルシステムにアクセスできるマシンとともに、 アクセスオプションも指定できます。 このファイルで指定できるオプションはたくさんありますが、 ここではほんの少しだけ言及します。exports(5) マニュアルページを読めば、 他のオプションは簡単にみつけられるでしょう。
いくつか /etc/exports の設定例を示します。
以下の例はファイルシステムのエクスポートの考え方を示しますが、 あなたの環境とネットワーク設定に応じて設定は少し変わるでしょう。 たとえば次の行は /cdrom ディレクトリを、サーバと同じドメイン名か (そのため、いずれもドメイン名がありません)、 /etc/hosts に記述されている三つの例となるマシンに対してエクスポートします。 -ro フラグは共有されるファイルシステムを読み込み専用にします。 このフラグにより、 リモートシステムは共有されたファイルシステムに対して何の変更も行えなくなります。
/cdrom -ro host1 host2 host3
以下の設定は IP アドレスで指定した 3 つのホストに対して /home をエクスポートします。 この設定はプライベートネットワークで DNS が設定されていない場合に便利でしょう。 内部のホスト名に対して /etc/hosts を設定するという手段もあります。 詳細については hosts(5) を参照してください。 -alldirs フラグはサブディレクトリがマウントポイントとなることを認めます。 言い替えると、これはサブディレクトリをマウントしませんが、 クライアントが要求するか、 または必要とするディレクトリだけをマウントできるようにします。
/home -alldirs 10.0.0.2 10.0.0.3 10.0.0.4
以下の設定は、サーバとは異なるドメイン名の 2 台のクライアントがアクセスできるように /a をエクスポートします。 -maproot=root フラグは、リモートシステムの root ユーザが、 エクスポートされたファイルシステムに root として書き込むことを許可します。 -maproot=root フラグが無ければ、 リモートマシンの root 権限を持っていても、 共有されたファイルシステム上のファイルを変更することはできないでしょう。
/a -maproot=root host.example.com box.example.org
クライアントがエクスポートされたファイルシステムにアクセスするためには、 そうする権限が与えられていなければなりません。 /etc/exports ファイルに クライアントが含まれているかどうか確認してください。
/etc/exports ファイルでは、 それぞれの行が一つのファイルシステムを一つのホストにエクスポートすることを表します。 リモートホストはファイルシステム毎に一度だけ指定することができ、 それに加えて一つのデフォルトエントリを置けます。たとえば /usr が単一のファイルシステムであると仮定します。 次の /etc/exports は無効です。
/usr/src client /usr/ports client
単一のファイルシステムである /usr は、2 行に渡って、同じホスト client へエクスポートされています。 この場合、正しい書式は次のとおりです。
/usr/src /usr/ports client
あるホストにエクスポートされるある 1 つのファイルシステムのプロパティは、 1 行ですべて指定しなければなりません。 クライアントの指定のない行は、単一のホストとして扱われます。 これはファイルシステムをエクスポートできる方法を制限しますが、 多くの場合これは問題になりません。
下記は、 /usr および /exports がローカルファイルシステムである場合の、 有効なエクスポートリストの例です。
# Export src and ports to client01 and client02, but only # client01 has root privileges on it /usr/src /usr/ports -maproot=root client01 /usr/src /usr/ports client02 # The client machines have root and can mount anywhere # on /exports. Anyone in the world can mount /exports/obj read-only /exports -alldirs -maproot=root client01 client02 /exports/obj -ro
変更が有効となるように、 /etc/exports が変更されたら mountd を再起動しなければなりません。 これは mountd プロセスに HUP シグナルを送ることで実行できます。
# kill -HUP `cat /var/run/mountd.pid`他には、再起動すれば、FreeBSD はすべてを適切に設定します。 しかしながら、再起動は必須ではありません。 root 権限で以下のコマンドを実行すれば、すべてが起動するでしょう。
NFS サーバでは
# portmap
# nfsd -u -t -n 4
# mountd -rNFS クライアントでは
# nfsiod -n 4これでリモートのファイルシステムを実際にマウントする準備がすべてできました。 この例では、サーバの名前は server で、 クライアントの名前は client とします。 リモートファイルシステムを一時的にマウントするだけ、 もしくは設定をテストするだけなら、クライアント上で root 権限で以下のコマンドを実行するだけです。
# mount server:/home /mntこれで、サーバの /home ディレクトリが、クライアントの /mnt にマウントされます。もしすべてが正しく設定されていれば、 クライアントの /mnt に入り、 サーバにあるファイルすべてを見れるはずです。
リモートファイルシステムを起動のたびに自動的にマウントしたいなら、 ファイルシステムを /etc/fstab ファイルに追加してください。 例としてはこのようになります。
server:/home /mnt nfs rw 0 0
fstab(5) マニュアルページに利用可能なオプションがすべて掲載されています。
20.6.3. 実用的な使い方
NFS には実用的な使用法がいくつもあります。 ここで典型的な使用法をいくつか紹介しましょう。
何台ものマシンで CDROM などのメディアを共有するように設定します。 これは安上がりで、たいていは、 複数のマシンにソフトウェアをインストールするのにより便利な方法です。
大規模なネットワークでは、 すべてのユーザのホームディレクトリを格納するメイン NFS サーバを構築すると、ずっと便利でしょう。 どのワークステーションにログインしても、 ユーザがいつでも同じホームディレクトリを利用できるように、 これらのホームディレクトリはネットワークに向けてエクスポートされます。
何台ものマシンで /usr/ports/distfiles ディレクトリを共有できます。こうすると、 何台ものマシン上に port をインストールする必要がある時に、 それぞれのマシンでソースコードをダウンロードすることなく、 直ちにソースにアクセスできます。
20.6.4. amd による自動マウント
amd(8) (自動マウントデーモン) は、 ファイルシステム内のファイルまたはディレクトリがアクセスされると、 自動的にリモートファイルシステムをマウントします。 また、一定の間アクセスされないファイルシステムは amd によって自動的にアンマウントされます。 amd を使用することは、通常 /etc/fstab 内に記述する恒久的なマウントに対する、 単純な代替案となります。
amd はそれ自身を NFS サーバとして /host および /net ディレクトリに結びつけることによって動作します。 このディレクトリ内のどこかでファイルがアクセスされると、 amd は対応するリモートマウントを調べて、 自動的にそれをマウントします。 /net が、エクスポートされたファイルシステムを IP アドレスで指定してマウントするのに利用される一方で、 /host は、エクスポートされたファイルシステムをリモートホスト名で指定してマウントするのに利用されます。
/host/foobar/usr 内のファイルにアクセスすると、 amd はホスト foobar からエクスポートされた /usr をマウントします。
例 1. amd によるエクスポートされたファイルシステムのマウント
showmount コマンドを用いて、 リモートホストのマウントで利用できるものが見られます。 たとえば、foobar と名付けられたホストのマウントを見るために次のように利用できます。
% showmount -e foobar
Exports list on foobar:
/usr 10.10.10.0
/a 10.10.10.0
% cd /host/foobar/usr例のように showmount はエクスポートとして /usr を表示します。 /host/foobar/usr にディレクトリを変更すると、 amd はホスト名 foobar を解決し、お望みのエクスポートをマウントしようと試みます。
amd は /etc/rc.conf 内に次の行を記述すれば、 起動スクリプトによって起動されます。
amd_enable="YES"
さらに amd_flags オプションによって amd にフラグをカスタマイズして渡せます。デフォルトでは amd_flags は次のように設定されています。
amd_flags="-a /.amd_mnt -l syslog /host /etc/amd.map /net /etc/amd.map"
/etc/amd.map ファイルは、 エクスポートがマウントされるデフォルトオプションを決定します。 /etc/amd.conf ファイルは、 amd のより高度な機能の一部を設定します。
詳細については amd(8) および amd.conf(8) マニュアルページを参照してください。
20.6.5. 他のシステムとの統合についての問題
ISA バス用のイーサネットアダプタの中には性能が悪いため、 ネットワーク、特に NFS で深刻な問題がおきるものがあります。 これは FreeBSD に限ったことではありませんが FreeBSD でも起こり得ます。
この問題は (FreeBSD を使用した) PC がシリコングラフィックス社やサン・マイクロシステムズ社などの高性能なワークステーションにネットワーク接続されている場合に頻繁に起こります。 NFS マウントはうまく動作するでしょう。 また、いくつかの操作もうまく動作するかもしれませんが、 他のシステムに対する要求や応答は続いていても、 突然サーバがクライアントの要求に対して応答しなくなります。これは、 クライアントが FreeBSD か上記のワークステーションであるときにクライアント側に起きる現象です。 多くのシステムでは、いったんこの問題が現われると、 行儀良くクライアントを終了する手段はありません。 NFS がこの状態に陥ってしまうと正常に戻すことはできないため、 多くの場合クライアントをリセットすることが唯一の解決法となります。
"正しい" 解決法は、より高性能のイーサネットアダプタを FreeBSD システムにインストールすることですが、 満足に動作させる簡単な方法があります。 FreeBSD システムが サーバ になるのなら、 クライアントからのマウント時に -w=1024 オプションをつけて下さい。FreeBSD システムが クライアント になるのなら、 NFS ファイルシステムを -r=1024 オプションつきでマウントして下さい。 これらのオプションは自動的にマウントをおこなう場合には クライアントの fstab エントリの 4 番目のフィールドに指定してもよいですし、 手動マウントの場合は mount コマンドの -o パラメータで指定してもよいでしょう。
NFS サーバとクライアントが別々のネットワーク上にあるような場合、 これと間違えやすい他の問題が起きることに注意して下さい。 そのような場合は、ルータが必要な UDP 情報をきちんとルーティングしているかを確かめて下さい。 していなければ、たとえあなたが何をしようと解決できないでしょう。
次の例では fastws は高性能ワークステーションのホスト (インタフェース) 名で、 freebox は低性能のイーサネットアダプタを備えた FreeBSD システムのホスト (インタフェース) 名です。 また /sharedfs はエクスポートされる NFS ファイルシステムであり (exports(5) を参照) 、 /project はエクスポートされたファイルシステムの、 クライアント上のマウントポイントとなります。 すべての場合において、アプリケーションによっては hard や soft, bg といった追加オプションがふさわしいかもしれないことに注意して下さい。
クライアント側 FreeBSD システム (freebox) の /etc/fstab の例は以下のとおりです。
fastws:/sharedfs /project nfs rw,-r=1024 0 0
freebox 上で手動で mount コマンドを実行する場合は次のようにして下さい。
# mount -t nfs -o -r=1024 fastws:/sharedfs /projectサーバ側 FreeBSD システム (fastws) の /etc/fstab の例は以下のとおりです。
freebox:/sharedfs /project nfs rw,-w=1024 0 0
fastws 上で手動で mount コマンドで実行する場合は次のようにして下さい。
# mount -t nfs -o -w=1024 freebox:/sharedfs /project近いうちにどのような 16 ビットのイーサネットアダプタでも、上記の読み出し、 書き込みサイズの制限なしで操作できるようになるでしょう。
失敗が発生したとき何が起きているか関心のある人に、 なぜ回復不可能なのかも含めて説明します。NFS は通常 (より小さいサイズへ分割されるかもしれませんが) 8 K の "ブロック" サイズで動作します。 イーサネットのパケットサイズは最大 1500 バイト程度なので、 上位階層のコードにとっては 1 つのユニットであって、 NFS "ブロック" は複数のイーサネットパケットに分割されるものの、 上位階層のコードにとっては 1 つのユニットであって、 ユニットとして受信され、組み立て直され、 肯定応答 (ACK) されなければなりません。 高性能のワークステーションは次々に NFS ユニットを構成するパケットを、 標準の許す限り間隔を詰めて次々に送り出すことができます。 小さく、容量の低いカードでは、 同じユニットの前のパケットがホストに転送される前に、 後のパケットがそれを踏みつぶしてしまいます。 このため全体としてのユニットは、再構成も肯定応答もできません。 その結果、 ワークステーションはタイムアウトして再送を試みますが、 8 K のユニット全体を再送しようとするので、 このプロセスは際限無く繰り返されてしまいます。
ユニットサイズをイーサネットのパケットサイズの 制限以下に抑えることにより、 受信した完全なイーサネットパケットについて個々に肯定応答を返せることが保証されるので、 デッドロック状態を避けられるようになります。
それでも、高性能なワークステーションが力任せに次々と PC システムにデータを送ったときには踏みつぶしが起きるかもしれません。 しかし、高性能のカードを使っていれば、NFS "ユニット" で必ずそのような踏みつぶしが起きるとは限りません。 踏みつぶしが起きたら、影響を受けたユニットは再送されて、 受信され、組み立てられ、肯定応答される十分な見込みがあります。
20.7. ディスクレス稼働
FreeBSD マシンはネットワークを通じて起動でき、 そして NFS サーバからマウントしたファイルシステムを使用して、 ローカルディスクなしで動作することができます。 標準の設定ファイルを変更する以上の、システムの修正は必要ありません。 必要な要素のすべてが用意されているので、 このようなシステムを設定するのは簡単です。
ネットワークを通じてカーネルを読み込む方法は、 少なくとも二つあります。
PXE: Intel® の Preboot Execution Environment システムは、 一部のネットワークカードまたはマザーボードに組み込まれた、 スマートなブート ROM の一形態です。 詳細については pxeboot(8) を参照してください。
port の etherboot (net/etherboot) は、 ネットワークを通じてカーネルを起動する ROM 化可能なコードを提供します。 コードはネットワークカード上のブート PROM に焼き付けるか、 あるいはローカルフロッピー (ハード) ディスクドライブ、 または動作している MS-DOS® システムから読み込むことができます。 多くのネットワークカードに対応しています。
サンプルスクリプト (/usr/shared/examples/diskless/clone_root) はサーバ上で、 ワークステーションのルートファイルシステムの作成と維持をやり易くします。 このスクリプトは少し書き換えないといけないでしょうが、 早く取り掛かれるようにします。
ディスクレスシステム起動を検知しサポートする標準のシステム起動ファイルが /etc 内にあります。
必要なら、NFS ファイルまたはローカルディスクのどちらかにスワップできます。
ディスクレスワークステーションを設定する方法はいろいろあります。 多くの要素が関わっており、 その多くはローカルの状況に合わせてカスタマイズできます。下記は、 単純さと標準の FreeBSD 起動スクリプトとの互換性を強調した完全なシステムの設定を説明します。 記述されているシステムの特徴は次のとおりです。
ディスクレスワークステーションは、 共有された読み取り専用の ルートファイルシステムと、 共有された読み取り専用の /usr を使用します。
ルート ファイルシステムは、 標準的な FreeBSD (典型的にはサーバの) のルートのコピーで、 一部の設定ファイルが、ディスクレス稼働、 また場合によってはそのワークステーションに特有のもので上書きされています。
書き込み可能でなければならない ルート の部分は mfs(8) ファイルシステムで覆われます。 システムが再起動するときにはすべての変更が失われるでしょう。
カーネルは DHCP (または BOOTP) および TFTP を用いて etherboot によって読み込まれます。
記述されているとおり、 このシステムは安全ではありません。 ネットワークの保護された範囲で使用されるべきであり、 他のホストから信頼されてはいけません。 |
20.7.1. セットアップの手順
20.7.1.1. DHCP/BOOTP の設定
ネットワークを通じて設定を取得し、 ワークステーションを起動するために一般的に使用されるプロトコルには、 BOOTP と DHCP の 2 つがあります。 それらはワークステーションのブートストラップ時に何ヵ所かで使用されます。
etherboot はカーネルを見つけるために DHCP (デフォルト) または BOOTP (設定オプションが必要) を使用します (PXE は DHCP を使用します) 。
NFS ルートの場所を定めるためにカーネルは BOOTP を使用します。
BOOTP だけを使用するようにシステムを設定することもできます。 bootpd(8) サーバプログラムは FreeBSD のベースシステムに含まれています。
しかしながら、DHCP には BOOTP に勝る点が多々あります。 (よりよい設定ファイル、PXE が使えること、 そしてディスクレス稼働には直接関係しない多くの長所) ここでは BOOTP だけ利用する場合と、 BOOTP と DHCP を組み合わせた設定を扱います。特に ISC DHCP ソフトウェアパッケージを利用する後者の方法に重点をおきます。
ISC DHCP を使用する設定
isc-dhcp サーバは、 BOOTP および DHCP リクエストの両方に答えることができます。
4.4-RELEASE の時点で isc-dhcp 3.0 はベースシステムの一部では無くなりました。 まずはじめに net/isc-dhcp3-server port または対応する package をインストールする必要があるでしょう。 ports および package に関する一般的な情報については アプリケーションのインストール - packages と ports を参照してください。
isc-dhcp がインストールされると、 動作するために設定ファイルを必要とします (通常 /usr/local/etc/dhcpd.conf が指定されます) 。 下記にコメントを含めた例を示します。
default-lease-time 600;
max-lease-time 7200;
authoritative;
option domain-name "example.com";
option domain-name-servers 192.168.4.1;
option routers 192.168.4.1;
subnet 192.168.4.0 netmask 255.255.255.0 {
use-host-decl-names on; (1)
option subnet-mask 255.255.255.0;
option broadcast-address 192.168.4.255;
host margaux {
hardware ethernet 01:23:45:67:89:ab;
fixed-address margaux.example.com;
next-server 192.168.4.4;(2)
filename "/tftpboot/kernel.diskless";(3)
option root-path "192.168.4.4:/data/misc/diskless";(4)
}
}| 1 | このオプションは host 宣言の値を、 ディスクレスホストへのホスト名として送るように dhcpd に指示します。 別の方法として、ホスト宣言内に option host-name margaux を加えるものがあります。 |
| 2 | TFTP サーバを next-server ディレクティブに指定します (デフォルトは DHCP サーバと同じホストを使います)。 |
| 3 | カーネルとして etherboot が読み込むファイルを filename ディレクティブに指定します。 |
| 4 | ルートファイルシステムへのパスを、 通常の NFS 書式で root-path オプションに指定します。 |
BOOTP を使用する設定
続けて、bootpd で同等のことをする設定です。 これは /etc/bootptab におきます。
BOOTP を使用するために、デフォルトではない NO_DHCP_SUPPORT オプション付きで etherboot をコンパイルしなければならないことと、PXE は DHCP を 必要 とすることに注意してください。 bootpd の唯一明白な利点は、 これがベースシステムに存在するということです。
.def100:\
:hn:ht=1:sa=192.168.4.4:vm=rfc1048:\
:sm=255.255.255.0:\
:ds=192.168.4.1:\
:gw=192.168.4.1:\
:hd="/tftpboot":\
:bf="/kernel.diskless":\
:rp="192.168.4.4:/data/misc/diskless":
margaux:ha=0123456789ab:tc=.def10020.7.1.2. Etherboot を用いるブートプログラムの準備
Etherboot のウェブサイト には主に Linux システムについて述べた 広範囲の文書 が含まれています。 しかし、それにもかかわらず有用な情報を含んでいます。 下記は FreeBSD システム上での etherboot の使用法についての概観を示します。
まずはじめに net/etherboot の package または port をインストールしなければなりません。 etherboot port は通常 /usr/ports/net/etherboot にあります。 ports ツリーがシステムにインストールされている場合、 このディレクトリ内で make を実行すれば、よきに計らってくれます。 ports および packages に関する情報は アプリケーションのインストール - packages と ports を参照してください。
ここで説明している方法では、ブートフロッピーを使用します。 他の方法 (PROM または DOS プログラム) については etherboot の文書を参照してください。
ブートフロッピーを作成するためには、 etherboot をインストールしたマシンのドライブにフロッピーディスクを挿入します。 それからカレントディレクトリを etherboot ツリー内の src ディレクトリにして次のように入力します。
# gmake bin32/devicetype.fd0devicetype は ディスクレスワークステーションのイーサネットカードタイプに依存します。 正しい devicetype を決定するために、 同じディレクトリ内の NIC ファイルを参照してください。
20.7.1.3. TFTP および NFS サーバの設定
TFTP サーバ上で tftpd を有効にする必要があります。
tftpdが提供するファイルを置くディレクトリ (たとえば /tftpboot) を作成してください。/etc/inetd.conf ファイルに以下の行を追加してください。
tftp dgram udp wait root /usr/libexec/tftpd tftpd -s /tftpboot
少なくとも PXE のいくつかのバージョンが TCP 版の TFTP を要求するようです。その場合
dgram udpをstream tcpに置き換えた 2 番目の行を追加してください。inetdに設定ファイルを再読み込みさせてください。# kill -HUP `cat /var/run/inetd.pid`
tftpboot ディレクトリはサーバ上のどこにでも置けます。 その場所が inetd.conf および dhcpd.conf の両方に設定されていることを確かめてください。
さらに NFS を有効にして NFS サーバの適切なファイルシステムをエクスポートする必要があります。
この行を /etc/rc.conf に追加してください。
nfs_server_enable="YES"
下記を /etc/exports に加えることで、 ディスクレスマシンのルートディレクトリが位置するファイルシステムをエクスポートしてください (ボリュームのマウントポイントを適当に調節し、 margaux をディスクレスワークステーションの名前に置き換えてください)。
/data/misc -alldirs -ro margaux
mountdに設定ファイルを再読み込みさせてください。 /etc/rc.conf 内で NFS をはじめて有効にする必要があったのなら、 代わりに再起動した方がよいかもしれません。# kill -HUP `cat /var/run/mountd.pid`
20.7.1.4. ディスクレス用のカーネル構築
次のオプションを (通常のものに) 追加した、 ディスクレスクライアント用のカーネルコンフィグレーションファイルを作成してください。
options BOOTP # Use BOOTP to obtain IP address/hostname
options BOOTP_NFSROOT # NFS mount root filesystem using BOOTP info
options BOOTP_COMPAT # Workaround for broken bootp daemons.BOOTP_NFSV3 および BOOTP_WIRED_TO を利用してもよいかもしれません (LINT を参照してください)。
カーネルを構築して (FreeBSD カーネルのコンフィグレーション を参照)、 dhcpd.conf に記述した名称で tftp ディレクトリにコピーしてください。
20.7.1.5. ルートファイルシステムの準備
dhcpd.conf に root-path として記載された ディスクレスワークステーションのためのルートファイルシステムを作成する必要があります。
これを行う最も簡単な方法は /usr/shared/examples/diskless/clone_root シェルスクリプトを使用することです。 このスクリプトは、少なくともファイルシステムが作成される場所 (DEST 変数) を調節するために変更する必要があります。
説明についてはスクリプトの一番上にあるコメントを参照してください。 ベースシステムをどのように構築するか、 またファイルがどのようにディスクレス稼働、サブネット、 または個々のワークステーションに固有のバージョンによって、 選択的にオーバライドできるかを説明します。 また、ディスクレスな場合の /etc/fstab ファイルおよび /etc/rc.conf ファイルの例を示します。
/usr/shared/examples/diskless 内の README ファイルには、多くの興味深い背景情報が書かれています。 しかし diskless ディレクトリ内の他の例と同じく、 clone_root と /etc/rc.diskless[12] で実際に使われているものとは異なる設定方法が説明されています。 ここに書かれている方法は rc スクリプトの変更が必要になりますが、 こちらの方が気に入ったというのでなければ、 参照にとどめてください。
20.7.1.6. スワップの設定
必要なら、サーバに置かれたスワップファイルに NFS 経由でアクセスできます。 bootptab または dhcpd.conf の正確なオプションは、 現時点では明確には文書化されていません。 下記の設定例は isc-dhcp 3.0rc11 を使用して動作したと報告されているものです。
dhcpd.conf に下記の行を追加してください。
# Global section option swap-path code 128 = string; option swap-size code 129 = integer 32; host margaux { ... # Standard lines, see above option swap-path "192.168.4.4:/netswapvolume/netswap"; option swap-size 64000; }これは、少なくとも FreeBSD クライアントにおいては、 DHCP/BOOTP オプションコードの 128 は NFS スワップファイルへのパスで、オプションコード 129 は KB 単位のスワップサイズだということです。 もっと古いバージョンの
dhcpdではoption option-128 "…という書式が受け付けられましたが、 もはや対応していません。代わりに、/etc/bootptab では次の書式を使います。
T128="192.168.4.4:/netswapvolume/netswap":T129=0000fa00/etc/bootptab では、スワップの大きさは 16 進数で表さなければなりません。
NFS スワップファイルサーバ側でスワップファイルを作成します。
# mkdir /netswapvolume/netswap # cd /netswapvolume/netswap # dd if=/dev/zero bs=1024 count=64000 of=swap.192.168.4.6 # chmod 0600 swap.192.168.4.6192.168.4.6 はディスクレスクライアントの IP アドレスです。
NFS スワップファイルサーバ上で /etc/exports に下記の行を追加してください。
/netswapvolume -maproot=0:10 -alldirs margaux
それから、上述したように mountd にエクスポートファイルを再読み込みさせてください。
20.7.1.7. 雑多な問題
読み取り専用の /usr で動作させる
ディスクレスワークステーションが X を起動するように設定されている場合、 xdm 設定ファイルを調整しなければならないでしょう。 これはデフォルトでエラーファイルを /usr に置きます。
FreeBSD ではないサーバを使用する
ルートファイルシステムを提供するサーバが FreeBSD で動作していない場合、 FreeBSD マシン上でルートファイルシステムを作成し、 tar または cpio を利用して置きたい場所にコピーしなければならないでしょう。
この状況では、major/minor 整数サイズが異なっていることにより /dev 内のスペシャルファイルに関する問題が時々おこります。 この問題を解決するには、非 FreeBSD サーバからディレクトリをエクスポートして、 そのディレクトリを FreeBSD マシンでマウントし、 FreeBSD マシン上で MAKEDEV を実行して正しいデバイスエントリを作成します (FreeBSD 5.0 およびそれ以降では、devfs(5) を使用してユーザに意識させずにデバイスノードを割り当てるので、 これらのバージョンでは MAKEDEV は必要ありません)。
20.8. ISDN
ISDN 技術とハードウェアに関しては、 Dan Kegel’s ISDN Page がよい参考になるでしょう。
手軽な ISDN の導入手順は以下のようになります。
ヨーロッパ在住の方は ISDN カードの節に進んでください。
ダイヤルアップ専用でない回線上で、 インターネットプロバイダをつかってインターネットに接続するために ISDN を使用することを第一に考えている場合は、 ターミナルアダプタの使用を考えてみてください。 この方法はもっとも柔軟性があり、 プロバイダを変更した場合の問題も少ないでしょう。
2 つの LAN を接続する場合や、 ISDN 専用線を使用する場合には、 スタンドアロンなルータまたはブリッジの使用を勧めます。
費用はどの解決法を選ぶかを決める重要な要因です。 以下に、最も安価な方法から、高価な方法まで順に説明していきます。
20.8.1. ISDN カード
FreeBSD の ISDN 実装は、パッシブカードを使用した DSS1/Q.931 (または Euro-ISDN) 標準だけに対応しています。FreeBSD 4.4 からは、ファームウェアが他の信号プロトコルにも対応している 一部のアクティブカードにも対応しました。 その中には、はじめて対応された一次群速度インタフェース (PRI) ISDN カードもあります。
isdn4bsd は IP over raw HDLC または同期 PPP を利用して他の ISDN ルータに接続できるようにします。 PPP では、カーネル PPP を sppp(4) ドライバを修正した isppp ドライバとともに利用するか、または ユーザプロセス ppp(8) を利用するかのどちらかになります。ユーザ ppp(8) を利用すると、二つ以上の ISDN B チャネルを併せて利用できます。 ソフトウェア 300 ボーモデムのような多くのユーティリティとともに、 留守番電話アプリケーションも利用可能です。
FreeBSD が対応している PC ISDN カードの数は増加しており、 ヨーロッパ全域や世界のその他多くの地域でうまく使えることが報告されています。
対応しているパッシブ ISDN カードのほとんどは Infineon (前身は Siemens) の ISAC/HSCX/IPAC ISDN チップセットを備えたカードですが、 Cologne Chip から供給されたチップを備えた ISDN カード (ISA バスのみ)、Winbond W6692 チップを備えた PCI カード、 Tiger300/320/ISAC チップセットを組み合わたカードの一部、 および AVM Fritz!Card PCI V.1.0 や AVM Fritz!Card PnP のようなベンダ独自のチップセットに基づいたカードもあります。
現在のところ、対応しているアクティブカードは AVM B1 (ISA および PCI) BRI カードと AVM T1 PCI PRI カードです。
isdn4bsd についての文書は FreeBSD システム内の /usr/shared/examples/isdn/ ディレクトリまたは isdn4bsd のウェブサイトを参照してください。 そこにはヒントや正誤表や isdn4bsd ハンドブックのような、 さらに多くの文書に対するポインタがあります。
異なる ISDN プロトコルや、現在対応されていない ISDN PC カードに対応することや、その他 isdn4bsd を拡張することに興味があるなら、Hellmuth Michaelis <hm@FreeBSD.org> に連絡してください。
isdn4bsd のインストール、設定、 そしてトラブルシューティングに関して質問があれば freebsd-isdn メーリングリストが利用可能です。
20.8.2. ISDN ターミナルアダプタ
ターミナルアダプタ (TA) は ISDN で、 通常の電話線におけるモデムに相当するものです。
ほとんどの TA は、標準のヘイズ AT コマンドセットを使用しているので、 単にモデムと置き換えて使うことができます。
TA は、基本的にはモデムと同じように動作しますが、 接続方法は異なり、通信速度も古いモデムよりはるかに速くなります。 PPP の設定を、 モデムの場合と同じように行ってください。 特にシリアル速度を使用できる最高速度に設定するのを忘れないでください。
プロバイダへの接続に TA を使用する最大のメリットは、動的 PPP を行えることです。 最近 IP アドレス空間がますます不足してきているため、 ほとんどのプロバイダは、 固定 IP アドレスを割り当てないようになっています。 ほとんどのスタンドアローンルータは、動的 IP アドレス割り当てに対応していません。
最近の ISDN ルータでは IP アドレスの動的割り当てに対応しているものも多いようです。 ただし制限がある場合もありますので、 詳しくはメーカに問い合わせてください。 |
TA を使用した場合の機能や接続の安定性は、使用している PPP デーモンに完全に依存します。そのため、FreeBSD で PPP の設定が完了していれば、使用している既存のモデムを ISDN の TA に簡単にアップグレードすることができます。ただし、それまでの PPP のプログラムに問題があった場合、その問題は TA に置き換えてもそのまま残ります。
最高の安定性を求めるのであれば、 ユーザランド PPP ではなく、カーネル PPPを使用してください。
以下の TA は、FreeBSD で動作確認ずみです。
Motorola BitSurfer および Bitsurfer Pro
Adtran
他の TA もほとんどの場合うまく動作するでしょう。TA のメーカーでは、TA がほとんどの標準モデム AT コマンドセットを受け付けるようにするよう努力しているようです。
外部 TA を使う際の最大の問題点は、 モデムの場合と同じく良いシリアルカードが必要であるということです。
シリアルデバイスの詳細と、 非同期シリアルポートと同期シリアルポートの差を理解するには、FreeBSD シリアルハードウェアチュートリアルを参照してください。
標準の PC シリアルポート (非同期) に接続された TA は 128 Kbs の接続を行っていても、最大通信速度が 115.2 Kbs に制限されてしまいます。128 Kbs の ISDN の性能を最大限に生かすためには TA を同期シリアルカードに接続しなければなりません。
内蔵 TA を購入すれば、 同期/非同期問題を回避できるとは思わないでください。内蔵 TA には、 単に標準 PC シリアルポートのチップが内蔵されているだけです。 内蔵 TA の利点といえば、 シリアルケーブルを買わなくていいということと、 電源コンセントが一つ少なくて済むということくらいでしょう。
同期カードと TA の組合せでも、スタンドアロンのルータと同程度の速度は確保できます。 さらに、386 の FreeBSD マシンと組合せると、 より柔軟な設定が可能です。
同期カード/TA を選ぶか、スタンドアロンルータを選ぶかは、 多分に宗教的な問題です。 メーリングリストでもいくつか議論がありました。議論の全容については、 アーカイブ を検索してください。
20.8.3. スタンドアロン ISDN ブリッジ/ルータ
ISDN ブリッジあるいはルータは、 FreeBSD あるいは他の OS に特有のものでは皆目ありません。 ルーティングやブリッジング技術に関する詳細は、 ネットワークの参考書をご覧ください。
この節では、 ルータとブリッジのどちらでもあてはまるように記述します。
ローエンド ISDN ルータ/ブリッジ製品は、 価格が下がってきていることもあり、 より広く選択されるようになるでしょう。ISDN ルータは、 ローカルイーサネットネットワークに直接接続し、 自身で他のブリッジ/ルータとの接続を制御する小さな箱です。PPP や他の広く使用されているプロトコルをつかって通信するためのソフトウェアが組み込まれています。
ルータは、完全な同期 ISDN 接続を使用するため、通常の TA と比較してスループットが大幅に向上します。
ISDN ルータ/ブリッジを使用する場合の最大の問題点は、 各メーカーの製品間に相性の問題がまだ存在することです。 インターネットプロバイダとの接続を考えている場合には、 プロバイダと相談することをお勧めします。
事務所の LAN と家庭の LAN の間など、二つの LAN セグメントの間を接続しようとしている場合は、 これはもっともメンテナンスが簡単で、安くあがる解決方法です。 接続の両側の機材を購入するので、 リンクがうまくいくであろうことを保証できます。
たとえば、 家庭のコンピュータや支店のネットワークを本社のネットワークに接続するためには、 以下のような設定が使用できます。
例 2. 支店または家庭のネットワーク
ネットワークは 10 Base 2 イーサネット ("thinnet") のバス型トポロジを用いています。ルータとネットワークの間は、 必要に応じて AUI/10BT トランシーバを使って接続してください。
家庭/支店で一台しかコンピュータを使用しないのであれば、 クロスのツイストペアケーブルを使用して、 直接スタンドアロンルータに接続することも可能です。
例 3. 本社 LAN や他の LAN
ネットワークは 10 base T イーサネット ("Twisted Pair") のスター型トポロジを用いています。
ほとんどのルータ/ブリッジの大きな利点は、 別々の二つのサイトに対して、同時 にそれぞれ独立した二つの PPP 接続が可能であることです。 これは、シリアルポートを 2 つもった特定の (通常は高価な) モデルを除いて、通常の TA では対応していません。 チャネルボンディングや MPP などと混同しないでください。
たとえば、事務所で専用線 ISDN 接続を使用していて、 別の ISDN 回線を購入したくないときには大変便利な機能です。この場合、 事務所のルータは、インターネットに接続するための一つの専用線 B チャネル接続 (64 Kbs) を管理し、 別の B チャネルを他のデータ接続に使用できます。 2 つ目の B チャネルは他の場所とのダイアルイン、 ダイアルアウトに使用したり、バンド幅を増やすために、 1 つ目の B チャネルと動的に結合すること (MPPなど) ができます。
またイーサネットブリッジは、IP パケット以外も中継できます。 IPX/SPX など、使用するすべてのプロトコルを送ることが可能です。
20.9. NIS/YP
20.9.1. NIS/YP とは?
NIS とは Network Information Services の略で Sun Microsystems によって UNIX® の (もともとは SunOS™ の) 集中管理のために開発されました。現在では事実上の業界標準になっており、 主要な UNIX® ライクシステム (Solaris™, HP-UX, AIX®, Linux, NetBSD, OpenBSD, FreeBSD、等々) はすべてこれをサポートしています。
NIS は元々、イエローページといっていましたが、 商標問題から Sun はその名前を変えました。 古い用語 (および yp) はまだよく見られ、使用されています。
NIS は RPC を使ったクライアント/サーバシステムです。 これを使うと NIS ドメイン内のマシン間で、 共通の設定ファイルを共有することができます。 また NIS を使うことでシステム管理者は最小限の設定データで NIS クライアントを立ち上げることができ、 1 ヶ所から設定データの追加、削除、変更が可能です。
NIS は Windows NT® のドメインシステムに似ています。 内部の実装は似ても似つかないものですが、 基本的な機能を対比することはできます。
20.9.2. 知っておくべき用語 / プロセス
NIS サーバの立ち上げや NIS クライアントの設定など、 NIS を FreeBSD に導入するにあたって、 目にするであろう用語や重要なユーザプロセスがいくつかあります。
| 用語 | 説明 |
|---|---|
NIS ドメイン名 | NIS マスタサーバとそのクライアントすべて (スレーブサーバを含む) には NIS ドメイン名がついています。 Windows NT® ドメイン名と同様に、NIS ドメイン名は DNS とは何の関係もありません。 |
portmap | RPC (Remote Procedure Call, NIS で使用されるネットワークプロトコル) を利用するために実行しておかなければなりません。 |
ypbind | NIS クライアントを NIS サーバに "結びつけ" ます。 これは NIS ドメイン名をシステムから取得し RPC を用いてサーバに接続します。 |
ypserv | は NIS サーバでのみ実行されるべきもので、 NIS サーバプロセスそのものです。ypserv(8) が停止した場合、サーバはもはや NIS リクエストに応答することができなくなるでしょう (できれば、後を引き継ぐスレーブサーバがあるとよいでしょう)。 今まで使っていたサーバが機能を停止したとき、 別のサーバに再接続しに行かない NIS の実装もいくつかあります (FreeBSD のものは違います)。 そのような場合に復帰するための唯一の方法は、 サーバプロセス (あるいはサーバ全体)、もしくはクライアントの |
rpc.yppasswdd | NIS マスターサーバで動かすべき、 もう一つのプロセスです。これは NIS クライアントが NIS パスワードを変更することを可能にするデーモンです。 このデーモンが動作していないときは、 ユーザは NIS マスタサーバにログインし、 そこでパスワードを変更しなければなりません。 |
20.9.3. 動作のしくみ
NIS 環境にあるホストは、 マスターサーバ、スレーブサーバ、クライアントの 3 種類に分類されます。 サーバは、ホストの設定情報の中心的な情報格納庫の役割をします。 マスターサーバは元となる信頼できる情報を保持し、 スレーブサーバは冗長性を確保するためこの情報をミラーします。 そしてクライアントは、サーバから情報の提供を受けて動作します。
この方法を用いることで、数多くのファイルにある情報が共有できます。 よく NIS で共有されるのは、 master.passwd や group, hosts といったファイルです。 クライアント上のプロセスが、 通常ならローカルのファイルにある情報を必要とするときは、 クライアントは代わりに接続している NIS サーバに問い合わせを行います。
20.9.3.1. マシンの分類
NIS マスターサーバ。 このサーバは Windows NT® で言うところのプライマリドメインコントローラにあたります。 すべての NIS クライアントで利用されるファイルを保守します。 passwd や group、 その他 NIS クライアントが参照するファイルは、 マスターサーバにあります。
一つのマシンが一つ以上の NIS ドメインのマスターサーバになることは可能です。 しかし、ここでは比較的小規模の NIS 環境を対象としているため、 そのような場合については扱いません。
NIS スレーブサーバ。 Windows NT® のバックアップドメインコントローラに似たもので、 NIS スレーブサーバは NIS マスターサーバのデータファイルのコピーを保持します。 NIS スレーブサーバは重要な環境で必要とされる冗長性を提供し、 マスターサーバの負荷のバランスをとります。 NIS クライアントは常に最初にレスポンスを返したサーバを NIS サーバとして接続しますが、 これにはスレーブサーバも含まれます。
NIS クライアント。 NIS クライアントは大部分の Windows NT® ワークステーションのように、ログオンに際して NIS サーバ (Windows NT® ワークステーションの場合は Windows NT® ドメインコントローラ) に接続して認証します。
20.9.4. NIS/YP を使う
この節では NIS 環境の立ち上げ例を取り上げます。
この節ではあなたが FreeBSD 3.3 以降を使っているものとします。 ここで与えられる指示は おそらく FreeBSD の 3.0 以降のどのバージョンでも機能するでしょうが、 それを保証するものではありません。 |
20.9.4.1. 計画を立てる
あなたが大学の小さな研究室の管理人であるとしましょう。 この研究室は 15 台の FreeBSD マシンからなっていて、 現在はまだ集中管理されていません。 すなわち、各マシンは /etc/passwd と /etc/master.passwd を各々が持っています。 これらのファイルは手動でお互いに同期させています。 つまり現時点では、新しいユーザをあなたが追加するとき、 adduser を 15 ヶ所すべてで実行しなければなりません。 これは明らかに変える必要があるため、 あなたはこのうち 2 台をサーバにして NIS を導入することを決めました。
その結果、研究室の設定はこのようなものになります。
| マシンの名前 | IP アドレス | 役割 |
|---|---|---|
|
| NIS マスタ |
|
| NIS スレーブ |
|
| 教員用のワークステーション |
|
| クライアントマシン |
|
| その他のクライアントマシン |
もし NIS によるシステム管理の設定を行なうのが初めてなら、 どのようにしたいのか、 ひととおり最後まで考えてみることをお勧めします。 ネットワークの規模によらず、 いくつか決めるべきことがあるからです。
NIS ドメイン名を決める
ここでいうドメイン名は、今まであなたが使っていた、 いわゆる "ドメイン名" と呼んでいたものとは違います。 正確には "NIS ドメイン名" と呼ばれます。 クライアントがサーバに情報を要求するとき、 その要求には自分が属する NIS ドメインの名前が含まれています。 これは 1 つのネットワークに複数のサーバがある場合に、 どのサーバが要求を処理すれば良いかを決めるために使われます。 NIS ドメイン名とは、 関連のあるホストをグループ化するための名前である、 と考えると良いでしょう。
組織によってはインターネットのドメイン名を NIS ドメイン名に使っているところがあります。 これはネットワークのトラブルをデバッグするときに混乱の原因となるため、 お勧めできません。 NIS ドメイン名はネットワーク内で一意なければいけません。そして、 ドメイン名がドメインに含まれるマシンを表すようなものであれば分かり易いです。 たとえば Acme 社のアート (Art) 部門であれば NIS ドメイン名を "acme-art" とすれば良いでしょう。この例では NIS ドメイン名として test-domain を使用します。
しかしながらオペレーティングシステムによっては (特に SunOS™)、 NIS ドメイン名をネットワークドメイン名として使うものもあります。 あなたのネットワークにそのような制限のあるマシンが 1 台でもあるときは、NIS のドメイン名としてインターネットのネットワークドメイン名を使わなければ いけません。
サーバマシンの物理的必要条件
NIS サーバとして使うマシンを選ぶ際には、 いくつか注意すべき点があります。 NIS に関する困ったことの一つに、 クライアントのサーバへの依存度があります。 クライアントが自分の NIS ドメインのサーバに接続できないと、 マシンが使用不能になることがあまりに多いのです。 もし、ユーザやグループに関する情報が得られなければ、 ほとんどのシステムは一時的に停止してしまいます。 こういったことを念頭に置いて、頻繁にリブートされるマシンや、 開発に使われそうなマシンを選ばないようにしなければなりません。 理想的には NIS サーバはスタンドアロンで NIS サーバ専用のマシンにするべきです。 ネットワークの負荷が重くなければ、 他のサービスを走らせているマシンを NIS サーバにしてもかまいません。 ただし NIS サーバが使えなくなると、 すべての クライアントに影響をおよぼす、 という点には注意しなければなりません。
20.9.4.2. NIS サーバ
元となるすべての NIS 情報は、 NIS マスターサーバと呼ばれる 1 台のマシンに格納されます。 この情報が格納されるデータベースを NIS マップと呼びます。 FreeBSD では、このマップは /var/yp/[domainname] に置かれます。 [domainname] は、 サーバがサービスする NIS ドメインです。 1 台の NIS サーバが複数のドメインをサポートすることも可能です。 つまり、このディレクトリを各々のドメインごとに作ることができます。 それぞれのドメインは、 独立したマップの集合を持つことになります。
NIS のマスターサーバとスレーブサーバ上では、 ypserv デーモンがすべての NIS 要求を処理します。 ypserv は NIS クライアントからの要求を受け付け、 ドメイン名とマップ名を対応するデータベースファイルへのパスに変換し、 データをクライアントに返送します。
NIS マスターサーバの設定
やりたいことにもよりますが NIS マスターサーバの設定は比較的単純です。 FreeBSD は初期状態で NIS に対応しています。 必要なのは以下の行を /etc/rc.conf に追加することだけで、 あとは FreeBSD がやってくれます。
nisdomainname="test-domain"
この行はネットワークの設定後に (たとえば再起動後に) NIS のドメイン名を test-domain に設定します。
nis_server_enable="YES"
これは FreeBSD に次にネットワークが立ち上がったとき NIS のサーバプロセスを起動させます。
nis_yppasswdd_enable="YES"
これは
rpc.yppasswddデーモンを有効にします。上述したようにこれはユーザが NIS のパスワードをクライアントのマシンから変更することを可能にします。
NIS の設定によっては、 さらに他のエントリを付け加える必要があるかもしれません。 詳細については、下記の NIS クライアントとしても動作している NIS サーバ 節を参照してください。 |
さて、あとはスーパユーザ権限で /etc/netstart コマンドを実行するだけです。 これにより /etc/rc.conf で定義された値を使ってすべての設定が行なわれます。
NIS マップの初期化
NIS マップ とは /var/yp ディレクトリにあるデータベースファイルです。 これらは NIS マスタの /etc ディレクトリの設定ファイルから作られます。 唯一の例外は /etc/master.passwd ファイルです。これは root や他の管理用アカウントのパスワードまでその NIS ドメインのすべてのサーバに伝えたくないという、 もっともな理由によるものです。このため NIS マップの初期化の前に以下を行う必要があります。
# cp /etc/master.passwd /var/yp/master.passwd
# cd /var/yp
# vi master.passwdシステムに関するアカウント (bin, tty, kmem, games など) や、NIS クライアントに伝えたくないアカウント (たとえば root や他の UID が 0 (スーパユーザ) のアカウント) をすべて NIS マップから取り除かなければなりません。
/var/yp/master.passwd が グループまたは誰もが読めるようになっていないようにしてください (モード 600)! 必要なら |
すべてが終わったら NIS マップを初期化します! FreeBSD には、これを行うために ypinit という名のスクリプトが含まれています (詳細はそのマニュアルページをご覧ください)。 このスクリプトはほとんどの UNIX® OS に存在しますが、 すべてとは限らないことを覚えておいてください。 Digital Unix/Compaq Tru64 UNIX では ypsetup と呼ばれています。NIS マスタのためのマップを作るためには -m オプションを ypinit に与えます。上述のステップを完了しているなら、以下を実行して NIS マップを生成します。
ellington# ypinit -m test-domain
Server Type: MASTER Domain: test-domain
Creating an YP server will require that you answer a few questions.
Questions will all be asked at the beginning of the procedure.
Do you want this procedure to quit on non-fatal errors? [y/n: n] n
Ok, please remember to go back and redo manually whatever fails.
If you don't, something might not work.
At this point, we have to construct a list of this domains YP servers.
rod.darktech.org is already known as master server.
Please continue to add any slave servers, one per line. When you are
done with the list, type a <control D>.
master server : ellington
next host to add: coltrane
next host to add: ^D
The current list of NIS servers looks like this:
ellington
coltrane
Is this correct? [y/n: y] y
[..output from map generation..]
NIS Map update completed.
ellington has been setup as an YP master server without any errors.ypinit は /var/yp/Makefile を /var/yp/Makefile.dist から作成します。 作成された時点では、そのファイルはあなたが FreeBSD マシンだけからなるサーバが 1 台だけの NIS 環境を扱っていると仮定しています。 test-domain はスレーブサーバを一つ持っていますので /var/yp/Makefile を編集しなければなりません。
ellington# vi /var/yp/Makefile以下の行を (もし既にコメントアウトされていないならば) コメントアウトしなければなりません。
NOPUSH = "True"
NIS スレーブサーバの設定
NIS スレーブサーバの設定はマスターサーバの設定以上に簡単です。 スレーブサーバにログオンし /etc/rc.conf ファイルを前回と同様に編集します。唯一の違うところは ypinit の実行に -s オプションを使わなければいけないことです。 -s オプションは NIS マスターサーバの名前を要求し、 コマンドラインは以下のようになります。
coltrane# ypinit -s ellington test-domain
Server Type: SLAVE Domain: test-domain Master: ellington
Creating an YP server will require that you answer a few questions.
Questions will all be asked at the beginning of the procedure.
Do you want this procedure to quit on non-fatal errors? [y/n: n] n
Ok, please remember to go back and redo manually whatever fails.
If you don't, something might not work.
There will be no further questions. The remainder of the procedure
should take a few minutes, to copy the databases from ellington.
Transferring netgroup...
ypxfr: Exiting: Map successfully transferred
Transferring netgroup.byuser...
ypxfr: Exiting: Map successfully transferred
Transferring netgroup.byhost...
ypxfr: Exiting: Map successfully transferred
Transferring master.passwd.byuid...
ypxfr: Exiting: Map successfully transferred
Transferring passwd.byuid...
ypxfr: Exiting: Map successfully transferred
Transferring passwd.byname...
ypxfr: Exiting: Map successfully transferred
Transferring group.bygid...
ypxfr: Exiting: Map successfully transferred
Transferring group.byname...
ypxfr: Exiting: Map successfully transferred
Transferring services.byname...
ypxfr: Exiting: Map successfully transferred
Transferring rpc.bynumber...
ypxfr: Exiting: Map successfully transferred
Transferring rpc.byname...
ypxfr: Exiting: Map successfully transferred
Transferring protocols.byname...
ypxfr: Exiting: Map successfully transferred
Transferring master.passwd.byname...
ypxfr: Exiting: Map successfully transferred
Transferring networks.byname...
ypxfr: Exiting: Map successfully transferred
Transferring networks.byaddr...
ypxfr: Exiting: Map successfully transferred
Transferring netid.byname...
ypxfr: Exiting: Map successfully transferred
Transferring hosts.byaddr...
ypxfr: Exiting: Map successfully transferred
Transferring protocols.bynumber...
ypxfr: Exiting: Map successfully transferred
Transferring ypservers...
ypxfr: Exiting: Map successfully transferred
Transferring hosts.byname...
ypxfr: Exiting: Map successfully transferred
coltrane has been setup as an YP slave server without any errors.
Don't forget to update map ypservers on ellington.この例の場合 /var/yp/test-domain というディレクトリが必要になります。 NIS マスターサーバのマップファイルのコピーは、 このディレクトリに置いてください。 これらを確実に最新のものに維持する必要があります。 次のエントリをスレーブサーバの /etc/crontab に追加することで、最新のものに保つことができます。
20 * * * * root /usr/libexec/ypxfr passwd.byname 21 * * * * root /usr/libexec/ypxfr passwd.byuid
この二行はスレーブサーバにあるマップファイルを、 マスターサーバのマップファイルと同期させるものです。 このエントリは必須というわけではありませんが、マスターサーバは NIS マップに対する変更をスレーブサーバに伝えようとしますし、 サーバが管理するシステムにとってパスワード情報はとても重要なので、 強制的に更新してしまうことはよい考えです。特に、 マップファイルの更新がきちんと行なわれるかどうかわからないくらい混雑するネットワークでは、 重要になります。
スレーブサーバ上でも /etc/netstart コマンドを実行して、NIS サーバを再起動してください。
20.9.4.3. NIS クライアント
NIS クライアントは ypbind デーモンを使って、特定の NIS サーバとの間に結合 (binding) と呼ばれる関係を成立させます。 ypbind はシステムのデフォルトのドメイン (domainname コマンドで設定されます) を確認し、RPC 要求をローカルネットワークにブロードキャストします。 この RPC 要求により ypbind が結合を成立させようとしているドメイン名が指定されます。 要求されているドメイン名に対してサービスするよう設定されたサーバが ブロードキャストを受信すると、 サーバは ypbind に応答しypbind は応答のあったサーバのアドレスを記録します。複数のサーバ (たとえば一つのマスターサーバと、複数のスレーブサーバ) が利用可能な場合、ypbind は、 最初に応答したサーバのアドレスを使用します。 これ以降、クライアントのシステムは、 すべての NIS の要求をそのサーバに向けて送信します。 ypbind は、 サーバが順調に動作していることを確認するため、 時々 "ping" をサーバに送ります。 反応が戻ってくるべき時間内に ping に対する応答が来なければ、 ypbind は、そのドメインを結合不能 (unbound) として記録し、別のサーバを見つけるべく、 再びブロードキャストパケットの送信を行います。
NIS クライアントの設定
FreeBSD マシンを NIS クライアントにする設定は非常に単純です。
ネットワークの起動時に NIS ドメイン名を設定して
ypbindを起動させるために /etc/rc.conf ファイルを編集して以下の行を追加します。nisdomainname="test-domain" nis_client_enable="YES"
NIS サーバから、 利用可能なパスワードエントリをすべて取り込むため、 /etc/master.passwd からすべてのユーザアカウントを取り除いて、
vipwコマンドで以下の行を /etc/master.passwd の最後に追加します。+:::::::::
この行によって NIS サーバのパスワードマップにアカウントがある人全員にアカウントが与えられます。 この行を変更すると、 さまざまな NIS クライアントの設定を行なうことが可能です。 詳細は ネットグループ を、さらに詳しい情報については、O’Reilly の
Managing NFS and NISを参照してください。/etc/master.passwd 内に少なくとも一つのローカルアカウント (つまり NIS 経由でインポートされていないアカウント) を置くべきです。 また、このアカウントは
wheelグループのメンバーであるべきです。 NIS がどこか調子悪いときには、 リモートからこのアカウントでログインし、 root になって修復するのに利用できます。NIS サーバにあるすべてのグループエントリを取り込むため、 以下の行を /etc/group に追加します。
+:*::
上記の手順がすべて完了すれば、 ypcat passwd によって NIS サーバの passwd マップが参照できるようになっているはずです。
20.9.5. NIS セキュリティ
一般にドメイン名さえ知っていれば、 どこにいるリモートユーザでも ypserv(8) に RPC を発行して NIS マップの内容を引き出すことができます。 こういった不正なやりとりを防ぐため、 ypserv(8) には securenets と呼ばれる機能があります。これは、 アクセスを決められたホストだけに制限するのに使える機能です。 ypserv(8) は起動時に /var/yp/securenets ファイルから securenets に関する情報を読み込みます。
上記のパス名は |
# allow connections from local host -- mandatory 127.0.0.1 255.255.255.255 # allow connections from any host # on the 192.168.128.0 network 192.168.128.0 255.255.255.0 # allow connections from any host # between 10.0.0.0 to 10.0.15.255 10.0.0.0 255.255.240.0
ypserv(8) が上記のルールの一つと合致するアドレスからの要求を受け取った場合、 処理は正常に行なわれます。 もしアドレスがルールに合致しなければ、 その要求は無視されて警告メッセージがログに記録されます。 また /var/yp/securenets が存在しない場合、 ypserv はすべてのホストからの接続を受け入れます。
ypserv は Wietse Venema 氏による tcpwrapper パッケージもサポートしています。 そのため /var/yp/securenets の代わりに tcpwrapper の設定ファイルを使ってアクセス制御を行なうことも可能です。
これらのアクセス制御機能は一定のセキュリティを提供しますが、 どちらも特権ポートのテストのような "IP spoofing" 攻撃に対して脆弱です。すべての NIS 関連のトラフィックはファイアウォールでブロックされるべきです。 /var/yp/securenets を使っているサーバは、古い TCP/IP 実装を持つ正当なクライアントへのサービスに失敗することがあります。 これらの実装の中にはブロードキャストのホストビットをすべて 0 でセットしてしまったり、 ブロードキャストアドレスの計算でサブネットマスクを見落としてしまったりするものがあります。 これらの問題にはクライアントの設定を正しく行なえば解決できるものもありますが、 問題となっているクライアントシステムを引退させるか、 /var/yp/securenets を使わないようにしなければならないものもあります。 このような古風な TCP/IP の実装を持つサーバで /var/yp/securenets を使うことは実に悪い考えであり、 あなたのネットワークの大部分において NIS の機能喪失を招きます。 tcpwrapper パッケージを使うとあなたの NIS サーバのレイテンシ (遅延) が増加します。特に混雑したネットワークや遅い NIS サーバでは、遅延の増加によって、 クライアントプログラムのタイムアウトが起こるかもしれません。 一つ以上のクライアントシステムがこれらの兆候を示したなら、 あなたは問題となっているクライアントシステムを NIS スレーブサーバにして自分自身に結び付くように強制すべきです。 |
20.9.6. 何人かのユーザのログオンを遮断する
わたしたちの研究室には basie という、 教員専用のマシンがあります。わたしたちはこのマシンを NIS ドメインの外に出したくないのですが、 マスタ NIS サーバの passwd ファイルには教員と学生の両方が載っています。 どうしたらいいでしょう?
当該人物が NIS のデータベースに載っていても、 そのユーザがマシンにログオンできないようにする方法があります。 そうするには -username をクライアントマシンの /etc/master.passwd ファイルの末尾に付け足します。 username はあなたがログインさせたくないと思っているユーザのユーザ名です。 これは vipw で行うべきです。 vipw は /etc/master.passwd への変更をチェックし、編集終了後パスワードデータベースを再構築します。 たとえば、ユーザ bill が basie にログオンするのを防ぎたいなら、以下のようにします。
basie# vipw
[add -bill to the end, exit]
vipw: rebuilding the database...
vipw: done
basie# cat /etc/master.passwd
root:[password]:0:0::0:0:The super-user:/root:/bin/csh
toor:[password]:0:0::0:0:The other super-user:/root:/bin/sh
daemon:*:1:1::0:0:Owner of many system processes:/root:/sbin/nologin
operator:*:2:5::0:0:System &:/:/sbin/nologin
bin:*:3:7::0:0:Binaries Commands and Source,,,:/:/sbin/nologin
tty:*:4:65533::0:0:Tty Sandbox:/:/sbin/nologin
kmem:*:5:65533::0:0:KMem Sandbox:/:/sbin/nologin
games:*:7:13::0:0:Games pseudo-user:/usr/games:/sbin/nologin
news:*:8:8::0:0:News Subsystem:/:/sbin/nologin
man:*:9:9::0:0:Mister Man Pages:/usr/shared/man:/sbin/nologin
bind:*:53:53::0:0:Bind Sandbox:/:/sbin/nologin
uucp:*:66:66::0:0:UUCP pseudo-user:/var/spool/uucppublic:/usr/libexec/uucp/uucico
xten:*:67:67::0:0:X-10 daemon:/usr/local/xten:/sbin/nologin
pop:*:68:6::0:0:Post Office Owner:/nonexistent:/sbin/nologin
nobody:*:65534:65534::0:0:Unprivileged user:/nonexistent:/sbin/nologin
+:::::::::
-bill
basie#20.9.7. ネットグループの利用
前節までに見てきた手法は、 極めて少ないユーザ/マシン向けに個別のルールを必要としている場合にはうまく機能します。 しかし大きなネットワークでは、 ユーザに触られたくないマシンへログオンを防ぐのを 忘れるでしょう し、 そうでなくとも各マシンを個別に設定して回らなければならず、 集中管理という NIS の恩恵を失ってしまいます。
NIS の開発者はこの問題を ネットグループ と呼ばれる方法で解決しました。 その目的と意味合いは UNIX® のファイルシステムで使われている一般的なグループと比較できます。 主たる相違は数値 ID が存在しないことと、 ユーザアカウントと別のネットグループを含めたネットグループを定義できることです。
ネットグループは百人/台以上のユーザとマシンを含む、 大きく複雑なネットワークを扱うために開発されました。 あなたがこのような状況を扱わなければならないなら便利なものなのですが、 一方で、この複雑さは単純な例でネットグループの説明をすることをほとんど不可能にしています。 この節の残りで使われている例は、この問題を実演しています。
あなたの行なった、 研究室への NIS の導入の成功が上司の目に止ったとしましょう。 あなたの次の仕事は、あなたの NIS ドメインをキャンパスの他のいくつものマシンを覆うものへ拡張することです。 二つの表は新しいユーザと新しいマシンの名前とその説明を含んでいます。
| ユーザの名前 | 説明 |
|---|---|
alpha, beta | IT 学科の通常の職員 |
charlie, delta | IT 学科の新しい見習い |
echo, foxtrott, golf, … | 一般の職員 |
able, baker, … | まだインターン |
| マシンの名前 | 説明 |
|---|---|
war, death, famine, pollution | 最も重要なサーバ。IT 職員だけがログオンを許されます。 |
pride, greed, envy, wrath, lust, sloth | あまり重要でないサーバ。 IT 学科の全員がログオンを許されます。 |
one, two, three, four, … | 通常のワークステーション。 本当の 職員だけがログオンを許されます。 |
trashcan | 重要なデータの入っていないひどく古いマシン。 インターンでもこのマシンの使用を許されます。 |
もしあなたがこの手の制限を各ユーザを個別にブロックする形で実装するなら、 あなたはそのシステムにログオンすることが許されていない各ユーザについて -user という 1 行を、各システムの passwd に追加しなければならなくなるでしょう。 もしあなたが 1 エントリでも忘れればトラブルに巻き込まれてしまいます。 最初のセットアップの時にこれを正しく行えるのはありえることかも知れませんが、 遂には連日の業務の間に例の行を追加し忘れてしまうでしょう。 結局マーフィーは楽観主義者だったのです。
この状況をネットグループで扱うといくつかの有利な点があります。 各ユーザを別個に扱う必要はなく、 ユーザを一つ以上のネットグループに割り当て、 ネットグループの全メンバのログインを許可したり禁止したりすることができます。 新しいマシンを追加するときはネットグループへログインの制限を定義するだけ、 新しいユーザを追加するときはそのユーザを一つ以上のネットグループへ追加するだけで、 それぞれ行なうことができます。 これらの変更は互いに独立なので、 "ユーザとマシンの組合わせをどうするか" は存在しなくなります。 あなたの NIS のセットアップが注意深く計画されていれば、 マシンへのアクセスを認めるにも拒否するにも中心の設定をたった一カ所変更するだけです。
最初のステップは NIS マップネットグループの初期化です。 FreeBSD の ypinit(8) はこのマップをデフォルトで作りませんが、 その NIS の実装はそれが作られさえすればそれをサポートするものです。 空のマップを作るには、単に
ellington# vi /var/yp/netgroupとタイプして内容を追加していきます。 わたしたちの例では、すくなくとも IT 職員、IT 見習い、一般職員、 インターンの 4 つのネットグループが必要です。
IT_EMP (,alpha,test-domain) (,beta,test-domain) IT_APP (,charlie,test-domain) (,delta,test-domain) USERS (,echo,test-domain) (,foxtrott,test-domain) \ (,golf,test-domain) INTERNS (,able,test-domain) (,baker,test-domain)
IT_EMP, IT_APP 等はネットグループの名前です。 それぞれの括弧で囲まれたグループが一人以上のユーザアカウントをそれに登録しています。 グループの 3 つのフィールドは
その記述が有効なホスト (群) の名称。 ホスト名を特記しなければそのエントリはすべてのホストで有効です。 もしあなたがホスト名を特記するなら、 あなたは闇と恐怖と全き混乱の領域に入り込んでしまうでしょう。
このネットグループに所属するアカウントの名称。
そのアカウントの NIS ドメイン。 もしあなたが一つ以上の NIS ドメインの不幸な仲間なら、 あなたは他の NIS ドメインからあなたのネットグループにアカウントを導入できます。
各フィールドには、ワイルドカードが使えます。 詳細は netgroup(5) をご覧ください。
8 文字以上のネットグループ名は、特にあなたの NIS ドメインで他のオペレーティングシステムを走らせているときは使うべきではありません。 名前には大文字小文字の区別があります。 そのためネットグループ名に大文字を使う事は、 ユーザやマシン名とネットグループ名を区別する簡単な方法です。 (FreeBSD 以外の) NIS クライアントの中には 多数のエントリを扱えないものもあります。 たとえば SunOS™ の古い版では 15 以上の エントリ を含むネットグループはトラブルを起こします。 この制限は 15 ユーザ以下のサブネットグループをいくつも作り、 本当のネットグループはこのサブネットグループからなるようにすることで回避できます。 BIGGRP1 (,joe1,domain) (,joe2,domain) (,joe3,domain) [...] BIGGRP2 (,joe16,domain) (,joe17,domain) [...] BIGGRP3 (,joe31,domain) (,joe32,domain) BIGGROUP BIGGRP1 BIGGRP2 BIGGRP3 単一のネットグループに 225 人以上のユーザをいれたいときは、 このやり方を繰り返すことができます。 |
新しい NIS マップの有効化と配布は簡単です。
ellington# cd /var/yp
ellington# makeこれで新しい 3 つの NIS マップ netgroup, netgroup.byhost, netgroup.byuser ができるはずです。 新しい NIS マップが利用できるか確かめるには ypcat(1) を使います。
ellington% ypcat -k netgroup
ellington% ypcat -k netgroup.byhost
ellington% ypcat -k netgroup.byuser最初のコマンドの出力は /var/yp/netgroup の内容に似ているはずです。 2 番目のコマンドはホスト別のネットグループを作っていなければ出力されません。 3 番目のコマンドはユーザに対するネットグループのリストを得るのに使えます。
クライアント側の設定は非常に簡単です。 サーバ war を設定するには、 vipw(8) を実行して以下の行
+:::::::::
を
+@IT_EMP:::::::::
に入れ替えるだけです。
今、ネットグループ IT_EMP で定義されたユーザのデータだけが war のパスワードデータベースに読み込まれ、 そのユーザだけがログインを許されています。
残念ながらこの制限はシェルの ~ の機能や、 ユーザ名や数値の ユーザ ID の変換ルーチンにも影響します。 つまり、 cd ~user はうまく動かず、 ls -l はユーザ名のかわりに数値の ID を表示し find . -user joe -print は "No such user" で失敗します。 これを避けるためには、すべてのユーザのエントリを サーバにログインすることを許さずに 読み込まなければなりません。
これはもう一行を /etc/master.passwd に追加することで実現できます。その行は以下の
+:::::::::/sbin/nologin を含んでおり、 これは "すべてのエントリを読み込むが、読み込まれたエントリのシェルは /sbin/nologin で置き換えられる" ということを意味します。passwd エントリの他のフィールドを /etc/master.passwd の既定値から置き換えることも可能です。
|
この変更の後では、新しい職員が IT 学科に参加しても NIS マップを一つ書き換えるだけで済みます。 同様にして、あまり重要でないサーバのローカルの /etc/master.passwd のかつての +::::::::: 行を以下のように置き換えます。
+@IT_EMP::::::::: +@IT_APP::::::::: +:::::::::/sbin/nologin
この行は、一般のワークステーションでは以下のようになります。
+@IT_EMP::::::::: +@USERS::::::::: +:::::::::/sbin/nologin
これでしばらく順調に運用していましたが、 数週間後、ポリシに変更がありました。 IT 学科はインターンを雇い始め、IT インターンは一般のワークステーションと余り重要ではないサーバを使うことが許され、 IT 見習いはメインサーバへのログインが許されました。 あなたは新たなネットグループ IT_INTERN を追加して新しい IT インターンたちをそのグループに登録し、 すべてのマシンの設定を変えて回ることにしました。 古い諺にこうあります。 "集中管理における過ちは、大規模な混乱を導く"。
いくつかのネットグループから新たなネットグループを作るという NIS の機能は、このような状況に対処するために利用できます。 その方法の一つは、役割別のネットグループを作ることです。 たとえば、重要なサーバへのログイン制限を定義するために BIGSRV というネットグループを作り あまり重要ではないサーバへは SMALLSRV というネットグループを、そして一般のワークステーション用に USERBOX という第 3 のネットグループを 作ることができます。これらのネットグループの各々は、 各マシンにログインすることを許されたネットグループを含みます。 あなたの NIS マップネットグループの新しいエントリは、 以下のようになるはずです。
BIGSRV IT_EMP IT_APP SMALLSRV IT_EMP IT_APP ITINTERN USERBOX IT_EMP ITINTERN USERS
このログイン制限の定義法は、 同一の制限を持つマシンのグループを定義できるときには便利なものです。 残念ながらこのようなケースは例外的なものです。 ほとんどの場合、 各マシンに基づくログイン制限の定義機能が必要となるでしょう。
マシンごとのネットグループの定義は、 上述したようなポリシの変更を扱うことができるもうひとつの方法です。 このシナリオでは、各マシンの /etc/master.passwd は "+" で始まる 2 つの行からなります。 最初のものはそのマシンへのログインを許されたアカウントを追加するもので、 2 番目はその他のアカウントを /sbin/nologin をシェルとして追加するものです。 マシン名をすべて大文字で記述したものをネットグループの名前として使うのは良い考えです。 言い換えれば、件の行は次のようになるはずです。
+@BOXNAME::::::::: +:::::::::/sbin/nologin
一度、各マシンに対してこの作業を済ませてしまえば、 二度とローカルの /etc/master.passwd を編集する必要がなくなります。 以降のすべての変更は NIS マップの編集で扱うことができます。 以下はこのシナリオに対応するネットグループマップに、 いくつかの便利な定義を追加した例です。
# Define groups of users first IT_EMP (,alpha,test-domain) (,beta,test-domain) IT_APP (,charlie,test-domain) (,delta,test-domain) DEPT1 (,echo,test-domain) (,foxtrott,test-domain) DEPT2 (,golf,test-domain) (,hotel,test-domain) DEPT3 (,india,test-domain) (,juliet,test-domain) ITINTERN (,kilo,test-domain) (,lima,test-domain) D_INTERNS (,able,test-domain) (,baker,test-domain) # # Now, define some groups based on roles USERS DEPT1 DEPT2 DEPT3 BIGSRV IT_EMP IT_APP SMALLSRV IT_EMP IT_APP ITINTERN USERBOX IT_EMP ITINTERN USERS # # And a groups for a special tasks # Allow echo and golf to access our anti-virus-machine SECURITY IT_EMP (,echo,test-domain) (,golf,test-domain) # # machine-based netgroups # Our main servers WAR BIGSRV FAMINE BIGSRV # User india needs access to this server POLLUTION BIGSRV (,india,test-domain) # # This one is really important and needs more access restrictions DEATH IT_EMP # # The anti-virus-machine mentioned above ONE SECURITY # # Restrict a machine to a single user TWO (,hotel,test-domain) # [...more groups to follow]
もしユーザアカウントを管理するのにデータベースの類を使っているなら、 データベースのレポートツールからマップの最初の部分を作れるようにするべきです。 そうすれば、新しいユーザは自動的にマシンにアクセスできるでしょう。
最後に使用上の注意を: マシン別のネットグループを使うことが常に賢明というわけではありません。 あなたが数ダースから数百の同一の環境のマシンを学生の研究室に配置しているのならば、 NIS マップのサイズを手頃な範囲に押さえるために、 マシン別のネットグループのかわりに役割別のネットグループを使うべきです。
20.9.8. 忘れてはいけないこと
NIS 環境にある今、 今までとは違ったやり方が必要なことがいくつかあります。
研究室にユーザを追加するときは、それをマスター NIS サーバに だけ 追加しなければならず、さらに NIS マップを再構築することを忘れてはいけません。 これを忘れると新しいユーザは NIS マスタ以外のどこにもログインできなくなります。 たとえば、新しくユーザ "jsmith" をラボに登録したいときは以下のようにします。
# pw useradd jsmith # cd /var/yp # make test-domainpw useradd jsmithのかわりにadduser jsmithを使うこともできます。管理用アカウントを NIS マップから削除してください。 管理用アカウントやパスワードを、 それらのアカウントへアクセスさせてはいけないユーザが居るかも知れないマシンにまで伝えて回りたいとは思わないでしょう。
NIS のマスタとスレーブをセキュアに、 そして機能停止時間を最短に保ってください。 もし誰かがこれらのマシンをクラックしたり、 あるいは単に電源を落としたりすると、 彼らは実質的に多くの人を研究室へログインできなくしてしまえます。
これはどの集中管理システムにとってももっとも大きな弱点でしょう。 あなたの NIS サーバを守らなければ怒れるユーザと対面することになるでしょう!
20.9.9. NIS v1 との互換性
FreeBSD の ypserv は、 NIS v1 クライアントを部分的にサポートしています。 FreeBSD の NIS 実装は NIS v2 プロトコルのみを使用していますが、 ほかの実装では、古いシステムとの下位互換性を持たせるため v1 プロトコルをサポートしているものもあります。 そのようなシステムに付いている ypbind デーモンは、 必要がないにもかかわらず NIS v1 のサーバとの結合を成立させようとします (しかも v2 サーバからの応答を受信した後でも、 ブロードキャストをし続けるかも知れません)。 FreeBSD の ypserv は、 クライアントからの通常のリクエストはサポートしていますが、 v1 のマップ転送リクエストはサポートしていないことに注意してください。 つまり FreeBSD の ypserv を、 v1 だけをサポートするような古い NIS サーバと組み合わせて マスターやスレーブサーバとして使うことはできません。 幸いなことに、現在、そのようなサーバが使われていることは ほとんどないでしょう。
20.9.10. NIS クライアントとしても動作している NIS サーバ
複数のサーバが存在し、サーバ自身が NIS クライアントでもあるようなドメインで ypserv が実行される場合には注意が必要です。 一般的に良いとされているのは、 他のサーバと結合をつくるようにブロードキャストさせるのではなく、 サーバをそれ自身に結合させることです。 もし、サーバ同士が依存関係を持っていて、一つのサーバが停止すると、 奇妙なサービス不能状態に陥ることがあります。 その結果、すべてのクライアントはタイムアウトを起こして 他のサーバに結合しようと試みますが、 これにかかる時間はかなり大きく、 サーバ同士がまた互いに結合してしまったりすると、 サービス不能状態はさらに継続することになります。
ypbind に -S オプションフラグを指定して実行することで、 ホストを特定のサーバに結合することが可能です。 NIS サーバを再起動するたびに、これを手動で行いたくないなら、 次の行を /etc/rc.conf に追加すればよいでしょう。
nis_client_enable="YES" # run client stuff as well nis_client_flags="-S NIS domain,server"
詳細については ypbind(8) を参照してください。
20.9.11. パスワード形式
NIS を実装しようする人の誰もがぶつかる問題の一つに、 パスワード形式の互換性があります。 NIS サーバが DES 暗号化パスワード使っている場合には、 同様に DES を使用しているクライアントしか対応できません。 たとえば Solaris™; の NIS クライアントがネットワーク内にある場合、 ほぼ確実に DES 暗号化パスワードを使用しなければならないでしょう。
サーバとクライアントがどのライブラリを使用しているかは、 /etc/login.conf を確認してください。 ホストが DES 暗号パスワードを使用するように設定されている場合、 default クラスには以下のようなエントリが含まれます。
default:\
:passwd_format=des:\
[Further entries elided]passwd_format 特性について他に利用可能な値は blf および md5 (それぞれ Blowfish および MD5 暗号化パスワード) です。
/etc/login.conf を変更したときは、 ログイン特性データベースも再構築しなければなりません。 これは root 権限で下記のようにコマンドを実行すればできます。
# cap_mkdb /etc/login.confすでに /etc/master.passwd 内に記録されているパスワード形式は、 ログイン特性データベースが再構築された後、 ユーザが彼らのパスワードをはじめて変更するまで変更されないでしょう。 |
次に、 パスワードが選択した形式で暗号化されることを確実にするために、 さらに /etc/auth.conf 内の crypt_default において、 選択したパスワード形式に高い優先順位がついていることも確認してください。 そうするためには、選択した形式をリストの先頭に置いてください。 たとえば DES 暗号化されたパスワードを使用するときは、 エントリは次のようになります。
crypt_default = des blf md5
FreeBSD 上の各 NIS サーバおよびクライアントにおいて上記の手順に従えば、 ネットワーク内でどのパスワード形式が使用されるかが それらのマシン間で整合されているということを確信できます。 NIS クライアント上で問題があれば、 ここから問題となりそうな部分を探すと良いでしょう。 覚えておいてください: 異種混在ネットワークに NIS サーバを配置したいときには、 DES が最大公約数的な標準となるでしょうから、 すべてのシステムで DES を使用しなければならないかもしれません。
20.10. DHCP
20.10.1. DHCP とは何でしょうか?
DHCP (Dynamic Host Configuration Protocol) は、 システムをネットワークに接続するだけで、 ネットワークでの通信に必要な情報を入手することができる仕組みです。 FreeBSD では ISC (Internet Software Consortium) による DHCP の実装を使用しています。したがって、 ここでの説明のうち実装によって異なる部分は ISC のもの用になっています。
20.10.2. この節で説明していること
この節は ISC DHCP システムのクライアント側およびサーバ側の構成要素の両方について説明します。 クライアント側のプログラムである dhclient は FreeBSD のベースシステム内に含まれています。そして、サーバ側の要素は net/isc-dhcp3-server port から利用可能です。下記の説明の他に、 dhclient(8), dhcp-options(5) および dhclient.conf(5) マニュアルページが役にたつ情報源です。
20.10.3. DHCP の動作
クライアントとなるマシン上で、 DHCP のクライアントである dhclient を実行すると、 まず設定情報の要求をブロードキャストします。デフォルトでは、 このリクエストには UDP のポート 68 を使用します。 サーバは UDP のポート 67 で応答し、クライアントの IP アドレスと、 ネットマスクやルータ、DNS サーバなどの関連する情報を提供します。 これらの情報のすべては DHCP の "リース" の形で送られ、DHCP サーバ管理者によって決められたある一定の時間内でのみ有効になります。 これによって、ネットワークに存在しなくなったホストの IP アドレスは自動的に回収されることになります。
DHCP クライアントはサーバから非常に多くの情報を取得することができます。 dhcp-options(5) に非常に大きなリストが載っています。
20.10.4. FreeBSD への組み込み
FreeBSD は ISC の DHCP クライアントである dhclient を完全に組み込んでいます。 DHCP クライアントはインストーラと基本システムの両方で提供されています。 ですから DHCP サーバを走らせているネットワーク上ではネットワーク関係の設定についての詳細な知識は必要になりません。 dhclient は、3.2 以降のすべての FreeBSD の配布物に含まれています。
DHCP は sysinstall で対応されており、sysinstall でのネットワークインタフェイス設定の際は、 "このインタフェイスの設定として DHCP を試してみますか? (Do you want to try DHCP configuration of this interface?)" という質問が最初になされます。 これに同意することで dhclient が実行され、 それが成功すればネットワークの設定情報は自動的に取得されます。
システム起動時に DHCP を使ってネットワーク情報を取得するように するには、次の二つを行なう必要があります。
bpf デバイスがカーネルに組み込まれていることを確認します。 これを組み込むには、カーネルコンフィグレーションファイルに
pseudo-device bpfという行を追加し、カーネルを再構築します。 カーネルの構築に関する詳細は、 FreeBSD カーネルのコンフィグレーション を参照してください。bpf デバイスは、 FreeBSD にはじめから用意されている GENERIC カーネルに組み込まれていますので、 自分で設定を変えたカスタムカーネルを使っているのでなければ、 DHCP を動作させるためにカーネルを再構築する必要はありません。
セキュリティに関心のある方向けに注意しておきます。 bpf デバイスは、パケットスニファ (盗聴プログラム) を動作させることができる (ただし
root権限が必要) デバイスです。 bpf は DHCP を動作させるために かならず必要ですが、 セキュリティが非常に重要な場面では DHCP をいつか使うかもしれないというだけで bpf デバイスをカーネルに追加すべきではないでしょう。/etc/rc.conf を編集して、 次の行を追加してください。
ifconfig_fxp0="DHCP"
で説明されているように
fxp0の部分を、 動的に設定したいインタフェースの名前で置き換えることを忘れないようにしてください。もし、使っている
dhclientの場所を変更していたり、dhclientにフラグを渡したい場合は、 同様に下のように書き加えてください。dhcp_program="/sbin/dhclient" dhcp_flags=""
DHCP サーバ dhcpd は、Ports Collection に net/isc-dhcp3-server の一部として収録されています。 この port には ISC DHCP サーバと文書が含まれています。
20.10.5. 関連ファイル
/etc/dhclient.conf
dhclientは設定ファイル /etc/dhclient.conf を必要とします。 大抵の場合、このファイルはコメントだけであり、 デフォルトが通常使いやすい設定になっています。 この設定ファイルは dhclient.conf(5) マニュアルページで説明しています。/sbin/dhclient
dhclientは静的にリンクされており、 /sbin に置かれています。dhclient(8) マニュアルページでdhclientコマンドについてより詳しく説明しています。/sbin/dhclient-script
dhclient-scriptは FreeBSD 特有の、 DHCP クライアント設定スクリプトです。これについては dhclient-script(8) マニュアルページで説明されていますが、 これを編集する必要はほとんど発生しないでしょう。/var/db/dhclient.leases
DHCP クライアントはこのファイルに有効なリースのデータベースをログとして記録します。 dhclient.leases(5) にもうすこし詳しい解説があります。
20.10.7. DHCP サーバのインストールと設定
20.10.7.1. この節で説明していること
この節は DHCP の ISC (Internet Software Consortium) 実装を用いて FreeBSD システムを DHCP サーバとして動作させる方法の情報を提供します。
DHCP のサーバ部分は FreeBSD の一部として提供されません。 したがって、このサービスを提供するために net/isc-dhcp3-server port をインストールする必要があるでしょう。 Ports Collection を使用する情報についての詳細は アプリケーションのインストール - packages と ports を参照してください。
20.10.7.2. DHCP サーバのインストール
FreeBSD システムを DHCP サーバとして設定するために、bpf(4) デバイスがカーネルに組み込まれていることを保証する必要があります。 そうするためには、カーネルコンフィギュレーションファイルに pseudo-device bpf を追加して、 カーネルを再構築してください。 カーネルの構築に関する詳細は FreeBSD カーネルのコンフィグレーション を参照してください。
bpf デバイスは、 FreeBSD にはじめから用意されている GENERIC カーネルの一部なので、DHCP を動作させるためにカスタムカーネルを作成する必要はありません。
セキュリティを特に意識する人は、bpf bpf はパケットスニファ (盗聴プログラム) が正常に (このようなプログラムはさらに特権アクセスを必要としますが) 動作することを可能にするデバイスでもあることに注意してください。 bpf は DHCP を使用するために必要 です。 しかし、セキュリティをとても気にしているなら、 DHCP をいつか使うかもしれないというだけで bpf デバイスをカーネルに含めるべきではないでしょう。 |
次に行わねばならないのは、 net/isc-dhcp3-server port によってインストールされた dhcpd.conf のサンプルを編集することです。 デフォルトでは、これは /usr/local/etc/dhcpd.conf.sample で、 編集する前にこれを /usr/local/etc/dhcpd.conf にコピーするべきでしょう。
20.10.7.3. DHCP サーバの設定
dhcpd.conf はサブネットおよびホストに関する宣言で構成されます。 例を使って説明するのが最も簡単でしょう。
option domain-name "example.com";(1)
option domain-name-servers 192.168.4.100;(2)
option subnet-mask 255.255.255.0;(3)
default-lease-time 3600;(4)
max-lease-time 86400;(5)
ddns-update-style none;(6)
subnet 192.168.4.0 netmask 255.255.255.0 {
range 192.168.4.129 192.168.4.254;(7)
option routers 192.168.4.1;(8)
}
host mailhost {
hardware ethernet 02:03:04:05:06:07;(9)
fixed-address mailhost.example.com;(10)
}| 1 | このオプションは、 デフォルト探索ドメインとしてクライアントに渡されるドメインを指定します。 これが意味するところの詳細については resolv.conf(5) を参照してください。 |
| 2 | このオプションはクライアントが使用する、 コンマで区切られた DNS サーバのリストを指定します。 |
| 3 | クライアントに渡されるネットマスクです。 |
| 4 | クライアントは特定のリース期限を要求することもできます。 それ以外の場合は、サーバはこのリース期限値 (秒) でリースを割り当てるでしょう。 |
| 5 | これはサーバがリースする時間の最大値です。 クライアントがこれより長いリースを要求しても、 max-lease-time 秒だけしか有効にならないでしょう。 |
| 6 | このオプションは、リースが受理、またはリリースされたときに DHCP サーバが DNS を更新しようとするかどうかを指定します。 ISC 実装では、このオプションは 必須 です。 |
| 7 | これはどの範囲の IP アドレスが、 クライアントに割り当てるために予約されたプールに使用されるかを示します。 この範囲に含まれている IP アドレスはクライアントに渡されます。 |
| 8 | クライアントに供給されるデフォルトゲートウェイを宣言します。 |
| 9 | (リクエストが生じた時に DHCP サーバがホストを認識できるように) ホストのハードウェア MAC アドレスを指定します。 |
| 10 | ホストに常に同じ IP アドレスを付与することを指定します。 DHCP サーバはリース情報を返す前にホスト名の名前解決をするので、 ここにホスト名を書いても構いません。 |
dhcpd.conf を書き終えたら以下のコマンドでサーバを起動できます。
# /usr/local/etc/rc.d/isc-dhcpd.sh start今後サーバの設定に変更を加える必要が生じた時には、 SIGHUP シグナルを dhcpd に送っても、 多くのデーモンがそうであるようには、 設定ファイルが再読み込み されない ことに注意してください。 SIGTERM シグナルを送ってプロセスを停止し、 それから上記のコマンドを用いて再起動させる必要があります。
20.10.7.4. ファイル
/usr/local/sbin/dhcpd
dhcpd は静的にリンクされ /usr/local/sbin に置かれます。 dhcpd に関するそれ以上の情報は port とともにインストールされる dhcpd(8) マニュアルページにあります。
/usr/local/etc/dhcpd.conf
dhcpd はクライアントへのサービス提供をはじめる前に設定ファイル /usr/local/etc/dhcpd.conf を必要とします。このファイルは、 サーバの稼働に関する情報に加えて、 サービスされているクライアントに提供される情報のすべてを含む必要があります。 この設定ファイルについての詳細は、 port によってインストールされる dhcpd.conf(5) マニュアルページを参照してください。
/var/db/dhcpd.leases
DHCP サーバは発行したリースのデータベースをこのファイルにログとして保持します。 port によってインストールされる dhcpd.leases(5) にはもう少し詳しい説明があります。
/usr/local/sbin/dhcrelay
dhcrelay は、DHCP サーバがクライアントからのリクエストを、 別のネットワーク上にある DHCP サーバに転送する高度な環境下で使用されます。 この機能が必要なら、net/isc-dhcp3-server port をインストールしてください。 port とともに提供される dhcrelay(8) マニュアルページにはより詳細な情報が含まれます。
20.11. DNS
20.11.1. 概観
FreeBSD はデフォルトでは DNS プロトコルの最も一般的な実装である BIND (Berkeley Internet Name Domain) を使用します。DNS はホスト名を IP アドレスに、そして IP アドレスをホスト名に関連づけるプロトコルです。 たとえば www.FreeBSD.org に対する問い合わせは The FreeBSD Project の ウェブサーバの IP アドレスを受け取るでしょう。 その一方で ftp.FreeBSD.org に対する問い合わせは、 対応する FTP マシンの IP アドレスを返すでしょう。 同様に、その逆のことも可能です。 IP アドレスに対する問い合わせを行うことで、 そのホスト名を解決することができます。 DNS 検索を実行するために、 システム上でネームサーバを動作させる必要はありません。
DNS は、 個々のドメイン情報を格納およびキャッシュした、 権威のあるルートサーバおよび他の小規模なネームサーバによる多少複雑なシステムによって、 インターネット全体にわたって協調して動作します。
この文書は FreeBSD で安定版として利用されている BIND 8.x について説明します。 FreeBSD では BIND 9.x を net/bind9 port からインストールできます。
RFC1034 および RFC1035 は DNS プロトコルを定義しています。
現在のところ BIND は Internet Software Consortium (www.isc.org) によって保守されています。
20.11.2. 用語
この文書を理解するには DNS 関連の用語をいくつか理解しなければいけません。
| 用語 | 定義 |
|---|---|
正引き DNS | ホスト名から IP アドレスへの対応です。 |
オリジン (origine) | 特定のゾーンファイルによってカバーされるドメインへの参照です。 |
named, BIND, ネームサーバ | FreeBSD 内の BIND ネームサーバパッケージの一般名称です。 |
リゾルバ (resolver) | マシンがゾーン情報についてネームサーバに問い合わせるシステムプロセスです。 |
逆引き DNS | 正引き DNS の逆です。つまり IP アドレスからホスト名への対応です。 |
ルートゾーン | インターネットゾーン階層の起点です。 すべてのゾーンはルートゾーンの下に属します。 これはファイルシステムのすべてのファイルがルートディレクトリの下に属することと似ています。 |
ゾーン | 同じ権威によって管理される個々の DNS ドメイン、 DNS サブドメイン、あるいは DNS の一部分です。 |
ゾーンの例:
.はルートゾーンです。org.はルートゾーンの下のゾーンです。example.orgはorg.ゾーンの下のゾーンです。foo.example.org.はサブドメインで、example.org.の下のゾーンです。1.2.3.in-addr.arpaは 3.2.1.* の IP 空間に含まれるすべての IP アドレスを参照するゾーンです。
見て分かるように、ホスト名のより詳細な部分はその左側に現れます。 たとえば example.org. は org. より限定的です。同様に org. はルートゾーンより限定的です。 ホスト名の各部分のレイアウトはファイルシステムに非常に似ています。 たとえば /dev はルートの下であることなどです。
20.11.3. ネームサーバを実行する理由
ネームサーバは通常二つの形式があります: 権威のあるネームサーバとキャッシュネームサーバです。
権威のあるネームサーバは以下の場合に必要です。
問い合わせに対して信頼できる返答をすることで、 ある人が DNS 情報を世界に向けて発信したいとき。
example.orgといったドメインが登録されており、 その下にあるホスト名に IP アドレスを割り当てる必要があるとき。IP アドレスブロックが (IP からホスト名への) 逆引き DNS エントリを必要とするとき。
プライマリサーバがダウンしているかまたはアクセスできない場合に、 代わりに問い合わせに対してスレーブと呼ばれるバックアップネームサーバが返答しなければならないとき。
キャッシュネームサーバは以下の場合に必要です。
ローカルのネームサーバが、 外部のネームサーバに問い合わせするよりも、 キャッシュしてより速く返答できるとき。
ネットワークトラフィックの総量を減らしたいとき (DNS のトラフィックはインターネットトラフィック全体の 5% 以上を占めることが測定されています)
www.FreeBSD.org に対する問い合わせを発したとき、 リゾルバは大体の場合上流の ISP のネームサーバに問い合わせをして返答を得ます。 ローカルのキャッシュ DNS サーバがあれば、 問い合わせはキャッシュ DNS サーバによって外部に対して一度だけ発せられます。 情報がローカルに蓄えられるので、 追加の問い合わせはいずれもローカルネットワークの外側にまで確認しなくてもよくなります。
20.11.4. 動作のしくみ
FreeBSD では BIND デーモンは自明な理由から named と呼ばれます。
| ファイル | 説明 |
|---|---|
named | BIND デーモン |
| ネームデーモンコントロールプログラム |
/etc/namedb | BIND のゾーン情報が置かれるディレクトリ |
/etc/namedb/named.conf | デーモンの設定ファイル |
ゾーンファイルは通常 /etc/namedb ディレクトリ内に含まれており、ネームサーバによって処理される DNS ゾーン情報を含んでいます。
20.11.5. BIND の起動
BIND はデフォルトでインストールされているので、 すべてを設定することは比較的単純です。
named デーモンが起動時に開始されることを保証するには、 /etc/rc.conf に以下の変更をいれてください。
named_enable="YES"
デーモンを手動で起動するためには (設定をした後で)
# ndc start20.11.6. 設定ファイル
20.11.6.1. make-localhost の利用
次のコマンドが
# cd /etc/namedb
# sh make-localhostローカル逆引き DNS ゾーンファイルを /etc/namedb/localhost.rev に適切に作成することを確認してください。
20.11.6.2. /etc/namedb/named.conf
// $FreeBSD$
//
// 詳細については named(8) マニュアルページを参照してください。プライマリサーバ
// を設定するつもりなら、DNS がどのように動作するかの詳細を確実に理解してくださ
// い。単純な間違いであっても、影響をうける相手に対する接続を壊したり、無駄な
// インターネットトラフィックを大量に引き起こし得ます。
options {
directory "/etc/namedb";
// "forwarders" 節に加えて次の行を有効にすることで、ネームサーバに決して自発的
// に問い合わせを発せず、常にそのフォワーダにたいして尋ねるように強制すること
// ができます:
//
// forward only;
// あなたが上流のプロバイダ周辺の DNS サーバを利用できる場合、その IP アドレス
// をここに入力し、下記の行を有効にしてください。こうすれば、そのキャッシュの
// 恩恵にあやかることができ、インターネット全体の DNS トラフィックが減るでしょう。
/*
forwarders {
127.0.0.1;
};
*/コメントが言っている通り、上流のキャッシュの恩恵を受けるために forwarders をここで有効にすることができます。 通常の状況では、ネームサーバはインターネットの特定のネームサーバを調べて、 探している返答を見つけるまで再帰的に問い合わせを行います。 これが有効になっていれば、まず上流のネームサーバ (または 与えられたネームサーバ) に問い合わせて、 そのキャッシュを利用するでしょう。 問い合わせをする上流のネームサーバが極度に通信量が多く、 高速であった場合、これを有効にする価値があるかもしれません。
ここに |
/*
* あなたと利用したいネームサーバとの間にファイアウォールがある場合、
* 下記の quiery-source 指令を有効にする必要があるでしょう。
* 過去の BIND のバージョンは常に 53 番ポートに問い合わせをしますが、
* BIND 8.1 はデフォルトで非特権ポートを使用します。
*/
// query-source address * port 53;
/*
* 砂場内で動作させている場合、ダンプファイルのために異なる場所を指定
* しなければならないかもしれません。
*/
// dump-file "s/named_dump.db";
};
// 注意: 下記は将来のリリースで対応されるでしょう。
/*
host { any; } {
topology {
127.0.0.0/8;
};
};
*/
// セカンダリを設定することはより簡単な方法で、そのおおまかな姿が下記で説明さ
// れています。
//
// ローカルネームサーバを有効にする場合、このサーバが最初に尋ねられるように
// /etc/resolv.conf に 127.0.0.1 を入力することを忘れないでください。さらに、
// /etc/rc.conf 内で有効にすることも確認してください。
zone "." {
type hint;
file "named.root";
};
zone "0.0.127.IN-ADDR.ARPA" {
type master;
file "localhost.rev";
};
zone
"0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.IP6.INT" {
type master;
file "localhost.rev";
};
// 注意: 下記の IP アドレスを使用しないでください。これはダミーでありデモや文書
// だけを目的としたものです。
//
// セカンダリ設定の例です。少なくともあなたのドメインが属するゾーンに対するセカ
// ンダリになることは便利かもしれません。プライマリの責を負っている IP アドレス
// をネットワーク管理者に尋ねてください。
//
// 逆引き参照ゾーン (IN-ADDR.ARPA) を含めることを決して忘れないでください!
// (これは ".IN-ADDR.ARPA" を付け加えられたそれぞれの IP アドレスの最初のバイト
// の逆順です。)
//
// プライマリゾーンの設定をはじめる前に DNS および BIND がどのように動作するか
// 完全に理解してください。時々自明でない落し穴があります。それに比べるとセカン
// ダリを設定するのは単純です。
//
// 注意: 下記の例を鵜呑みにして有効にしないでください。:-) 実際の名前とアドレス
// を代わりに使用してください。
//
// 注意!!! FreeBSD は bind を砂場のなかで動かします (rc.conf 内の named_flags
// を参照してください)。セカンダリゾーンを含んだディレクトリは、bind によって
// 書き込み可能でなければなりません。次の手順が推奨されます:
//
// mkdir /etc/namedb/s
// chown bind:bind /etc/namedb/s
// chmod 750 /etc/namedb/sBIND を砂場 (sandbox) で (訳注: chroot をもちいて) 動作させるための詳細は 砂場で named を実行する を参照してください。
/*
zone "example.com" {
type slave;
file "s/example.com.bak";
masters {
192.168.1.1;
};
};
zone "0.168.192.in-addr.arpa" {
type slave;
file "s/0.168.192.in-addr.arpa.bak";
masters {
192.168.1.1;
};
};
*/named.conf の中で、 上記は転送と逆引きゾーンのためのスレーブエントリの例です。
新しくサービスするそれぞれのゾーンについて、新規のエントリを named.conf に加えなければいけません。
たとえば example.org に対する最もシンプルなゾーンエントリは以下のようになります。
zone "example.org" {
type master;
file "example.org";
};このゾーンは type 命令で示されているようにマスタで、ゾーン情報を file 命令で指示された /etc/namedb/example.org ファイルに保持しています。
zone "example.org" {
type slave;
file "example.org";
};スレーブの場合、 ゾーン情報は特定のゾーンのマスタネームサーバから転送され、 指定されたファイルに保存されます。 マスタサーバが停止するか到達できない場合には、 スレーブサーバが転送されたゾーン情報を保持していて、 サービスできるでしょう。
20.11.6.3. ゾーンファイル
example.org に対するマスタゾーンファイル (/etc/namedb/example.org に保持されます) の例は以下のようになります。
$TTL 3600
example.org. IN SOA ns1.example.org. admin.example.org. (
5 ; Serial
10800 ; Refresh
3600 ; Retry
604800 ; Expire
86400 ) ; Minimum TTL
; DNS Servers
@ IN NS ns1.example.org.
@ IN NS ns2.example.org.
; Machine Names
localhost IN A 127.0.0.1
ns1 IN A 3.2.1.2
ns2 IN A 3.2.1.3
mail IN A 3.2.1.10
@ IN A 3.2.1.30
; Aliases
www IN CNAME @
; MX Record
@ IN MX 10 mail.example.org."." が最後についているすべてのホスト名は正確なホスト名であり、 一方で "." で終了しないすべての行はオリジンが参照されることに注意してください。 たとえば www は www + オリジン に展開されます。この架空のゾーンファイルでは、 オリジンは example.org. なので www は www.example.org. に展開されます。
ゾーンファイルの書式は次のとおりです。
recordname IN recordtype value
DNS レコードに使われる最も一般的なものは以下のとおりです。
- SOA
ゾーン権威の起点
- NS
権威のあるネームサーバ
- A
ホストのアドレス
- CNAME
別名としての正規の名称
- MX
メールエクスチェンジャ
- PTR
ドメインネームポインタ (逆引き DNS で使用されます)
example.org. IN SOA ns1.example.org. admin.example.org. (
5 ; Serial
10800 ; Refresh after 3 hours
3600 ; Retry after 1 hour
604800 ; Expire after 1 week
86400 ) ; Minimum TTL of 1 dayexample.org.このゾーンのオリジンでもあるドメイン名
ns1.example.org.このゾーンに対して権威のあるプライマリネームサーバ
admin.example.org.このゾーンの責任者。@ を置き換えた電子メールアドレスを指定します。 (admin@example.org は
admin.example.orgになります)5ファイルのシリアル番号です。 これはファイルが変更されるたびに増加させる必要があります。 現在では多くの管理者は
yyyymmddrrという形式をシリアル番号として使用することを好みます。 2001041002 は最後に修正されたのが 2001/04/10 で、後ろの 02 はその日で二回目に修正されたものであるということを意味するでしょう。 シリアル番号は、 それが更新されたときにスレーブネームサーバに対してゾーンを通知するので重要です。
@ IN NS ns1.example.org.
これは NS エントリです。 このゾーンに対して権威のある返答を返すネームサーバはすべて、 このエントリを一つ有していなければなりません。 ここにある @ は example.org. を意味します。 @ はオリジンに展開されます。
localhost IN A 127.0.0.1 ns1 IN A 3.2.1.2 ns2 IN A 3.2.1.3 mail IN A 3.2.1.10 @ IN A 3.2.1.30
A レコードはマシン名を示します。 上記のように ns1.example.org は 3.2.1.2 に結びつけられるでしょう。 ふたたびオリジンを示す @ がここに使用されていますが、これは example.org が 3.2.1.30 に結び付けられることを意味しています。
www IN CNAME @
CNAME レコードは通常マシンに別名を与えるときに使用されます。 例では www はオリジン、すなわち example.org (3.2.1.30) のアドレスをふられたマシンへの別名を与えます。 CNAME はホスト名の別名、 または複数のマシン間で一つのホスト名をラウンドロビン (訳注: 問い合わせがあるたびに別の IP アドレスを返すことで、 一台にアクセスが集中することを防ぐ手法) するときに用いられます。
@ IN MX 10 mail.example.org.
MX レコードは、 ゾーンに対してどのメールサーバがやってきたメールを扱うことに責任を持っているかを示します。 mail.example.org はメールサーバのホスト名で、10 はメールサーバの優先度を示します。
優先度が 3,2 または 1 などのメールサーバをいくつも置くことができます。 example.org へ送ろうとしているメールサーバははじめに一番優先度の高いメールサーバに接続しようとします。 そして接続できない場合、二番目に優先度の高いサーバに接続しようとし、 以下、メールが適切に配送されるまで同様に繰り返します。
in-addr.arpa ゾーンファイル (逆引き DNS) に対しても A または CNAME の代わりに PTR エントリが用いられることを除けば、 同じ書式が使われます。
$TTL 3600
1.2.3.in-addr.arpa. IN SOA ns1.example.org. admin.example.org. (
5 ; Serial
10800 ; Refresh
3600 ; Retry
604800 ; Expire
3600 ) ; Minimum
@ IN NS ns1.example.org.
@ IN NS ns2.example.org.
2 IN PTR ns1.example.org.
3 IN PTR ns2.example.org.
10 IN PTR mail.example.org.
30 IN PTR example.org.このファイルは上記の架空のドメインの IP アドレスからホスト名への対応を与えます。
20.11.7. キャッシュネームサーバ
キャッシュネームサーバはどのゾーンに対しても権威をもたないネームサーバです。 キャッシュネームサーバは単に自分で問い合わせをし、 後で使えるように問い合わせの結果を覚えておきます。 これを設定するには、ゾーンを何も含まずに、 通常通りネームサーバを設定してください。
20.11.8. 砂場で named を実行する
セキュリティを強めるために named(8) を非特権ユーザで実行し、 砂場のディレクトリ内に chroot(8) して実行したいと思うかもしれません。 こうすると named デーモンは砂場の外にはまったく手を出すことができません。 named が乗っ取られたとしても、 これによって起こりうる損害が小さくなるでしょう。 FreeBSD にはデフォルトで、そのための bind というユーザとグループがあります。
多くの人々は named を |
named は砂場の外 (共有ライブラリ、ログソケットなど) にアクセスできないので、 named を正しく動作させるためにいくつもの段階を経る必要があります。 下記のチェックリストにおいては、砂場のパスは /etc/namedb で、 このディレクトリの内容には何も手を加えていないと仮定します。 root 権限で次のステップを実行してください。
named が存在することを期待しているディレクトリをすべて作成します。
# cd /etc/namedb # mkdir -p bin dev etc var/tmp var/run master slave # chown bind:bind slave var/* (1)1 これらのディレクトリに対して named が必要なのは書き込み権限だけなので、それだけを与えます。 基本ゾーンファイルと設定ファイルの編集と作成を行います。
# cp /etc/localtime etc (1) # mv named.conf etc && ln -sf etc/named.conf # mv named.root master # sh make-localhost && mv localhost.rev localhost-v6.rev master # cat > master/named.localhost $ORIGIN localhost. $TTL 6h @ IN SOA localhost. postmaster.localhost. ( 1 ; serial 3600 ; refresh 1800 ; retry 604800 ; expiration 3600 ) ; minimum IN NS localhost. IN A 127.0.0.1 ^D1 これは named が syslogd(8) に正しい時刻でログを書き込むことを可能にします。 4.9-RELEASE より前のバージョンの FreeBSD を使用している場合、 静的リンクされた named-xfer を構築し、砂場にコピーしてください。
# cd /usr/src/lib/libisc # make cleandir && make cleandir && make depend && make all # cd /usr/src/lib/libbind # make cleandir && make cleandir && make depend && make all # cd /usr/src/libexec/named-xfer # make cleandir && make cleandir && make depend && make NOSHARED=yes all # cp named-xfer /etc/namedb/bin && chmod 555 /etc/namedb/bin/named-xfer(1)静的リンクされた
named-xferをインストールしたら、 ソースツリーの中にライブラリまたはプログラムの古くなったコピーを残さないように、 掃除する必要があります。# cd /usr/src/lib/libisc # make cleandir # cd /usr/src/lib/libbind # make cleandir # cd /usr/src/libexec/named-xfer # make cleandir1 このステップは時々失敗することが報告されています。 もし失敗した場合、次のコマンドを実行してください。そして /usr/obj ツリーを削除します。これはソースツリーからすべての "がらくた" を一掃します。 もう一度上記の手順を行うと、今度はうまく動作するでしょう。 バージョン 4.9-RELEASE 以降の FreeBSD を使用している場合 /usr/libexec にある
named-xferのコピーはデフォルトで静的リンクされています。 砂場にコピーするために単純に cp(1) が使えます。named が見ることができ、 書き込むことのできる dev/null を作成します。
# cd /etc/namedb/dev && mknod null c 2 2 # chmod 666 null/etc/namedb/var/run/ndc から /var/run/ndc へのシンボリックリンクを作成します。
# ln -sf /etc/namedb/var/run/ndc /var/run/ndcこれは単に ndc(8) を実行するたびに
-cオプションを指定しなくてもよいようにするだけです。 /var/run の中身は起動時に削除されるため、 これが有用だと思うなら、このコマンドをルートの crontab に@rebootオプションを指定して追加してください。 詳細については crontab(5) を参照してください。named が書き込める追加の log ソケットを作成するように syslogd(8) を設定します。 これを行うためには、/etc/rc.conf 内の
syslogd_flags変数に-l /etc/namedb/dev/logを加えてください。次の行を /etc/rc.conf に加えて named が起動し、 自身を砂場内に
chrootするように調整しますnamed_enable="YES" named_flags="-u bind -g bind -t /etc/namedb /etc/named.conf"
設定ファイル /etc/named.conf は 砂場のディレクトリに対して相対的な フルパスで表されることに注意してください。 つまり、上記の行で示されたファイルは実際には /etc/namedb/etc/named.conf です。
次のステップは named がどのゾーンを読み込むか、 そしてディスク上のどこにゾーンファイルがあるのかを知るために /etc/namedb/etc/named.conf を編集することです。 下記に例をコメントを加えて示します (ここで特にコメントされていない内容については、 砂場の中で動作させない DNS サーバの設定と同じです)。
options {
directory "/";(1)
named-xfer "/bin/named-xfer";(2)
version ""; // Don't reveal BIND version
query-source address * port 53;
};
// ndc control socket
controls {
unix "/var/run/ndc" perm 0600 owner 0 group 0;
};
// Zones follow:
zone "localhost" IN {
type master;
file "master/named.localhost";(3)
allow-transfer { localhost; };
notify no;
};
zone "0.0.127.in-addr.arpa" IN {
type master;
file "master/localhost.rev";
allow-transfer { localhost; };
notify no;
};
zone "0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.ip6.int" {
type master;
file "master/localhost-v6.rev";
allow-transfer { localhost; };
notify no;
};
zone "." IN {
type hint;
file "master/named.root";
};
zone "private.example.net" in {
type master;
file "master/private.example.net.db";
allow-transfer { 192.168.10.0/24; };
};
zone "10.168.192.in-addr.arpa" in {
type slave;
masters { 192.168.10.2; };
file "slave/192.168.10.db";(4)
};| 1 | directory は / を指定します。 named が必要とするファイルはすべてこのディレクトリにあります。 (この指定は "通常の" (訳注: 砂場内で動作させない) ユーザにとっての /etc/namedb と等価です)。 |
| 2 | named-xfer バイナリへの (named にとっての) フルパスを指定します。 named はデフォルトで named-xfer を /usr/libexec から探すようにコンパイルされているので、これが必要です |
| 3 | このゾーンに対するゾーンファイルを named が見つけられるようにファイル名を (上記と同様に directory からの相対パスで) 指定します。 |
| 4 | このゾーンに対するゾーン情報がマスタサーバからが転送されたあとに、 named がゾーンファイルのコピーを書き込むファイル名を (上記と同様に directory からの相対パスで) 指定します。これが、上記のように設定段階で slave ディレクトリの所有者を bind に変更する理由です。 |
上記のステップを完了したら、サーバを再起動するか syslogd(8) を再起動し、named(8) を起動してください。その際、 syslogd_flags および named_flags に新たに指定したオプションが有効になっていることを確かめてください。 これで named を砂場のなかで動作させることができているはずです!
20.11.9. セキュリティ
BIND は DNS の最も一般的な実装ではありますが、 常にセキュリティ問題を抱えています。 問題になり得る、また悪用可能なセキュリティホールが時々みつかります。
現在のインターネットおよび FreeBSD のセキュリティ問題について常に最新の情報を得るために CERT および freebsd-security-notifications を購読するとよいでしょう。
問題が生じたとしても、 最新のソースからビルドした named を用意しておけば、 問題にならないかもしれません。 |
20.11.10. さらなる情報源
BIND/named のマニュアルページ: ndc(8) named(8) named.conf(8)
20.12. NTP
20.12.1. 概説
時間の経過とともに、コンピュータの時計はずれてしまいがちです。 時間が経つと、コンピュータの時計は正確でなくなってゆきます。 NTP (Network Time Protocol) は時計が正確であることを保証する方法の一つです。
インターネットサービスの多くは、 コンピュータの時計が正確であることに依存しているか、 あるいは多くを負っています。 たとえば web サーバ は、 あるファイルがある時刻以降に修正されていたらそのファイルを送ってほしいという要求を受け取るかもしれません。 cron(8) のようなサービスは所定の時間にコマンドを実行します。 時計が正確でない場合、 これらのコマンドは期待したとおりには実行されないかもしれません。
FreeBSD は ntpd(8) NTP サーバを搭載しています。これは、 マシンの時計を合わせるために他の NTP サーバに問い合わせをしたり、 他のマシンに対して時刻を報じるために使用できます。
20.12.2. 適切な NTP サーバの選択
時刻を同期するために利用する NTP サーバを、 一つ以上見つける必要があります。 ネットワーク管理者、または ISP はこの目的のために NTP サーバを設定しているかもしれません - 本当にそうなのか確かめるためにドキュメントを確認してください。 あなたの近くの NTP サーバを探せる 公にアクセス可能な NTP サーバのリスト があります。 どのサーバを選択するとしても、そのサーバの運営ポリシを理解し、 要求されているなら利用許可を求めることを忘れないでください。
使用しているサーバのうちのどれかが到達不能になるか、 その時計の信頼性が低い場合、無関係の NTP サーバをいくつか選択するとよいでしょう。 ntpd(8) は他のサーバから受け取った応答を賢く利用します - 信頼できないサーバより信頼できるサーバを重視します。
20.12.3. マシンの設定
20.12.3.1. 基本設定
マシンが起動するときだけ時計を同期させたい場合は ntpdate(8) が使えます。頻繁に再起動され、 たまに同期すれば十分なデスクトップマシンには適切かもしれません。 しかしほとんどのマシンでは ntpd(8) を実行するべきです。
ntpd(8) を動かしているマシンでも、起動時に ntpdate(8) を使用するのはよい考えです。 ntpd(8) プログラムは時計を徐々に変更します。しかし ntpdate(8) は正しい時刻と現在設定されているマシンの時刻がどんなに離れていようとも時計を設定します。
起動時に ntpdate(8) を有効にするためには、 ntpdate_enable="YES" を /etc/rc.conf に追加してください。 さらに、同期したいすべてのサーバおよび、ntpdate(8) に渡すあらゆるフラグを ntpdate_flags に指定する必要があるでしょう。
20.12.3.2. 一般設定
NTP は ntp.conf(5) に記述された書式の /etc/ntp.conf ファイルによって設定されます。 簡単な例を以下に示します。
server ntplocal.example.com prefer server timeserver.example.org server ntp2a.example.net driftfile /var/db/ntp.drift
server オプションは、 使用するサーバを一行に一つずつ指定します。サーバが上記の ntplocal.example.com のように prefer 引数とともに指定された場合、 このサーバは他のサーバより優先されます。 優先されたサーバからの応答は、 他のサーバの応答と著しく異なる場合は破棄されますが、 そうでなければ他の応答を考慮することなく使用されます。 prefer 引数は、通常、 特別な時間モニタハードウェアを備えているような非常に正確であるとされている NTP サーバに対して使用されます。
driftfile オプションはシステム時計の周波数オフセットを格納するために使用するファイルを指定します。 ntpd(8) プログラムは、 時計の自然変動を自動的に補正するためにこれを用います。 これにより、一定時間外部の時刻ソースから切り離されたとしても、 十分正確な時刻を維持することを可能にします。
driftfile オプションは、使用している NTP サーバから過去に受け取った応答に関する情報を格納するために、 どのファイルが使用されるか指定します。 このファイルは NTP に関する内部情報を含んでいます。 これは他のプロセスによって修正されてはいけません。
20.12.3.3. サーバへのアクセス制御
デフォルトでは NTP サーバはインターネット上のすべてのホストからアクセスが可能です。 /etc/ntp.conf 内で restrict オプションを指定することによって、 どのマシンがサーバにアクセスできるかを制御できるようにします。
NTP サーバにアクセスするマシンのすべてを拒否したいのなら、 以下の行を /etc/ntp.conf に追加してください。
restrict default ignore
あなたのネットワーク内のマシンにだけサーバに接続して時計を同期することを認めたいが、 それらからサーバに対して設定を行うのを許さず、 同期する端末としても利用されないようにしたいのなら、 以下を加えてください。
restrict 192.168.1.0 mask 255.255.255.0 notrust nomodify notrap
192.168.1.0 をあなたのネットワークの IP アドレスに 255.255.255.0 をあなたのネットワークのネットマスクに置き換えてください。
/etc/ntp.conf には複数の restrict オプションを置けます。 詳細に付いては ntp.conf(5) の Access Control Support サブセクションを参照してください。
20.12.4. NTP サーバの実行
NTP サーバが起動時に実行されることを保証するために、 xntpd_enable="YES" を /etc/rc.conf に加えてください。 ntpd(8) にフラグを追加したい場合は /etc/rc.conf 内の xntpd_flags パラメータを編集してください。
マシンを再起動することなくサーバを実行したいときは、 /etc/rc.conf 内の xntpd_flags で追加されたパラメータをすべて指定して ntpd を実行してください。以下に例を示します。
# ntpd -p /var/run/ntpd.pidFreeBSD 5.X では /etc/rc.conf 内のさまざまなオプションの名前が変わりました。 したがって、上記の |
20.12.5. 一時的なインターネット接続で ntpd を使用する
ntpd(8) プログラムは正しく機能するために、 インターネットへの常時接続を必要としません。しかしながら、 オンデマンドでダイアルアップされるように設定された一時的な接続の場合、 NTP トラフィックがダイアルを引き起こしたり、 接続を維持し続けるようなことを避けるようにした方がよいでしょう。 ユーザ PPP を使用している場合、以下の例のように /etc/ppp/ppp.conf 内で filter ディレクティブが使用できます。
set filter dial 0 deny udp src eq 123 # Prevent NTP traffic from initiating dial out set filter dial 1 permit 0 0 set filter alive 0 deny udp src eq 123 # Prevent incoming NTP traffic from keeping the connection open set filter alive 1 deny udp dst eq 123 # Prevent outgoing NTP traffic from keeping the connection open set filter alive 2 permit 0/0 0/0
詳細については ppp(8) 内の PACKET FILTERING セクション、および /usr/shared/examples/ppp/ 内の例を参照してください。
小さい番号のポートをブロックするインターネットアクセスプロバイダでは、 応答があなたのマシンに到達しないので NTP がきちんと動作しない場合もあります。 |
20.13. ネットワークアドレス変換 (NAT)
20.13.1. 概要
一般に natd(8) として知られている FreeBSD ネットワークアドレス変換デーモンは、 raw IP パケットを受信して、 ソースアドレスをローカルマシンに変更し、 そのパケットを外向きの IP パケットの流れに再注入するデーモンです。 natd(8) は、 データが戻ってきたときに、データの本来の場所を判別し、 もともと要求した相手へデータを返すことができるようにソース IP アドレスとポートを変更します。
NAT の最も一般的な使用法は、 一般的にはインターネット接続共有として知られているものを実行することです。
20.13.2. 設定
IPv4 の IP 空間が足りなくなりつつあること、および、 ケーブルや DSL のような高速の加入者回線利用者の増加によって、 人々はますますインターネット接続を共有する手段を必要としています。 一つの接続および IP アドレスを通していくつものコンピュータを回線に接続する能力がある natd(8) が合理的な選択になります。
もっともよくあるのは、ユーザが 1 つの IP アドレスでケーブルまたは DSL 回線に接続されたマシンを持っており、 インターネットへのアクセスを LAN 経由でいくつかのコンピュータに提供するのに、 この接続されたコンピュータを使用したいという場合です。
そのためには、インターネットに接続されている FreeBSD マシンはゲートウェイとして動作しなければなりません。 このゲートウェイマシンは 2 つの NIC が必要です (1 つはインターネットルータへ接続するためで、もう 1 つは LAN に接続するためです)。 LAN 上のすべてのマシンはハブまたはスイッチを通して接続されます。
インターネット接続を共有するために、 このような設定がよく使用されています。 LAN 内のマシンの 1 台がインターネットに接続しています。 残りのマシンはその "ゲートウェイ" マシンを通してインターネットにアクセスします。
20.13.3. 設定
次のオプションがカーネルコンフィギュレーションファイルに必要です。
options IPFIREWALL options IPDIVERT
さらに、次のオプションを入れてもよいでしょう。
options IPFIREWALL_DEFAULT_TO_ACCEPT options IPFIREWALL_VERBOSE
下記の設定を /etc/rc.conf で行わなければなりません。
gateway_enable="YES" firewall_enable="YES" firewall_type="OPEN" natd_enable="YES" natd_interface="fxp0" natd_flags=""
gateway_enable="YES" | マシンがゲートウェイとして動作するように設定します。 |
firewall_enable="YES" | /etc/rc.firewall にあるファイアウォールルールを起動時に有効にします。 |
firewall_type="OPEN" | これはあらかじめ定義されている、 すべてのパケットを通すファイアウォールルールセットを指定します。 他のタイプについては /etc/rc.firewall を参照してください。 |
natd_interface="fxp0" | パケットを転送するインタフェースを指定します (インターネットに接続されたインタフェース)。 |
natd_flags="" | 起動時に natd(8) に渡される追加の引数 |
/etc/rc.conf に前述したオプションを定義すると、起動時に natd -interface fxp0 が実行されます。 これは手動でも実行できます。
オプションの定義に natd(8) のコンフィグレーションファイルを使うこともできます。 この場合には、/etc/rc.conf に以下の行を追加し、 コンフィグレーションファイルを定義してください。 natd_flags="-f /etc/natd.conf" /etc/natd.conf ファイルでは、一行ごとにオプションを設定します。たとえば、 次節の例では以下のような行を含むファイルを用意してください。 redirect_port tcp 192.168.0.2:6667 6667 redirect_port tcp 192.168.0.3:80 80 コンフィグレーションファイルに関する、より詳細な情報については、 natd(8) マニュアルページの |
LAN にぶら下がっているマシンおよびインタフェースのそれぞれには RFC 1918 で定義されているプライベートネットワーク空間の IP アドレス番号を割り当て、デフォルトゲートウェイアドレスを natd マシンの内側の IP アドレスにすべきです。
たとえば LAN 側のクライアント A および B は IP アドレス 192.168.0.2 および 192.168.0.3 を割り当てられており、 natd マシンの LAN インタフェースは IP アドレス 192.168.0.1 を割り当てられています。 クライアント A および B のデフォルトゲートウェイは natd マシンの 192.168.0.1 に設定されなければなりません。 natd マシンの外部、 またはインターネットインタフェースは natd(8) の動作に際して特別の修正を必要としません。
20.13.4. ポート転送
natd(8) の短所は、インターネットから LAN 内のクライアントにアクセスできないということです。 LAN 内のクライアントは外部に向けて接続を行うことはできますが、 入って来るものを受け取ることができません。これは、LAN クライアントのどれかでインターネットサービスを動かそうとした場合に、 問題になります。これを何とかする単純な方法は natd マシンから LAN クライアントへ、 選択したインターネットポートを転送することです。
たとえばクライアント A で実行されている IRC サーバがあり、 クライアント B 上で実行されている web サーバがあるとします。 これが正しく動作するには、ポート 6667 (IRC) および 80 (web) への接続を対応するマシンに転送しなければなりません。
-redirect_port に適切なオプションを加えて natd(8) に渡さなければなりません。 書式は以下のとおりです。
-redirect_port proto targetIP:targetPORT[-targetPORT]
[aliasIP:]aliasPORT[-aliasPORT]
[remoteIP[:remotePORT[-remotePORT]]]上記の例では、引数は以下のようにします。
-redirect_port tcp 192.168.0.2:6667 6667
-redirect_port tcp 192.168.0.3:80 80これで適切な tcp ポートが LAN クライアントマシンに転送されます。
-redirect_port 引数は個々のポートを対応させるポート範囲を示すのに使えます。 たとえば tcp 192.168.0.2:2000-3000 2000-3000 は 2000 番から 3000番ポートに受け取られたすべての接続を、 クライアント A 上の 2000 番から 3000 番に転送します。
これらのオプションは natd(8) を直接実行するか、 /etc/rc.conf 内の natd_flags="" オプションで設定するか、 もしくはコンフィグレーションファイルから渡してください。
設定オプションの詳細については natd(8) をご覧ください。
20.13.5. アドレス転送
複数の IP アドレスが利用可能ですが、 それらが 1 台のマシン上になければならないときには、 アドレス転送が便利です。 これを用いれば natd(8) は LAN クライアントのそれぞれに外部 IP アドレスを割り当てることができます。 natd(8) は LAN クライアントから外部へ出て行くパケットを適切な外部の IP アドレスで書き直し、 そして特定の IP アドレスに対してやって来るトラフィックのすべてを、 指定された LAN クライアントに転送します。 これは静的 NAT としても知られています。 たとえば 128.1.1.1, 128.1.1.2 および 128.1.1.3 の IP アドレスが、 natd ゲートウェイマシンに属しているとします。 128.1.1.2 および 128.1.1.3 は LAN クライアントの A および B に転送される一方で、128.1.1.1 は natd ゲートウェイマシンの外部 IP アドレスとして使用することができます。
-redirect_address の書式は以下のとおりです。
-redirect_address localIP publicIP
localIP | LAN クライアントの内部 IP アドレス |
publicIP | LAN クライアントに対応する外部 IP アドレス |
上記の例では引数は以下のようになります。
-redirect_address 192.168.0.2 128.1.1.2 -redirect_address 192.168.0.3 128.1.1.3
-redirect_port と同様に、これらの引数は /etc/rc.conf 内の natd_flags="" オプションで設定するか、 コンフィグレーションファイルから渡すことで指定できます。 アドレス転送では、 特定の IP アドレスで受け取られたデータはすべて転送されるので、 port 転送は必要ありません。
natd マシン上の外部 IP アドレスは、 アクティブで外部インタフェースにエイリアスされていなければなりません。 やりかたは rc.conf(5) を参照してください。
20.14. inetd"スーパサーバ"
20.14.1. 概観
inetd(8) は複数のデーモンに対する接続を制御するので、 "インターネットスーパサーバ" と呼ばれます。 ネットワークサービスを提供するプログラムは、 一般的にデーモン呼ばれます。inetd は他のデーモンを管理するサーバを努めます。 接続が inetd によって受け付けられると、 inetd は接続がどのデーモンに対するものか判断して、 そのデーモンを起動し、ソケットを渡します。 inetd を 1 つ実行することにより、 それぞれのデーモンをスタンドアロンモードで実行することに比べ、 全体としてのシステム負荷を減らします。
基本的に、inetd は他のデーモンを起動するために使用されます。しかし、 chargen, auth および daytime のようなささいなプロトコルは直接扱われます。
この節ではコマンドラインオプションおよび設定ファイル /etc/inetd.conf による inetd の設定の基本を説明します。
20.14.2. 設定
inetd は /etc/rc.conf の仕組によって初期化されます。 デフォルトでは inetd_enable オプションは "NO" に設定されています。 しかし多くの場合、sysinstall でセキュリティプロファイルを medium に設定することにより、有効化されます。
inetd_enable="YES"
または
inetd_enable="NO"
を /etc/rc.conf に置くことで、起動時に inetd を有効または無効にできます。
さらに inetd_flags オプションによって、 いろいろなコマンドラインオプションを inetd に渡すことができます。
20.14.3. コマンドラインオプション
inetd 書式
inetd [-d] [-l] [-w] [-W] [-c maximum] [-C rate] [-a address | hostname] [-p filename] [-R rate] [configuration file]
- -d
デバッグモードにします。
- -l
成功した接続のログをとります。
- -w
外部サービスに対して TCP Wrapper を有効にします (デフォルト)。
- -W
inetd 組み込みの内部サービスに対して TCP Wrapper を有効にします (デフォルト)。
- -c maximum
サービス毎に同時に起動可能な最大値のデフォルトを指定します。 デフォルトでは無制限です。サービスごとに指定する
max-childパラメータで上書きできます。- -C rate
1 分間にひとつの IP アドレスから起動されるサービスの、 最大値のデフォルトを指定します。デフォルトは無制限です。 サービスごとに指定する
max-connections-per-ip-per-minuteパラメータで上書きできます。- -R rate
あるサービスを 1 分間に起動できる最大の数を指定します。 デフォルトは 256 です。rate に 0 を指定すると、 起動可能な数は無制限になります。
- -a
バインドする IP アドレスを一つ指定します。 代わりにホスト名も指定できます。この場合、ホスト名に対応する IPv4 または IPv6 アドレスが使用されます。通常 inetd が jail(8) 内で起動される時点で、ホスト名が指定されます。この場合、 ホスト名は jail(8) 環境に対応するものです。
ホスト名指定が使用され、 IPv4 および IPv6 両方にバインドしたい場合、 /etc/inetd.conf の各サービスに対して、 各バインドに対する適切なプロトコルのエントリが必要です。 たとえば TCP ベースのサービスは、 ひとつはプロトコルに "tcp4" を使用し、 もう一つは "tcp6" を使用する、 2 つのエントリが必要です。
- -p
デフォルトとは異なる PID を保持するファイルを指定します。
/etc/rc.conf 内の inetd_flags オプションを用いて、これらのオプションを inetd に渡すことができます。デフォルトでは inetd_flags は "-wW" に設定されており、 これは inetd の内部および外部サービスに対して TCP wrapper を有効にします。 初心者ユーザはこれらのパラメータを変更する必要は通常ありませんし、 /etc/rc.conf に入力する必要もありません。
外部サービスは、接続を受け取ったときに起動される inetd の外部にあるデーモンで、 それに対して、内部サービスは inetd 自身が提供する内部のデーモンです。 |
20.14.4. inetd.conf
inetd の設定は /etc/inetd.conf ファイルによって制御されます。
/etc/inetd.conf が変更されたときは、 以下のように inetd プロセスに HangUP シグナルを送ることにより、inetd に設定ファイルを再読み込みさせられます。
例 4. inetd への HangUP シグナル送付
# kill -HUP `cat /var/run/inetd.pid`設定ファイルのそれぞれの行は、 個々のデーモンについての指示になります。 ファイル内のコメントは "#" が先頭につきます。 /etc/inetd.conf の書式は以下のとおりです。
service-name
socket-type
protocol
{wait|nowait}[/max-child[/max-connections-per-ip-per-minute]]
user[:group][/login-class]
server-program
server-program-argumentsIPv4 を利用する ftpd デーモンのエントリの例です。
ftp stream tcp nowait root /usr/libexec/ftpd ftpd -l
- service-name
これは特定のデーモンのサービス名です。 これは /etc/services 内のサービスリストに対応していなければなりません。 これは inetd がどのポートで受け付けなければならないかを決定します。 新しいサービスが作成された場合、まずはじめに /etc/services 内に記載しなければなりません。
- socket-type
stream,dgram,rawまたはseqpacketのどれかを指定します。streamはコネクションに基づいた TCP デーモンに使用しなければならず、 一方でdgramは UDP 転送プロトコルを利用したデーモンに対して使用されます。- protocol
次のうちのどれか 1 つを指定します。
プロトコル 説明 tcp, tcp4
TCP IPv4
udp, udp4
UDP IPv4
tcp6
TCP IPv6
udp6
UDP IPv6
tcp46
TCP IPv4 および v6 の両方
udp46
UDP IPv4 および v6 の両方
- {wait|nowait}[/max-child[/max-connections-per-ip-per-minute]]
wait|nowaitは inetd から起動したデーモンが、 自分のソケットを管理できるかどうかを示します。 通常マルチスレッド化されている stream ソケットデーモンはnowaitを使用するべきである一方、dgramソケットタイプは wait オプションを使用しなければなりません。nowaitは新しいソケット毎に子のデーモンを起動する一方で、waitは通常複数のソケットを 1 つのデーモンに渡します。inetd が起動できる子のデーモンの最大数は
max-childオプションで設定できます。 特定のデーモンに対して、起動する数が 10 までという制限が必要な場合、nowaitの後に/10を置きます。max-childに加えて、他にある 1 つの場所から特定のデーモンへの最大接続数を制限するオプションが利用できます。max-connections-per-ip-per-minuteがそれです。ここに 10 を指定すると、特定の IP アドレスからの特定のサービスへの接続を 1 分間につき 10 回に制限します。 これは故意または故意でない資源の浪費および、 マシンへのサービス不能 (DoS) 攻撃を防ぐのに有用です。waitまたはnowaitはこの欄に必ず必要です。max-childおよびmax-connections-per-ip-per-minuteは任意です。max-childまたはmax-connections-per-ip-per-minute制限をかけない stream タイプのマルチスレッドデーモンの設定はnowaitになります。作成できる子プロセスの上限が 10 である同じデーモンの設定は
nowait/10になります。さらに、 1 分間に IP アドレスあたりの接続制限が 20、 子プロセスの上限が 10 である同じデーモンの設定は
nowait/10/20になります。以下のように、これらのオプションはすべて fingerd デーモンのデフォルト設定に使われています。
finger stream tcp nowait/3/10 nobody /usr/libexec/fingerd fingerd -s
- user
user はあるデーモンが実行するときのユーザ名を指定します。 一般的にデーモンは
rootユーザとして実行します。セキュリティを考慮して、 いくつかのサーバはdaemonユーザ、 または最低の権限が与えられているnobodyユーザとして実行することも多く見られます。- server-program
接続を受け取ったときに実行するデーモンのフルパスです。 デーモンが inetd によって内部的に提供されるサービスの場合
internalを使用します。- server-program-arguments
ここには、起動するときにデーモンに渡される、 argv[0] から始まる引数を指定して、
server-programと協調して動作します。 mydaemon -d がコマンドラインの場合、server program argumentsの値にmydaemon -dを指定します。 また、デーモンが内部サービスの場合、ここにinternalを指定します。
20.14.5. セキュリティ
インストールの時に選択したセキュリティプロファイルによっては、 多くの inetd のデーモンがデフォルトで有効になっているかもしれません。 あるデーモンが特に必要でない場合には、それを無効にしてください! 問題となっているデーモンが記述されている行の先頭に "#" をおいて inetd にハングアップシグナルを送ってください。 fingerd のようないくつかのデーモンは、 動かそうとすべきではないかもしれません。なぜなら、 それらは攻撃者に対してあまりにも多くの情報を与えるからです。
セキュリティをあまり考慮せず、 接続試行に対してタイムアウトまでの時間が長いか、 タイムアウトしないデーモンもあります。 これは、特定のデーモンに攻撃者がゆっくり接続要求を送ることによって、 利用可能なリソースを飽和させることを可能にします。ある種のデーモンに ip-per-minute および max-child 制限を設けることはよい考えかもしれません。
TCP wrapper はデフォルトで有効です。 inetd から起動されるさまざまなデーモンに対して TCP 制限を設けることの詳細については hosts_access(5) マニュアルページを参照してください。
20.14.6. その他
daytime, time, echo, discard, chargen および auth はすべて inetd が内部的に提供するサービスです。
auth サービスは identity (ident, identd) ネットワークサービスを提供し、 ある程度設定可能です。
詳細については inetd(8) マニュアルを参照してください。
20.15. パラレルライン IP (PLIP)
PLIP はパラレルポート間で TCP/IP 通信を可能にします。 これはネットワークカードの無いマシンやノートパソコンにインストールするときに役に立ちます。 この節では以下について説明します。
パラレル (ラップリンク または パラレルクロス) ケーブルの作成。
2 台のコンピュータの PLIP による接続。
20.15.1. パラレル (クロス) ケーブルの作成
コンピュータ用品店のほとんどでパラレル (クロス) ケーブルを購入することができます。 購入することができないか、 単にケーブルがどのような構造であるか知りたい場合は、 次の表に通常のパラレルプリンタケーブルをもとに作成する方法が示されています。
| A-名称 | A-端 | B-端 | 説明 | Post/Bit |
|---|---|---|---|---|
.... DATA0 -ERROR .... | .... 2 15 .... | .... 15 2 .... | Data | .... 0/0x01 1/0x08 .... |
.... DATA1 +SLCT .... | .... 3 13 .... | .... 13 3 .... | Data | .... 0/0x02 1/0x10 .... |
.... DATA2 +PE .... | .... 4 12 .... | .... 12 4 .... | Data | .... 0/0x04 1/0x20 .... |
.... DATA3 -ACK .... | .... 5 10 .... | .... 10 5 .... | Strobe | .... 0/0x08 1/0x40 .... |
.... DATA4 BUSY .... | .... 6 11 .... | .... 11 6 .... | Data | .... 0/0x10 1/0x80 .... |
GND | 18-25 | 18-25 | GND | - |
20.15.2. PLIP の設定
はじめに、ラップリンクケーブルを入手しなければなりません。 次に、両方のコンピュータのカーネルが lpt(4) ドライバ対応であることを確認してください。
# grep lp /var/run/dmesg.boot
lpt0: <Printer> on ppbus0
lpt0: Interrupt-driven portパラレルポートは割り込み駆動ポートでなければなりません。 FreeBSD 4.X では、 以下のような行がカーネルコンフィギュレーションファイル内になければならないでしょう。
device ppc0 at isa? irq 7
FreeBSD 5.X では /boot/device.hints ファイルに以下の行がなければならないでしょう。
hint.ppc.0.at="isa" hint.ppc.0.irq="7"
それからカーネルコンフィギュレーションファイルに device plip という行があるか、または plip.ko カーネルモジュールが読み込まれていることを確認してください。 どちらの場合でも ifconfig(8) コマンドを直接実行したときに、 パラレルネットワークインタフェースが現れるはずです。 FreeBSD 4.X ではこのようになります。
# ifconfig lp0
lp0: flags=8810<POINTOPOINT,SIMPLEX,MULTICAST> mtu 1500FreeBSD 5.X ではこのようになります。
# ifconfig plip0
plip0: flags=8810<POINTOPOINT,SIMPLEX,MULTICAST> mtu 1500パラレルインタフェースに対して用いられるデバイス名は FreeBSD 4.X (lpX) と FreeBSD 5.X (plipX) 間で異なります。 |
両方のコンピュータのパラレルインタフェースにラップリンクケーブルを接続します。
両方のネットワークインタフェースパラメータを root で設定します。 たとえば、FreeBSD 4.X を動作させている host1 と FreeBSD 5.X を動作させている host2 の両ホストを接続したい場合は次のようにします。
host1 <-----> host2 IP Address 10.0.0.1 10.0.0.2
次のコマンドで host1 上のインタフェースを設定します。
# ifconfig lp0 10.0.0.1 10.0.0.2次のコマンドで host2 上のインタフェースを設定します。
# ifconfig plip0 10.0.0.2 10.0.0.1さらに/etc/hosts に両ホストを加えるとよいでしょう。
127.0.0.1 localhost.my.domain localhost 10.0.0.1 host1.my.domain host1 10.0.0.2 host2.my.domain
接続がうまくいっているか確かめるために、 両方のホスト上で互いを ping してください。 たとえば host1 で以下を実行します。
# ifconfig lp0
lp0: flags=8851<UP,POINTOPOINT,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 10.0.0.1 --> 10.0.0.2 netmask 0xff000000
# netstat -r
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
host2 host1 UH 0 0 lp0
# ping -c 4 host2
PING host2 (10.0.0.2): 56 data bytes
64 bytes from 10.0.0.2: icmp_seq=0 ttl=255 time=2.774 ms
64 bytes from 10.0.0.2: icmp_seq=1 ttl=255 time=2.530 ms
64 bytes from 10.0.0.2: icmp_seq=2 ttl=255 time=2.556 ms
64 bytes from 10.0.0.2: icmp_seq=3 ttl=255 time=2.714 ms
--- host2 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max/stddev = 2.530/2.643/2.774/0.103 ms20.16. IPv6
IPv6 (IPng "IP next generation" とも呼ばれます) は、著名な IP プロトコル (IPv4 とも呼ばれます) の新しいバージョンです。 他の最新の *BSD システムと同様に FreeBSD は KAME IPv6 リファレンス実装を含んでいます。したがって、あなたの FreeBSD システムには IPv6を試すために必要なものすべてが備わっています。 この節では IPv6 の設定と実行に関して説明します。
1990 年代のはじめには、人々は IPv4 アドレス空間が急速に縮小していることに気づくようになりました。 インターネットの成長率が増大するにしたがって、 2 つの心配ごとがでてきました。
アドレスの枯渇。 今日では、プライベートアドレス空間 (
10.0.0.0/8,192.168.0.0/24など) およびネットワークアドレス変換 (NAT) が使用されているので、それほど心配されていません。ルーティングテーブルのエントリが大きくなりすぎていました。 これは今でも心配な事柄です。
IPv6 は以下の、そしてその他多くの問題を扱います。
128 bit アドレス空間。言い換えると、理論上 340,282,366,920,938,463,463,374,607,431,768,211,456 個のアドレスが利用可能です。これは地球上の一平方メータあたり、 およそ 6.67 * 10^27 個の IPv6 アドレスがあることを意味します。
ルータは、 ルーティングテーブル内にネットワーク集約アドレスだけを格納することで、 ルーティングテーブルの平均を 8192 項目程度に減らします。
他にも以下のように IPv6 の便利な機能がたくさんあります。
アドレス自動設定 (RFC2462)
エニーキャスト (anycast) アドレス ("one-out-of many" 訳注: 複数の異なるノードが応答する 1 つのアドレス。 RFC2526 を参照してください)。
強制マルチキャストアドレス
IPsec (IP セキュリティ)
シンプルなヘッダ構造
モバイル IP
IPv4 から IPv6 への移行手段
詳細については下記を参照してください。
20.16.1. IPv6 アドレスの背景
いくつか違うタイプの IPv6 アドレスがあります。 ユニキャスト (Unicast)、エニーキャスト (Anycast) およびマルチキャスト (Multicast) です。
ユニキャストアドレスは周知のアドレスです。 ユニキャストアドレスへ送られたパケットは、 まさにそのアドレスに属するインターフェースに到着します。
エニーキャストアドレスはユニキャストアドレスと構文上判別不可能ですが、 インタフェース群に宛てられています。 エニーキャストアドレスに送られたパケットは (ルータメトリック的に) 最も近いインタフェースに到着します。 エニーキャストアドレスはルータでしか使ってはいけません。
マルチキャストアドレスはインタフェース群を識別します。 マルチキャストアドレスに送られたパケットは、 マルチキャスト群に属するすべてのインタフェースに到着します。
IPv4 のブロードキャストアドレス (通常 |
| IPv6 アドレス | プレフィックス長 (ビット) | 説明 | 備考 |
|---|---|---|---|
| 128 ビット | 不特定 | IPv4 の |
| 128 ビット | ループバックアドレス | IPv4 の |
| 96 ビット | IPv4 埋め込みアドレス | 下位の 32 ビットは IPv4 アドレスです。 "IPv4 互換 IPv6 アドレス" とも呼ばれます。 |
| 96 ビット | IPv4 射影 IPv6 アドレス | 下位の 32 ビットは IPv4 アドレスです。 IPv6 に対応していないホストに対するアドレスです。 |
| 10 ビット | リンクローカル | IPv4 のループバックアドレス参照 |
| 10 ビット | サイトローカル | |
| 8 ビット | マルチキャスト | |
| 3 ビット | グローバルユニキャスト | すべてのグローバルユニキャストアドレスはこのプールから割り当てられます。 はじめの 3 ビットは "001" です。 |
20.16.2. IPv6 アドレスを読む
正規の書式では x:x:x:x:x:x:x:x と表されます。それぞれの "x" は 16 ビットの 16 進数です。たとえば FEBC:A574:382B:23C1:AA49:4592:4EFE:9982 となります。
すべてゼロの長い部分文字列がアドレス内によく現れます。 そのため、そのような部分文字列は "::" に短縮することができます。 たとえば、fe80::1 は正規形の fe80:0000:0000:0000:0000:0000:0000:0001 に対応します。
3 番目の形式は、最後の 32 ビットの部分を "." を分割文字として使う、 なじみ深い IPv4 (10 進) 形式で書くことです。 たとえば 2002::10.0.0.1 は (16 進) 正規形の 2002:0000:0000:0000:0000:0000:0a00:0001 に対応し、同時に 2002::a00:1 と書くこととも等価です。
ここまで来れば、下記を理解することができるでしょう。
# ifconfigrl0: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> mtu 1500
inet 10.0.0.10 netmask 0xffffff00 broadcast 10.0.0.255
inet6 fe80::200:21ff:fe03:8e1%rl0 prefixlen 64 scopeid 0x1
ether 00:00:21:03:08:e1
media: Ethernet autoselect (100baseTX )
status: activefe80::200:21ff:fe03:8e1%rl0 は自動的に設定されたリンクローカルアドレスです。 これは自動設定の一環として、 イーサネット MAC アドレスを変換したものを含んでいます。
IPv6 アドレス構造についての詳細は RFC3513 をご覧ください。
20.16.3. 接続
現在、他の IPv6 ホストおよびネットワークに接続するためには 4 つの方法があります。
6bone 実験ネットワークに参加する。
上流のプロバイダから IPv6 ネットワークの割り当てを受ける。 手順については、インターネットプロバイダに問い合わせてください。
IPv6 over IPv4 によるトンネル。
ダイアルアップ接続の場合 freenet6 port を使用する。
ここでは、現在もっともよく使われている方法と思われる 6bone へ接続する方法を説明します。
はじめに 6bone サイトをみて、 あなたに最も近い 6bone 接続先を見つけてください。 責任者に連絡すると、少しばかり運がよければ、 接続を設定する方法についての指示を受けられるでしょう。 多くのばあい、これには GRE (gif) トンネルの設定が含まれます。
6bone は |
ここに gif(4) トンネルを設定する典型的な例を示します。
# ifconfig gif0 create
# ifconfig gif0
gif0: flags=8010<POINTOPOINT,MULTICAST> mtu 1280
# ifconfig gif0 tunnel MY_IPv4_ADDR HIS_IPv4_ADDR
# ifconfig gif0 inet6 alias MY_ASSIGNED_IPv6_TUNNEL_ENDPOINT_ADDR大文字になっている単語を、 上流の 6bone ノードから受け取った情報に置き換えてください。
これでトンネルが確立されます。ping6(8) を ff02::1%gif0 に送ることによって、トンネルが動作しているか確かめてください。 ping の応答を 2 つ受け取るはずです。
|
ここまで来ると 6bone アップリンクに経路設定することは比較的簡単でしょう。
# route add -inet6 default -interface gif0
# ping6 -n MY_UPLINK# traceroute6 www.jp.FreeBSD.org
(3ffe:505:2008:1:2a0:24ff:fe57:e561) from 3ffe:8060:100::40:2, 30 hops max, 12 byte packets
1 atnet-meta6 14.147 ms 15.499 ms 24.319 ms
2 6bone-gw2-ATNET-NT.ipv6.tilab.com 103.408 ms 95.072 ms *
3 3ffe:1831:0:ffff::4 138.645 ms 134.437 ms 144.257 ms
4 3ffe:1810:0:6:290:27ff:fe79:7677 282.975 ms 278.666 ms 292.811 ms
5 3ffe:1800:0:ff00::4 400.131 ms 396.324 ms 394.769 ms
6 3ffe:1800:0:3:290:27ff:fe14:cdee 394.712 ms 397.19 ms 394.102 msこの出力はマシンによって異なります。 これで、あなたが www/mozilla のような IPv6 が利用可能なブラウザを持っていれば、 IPv6 サイト www.kame.net にいって踊るカメを見ることができるでしょう。
最終更新日: 2026年6月18日 by Alexander Ziaee