Date: Mon, 19 Jan 2009 15:04:02 -0500 From: David Schultz <das@FreeBSD.ORG> To: d@delphij.net Cc: freebsd-arch@FreeBSD.ORG Subject: Re: RFC: MI strlen() Message-ID: <20090119200402.GA26878@zim.MIT.EDU> In-Reply-To: <4966B5D4.7040709@delphij.net> References: <4966B5D4.7040709@delphij.net>
next in thread | previous in thread | raw e-mail | index | archive | help
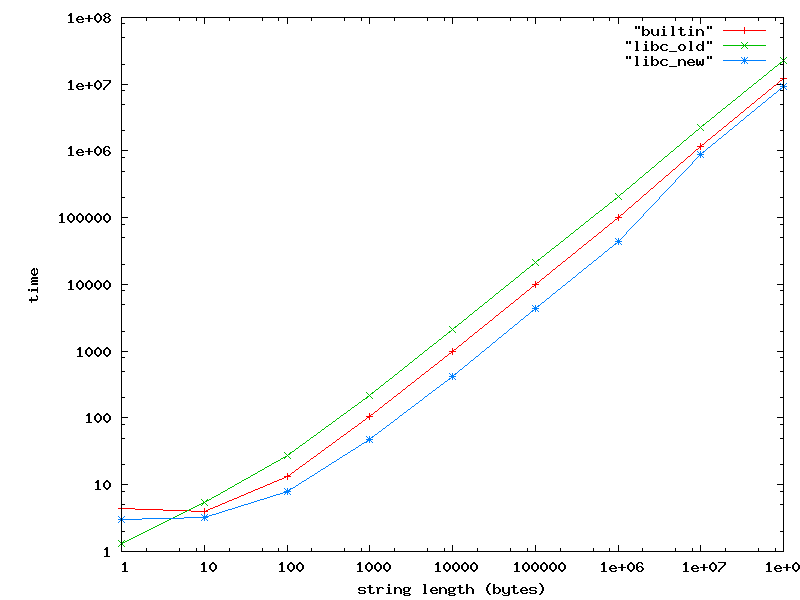
On Thu, Jan 08, 2009, Xin LI wrote: > Here is a new implementation of strlen() which employed the bitmask > skill in order to achieve better performance on modern hardware. For > common case, this would be a 5.2x boost on FreeBSD/amd64. The code is > intended for MI use when there is no hand-optimized assembly. I ran some microbenchmarks on amd64, which show that the version of strlen() in libc is up to twice as fast as yours for short strings (< 4 bytes), but your implementation is nearly 5 times as fast for longer strings. As Bruce pointed out, gcc will almost use its builtin strlen(). However, that may change in the future, and nobody has suggested that your version would actually hurt anything, so I think you should commit it. Benchmark results: http://www.freebsd.org/~das/strlen.gif I ran this on a Wolfdale core using word-aligned ASCII strings and an adaptive number of iterations. As you can see, the gcc builtin is always slower than your code, but faster than our current libc implementation. I can't explain why the builtin is faster for strings of length 10 than it is for strings of length 1, but the results are repeatable. Another interesting thing to note is that your implementation is the only one that gets less throughput when the string no longer fits in the L2 cache. This suggests that either the other two are so slow that they can't use the full memory bandwidth, or they are more effective at triggering the CPU's prefetch heuristics.
{kind=link}
Want to link to this message? Use this URL: <https://mail-archive.FreeBSD.org/cgi/mid.cgi?20090119200402.GA26878>